【Python 自动化】自媒体剪辑第一版·思路简述与技术方案
大家都知道我主业是个运维开发(或者算法工程师),每天时间不多,但我又想做自媒体。然后呢,我就想了个方案,每天起来之后写个短视频的脚本,包含一系列图片和文字,然后上班的时候给它提交到流水线上跑,下班之前就能拿到视频,然后往各大平台上一传,是不是挺美滋滋的。
我和我之前的合伙人一说,他就觉得做短视频没啥用,不过还是按我说的做,出了一个脚本,我一看什么玩意儿,根本就没办法跑起来。无奈之下,我重新写了现在我要展示的这个版本。后来这个合伙人就装逼失败跑路了,大快人心。这个版本不长,也就3~400行,我就在想,连一个几百行的程序都写不好,还谈啥副业,真是可笑。
首先程序接受这样一个 YAML 剧本,定义了图片和文字内容。这里我把MR数据杨第一版引擎所使用的素材做成了剧本:
name: 人气直播主饶方晴气质笑颜无害又迷人
format: mp4
imgSize: [1280, 768]
contents:- type: image:filevalue: asset/1.jpg- type: audio:ttsvalue: 人气直播主饶方晴,气质笑颜无害又迷人。- type: image:filevalue: asset/2.jpg- type: audio:ttsvalue: 这笑容是要融化多少单身汉!小编今天要为大家送上这位白嫩系的正妹「亮亮Sunny」。- type: image:filevalue: asset/3.jpg- type: audio:ttsvalue: 浑身白皙的肌肤吹弹可破一般稚嫩,留着柔顺长发的她衬着那张清新又甜美的脸蛋。- type: image:filevalue: asset/4.jpg- type: audio:ttsvalue: 水汪大眼搭上迷人的微笑,让人对到一眼就深深着迷。- type: image:filevalue: asset/5.jpg- type: audio:ttsvalue: 往下一望还有一双壮美的峰景,深厚的事业线简直不留余地给司机们啊!- type: image:filevalue: asset/6.jpg- type: audio:ttsvalue: 亮亮本名又叫作「饶方晴」,身为美女主播的她凭着那亮丽的外表和姣好的体态。- type: image:filevalue: asset/7.jpg- type: audio:ttsvalue: 总能无时无刻圈下不少忠实粉丝,开朗又活泼的个性更是深受大家喜爱。- type: image:filevalue: asset/8.jpg- type: audio:ttsvalue: 大方的她平日也总在IG上放晒迷人又性感的自拍照。- type: image:filevalue: asset/9.jpg- type: audio:ttsvalue: 不只是濠乳沟乍现,连笔直又纤长的美腿也让腿控们大饱眼福呢!
很简单是吧,就是一个图片一个文本这样。真的不用太多,精雕细琢没意义,樊登说了,自媒体平台靠走量刷流量池取胜。我在此奉劝大家彻底抛弃完美主义。
子命令回调
因为我这个功能是一个工具集的子命令,回调就是子命令的入口。我们看看回调咋写的:
def autovideo(args):cfg_fname = args.configif not cfg_fname.endswith('.yml'):print('请提供 YAML 文件')returncfg_dir = path.dirname(cfg_fname)user_cfg = yaml.safe_load(open(cfg_fname, encoding='utf8').read())update_config(user_cfg, cfg_dir)# 素材预处理preproc_asset(config)# 转换成帧的形式frames = contents2frame(config['contents'])# 组装视频video = make_video(frames)if config['format'] != 'mp4':video = ffmpeg_conv_fmt(video, 'mp4', config['format'])# 写文件video_fname = fname_escape(config['name']) + '.' + config['format']print(video_fname)open(video_fname, 'wb').write(video)
一共这么五步:(1)读取配置(2)预处理(3)模块划分(4)组装(5)写文件,大功告成。
读取配置
(1)将用户传入的配置覆盖程序默认配置,(2)将所有素材对于剧本的相对路径转换成对于 CWD 的相对路径,(3)加载外部模块,覆盖 TTI 和 TTS 函数。
def update_config(user_cfg, cfg_dir):global ttsglobal tticonfig.update(user_cfg)if not config['contents']:raise AttributeError('内容为空,无法生成')for cont in config['contents']:if cont['type'].endswith(':file'):cont['value'] = path.join(cfg_dir, cont['value'])if config['header']:config['header'] = path.join(cfg_dir, config['header'])if config['footer']:config['footer'] = path.join(cfg_dir, config['footer'])if config['external']:mod_fname = path.join(cfg_dir, config['external'])exmod = load_module(mod_fname)if hasattr(exmod, 'tts'): tts = exmod.ttsif hasattr(exmod, 'tti'): tti = exmod.tti
预处理
(1)遍历每个内容,分别处理不同类型:
:file是文件,直接读取image:dir需要从资源目录随机挑选一张指定关键词的图片:url是网络资源,直接下载audio:tts是机器朗读的音频,直接调用 TTS 函数image:color是纯色图片,用 OpenCV 生成image:tti是文成图,直接调用 TTI 函数audio:blank是空白音频,直接用 SciPy 生成
(2)剪裁图片到配置规定的尺寸,(3)如果第一张不是图片,将第一个图片提前(当前这块逻辑也可以改成如果第一张不是图片就插入一个纯黑的图片)。
def preproc_asset(config):# 加载或生成内容for cont in config['contents']:if cont['type'].endswith(':file'):cont['asset'] = open(cont['value'], 'rb').read()elif cont['type'] == 'image:dir':assert config['assetDir']cont['asset'] = get_rand_asset_kw(config['assetDir'], cont['value'], is_pic)elif cont['type'].endswith(':url'):url = cont['value']print(f'下载:{url}')cont['asset'] = request_retry('GET', url).contentelif cont['type'] == 'audio:tts':text = cont['value']print(f'TTS:{text}')cont['asset'] = tts(text)elif cont['type'] == 'image:color':bgr = cont['value']if isinstance(bgr, str):assert re.search(r'^#[0-9a-fA-F]{6}$', bgr)r, g, b = int(bgr[1:3], 16), int(bgr[3:5], 16), int(bgr[5:7], 16)bgr = [b, g, r]cont['asset'] = gen_mono_color(config['size'][0], config['size'][1], bgr)elif cont['type'] == 'image:tti':text = cont['value']print(f'TTI:{text}')cont['asset'] = tti(text)elif cont['type'] == 'audio:blank':cont['asset'] = gen_blank_audio(cont['value'])config['contents'] = [c for c in config['contents']if 'asset' in c]# 剪裁图片w, h = config['size']mode = config['resizeMode']for c in config['contents']:if c['type'].startswith('image:'):c['asset'] = resize_img(c['asset'], w, h, mode)# 如果第一张不是图片,则提升第一个图片idx = -1for i, c in enumerate(config['contents']):if c['type'].startswith('image:'):idx = ibreakif idx == -1:print('内容中无图片,无法生成视频')sys.exit()if idx != 0:c = config['contents'][idx]del config['contents'][idx]config['contents'].insert(0, c)
模块划分
每个模块相对独立,每个模块只能有一个图片,但可以有多个音频。所以将单个图片和其后的连续音频划分到一个模块中。每个模块单独组装,之后再连接起来,这样比较方便处理字幕。
def contents2frame(contents):frames = []for c in contents:if c['type'].startswith('image:'):frames.append({'image': c['asset'],'audios': [],})elif c['type'].startswith('video:'):frames.append({'video_noaud': c['asset'],'audios': [],})elif c['type'].startswith('audio:'):if len(frames) == 0: continueframes[-1]['audios'].append({'audio': c['asset'],'len': audio_len(c['asset']),'subtitle': c['value'] if c['type'] == 'audio:tts' else '',})for f in frames:f['len'] = sum([a['len'] for a in f['audios']])f['video_noaud'] = img_nsec_2video(f['image'], f['len'], config['fps'])f['audio'] = (f['audios'][0]['audio'] if len(f['audios']) == 1 else ffmpeg_cat([a['audio'] for a in f['audios']], 'mp3'))f['video'] = ffmpeg_merge_video_audio(f['video_noaud'], f['audio'], audio_fmt='mp3')f['srt'] = gen_srt(f['audios'])f['video'] = ffmpeg_add_srt(f['video'], f['srt'])return frames
这里的逻辑是,(1)划分模块,将每个图片连同后面的连续音频划分进一个模块。
(2)对于每个模块,根据音频求出整个模块长度,制作无声视频,连接音频,制作字幕,然后把这些都连接起来。
字幕处理
模块划分这一步需要为每个模块生成 SRT 文件。
def srt_time_fmt(num):sec = int(num) % 60min_ = int(num) // 60 % 60hr = int(num) // 3600msec = int(num * 1000) % 1000return f'{hr:02d}:{min_:02d}:{sec:02d},{msec:03d}'# 生成字幕
def gen_srt(audios):# 提取 audios 数组中的字幕subs = [{'text': a['subtitle'],'len': a['len'],}for a in audios]# 将每个字幕按指定长度分割for s in subs:text = s['text']if not text: continueparts = split_text_even(text, config['subtitleMaxLen'])s['parts'] = [{'text': p,'len': len(p) / len(text) * s['len'],}for p in parts]# 将分割后的字幕替换原字幕subs = sum([s.get('parts', s) for s in subs], [])# 计算起始时间offset = 0for s in subs:s['start'] = offsetoffset += s['len']# 组装 SRT 文件srts = []for i, s in enumerate(subs):if not s['text']: continuest, ed = srt_time_fmt(s['start']), srt_time_fmt(s['start'] + s['len'])text = s['text']srts.append(f'{i+1}\n{st} --> {ed}\n{text}\n')srt = '\n'.join(srts)return srt这里我们把每个音频挑出来,从里面获取字幕和长度。然后对于每个字幕,将其按照指定好的长度分割,按照每个片段的比例计算其长度。最后给每条字幕计算起始时间,并组装 SRT 文件。
为了防止字母分割之后有个小尾巴,我们根据最大长度计算片段数量,然后按照这个数量平均分割。
def split_text_even(text, maxlen):textlen = len(text)num = math.ceil(textlen / maxlen)reallen = textlen // numres = [text[i:i+reallen] for i in range(0, textlen, reallen)]if textlen % num != 0:res[-1] += text[:-textlen%num]return res
组装视频
这就简单了,合并所有模块的视频,并添加片头片尾(如果存在的话)。
def make_video(frames):# 合并视频video = ffmpeg_cat([f['video'] for f in frames])# 合并片头片尾if config['header']:header = open(config['header'], 'rb').read()video = ffmpeg_cat([header, video])if config['footer']:footer = open(config['footer'], 'rb').read()video = ffmpeg_cat([video, footer])return video
工具函数
工具函数基本都用 FFMPEG 或者 OpenCV 实现的。
tts
直接调用 EdgeTTS:
def edgetts_cli(text, voice='zh-CN-XiaoyiNeural', fmt='mp3'):fname = path.join(tempfile.gettempdir(), uuid.uuid4().hex + '.' + fmt)cmd = ['edge-tts', '-t', text, '-v', voice, '--write-media', fname,]print(f'cmd: {cmd}')subp.Popen(cmd, shell=True).communicate()res = open(fname, 'rb').read()safe_remove(fname)return res
然后外面包了一层加了个缓存:
def tts(text):hash_ = hashlib.md5(text.encode('utf8')).hexdigest()cache = load_tts(hash_, 'none')if cache: return cachedata = edgetts_cli(text)save_tts(hash_, 'none', data)return datadef load_tts(hash_, voice):fname = path.join(DATA_DIR, f'{hash_}-{voice}')if path.isfile(fname):return open(fname, 'rb').read()else:return Nonedef save_tts(hash_, voice, data):safe_mkdir(DATA_DIR)fname = path.join(DATA_DIR, f'{hash_}-{voice}')open(fname, 'wb').write(data)
tti
这个函数没有实现,可以在外部脚本里面实现。
get_rand_asset_kw
用os.walk遍历指定目录及其子目录中的文件,使用过滤函数和关键词过滤,再随机挑选。
def get_rand_asset_kw(dir, kw, func_filter=is_pic):tree = list(os.walk(dir))fnames = [path.join(d, n) for d, _, fnames in tree for n in fnames]pics = [n for n in fnames if func_filter(n)]cand = [n for n in pics if kw in n]return random.choice(cand) if len(cand) else random.choice(pics)
gen_mono_color
用 NumPy 生成[H, W, 3]尺寸的 BGR 图片,然后每个第二维都赋值为指定 BGR。最后拿 OpenCV 编码。
def gen_mono_color(w, h, bgr):assert len(bgr) == 3img = np.zeros([h, w, 3])img[:, :] = bgrimg = cv2.imencode('.png', img, [cv2.IMWRITE_PNG_COMPRESSION, 9])[1]return bytes(img)
gen_blank_audio
用 NumPy 生成[SR * L]尺寸的纯零数组,用sp.io写到内存流里面。
def gen_blank_audio(nsec, sr=22050, fmt='wav'):audio = np.zeros(int(nsec * sr), dtype=np.uint8)bio = BytesIO()wavfile.write(bio, sr, audio)audio = bio.getvalue()if fmt != 'wav':audio = ffmpeg_conv_fmt(audio, 'wav', fmt)return audio
ffmpeg_get_info
调用 FFMPEG 获取视频的时长、FPS、SR。
def ffmpeg_get_info(video, fmt='mp4'):if isinstance(video, bytes):fname = path.join(tempfile.gettempdir(), uuid.uuid4().hex + '.' + fmt)open(fname, 'wb').write(video)else:fname = videocmd = ['ffmpeg', '-i', fname]print(f'cmd: {cmd}')r = subp.Popen(cmd, stdout=subp.PIPE, stderr=subp.PIPE, shell=True).communicate()text = r[1].decode('utf8')res = {}m = re.search(r'Duration:\x20(\d+):(\d+):(\d+)(.\d+)', text)if m:hr = int(m.group(1))min_ = int(m.group(2))sec = int(m.group(3))ms = float(m.group(4))res['duration'] = hr * 3600 + min_ * 60 + sec + msm = re.search(r'(\d+)\x20fps', text)if m:res['fps'] = int(m.group(1))m = re.search(r'(\d+)\x20Hz', text)if m:res['sr'] = int(m.group(1))if isinstance(video, bytes):safe_remove(fname)
resize_img
保持长宽比缩放图片。有两种模式:wrap将图片缩放到不大于指定尺寸的最大尺寸,然后填充不足的部分;fill缩放到大于指定尺寸的最小尺寸,然后切掉多余的部分。
# 缩放到最小填充尺寸并剪裁
def resize_img_fill(img, nw, nh):fmt_bytes = isinstance(img, bytes)if fmt_bytes:img = cv2.imdecode(np.frombuffer(img, np.uint8), cv2.IMREAD_COLOR)h, w, *_ = img.shape# 计算宽高的缩放比例,使用较大值等比例缩放x_scale = nw / wy_scale = nh / hscale = max(x_scale, y_scale)rh, rw = int(h * scale), int(w * scale)img = cv2.resize(img, (rw, rh), interpolation=cv2.INTER_CUBIC)# 剪裁成预定大小cut_w = rw - nwcut_h = rh - nhimg = img[cut_h // 2 : cut_h // 2 + nh,cut_w // 2 : cut_w // 2 + nw,]if fmt_bytes:img = bytes(cv2.imencode('.png', img, IMWRITE_PNG_FLAG)[1])return img# 缩放到最大包围并填充
def resize_img_wrap(img, nw, nh):fmt_bytes = isinstance(img, bytes)if fmt_bytes:img = cv2.imdecode(np.frombuffer(img, np.uint8), cv2.IMREAD_COLOR)h, w, *_ = img.shape# 计算宽高的缩放比例,使用较小值等比例缩放x_scale = nw / wy_scale = nh / hscale = min(x_scale, y_scale)rh, rw = int(h * scale), int(w * scale)img = cv2.resize(img, (rw, rh), interpolation=cv2.INTER_CUBIC)# 填充到预定大小pad_w = nw - rwpad_h = nh - rhimg = cv2.copyMakeBorder(img, pad_h // 2, pad_h - pad_h // 2, pad_w // 2, pad_w - pad_w // 2, cv2.BORDER_CONSTANT, None, (0,0,0)) if fmt_bytes:img = bytes(cv2.imencode('.png', img, IMWRITE_PNG_FLAG)[1])return imgdef resize_img(img, nw, nh, mode='wrap'):assert mode in ['wrap', 'fill']func_resize_img = resize_img_wrap if mode == 'wrap' else resize_img_fillreturn func_resize_img(img, nw, nh)
imgs_nsecs_2video
将指定图片做成长度固定的视频。就是使用秒数乘以 FPS,作为帧数,将帧塞进VideoWriter做成视频即可。
def imgs2video(imgs, fps=30):ofname = path.join(tempfile.gettempdir(), uuid.uuid4().hex + '.mp4')fmt = cv2.VideoWriter_fourcc('M', 'P', '4', 'V')w, h = get_img_size(imgs[0])vid = cv2.VideoWriter(ofname, fmt, fps, [w, h])for img in imgs:if isinstance(img, bytes):img = cv2.imdecode(np.frombuffer(img, np.uint8), cv2.IMREAD_COLOR)vid.write(img)vid.release()res = open(ofname, 'rb').read()safe_remove(ofname)return resdef get_img_size(img):if isinstance(img, bytes):img = cv2.imdecode(np.frombuffer(img, np.uint8), cv2.IMREAD_COLOR)assert isinstance(img, np.ndarray) and img.ndim in [2, 3]return img.shape[1], img.shape[0]def img_nsec_2video(img, nsec, fps=30):count = math.ceil(fps * nsec)imgs = [img] * countreturn imgs2video(imgs, fps)
ffmpeg_*
这些都是 FFMPEG 命令行的包装,注意处理好编码和反斜杠什么的就可以。
def ffmpeg_conv_fmt(video, from_, to):prefix = uuid.uuid4().hexfrom_fname = path.join(tempfile.gettempdir(), f'{prefix}.{from_}')to_fname = path.join(tempfile.gettempdir(), f'{prefix}.{to}')open(from_fname, 'wb').write(video)cmd = ['ffmpeg', '-i', from_fname, '-c', 'copy', to_fname, '-y']print(f'cmd: {cmd}')subp.Popen(cmd, shell=True).communicate()res = open(to_fname, 'rb').read()safe_remove(from_fname)safe_remove(to_fname)return resdef ffmpeg_cat(videos, fmt='mp4'):tmpdir = path.join(tempfile.gettempdir(), uuid.uuid4().hex)safe_mkdir(tmpdir)for i, video in enumerate(videos):fname = path.join(tmpdir, f'{i}.{fmt}')open(fname, 'wb').write(video)video_fnames = ['file ' + path.join(tmpdir, f'{i}.{fmt}').replace('\\', '\\\\')for i in range(len(videos))]video_li_fname = path.join(tmpdir, f'list.txt') open(video_li_fname, 'w', encoding='utf8').write('\n'.join(video_fnames))ofname = path.join(tmpdir, f'res.{fmt}')cmd = ['ffmpeg', '-f', 'concat', '-safe', '0','-i', video_li_fname, '-c', 'copy', ofname, '-y',]print(f'cmd: {cmd}')subp.Popen(cmd, shell=True).communicate()res = open(ofname, 'rb').read()safe_rmdir(tmpdir)return resdef ffmpeg_add_srt(video, srt, video_fmt='mp4'):tmpdir = path.join(tempfile.gettempdir(), uuid.uuid4().hex)safe_mkdir(tmpdir)vfname = path.join(tmpdir, f'video.{video_fmt}')open(vfname, 'wb').write(video)sfname = path.join(tmpdir, f'subtitle.srt')open(sfname, 'w', encoding='utf8').write(srt)res_fname = path.join(tmpdir, f'merged.{video_fmt}')cmd = ['ffmpeg', '-i', f'video.{video_fmt}', '-vf', f'subtitles=subtitle.srt', res_fname, '-y']'''cmd = ['ffmpeg', '-i', vfname, '-i', sfname, '-c', 'copy', res_fname, '-y',]if video_fmt == 'mp4': cmd += ['-c:s', 'mov_text']'''print(f'cmd: {cmd}')subp.Popen(cmd, shell=True, cwd=tmpdir).communicate()res = open(res_fname, 'rb').read()safe_rmdir(tmpdir)return resdef ffmpeg_merge_video_audio(video, audio, video_fmt='mp4', audio_fmt='mp4'):tmpdir = path.join(tempfile.gettempdir(), uuid.uuid4().hex)safe_mkdir(tmpdir)vfname = path.join(tmpdir, f'video.{video_fmt}')v0fname = path.join(tmpdir, f'video0.{video_fmt}')open(vfname, 'wb').write(video)afname = path.join(tmpdir, f'audio.{audio_fmt}')a0fname = path.join(tmpdir, f'audio0.{audio_fmt}')open(afname, 'wb').write(audio)res_fname = path.join(tmpdir, f'merged.{video_fmt}')cmds = [['ffmpeg', '-i', vfname, '-vcodec', 'copy', '-an', v0fname, '-y'],['ffmpeg', '-i', afname, '-acodec', 'copy', '-vn', a0fname, '-y'],['ffmpeg', '-i', a0fname, '-i', v0fname, '-c', 'copy', res_fname, '-y'],]for cmd in cmds:print(f'cmd: {cmd}')subp.Popen(cmd, shell=True).communicate()res = open(res_fname, 'rb').read()safe_rmdir(tmpdir)return res
load_module
用一些骚操作加载外部模块。(1)创建加载目录,并添加到sys.path。(2)为模块起个名字,并将文件内容用这个名字保存到加载目录中。(3)导入模块,删除文件。
def load_module(fname):if not path.isfile(fname) or \not fname.endswith('.py'):raise FileNotFoundError('外部模块应是 *.py 文件')tmpdir = path.join(tempfile.gettempdir(), 'load_module')safe_mkdir(tmpdir)if tmpdir not in sys.path:sys.path.insert(0, tmpdir)mod_name = 'x' + uuid.uuid4().hexnfname = path.join(tmpdir, mod_name + '.py')shutil.copy(fname, nfname)mod = __import__(mod_name)safe_remove(nfname)return mod
未来规划
- 添加视频整合能力
- 添加 PPT(富文本转图片)整合能力
- 没了。。。
相关文章:

【Python 自动化】自媒体剪辑第一版·思路简述与技术方案
大家都知道我主业是个运维开发(或者算法工程师),每天时间不多,但我又想做自媒体。然后呢,我就想了个方案,每天起来之后写个短视频的脚本,包含一系列图片和文字,然后上班的时候给它提…...

【前端】webpack打包去除console.log
0 问题 需要在打包的时候,自动地去除掉所有console.log 1 方法 // vue.config.js //... module.exports {//...config.optimization.minimizer[0].iptions.terserOptions.compress.drop_console true//... } //...也可以用if(process.env.NODE_ENV production…...
docker使用(二)提交到dockerhub springboot制作镜像
docker使用(二) dockerhub创建账号创建存储库成功!开始推送获取image名 提交成功SpringBoot项目制作Dockerfile镜像部署打jar包 dockerhub创建账号 (自认为可以理解为github一类的东西) 单击创建存储库按钮。 设定存…...

antd中Popover 气泡卡片样式修改
最近在开发react项目的一个新需求时,遇到气泡卡片Popover组件样式调整的问题,发现不管是在标签中设置className属性,还是在<Popover>标签中直接设置style属性,都不起作用。 最后搜索查阅发现要使用overlayClassName index…...

3月面试华为被刷,准备半年,9月二战华为终于上岸,要个27K不过分吧?
终于二战上岸了,二战华为也并不是说非华为不可,只是觉得心里憋着一口气,这就导致我当时有其他比较好的offer,我也没有去,就是想上岸华为来证明自己,现在也算是如愿了,来跟大伙们分享一下~ 个人情况 我本人…...

Kali之BurpSuite_pro安装配置
文章目录 配置jdk环境安装BurpSuitePro设置快捷方式启动方式 BurpSuite2021专业版本地址: 下载链接:https://pan.baidu.com/s/1PjzcukRDoc_ZFjrNxI8UjA 提取码:nwm7 我的安装工具都在/home/kali/tools/ 解压后我放在burpsuite_pro目录下 把j…...

双指针算法总结
双指针 常见的双指针有两种形式:对撞指针,左右指针。 对撞指针: 对撞指针一般用于顺序结构中,也称左右指针。 • 对撞指针从两端向中间移动。以个指针从最左端开始,另⼀个从最右端开始,然后逐渐往中间逼…...
开源照片管理服务LibrePhotos
本文是为了解决网友 赵云遇到的问题,顺便折腾的。虽然软件跑起来了,但是他遇到的问题,超出了老苏的认知。当然最终问题还是得到了解决,不过与 LibrePhotos 无关; 什么是 LibrePhotos ? LibrePhotos 是一个自托管的开源…...

Linux指令
1 Linux 系统目录结构 /bin 存放系统指令(可执行文件) /boot 存放linux系统开机引导程序 /dev 存放设备文件的地方 /etc 存放系统配置文件的地方 /home 存放用户家目录的地方。 /lib和/lib64 存放系统动态链接库的地方。 /lostfound linux文件系统下特有…...
如何在Mac电脑上安装WeasyPrint:简单易懂的步骤
1. 安装homebrew 首先需要确保安装了homebrew,通过homebrew安装weasyprint可以将需要的库都安装好,比pip安装更简单快捷。 安装方法如下: /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)&qu…...
手机电脑scoket通信 手机软件 APP inventor 服务端程序python
python scoket 通信 再帮助同学坐课题的时候接触到了scoket通信,了解到这应该是基层网络通信的原理,于是就导出搜索了一下相关的资料,简单来说scoket通信就是,可以让不同设备在同一个网络环境的条件下,可以实现相互通…...

软考高级之系统架构师之系统安全性和保密性设计
今天是2023年08月31日,距离软考高级只有65天,加油! 备注:资料搜集自网络。 基础 信息必须依赖于存储、传输、处理及应用的载体(媒介)而存在。信息系统安全可以划分设备安全、数据安全、内容安全和行为安…...

FPGA实现电机转速PID控制
通过纯RTL实现电机转速PID控制,包括电机编码器值读取,电机速度、正反转控制,PID算法,卡尔曼滤波,最终实现对电机速度进行控制,使其能够渐近设定的编码器目标值。 一、设计思路 前面通过SOPC之NIOS Ⅱ实现电…...

C++中的volatile
volatile的本意是“易变的”,是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,比如操作系统、硬件或者其它线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可…...
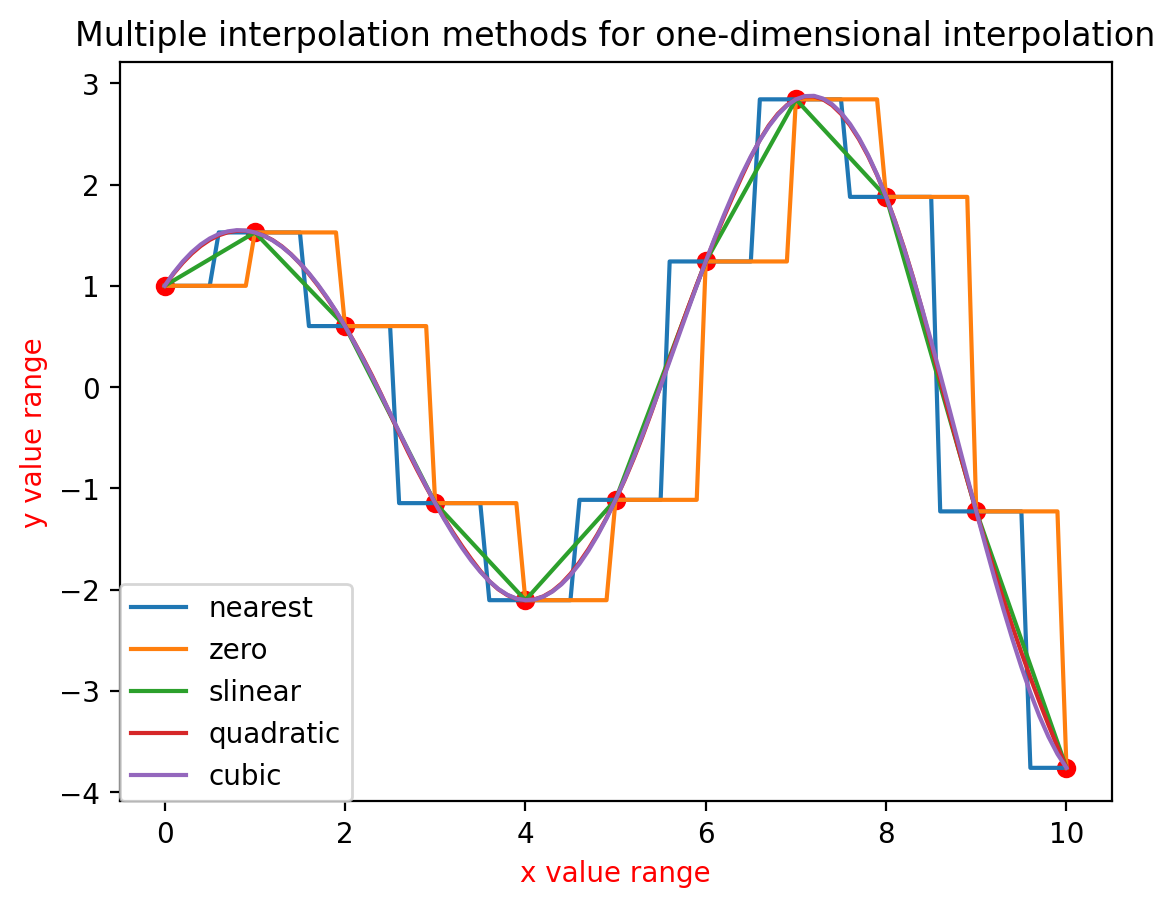
数学建模--一维插值法的多种插值方式的Python实现
目录 1.算法流程步骤 2.算法核心代码 3.算法效果展示 1.算法流程步骤 #算法的核心就是利用scipy中的interpolate来完成工作 #一共是5种一维插值算法形式: #插值方法:1.阶梯插值 2.线性插值 3.2阶样条插值 4.3阶样条插值 #"nearest"阶梯插值 #"zero&…...

爱校对:让法律、医疗、教育行业的文本更加无懈可击
在今天这个信息爆炸的世界里,文本准确性成了法律、医疗和教育这些严谨行业中一个不能忽视的要点。一个小错误可能造成严重的后果,甚至影响人们的生命和事业。这正是为什么更多的专业人士开始选择使用“爱校对”来确保他们的文档、研究和通讯无懈可击。 法…...
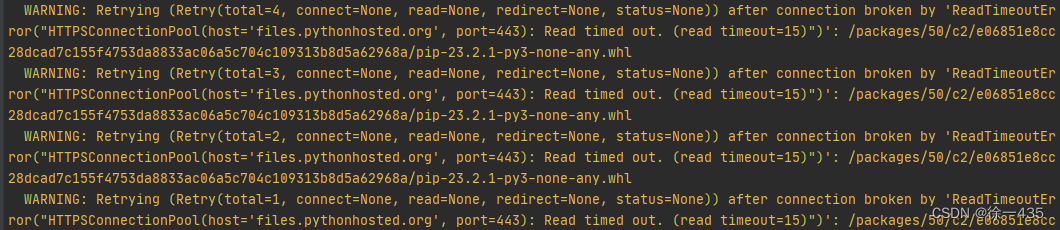
使用pip下载第三方软件包报错超时处理方法
报错如下: WARNING: Retrying (Retry(total4, connectNone, readNone, redirectNone, statusNone)) after connection broken by ‘ReadTimeoutEr ror(“HTTPSConnectionPool(host‘files.pythonhosted.org’, port443): Read timed out. (read timeout15)”)’: /p…...

计算古坐标——基于GPlates Web Service的坐标点重建
Gplates客户端和在线门户,pygplates和gplately是存在内在联系的应用,它们主要实现可视化,输入板块模型和化石点的现今坐标信息,在GPlates中可视化呈现,点位的坐标计算并不展现。而rgplates利用R语言提供了直接进行坐标…...

智安网络|加强软件供应链安全保障:共同抵御威胁的关键路径
在当今数字化时代,软件供应链安全成为了一个备受关注的话题。各行各业都依赖于软件产品和服务来支持其业务运营。然而,随着供应链的不断扩大和复杂化,软件供应链安全问题也日益突出。那么应该如何解决? 首先,软件供应…...
华为Mate 60系列发售,北斗卫星通信技术进一步深入大众消费市场
近日,华为Mate 60系列手机在没有举办发布会的情况下在官方商城突然上架开售,人气火爆。 值得一提的是,华为Mate60 Pro支持卫星通话,无地面网络时,也能拨打和接听卫星电话,还可自由编辑卫星消息。华为 Mate6…...

BiliDownloader实战演练:解锁B站视频离线观看的智能解决方案
BiliDownloader实战演练:解锁B站视频离线观看的智能解决方案 【免费下载链接】BiliDownloader BiliDownloader是一款界面精简,操作简单且高速下载的b站下载器 项目地址: https://gitcode.com/gh_mirrors/bi/BiliDownloader 你是否曾为无法下载B站…...

STC32G单片机开发实战:GPIO模式配置与寄存器详解
1. STC32G单片机GPIO基础认知 第一次拿到STC32G开发板时,我习惯性地想用STM32那套HAL库来操作GPIO,结果发现根本行不通。这就像拿着汽车钥匙去开保险箱,虽然都是"开锁",但机制完全不同。STC32G作为增强型8051架构单片机…...

FanControl风扇控制软件:Windows电脑散热优化终极指南
FanControl风扇控制软件:Windows电脑散热优化终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa…...

思源宋体TTF:免费专业中文字体终极使用指南
思源宋体TTF:免费专业中文字体终极使用指南 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版找不到合适的免费字体而烦恼吗?思源宋体TTF正是你需要…...

Perplexity认证备考资源严重稀缺!仅开放3个月的模拟题库已限流,速领2024Q3最新版PDF+视频解析
更多请点击: https://codechina.net 第一章:Perplexity认证考试概览与最新动态 Perplexity认证考试是由Perplexity AI官方推出的面向开发者、AI工程师及技术决策者的专业能力评估体系,旨在验证考生在大语言模型原理、提示工程实践、API集成、…...

3分钟学会TV Bro浏览器:智能电视上网终极指南
3分钟学会TV Bro浏览器:智能电视上网终极指南 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro TV Bro是一款专为智能电视设计的安卓网页浏览器,通…...

拆解安防摄像头的“眼睛”:从IMX290 Sensor到镜头,如何一步步调出通透画质?
拆解安防摄像头的“眼睛”:从IMX290 Sensor到镜头,如何一步步调出通透画质? 在安防监控领域,画质表现直接决定了产品的核心竞争力。当我们谈论"通透画质"时,实际上是在讨论一种光学与电子系统的协同优化艺术…...

如何5分钟配置Zotero PDF翻译插件:新手快速上手教程
如何5分钟配置Zotero PDF翻译插件:新手快速上手教程 【免费下载链接】zotero-pdf-translate Translate PDF, EPub, webpage, metadata, annotations, notes to the target language. Support 20 translate services. 项目地址: https://gitcode.com/gh_mirrors/zo…...

CANape测量启动报错“存储空间不足”的系统性排查与解决方案
1. 问题现象与根源剖析如果你是一名汽车电子工程师,或者从事车辆标定、诊断与测试工作,那么CANape这个软件对你来说,就像吃饭用的筷子一样熟悉。它强大的测量、标定和诊断功能,是我们在开发过程中不可或缺的利器。然而,…...

Beyond Compare 5终极激活指南:3分钟获取永久授权密钥
Beyond Compare 5终极激活指南:3分钟获取永久授权密钥 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 你是否还在为Beyond Compare 5的30天试用期到期而烦恼?每次打开软件…...