Redis面试题(笔记)
目录
1.缓存穿透
2.缓存击穿
3.缓存雪崩
小结
4.缓存-双写一致性
5.缓存-持久性
6.缓存-数据过期策略
7.缓存-数据淘汰策略
数据淘汰策略-使用建议
数据淘汰策略总结
8.redis分布式锁
setnx
redission
主从一致性
9.主从复制、主从同步
10.哨兵模式
服务状态监控
redis集群(哨兵模式)脑裂
11.分片集群
Redis是单线程的,但是为什么还那么快?
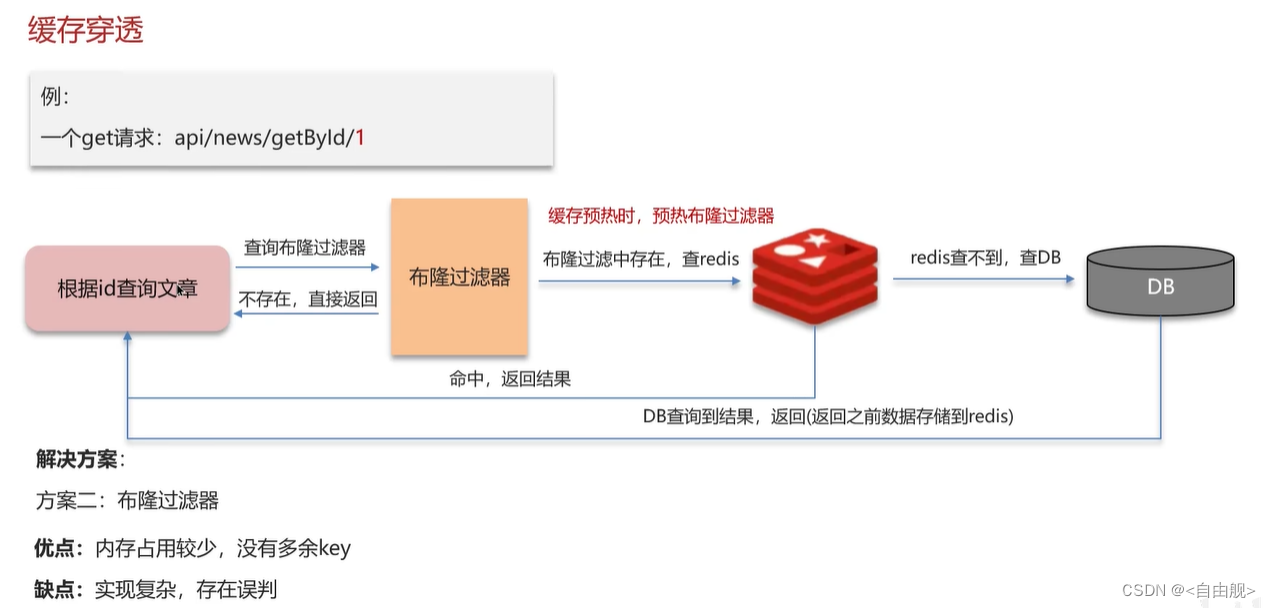
1.缓存穿透
面试官:什么是缓存穿透 ? 怎么解决 ?
候选人:
嗯~~,我想一下
缓存穿透是指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,可能导致 DB 挂掉。这种情况大概率是遭到了攻击。
解决方案一:缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存, 例如:{key:1,value: null}
优点:简单
缺点:消耗内存,可能会发送不一致的问题
(可能会导致当数据真的存储了,查询缓存还是null,可以设置缓存过期时间)
解决方案二,我们通常都会用布隆过滤器来解决它
候选人:
嗯,是这样~
布隆过滤器主要是用于检索一个元素是否在一个集合中。我们当时使用的是redisson实现的布隆过滤器。
它的底层主要是先去初始化一个比较大数组,里面存放的二进制0或1。在一开始都是0,当一个key来了之后经过3次hash计算,模于数组长度找到数据的下标然后把数组中原来的0改为1,这样的话,三个数组的位置就能标明一个key的存在。查找的过程也是一样的。
当然是有缺点的,布隆过滤器有可能会产生一定的误判,我们一般可以设置这个误判率,大概不会超过5%,其实这个误判是必然存在的,要不就得增加数组的长度,其实已经算是很划分了,5%以内的误判率一般的项目也能接受,不至于高并发下压倒数据库。
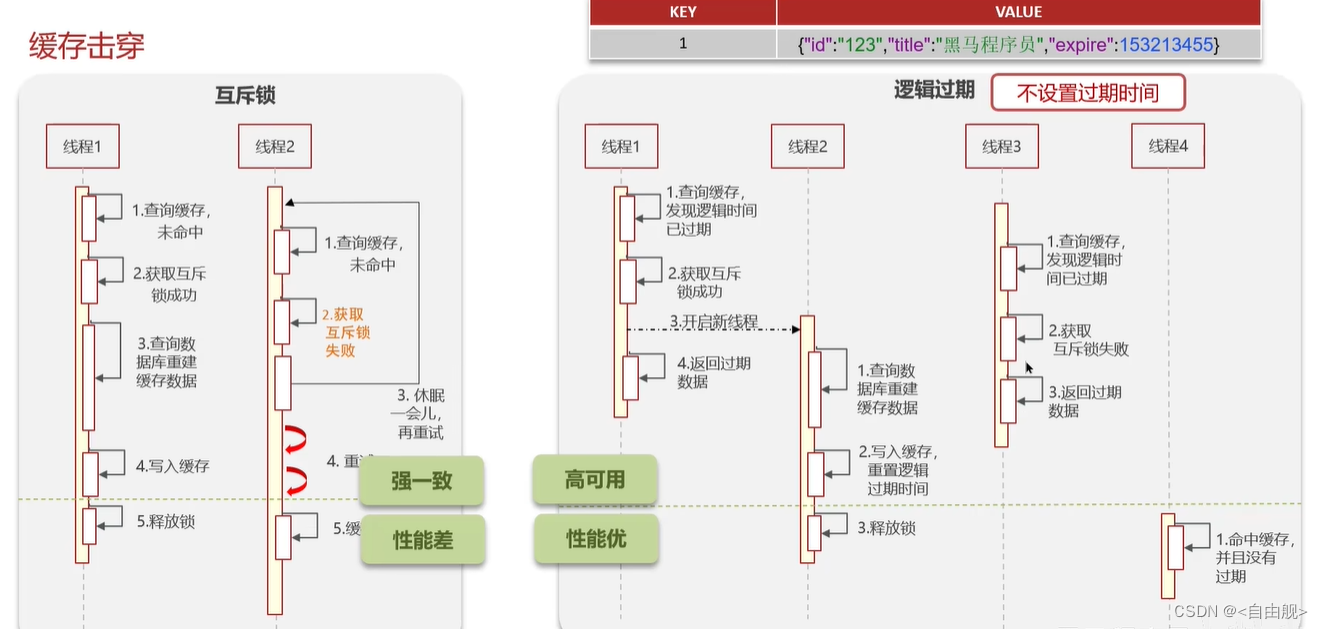
2.缓存击穿
面试官:什么是缓存击穿 ? 怎么解决 ?
候选人:缓存击穿的意思是对于设置了过期时间的key,缓存在某个时间点过期的时候,恰好这时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把 DB 压垮。
解决方案有两种方式:
解决方案一:互斥锁 (强一致的业务,跟钱相关的业务)
解决方案二:逻辑过期 (注重体验,高可用性)
第一可以使用互斥锁:当缓存失效时,不立即去load db,先使用如 Redis 的 setnx 去设置一个互斥锁,当操作成功返回时再进行 load db的操作并回设缓存,否则重试get缓存的方法
第二种方案可以设置当前key逻辑过期,大概是思路如下:
①:在设置key的时候,设置一个过期时间字段一块存入缓存中,不给当前key设置过期时间
②:当查询的时候,从redis取出数据后判断时间是否过期
③:如果过期则开通另外一个线程进行数据同步,当前线程正常返回数据,这个数据不是最新
当然两种方案各有利弊:
如果选择数据的强一致性,建议使用分布式锁的方案,性能上可能没那么高,锁需要等,也有可能产生死锁的问题
如果选择key的逻辑删除,则优先考虑的高可用性,性能比较高,但是数据同步这块做不到强一致。
3.缓存雪崩
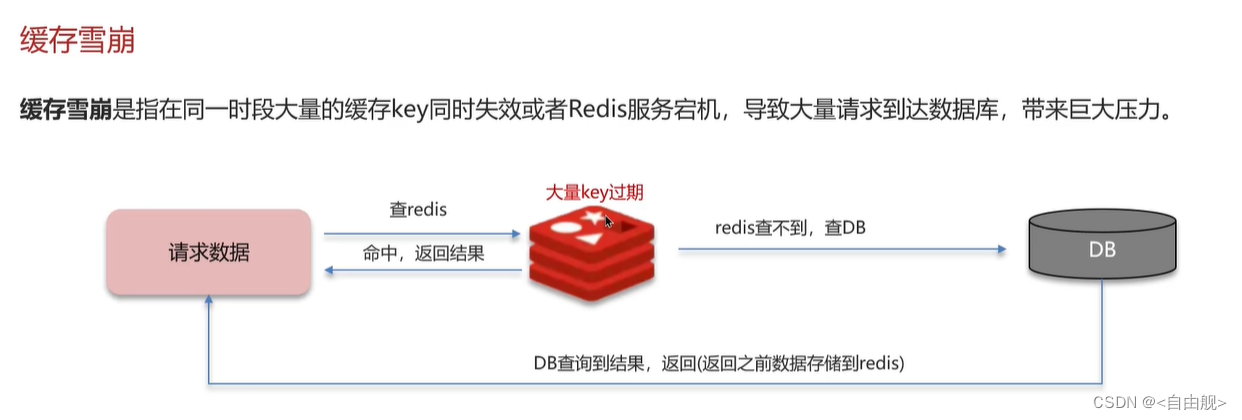
面试官:什么是缓存雪崩 ? 怎么解决 ?
候选人:
嗯!!
缓存雪崩意思是设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB 瞬时压力过重雪崩。与缓存击穿的区别:雪崩是很多key,击穿是某一个key缓存。
解决方案主要是可以将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
解决方案有以下四种
解决方案一:给不同的Key的TTL添加随机值
解决方案二:利用Redis集群提高服务的可用性
解决方案三:给缓存业务添加降级限流策略(降级可作为系统的保底策略,适用于穿透、击穿、雪崩)
解决方案四:给业务添加多级缓存
小结

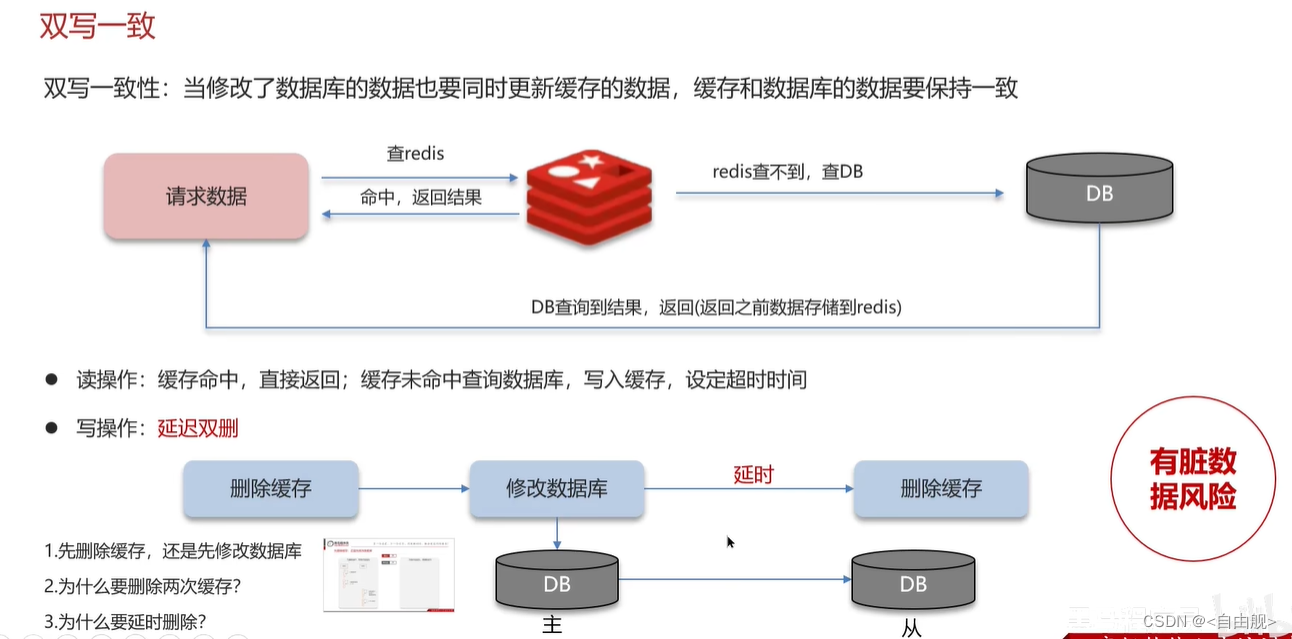
4.缓存-双写一致性
双写一致性:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致
延时双删
解决方式一,基于MQ异步通知保证数据的最终一致性
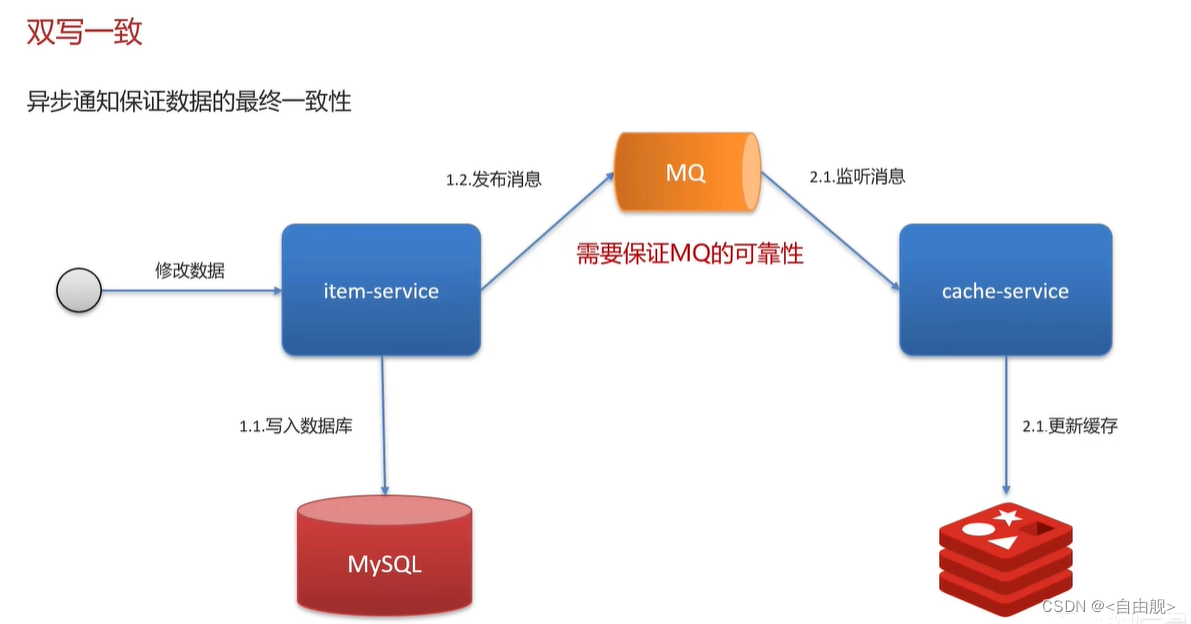
解决方式二:基于Canal的异步通知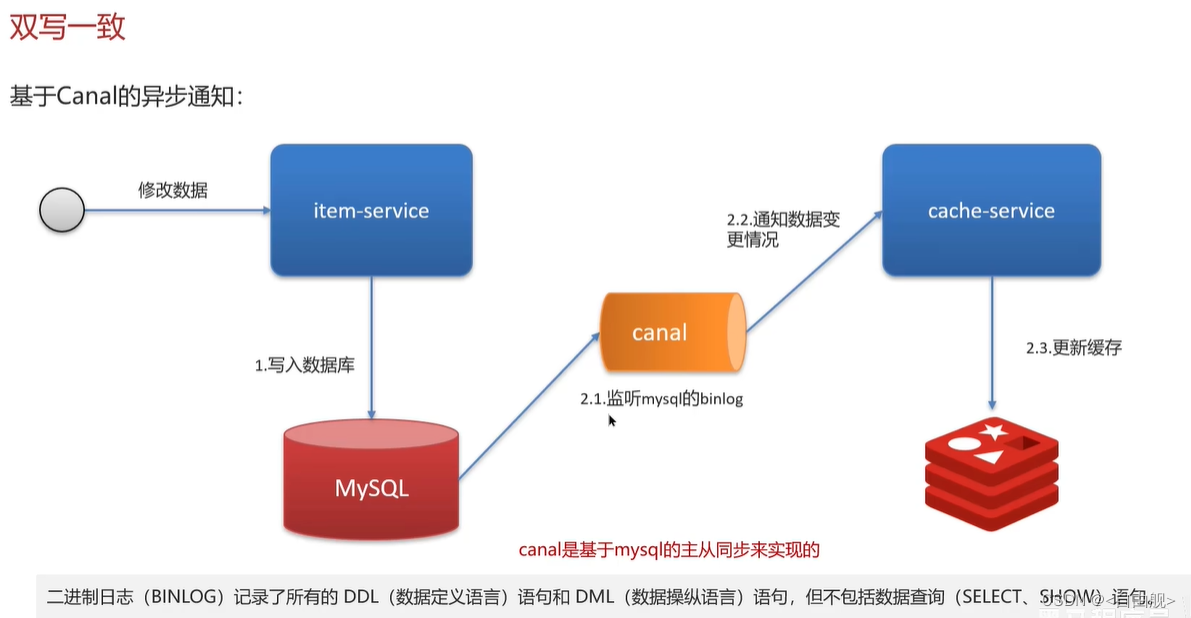
----------------------------------------------------------------------------------------------------------------------
面试官:redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
候选人:嗯!就说我最近做的这个项目,里面有xxxx(根据自己的简历上写)的功能,需要让数据库与redis高度保持一致,因为要求时效性比较高,我们当时采用的读写锁保证的强一致性。
我们采用的是redisson实现的读写锁,在读的时候添加共享锁,可以保证读读不互斥,读写互斥。当我们更新数据的时候,添加排他锁,它是读写,读读都互斥,这样就能保证在写数据的同时是不会让其他线程读数据的,避免了脏数据。这里面需要注意的是读方法和写方法上需要使用同一把锁才行。
----------------------------------------------------------------------------------------------------------------------
面试官:那这个排他锁是如何保证读写、读读互斥的呢?
候选人:其实排他锁底层使用也是setnx,保证了同时只能有一个线程操作锁住的方法
面试官:你听说过延时双删吗?为什么不用它呢?
候选人:延迟双删,如果是写操作,我们先把缓存中的数据删除,然后更新数据库,最后再延时删除缓存中的数据,其中这个延时多久不太好确定,在延时的过程中可能会出现脏数据,并不能保证强一致性,所以没有采用它。
----------------------------------------------------------------------------------------------------------------------
面试官:redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
候选人:嗯!就说我最近做的这个项目,里面有xxxx(根据自己的简历上写)的功能,数据同步可以有一定的延时(符合大部分业务)
我们当时采用的阿里的canal组件实现数据同步:不需要更改业务代码,部署一个canal服务。canal服务把自己伪装成mysql的一个从节点,当mysql数据更新以后,canal会读取binlog数据,然后在通过canal的客户端获取到数据,更新缓存即可。
5.缓存-持久性
面试官:redis做为缓存,数据的持久化是怎么做的?
候选人:在Redis中提供了两种数据持久化的方式:
1、RDB (RDB的全称是Redis DataBase)
2、AOF (Append Only File)追加文件
面试官:这两种持久化方式有什么区别呢?
候选人:RDB是一个快照文件,它是把redis内存存储的数据写到磁盘上,当redis实例宕机恢复数据的时候,方便从RDB的快照文件中恢复数据。
AOF的含义是追加文件,当redis操作写命令的时候,都会存储这个文件中,当redis实例宕机恢复数据的时候,会从这个文件中再次执行一遍命令来恢复数据
----------------------------------------------------------------------------------------------------------------------
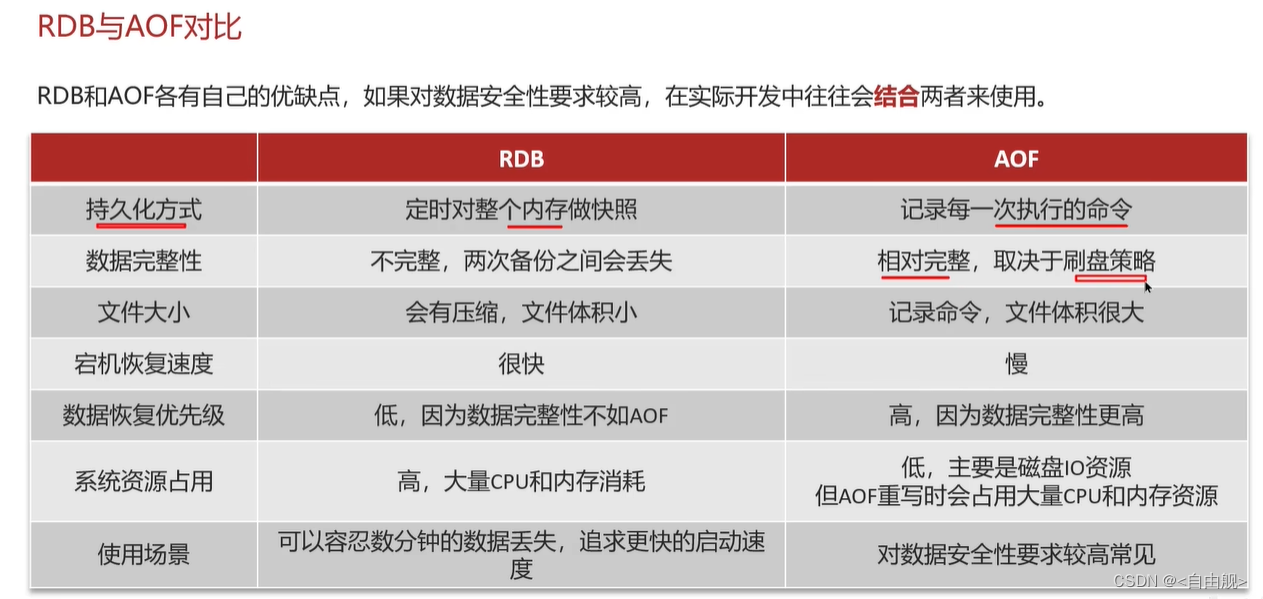
面试官:这两种方式,哪种恢复的比较快呢?
候选人:RDB因为是二进制文件,在保存的时候体积也是比较小的,它恢复的比较快,但是它有可能会丢数据,我们通常在项目中也会使用AOF来恢复数据,虽然AOF恢复的速度慢一些,但是它丢数据的风险要小很多,在AOF文件中可以设置刷盘策略,我们当时设置的就是每秒批量写入一次命令
6.缓存-数据过期策略
面试官:Redis的数据过期策略有哪些 ?
候选人:
嗯~,在redis中提供了两种数据过期删除策略
第一种是惰性删除,在设置该key过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key。
第二种是 定期删除,就是说每隔一段时间,我们就对一些key进行检查,删除里面过期的key
定期清理的两种模式:
- SLOW模式是定时任务,执行频率默认为10hz,每次不超过25ms,以通过修改配置文件redis.conf 的 hz 选项来调整这个次数
- FAST模式执行频率不固定,每次事件循环会尝试执行,但两次间隔不低于2ms,每次耗时不超过1ms
Redis的过期删除策略:惰性删除 + 定期删除两种策略进行配合使用。
7.缓存-数据淘汰策略
面试官:Redis的数据淘汰策略有哪些 ?
候选人:
嗯,这个在redis中提供了很多种,默认是noeviction,不删除任何数据,内部不足直接报错
是可以在redis的配置文件中进行设置的,里面有两个非常重要的概念,一个是LRU,另外一个是LFU
LRU的意思就是最少最近使用,用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
LFU的意思是最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高
我们在项目设置的allkeys-lru,挑选最近最少使用的数据淘汰,把一些经常访问的key留在redis中

数据淘汰策略-使用建议
1.优先使用 allkeys-lru 策略。充分利用LRU 算法的优势,把最近最常访问的数据留在缓存中。如果业务有明显的冷热数据区分,建议使用。
2.如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用 allkeys-random,随机选择淘汰
3.如果业务中有置顶的需求,可以使用 volatile-lru 策略,同时置顶数据不设置过期时间,这些数据就一直不被删除,会淘汰其他设置过期时间的数据
4.如果业务中有短时高频访问的数据,可以使用 allkeys-lfu 或 volatile-lfu 策略
----------------------------------------------------------------------------------------------------------------------
面试官:数据库有1000万数据 ,Redis只能缓存20w数据, 如何保证Redis中的数据都是热点数据 ?
候选人:
嗯,我想一下~~
可以使用 allkeys-lru (挑选最近最少使用的数据淘汰)淘汰策略,那留下来的都是经常访问的热点数据
面试官:Redis的内存用完了会发生什么?
候选人:
嗯~,这个要看redis的数据淘汰策略是什么,如果是默认的配置,redis内存用完以后则直接报错。我们当时设置的 allkeys-lru 策略。把最近最常访问的数据留在缓存中。
数据淘汰策略总结
1.Redis提供了8种不同的数据淘汰策略,默认是noeviction不删除任何数据,内存不足直接报错
2.LRU:最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰
优先级越高。
3.LFU:最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高
平时开发过程中用的比较多的就是allkeys-lru (结合自己的业务场景
8.redis分布式锁
使用场景,如果不适用分布式锁,在集群下可能会出现超卖的情况
-
setnx
面试官:Redis分布式锁如何实现 ?
候选人:嗯,在redis中提供了一个命令setnx(SET if not exists)
由于redis的单线程的,用了命令之后,只能有一个客户端对某一个key设置值,在没有过期或删除key的时候是其他客户端是不能设置这个key的
-
redission
面试官:好的,那你如何控制Redis实现分布式锁有效时长呢?
候选人:嗯,的确,redis的setnx指令不好控制这个问题,我们当时采用的redis的一个框架redisson实现的。
在redisson中需要手动加锁,并且可以控制锁的失效时间和等待时间,当锁住的一个业务还没有执行完成的时候,在redisson中引入了一个看门狗机制,就是说每隔一段时间就检查当前业务是否还持有锁,如果持有就增加加锁的持有时间,当业务执行完成之后需要使用释放锁就可以了
还有一个好处就是,在高并发下,一个业务有可能会执行很快,先客户1持有锁的时候,客户2来了以后并不会马上拒绝,它会自旋不断尝试获取锁,如果客户1释放之后,客户2就可以马上持有锁,性能也得到了提升。
面试官:好的,redisson实现的分布式锁是可重入的吗?
候选人:嗯,是可以重入的。这样做是为了避免死锁的产生。这个重入其实在内部就是判断是否是当前线程持有的锁,如果是当前线程持有的锁就会计数,如果释放锁就会在计算上减一。在存储数据的时候采用的hash结构,大key可以按照自己的业务进行定制,其中小key是当前线程的唯一标识,value是当前线程重入的次数
-
主从一致性
面试官:redisson实现的分布式锁能解决主从一致性的问题吗
候选人:这个是不能的,比如,当线程1加锁成功后,master节点数据会异步复制到slave节点,此时当前持有Redis锁的master节点宕机,slave节点被提升为新的master节点,假如现在来了一个线程2,再次加锁,会在新的master节点上加锁成功,这个时候就会出现两个节点同时持有一把锁的问题。
我们可以利用redisson提供的红锁来解决这个问题,它的主要作用是,不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁,并且要求在大多数redis节点上都成功创建锁,红锁中要求是redis的节点数量要过半。这样就能避免线程1加锁成功后master节点宕机导致线程2成功加锁到新的master节点上的问题了。
但是,如果使用了红锁,因为需要同时在多个节点上都添加锁,性能就变的很低了,并且运维维护成本也非常高,所以,我们一般在项目中也不会直接使用红锁,并且官方也暂时废弃了这个红锁
面试官:好的,如果业务非要保证数据的强一致性,这个该怎么解决呢?
候选人:嗯~,redis本身就是支持高可用的,做到强一致性,就非常影响性能,所以,如果有强一致性要求高的业务,建议使用zookeeper实现的分布式锁,它是可以保证强一致性的。
9.主从复制、主从同步
面试官:那你来介绍一下主从同步
候选人:嗯,是这样的,单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,可以搭建主从集群,实现读写分离。一般都是一主多从,主节点负责写数据,从节点负责读数据,主节点写入数据之后,需要把数据同步到从节点中
面试官:能说一下,主从同步数据的流程
候选人:嗯~~,好!主从同步分为了两个阶段,一个是全量同步,一个是增量同步
全量同步是指从节点第一次与主节点建立连接的时候使用全量同步,流程是这样的:
第一:从节点请求主节点同步数据,其中从节点会携带自己的replication id和offset偏移量。
第二:主节点判断是否是第一次请求,主要判断的依据就是,主节点与从节点是否是同一个replication id,如果不是,就说明是第一次同步,那主节点就会把自己的replication id和offset发送给从节点,让从节点与主节点的信息保持一致。
第三:在同时主节点会执行bgsave,生成rdb文件后,发送给从节点去执行,从节点先把自己的数据清空,然后执行主节点发送过来的rdb文件,这样就保持了一致
当然,如果在rdb生成执行期间,依然有请求到了主节点,而主节点会以命令的方式记录到缓冲区,缓冲区是一个日志文件,最后把这个日志文件发送给从节点,这样就能保证主节点与从节点完全一致了,后期再同步数据的时候,都是依赖于这个日志文件,这个就是全量同步
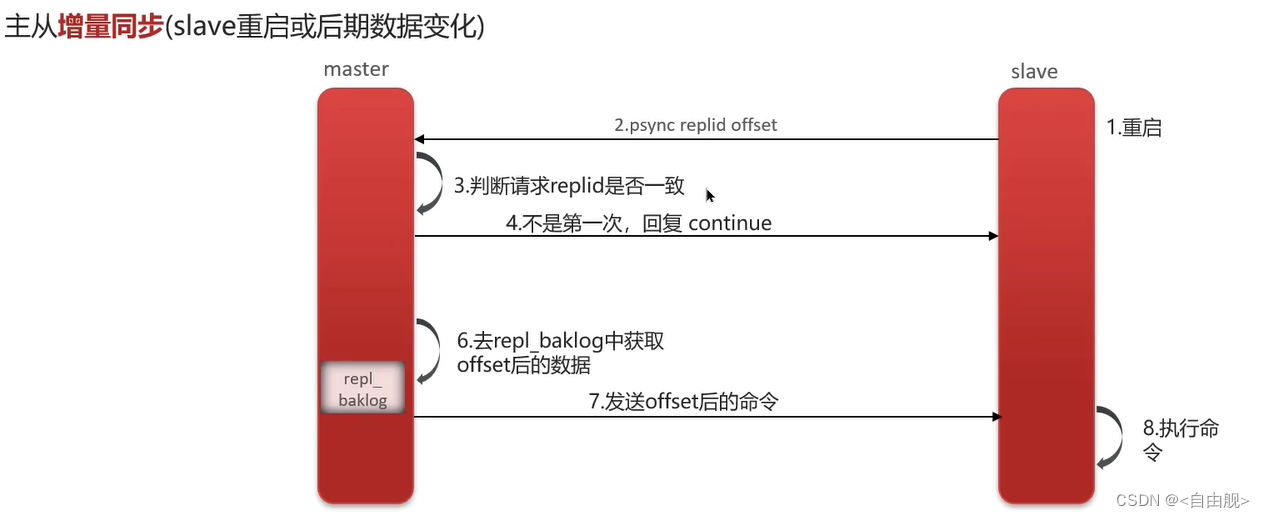
增量同步指的是,当从节点服务重启之后,数据就不一致了,所以这个时候,从节点会请求主节点同步数据,主节点还是判断不是第一次请求,不是第一次就获取从节点的offset值,然后主节点从命令日志中获取offset值之后的数据,发送给从节点进行数据同步
10.哨兵模式
-
服务状态监控
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
- 主观下线: 如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线
- 客观下线:若超过指定数量 (quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半

-
redis集群(哨兵模式)脑裂
----------------------------------------------------------------------------------------------------------------------
面试官:怎么保证Redis的高并发高可用
候选人:首先可以搭建主从集群,再加上使用redis中的哨兵模式,哨兵模式可以实现主从集群的自动故障恢复,里面就包含了对主从服务的监控、自动故障恢复、通知;如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主;同时Sentinel也充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端,所以一般项目都会采用哨兵的模式来保证redis的高并发高可用
面试官:你们使用redis是单点还是集群,哪种集群
候选人:嗯!,我们当时使用的是主从(1主1从)加哨兵。一般单节点不超过10G内存,如果Redis内存不足则可以给不同服务分配独立的Redis主从节点。尽量不做分片集群。因为集群维护起来比较麻烦,并且集群之间的心跳检测和数据通信会消耗大量的网络带宽,也没有办法使用lua脚本和事务
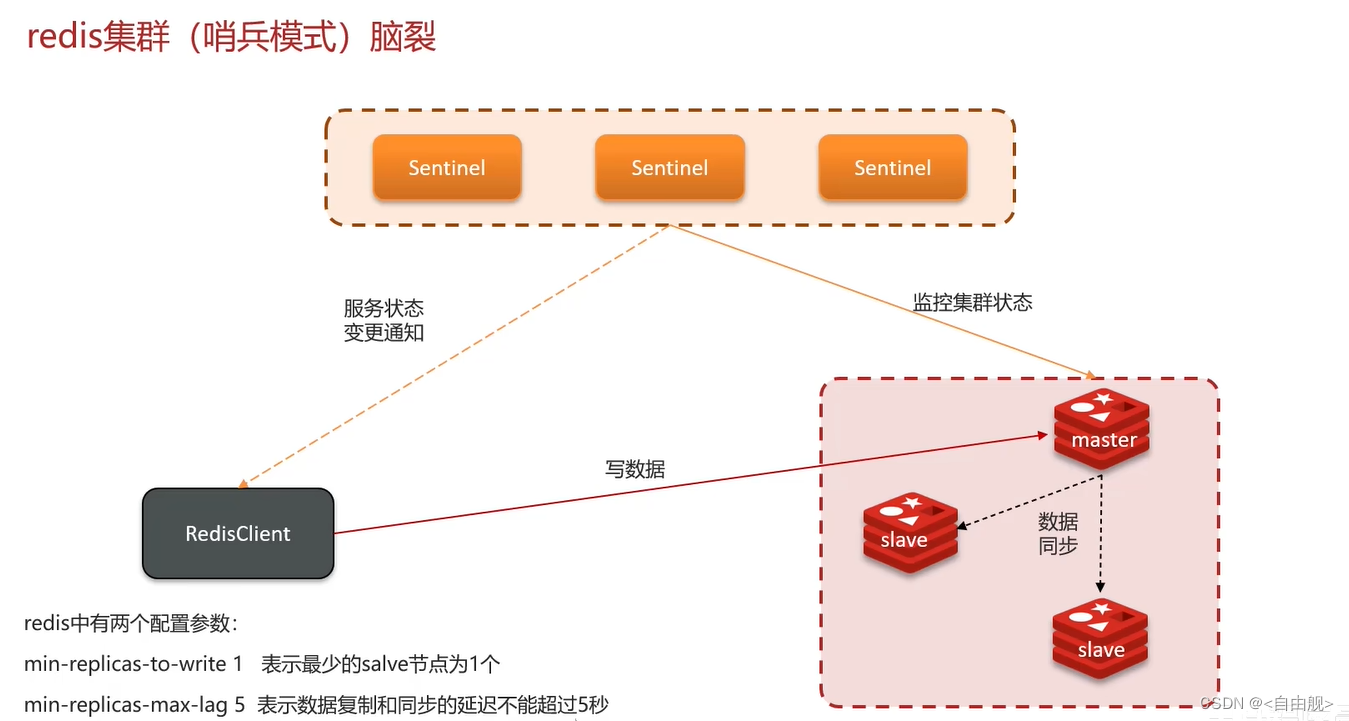
面试官:redis集群脑裂,该怎么解决呢?
候选人:嗯! 这个在项目很少见,不过脑裂的问题是这样的,我们现在用的是redis的哨兵模式集群的
有的时候由于网络等原因可能会出现脑裂的情况,就是说,由于redis master节点和redis salve节点和sentinel处于不同的网络分区,使得sentinel没有能够心跳感知到master,所以通过选举的方式提升了一个salve为master,这样就存在了两个master,就像大脑分裂了一样,这样会导致客户端还在old master那里写入数据,新节点无法同步数据,当网络恢复后,sentinel会将old master降为salve,这时再从新master同步数据,这会导致old master中的大量数据丢失。
关于解决的话,我记得在redis的配置中可以设置:第一可以设置最少的salve节点个数,比如设置至少要有一个从节点才能同步数据,第二个可以设置主从数据复制和同步的延迟时间,达不到要求就拒绝请求,就可以避免大量的数据丢失
11.分片集群
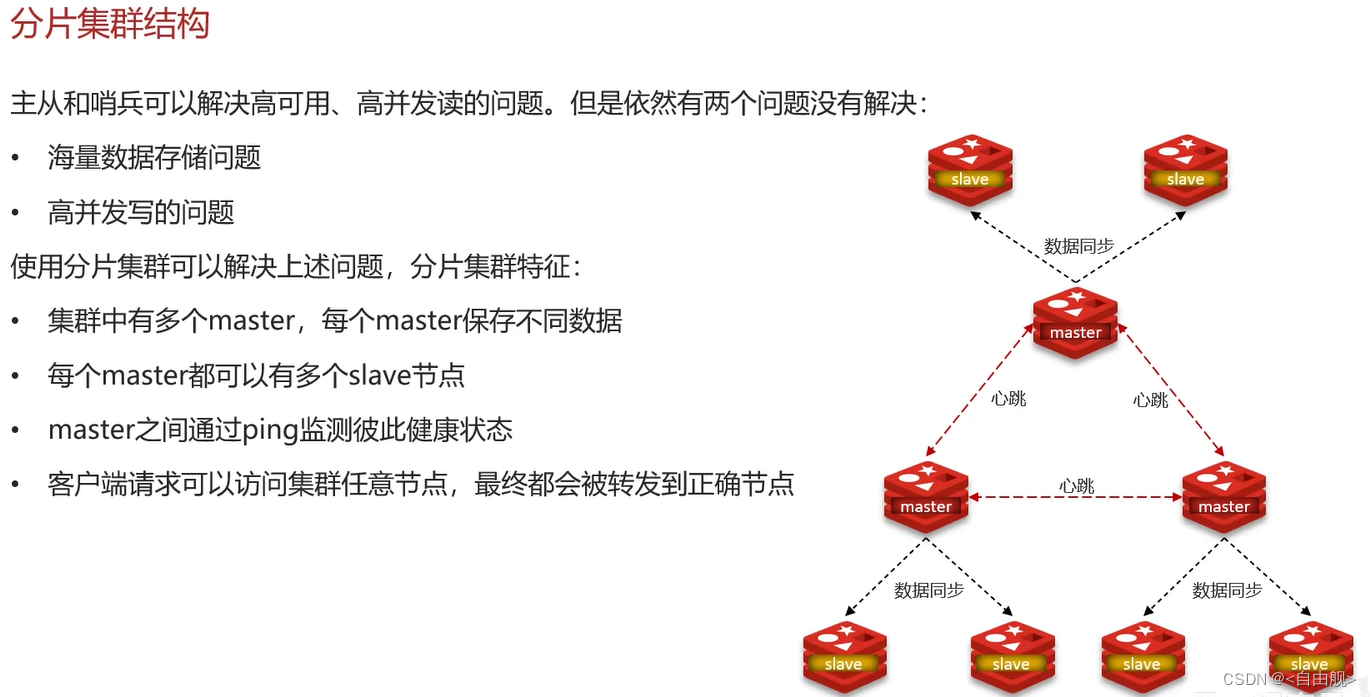
面试官:redis的分片集群有什么作用
候选人:分片集群主要解决的是,海量数据存储的问题,集群中有多个master,每个master保存不同数据,并且还可以给每个master设置多个slave节点,就可以继续增大集群的高并发能力。同时每个master之间通过ping监测彼此健康状态,就类似于哨兵模式了。当客户端请求可以访问集群任意节点,最终都会被转发到正确节点
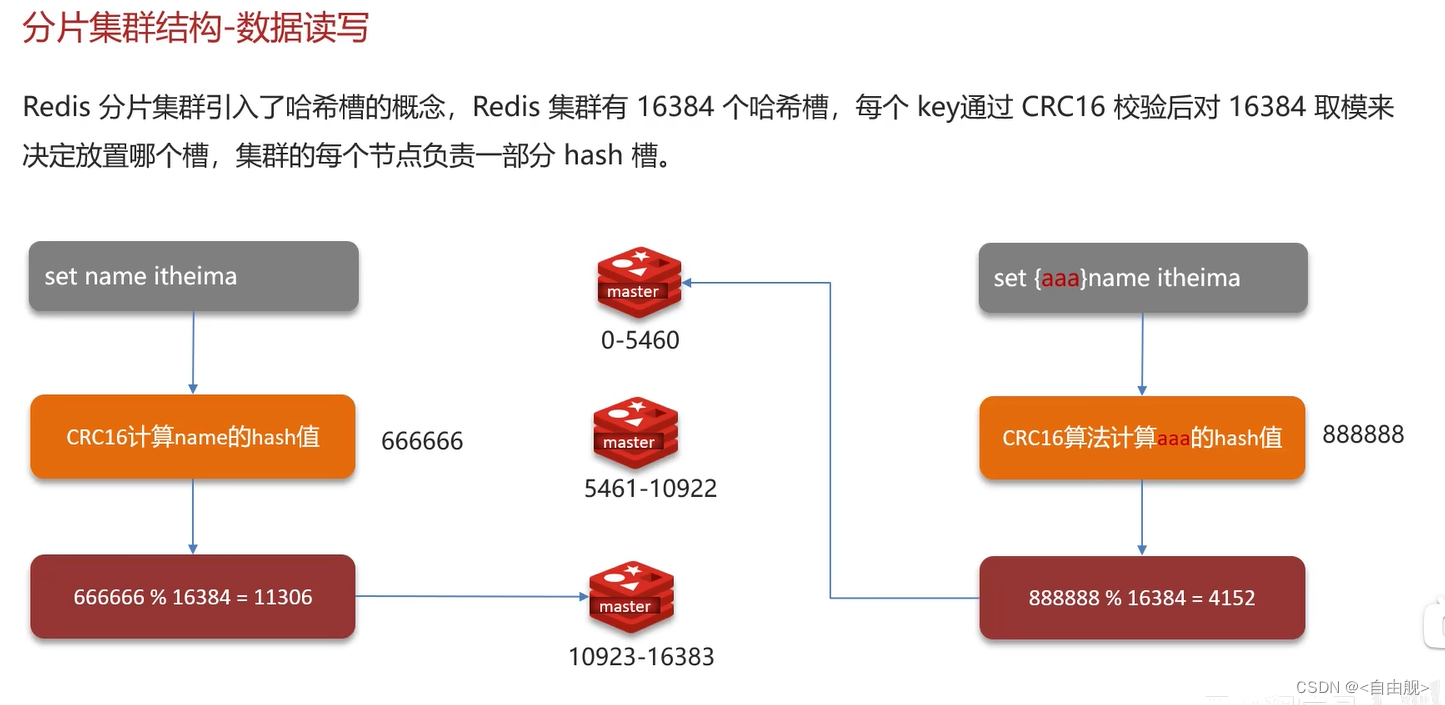
面试官:Redis分片集群中数据是怎么存储和读取的?
候选人:
嗯~,在redis集群中是这样的
Redis 集群引入了哈希槽的概念,有 16384 个哈希槽,集群中每个主节点绑定了一定范围的哈希槽范围, key通过 CRC16 校验后对 16384 取模来决定放置哪个槽,通过槽找到对应的节点进行存储。
取值的逻辑是一样的
-
Redis是单线程的,但是为什么还那么快?
面试官:Redis是单线程的,但是为什么还那么快?
候选人:
嗯,这个有几个原因吧~~~
1、完全基于内存的,C语言编写
2、采用单线程,避免不必要的上下文切换可竞争条件
3、使用多路I/O复用模型,非阻塞IO
例如:bgsave 和 bgrewriteaof 都是在后台执行操作,不影响主线程的正常使用,不会产生阻塞
面试官:能解释一下I/O多路复用模型?
候选人:嗯~~,I/O多路复用是指利用单个线程来同时监听多个Socket ,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。目前的I/O多路复用都是采用的epoll模式实现,它会在通知用户进程Socket就绪的同时,把已就绪的Socket写入用户空间,不需要挨个遍历Socket来判断是否就绪,提升了性能。
其中Redis的网络模型就是使用I/O多路复用结合事件的处理器来应对多个Socket请求,比如,提供了连接应答处理器、命令回复处理器,命令请求处理器;
在Redis6.0之后,为了提升更好的性能,在命令回复处理器使用了多线程来处理回复事件,在命令请求处理器中,将命令的转换使用了多线程,增加命令转换速度,在命令执行的时候,依然是单线程
相关文章:
Redis面试题(笔记)
目录 1.缓存穿透 2.缓存击穿 3.缓存雪崩 小结 4.缓存-双写一致性 5.缓存-持久性 6.缓存-数据过期策略 7.缓存-数据淘汰策略 数据淘汰策略-使用建议 数据淘汰策略总结 8.redis分布式锁 setnx redission 主从一致性 9.主从复制、主从同步 10.哨兵模式 服务状态监…...

iPhone 15 Pro展示设计:7项全新变化呈现
我们不应该再等iPhone 15 Pro在苹果9月12日的“Wonderlust”活动上发布了,而且可能会有很多升级。有传言称,iPhone 15 Pro将是自iPhone X以来最大的飞跃,这要归功于大量的新变化,从带有更薄边框的新钛框架到顶级A17仿生芯片和动作…...

【六袆 - Windows】PL/SQL instantclient安装包下载;PL/SQL双击登录配置
安装 PL/SQL 15 OMIT Oracle Instant Client Downloads for Microsoft Windows (x64) 64-bit https://www.oracle.com/database/technologies/instant-client/winx64-64-downloads.html 配置 # tnsnames.ora Network Configuration File:E:\oracle\product\10.2.0\db_1\ne…...
Springboot+mybatis-plus+dynamic-datasource 切换数据源失败问题总结
Springbootmybatis-plusdynamic-datasourceDruid 多数据源 切换数据源失败总结 文章目录 Springbootmybatis-plusdynamic-datasourceDruid 多数据源 切换数据源失败总结0.前言1. dynamic-datasource 切换数据源失败场景总结1. spring-batch整合情况下切换数据源异常解决办法&am…...

QuantLib学习笔记——InterestRate的应用
⭐️ 单利还是复利 巴菲特老爷子有句名言:“人生就像滚雪球,重要的是发现很湿的雪和很长的坡。” 很湿的雪,指的就是复利。很长的坡,指的就是时间。很湿的雪和很长的坡组合起来,就能滚成巨大的雪球。 哈哈࿰…...

记录--解决前端内存泄漏:问题概览与实用解决方案
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 内存泄漏是前端开发中的一个常见问题,可能导致项目变得缓慢、不稳定甚至崩溃。在本文中,我们将深入探讨在JavaScript、Vue和React项目中可能导致内存泄漏的情况,并提…...
IP初学习
1.IP报文 首部长度指的是报头长度,用于分离报头和有效载荷 2.网段划分 IP地址 目标网络 目标主机 3.例子 4.特殊的IP地址 5.真正的网络环境 6.调制解调器 “猫”,学名叫宽带无线猫 7.NAT 源IP在内网环境不断被替换 8.私有IP不能出现在公网上 因…...

live5555 testProgs目录
文章目录 测试testProgs视频流直播流注意: 测试 testProgs 当涉及到许多示例程序时,解释每一个都可能会变得非常冗长。然而,我可以为你提供一些关键示例程序的简要解释,以帮助你了解每个示例的用途和功能: testOnDem…...

yolov5模型s,l,m,x的区别
yolov5s 是什么?yolov5系列最小的模型,s是small。 适合什么情况下使用?适合在计算资源有限的设备上使用。如移动设备或边缘设备。 速度和准确率:速度最快,准确率最低。 输入分辨率:通常为640x640 # Param…...

Springboot 实践(13)spring boot 整合RabbitMq
前文讲解了RabbitMQ的下载和安装,此文讲解springboot整合RabbitMq实现消息的发送和消费。 1、创建web project项目,名称为“SpringbootAction-RabbitMQ” 2、修改pom.xml文件,添加amqp使用jar包 <!-- RabbitMQ --> <dependency&g…...
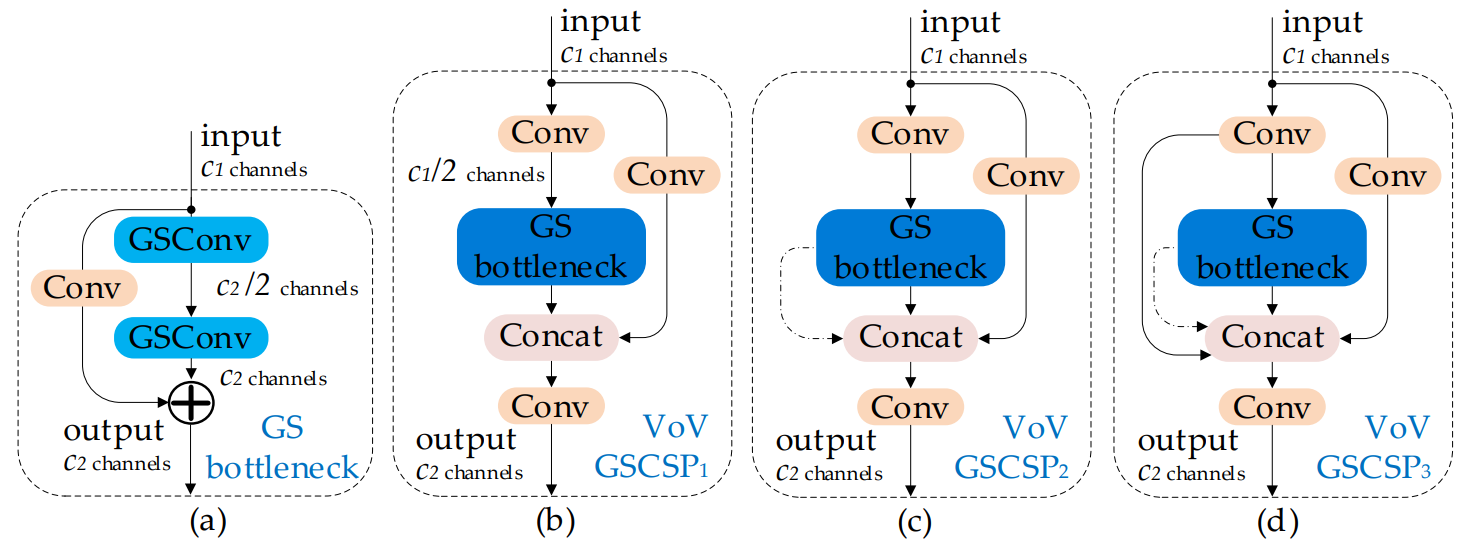
YoloV8改进策略:轻量级Slim Neck打造极致的YoloV8
文章目录 摘要Yolov8官方结果源码改进方法测试结果总结摘要 论文链接:https://arxiv.org/ftp/arxiv/papers/2206/2206.02424.pdf 作者研究了增强 CNN 学习能力的通用方法,例如 DensNet、VoVNet 和 CSPNet,然后根据这些方法的理论设计了 Slim-Neck 结构。 使用轻量级卷积…...
使用java代码给Excel加水印,代码全,进阶版
以下代码,亲测可以跑通 1、上一篇博客用了Apache POI库3.8的版本的形式对Excel加了水印,但是最近主线版本用了4.1.2的形式,由于为了保持版本的兼容性,下面有开发了Apache POI的4.1.2的版本号的方案。 pom文件为: <d…...

day37:网编day4,多点通信和并发服务器
一、广播接收方: #include <myhead.h>#define ERR_MSG(msg) do{\ fprintf(stderr,"__%d__\n",__LINE__);\ perror(msg);\ }while(0)#define BRD_IP "192.168.114.255" #define BRD_PORT 8888int main(int argc, const char *argv[]) {//…...
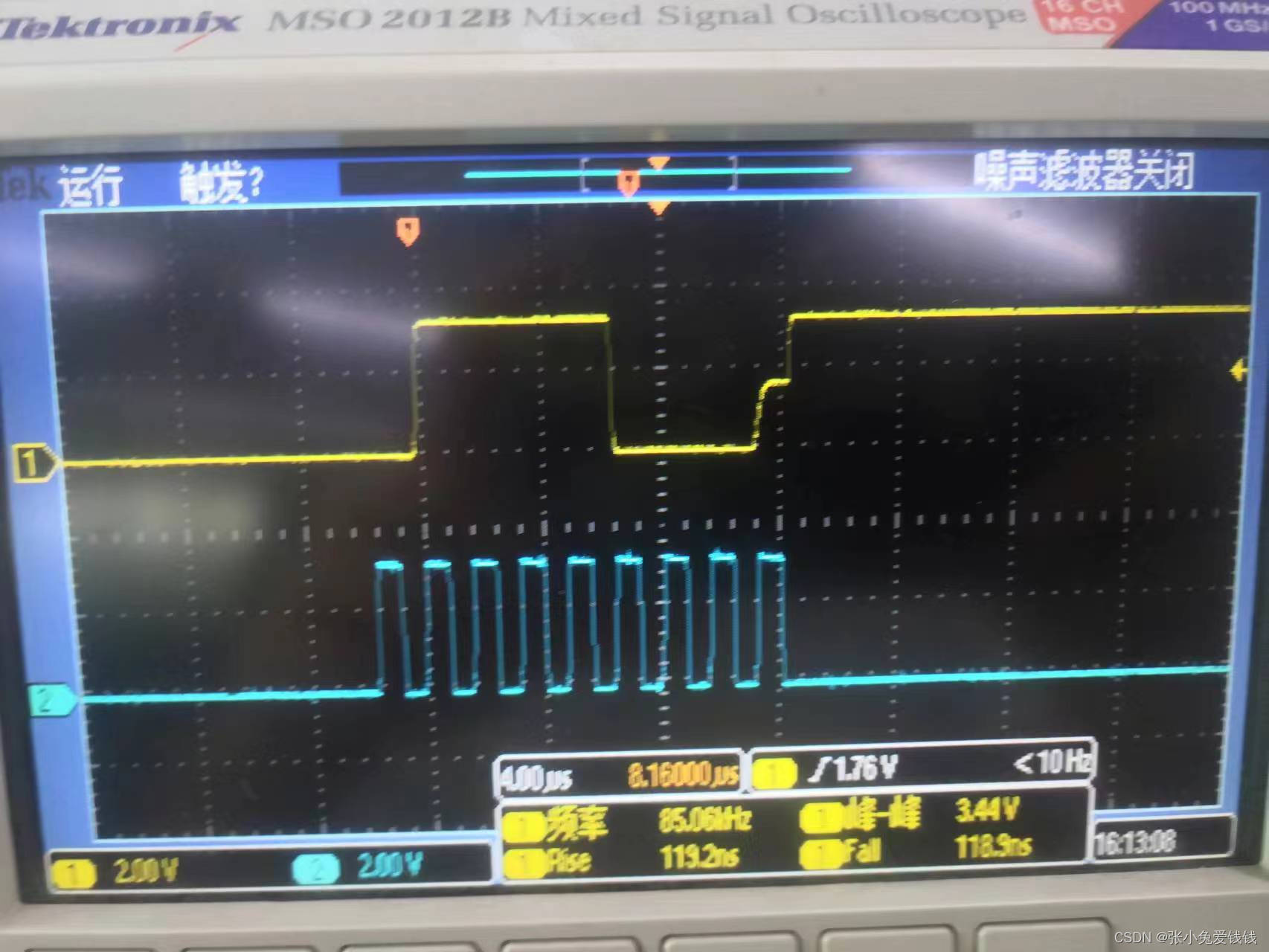
STM32 硬件IIC 控制OLED I2C卡死问题
1. STM32L151C8T6 硬件IIC 控制OLED 屏,OLED 驱动IC CH1116G, 查阅OLED 数据手册 2. STM32 硬件IIC 初始化,用的标准库,固件库 // stm32l151c8t6 as master, oled control ic (CH1116G) as slave, and communicate by master iic2 void STM3…...

Redis图文指南
1、什么是 Redis? Redis(REmote DIctionary Service)是一个开源的键值对数据库服务器。 Redis 更准确的描述是一个数据结构服务器。Redis 的这种特殊性质让它在开发人员中很受欢迎。 Redis不是通过迭代或者排序方式处理数据,而是…...

C++17 std::string_view介绍与使用
std::string_view介绍 std::string_view是C17增加的新内容。它是一个轻量级的、只读的字符串视图,可以用来表示一个字符串或字符串的一部分。std::string_view可以提高代码的可读性、可维护性和性能。 std::string_view与std::string的主要区别在于,st…...
写得了代码,焊得了板!嵌入式开发工程师必修之代码管理方案(下)
目录 极狐GitLab嵌入式开发场景解决方案 3.1 高可用部署与灾备 3.2 组织管理 3.3 分支策略 3.4 分支保护 3.5 推送规则 3.6 代码评审 3.7 数据保护 3.8 其他相关 本文来自 武让 极狐GitLab 高级解决方案架构师 💡 前两篇文章,作者介绍了嵌入式开…...
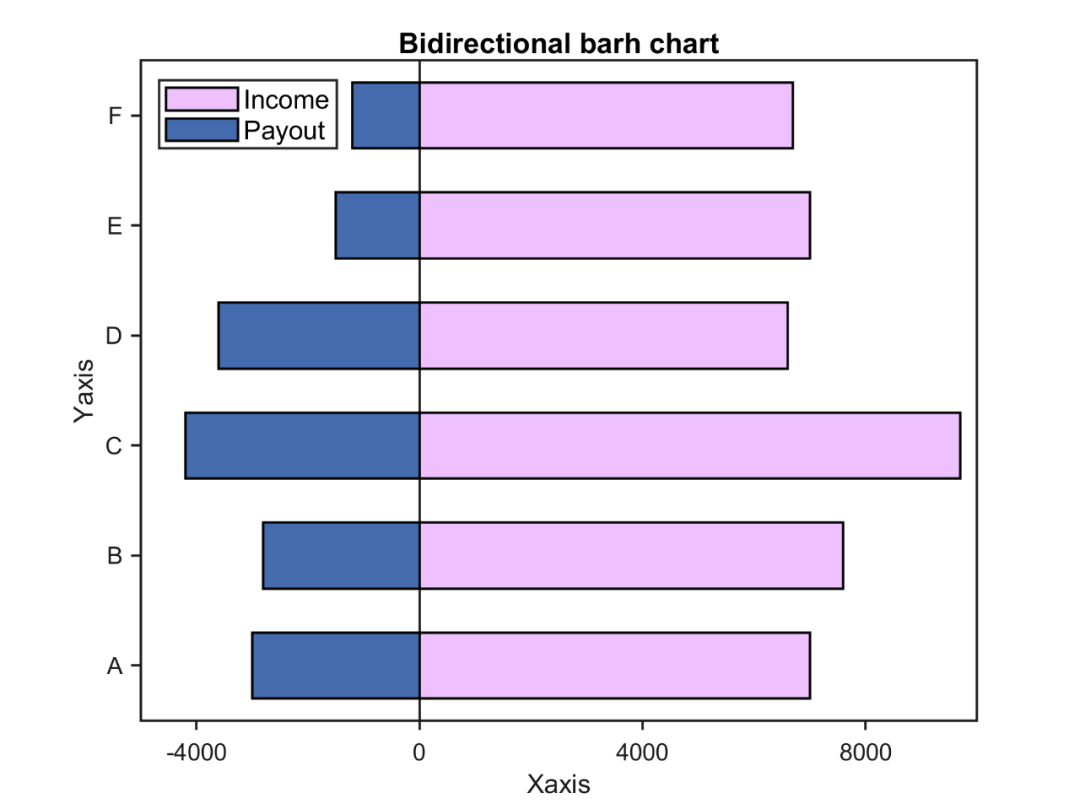
Matlab论文插图绘制模板第110期—水平双向柱状图
在之前的文章中,分享了很多Matlab柱状图的绘制模板: 进一步,再来看一种特殊的柱状图:水平双向柱状图。 先来看一下成品效果: 特别提示:本期内容『数据代码』已上传资源群中,加群的朋友请自行下…...

【广州华锐互动】VR全景工厂虚拟导览,虚拟现实技术提升企业数字化信息管理水平
随着工业4.0的到来,VR工厂全景制作成为了越来越多工业企业的选择。传统的工厂管理方式往往存在诸多问题,如信息不对称、安全隐患等。为了解决这些问题,VR工厂全景制作应运而生,它通过结合虚拟现实现实技术和数据采集技术ÿ…...
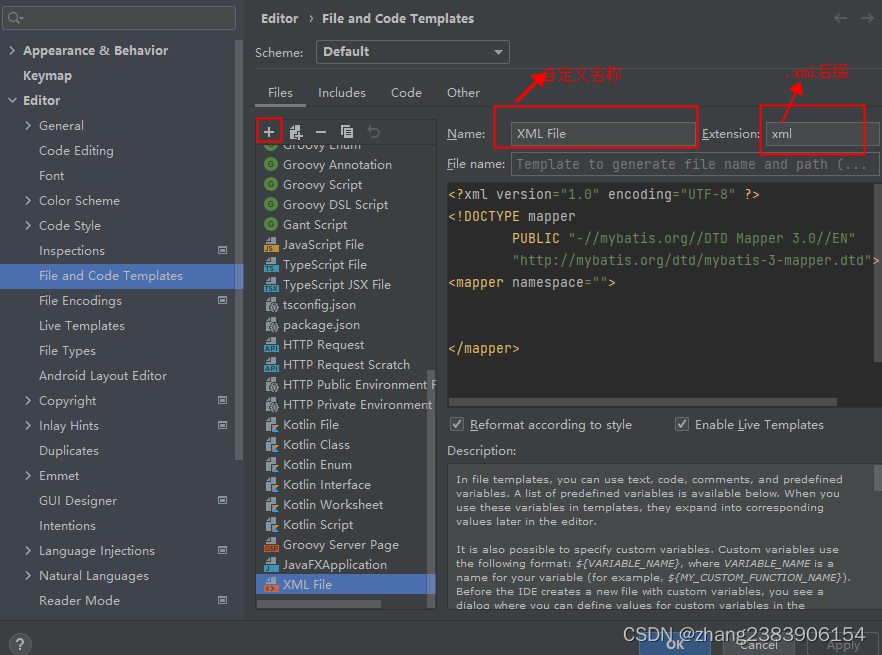
idea 创建mybatis xml文件时找不到
1、File >Settings 如图 : 2、添加模板:如下图 3、添加xml模板 如下图: 模板内容: <?xml version"1.0" encoding"UTF-8" ?> <!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//E…...

Pandas 数据清洗与分析
第一部分:水果销售分析(入门篇)首先,我们有一个简单的水果销售列表。我们的任务是算出每种水果的总销量,以及每天的销售明细。1. 数据准备我们先造一点数据:import pandas as pd import numpy as npdata {…...
)
手把手教你用YOLACT训练自己的数据集:从COCO格式准备到模型推理全流程(附Python源码)
YOLACT实战指南:从数据标注到工业级实例分割模型部署 1. 实例分割技术演进与YOLACT核心优势 在计算机视觉领域,实例分割一直被视为目标检测与语义分割的结合体。不同于简单的边界框检测或像素级分类,实例分割要求算法能够区分同一类别的不同个…...

Visual C++运行库合集:一站式解决Windows应用程序依赖问题的终极指南
Visual C运行库合集:一站式解决Windows应用程序依赖问题的终极指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 还在为"缺少msvcp140.dll&qu…...

抖音下载器终极实战指南:高效批量下载与去水印的完整解决方案
抖音下载器终极实战指南:高效批量下载与去水印的完整解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallbac…...

VisualHMI灵敏度调校全攻略:从触摸校准到性能优化
1. 项目概述:从“调参”到“调感”的界面设计进阶在工业HMI(人机界面)开发领域,尤其是使用像VisualHMI这类图形化设计软件时,“调节灵敏度”这个需求,远不止是拖动一个滑块、输入一个数值那么简单。它背后牵…...

如何用N_m3u8DL-RE破解加密流媒体:跨平台下载的终极指南
如何用N_m3u8DL-RE破解加密流媒体:跨平台下载的终极指南 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

从 JetBrains 全家桶用户视角,聊聊 DataGrip 那些被低估的『协同』技巧:共享查询、布局同步与团队规范
从 JetBrains 全家桶用户视角,聊聊 DataGrip 那些被低估的『协同』技巧:共享查询、布局同步与团队规范 在团队开发环境中,数据库操作往往被视为个人技能而非团队资产。当开发者频繁切换于 IntelliJ IDEA、PyCharm 和 DataGrip 之间时…...

【麒麟系统-解释器错误:权限不足】
执行脚本后发现无法执行权限不足查看发现当前是有执行权限的;最后发现可能是有安全限制: 执行命令getstatus 执行这个命令即可:sudo setstatus softmode...

别再混淆Eb/N0和SNR了!手把手教你用Python仿真验证MQAM误码率公式
别再混淆Eb/N0和SNR了!手把手教你用Python仿真验证MQAM误码率公式 在通信系统设计与性能分析中,Eb/N0(每比特能量与噪声功率谱密度之比)和SNR(信噪比)是最基础却最易混淆的概念。许多工程师在仿真MQAM系统时…...

电子项目布线指南:从导线、电缆到连接器的核心选型与避坑
1. 项目概述:为什么“线”比“电路”本身更重要?干了十几年电子项目,从学生时代的第一个闪烁LED,到后来复杂的机器人系统和工业控制器,我踩过最多的坑,往往不是芯片选型或代码逻辑,而是那些看起…...