京东搜索EE链路演进 | 京东云技术团队
导读
搜索系统中容易存在头部效应,中长尾的优质商品较难获得充分的展示机会,如何破除系统的马太效应,提升展示结果的丰富性与多样性,助力中长尾商品成长是电商平台搜索系统的一个重要课题。其中,搜索EE系统在保持排序结果基本稳定的基础上,通过将优质中长尾商品穿插至排序结果中将优质商品动态展示给用户,提升用户体验与搜索结果丰富性,是破除马太效应的一大助力。
本文将从搜索EE近期的全量迭代出发,展现其链路演进的整体脉络,包含:EE自适应动态探测模型——EE场景建模方式升级——打分与穿插两阶段一致性升级——探测与自然流量全局联动优化四个阶段,梳理对搜索EE的思考与下一步迭代方向。
全文目录:
1. EE自适应动态探测模型
2. EE场景建模方式升级
3. 打分与穿插两阶段一致性升级
4. 感知上下文的品牌店铺维度探测
5. 总结与展望
一、EE自适应动态探测模型
传统EE模型从商品曝光置信度、打分置信度等角度出发,决策EE商品的展示位置以及穿插位置,较少从用户浏览意图与探索意愿的差异化角度,来考量探测力度。其可能导致用户在宽泛浏览与挑选商品时,缺少丰富的商品选择,在决策购买时反而穿插了探索商品的误判情景,影响用户的搜索体验,不能充分发挥搜索EE系统的探索和利用(Explore & Exploit)两大能力。
针对以上探测错配情况,可尝试在EE模型中显式建模用户的“逛”、“买”探索偏好,进一步结合偏好,自适应调整搜索EE的利用与探索力度。对于偏“逛”用户增强EE探索力度,提供更丰富的探索展示;对于购买意愿明显的用户,提供更直接的购买选择。通过对用户探索偏好的显式建模,能够在提升用户的转化效率的同时提升搜索结果丰富性。
1.自适应探索模型优化
相较于原有EE模型,自适应探索对EE模型的自适应探索能力进行了升级,主要体现在如下三点:(1)对用户探索偏好进行差异化建模:“逛” "买"用户提供动态差异化探测力度,在转化效率和搜索丰富性中取得平衡。(2)以用户浏览深度为子任务建模到EE模型中:以浏览深度作为用户意愿的重要指标,并建模到EE模型中,显式增强模型对用户浏览意愿的感知。(3)提升模型对探索性特征利用性:对探索偏好的显式建模,提升探索性特征在模型中的学习权重,在EE过程中对探索特征进行充分利用。
2.方案实践
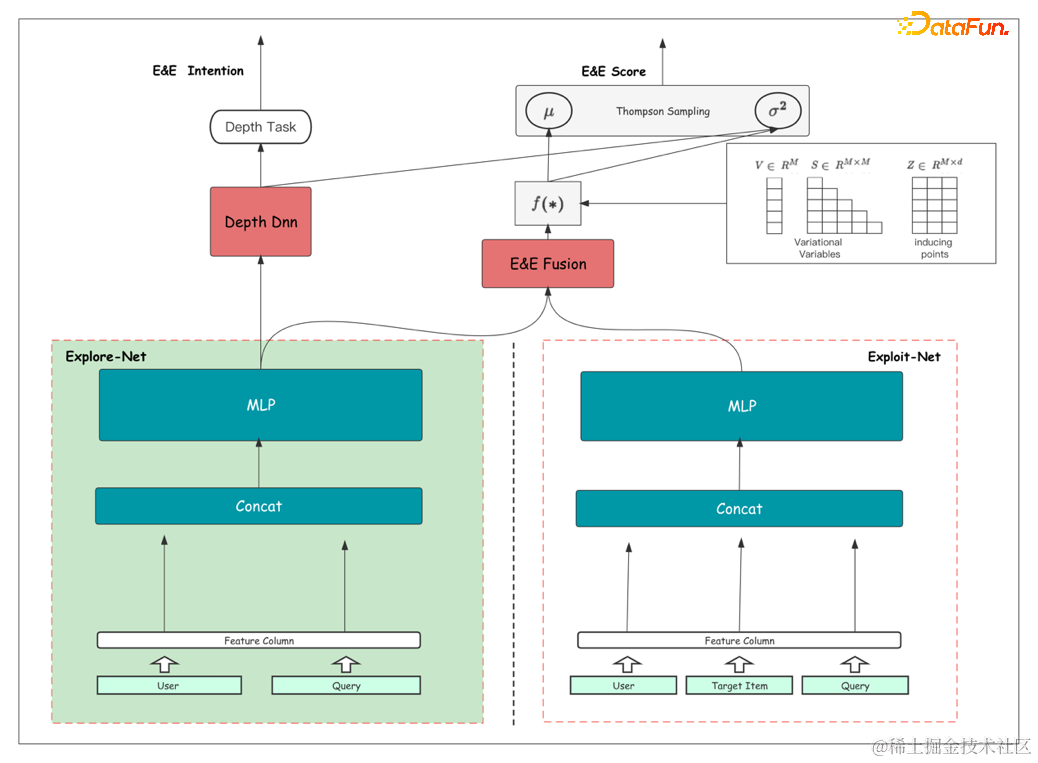
为了增强EE模型的自适应探索能力,针对原有EE模型进行如下升级:
(1)探索偏好网络Explore-Net
在保持原有的EE模型主网络Exploit-Net基础上,添加了探索偏好网络Explore-Net(图中左下绿色部分),提升模型对用户探索意图的差异化建模。
①输入特征优化
考虑到用户的探索意图只与个人特性、搜索词相关,因此Explore-Net的输入特征仅使用用户侧、Query侧中相关特征。
为进一步度量特征与探索偏好的关联性,统计不同浏览深度下各特征的分布差异,剔除了未与浏览深度明显相关特征,如搜索词长度等,精简特征空间提升预估精度。
②模型显性建模
EE原模型的输入中包含探索性特征,但在进行搜索排序任务中易被其他特征掩盖导致利用率不强,在探索偏好建模中显式构建了探索偏好网络Explore-Net,对用户探索意图进行独立建模构建,增强探索性特征的重要性。
优化后的EE模型具有Exploit-Net与Explore-Net双塔结构,Exploit-Net对商品进行精准化打分,对候选商品进行充分利用;Explore-Net对用户探索意愿进行建模,根据用户偏好动态调整探索力度,共同构成商品探索与利用的完整机制。
(2)用户浏览深度回归任务构建
在原有的训练过程基础上,添加了用户浏览深度回归任务(图中左上红色部分),提升模型对用户浏览意愿的感知性,增强EE模型的自适应探索能力。
①辅助任务选择
浏览深度作为用户浏览意愿的直观体现,表现了用户的探索意愿,因此使用浏览深度预估任务作为模型训练的辅助任务,对用户偏好进行显式建模。
在辅助任务类型的考量上,综合考虑了将浏览深度划分不同区间进行预测的分类任务,以及对浏览深度的回归任务。在实验中分类任务体现出较为明显的头尾倾向性,输出值分布不均匀,实践中最终选用了回归任务作为辅助任务。
②回归任务设计
在样本数据分析中,发现用户的浏览深度差异化极大。为了平衡浏览深度的差异,保障模型输出值的均匀性与差异性,对浏览深度标签进行了log平滑放缩,并选用RMSE-loss作为辅助任务的损失函数对浏览深度任务进行构建。
在模型训练中头尾样本相对较少,对过浅和过深的两类样本预测准确性偏低。为平衡样本间差异,在损失函数的样本权重设计中,对由浅到深相应样本,其权重为先减小后增大的 “凹形”权重,平衡头尾和腰部样本的准确性。
(3)Explore-Net与主网络的二次融合
Explore-Net 和 Exploit-Net 进行了融合(图中中上红色部分),增强模型整体对探索性特征的利用,提升EE隐层embedding丰富性,对探索偏好较强的用户提升了不确定性打分,提升探索商品的范围和丰富度。

①特征融合
由于在用户浏览深度回归任务上对用户的探索偏好进行了显式建模,Explore-Net的输出embedding对探索性特征进行了高维抽取,能够对用户偏好进行自适应建模。
为让探索偏好特征更好地参与到整体任务训练中,平衡打分的精准性与差异化,将Explore-Net的深层表征与Exploit-Net的深层表征进行拼接融合,提升EE模型隐层embedding的丰富性和表征能力,提升模型打分能力。
②不确定性预估融合
用户的探索偏好与商品的不确定性预估有直接的相关关联。对于探索意图较强的用户,提升商品打分的不确定性,助力更丰富的商品穿插到搜索结果中,反之亦如此。因此在不确定性预估模块中,设计在探索表征层面进行融合。
在不确定性预估(SVGP)模块中,将浏览深度回归网络输出值与方差预估部分进行了二次融合,对于探索偏好较强的用户,显式强化了商品不确定性打分,提升探索力度。
3.升级效果
(1)探索利用效果分析
①EE模型打分结果分析:
在相同的预测集上,统计了平均打分探测力度随浏览深度变化情况
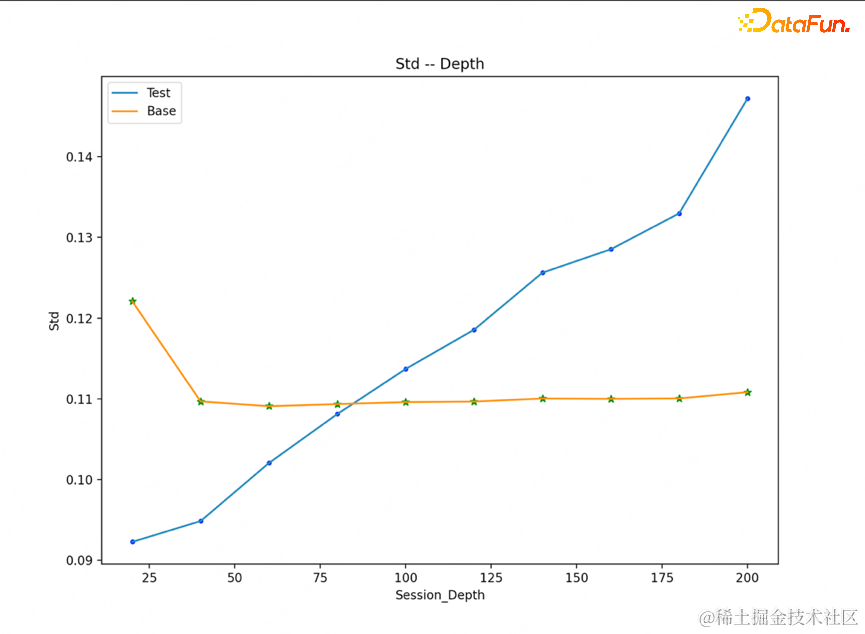
结论:相比原模型,自适应探索模型的平均探测力度,随浏览深度增大而逐渐增大,体现出session维度的显著差异化。
②EE实验位下穿插商品位置分析:
在各实验位下,统计平均插入位置与浏览深度的变化情况。

结论:Test桶结果,随着浏览深度增大,商品的平均插入位置相比原模型有所前移,探索力度增强。
核心结论:通过以上对探索利用的效果分析,自适应探索模型符合设计预期,在浏览深度较低的session下插入商品较少,探索力度较弱;在浏览深度较深的session下,EE模型的探索意愿更强,模型探索力度更大,穿插商品位置有所前移。
(2)线上效果
保持搜索效率持平的情况下,EE核心指标提升明显并全量上线,流动性、探索成功率提升近 0.5%。
商品建模方式思考:
差异化建模用户探索意图后,EE模块实现了对不同用户自适应调整探索并取得了一定收益。用户侧建模方式优化后,对商品侧建模方式进行升级改造,将是进一步提升EE探测模型的合理切入点。
二、EE场景建模方式升级
原主网络建模方式为点击率单任务,点击作为转化的前置行为,建模点击行为实现对潜力中长尾的探索助力。同时在实践中,通过样本label进行动态权重调整,隐式建模转化属性,兼顾转化效率。
仅建模点击对高转化属性商品并不友好,同时是对标题党行为的潜在鼓励,和EE模块优化整体生态环境、打造搜索长期价值的初衷有所偏差。因此升级思路不再局限于仅关注曝光后获得点击这一前置链路行为,而是对整体转化链路进行建模,关注商品的多维度属性。
1.EE场景建模方式优化
在原有基础上引入转化行为的显式建模任务,将主网络结构从点击单任务升级为点击转化多任务,以多任务方式增强不同行为的建模质量,实现对商品的更全面、更准确建模。
2.方案实践

在EE自适应探索机制基础上,EE场景建模方式升级对原有模型进行了如下优化与升级:
(1)SVGP模块交互方案设计
原模型中主网络和辅助模块在SVGP模块中交互,新版方案中辅助任务是否需要与SVGP模块进行交互? 即随机高斯过程是否需要同样作用于建模转化任务,是方案设计首要考虑的问题。
具体实验中,发现SVGP会导致收敛后AUC指标在千分位级别降低,即其在引入不确定性功能的同时,会轻微降低模型效果。考虑到目前SVGP模块已带来所需的探索能力,难以通过多SVGP堆叠方式带来收益。因此升级方案选择将辅助任务构建成纯净任务,其仅建模商品属性而不构建对应的SVGP模块。
(2)多任务网络框架实现
EE探测线上耗时较低,建模方式升级后需延续这一目标。虽然主流多任务结构MMOE性能更为优越,但线上耗时将有增加风险,因此选择更轻量级的share bottom方式,在基本不增加线上耗时的情况下完成多任务建模。升级方案把多任务被设计为双任务模型,使用低层网络进行表征抽取,在高层维度使用两个tower分别建模主任务和辅助任务。
①任务组合选取
选择双任务为ctr任务+ctcvr任务,考虑到点击样本比订单样本更丰富, ctr正样本更多,对于需要大量引导点的SVGP模块更为友好。同时点击相对购买行为的不确定性更高,在点击预测上引入不确定性打分更为合理,因此将ctr作为主任务、ctcvr为辅助任务进行配置。
②模型结构迭代
前述迭代过程中模型结构如图中间所示,低层网络编码输入信息后使用两个浅层tower分别学习不同任务, 该结构潜在缺点为一方面可能导致低层网络梯度被某个任务主导(例如ctr任务),另一方面上层tower过浅可能导致任务学习不够充分。
进一步探索仅共享特征、增加任务tower深度的网络结构。在多任务分数融合方式相同的情况下,新结构线上表现更佳,因此最终结构如上图最右所示,使用较深的tower head建模各自任务,彼此间仅共享特征。
③融合方式迭代
上述模型在离线指标上取得了不错的收益且线上表现更优,但遇到了大盘效率和EE相关指标无法同时提升的问题。分析梳理现有方案实验后,认为目前多任务融合方式相对朴素、存在改善提升空间。
选取带权相加、直接相乘和幂次指数相乘三种方式。由于缺乏合适的理论量化分析工具,因此选择从实验结果出发选取最优融合方式和融合系数,为此开发了离线融合寻参模块,将predict时各head打分结果保存后,通过网格搜索方式选取最优参数。
通过在多组数据上遍历寻优确定不同融合方式的最优系数,并基于此开展线上实验选取表现最优方式,最终我们选取带权相加方式,在EE指标提升的同时保持大盘效率指标持平。
3.升级效果
(1)模型建模升级效果分析
①EE模型打分区分度分析:
在相同的预测集上,统计了离线打分分布情况

结论:分布由橙色线条(原版)变为蓝色线条(升级后版本),整体更加平缓,保证不同商品彼此更具备区分度。
②EE探测次数分析:
统计线上打分分布情况,对线上探测情况进行分析

结论:横轴为曝光数量大于等于N,纵轴为distinct sku数量,下图表明模型升级后在仅探索一次的dst sku数量上有所下降,减少偏随机的一次性探测,但在多次探索商品上有所提升,表明test更倾向于探索中腰部商品。
(2)线上效果
搜索效率持平情况下,流动性指标、探索成功率提升显著并全量上线。
链路一致性思考:
完成EE打分模型优化后,能够一定程度实现探索力度随用户探索意愿的动态调整。但从整体EE链路上看 (候选集生成 → EE打分 → 动态展示),EE动态穿插决策与打分阶段相互独立,其结果由一个xgb回归模型决定,两个阶段的联动关系和一致性程度弱。如何跟随用户浏览意愿,将 EE打分→ 动态展示 两个环节能够同步、一致性地调整,是进一步的优化方向。
三、打分与穿插端到端一致性升级
打分与穿插展示两个阶段一致性未能对齐,可能导致激进的模型打分无法匹配上丰富的穿插展示,无法同步放大EE的探测效果。此外,两个阶段分别由两个模型独立控制,也增加了维护和迭代成本。
面对此一致性问题,升级了端到端打分与穿插方案。EE模型中建模的用户浏览意图,不仅影响EE探测的力度大小,也同时决定动态穿插展示的策略强弱。两阶段的决策过程端到端实现,将流量进行更合理分配,宽泛意图的用户能够达到探测更激进、穿插更多的共振。
1.端到端动态穿插机制优化点
端到端动态穿插机制在原有自适应探索基础上,升级点主要体现在如下三点:
(1)浏览深度预估精准度升级:在EE探索偏好建模网络Explore-net基础上,提升浏览深度预测精准度。
(2)EE流量精准化分配:根据session浏览深度分布,动态分配各深度下穿插商品量,提升EE穿插商品占比调控可操作性。
(3)模型打分与动态穿插数量端到端一致性增强:采用EE主模型的浏览深度,映射得到当前session下穿插商品数量,端到端解决EE穿插商品数量与EE商品打分两个任务,提升两阶段一致性。
2.方案实践
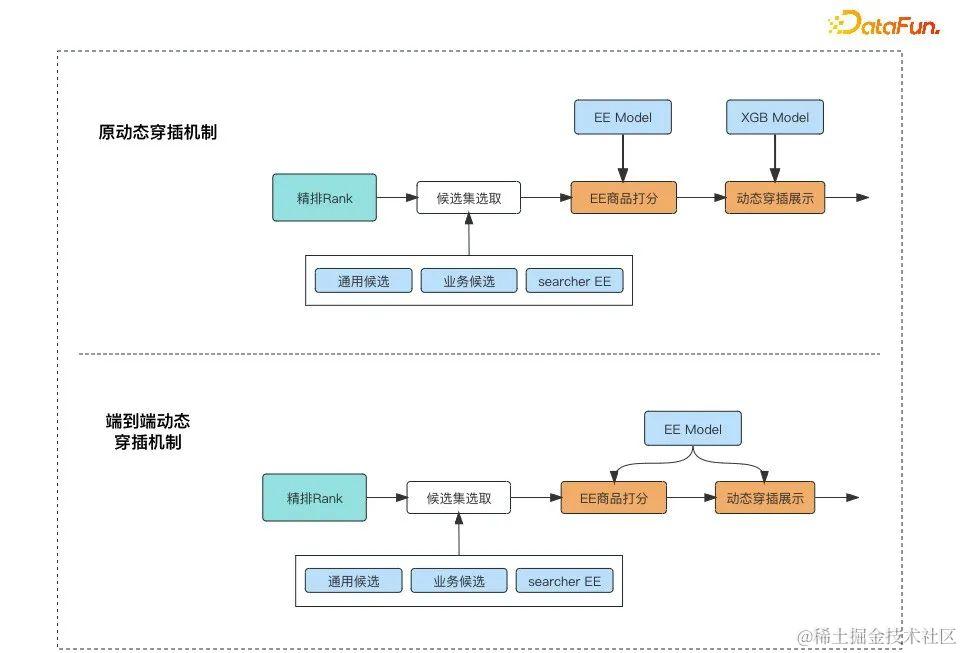
在EE自适应探索机制基础上,端到端动态穿插机制对原有动态穿插机制进行了如下优化与升级:
(1)动态穿插机制端到端建模
①浏览深度预估任务优化
浏览深度代表了用户在session下的浏览意愿,是EE流量进行合理分配的基础性指标。在不同浏览深度的session下,匹配适合数量的EE商品能在保障效率的前提下提升搜索结果丰富性。
进一步优化了自适应探索模型中Explore-Net对浏览深度预估子任务的准确性,对其输出的浏览深度预估值进行评估,其准度明显高于原有xgb模型,可以对原有xgb模型进行替换。
②端到端建模浏览深度与模型打分
自适应探索实验中使用Explore-Net对模型打分进行差异化探索,其中的浏览深度预估任务可以沿用到穿插商品数量任务中,使模型具有端到端建模两个子任务的能力。
(2)合理设计浏览深度与穿插商品数量映射
在准确预估浏览深度的情况下,通过将浏览深度预估值映射到穿插数量中,保障穿插数量与模型打分一致性,在更深的session下有更多的商品穿插数量和更强的探测力度。
3.升级效果
(1)动态穿插效果分析
①浏览深度预测准度分析:
对比两模型的浏览深度预估准确性,使用均方根对数误差(Root Mean Squared Logarithmic Error, RMSLE)指标进行衡量

结论:在同样的验证集下,Explore-net模型的预估精度明显优于原模型。
②探索打分、动态穿插一致性效果分析:
检查各浏览深度下base与test两个机制下各浏览深度下预设的插入商品曲线和穿插商品数量分布图。
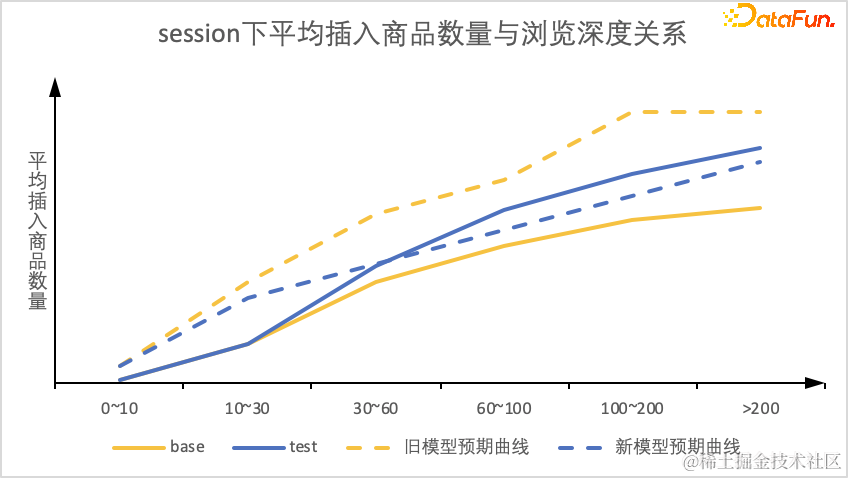
结论:
- 比较蓝色(test)与黄色(base)两根实线,在较浅的session下,新旧机制穿插商品数量基本持平;在较深的session下,新机制相较于旧机制插入商品数量更多,体现了探索较强时新的穿插机制会探索更多商品。
- 通过蓝色实线与虚线,黄色实线与虚线两组曲线对比,新穿插机制下预期插入数量曲线与实际插入数量曲线更贴合,说明穿插数量设定更为合理,新的穿插机制与商品打分一致性更强。
(2)线上效果
搜索效率持平情况下,EE核心指标有一定提升并全量上线。
流量整体联动优化思考:
在对EE流量进行整体优化后,商品探索力度与EE流量分配能够随用户浏览意愿进行自适应调整,但从全局商品展示结果中看,EE探测流量与自然流量相互独立,两者之间并未建立充分的联动与结合。
将视角逐渐放宽到整个排序链路,如何做好EE流量与自然流量的联动,发挥EE在搜索排序链路后置位的优势充分补充与优化自然流量是下一个关心的问题。
四、感知上下文的品牌店铺维度探测
在搜索链路中,EE处于相对后置的位置,然而原EE系统未充分利用这一感知优势,对前序排序结果感知能力较弱。在一些强势品牌、店铺主导的关键词下,存在头部品牌、店铺扎堆现象,优质新品、中长尾商品无法露出,马太效应明显。
对此问题,尝试跳出仅考虑商品维度探测的局限,从更高的品牌、店铺维度视角,对排序结果进行全局性联动优化,建立感知上下文的多维度探测能力。其设计旨在增强对上下文排序结果的感知能力,并在自然流量中对商品分布进行联动优化,系统性缓解排序链路的马太效应。

1.感知上下文的多维度探测机制优化点
感知上下文的多维度探测机制在原有EE探测能力基础上,进行了如下三个方面的优化:
(1)新增EE探测系统对上下文感知能力:对EE前的排序上下文结果进行充分的感知,对自然流量下原有搜索排序结果进行自适应的穿插优化。
(2)实现EE探测维度的扩展:除了现有支持的商品粒度探测,从更宏观的品牌、店铺等维度视角对排序生态进行优化。
(3)EE流量与自然流量联动全局性优化:缓解部分词下头部品牌和店铺扎堆现象,提升排序多样性,避免对头部品牌、店铺商品进行更多探测、加剧马太效应。
2.方案实践
本次升级在原有的搜索EE穿插机制下进行了如下能力的增强与优化:
(1)新增上下文感知能力
在原有搜索EE穿插机制基础上,新增加上下文感知能力,对搜索词属性和上下文排序结果的商品分布进行计算,指导后续的穿插过程
①感知query词属性
为保障搜索排序结果合理性,避免产生体验性问题,感知上下文能力将判断query词是否是品牌词(如:华为)或型号词(如:iphone),决定是否开启品牌维度探测;判断query词是否是精准店铺词,决定是否开启店铺维度探测。
②排序结果商品分布
新增上下文排序结果感知能力,通过统计上链路搜索结果排名前k的商品中的品牌和店铺的分布情况,判断是否存在品牌或店铺的集中现象,进而决定是否开启多维度探测能力。
(2)优化原有穿插机制
在感知能力作为多维度探测启动开关基础上,优化了原有的穿插机制,通过EE展示效果与自然流量结果联动提升搜索结果丰富性与多样性,对搜索结果进行直接高效的影响。
①由感知能力模块判断用户搜索意图和商品分布,决定是否进行多维度探测
对用户搜索意图直接的搜索词动态开启多维度探测功能,如query为品牌词或型号词则不应进行品牌维度探测,如query为店铺词则不进行店铺维度探测,避免影响搜索结果的准确性。考量搜索结果的前k个商品的品牌/店铺分布,判断是否存在头部品牌/店铺扎堆的问题,当同一品牌/店铺下商品占比超过p%后,不再插入该类型EE商品。
②穿插结果优化
如不再插入该类型EE商品,在候选商品中剔除该类型,其余商品按照EE打分结果插入到排序结果中,不影响EE穿插过程与穿插数量,保障EE穿插位置和展现效果合理性。
3.升级效果
(1)多维度探测效果分析
①EE穿插曝光占比分析:
在EE穿插过程中,由于部分EE模型打分较高的头部品牌/店铺的商品在EE候选商品中被剔除,剩余商品模型打分稍低导致穿插位置发生后移或无法穿插进排序结果中,为了避免EE穿插曝光占比降低,提升了各浏览深度下EE穿插商品的配额。实验期间EE曝光占比base与test基本持平。
②多维度探测体验分析:
下面对比了多款热词下EE穿插商品情况。

结论:在多组query词下,test机制相较于base机制在穿插的过程中减少了头部品牌/店铺的插入,增强了展示结果的丰富性,缓解马太效应;同时注意到test机制由于部分头部品牌/店铺商品被滤除,穿插位置相对有所后移,在排序靠后的位置受配额影响多插入1-2个商品,整体曝光量与base基本一致,与分析一的结论一致。
(2)线上效果
在保持搜索效率持平的情况下,多样性指标大幅提升并全量上线。
五、总结与展望
本文重点阐述了在搜索EE机制迭代过程中的思考与演进历程,搜索EE作为优化搜索生态与缓解搜索马太效应的重要工具,在演进过程中也围绕搜索结果丰富性和体验性进行了系统性优化。
在优化思路上,不断寻找EE系统的瓶颈问题,在自适应探索机制和建模方式升级提供差异化商品探索力度;将商品打分与穿插商品个数进行联动,端到端优化EE流量分配问题;之后将视野扩展到全局流量,通过多维度探索机制联动自然流量,使EE流量作为自然流量的互相补充。整体思路体现出从商品间探索打分优化——EE流量个性化分配——与自然流量全局优化的迭代进程。
搜索EE后续还将面临更多的问题和挑战,后续会继续沿用这样的迭代思路在更多方面进行探索与深入:
- 扩展EE模型的训练样本空间,优化现有任务建模方案。
- 搜索EE向更广链路辐射,打造全链路EE探索能力。
- EE覆盖更广商品建模,打造更完善的中长尾商品泛化表征。
今天的分享就到这里,谢谢大家。
作者:京东零售 才子嘉,赵恒
来源:京东云开发者社区 转载请注明来源
相关文章:
京东搜索EE链路演进 | 京东云技术团队
导读 搜索系统中容易存在头部效应,中长尾的优质商品较难获得充分的展示机会,如何破除系统的马太效应,提升展示结果的丰富性与多样性,助力中长尾商品成长是电商平台搜索系统的一个重要课题。其中,搜索EE系统在保持排序…...

【C++】反向迭代器精讲(以lIst为例)
目录 二,全部代码 三,设计思路 1. 讨论 2. 关于迭代器文档一个小细节 结语 一,前言 如果有小伙伴还未学习普通迭代器,请参考这篇文章中的普通迭代器实现。 【STL】list用法&试做_底层实现_花果山~~程序猿的博客-CSDN…...

时序预测 | MATLAB实现基于PSO-GRU、GRU时间序列预测对比
时序预测 | MATLAB实现基于PSO-GRU、GRU时间序列预测对比 目录 时序预测 | MATLAB实现基于PSO-GRU、GRU时间序列预测对比效果一览基本描述程序设计参考资料 效果一览 基本描述 MATLAB实现基于PSO-GRU、GRU时间序列预测对比。 1.MATLAB实现基于PSO-GRU、GRU时间序列预测对比&…...

2023年高教社杯 国赛数学建模思路 - 案例:感知机原理剖析及实现
文章目录 1 感知机的直观理解2 感知机的数学角度3 代码实现 4 建模资料 # 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 感知机的直观理解 感知机应该属于机器学习算法中最简单的一种算法,其…...

Java 利用pdfbox将图片和成到pdf指定位置
业务背景:用户在手机APP上进行签名,前端将签完名字的图片传入后端,后端合成新的pdf. 废话不多说,上代码: //控制层代码PostMapping("/imageToPdf")public Result imageToPdf(RequestParam("linkName&…...

大数据课程K19——Spark的电影推荐案例推荐系统的冷启动问题
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握Spark的案例——电影推荐; ⚪ 掌握Spark的模型存储; ⚪ 掌握Spark的模型加载; ⚪ 掌握Spark的推荐系统的冷启动问题; 一、案例——电影推荐 1. 基于用户的推荐 1. 说明 我们现…...
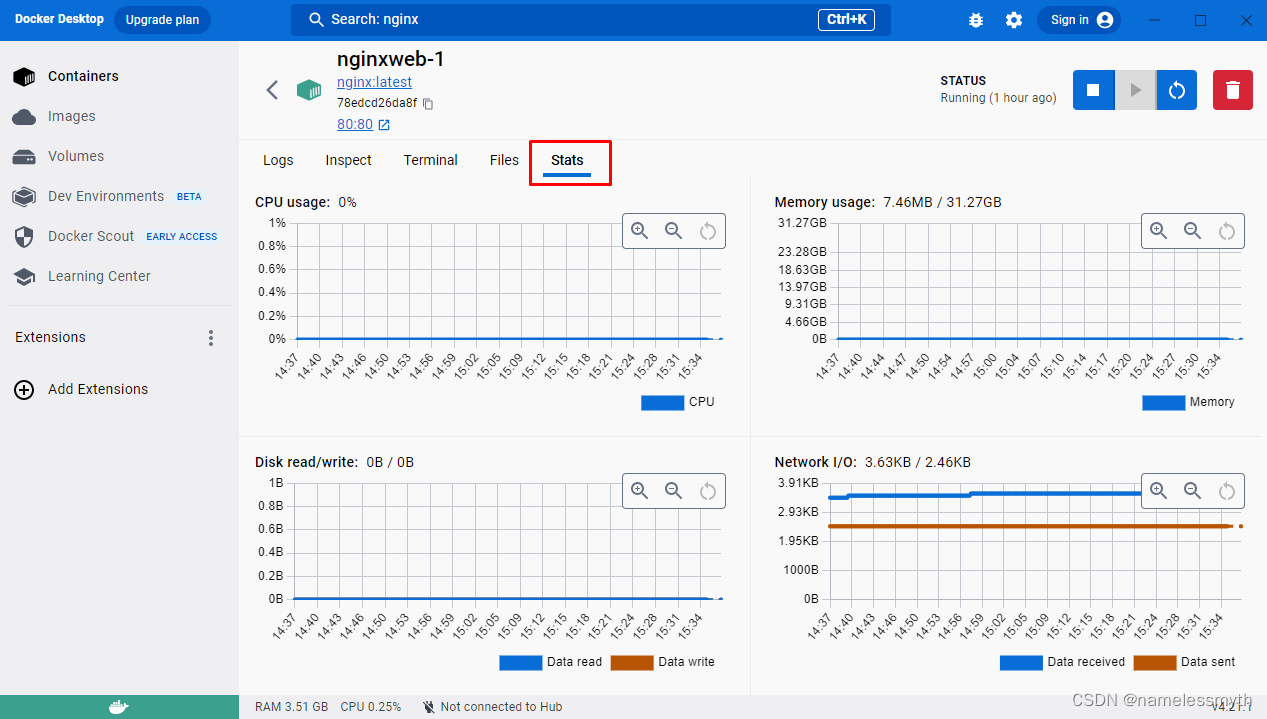
Docker-安装(Linux,Windows)
目录 前言安装版本Docker版本说明前提条件Linux安装使用YUM源部署获取阿里云开源镜像站YUM源文件安装Docker-ce配置Docker Daemon启动文件启动Docker服务并查看已安装版本 使用二进制文件部署 Windows安装实现原理安装步骤基本使用 参考说明 前言 本文主要说明Docker及其相关组…...
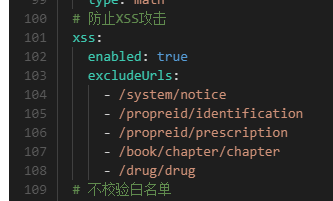
若依富文本 html样式 被过滤问题
一.场景 进入页面,富文本编辑框里回显这条新闻内容,如下图, 然后可以在富文本编辑框里对它实现再编辑,编辑之后将html代码提交保存到后台数据库。可以点击详情页进行查看。 出现问题:在提交到后台controller时&#x…...

VS Code 快速消除前置空格和常用快捷键
目录 介绍: 消除前置空格:SHIFTTAB 常用的 VS Code 快捷键 介绍: 在使用 Visual Studio Code (VS Code) 进行代码编辑时,熟练掌握一些快捷键和编辑技巧可以大幅提高开发效率。本文将重点介绍如何使用快捷键 SHIFTTAB 快速消除代…...
)
【跟小嘉学 Rust 编程】二十五、Rust命令行参数解析库(clap)
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...
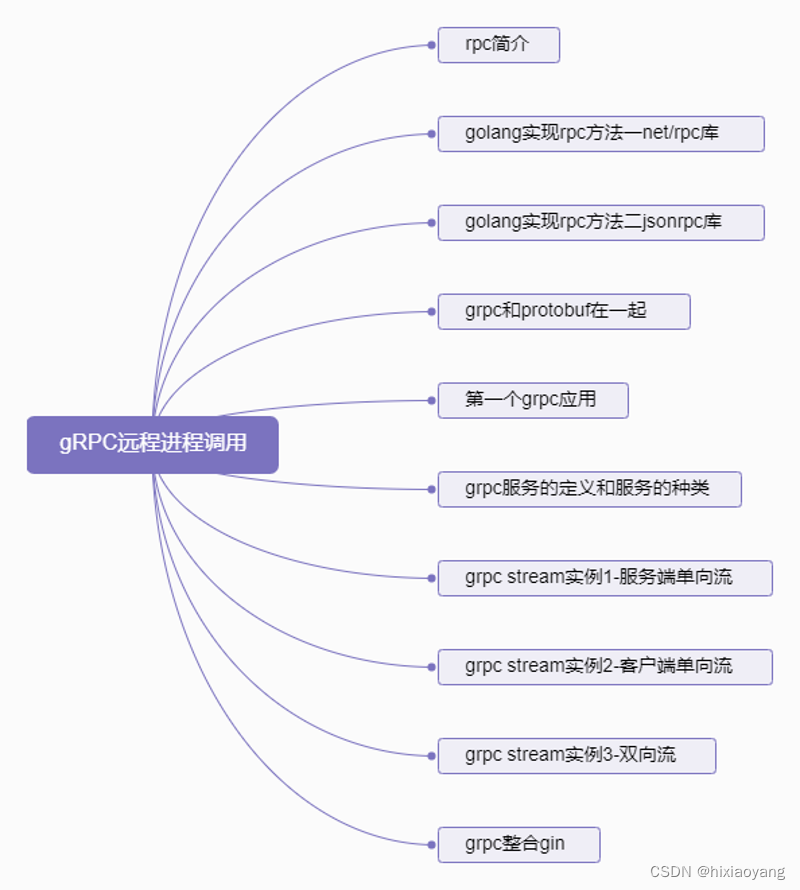
gRPC远程进程调用
gRPC远程进程调用 rpc简介golang实现rpc方法一net/rpc库golang实现rpc方法二jsonrpc库grpc和protobuf在一起第一个grpc应用grpc服务的定义和服务的种类grpc stream实例1-服务端单向流grpc stream实例2-客户端单向流grpc stream实例3-双向流grpc整合gin...
什么是继承
提示:继承基础概念 文章目录 一、继承1.1 基础概念1.2 继承作用与继承方式1.2 继承中的隐藏1.3 类中构造、析构在继承方面知识1.4 继承知识拓展 一、继承 1.1 基础概念 继承机制是面向对象程序设计使代码可以复用的最重要的手段,它允许在保持原有类特性…...
QT连接数据库
目录 数据库 数据库基本概念 常用的数据库 SQLite3基础 SQLite特性: QT连接数据库 1.1 QT将数据库分为三个层次 1.2 实现数据库操作的相关方法 sql语句(常用) 1)创建表格 2)删除表格 3)插入记录 …...
navicat访问orcal数据库
1)因为不能直接访问服务器,所以通过中介进行了端口转发; 2)依然不能访问,提示netadmin权限什么错误; 3)下载了一个 PLSQL Developer 13.0.0.1883 版本,自带的instantclient 好像不…...

Linux中查找某路径下,包含某个字符串的所有文件
path表示需要查找的路径,string表示需要包含的字符\字符串 grep -rnw path -e "string"只查找包含特定string的所有.c和.h文件 grep --include\*.{c,h} -rnw -rnw path -e "string" 除去所有.o文件,查找其他文件是否包含特定strin…...
的原理解析与C语言实现)
常见信号滤波方法(卡尔曼滤波、滑动平均、异常值剔除)的原理解析与C语言实现
常见信号滤波方法(卡尔曼滤波、滑动平均、异常值剔除)的原理解析与C语言实现 日期作者版本备注2023.09.04Dog TaoV1.0完成文档的初始版本。 文章目录 常见信号滤波方法(卡尔曼滤波、滑动平均、异常值剔除)的原理解析与C语言实现前…...
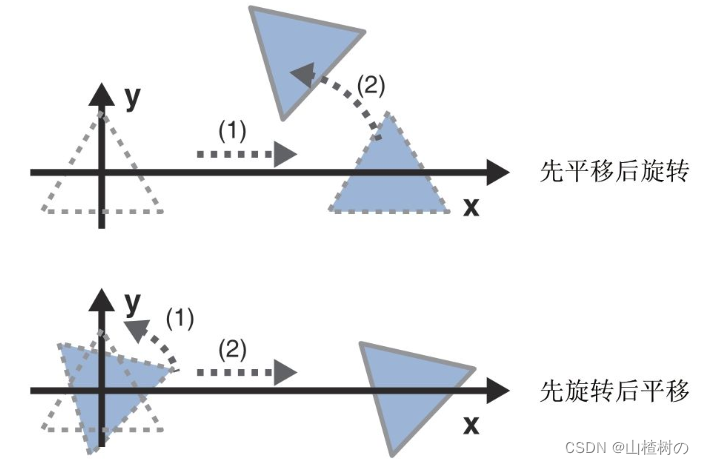
WebGL模型矩阵
前言:依赖矩阵库 WebGL矩阵变换库_山楂树の的博客-CSDN博客 先平移,后旋转的模型变换: 1.将三角形沿着X轴平移一段距离。 2.在此基础上,旋转三角形。 先写下第1条(平移操作)中的坐标方程式。 等式1&am…...

Flutter:WebSocket封装-实现心跳、重连机制
前言Permalink Flutter简介 Flutter 是 Google推出并开源的移动应用开发框架,主打跨平台、高保真、高性能。开发者可以通过 Dart语言开发 App,一套代码同时运行在 iOS 和 Android平台。 Flutter提供了丰富的组件、接口,开发者可以很快地为 F…...

c语言中:struct timespec
在C语言中,struct timespec 是一个结构体,通常用于处理时间和时间间隔。这个结构体通常包含以下两个成员: tv_sec:这是一个长整型(long),用于存储秒数。它表示时间的整数部分,即秒数…...
Mendix如何实现导出文件
刚刚接触Mendix低代码两周,花了一周在b站看初级视频然后考完初级,第二周开始做个列表查询感觉照葫芦画瓢没啥难度。但最近要求写个导出列表数据,在mendix社区翻了翻,这个功能算是常见的。找了mendix官方提供的Docs磕磕盼盼才实现了…...

JetBrains IDE 试用期重置指南:3种简单方法恢复30天免费使用
JetBrains IDE 试用期重置指南:3种简单方法恢复30天免费使用 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在紧张的项目开发中,突然发现你的 JetBrains IDE(如 Int…...

洛谷 B4358:[GESP202506 三级] 奇偶校验 ← 位运算
【题目来源】 https://www.luogu.com.cn/problem/B4358 【题目描述】 数据在传输过程中可能出错,因此接收方收到数据后通常会校验传输的数据是否正确,奇偶校验是经典的校验方式之一。 给定 n 个非负整数 c1,c2,…,cn 代表所传输的数据,它们…...

抖音批量下载助手:5分钟学会个人主页视频一键批量保存完整指南
抖音批量下载助手:5分钟学会个人主页视频一键批量保存完整指南 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 在当前短视频盛行的时代,抖音作为内容创作的宝库,汇聚了海…...

泉州某卫浴GEO优化实战:四标融合+场景化方法论,从搜索不可见到AI优先引用
我们在服务制造业企业的过程中发现一个根本性变化:过去大家关心“怎么让用户搜到我”,现在AI直接生成答案,企业真正的挑战变成了“怎么让AI准确信任我、优先引用我”。传统SEO在AI的“黑箱”面前越来越失效,企业必须重新建立一套可…...

STM32F103C8T6最小系统板避坑指南:从ST-LINK接线到Keil5乱码,新手必看的5个实战问题
STM32F103C8T6最小系统板避坑指南:从ST-LINK接线到Keil5乱码,新手必看的5个实战问题 第一次点亮STM32开发板的LED时,那种成就感就像电子工程师的"成人礼"。但通往成功的路上往往布满荆棘——接错一根线可能导致整晚的调试失败&…...

从 XChat 到超级 APP 生态:小程序生态为什么成为了超级APP的最佳技术选型
2026年4月17日,XChat 正式登陆苹果 App Store。 马斯克一直想做一个美国版的微信的目标已经实现:端对端加密、无广告、无追踪,注册只需要一个 X 账号,不需要手机号。马斯克给它的目标也很直接——X 要从社交平台,变成「…...
详解:终于搞懂管道、消息队列、共享内存到底在干什么)
Linux 进程间通信(IPC)详解:终于搞懂管道、消息队列、共享内存到底在干什么
很多人第一次学 Linux 进程间通信(IPC)时,都会有一种感觉:概念很多 API 很杂 学完还是不知道到底什么时候该用什么最容易出现的问题是:管道和消息队列有什么区别?为什么共享内存最快?信号量到底…...

Windows HEIC缩略图插件:为什么你的iPhone照片在Windows上无法预览?
Windows HEIC缩略图插件:为什么你的iPhone照片在Windows上无法预览? 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumb…...

终极免费macOS应用清理工具:让你的Mac告别数字垃圾
终极免费macOS应用清理工具:让你的Mac告别数字垃圾 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经遇到过这样的困扰:明明…...

【紧急预警】NotebookLM 2.3版本将关闭本地PDF语义隔离模式——社会科学研究者必须在48小时内完成知识库迁移
更多请点击: https://kaifayun.com 第一章:NotebookLM 2.3版本语义隔离模式终止的技术动因与社会科学研究范式冲击 语义隔离模式终止的核心技术动因 NotebookLM 2.3 版本正式移除了“语义隔离(Semantic Isolation)”模式&#x…...