第64步 深度学习图像识别:多分类建模误判病例分析(Pytorch)
基于WIN10的64位系统演示
一、写在前面
上期我们基于TensorFlow环境介绍了多分类建模的误判病例分析。
本期以健康组、肺结核组、COVID-19组、细菌性(病毒性)肺炎组为数据集,基于Pytorch环境,构建SqueezeNet多分类模型,分析误判病例,因为它建模速度快。
同样,基于GPT-4辅助编程。
二、误判病例分析实战
使用胸片的数据集:肺结核病人和健康人的胸片的识别。其中,健康人900张,肺结核病人700张,COVID-19病人549张、细菌性(病毒性)肺炎组900张,分别存入单独的文件夹中。
直接分享代码:
######################################导入包###################################
import copy
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision import models
from torch.utils.data import DataLoader
from torch import optim, nn
from torch.optim import lr_scheduler
import os
import matplotlib.pyplot as plt
import warnings
import numpy as npwarnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 设置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")################################导入数据集#####################################
from torchvision import datasets, transforms
from torch.nn.functional import softmax
from PIL import Image
import pandas as pd
import torch.nn as nn
import timm
from torch.optim import lr_scheduler# 自定义的数据集类
class ImageFolderWithPaths(datasets.ImageFolder):def __getitem__(self, index):original_tuple = super(ImageFolderWithPaths, self).__getitem__(index)path = self.imgs[index][0]tuple_with_path = (original_tuple + (path,))return tuple_with_path# 数据集路径
data_dir = "./MTB-1"# 图像的大小
img_height = 256
img_width = 256# 数据预处理
data_transforms = {'train': transforms.Compose([transforms.RandomResizedCrop(img_height),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(0.2),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize((img_height, img_width)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}# 加载数据集
full_dataset = ImageFolderWithPaths(data_dir, transform=data_transforms['train'])# 获取数据集的大小
full_size = len(full_dataset)
train_size = int(0.8 * full_size) # 假设训练集占70%
val_size = full_size - train_size # 验证集的大小# 随机分割数据集
torch.manual_seed(0) # 设置随机种子以确保结果可重复
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])# 应用数据增强到训练集和验证集
train_dataset.dataset.transform = data_transforms['train']
val_dataset.dataset.transform = data_transforms['val']# 创建数据加载器
batch_size = 8
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=0)dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes# 获取数据集的类别
class_names = full_dataset.classes# 保存预测结果的列表
results = []###############################定义SqueezeNet模型################################
# 定义SqueezeNet模型
model = models.squeezenet1_1(pretrained=True) # 这里以SqueezeNet 1.1版本为例
num_ftrs = model.classifier[1].in_channels# 根据分类任务修改最后一层
# 这里我们改变模型的输出层为4,因为我们做的是四分类
model.classifier[1] = nn.Conv2d(num_ftrs, 4, kernel_size=(1,1))# 修改模型最后的输出层为我们需要的类别数
model.num_classes = 4model = model.to(device)# 打印模型摘要
print(model)#############################编译模型#########################################
# 定义损失函数
criterion = nn.CrossEntropyLoss()# 定义优化器
optimizer = torch.optim.Adam(model.parameters())# 定义学习率调度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# 开始训练模型
num_epochs = 20# 初始化记录器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 每个epoch都有一个训练和验证阶段for phase in ['train', 'val']:if phase == 'train':model.train() # 设置模型为训练模式else:model.eval() # 设置模型为评估模式running_loss = 0.0running_corrects = 0# 遍历数据for inputs, labels, paths in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 零参数梯度optimizer.zero_grad()# 前向with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# 只在训练模式下进行反向和优化if phase == 'train':loss.backward()optimizer.step()# 统计running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)epoch_loss = running_loss / dataset_sizes[phase]epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()# 记录每个epoch的loss和accuracyif phase == 'train':train_loss_history.append(epoch_loss)train_acc_history.append(epoch_acc)else:val_loss_history.append(epoch_loss)val_acc_history.append(epoch_acc)print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))print()# 保存模型
torch.save(model.state_dict(), 'SqueezeNet_model-m-s.pth')# 加载最佳模型权重
#model.load_state_dict(best_model_wts)
#torch.save(model, 'shufflenet_best_model.pth')
#print("The trained model has been saved.")
###########################误判病例分析#################################
import os
import pandas as pd
from collections import defaultdict# 判定组别的字典
group_dict = {("COVID-19", "Normal"): "B",("COVID-19", "Pneumonia"): "C",("COVID-19", "Tuberculosis"): "D",("Normal", "COVID-19"): "E",("Normal", "Pneumonia"): "F",("Normal", "Tuberculosis"): "G",("Pneumonia", "COVID-19"): "H",("Pneumonia", "Normal"): "I",("Pneumonia", "Tuberculosis"): "J",("Tuberculosis", "COVID-19"): "K",("Tuberculosis", "Normal"): "L",("Tuberculosis", "Pneumonia"): "M",
}# 创建一个字典来保存所有的图片信息
image_predictions = {}# 循环遍历所有数据集(训练集和验证集)
for phase in ['train', 'val']:# 设置模型的状态model.eval()# 遍历数据for inputs, labels, paths in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 计算模型的输出with torch.no_grad():outputs = model(inputs)_, preds = torch.max(outputs, 1)# 循环遍历每一个批次的结果for path, pred in zip(paths, preds):# 提取图片的类别actual_class = os.path.split(os.path.dirname(path))[-1] # 提取图片的名称image_name = os.path.basename(path)# 获取预测的类别predicted_class = class_names[pred]# 判断预测的分组类型if actual_class == predicted_class:group_type = 'A'elif (actual_class, predicted_class) in group_dict:group_type = group_dict[(actual_class, predicted_class)]else:group_type = 'Other' # 如果没有匹配的条件,可以归类为其他# 保存到字典中image_predictions[image_name] = [phase, actual_class, predicted_class, group_type]# 将字典转换为DataFrame
df = pd.DataFrame.from_dict(image_predictions, orient='index', columns=['Dataset Type', 'Actual Class', 'Predicted Class', 'Group Type'])# 保存到CSV文件中
df.to_csv('result-m-s.csv')四、改写过程
先说策略:首先,先把二分类的误判病例分析代码改成四分类的;其次,用咒语让GPT-4帮我们续写代码已达到误判病例分析。
提供咒语如下:
①改写{代码1},改变成4分类的建模。代码1为:{XXX};
②在{代码1}的基础上改写代码,达到下面要求:
(1)首先,提取出所有图片的“原始图片的名称”、“属于训练集还是验证集”、“预测为分组类型”;文件的路劲格式为:例如,“MTB-1\Normal\XXX.png”属于Normal,“MTB-1\COVID-19\XXX.jpg”属于COVID-19,“MTB-1\Pneumonia\XXX.jpeg”属于Pneumonia,“MTB-1\Tuberculosis\XXX.png”属于Tuberculosis;
(2)其次,根据样本预测结果,把样本分为以下若干组:(a)预测正确的图片,全部判定为A组;(b)本来就是COVID-19的图片,预测为Normal,判定为B组;(c)本来就是COVID-19的图片,预测为Pneumonia,判定为C组;(d)本来就是COVID-19的图片,预测为Tuberculosis,判定为D组;(e)本来就是Normal的图片,预测为COVID-19,判定为E组;(f)本来就是Normal的图片,预测为Pneumonia,判定为F组;(g)本来就是Normal的图片,预测为Tuberculosis,判定为G组;(h)本来就是Pneumonia的图片,预测为COVID-19,判定为H组;(i)本来就是Pneumonia的图片,预测为Normal,判定为I组;(j)本来就是Pneumonia的图片,预测为Tuberculosis,判定为J组;(k)本来就是Tuberculosis的图片,预测为COVID-19,判定为H组;(l)本来就是Tuberculosis的图片,预测为Normal,判定为I组;(m)本来就是Tuberculosis的图片,预测为Pneumonia,判定为J组;
(3)居于以上计算的结果,生成一个名为result-m.csv表格文件。列名分别为:“原始图片的名称”、“属于训练集还是验证集”、“预测为分组类型”、“判定的组别”。其中,“原始图片的名称”为所有图片的图片名称;“属于训练集还是验证集”为这个图片属于训练集还是验证集;“预测为分组类型”为模型预测该样本是哪一个分组;“判定的组别”为根据步骤(2)判定的组别,从A到J一共十组选择一个。
(4)需要把所有的图片都进行上面操作,注意是所有图片,而不只是一个批次的图片。
代码1为:{XXX}
③还需要根据报错做一些调整即可,自行调整。
最后,看看结果:
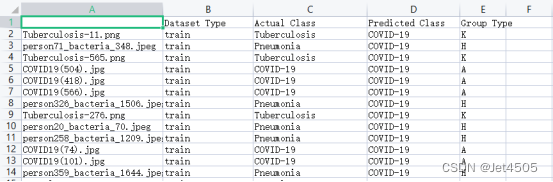
模型只运行了2次,所以效果很差哈,全部是预测成了COVID-19。
四、数据
链接:https://pan.baidu.com/s/1rqu15KAUxjNBaWYfEmPwgQ?pwd=xfyn
提取码:xfyn
五、结语
深度学习图像分类的教程到此结束,洋洋洒洒29篇,涉及到的算法和技巧也够发一篇SCI了。当然,图像识别还有图像分割和目标识别两块内容,就放到最后再说了。下一趴,我们来介绍时间序列建模!!!
相关文章:
第64步 深度学习图像识别:多分类建模误判病例分析(Pytorch)
基于WIN10的64位系统演示 一、写在前面 上期我们基于TensorFlow环境介绍了多分类建模的误判病例分析。 本期以健康组、肺结核组、COVID-19组、细菌性(病毒性)肺炎组为数据集,基于Pytorch环境,构建SqueezeNet多分类模型…...
ES查询报错内容长度超过104857600
项目场景: 使用 ElasticsearchRestTemplate 或者使用 RestHighLevelClient 查询 ES 报错 内容长度超过 104857600 问题描述 ES 查询报错 entiity content is too long xxx for the configured buffer limit 104857600 Overridepublic void esQuery() {restHighL…...

2023欧亚合作发展大会暨国际公共采购大会在京举行
2023年9月2日至6日,以“合作、协同、共赢、共享”为主题的“2023欧亚合作发展大会暨国际公共采购大会等系列会议”在北京炎黄书院隆重举行,共有500多位中外贵宾参加了本次盛会。 本次大会指导单位是中国联合国采购促进会、北京市中医药局,由中…...

宝塔面板linux在终端使用命令开启服务保持服务不关闭
我们经常在宝塔面板终端开启服务(比如socket等服务时),如果关闭面板标签页或者关闭终端,服务也随之关闭了,要保持服务一直运行,就需要把终端进程放在linux后台执行,方法如下: 1、先…...
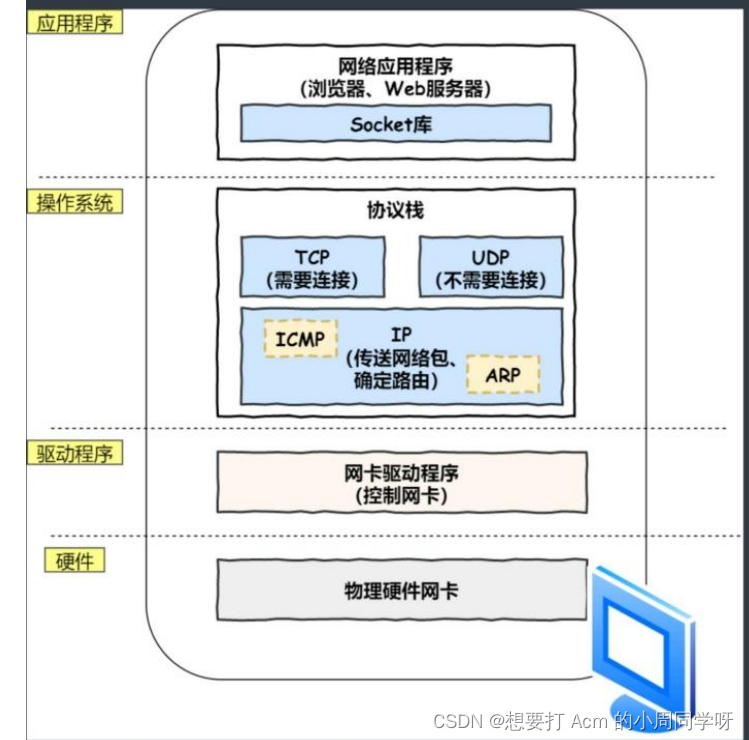
面试题--从键盘输入网站到网页显示,之间发生了什么
文章目录 首先进入HTTP阶段协议栈阶段TCP阶段IP阶段MAC网卡交换机路由器抵达 首先进入HTTP阶段 1.解析对应的URL,访问一个对应的服务器xxx.com的一个文件index.html; 2 使用DNS查询对应的ip地址,通过DNS服务器进行查找 3 组装http报文,生成h…...

字节9.3秋招研发笔试 【后端方向】第三题
题目 小红拿到了一个无向图,初始每人节点是白色,其中有若干个节点被染成了红色。小红想知道,若将 i 号节点染成红色,当前的红色连块的数量是多少? 你需要回答i∈[1,n] 的答案。 定义,若干节点组成一个红色连通块&am…...
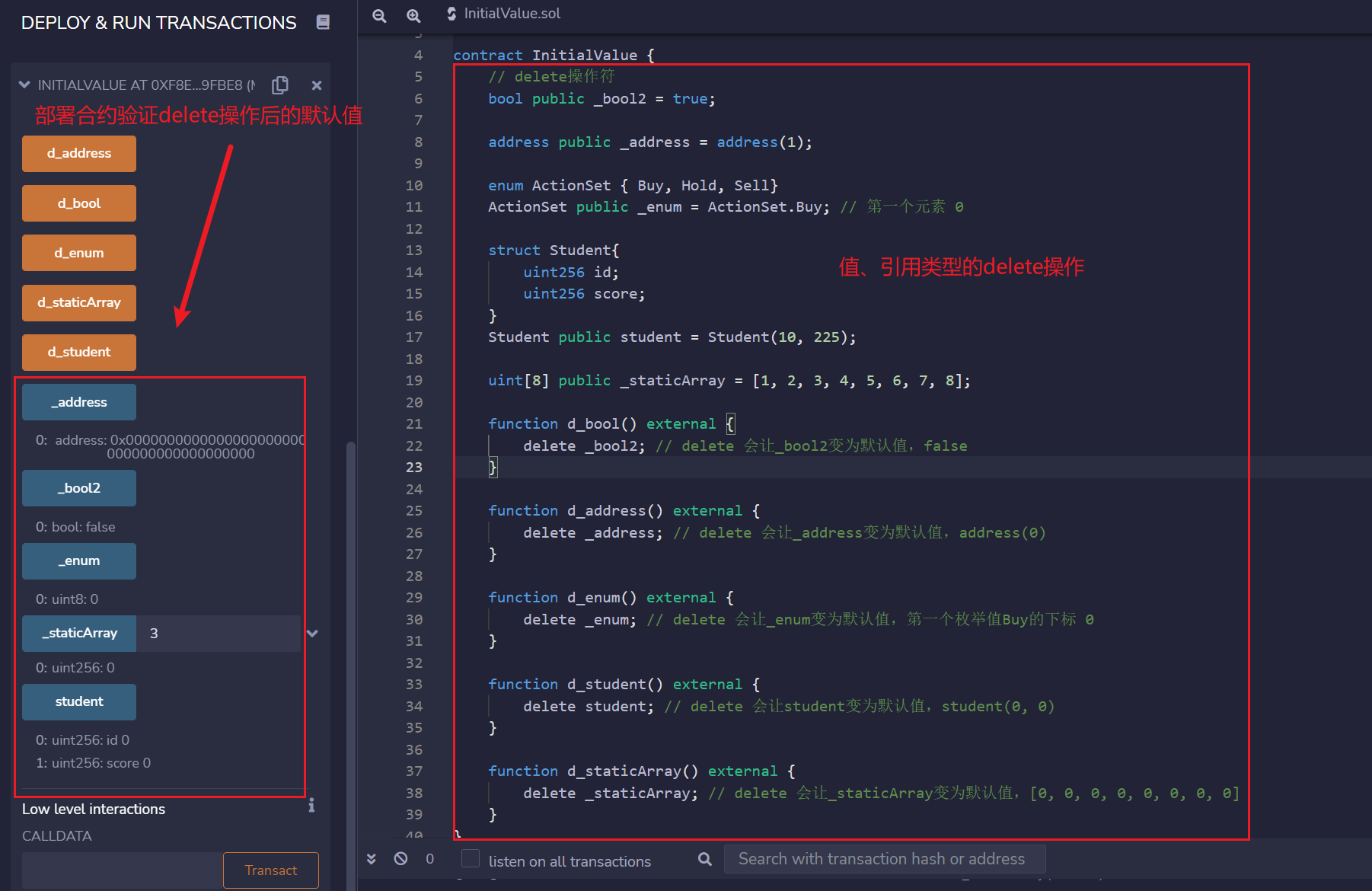
Solidity 小白教程:8. 变量初始值
Solidity 小白教程:8. 变量初始值 变量初始值 在solidity中,声明但没赋值的变量都有它的初始值或默认值。这一讲,我们将介绍常用变量的初始值。 值类型初始值 boolean: falsestring: “”int: 0uint: 0enum: 枚举中的第一个元素address: …...

时序预测 | MATLAB实现EEMD-SSA-LSTM、EEMD-LSTM、SSA-LSTM、LSTM时间序列预测对比
时序预测 | MATLAB实现EEMD-SSA-LSTM、EEMD-LSTM、SSA-LSTM、LSTM时间序列预测对比 目录 时序预测 | MATLAB实现EEMD-SSA-LSTM、EEMD-LSTM、SSA-LSTM、LSTM时间序列预测对比预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 时序预测 | MATLAB实现EEMD-SSA-LSTM、E…...

京东搜索EE链路演进 | 京东云技术团队
导读 搜索系统中容易存在头部效应,中长尾的优质商品较难获得充分的展示机会,如何破除系统的马太效应,提升展示结果的丰富性与多样性,助力中长尾商品成长是电商平台搜索系统的一个重要课题。其中,搜索EE系统在保持排序…...

【C++】反向迭代器精讲(以lIst为例)
目录 二,全部代码 三,设计思路 1. 讨论 2. 关于迭代器文档一个小细节 结语 一,前言 如果有小伙伴还未学习普通迭代器,请参考这篇文章中的普通迭代器实现。 【STL】list用法&试做_底层实现_花果山~~程序猿的博客-CSDN…...

时序预测 | MATLAB实现基于PSO-GRU、GRU时间序列预测对比
时序预测 | MATLAB实现基于PSO-GRU、GRU时间序列预测对比 目录 时序预测 | MATLAB实现基于PSO-GRU、GRU时间序列预测对比效果一览基本描述程序设计参考资料 效果一览 基本描述 MATLAB实现基于PSO-GRU、GRU时间序列预测对比。 1.MATLAB实现基于PSO-GRU、GRU时间序列预测对比&…...

2023年高教社杯 国赛数学建模思路 - 案例:感知机原理剖析及实现
文章目录 1 感知机的直观理解2 感知机的数学角度3 代码实现 4 建模资料 # 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 感知机的直观理解 感知机应该属于机器学习算法中最简单的一种算法,其…...

Java 利用pdfbox将图片和成到pdf指定位置
业务背景:用户在手机APP上进行签名,前端将签完名字的图片传入后端,后端合成新的pdf. 废话不多说,上代码: //控制层代码PostMapping("/imageToPdf")public Result imageToPdf(RequestParam("linkName&…...

大数据课程K19——Spark的电影推荐案例推荐系统的冷启动问题
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握Spark的案例——电影推荐; ⚪ 掌握Spark的模型存储; ⚪ 掌握Spark的模型加载; ⚪ 掌握Spark的推荐系统的冷启动问题; 一、案例——电影推荐 1. 基于用户的推荐 1. 说明 我们现…...
Docker-安装(Linux,Windows)
目录 前言安装版本Docker版本说明前提条件Linux安装使用YUM源部署获取阿里云开源镜像站YUM源文件安装Docker-ce配置Docker Daemon启动文件启动Docker服务并查看已安装版本 使用二进制文件部署 Windows安装实现原理安装步骤基本使用 参考说明 前言 本文主要说明Docker及其相关组…...
若依富文本 html样式 被过滤问题
一.场景 进入页面,富文本编辑框里回显这条新闻内容,如下图, 然后可以在富文本编辑框里对它实现再编辑,编辑之后将html代码提交保存到后台数据库。可以点击详情页进行查看。 出现问题:在提交到后台controller时&#x…...

VS Code 快速消除前置空格和常用快捷键
目录 介绍: 消除前置空格:SHIFTTAB 常用的 VS Code 快捷键 介绍: 在使用 Visual Studio Code (VS Code) 进行代码编辑时,熟练掌握一些快捷键和编辑技巧可以大幅提高开发效率。本文将重点介绍如何使用快捷键 SHIFTTAB 快速消除代…...
)
【跟小嘉学 Rust 编程】二十五、Rust命令行参数解析库(clap)
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...
gRPC远程进程调用
gRPC远程进程调用 rpc简介golang实现rpc方法一net/rpc库golang实现rpc方法二jsonrpc库grpc和protobuf在一起第一个grpc应用grpc服务的定义和服务的种类grpc stream实例1-服务端单向流grpc stream实例2-客户端单向流grpc stream实例3-双向流grpc整合gin...
什么是继承
提示:继承基础概念 文章目录 一、继承1.1 基础概念1.2 继承作用与继承方式1.2 继承中的隐藏1.3 类中构造、析构在继承方面知识1.4 继承知识拓展 一、继承 1.1 基础概念 继承机制是面向对象程序设计使代码可以复用的最重要的手段,它允许在保持原有类特性…...

浅谈MIKEURBAN计算进度条停止的解决方法
01 问题昨天晚上,一个同事拿着笔记本对着我说,为什么我的MIKE URBAN计算进度条一直停滞在5%,停止了。我说是不是兼容问题,要不重新安装下软件吧。最终还是很感谢某同事找到了解决方法。02 解决方法MIKE URBAN低版本的通常分为了32…...

3步掌握百度网盘效率工具:全平台秒传链接解决方案
3步掌握百度网盘效率工具:全平台秒传链接解决方案 【免费下载链接】baidupan-rapidupload 百度网盘秒传链接转存/生成/转换 网页工具 (全平台可用) 项目地址: https://gitcode.com/gh_mirrors/bai/baidupan-rapidupload 在数字化协作时代,文件传输…...

ESP32-S3实战指南:SPI多设备管理与高效数据传输
1. ESP32-S3的SPI总线基础认知 第一次接触ESP32-S3的SPI总线时,我完全被各种专业术语搞懵了。后来在实际项目中反复折腾才发现,SPI本质上就是个"快递小哥",负责在芯片和外围设备之间搬运数据。ESP32-S3内置了4个这样的"快递站…...

Phi-4-mini-reasoning效果对比:在GSM8K与AQuA数据集上的zero-shot推理表现
Phi-4-mini-reasoning效果对比:在GSM8K与AQuA数据集上的zero-shot推理表现 1. 模型介绍 Phi-4-mini-reasoning是一款专注于推理任务的文本生成模型,特别擅长处理需要多步逻辑分析和精确结论输出的任务场景。与通用对话模型不同,它被专门设计…...

InoDriverShop参数设置避坑指南:如何避免伺服系统调试中的常见错误
InoDriverShop参数设置避坑指南:如何避免伺服系统调试中的常见错误 伺服系统调试是工业自动化领域中的关键环节,而InoDriverShop作为一款功能强大的伺服驱动配置工具,其参数设置的准确性直接影响到设备的运行性能。本文将深入剖析新手工程师…...

终极指南:如何使用Harepacker-resurrected打造个性化MapleStory游戏体验
终极指南:如何使用Harepacker-resurrected打造个性化MapleStory游戏体验 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 你是否曾…...

Windows系统优化工具WinUtil:从新手到专家的完整使用指南
Windows系统优化工具WinUtil:从新手到专家的完整使用指南 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 你是否厌倦了Windows系统…...

数据库索引原理:B+树与哈希索引的深度对决
数据库索引原理:B树与哈希索引的深度对决在数据库的世界里,索引是提升查询性能的“核武器”。如果把数据库表比作一本厚厚的书,那么索引就是书中的目录。没有目录,想要找到特定的知识点只能一页页翻找(全表扫描&#x…...

数据主权时代,企业即时通讯厂商选型推荐
BeeWorks作为企业级私有化 IM,主打安全可控、深度协同、信创适配,在政企、军工、金融等强合规场景口碑突出。BeeWorks 定位为安全专属数字化协作平台,核心是私有化部署 全链路安全 业务深度融合,区别于通用 SaaS IM。1. 核心架构…...

星露谷物语SMAPI模组加载器:终极安装与使用完全指南
星露谷物语SMAPI模组加载器:终极安装与使用完全指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 想要为《星露谷物语》安装模组来扩展游戏体验吗?SMAPI模组加载器是官方推…...