解码自我注意的魔力:深入了解其直觉和机制
一、说明
自我注意层提供了一种捕获顺序数据(如时间序列)中的依赖关系的有效方法。使用自我注意进行时间序列/序列分析背后的关键直觉在于它能够为输入序列中的不同步骤分配不同的重要性权重,使模型能够专注于输入中最相关的部分以进行预测。
内容
- 它是如何工作的?简化的理解方式
- 自我注意的数学
- 位置编码
- 计算权重背后的直觉
- 查询、键和值
- 注意力层输入:词嵌入
- 多头注意力
- 自我注意,RNN,1D CONV
- 变压器型号
二、它是如何工作的?一种简化的理解方式。
以下是理解它的简化方法:
- 捕获长期依赖关系:传统的序列模型,如递归神经网络(RNN)及其变体(如LSTM和GRU),有时会由于梯度消失等问题而难以解决长期依赖关系。然而,自我注意可以捕获序列中任何两点之间的依赖关系,无论它们的距离如何。这种能力在时间序列分析中特别有价值,因为过去的事件,即使是遥远的过去事件,也可以影响未来的预测。
- 加权重要性:自我注意计算一个权重,该权重表示特定时间步长的其他时间步长的重要性或相关性。例如,在股票价格的时间序列中,模型可以学习更多地关注与重大市场事件相对应的时间步长。
- 并行化:与按顺序处理数据的 RNN 不同,自我注意力同时对整个序列进行操作,允许并行计算。这使得它在处理大型时间序列时更快、更高效。
- 可解释性:自我注意层可以提供一种形式的可解释性,因为注意力权重可以深入了解模型认为对每个预测重要的时间步长。
三、自我注意的数学
在注意力机制中,给定一组向量值和一个向量查询,注意力根据查询和一组键向量计算值的加权和。查询、键和值都是向量;它们的维数是模型的一个参数,它们都是在训练过程中学习的。
变形金刚中使用的特定注意力类型称为缩放点积注意力。以下是它的工作原理:
- 计算注意力分数:对于每个查询和键对,计算查询和键的点积。这将生成一个表示查询和键之间的“匹配”的数字。这是对所有查询键对完成的。
- 比例分数:然后通过将其除以查询/键向量维度的平方根来缩放分数。这样做是为了防止点积随着维数的增加而变得太大。
- 应用 softmax:接下来,将 softmax 函数应用于每个查询的这些缩放分数。这可确保分数为正且总和为 1。这使得它们可以用作加权总和的权重。
- 计算输出:最后,每个查询的输出计算为值向量的加权和,使用 softmax 输出作为权重。
在数学上,它可以表示如下:
注意 (Q, K, V) = SoftMax((QKT) / sqrt(dk)) V
这里:
- Q 是查询矩阵。
- K 是键的矩阵。
- V 是值的矩阵。
- dk 是查询/键的维度。
- 运算 QK^T 表示 Q 的点积和 K 的转置。
此过程针对输入序列中的每个位置执行,允许每个位置以加权方式关注所有其他位置,权重由查询和每个键之间的兼容性确定。

四、位置编码
位置编码是一种技术,用于为模型提供有关句子中单词相对位置的一些信息。
变压器基于自我注意机制,它本质上不考虑句子中单词的顺序。这与 RNN 或 LSTM 等模型不同,后者按顺序处理输入,因此自然地合并单词的位置。
位置编码在传递到自我注意层之前被添加到输入嵌入(表示单词)中。位置编码是对句子中单词的位置进行编码的向量。这些向量的设计方式使模型可以轻松地学习根据单词之间的距离来关注单词。
位置编码的确切形式可能会有所不同。在原始变压器模型中,位置编码是使用涉及正弦和余弦函数的特定公式创建的。但是,其他形式的位置编码(例如学习的位置编码)也是可能的。
在图中,位置编码表示为输入嵌入之后的单独步骤,但在实践中,位置编码通常在传递到自我注意层之前添加到嵌入中。
五、计算权重背后的直觉
在自我注意机制中,步骤的重要性与该步骤的内容有着内在的联系。例如,考虑在自然语言处理任务中使用自我注意力的转换器体系结构。该模型为输入中的每个单词计算一组注意力分数(步骤的“重要性”),这些分数指示在将当前单词编码为上下文相关表示时应考虑多少其他单词。
自我注意机制本质上考虑了整个输入序列,并根据每个单词的语义和句法关系确定每个单词对当前单词的重要性。此关系是通过计算查询向量(表示当前单词)和键向量(表示另一个单词)的点积来确定的。然后是 SoftMax 操作,以确保所有注意力分数的总和为 1。
这些查询、键(和值)向量是在训练过程中学习的,因此一个单词的重要性(及其与另一个单词的关系)可以根据使用它的上下文而变化。注意力权重实质上在输入序列上形成一个分布,表示在对当前单词进行编码时哪些单词是重要的。因此,学习的重要性权重(注意力分数)确实与内容相关,并与特定单词相关联。每个单词的上下文(即它与序列中其他单词的关系)决定了模型在对序列中的不同单词进行编码时对该单词的关注程度。例如,如果你正在处理句子“黑色的猫坐在垫子上”,那么在编码单词“cat”时,自我注意机制可能会为“黑色”和“sat”分配高注意力分数,表明这些单词对于理解此句子中“cat”的上下文很重要。
六、查询、键和值
通过乘以训练期间学习的三个不同的权重矩阵,将层的输入转换为查询、键和值向量。查询和关键向量用于计算注意力分数,这些分数确定对输入的每个部分的关注程度。然后使用值向量创建基于这些分数的加权组合。这种加权组合是自我注意层的输出。
注意力机制中的键和值向量派生自输入嵌入,并且两者都扮演着不同的角色:
- 关键向量 (K):关键向量用于计算注意力分数。在句子或序列的上下文中,它们代表单词的“上下文身份”,用于注意力评分。句子中的每个单词都与一个键相关联,该键用于通过查询计算点积以计算注意力分数。此分数反映了与该键关联的单词与查询所表示的单词的相关性。
- 值向量 (V):值向量用于将 SoftMax 函数应用于注意力分数后的加权和的计算。它们是平均在一起形成注意力层输出的东西。在某种程度上,您可以将价值向量视为由注意力分数加权的“内容”。
本质上,键用于确定“如何注意”,即它们计算与查询的兼容性分数,值用于确定“要注意什么”,即它们有助于基于注意力分数的最终输出。
在句子中,为每个单词计算一个查询、一个键和一个值。特定单词的查询与所有键(包括其自身)交互以计算注意力分数,然后用于对值进行加权。
例如,如果我们有句子“猫坐在垫子上”,在处理单词“sat”时,模型将使用与“sat”关联的查询,并使用与“The”、“cat”、“sat”、“on”、“the”和“mat”关联的键计算其点积。这将导致注意力分数,表示模型在尝试理解“sat”的含义时应该关注这些单词中的每一个。然后使用这些分数对与每个单词关联的值向量进行加权,并将它们相加以产生输出。
请务必注意,查询、键和值未显式链接到特定字词或含义。它们是在训练期间学习的,模型确定如何最好地使用它们来完成训练的任务。
七、注意力层输入:词嵌入
在机器学习中,模型不会像人类那样“理解”或“记住”单词。相反,它们以数字表示单词并学习这些表示中的模式。有多种方式可以对单词进行数字表示,例如单词袋、TF-IDF 和单词嵌入。
深度学习模型中最常见的方法,如变形金刚,是使用词嵌入。以下是其工作原理的简化说明:
- 词嵌入:词汇表中的每个单词都映射到实数向量,形成其词嵌入。此向量通常有几百维长。这些向量最初是随机分配的。
- 上下文学习:在训练期间,模型根据每个单词出现的上下文调整单词嵌入。经常出现在类似上下文中的单词将具有类似的嵌入。因此,例如,“猫”和“小猫”最终可能会有类似的嵌入,因为它们都经常用于关于宠物的句子中。
- 反向传播和优化:学习是通过称为反向传播的过程完成的。该模型根据当前嵌入进行预测,然后计算这些预测与实际值之间的误差。然后,此错误用于调整嵌入,以使预测更接近实际值。
- 捕获含义:随着时间的推移,这些单词嵌入开始捕获语义和句法含义。例如,模型可能会了解到“猫”和“狗”彼此更相似(两者都是宠物),而不是“猫”和“汽车”。
在像变形金刚这样的自我注意模型中,这些单词嵌入然后作为自我注意层的输入,其中不同单词之间的关系被进一步建模。每个单词不仅由其自己的嵌入表示,而且还受到句子中与之交互的单词嵌入的影响,从而允许每个单词的丰富,上下文相关的表示。
重要的是要注意,该模型不会像人类那样“理解”单词。它不知道猫是一种小型的、典型的毛茸茸的、驯化的、肉食性的哺乳动物。它只知道它学到的数字表示和这些数字中的模式。它学习的语义关系纯粹基于它所训练的数据中的模式。
八、多头注意力
多头注意力是转换器模型架构的关键组件,用于允许模型专注于不同类型的信息。
多头注意力背后的直觉是,通过多次并行应用注意力机制(这些并行应用是“头”),模型可以捕获数据中不同类型的关系。
每个注意力头都有自己的学习线性转换,它应用于输入嵌入以获取其查询、键和值。因为这些转换是分开学习的,所以每个头都有可能学会专注于不同的事情。在自然语言处理的背景下,这可能意味着一个头学会注意句法关系(如主谓一致),而另一个头可以学习关注语义关系(如单词同义词或主题角色)。
例如,在处理句子“猫坐在垫子上”时,一个注意力头可能会关注“猫”和“坐着”之间的关系,捕捉猫是坐着的人的信息,而另一个头可能更关注“坐”和“垫子”之间的关系,捕捉关于坐在哪里发生的信息。
然后,所有头部的输出被串联并线性变换,形成多头注意力层的最终输出。这意味着每个头部捕获的不同类型的信息被组合在一起,形成一个统一的表示。
通过使用多个磁头,Transformers允许对输入进行比单一注意力机制应用更复杂和细致的理解。这在一定程度上有助于提高它们在广泛任务上的效力。
没有一种直接的机制可以确保每个注意力头在训练期间学习不同的东西。相反,这种行为自然地出现在训练过程的随机(随机)性质以及每个注意力头以不同的随机初始化参数开始的事实中。
原因如下:
- 随机初始化:神经网络中的权重通常使用较小的随机值进行初始化。由于每个注意力头都有自己的一组权重,因此它们从重量空间的不同位置开始。
- 随机梯度下降:神经网络通常使用随机梯度下降的变体进行训练。这包括向模型显示一小批随机选择的训练数据,计算模型在此批次上产生的误差,以及调整模型的权重以减少此错误。由于选择这些批次涉及随机性,每个头可能会在数据中看到略有不同的模式,从而导致他们学习不同的东西。
- 反向传播:在反向传播期间,由于初始参数和学习过程的性质不同,每个磁头都会接收不同的误差信号(梯度)。这些不同的错误信号将每个头部的重量推向不同的方向,进一步鼓励他们学习不同的东西。
然而,值得注意的是,上述因素只会让每个头脑都倾向于学习不同的东西。不能保证。在实践中,一些头部可能会学习类似甚至多余的表示。这是深度学习领域正在进行的研究领域,提出了各种正则化技术,以鼓励每个头部学习的表示更加多样化。
此外,虽然目标是让不同的负责人学习数据的不同方面,但重要的是他们都学习对手头任务的有用信息。因此,这是鼓励多样性和确保每个头部都为模型的整体性能做出贡献之间的平衡。
九、自我注意,RNN,1D CONV
9.1 自我关注
优点:自我注意,特别是以转换器模型的形式,允许并行计算,这大大加快了训练速度。它还捕获元素之间的依赖关系,而不管它们在序列中的距离如何,这对许多 NLP 任务都是有益的。
缺点:自注意相对于序列长度具有二次计算复杂性,这可能使其对于非常长的序列效率低下。此外,它本身不会捕获序列中的位置信息,因此需要位置编码。
应用:自我注意广泛用于NLP任务,如翻译,总结和情感分析。基于自我注意的变压器模型是BERT,GPT和T5等模型的基础。
计算需求:由于其二次复杂性,自我注意需要更多的内存,但它允许并行计算,这可以加快训练速度。
9.2 RNN
优点:RNN 擅长处理序列,可以捕获序列中接近的元素之间的依赖关系。它们也相对简单,并且已广泛使用多年。
缺点:RNN存在消失和爆炸梯度问题,这使得它们难以在长序列上进行训练。它们还按顺序处理序列,这会阻止并行计算并减慢训练速度。
应用:RNN 用于许多 NLP 任务,包括语言建模、翻译和语音识别。
计算需求:RNN的内存要求低于自我注意,但它们无法并行处理序列使得训练速度变慢。
9.3 转换1D
优点:Conv1D 可以捕获本地依赖关系,并且比 RNN 更有效,因为它允许并行计算。它也不太容易出现消失和爆炸梯度问题。
缺点:Conv1D具有固定的感受野,这意味着它可能无法捕获长期依赖关系以及自我注意或RNN。它还需要仔细选择内核大小和层数。
应用:Conv1D 通常用于涉及时间序列数据的任务,例如音频信号处理和物联网数据中的异常检测。在 NLP 中,它可用于文本分类和情感分析。
计算需求:在内存和计算方面,Conv1D 比 RNN 和自我注意力更有效,特别是对于涉及本地依赖的任务。
十、变压器型号
Vaswani等人在论文“注意力是你所需要的一切”中介绍的变压器模型由编码器和解码器组成,每个解码器都由一堆相同的层组成。反过来,这些层主要由两个子层组成:多头自注意力机制和位置全连接前馈网络。
让我们回顾一下每个组件:
- 多头自注意力机制:自我注意机制允许模型根据输入序列中不同单词与当前正在处理的单词的相关性对其进行权衡和编码。多头注意力允许模型捕获单词之间的不同类型的关系(例如,句法、语义)。
- 按位置全连接前馈网络:这是一个标准的前馈神经网络,可独立应用于每个位置。它用于转换自我注意层的输出。虽然自我注意层帮助模型理解单词之间的上下文关系,但前馈网络帮助模型了解单词本身。
- 残差连接和层归一化:变压器层中的两个子层(自注意和前馈)中的每一个都有围绕它的残差连接,然后是层归一化。这有助于缓解梯度消失问题,并使模型在堆叠到深度架构中时能够得到有效训练。
-

变压器层的体系结构。具有可训练参数的图层以橙色显示
堆叠多个 Transformer 层背后的关键直觉与任何深度学习模型相同:模型中的每一层都有可能学习捕获不同级别的抽象。在语言的上下文中,较低层可能会学习理解简单的句法结构,而较高层可能会学习理解更复杂的语义。
例如,在句子“黑白相间的猫坐在垫子上”中,较低层可能侧重于理解相邻单词之间的局部关系,而较高层可能会学习理解句子的整体结构以及“黑与白”提供有关“猫”的额外信息的事实。
法尔扎德·卡拉米
相关文章:
解码自我注意的魔力:深入了解其直觉和机制
一、说明 自我注意机制是现代机器学习模型中的关键组成部分,尤其是在处理顺序数据时。这篇博文旨在提供这种机制的详细概述,解释它是如何工作的,它的优点,以及它背后的数学原理。我们还将讨论它在变压器模型中的实现和多头注意力的…...

mysql之存储引擎
目录 存储引擎概念 MyISAM MyISAM特点 MyISAM 表的存储格式 MyISAM适用的生产场景 InnoDB InnoDB特点 选择存储引擎依据 MyISAM 和 INNODB区别 命令 查看系统支持的存储引擎 查看表使用的存储引擎 修改存储引擎 存储引擎概念 MySQL中的数据用各种不同的技术存…...
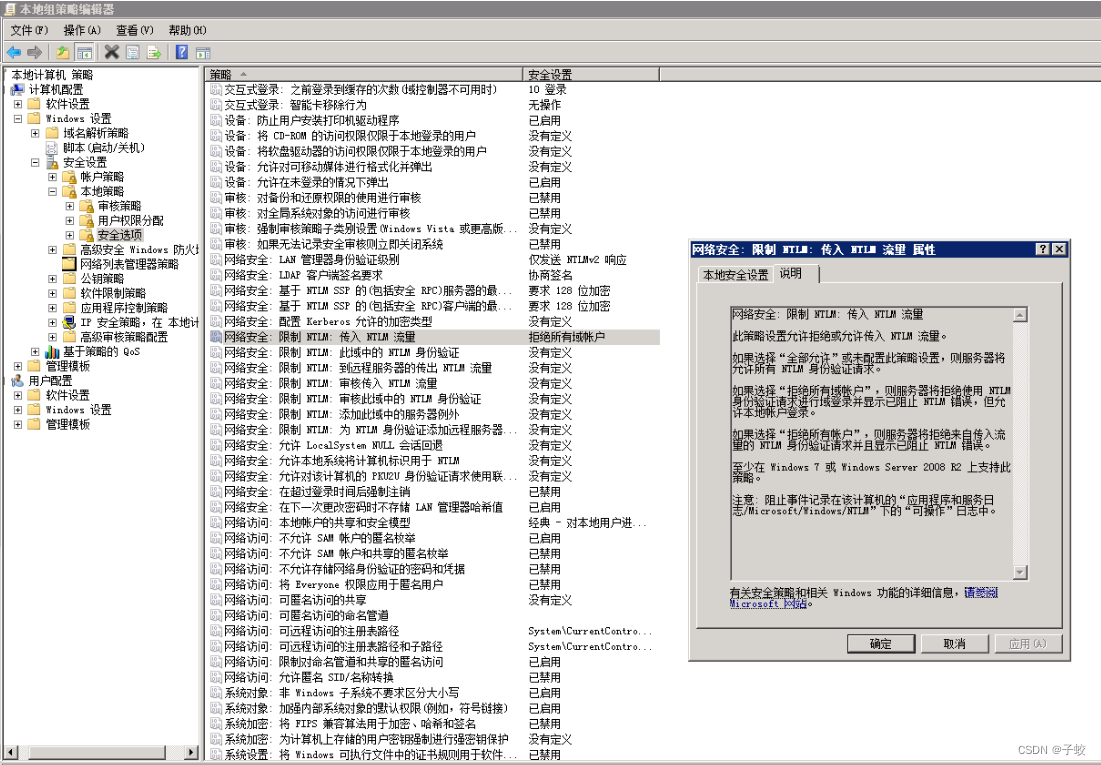
服务器日志出现大量NTLM(NT LAN Manager)攻击
日志名称:Security 来源: Microsoft-Windows-Security-Auditing 日期: 2023/8/30 20:57:40 事件 ID:4625 任务类别:登录 级别: 信息 关键字: 审核失败 用户: 暂缺 计算机: WIN-QBJ3ORTR0CF 描述: 帐户登录失败。 主题: 安全 ID:NULL SID 帐户名:- 帐户域:- …...
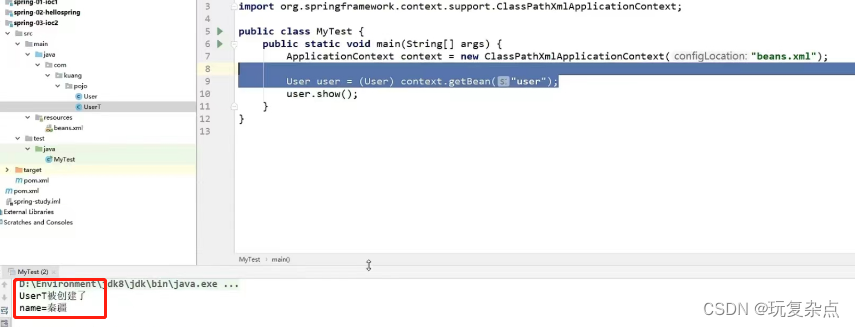
Spring学习|Spring简介、IOC控制反转理解、IOC创建对象方式
Spring Spring:春天------>给软件行业带来了春天! 2002,首次推出了Spring框架的雏形: interface21框架! Spring框架即以interface21框架为基础,经过重新设计,并不断丰富其内涵,于2004年3月24日发布了1.0正式版。 RodJohnson,Spring Framework创始人&…...
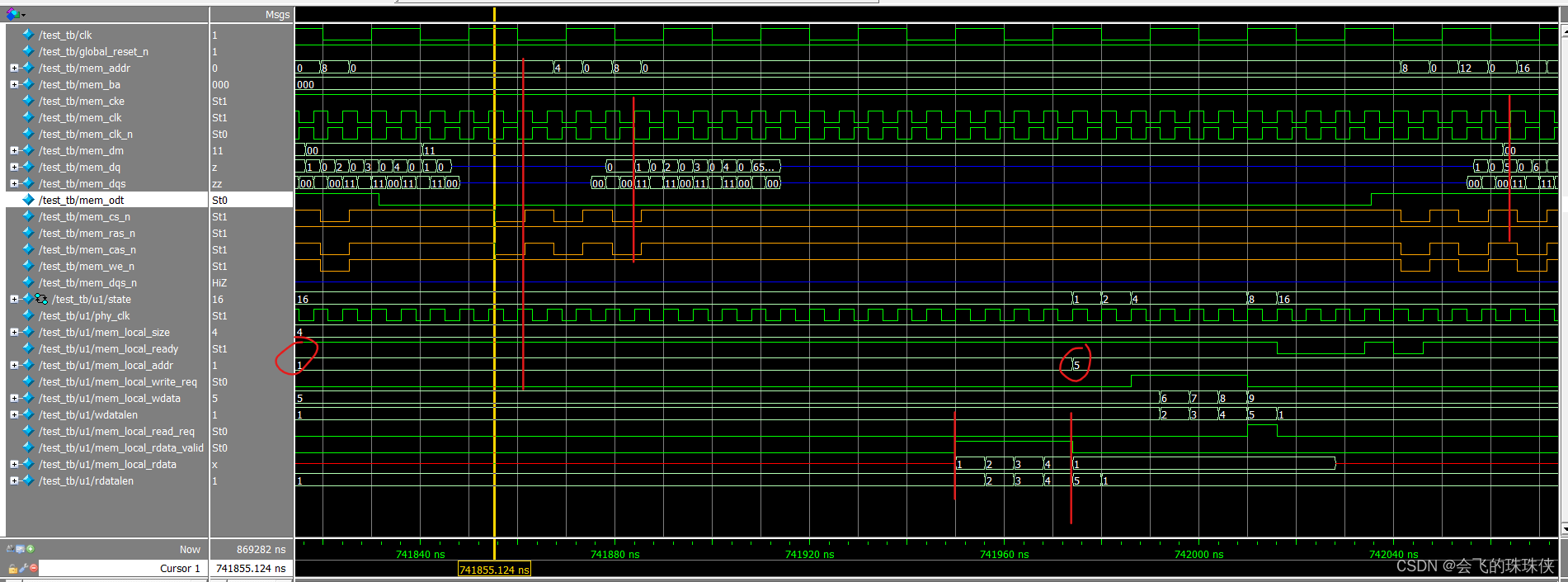
DDR2 IP核调式记录2
本文相对简单,只供自己看看就行。从其它的博客找了个代码,然后记录下仿真波形。 1. 功能 直接使用quartus生成的DDR2 IP核,然后实现循环 -->写入burst长度的数据后读出。 代码数据的传输是32位,实际使用了两片IC。因此IP核也是…...

【ES6】js 中class的extends、super关键字用法和避坑点
在JavaScript中,使用class关键字可以实现面向对象编程。其中,extends和super是两个非常重要的关键字,它们分别用于实现类的继承和调用父类的方法。 一、extends关键字 extends关键字用于实现类的继承,它可以让一个子类继承父类的…...
over(order by)和with * as 的用法)
mysql排名函数row_number()over(order by)和with * as 的用法
601. 体育馆的人流量(力扣mysql题,难度:困难) 表:Stadium ------------------------ | Column Name | Type | ------------------------ | id | int | | visit_date | date | | people | int | ------------------------vis…...

linux局域网IP地址冲突检测
使用keepalived设置vip的时候,发现vip无法连接,经查是出现了ip地址冲突,使用了一个在用的ip作为了vip,但是这个ip其实ping不通,因为目标机禁用了ping,也即是丢弃了ICMP包。 一、那么怎么检测IP地址是否已经…...

远距离WiFi模组方案,实现移动设备之间高效通信,无人机远程图传应用
随着科技的不断进步,无线通信技术也在日新月异地发展。其中,WiFi技术已经成为现代生活中不可或缺的一部分。 从室内到室外,WiFi的应用场景正在不断扩大,为我们的日常生活和工业生产带来了极大的便利。 WiFi技术,即无…...

Docker构建Springboot项目,并发布测试
把SpringBoot项目打包成Docker镜像有两种方案: 全自动化:先打好docker镜像仓库,然后在项目的maven配置中配置好仓库的地址,在项目里配置好Dockerfile文件,这样可以直接在idea中打包好后自动上传到镜像仓库,…...
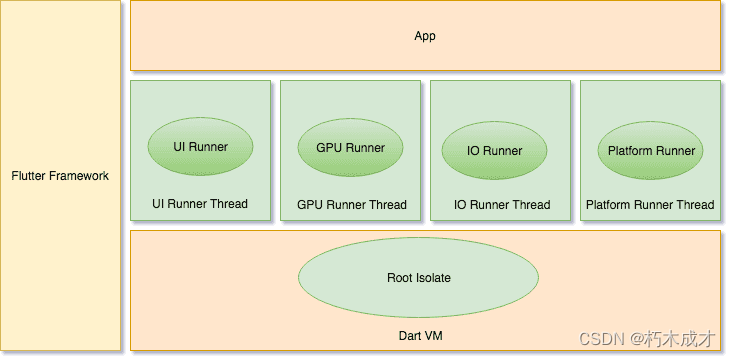
flutter架构全面解析
Flutter 是一个跨平台的 UI 工具集,它的设计初衷,就是允许在各种操作系统上复用同样的代码,例如 iOS 和 Android,同时让应用程序可以直接与底层平台服务进行交互。如此设计是为了让开发者能够在不同的平台上,都能交付拥…...
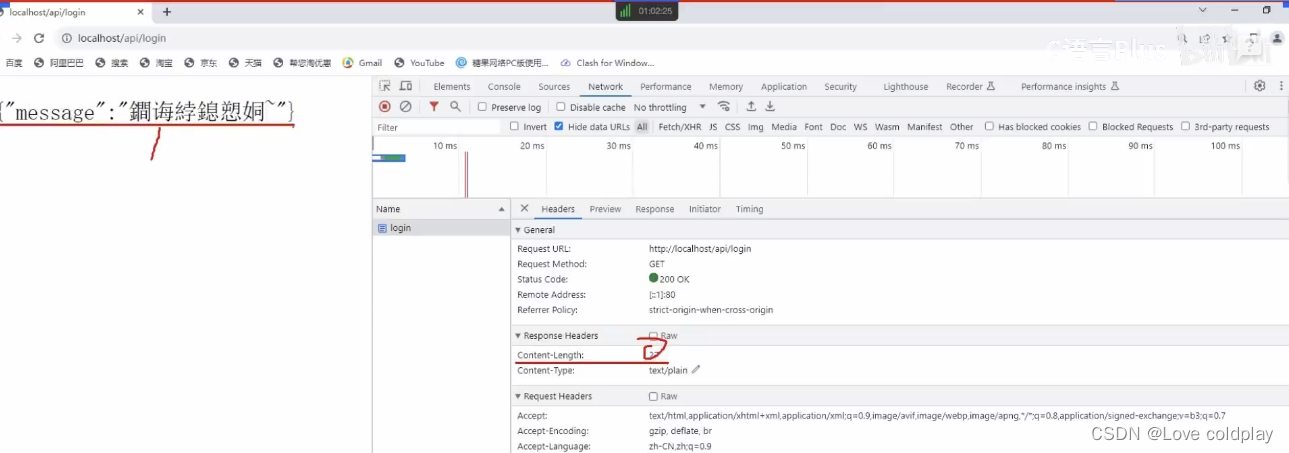
QHttpServer
QLineEdit-----输入提示 改动CmakeLists.txt 在帮助–索引查找QHttpServer 改动CmakeLists.txt,有三处改动 在谷歌浏览器测试,输入127.0.0.1/api/login 测试代码 #include<QCoreApplication> #include <QHttpServer> //http服务器 int m…...
21.3 CSS 背景属性
1. 背景颜色 background-color属性: 设置元素的背景颜色. 它可以接受各种颜色值, 包括命名颜色, 十六进制颜色码, RGB值, HSL值等.快捷键: bctab background-color:#fff;<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"…...

Ansible 常用命令50条
以下是 Ansible 常用的 50 条命令: ansible --version: 查看 Ansible 版本信息。ansible all -m ping: 检查所有主机的连通性。ansible-playbook playbook.yml: 运行指定的 Ansible Playbook 文件。ansible-doc module_name: 查看指定模块的帮助文档。ansible-conf…...

ceph源码阅读 erasure-code
1、ceph纠删码 纠删码(Erasure Code)是比较流行的数据冗余的存储方法,将原始数据分成k个数据块(data chunk),通过k个数据块计算出m个校验块(coding chunk)。把nkm个数据块保存在不同的节点,通过n中的任意k个块还原出原始数据。EC包含编码和解…...

C++ 之 命名空间
namespace_百度百科,有示例...

MyBatis关系映射
文章目录 前言一、一对一映射1.1 创建实体1.2 xml配置 二、一对多映射2.1 创建实体2.2 resultMap配置2.3 测试 三、 多对多映射3.1 创建实体3.2 resultMap配置3.3 测试 前言 MyBatis是一个Java持久化框架,它提供了一种将数据库表和Java对象之间进行关系映射的方式。…...
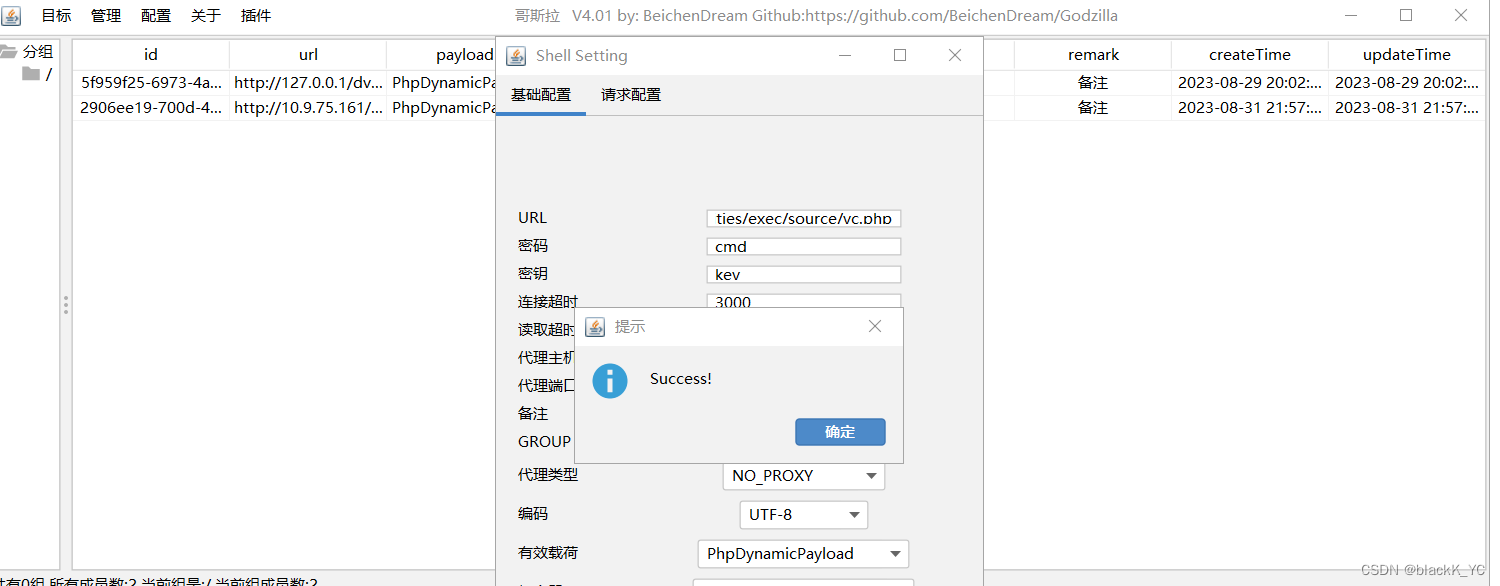
DVWA失效的访问控制
失效的访问控制,可以认为是系统对一些功能进行了访问或权限限制,但因为种种原因,限制并没有生效,造成失效的访问控制漏洞,比如越权等 这里以DVWA为例,先访问低难度的命令执行并抓包 删除cookie,并在请求头…...
docker 笔记2 Docker镜像和数据卷
参考: 1.镜像是什么?(面试题) 是一种轻量级、可执行的独立软件包,它包含运行某个软件所需的所有内容,我们把应用程序和配置依赖打包好形成一个可交付的运行环境(包括代码、运行时需要的库、环境变量和配置文…...

java springboot 时间格式序列化 UTC8
背景 我们在项目中使用序列化和反序列化组件中,默认一般采用Jackson,如果遇到特殊配置,我们该怎么配置呢,大致有如下两种方式:采用配置文件【application.yml】和代码配置 配置文件 比如添加jackson节点 spring:jac…...

Arm LUTI指令解析:向量化查找表优化实战
1. Arm LUTI指令深度解析:多寄存器查找表操作实战指南在Armv9架构的SME2扩展中,LUTI(Lookup Table Indexed)系列指令为向量化查找表操作提供了硬件级支持。这类指令通过ZT0寄存器存储查找表数据,利用源向量寄存器中的索…...

Analog Discovery 2:口袋实验室如何用FPGA重塑硬件调试体验
1. 口袋里的实验室:为什么我们需要Analog Discovery 2?作为一名在硬件开发一线摸爬滚打了十多年的工程师,我太熟悉那种面对复杂项目时,被实验室设备“卡脖子”的窘迫感了。你想验证一个想法,或者排查一个棘手的信号问题…...

慕尼黑电子展深度攻略:从技术侦察到资源对接的实战指南
1. 展会项目概述与核心价值解析又到了一年一度的行业盛会密集期,对于身处电子、嵌入式、物联网这些硬科技赛道的从业者来说,参加一场高质量的线下展会,其价值远不止是“逛一逛”那么简单。它更像是一次集中的行业体检、一次高效的技术社交和一…...

STM32H7网络延迟问题分析与解决方案
1. 问题现象与背景分析最近在将STM32H7系列设备的DFP(Device Family Pack)从v2.2.0升级到v2.3.0版本后,不少开发者反馈网络数据传输出现了明显的延迟问题。通过简单的ping测试可以直观观察到,使用v2.3.0版本的往返时间(RTT)相比v2…...

【亲测免费】 STM32F103CAN双机通信程序
STM32F103CAN双机通信程序 【下载地址】STM32F103CAN双机通信程序 本项目是专为嵌入式开发者设计的,特别是针对那些对STM32微控制器及CAN总线通信协议感兴趣的开发者。STM32F103系列芯片以其高性能、低功耗的特点广泛应用于工业控制、汽车电子等领域。此份资源集合了…...
)
TVA智能体范式的工业视觉革命(7)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

白盒测试覆盖题
先贴完整逻辑代码java运行if (温度 < 高温值 && 温度 > 低温值) {显示正常温度; // 分支1 } else {if (温度 > 高温值) {高温报警; // 分支2} else {低温报警; // 分支3}蜂鸣警报; // 分支4 }先定义 3 个条件A:温度<高温值B&am…...

Freeplane思维导图模板:如何10分钟创建专业级思维导图的终极解决方案
Freeplane思维导图模板:如何10分钟创建专业级思维导图的终极解决方案 【免费下载链接】Freeplane-MindMap-Template Freeplane-MindMap-Template(Freeplane 思维导图模板) 项目地址: https://gitcode.com/gh_mirrors/fr/Freeplane-MindMap-…...

KMS_VL_ALL_AIO:三步实现Windows和Office永久激活的完整指南
KMS_VL_ALL_AIO:三步实现Windows和Office永久激活的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出的激活提醒而烦恼吗?Office文档突…...

移动魔百盒CM101s刷机后体验:告别卡顿,解锁安装自由,这存储空间真香!
移动魔百盒CM101s焕新体验:从卡顿到流畅的全方位升级 每次打开电视都要忍受漫长的加载等待,存储空间不足导致无法安装新应用,系统自带功能单一无法满足全家需求——这或许是许多移动魔百盒CM101s用户的共同困扰。经过一周的深度使用测试&…...