ChatGPT追祖寻宗:GPT-1论文要点解读
论文地址:《Improving Language Understanding by Generative Pre-Training》
最近一直忙着打比赛,好久没更文了。这两天突然想再回顾一下GPT-1和GPT-2的论文, 于是花时间又整理了一下,也作为一个记录~话不多说,让我们一起来品读一下GPT经典之作吧!
Abstract

摘要部分其实是介绍了一下GPT研究的动机,值得一提的是,GPT可以算是预训练+微调这种范式在NLP领域成功应用的先河,它比BERT还早几个月。摘要中提到,无标注数据是很多的,但是特定领域带标数据匮乏,这对于许多NLP任务中模型的训练是一个很大的挑战。 接下来作者提到了他们的解决方案:先在大规模无标注数据集上训练一个预训练模型,接着再将此预训练模型放到特定任务中用少量数据微调。这个方案放在现在来看,再熟悉不过了,但是在当时,这种方法确实是新颖之作,因为在此之前,利用无标注数据建模的先例有著名的Word2Vector,但具体到下游任务,基本上都是特定任务特别训练,这里作者也提到了,对比前人的工作,他们方法的不同之处在于微调的时候直接构造和任务相关的输入进行的,换句话说,直接从输入形式来区分不同的任务,这样一来,他们只需要对模型结构做微小的改动就能达到想要的效果。
1 Instruction
 第一段总结来说,作者提到了无监督训练方式的重要性,能够有效的从原始训练语料中(通常认为是无标注的)学习的能力可以减轻模型对于下游有监督训练的依赖性,作者认为,即使在可以进行有监督学习的场景下,使用无监督的方式学到很好的语言表征也会让模型的表现更好。这一点在近两年的许多研究成果中也得到了印证。
第一段总结来说,作者提到了无监督训练方式的重要性,能够有效的从原始训练语料中(通常认为是无标注的)学习的能力可以减轻模型对于下游有监督训练的依赖性,作者认为,即使在可以进行有监督学习的场景下,使用无监督的方式学到很好的语言表征也会让模型的表现更好。这一点在近两年的许多研究成果中也得到了印证。

这一段作者提到了从无标注数据中学习词级别信息是具有挑战性的,并且列举了产生挑战性的两点原因:
(1)优化目标不统一。也就是说,对于无监督训练来讲,可以设计出诸多不同的优化目标,但是究竟哪种类型的优化目标是有效的,目前还不清晰。显然,作者提了一个很好的问题,Bert、GPT、Bart、T5、XLNet等等,它们的建模过程都要经历无监督训练阶段,它们无监督预训练所设计的训练目标不尽相同,比如bert采用了LM和NSP的预训练方式,Bart去掉了NSP,还增加了文档旋转,子序列掩码等预训练方式,XLNet更是采用了类似排列组合的预训练方式,它们都不完全一样,也都取得了很好的效果。可是究竟哪一种或者哪几种方式才最有效,目前尚不清楚(截止该论文)。
(2)如何有效的将学习到的文本表示迁移到下游特定任务中目前业界还没有一个共识。说白了,就是目前业界还没有得出一个结论,什么结论呢?就是如何利用预训练语言模型进行下游任务的微调是最有效的,通常都需要根据不同下游任务做一些模型结构上的改动。
作者认为这两点不确定使得半监督学习技术的发展遇到了很大的困难,作者在这里提到了半监督学习,其实就是“无监督预训练+有监督微调”。

这段话其实阐述了一下作者提出的一种半监督学习方式,总的来说,他们的半监督学习方式虽然也是无监督预训练+下游微调两步走的方式,但是他们在下游微调任务上,采用的是带有手动注释(也就是提示)的样例学习来将无监督学习到的表示嵌入到不同的下游任务中。这就是后来的提示学习。

作者说明了一下模型架构的选择,之所以选择Transformer作为基模,作者认为,还是因为transformer强大的序列特征提取能力。这段没啥说的。

这一段其实就是作者说了一下他们的方法在几个NLP任务上的效果,在12个任务中有9个任务都达到了sota的效果。值得注意的是,作者提到了零样本学习,看来作者们在GPT-1的时候就已经在思考这一思路了,果然大牛都是提前布局。
2 Related Work
这一章节主要介绍了与作者所研究的相关的先前工作。它介绍了半监督学习在自然语言处理中的应用,并提到了使用无标签数据进行词级别和短语级别的统计计算以及使用词嵌入来改善性能的方法。此外,作者还提到了无监督学习是半监督学习的一种特殊情况,其目标是寻找一个好的初始化方法来避免对监督学习过程中的目标进行改动,简而言之就是,通过无监督学习的方法就能够使得文本表示很好的迁移到下游任务中,而不是来一个下游任务就设置一个学习目标,这太繁琐了。与其他方法相比,作者选择了Transformer模型,并使用任务特定的输入转换来适应不同的任务,以实现有效的迁移学习。
3 Framework
这一章节比较重要,主要介绍了论文核心思想的实现方法。
3.1 Unsupervised Pre-training

GPT-1的思路其实就是利用了语言模型的思路,语言模型是什么呢?它其实就是通过对先验知识的条件概率计算获得预测词的这么一个东西,如上述式子,在i-1个词的出现的情况下来计算第i个词出现的概率,因为这一过程是依靠神经网络来完成的,因此上式还有个θ。

了解transformer的原理后,上式其实就很好理解,先通过词向量和位置向量来构建模型的输入,transformer_block是指transformer的各个模块,包括自注意力层,归一化层等,经过transformer各个模块计算后,最后再通过softmax来计算输出的概率分布,值得注意的是,GPT系列的模型都只用了transformer的解码器部分,并非标准的transformer,不存在类似bert的那种掩码机制,而必须是单向输出的,所以GPT-1这里,作者在无监督预训练的时候用的是滑窗机制来计算语言模型的条件概率,个人感觉这种方式在训练样本足够大的情况下,效果会比“完形填空”形式的LM掩码机制要好,而且这种形式确实更适用于生成任务。
3.2 Supervised fine-tuning
这一节介绍的是有监督微调的过程。

输入经由预训练语言模型计算后,取最有一层的向量作为微调的输入,微调就是用一个线性层将输入映射到目标任务所需要的空间中。比如我们的输入是256个词,向量维度定义为768维,那么最终Transformer的输出就是256·768,但是我们只取最后一个维度作为一句话的向量表示,即1·768,假如是二分类问题,那么我们的线性层就是768·2,这样线性映射后我们得到了一个1·2大小的向量,再做softmax后,就能得到两个概率值[p1, p2],取最大的概率值对应的索引,就得到了我们的预测值。

这个公式其实是无监督预训练和有监督微调统一训练的方法,作者用了一个λ来调节两者的平衡。作者也提到了,将无监督语言模型的学习作为有监督学习的辅助学习目标会带来两个好处,一个是改善有监督学习的性能,一个是加速收敛。
无监督预训练和有监督的微调介绍完,作者贴上了一个图来说明他们是如何将输入转化为与下游具体任务相关的输入形式的。

左边是论文提到的模型结构图,右边是具体输入输出的结构,可以看到,不同任务的输入形式也不尽相同,除了单句分类任务,其它的都有固定格式:start、text1、text2、delim、extract。要注意,start、delim和extract在实际代码中是用某些特殊符号给予标记的,从而避免了训练语料中存在这些单词。
从上图中我们可以看到后起之秀bert的影子,在bert中,针对不同任务的微调的输入输出也是像这样构造的。
3.3 Task-specific input transformations
这一节其实就是对上图的进一步解释,感兴趣的照着图看就好,这里不作重点记录。
4 Experiments
这一章将实验部分,涉及到具体模型参数的设置以及数据部分,值得品读。
4.1 Setup


GPT-1用了BooksCorpus数据集进行无监督预训练的,同时,作为其它数据集的选择,GPT-1页使用了10亿个单词的Word Benchmark,这和ELMo这个模型使用的数据集类似,只不过本文的方法是打乱了句子破坏了句子的长距离结构。说实话,我们看懂,GPT-1是只用了前一个数据集,还是两个数据集都用了,还是分开用的?
 这一段是模型的参数设置,首先,前面提到过,GPT-1使用了transformer结构中的Decoder,是一个12层的解码器,解码器参数设置细节如下:
这一段是模型的参数设置,首先,前面提到过,GPT-1使用了transformer结构中的Decoder,是一个12层的解码器,解码器参数设置细节如下:
- 状态向量维度为768,注意力头数为12,这和bert是一样的。
- 在位置编码方面,使用了3072维的内部状态。
- 优化算法采用了Adam,并设置了最大学习率为2.5e-4。
- 学习率在前2000次更新中线性增加,然后使用余弦调度将其退火为0。
- 模型使用64个随机采样的连续序列的小批量数据进行训练,每个序列包含512个token。
- 模型中广泛使用了layernorm,因此简单的权重初始化N(0, 0.02)就足够了。
- 模型使用了40,000个合并的字节对编码(BPE)词汇表,并使用了残差、嵌入和注意力的dropout来进行正则化,失活率为0.1。
- 模型还使用了[37]中提出的修改版L2正则化,对所有非偏置或增益权重设置了w = 0.01。
- 激活函数使用了高斯误差线性单元(GELU)。
- 模型使用了学习的位置嵌入,而不是原始版本提出的固定正弦值。
- 使用了ftfy库来清理BooksCorpus中的原始文本,标准化一些标点符号和空白符,并使用spaCy分词器进行处理。
 这是微调阶段的一些参数设置,作者大部分复用了无监督预训练阶段的参数设置方式,只有几个不同的地方:大多数任务的学习率设置为6.25e-5,batchsize设为了32,基本上迭代个3个epoch足矣。 公式(5)中的λ设为0.5。
这是微调阶段的一些参数设置,作者大部分复用了无监督预训练阶段的参数设置方式,只有几个不同的地方:大多数任务的学习率设置为6.25e-5,batchsize设为了32,基本上迭代个3个epoch足矣。 公式(5)中的λ设为0.5。
4.2 Supervised fine-tuning
这一节主要是介绍了在几种不同任务上以及不同数据集上的实验测试和分析对比,结论是GPT-1在12种数据集中有9种数据集的表现达到了SOTA。这块内容不做重点介绍,感兴趣的可以自己看下。
5 Analysis

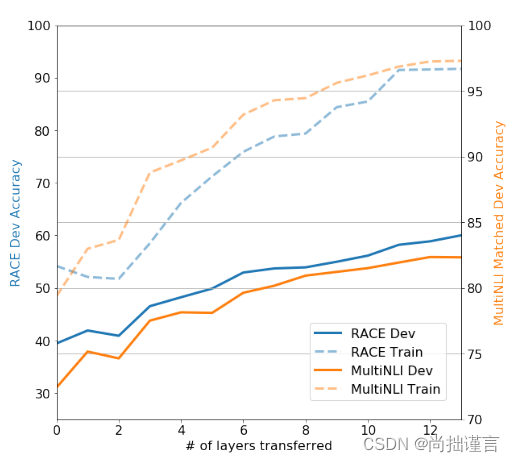
前面提到,GPT-1用了12层的transformer layer,作者在这里做了一个实验:层数从1-12增加,看看不同层数对于无监督预训练模型向有监督任务微调的迁移能力的影响,结果发现,12层中,每一层都对这种迁移能力的提升有正向作用。作者想说明12层的设计是正确的?


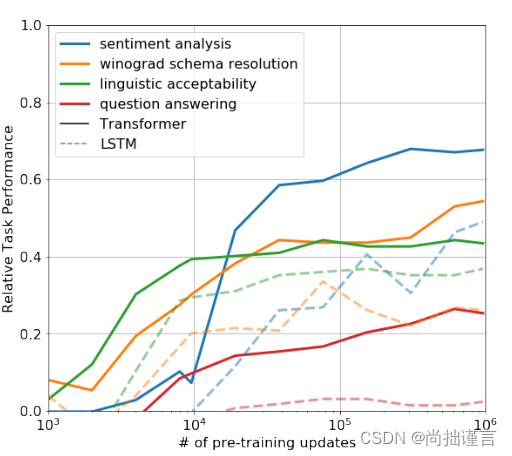
上图其实是作者想要更好的理解为什么基于transformer的预训练模型它是有效的而做的实验。作者提出了一个假设,即基础生成模型学习执行许多需要评估的任务,以提高其语言建模能力,并且transformer的更加结构化的注意力机制相对于LSTM有助于迁移学习。上图中,作者设计了一系列启发式解决方案,利用基础生成模型执行任务而无需监督微调,并证实了这些启发式解决方案在生成预训练过程中的有效性。观察到这些启发式解决方案的性能稳定,并且随着训练的进行逐渐提高,这表明生成预训练具备支持学习各种与任务相关的功能。同时观察到LSTM的零样本性能具有较高的方差,这表明Transformer架构的归纳偏差有助于迁移学习。

作者进行的三个消融实验研究。首先,作者在微调过程中没有使用辅助的语言模型目标,观察到辅助目标对NLI任务和QQP有帮助,但对较小的数据集没有帮助。其次,作者通过将Transformer与使用相同框架的单层2048单元LSTM进行比较,分析了Transformer的效果。结果显示,使用LSTM而不是Transformer时,平均得分下降了5.6。只有在一个数据集MRPC上,LSTM的表现优于Transformer。最后,作者还将他们的模型与Transformer架构直接在有监督目标任务上进行训练,即去掉无监督预训练的过程进行了比较。结果显示,缺乏预训练过程对所有任务的性能有所损害,与完整模型相比,性能下降了14.8%。
6 Conclusion
作者做了一下总结,总的来说,这篇论文提出了一个NLP领域全新的训练思路,即通过良好的无监督训练过程结合任务相关的有监督微调以达到多个NLP任务中的SOTA结果。作者的这套方案后来成为了业界主流模式,包括如今的chatGPT,可以说是开山之作。结尾处作者前瞻性的预见了在无监督训练领域仍然存在很大的潜在的研究价值,看来作者这么说了也这么做了,没有放弃,所以有了如今的chatGPT,牛!
相关文章:
ChatGPT追祖寻宗:GPT-1论文要点解读
论文地址:《Improving Language Understanding by Generative Pre-Training》 最近一直忙着打比赛,好久没更文了。这两天突然想再回顾一下GPT-1和GPT-2的论文, 于是花时间又整理了一下,也作为一个记录~话不多说,让我们…...
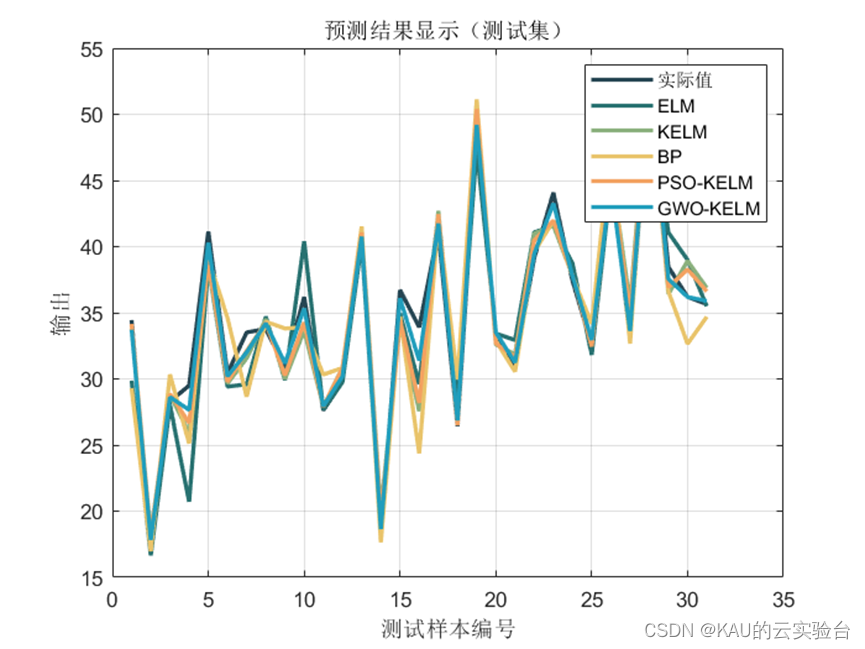
回归拟合 | 灰狼算法优化核极限学习机(GWO-KELM)MATLAB实现
这周有粉丝私信想让我出一期GWO-KELM的文章,因此乘着今天休息就更新了(希望不算晚) 作者在前面的文章中介绍了ELM和KELM的原理及其实现,ELM具有训练速度快、复杂度低、克服了传统梯度算法的局部极小、过拟合和学习率的选择不合适等优点,而KEL…...
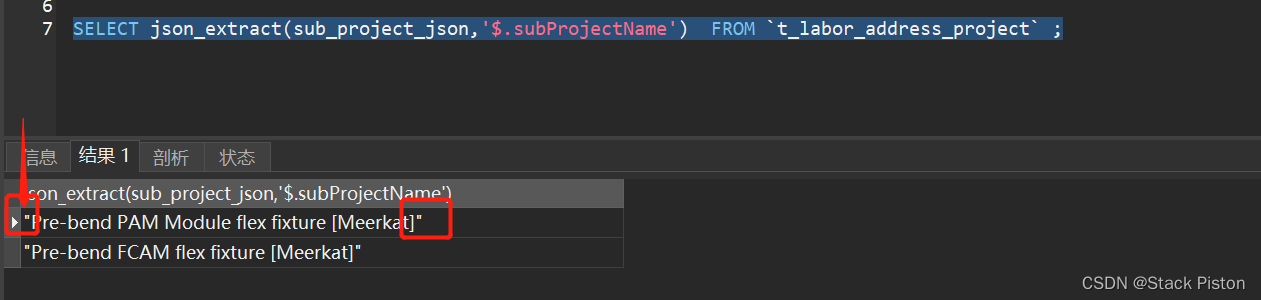
Mysql JSON
select json_extract(c2, $.a) select c2->"$.a" // json_extract的语法糖 (取出的值会保留"双引号" so不适合实战) 注:mysql若是引擎Mariadb则不支持json操作符->>语法糖 select c2->…...
使用Vue + axios实现图片上传,轻松又简单
目录 一、Vue框架介绍 二、Axios 介绍 三、实现图片上传 四、Java接收前端图片 一、Vue框架介绍 Vue是一款流行的用于构建用户界面的开源JavaScript框架。它被设计用于简化Web应用程序的开发,特别是单页面应用程序。 Vue具有轻量级、灵活和易学的特点…...

C# 中什么是重写(子类改写父类方法)
方法重写是指在继承关系中,子类重新实现父类或基类的某个方法。这种方法允许子类根据需要修改或扩展父类或基类的方法功能。在面向对象编程中,方法重写是一种多态的表现形式,它使得子类可以根据不同的需求和场景提供不同的方法实现。 方法重…...
【Leetcode-面试经典150题-day22】
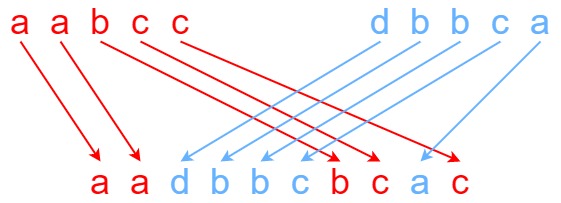
目录 97. 交错字符串 97. 交错字符串 题意: 给定三个字符串 s1、s2、s3,请你帮忙验证 s3 是否是由 s1 和 s2 交错 组成的。 两个字符串 s 和 t 交错 的定义与过程如下,其中每个字符串都会被分割成若干 非空 子字符串: s s1 s2 …...
LDAP服务器如何重启
1、find / -name ldap 该命令只会从根路径下查看ldap文件夹 find / -name ldap2、该命令会从根路径/查看所有包含ldap路径的文件夹,会查询出所有,相当于全局查询 find / -name *ldap*2、启动OpenLADP 找到LDAP安装目录后,执行以下命令 #直…...

AP51656 LED车灯电源驱动IC 兼容替代PT4115 PT4205 PWM和线性调光
产品描述 AP51656是一款连续电感电流导通模式的降压恒流源 用于驱动一颗或多颗串联LED 输入电压范围从 5V 到 60V,输出电流 可达 1.5A 。根据不同的输入电压和 外部器件, 可以驱动高达数十瓦的 LED。 内置功率开关,采用高端电流采样设置 …...
浅析安防视频监控平台EasyCVR视频融合平台接入大量设备后是如何维持负载均衡的
安防视频监控平台EasyCVR视频融合平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。视频汇聚融合管理平台EasyCVR既具备…...

SIEM 中不同类型日志监控及分析
安全信息和事件管理(SIEM)解决方案通过监控来自网络的不同类型的数据来确保组织网络的健康安全状况,日志数据记录设备上发生的每个活动以及整个网络中的应用程序,若要评估网络的安全状况,SIEM 解决方案必须收集和分析不…...
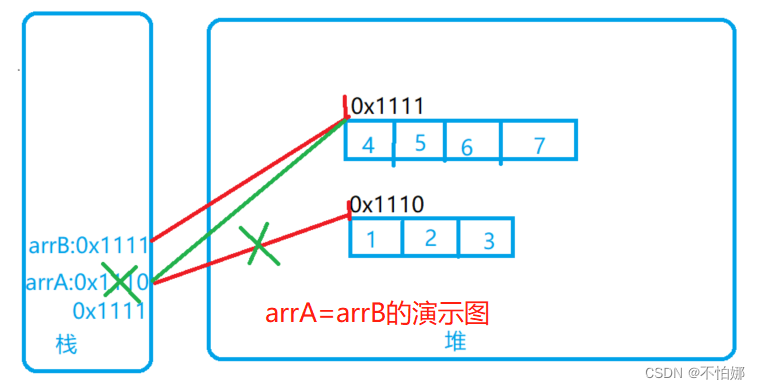
【java基础复习】java中的数组在内存中是如何存储的?
基本数据类型与内存存储数组类型与内存存储为什么数组需要两块空间?感谢 💖 基本数据类型与内存存储 首先,让我们回顾一下基本数据类型的内存存储方式。对于一个基本类型变量,例如int类型的变量a,内存中只有一块内存空…...

MySQL数据库 MHA高可用
MySQL MHA 什么是 MHA MHA(MasterHigh Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。 MHA 的出现就是解决MySQL 单点的问题。 MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。 MHA能在故障切换的…...

leetcode669. 修剪二叉搜索树(java)
修剪二叉搜索树 题目描述递归代码演示: 题目描述 难度 - 中等 LC - 669. 修剪二叉搜索树 给你二叉搜索树的根节点 root ,同时给定最小边界low 和最大边界 high。通过修剪二叉搜索树,使得所有节点的值在[low, high]中。修剪树 不应该 改变保留…...
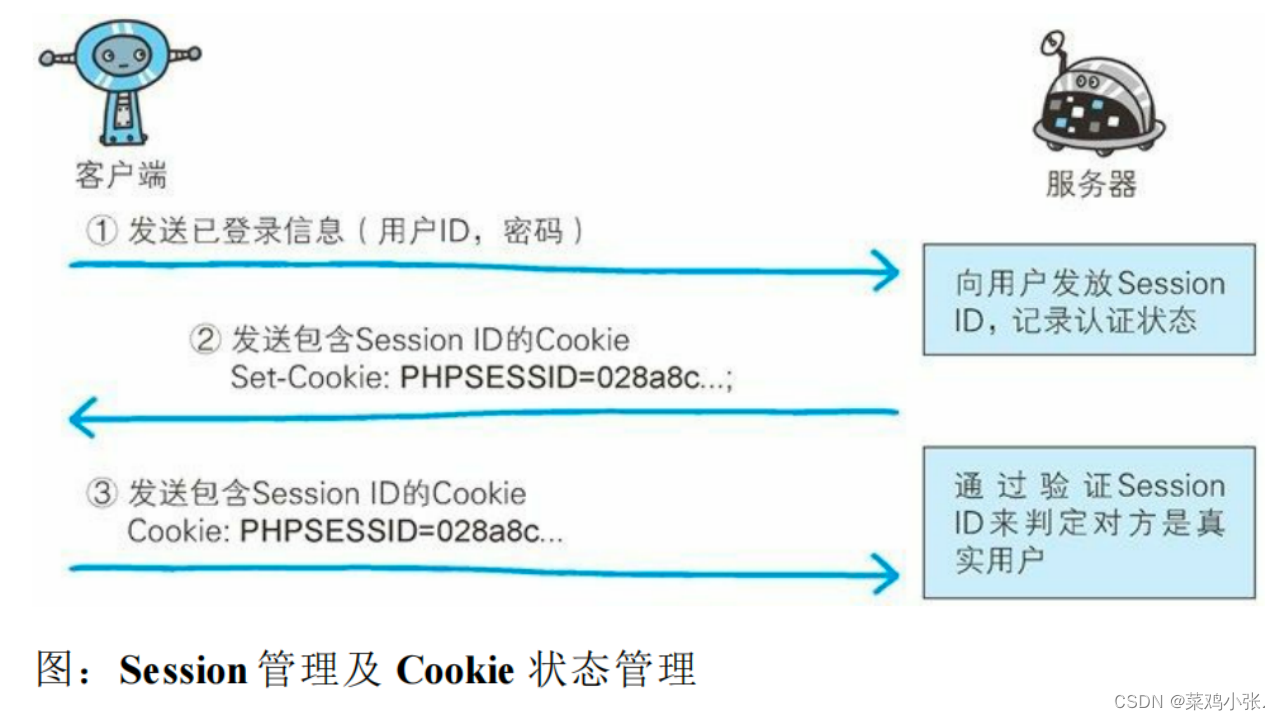
计算机网络的故事——确认访问用户身份的认证
确认访问用户身份的认证 HTTP使用的认证方式:BASIC认证(基本认证)、DIGEST(摘要认证)、SSL客户端认证、FormBase认证(基于表单认证)。 基于表单的认证:涉及到session管理以及cookie…...

C#禁用或启用任务管理器
参考文档https://zhuanlan.zhihu.com/p/95156063 借助上述参考文档里的C#操作注册表类,禁用或启用任务管理器 using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace HideTaskMgr { class Program { …...
【Redis】NoSQL之Redis的配置及优化
关系数据库与非关系数据库 关系型数据库 关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。 SQL 语句(标准数据查询语言)就是一种基于关系型数据库的语言&a…...

【数据库】如何利用Python中的petl将PostgreSQL中所有表的外键删除,迁移数据,再重建外键
一、简介 在数据库管理中,外键是一种重要的约束,用于确保数据的一致性和完整性。然而,在某些情况下,我们可能需要删除或修改外键。本文将介绍如何使用Python中的petl库将PostgreSQL中所有表的外键删除,迁移数据&#…...
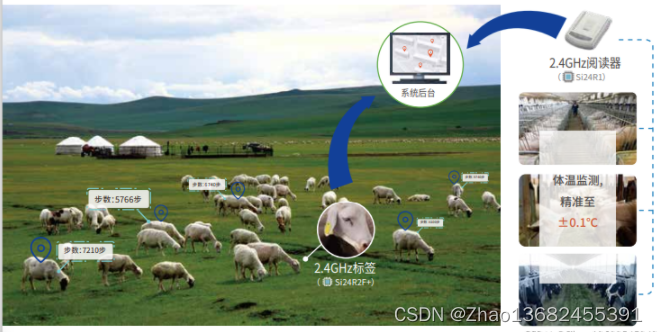
Si24R2F+畜牧 耳标测体温开发资料
Si24R2F是针对IOT应用领域推出的新款超低功耗2.4G内置NVM单发射芯片。广泛应用于2.4G有源活体动物耳标,带实时测温计步功能。相较于Si24R2E,Si24R2F增加了温度监控、自动唤醒间隔功能;发射功率由7dBm增加到12dBm,距离更远…...
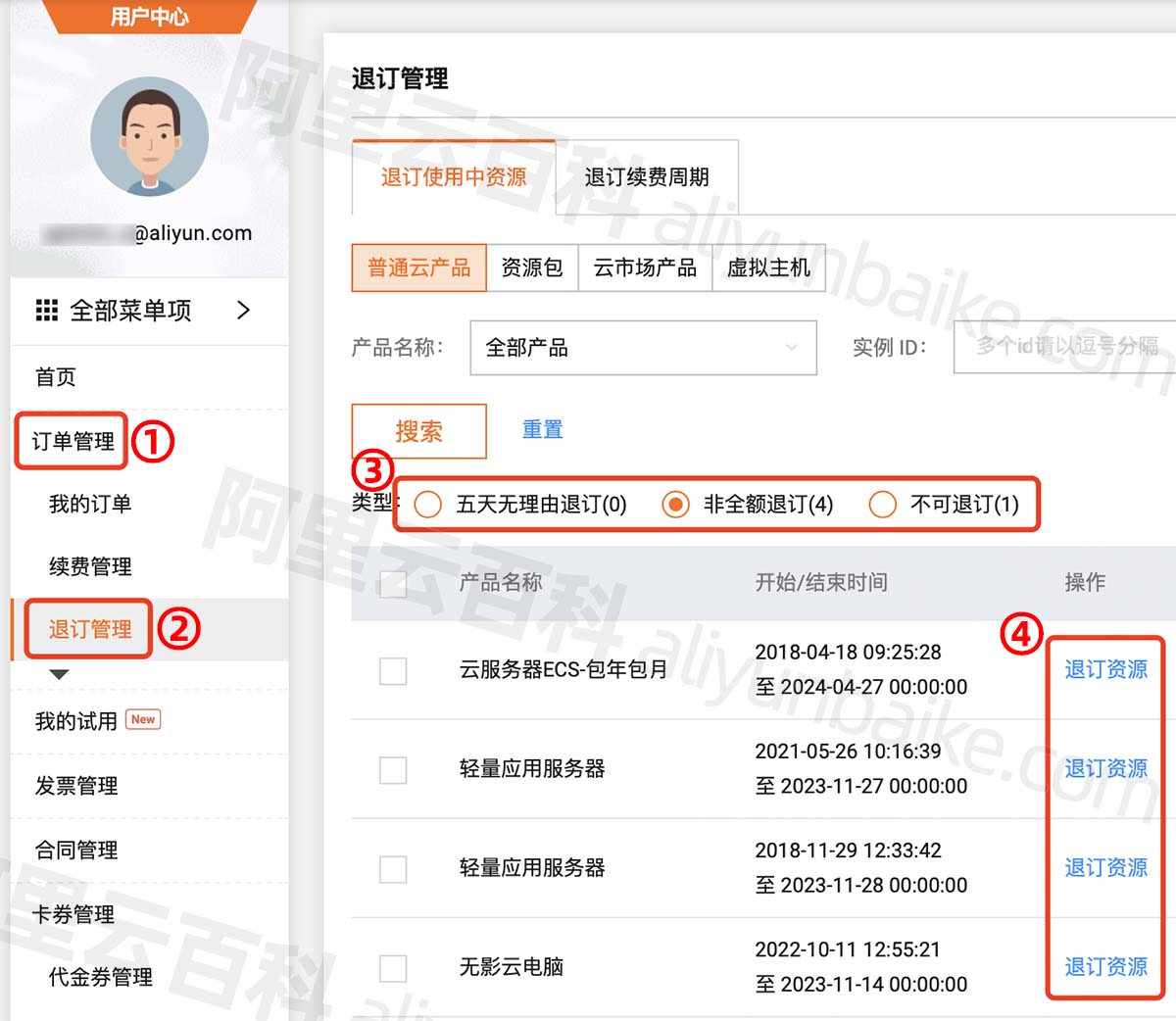
阿里云服务器退款流程_退订入口_到账时间说明
阿里云服务器如何退款?云服务器在哪申请退款?在用户中心订单管理中的退订管理中退款,阿里云百科分享阿里云服务器退款流程,包括申请退款入口、云服务器退款限制条件、退款多久到账等详细说明: 目录 阿里云服务器退款…...
自然语言处理实战项目17-基于多种NLP模型的诈骗电话识别方法研究与应用实战
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目17-基于NLP模型的诈骗电话识别方法研究与应用,相信最近小伙伴都都看过《孤注一掷》这部写实的诈骗电影吧,电影主要围绕跨境网络诈骗展开,电影取材自上万起真…...

STM32F407通过SPI接口高效读写SD卡:CubeMX配置与底层驱动实战
1. SD卡基础与SPI通信原理 SD卡作为嵌入式系统中最常用的存储介质之一,其SPI模式因其接线简单、协议清晰而广受欢迎。先说说我实际项目中遇到的坑:曾经因为没理解清楚SPI模式下SD卡的初始化时序,导致整整两天卡在设备无法识别的困境里。 SD卡…...

ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案
ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲&a…...

Go语言缓存雪崩:防止缓存失效
Go语言缓存雪崩:防止缓存失效 1. 雪崩防护 type CacheWithProtection struct {cache *RedisCachemu sync.Mutexlocks map[string]*sync.Mutex }func NewCacheWithProtection(cache *RedisCache) *CacheWithProtection {return &CacheWithProtect…...

ARM Cortex-X4/X925处理器仿真模型与指令集详解
1. ARM Cortex-X4/X925处理器仿真模型概述处理器仿真模型在现代芯片设计中扮演着至关重要的角色,特别是在Arm架构的生态系统中。作为Arm最新一代高性能核心,Cortex-X4和X925的Iris仿真组件提供了完整的指令集和微架构行为建模,使开发者能够在…...

Arm Iris组件参数化建模与调试实践
1. Arm Iris组件概述与核心价值Arm Iris组件是Fast Models仿真平台中的关键模块,它为芯片设计验证和软件开发提供了高度参数化的虚拟原型环境。作为一名长期从事Arm架构开发的工程师,我发现Iris组件的设计理念完美体现了"配置即硬件"的思想——…...

Claude API封装项目深度解析:从安全评估到自主构建代码助手
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫 ashish200729/claude-code-source-code 。光看这个标题,很多开发者朋友可能会心头一热,以为这是某个AI模型的源代码被开源了。但作为一个在开源社区混迹多年的老码农&…...
在Multi-Agent系统中的应用(图编排、动态DAG、Dynamic DAG)动态Agent Graph)
有向无环图(DAG)在Multi-Agent系统中的应用(图编排、动态DAG、Dynamic DAG)动态Agent Graph
文章目录有向无环图(DAG)在 Multi-Agent 系统中的应用一、什么是 DAG(有向无环图)二、为什么 Multi-Agent 需要 DAG三、Multi-Agent 的本质:任务图四、DAG 在 Multi-Agent 中的核心作用五、一个典型 Multi-Agent DAG六…...

轻量级Web框架Oli:从核心原理到生产实践
1. 项目概述:一个轻量级、可扩展的Web应用框架最近在梳理手头几个小项目的技术栈时,我又把amrit110/oli这个仓库翻了出来。这是一个在GitHub上由开发者amrit110创建并维护的名为oli的项目。乍一看标题,你可能会有点懵,oli是什么&a…...
)
从安迪·沃霍尔到AI画布:波普艺术三大视觉基因拆解,手把手复刻金罐头/玛丽莲肖像风格(含可复用prompt模板库)
更多请点击: https://intelliparadigm.com 第一章:从安迪沃霍尔到AI画布:波普艺术的范式迁移 安迪沃霍尔用丝网印刷将可口可乐瓶与玛丽莲梦露转化为大众文化的图腾,其核心并非复制,而是对**重复、去个性化与媒介即内容…...

多数人支持!微软或把 Xbox 重新品牌化为 XBOX,回归最初形式
Xbox 品牌重塑:从民意调查到账号更名微软 Xbox 首席执行官阿莎夏尔马在 X(原推特)上发起民意调查,询问粉丝微软应使用 Xbox 还是 XBOX,结果多数人支持 XBOX,随后公司将其 X 账号更名。不过,Xbox…...