Python数据分析-pandas库入门
pandas 库概述
pandas 提供了快速便捷处理结构化数据的大量数据结构和函数。自从2010年出现以来,它助使 Python 成为强大而高效的数据分析环境。pandas使用最多的数据结构对象是 DataFrame,它是一个面向列(column-oriented)的二维表结构,另一个是 Series,一个一维的标签化数组对象。
pandas 兼具 NumPy 高性能的数组计算功能以及电子表格和关系型数据库(如SQL)灵活的数据处理功能。它提供了复杂精细的索引功能,能更加便捷地完成重塑、切片和切块、聚合以及选取数据子集等操作。数据操作、准备、清洗是数据分析最重要的技能,pandas 是首选 python 库之一。
个人觉得,学习 pandas 还是最好在 anaconda 的 jupyter 环境下进行,方便断点调试分析,也方便一行行运行代码。
安装 pandas
Windows/Linux系统环境下安装
conda方式安装
conda install pandaspip3方式安装
py -3 -m pip install --upgrade pandas #Windows系统
python3 -m pip install --upgrade pandas #Linux系统pandas 库使用
pandas 采用了大量的 NumPy 编码风格,但二者最大的不同是 pandas 是专门为处理表格和混杂数据设计的。而 NumPy 更适合处理统一的数值数组数据。
导入 pandas 模块,和常用的子模块 Series 和 DataFrame
import pands as pd
from pandas import Series,DataFrame通过传递值列表来创建 Series,让 pandas 创建一个默认的整数索引:
s = pd.Series([1,3,5,np.nan,6,8])
s输出
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
pandas数据结构介绍
要使用 pandas,你首先就得熟悉它的两个主要数据结构:Series 和 DataFrame。虽然它们并不能解决所有问题,但它们为大多数应用提供了一种可靠的、易于使用的基础。
Series数据结构
Series 是一种类似于一维数组的对象,它由一组数据(各种 NumPy 数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生最简单的 Series。代码示例:
import pandas as pd
obj = pd.Series([1,4,7,8,9])
objSeries 的字符串表现形式为:索引在左边,值在右边。由于我们没有为数据指定索引,于是会自动创建一个 0 到 N-1( N 为数据的长度)的整数型索引。也可以通过Series 的 values 和 index 属性获取其数组表示形式和索引对象,代码示例:
obj.values
obj.index # like range(5)输出:
array([ 1, 4, 7, 8, 9])
RangeIndex(start=0, stop=5, step=1)
我们也希望所创建的 Series 带有一个可以对各个数据点进行标记的索引,代码示例:
obj2 = pd.Series([1, 4, 7, 8, 9],index=['a', 'b', 'c', 'd'])
obj2
obj2.index输出
a 1
b 4
c 7
d 8
e 9
dtype: int64
Index([‘a’, ‘b’, ‘c’, ‘d’, ‘e’], dtype=’object’)
与普通 NumPy 数组相比,你可以通过索引的方式选取 Series 中的单个或一组值,代码示例:
obj2[['a', 'b', 'c']]
obj2['a']=2
obj2[['a', 'b', 'c']][‘a’,’b’,’c]是索引列表,即使它包含的是字符串而不是整数。
使用 NumPy 函数或类似 NumPy 的运算(如根据布尔型数组进行过滤、标量乘法、应用数学函数等)都会保留索引值的链接,代码示例:
obj2*2
np.exp(obj2)还可以将 Series 看成是一个定长的有序字典,因为它是索引值到数据值的一个映射。它可以用在许多原本需要字典参数的函数中,代码示例:
dict = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000,'Utah': 5000}
obj3 = pd.Series(dict)
obj3输出
Ohio 35000
Oregon 16000
Texas 71000
Utah 5000
dtype: int64
DataFrame数据结构
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共用同一个索引)。DataFrame 中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
虽然 DataFrame 是以二维结构保存数据的,但你仍然可以轻松地将其表示为更高维度的数据(层次化索引的表格型结构,这是 pandas中许多高级数据处理功能的关键要素 )
创建 DataFrame 的办法有很多,最常用的一种是直接传入一个由等长列表或 NumPy 数组组成的字典,代码示例:
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada','Nevada'],'year': [2000, 2001, 2002, 2001, 2002, 2003],'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
frame = pd.DataFrame(data)
frame结果 DataFrame 会自动加上索引(跟 Series 一样),且全部列会被有序排列,输出如下:
对于特别大的 DataFrame,head 方法会选取前五行:
frame.head()如果指定了列序列,则 DataFrame 的列就会按照指定顺序进行排列,代码示例:
pd.DataFrame(data,columns=['state','year','pop'])如果传入的列在数据中找不到,就会在结果中产生缺失值,代码示例:
frame2 = pd.DataFrame(data,columns=['state','year','pop','debt'],index=['one','two','three','four','five','six'])
frame2获取 DataFrame 的 columns 和 index,代码示例:
frame2.columns
frame2.index输出
Index([‘state’, ‘year’, ‘pop’, ‘debt’], dtype=’object’)
Index([‘one’, ‘two’, ‘three’, ‘four’, ‘five’, ‘six’], dtype=’object’)
通过类似字典标记的方式或属性的方式,可以将 DataFrame 的列获取为一个 Series,代码示例:
frame2['state']
frame2.state列可以通过赋值的方式进行修改,赋值方式类似 Series。例如,我们可以给那个空的 “debt” 列赋上一个标量值或一组值(数组或列表形式),代码示例:
frame2.debt = np.arange(6.)
frame2注意:将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。
如果赋值的是一个 Series,就会精确匹配 DataFrame 的索引,所有的空位都将被填上缺失值,代码示例:
val = pd.Series([-1.2, -1.5, -1.7], index=['two', 'four','five'])
frame2.debt = val
frame2为不存在的列赋值会创建出一个新列。关键字 del 用于删除列。
作为 del 的例子,这里先添加一个新的布尔值的列,state 是否为 ‘Ohio’,代码示例:
frame2['eastern'] = frame2.state=='Ohio'
frame2DataFrame 另一种常见的数据形式是嵌套字典,如果嵌套字典传给 DataFrame,pandas 就会被解释为:外层字典的键作为列,内层键则作为行索引,代码示例:
#DataFrame另一种常见的数据形式是嵌套字典
pop = {'Nvidia':{2001:2.4,2002:3.4},'Intel':{2000:3.7,2001:4.7,2002:7.8}
}
frame3 = pd.DataFrame(pop,columns=['Nvidia','Intel'])
frame3表5-1列出了DataFrame构造函数所能接受的各种数据
索引对象
pandas 的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建 Series 或 DataFrame 时,所用到的任何数组或其他序列的标签都会被转换成一个 Index,代码示例:
import numpy as np
import pandas as pd
obj = pd.Series(np.arange(4),index=['a','b','c','d'])
index = obj.index
#index
index[:-1]注意:Index 对象是不可变的,因此用户不能对其进行修改。
不可变可以使 Index 对象在多个数据结构之间安全共享,代码示例:
#pd.Index储存所有pandas对象的轴标签
#不可变的ndarray实现有序的可切片集
labels = pd.Index(np.arange(3))
obj2 = pd.Series([1.5, -2.5, 0], index=labels)
obj2
#print(obj2.index is labels)注意:虽然用户不需要经常使用 Index 的功能,但是因为一些操作会生成包含被索引化的数据,理解它们的工作原理是很重要的。
与 python 的集合不同,pandas 的 Index 可以包含重复的标签,代码示例:
dup_labels = pd.Index(['foo','foo','bar','alice'])
dup_labels每个索引都有一些方法和属性,它们可用于设置逻辑并回答有关该索引所包含的数据的常见问题。表5-2列出了这些函数。
pandas 选择数据
import numpy as np
import pandas as pd
# dates = pd.date_range('20190325', periods=6)
dates = pd.date_range('20190325', periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates, columns=['A','B','C','D'])
print(df)
'''A B C D
2019-03-25 0 1 2 3
2019-03-26 4 5 6 7
2019-03-27 8 9 10 11
2019-03-28 12 13 14 15
2019-03-29 16 17 18 19
2019-03-30 20 21 22 23
'''
# 检索指定A列
print(df['A']) # 等同于print(df.A)
'''
2019-03-25 0
2019-03-26 4
2019-03-27 8
2019-03-28 12
2019-03-29 16
2019-03-30 20
Freq: D, Name: A, dtype: int64
'''
## 切片选取多行或多列
print(df[0:3]) # 等同于print(df['2019-03-25':'2019-03-27'])
'''A B C D
2019-03-25 0 1 2 3
2019-03-26 4 5 6 7
2019-03-27 8 9 10 11
'''
# 根据标签选择数据
# 获取特定行或列
# 指定行数据
print(df.loc['2019-03-25'])
bb = df.loc['2019-03-25']
print(type(bb))
'''
A 0
B 1
C 2
D 3
Name: 2019-03-25 00:00:00, dtype: int64
<class 'pandas.core.series.Series'>
'''
# 指定列, 两种方式
print(df.loc[:, ['A', 'B']]) # print(df.loc[:, 'A':'B'])
'''A B
2019-03-25 0 1
2019-03-26 4 5
2019-03-27 8 9
2019-03-28 12 13
2019-03-29 16 17
2019-03-30 20 21
'''
# 行列同时检索
cc = df.loc['20190325', ['A', 'B']]
print(cc);print(type(cc.values))# numpy ndarray
'''
A 0
B 1
Name: 2019-03-25 00:00:00, dtype: int64
<class 'numpy.ndarray'>
'''
print(df.loc['20190326', 'A'])
'''
4
'''
# 根据序列iloc获取特定位置的值, iloc是根据行数与列数来索引的
print(df.iloc[1,0]) # 13, numpy ndarray
'''
4
'''
print(df.iloc[3:5,1:3]) # 不包含末尾5或3,同列表切片
'''B C
2019-03-28 13 14
2019-03-29 17 18
'''
# 跨行操作
print(df.iloc[[1, 3, 5], 1:3])
'''B C
2019-03-26 5 6
2019-03-28 13 14
2019-03-30 21 22
'''
# 通过判断的筛选
print(df[df.A>8])
'''A B C D
2019-03-28 12 13 14 15
2019-03-29 16 17 18 19
2019-03-30 20 21 22 23
'''总结
本文主要记录了 Series 和 DataFrame 作为 pandas 库的基本结构的一些特性,如何创建 pandas 对象、指定 columns 和 index 创建 Series 和 DataFrame 对象、赋值操作、属性获取、索引对象等,这章介绍操作 Series 和 DataFrame 中的数据的基本手段。
参考资料
《利用python进行数据分析》
相关文章:

Python数据分析-pandas库入门
pandas 库概述pandas 提供了快速便捷处理结构化数据的大量数据结构和函数。自从2010年出现以来,它助使 Python 成为强大而高效的数据分析环境。pandas使用最多的数据结构对象是 DataFrame,它是一个面向列(column-oriented)的二维表…...
MacBook Pro 恢复出厂设置
目录1.恢复出厂设置1.1 按Command-R 键1.2 macOS 实用工具1.3 从 macOS 恢复功能的实用工具窗口中选择“磁盘工具”,然后点按“继续”1.4 在“磁盘工具”边栏中选择您的设备或宗卷。1.5 点按“抹掉”按钮或标签页1.6 抹掉OS X HD - 数据 完成1.7 抹掉 OS X HD1.8 查…...

googletest 笔记
什么是一个好的测试 1 测试应该是独立的和可重复的。调试一个由于其他测试而成功或 失败的测试是一件痛苦的事情。googletest 通过在不同的对象上 运行测试来隔离测试。当测试失败时,googletest 允许您单独运 行它以快速调试。 2 测试应该很好地“组织”,…...

MySQL修改密码的几种方式?
第一种方式: 最简单的方法就是借助第三方工具Navicat for MySQL来修改。方法如下: 1、登录mysql到指定库,如:登录到test库。 2、然后点击上方"用户"按钮。 3、选择要更改的用户名,然后点击上方的"编辑用…...

关于画一个句号--基于2022年终总结的反思与分享
没有平台鼓风造势,今年各大平台没有涌现出一批总结,非常清爽 正如同人发明了抽屉,将杂物进行整理、丢弃、收纳,才能对空间进行更合理地使用。我们也需要对知识、过往经历进行整理、丢弃、收纳,才能对大脑进行更合理地…...

学习Flask之三、模板
学习Flask之三、模板 书写易于维护的应用的关键是书写整洁和良构的代码。到目前为止你所见的例子过于简单而不能体现这点。把两个目的完全独立的Flask view 函数当作一个来写,会产生问题。view函数的一个显然的任务是对请求作出响应,如前面的例子所示。对…...

2023-02-20干活小计:
所以我今天的活开始了: In this paper, the authors target the problem of Multimodal Name Entity Recognition(MNER) as an improvement on NER(text only) The paper proposes a multimodal fusion based on a heterogeneous graph of texts and images to mak…...
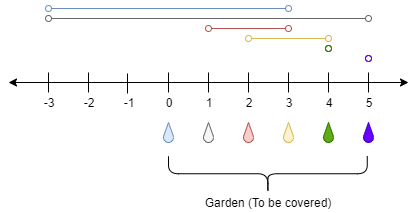
LeetCode_动态规划_困难_1326.灌溉花园的最少水龙头数目
目录1.题目2.思路3.代码实现(Java)1.题目 在 x 轴上有一个一维的花园。花园长度为 n,从点 0 开始,到点 n 结束。 花园里总共有 n 1 个水龙头,分别位于 [0, 1, …, n] 。 给你一个整数 n 和一个长度为 n 1 的整数数…...
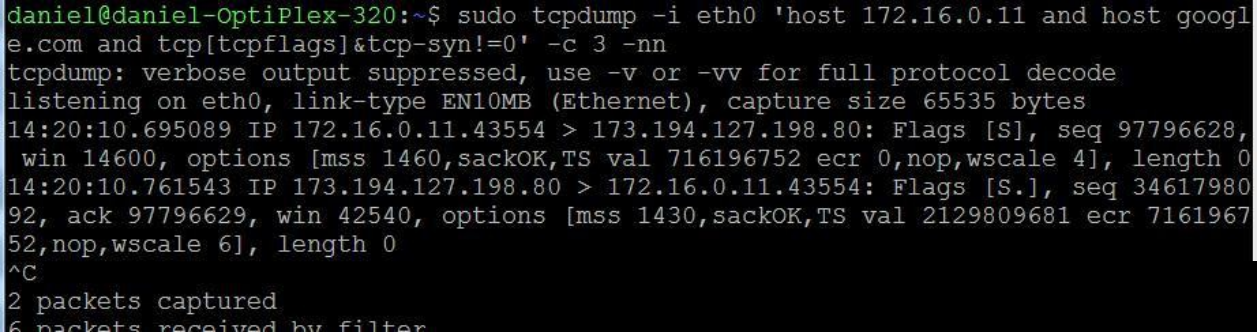
mac tcpdump学习
学习原因 工作上遇到了重启wifi后无法发出mDNS packet的情况,琢磨一下用tcpdump用的命令如下 sudo tcpdump -n -k -s 0 -i en0 -w VENDOR-DUT-INTERFACE.pcapng是在测airplay BCT认证时,官方文档的解决方法。对tcpdump很不了解,现汇总如下的学…...

【跟我一起读《视觉惯性SLAM理论与源码解析》】第二章 编程及编译工具
23.2.21终于拿到六哥的新书 感觉很是不错,打算近期写一写心得之类的 废话不多说,直接开啃 PS:我的建议是阅读完十四讲后再来看这本书,效果应该会很不错。 因为第一章都是介绍之类的我觉得没什么整理的必要,所以直接来…...

广东望京卡牌科技有限公司,2023年团建活动圆满举行
玉兔初临,春天相随,抖擞精神,好运连连。春天是一个万物复苏的季节,来自广东的望京卡牌科技有限公司,也迎来了新年第一次团建活动。在“乘风破浪、追逐梦想”的口号声中,2023望京卡牌目标启动会团结活动正式…...

ts语法如何在Vue3中运用?
一、父子传值的用法 父传子:defineProps的TS写法 // 父组件:和 vue2 一样正常传值 <template><div class"login-page"><cp-nav-bar title"登录" right-text"注册"></cp-nav-bar></div> &…...

RK3566添加湿度传感器以及浅析hal层
RK3566添加一款温湿度传感器gxht3x.挂在i2c总线下。驱动部分就不多做解析。大致流程硬件接好i2c线以及vcc gnd。后看数据手册。初始化寄存器,然后要读数据的话读那个寄存器,读出来的数据要做一个转化,然后实现open read write ioctl函数就行了。本文主要…...
看了这份Java高级笔试宝典覆盖近3年Java笔试中98%高频知识点,反打面试官
首先声明: 本书覆盖了近3年程序员面试笔试中超过98%Java高频知识点,当你细细品读完本书后,面试都是小问题。 一书在手/工作不愁 记住重点,考试要考 前言 程序员求职始终是当前社会的一个热点,而市面上有很多关于程…...
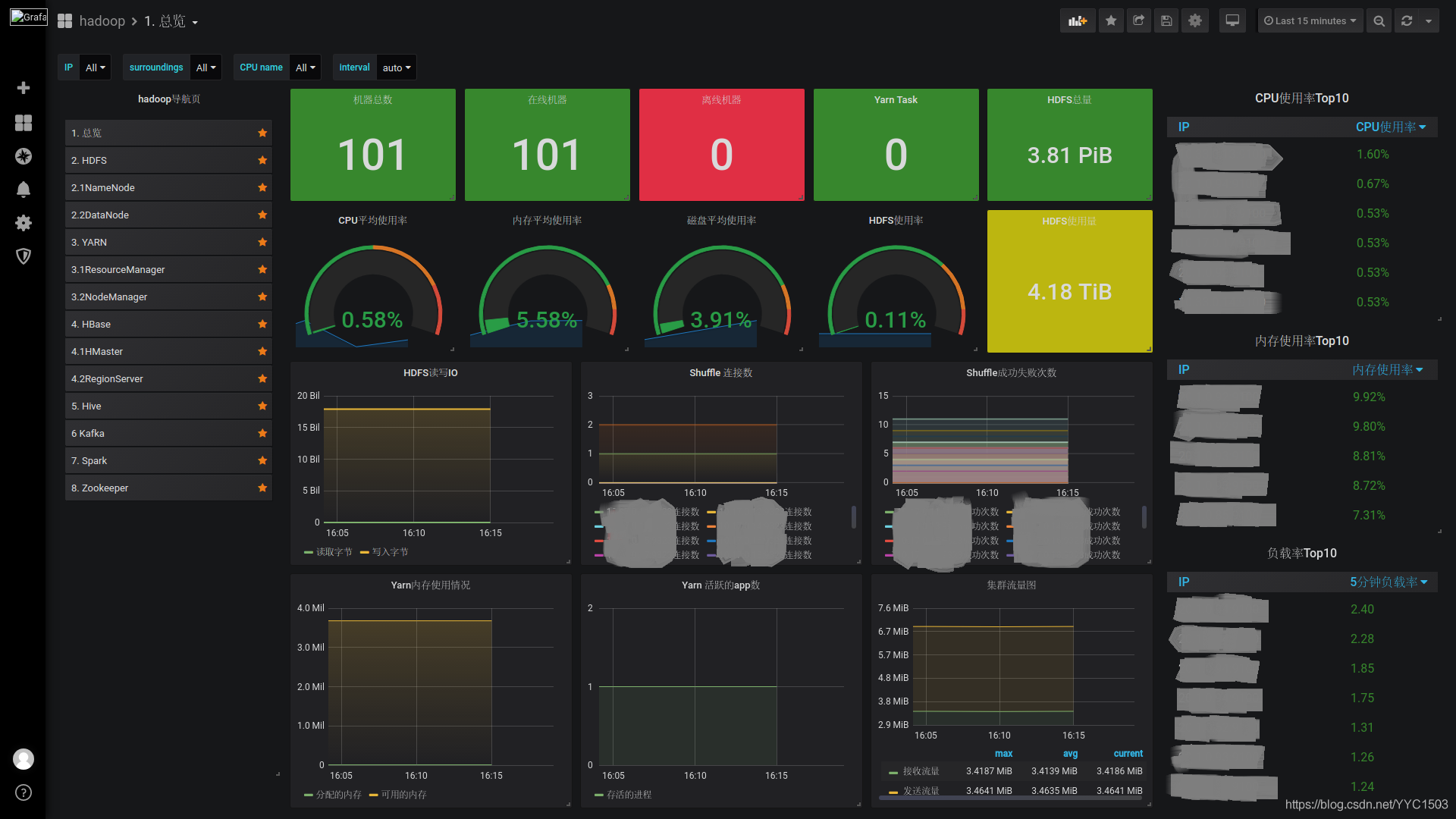
从0到1搭建大数据平台之监控
大家好,我是脚丫先生 (o^^o) 大数据平台设计中,监控系统尤为重要。 它时刻关乎大数据开发人员的幸福感。 试想如果半夜三更,被电话吵醒解决集群故障问题,那是多么的痛苦!!! 但是不加班是不可…...

采购评标管理过程是怎样的?有哪些评标标准?
采购活动的评标是检查和比较投标的有组织的过程,以选择最佳报价,努力获得实现企业目标所需的货物、工程和服务。 评标是由一个被称为评标小组的机构负责。这个小组如何称呼,取决于企业的情况。同义词有报价审查小组、投标审查委员会或投标审…...
《Vue+Spring Boot前后端分离开发实战》专著累计发行上万册
杰哥的学术专著《VueSpring Boot前后端分离开发实战》由清华大学出版社于2021年3月首次出版发行,虽受疫情影响但热度不减,受到业界读者的热捧,截至今日加印5次,累计发行12000册,引领读者开发前后端分离项目,…...

类与类之间的关系有哪几种?
文章目录程序设计要素1.可读性2.健壮性3.优化4.复用性5.可扩展性设计类的关系遵循的原则1、 高内聚低耦合2、面向对象开发中 “针对接口编程优于针对实现编程”,”组合优于继承” 的总体设计类与类之间的关系(即事物关系) A is-a B 泛化&…...

LeetCode 606.根据二叉树创建字符串,102.二叉树的层序遍历和牛客 二叉搜索树与双向链表
文章目录1. 根据二叉树创建字符串2. 二叉树的层序遍历3. 二叉搜索树与双向链表1. 根据二叉树创建字符串 难度 简单 题目链接 解题思路: 这里的意思就是:用前序遍历遍历这颗树。然后左子树和右子树分别在一个括号里。括号里的规则是: 1.左右都…...
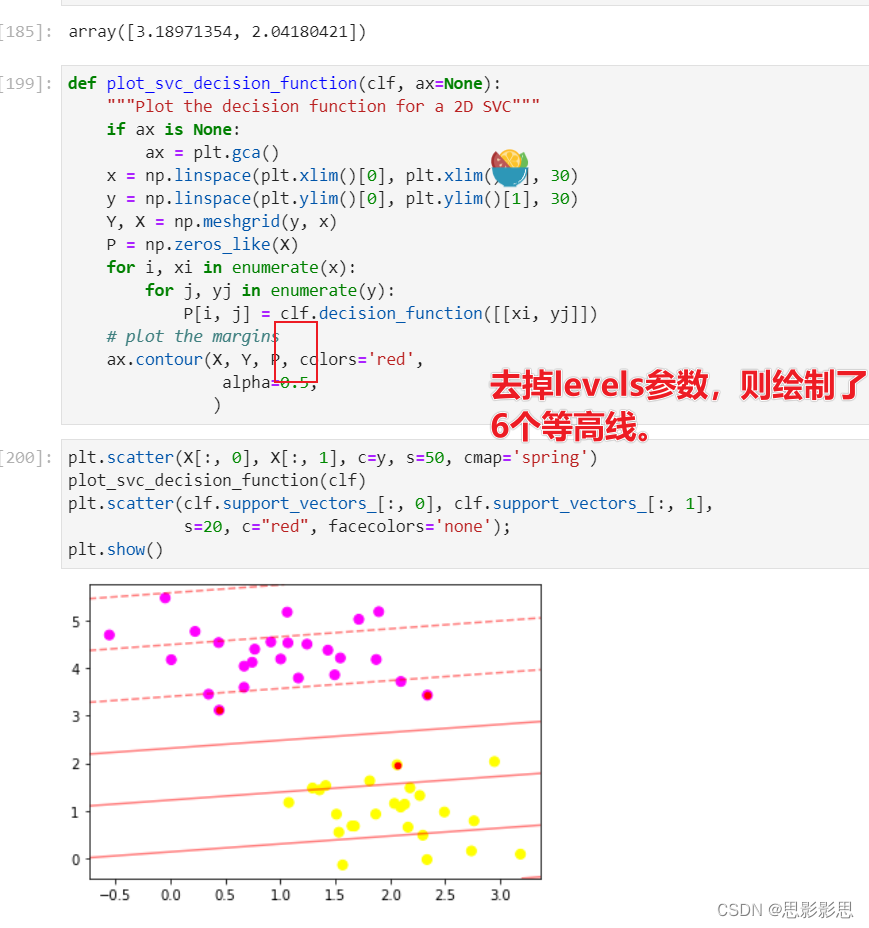
02-18 周六 图解机器学习之SMV 第五章5-2
02-18 周六 图解机器学习之SMV 第五章5-2时间版本修改人描述2023年2月18日11:47:18V0.1宋全恒新建文档 环境 程序的基本环境,是使用了jupyter,在容器中运行的。 简介 本程序主要演示支持向量的获取,支持向量是距离超平面最近的点组成的。程序…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

HarmonyOS ArkTS DateUtil 日期增减与日历计算完整指南
文章目录 背景一、引言二、日期增减方法详解使用示例 三、日历计算方法详解四、Demo 演示:日期增减结果展示五、Demo 演示:月历视图完整实现六、日历视图关键点解析为什么要填充前置空格?getLastDayOfMonth 的实现技巧 七、小结 背景 近期发现…...

WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南
WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸III作为经典即时战…...

光轮智能 谢晨 访谈总结机器人仿真数据产业
光轮智能 谢晨 访谈总结机器人仿真关于创始人关于数据数据金字塔数据痛点仿真数据的重要性仿真数据的质量b站链接地址公司官网关于创始人 清华物理;哥伦比亚金融;英伟达智驾仿真;小鹏智驾仿真;现为光轮智能CEO 关于数据 数据的…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...

AI率总超标?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...