自然语言处理实战项目17-基于多种NLP模型的诈骗电话识别方法研究与应用实战
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目17-基于NLP模型的诈骗电话识别方法研究与应用,相信最近小伙伴都都看过《孤注一掷》这部写实的诈骗电影吧,电影主要围绕跨境网络诈骗展开,电影取材自上万起真实诈骗案例。随着科技的快速发展,诈骗电话已经成为了一种常见的犯罪手段,给人们的生活和财务安全带来了巨大的威胁。诈骗电话的形式多种多样,如假冒银行工作人员、征信信息、足彩内部消息、谎称中奖、虚假投资机会等等,这些都给人们带来了极大的困扰和损失。

目录
一、引言
A. 研究背景和动机
二、诈骗电话识别方法概述
A. 诈骗电话的定义和分类
B. 传统的识别方法回顾
C. NLP在诈骗电话识别中的应用潜力
三、数据收集和预处理
A. 数据来源和描述
B. 数据预处理技术
1.电话通话录音转换和分割
2.文本转换和清洗
3.特征提取和选择
四、 NLP技术在诈骗电话识别中的应用
A. 文本特征提取和表示
1.文本向量化方法
2.关键词提取和频率统计
3.语义表示模型(如Word2Vec、BERT等)
B. 模型训练与评估
1.监督学习方法(如SVM、决策树等)
2.深度学习方法(如RNN、CNN等)
C. 模型性能评估指标
1.准确率、召回率和F1值
2.ROC曲线和AUC值
五、诈骗电话识别代码样例
A. 数据样例加载
B. 模型训练
1.TF-IDF模型搭建与训练
2.LSTM模型搭建与训练
六、结论与展望
A. 主要研究工作总结
B. 研究结果的意义和局限性
C. 后续研究方向和拓展空间
一、引言
A. 研究背景和动机
最近几个月,缅甸北部发生了大规模的诈骗活动,由一些犯罪团伙利用境外资源和优势进行组织和实施。这些诈骗团伙采取多种手段和形式,包括电话诈骗、网络诈骗以及冒充官方机构等方式。他们通常会使用技术手段隐藏真实身份和电话号码,使得受害者难以辨别真假。
这些诈骗团伙之所以能够猖獗,一方面是由于缅甸北部地区存在边境接触,使得警方追捕困难;另一方面,利用境外资源和技术,他们可以更容易地伪装身份、转移资金,并打击执法机构的追捕行动。
面对这样的诈骗团伙,我们需要加强国际合作和信息共享,以便及时获取相关情报,并采取有效的打击措施。同时,公众也应该增强对诈骗风险的认识,保持警惕,不轻易相信陌生人的电话或信息,并采取防范措施,如拒绝提供个人敏感信息、核实身份真伪以及及时报案。只有通过多方合作和群策群力,才能更好地遏制诈骗团伙的活动,保护人们的财务安全。
本研究旨在提供一种基于自然语言处理(NLP)的诈骗电话识别方法,以有效解决诈骗电话给人们带来的威胁。具体目标包括:首先,对诈骗电话进行定义和分类,明确研究对象;其次,回顾传统的识别方法,分析其优劣和局限性;最后,探讨NLP技术在诈骗电话识别中的应用潜力,为构建更准确的识别模型提供参考。
二、诈骗电话识别方法概述
A. 诈骗电话的定义和分类
诈骗电话是指利用手机或固定电话进行欺诈行为的电话通讯活动。根据诈骗手段和目的的不同,可以将诈骗电话分为多个分类,如银行诈骗、中奖诈骗、贷款诈骗、征信诈骗、快递赔偿诈骗、AI诈骗等。每种类型的诈骗电话都有其独特的特征和目的,因此需要针对不同类型的诈骗电话采取相应的识别方法。
B. 传统的识别方法回顾
过去的诈骗电话识别方法主要依赖于电话号码黑名单、特定关键词的匹配以及人工规则的制定。然而,这些方法存在一些局限性,如误判率高、识别效果不稳定等问题。因此,开发基于NLP的诈骗电话识别方法具有重要意义。
C. NLP在诈骗电话识别中的应用潜力
NLP技术在诈骗电话识别中具有广阔的应用潜力。首先,NLP可以通过语义分析、情感分析等技术来理解电话内容和说话者的意图,从而更准确地判断电话是否为诈骗电话。其次,NLP还可以通过挖掘大量的文本数据来构建诈骗电话识别模型,使其具备更好的泛化能力和适应性。
本文将详细探讨NLP技术在诈骗电话识别中的应用潜力,并提出一种基于NLP的识别模型构建方法,旨在提高识别准确率和稳定性,从而有效预防诈骗电话的发生。本研究的成果对于保障人们的财产安全、维护社会稳定具有重要意义。
三、 数据收集和预处理
A. 数据来源和描述
在诈骗电话识别中,数据的来源可以包括电话通话录音和文本记录。电话通话录音是通过电话录音设备或软件进行收集的,其中包含了来自不同电话号码的通话录音。文本记录则是电话通话过程中产生的文本信息,例如来自呼叫中心的记录或用户提供的文字转录。
B. 数据预处理技术
数据预处理是在进行进一步分析之前对原始数据进行清洗和转换的过程。在诈骗电话识别中,常用的数据预处理技术包括电话通话录音转换和分割、文本转换和清洗,以及特征提取和选择。
1.电话通话录音转换和分割
电话通话录音需要经过转换和分割的处理,以提取出有用的信息。转换包括将通话录音从音频格式转换为可处理的数字表示形式,例如波形图形式或声谱图。分割则是将整个通话录音切分为更小的段落,便于后续分析。
2.文本转换和清洗
对于文本记录,首先需要将其转换成机器可读的形式,例如将文本转换为字符串或标记序列。然后,对文本进行清洗,去除无用的字符、标点符号和停用词,以及进行大小写统一等操作,以减少噪音对后续分析的影响。
3.特征提取和选择
特征提取是从原始数据中提取有用信息的过程,以便训练模型进行分类或识别。在诈骗电话识别中,可以提取语音特征(如声谱图、基频等)和文本特征(如关键词、词性、句法结构等)。特征选择则是从众多特征中选择最相关和最具区分度的特征,以降低模型复杂度和提高分类性能。
四、 NLP技术在诈骗电话识别中的应用
A. 文本特征提取和表示
在诈骗电话识别中,文本特征的提取和表示是非常重要的步骤,它们用于将原始的文本数据转换为机器可理解的形式。
1.文本向量化方法
文本向量化是将文本转换为向量表示的方法之一。常用的文本向量化方法包括词袋模型(Bag of Words)和TF-IDF。词袋模型将文本表示为词汇表中词语的出现频率向量,忽略了单词的顺序和文法结构。TF-IDF考虑了词语在文本中的重要性,通过计算词频和逆文档频率得到向量表示。
2.关键词提取和频率统计
关键词提取是从文本中提取出具有重要意义的词语或短语。常用的关键词提取算法包括基于词频、TF-IDF、TextRank等。关键词提取可以帮助识别出诈骗电话中常见的欺诈手段或关键信息。
3.语义表示模型
语义表示模型通过学习词语之间的语义关系,将文本转换为语义空间中的向量表示。Word2Vec是一种基于神经网络的语义表示模型,它可以将词语映射到一个连续的向量空间。BERT是一种预训练的语言模型,它能够理解词语之间的上下文关系,产生更加准确的文本表示。
B. 模型训练与评估
在诈骗电话识别中,模型的训练和评估是为了建立一个能够自动判断电话是否属于诈骗的系统。
1.监督学习方法
监督学习是一种通过已标记的训练数据来训练模型的方法。在诈骗电话识别中,可以使用支持向量机(SVM)、决策树等机器学习算法进行分类。这些算法通过学习已知标签的样本,建立一个能够对新样本进行分类的模型。
2.深度学习方法
深度学习方法通过构建多层神经网络模型来进行训练和分类。在诈骗电话识别中,可以使用循环神经网络(RNN)、卷积神经网络(CNN)等深度学习模型。这些模型能够学习电话通话录音或文本数据中的复杂特征,提高分类的准确性。
C. 模型性能评估指标
为了评估模型的性能,需要使用一些指标来衡量其分类结果的准确性和稳定性。
1.准确率、召回率和F1值
准确率衡量模型正确分类样本的能力,召回率衡量模型找到所有正样本的能力。F1值是准确率和召回率的综合评价指标,用于平衡准确率和召回率之间的关系。
2.ROC曲线和AUC值
ROC曲线是以假阳性率为横轴,真阳性率为纵轴的曲线。AUC值表示ROC曲线下的面积,用于衡量模型分类性能的整体表现,AUC值越大,模型的分类效果越好。
五、 诈骗电话识别代码样例
A. 数据样例加载
假设我们的样例数据集为一个CSV文件,包含两列:“文本”和“标签”。其中,“文本”列包含电话通话录音或文本记录的内容,“标签”列用于表示该文本是否属于诈骗电话,标签取值为0(非诈骗)或1(诈骗)。
文本,标签
"您好,这里是ABC银行,我们怀疑您的银行账户出现异常活动,请提供您的个人信息以验证身份。",1
"尊敬的客户,您已被选中参加我们的奖品抽奖活动,只需支付一小笔费用即可获得高额奖金。",1
"您好,我是申通快递,您买的一个包裹,公司给您弄丢了,这里需要加我们的理赔客服对您快递进行理赔200元。",1
"您好,这是一条关于您的快递的通知,由于地址错误,需要支付额外的费用进行重新寄送。",0
"您好,我是您的移动运营商客服,您的账户余额已不足,请及时充值以避免影响正常使用。",0
"尊敬的客户,您的手机尾号2345的机主,目前已经欠费10元,将会影响您的宽带使用。",0
加载数据的步骤可以使用Python的pandas库来实现:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC# 加载CSV文件
data = pd.read_csv("data.csv")# 查看数据集信息
print(data.info())# 划分特征和标签
X = data["文本"]
y = data["标签"]
B. 模型训练
1.TF-IDF模型训练
接下来,可以使用NLP技术进行文本特征提取和表示,并建立模型进行诈骗文本的识别。常用的方法包括使用词袋模型、TF-IDF或深度学习模型(如RNN、CNN)。
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 特征提取和表示(使用TF-IDF)
vectorizer = TfidfVectorizer()
X_train_tfidf = vectorizer.fit_transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)# 创建分类模型(支持向量机)
svm_model = SVC()# 模型训练
svm_model.fit(X_train_tfidf, y_train)# 模型评估
accuracy = svm_model.score(X_test_tfidf, y_test)
print("模型准确率:", accuracy)这里使用TF-IDF对文本进行特征提取和表示,将文本转换为向量形式。接下来,创建并训练支持向量机分类模型。最后,通过对测试集进行预测并计算准确率,评估模型的性能。
2.LSTM模型训练
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pad_sequence# 自定义数据集类
class TextDataset(Dataset):def __init__(self, X, y):self.X = Xself.y = ydef __len__(self):return len(self.X)def __getitem__(self, index):return self.X[index], self.y[index]# 自定义LSTM模型
class LSTMModel(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):super(LSTMModel, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, x):embedded = self.embedding(x)output, _ = self.lstm(embedded)output = self.fc(output[:, -1, :])return output.squeeze()# 加载CSV文件
data = pd.read_csv("data.csv")# 划分特征和标签
X = data["文本"]
y = data["标签"]# 文本预处理
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(X)
X = pad_sequences(sequences)# 标签编码
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y)# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建数据加载器
train_dataset = TextDataset(torch.tensor(X_train), torch.tensor(y_train))
test_dataset = TextDataset(torch.tensor(X_test), torch.tensor(y_test))train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)# 定义模型超参数
vocab_size = len(word_index) + 1
embedding_dim = 100
hidden_dim = 64
output_dim = 1# 创建模型实例和优化器
model = LSTMModel(vocab_size, embedding_dim, hidden_dim, output_dim)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.BCEWithLogitsLoss()# 模型训练
def train(model, dataloader, optimizer, criterion):model.train()running_loss = 0.0for inputs, labels in dataloader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels.float().unsqueeze(1))loss.backward()optimizer.step()running_loss += loss.item() * inputs.size(0)epoch_loss = running_loss / len(dataloader.dataset)return epoch_loss# 模型评估
def evaluate(model, dataloader):model.eval()predictions = []true_labels = []with torch.no_grad():for inputs, labels in dataloader:outputs = model(inputs)preds = torch.round(torch.sigmoid(outputs))predictions.extend(preds.tolist())true_labels.extend(labels.tolist())accuracy = accuracy_score(true_labels, predictions)return accuracynum_epochs = 10for epoch in range(num_epochs):train_loss = train(model, train_loader, optimizer, criterion)test_acc = evaluate(model, test_loader)print(f"Epoch [{epoch+1}/{num_epochs}], Train Loss: {train_loss:.4f}, Test Accuracy: {test_acc:.4f}")
在上述代码中,我首先定义了两个自定义类:TextDataset用于创建自定义数据集,LSTMModel是一个简单的LSTM模型。
通过训练我们就可以识别文本里面是否是诈骗信息。
六、主要研究工作总结
A. 主要研究工作总结
通过设计与实现诈骗电话识别系统,并进行应用场景和效果验证,总结如下:
提出了一套基于人工智能技术的诈骗电话识别系统,能够有效识别和阻止来自诈骗电话的威胁。 在系统应用场景和效果验证中,取得了高准确率的识别结果,并具备良好的实时性能。
通过用户反馈和改进建议,不断改善和优化系统,提升用户体验和安全性。
B. 研究结果的意义和局限性
我们的研究结果具有重要的意义和实际应用价值:
1.帮助用户有效识别和阻止诈骗电话,保护用户通话安全。
2.提升通话的信任度和可靠性,推动通信行业的发展。
然而,我们的研究也存在一定的局限性:
1.对于新型诈骗电话的识别可能存在一定的延迟性,需要及时更新模型以适应新形势。
2.对于一些语音质量较差的电话,识别准确率可能会有所下降。
3.系统的适用性与可扩展性需要在更广泛的场景中进一步验证。
C. 后续研究方向和拓展空间
基于以上工作和结果,我们提出了以下后续研究方向和拓展空间:
1.引入更多的深度学习技术,如自然语言处理和语音情感分析,以提升系统的准确率和鲁棒性。
2.开展更多样本的数据收集与处理,完善系统的训练集,提高系统对各种类型诈骗电话的识别能力。
3.探索与通信运营商的合作,将诈骗电话识别技术应用到网络层面,进一步提升整体的识别效果和覆盖范围。
相关文章:
自然语言处理实战项目17-基于多种NLP模型的诈骗电话识别方法研究与应用实战
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目17-基于NLP模型的诈骗电话识别方法研究与应用,相信最近小伙伴都都看过《孤注一掷》这部写实的诈骗电影吧,电影主要围绕跨境网络诈骗展开,电影取材自上万起真…...

安全错误攻击
近年来基于错误的密码分析(fault-based cryptanalysis)已成为检测智能卡(Smartcard)安全的重要因素。这种基于错误的密码分析,假设攻击者可以向智能卡中导入一定数量的、某种类型的错误,那么智能卡会输出错…...
logstash配置语法详解)
ELK安装、部署、调试 (八)logstash配置语法详解
input {#输入插件 }filter {#过滤插件 }output {#输出插件 } 1.读取文件。 使用filewatch的ruby gem库来监听文件变化,并通过.sincedb的数据库文件记录被监听日志we年的读取进度(时间 搓) 。sincedb数据文件的默认路径为<path.data>/…...
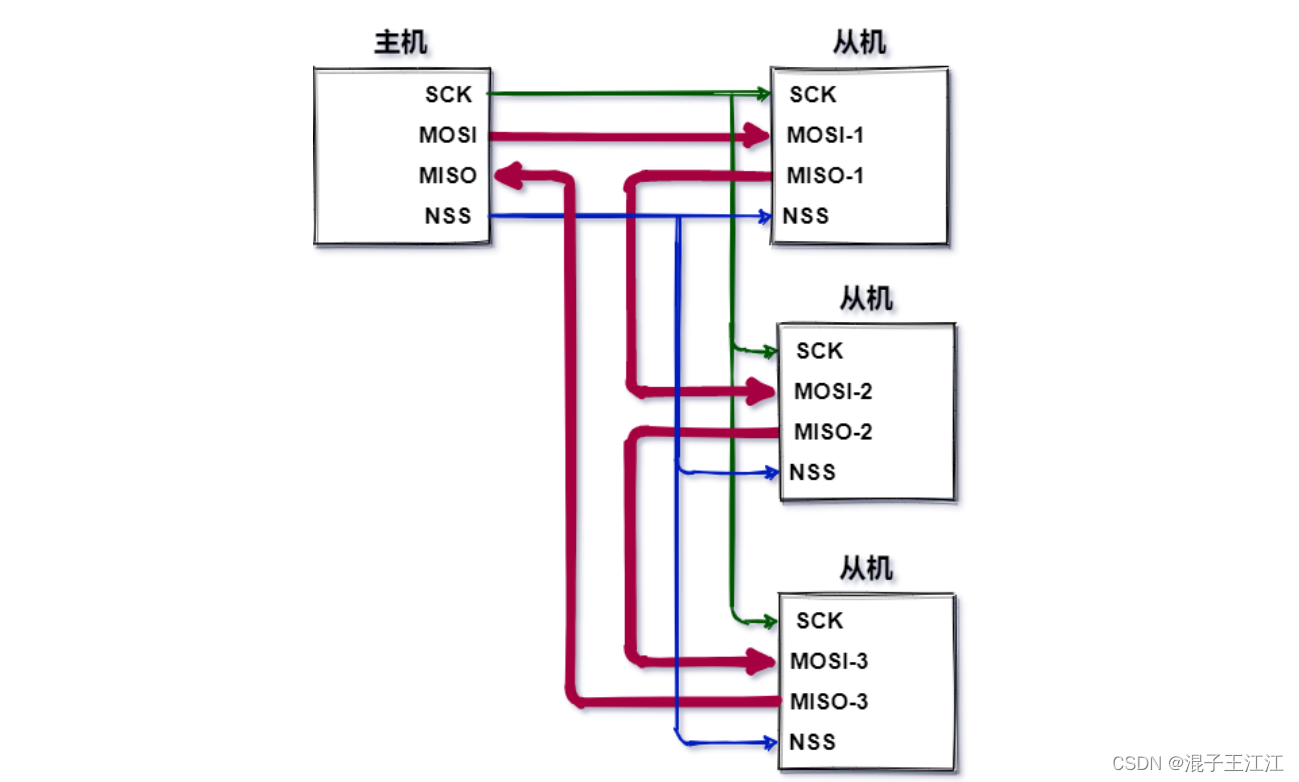
SPI协议
文章目录 前言一、简介1、通信模式2、总线定义3、SPI通信结构4、SPI通讯时序5、SPI数据交互过程 二、多从机模式1、多NSS2、菊花链3、SPI通信优缺点4、UART、IIC、SPI 区别 三、总结四、参考资料 前言 SPI协议是我们的重要通信协议之一,我们需要掌握牢靠。 一、简介…...

机器学习算法系列————决策树(二)
1.什么是决策树 用于解决分类问题的一种算法。 左边是属性,右边是标签。 属性选择时用什么度量,分别是信息熵和基尼系数。 这里能够做出来特征的区分。 下图为基尼系数为例进行计算。 下面两张图是对婚姻和年收入的详细计算过程(为GINI系…...

ACM中的数论
ACM中的数论是计算机科学领域中的一个重要分支,它主要研究整数的性质、运算规律和它们之间的关系。在ACM竞赛中,数论问题经常出现,因此掌握一定的数论知识对于参加ACM竞赛的选手来说是非常重要的。本文将介绍一些常见的数论概念和方法&#x…...
我的创作纪念日 —— 一年之期
前言 大家好!我是荔枝嘿~看到官方私信才发现原来时间又过去了一年,荔枝也在CSDN中创作满一年啦,虽然中间因为种种原因并没有经常输出博文哈哈,但荔枝一直在坚持创作嘿嘿。记得去年的同一时间我也同样写了一篇总结文哈哈哈&#x…...
qt.qpa.plugin:找不到Qt平台插件“wayland“|| (下载插件)Ubuntu上解决方案
相信大家也都知道这个地方应该做什么,当然是下载这个qt平台的插件wayland,但是很多人可能不知道怎么下载这个插件。 那么我现在要说的这个方法就是针对这种的。 sudo apt install qtwayland5完事儿了奥兄弟们。 看看效果 正常了奥。...

详解Spring Boot中@PostConstruct的使用
PostConstruct 在Java中,PostConstruct是一个注解,通常用于标记一个方法,它表示该方法在类实例化之后(通过构造函数创建对象之后)立即执行。 加上PostConstruct注解的方法会在对象的所有依赖项都已经注入完成之后执行…...

判断子序列
判断子序列 题目: 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"…...
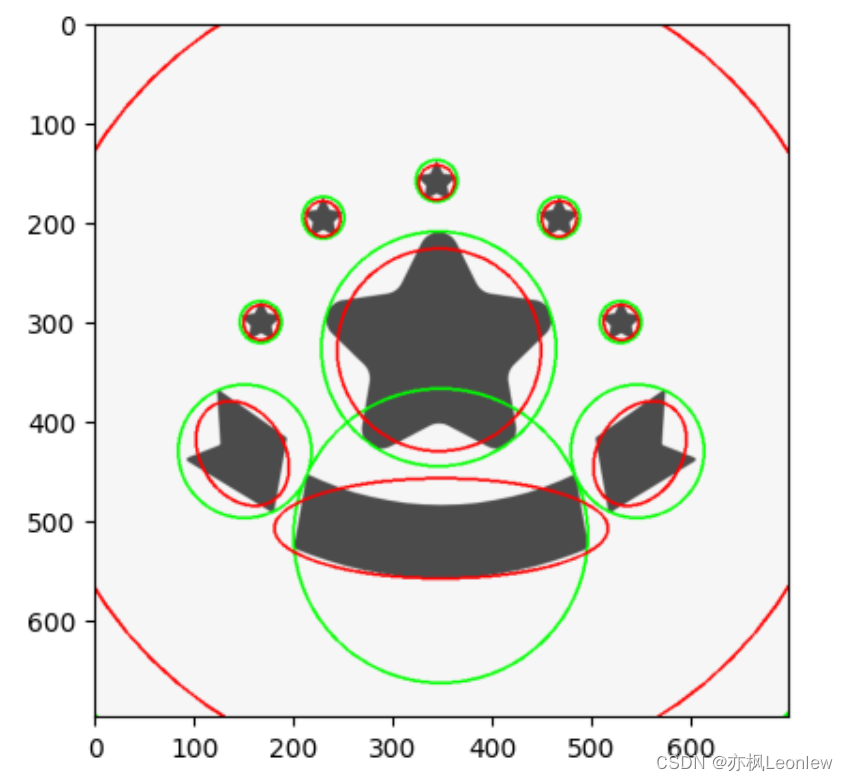
Python Opencv实践 - 轮廓特征(最小外接圆,椭圆拟合)
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/stars.PNG") plt.imshow(img[:,:,::-1])#轮廓检测 img_gray cv.cvtColor(img, cv.COLOR_BGR2GRAY) ret,thresh cv.threshold(img_gray, 127, 255, 0) contou…...

Ubuntu22.04 LTS+NVIDIA 4090+Cuda12.1+cudnn8.8.1
系统环境中: 1.系统驱动安装的是: NVIDIA-Linux-x86_64-530.30.02.run 2.CUDA安装:cuda_12.1.0_530.30.02_linux.run(无需第1步,直接安装它就带配套驱动) wget https://developer.download.nvidia.com/…...
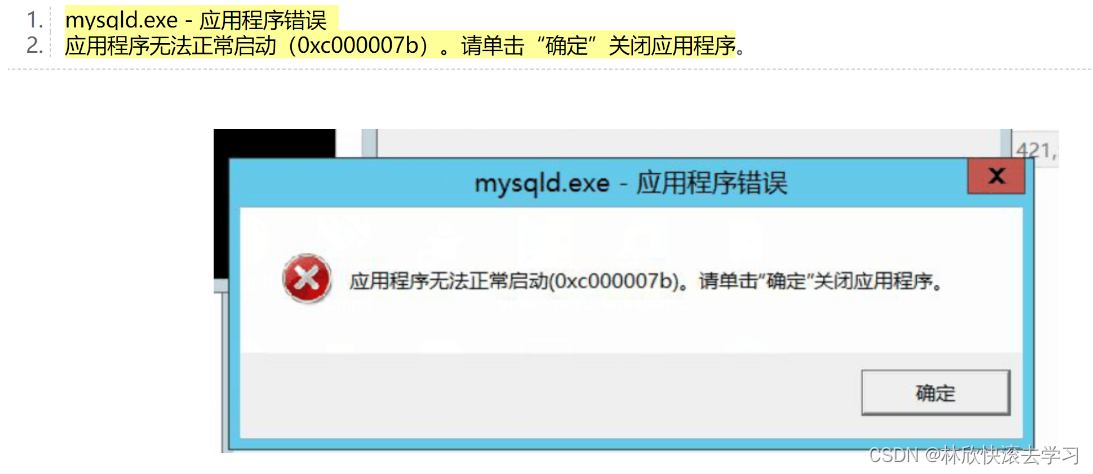
重装系统后,MySQL install错误,找不到dll文件,或者应用程序错误
文章目录 1.找不到某某dll文件2.mysqld.exe - 应用程序错误使用DX工具直接修复 1.找不到某某dll文件 由于找不到VCRUNTIME140_1.dll或者MSVCP120.dll,无法继续执行代码,重新安装程序可能会解决此问题。 在使用一台重装系统过的电脑,再次重新…...
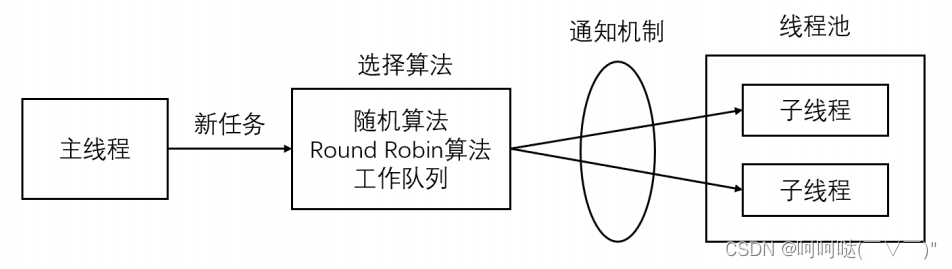
线程同步机制类封装及线程池实现
1.线程池 线程池是由服务器预先创建的一组子线程,线程池中的线程数量应该和 CPU 数量差不多。线程池中的所有子线程都运行着相同的代码。当有新的任务到来时,主线程将通过某种方式选择线程池中的某一个子线程来为之服务。相比与动态的创建子线程&#x…...

Linux中的用户、组和权限
一,Linux的安全模型 1.安全3A Authentication(认证),Authorization(授权),Accounting(审计)(AAA)是用于对计算机资源的访问、策略执行、审计使用情况和提供服务账单所需信息等功能进行智能控制的基本组件的一个术语。大多数人认为这三个组合的过程对有效的网络管理和…...

python学习--基本数据类型之字典
python中数据类型 第一类:不可变类型、静态数据类型、不支持增删改操作 数字(number)字符串(string)元组(tuple) 第二类:可变类型、动态数据类型、支持增删改操作 列表ÿ…...
【OpenCV入门】第九部分——模板匹配
文章结构 模板匹配方法单模板匹配单目标匹配多目标匹配 多模板匹配 模板匹配方法 模板是被查找的图像。模板匹配是指查找模板在原始图像中的哪个位置的过程。 result cv2.matchTemplate(image, templ, method, mask)image: 原始图像templ: 模板图像&a…...

在设计web页面时,为移动端设计一套页面,PC端设计一套页面,并且能自动根据设备类型来选择是用移动端的页面还是PC端的页面。
响应式设计,即移动端和PC端共用一个HTML模式,网站的程序和模板自动根据设备类型和屏幕大小进行自适应调整。这种方法我不喜欢,原因是不能很好保证各种客户端的效果,里面存在各种复杂的兼容性等问题。 我喜欢为不同的客户端写不同的…...
微信小程序地图应用总结版
1.应用场景:展示公司位置,并打开第三方app(高德,腾讯)导航到目标位置。 (1)展示位置地图 uniapp官网提供了相关组件,uniapp-map组件https://uniapp.dcloud.net.cn/component/map.ht…...
分支创建查看切换
1、初始化git目录,创建文件并将其推送到本地库 git init echo "123" > hello.txt git add hello.txt git commit -m "first commit" hello.txt$ git init Initialized empty Git repository in D:/Git/git-demo/.git/ AdministratorDESKT…...

别再手动算位宽了!Vivado FIR IP核的位宽计算逻辑与配置避坑指南
Vivado FIR IP核位宽计算实战:从黑盒解析到精准配置 在FPGA数字信号处理领域,FIR滤波器作为基础构建模块,其性能表现直接影响整个系统的信号处理质量。而位宽配置这个看似简单的参数,往往成为项目后期调试阶段的"隐形杀手&qu…...

MemPrivacy:面向端云智能体的隐私保护个性化记忆管理框架
之前文章介绍过:89.2%攻击成功率!腾讯、字节研究发现 OpenClaw Agent 存在可利用结构性漏洞 今天介绍一个 MemPrivacy 项目,来自 MemTensor、荣耀和同济大学的联合团队。 他们的研究让云端智能体能正常"记住你",但永远看…...

进化算法驱动机械爪设计优化:从原理到EvoClaw项目实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“EvoClaw”。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于“进化算法驱动的机械爪设计优化”的开源项目。简单来说,就是利用计算机…...

C语言结构体、枚举、联合体:从内存布局看区别,新手避坑指南
C语言结构体、枚举、联合体:从内存布局看区别,新手避坑指南 在C语言开发中,结构体、枚举和联合体是构建复杂数据模型的三大基石。但很多开发者在实际项目中常遇到这样的困惑:为什么结构体占用的内存比预期大?枚举变量在…...
)
用51单片机和HC-SR04超声波模块DIY一个倒车雷达(附完整代码和立创EDA原理图)
51单片机与HC-SR04超声波模块实战:打造高精度倒车雷达系统 在汽车电子和智能硬件领域,倒车雷达作为基础安全装置,其DIY实现不仅能帮助理解超声波测距原理,更是掌握嵌入式系统开发的绝佳实践。本文将手把手教你使用经典的STC89C52单…...

Rekall:基于时空查询的视频内容智能检索开源框架
1. 项目概述:Rekall,一个面向视频时空查询的开源利器 如果你曾经尝试过从一段长视频里,精准地找出“那个穿红色衣服的人从画面左侧走到右侧的片段”,或者想快速定位“所有出现这只特定宠物狗的镜头”,你就会知道这有多…...

Go语言构建开发者命令行工具箱:navis项目架构与实现解析
1. 项目概述:一个为开发者打造的“导航”工具箱最近在GitHub上看到一个挺有意思的项目,叫navis,作者是NaveenBuidl。光看名字,你可能会联想到“导航”或者“航行”,没错,这个项目的核心定位就是一个为开发者…...

Legacy-iOS-Kit完整指南:如何让老旧iPhone和iPad重获新生
Legacy-iOS-Kit完整指南:如何让老旧iPhone和iPad重获新生 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...

用C++和RealSense D435i搞个3D手势识别?从像素坐标到相机坐标的保姆级避坑指南
3D手势识别实战:用RealSense D435i实现像素到相机坐标的高精度转换 当你的手指在空气中划出一道弧线,计算机能否精准捕捉这个三维动作?这正是3D手势识别技术试图解决的问题。作为人机交互领域的前沿方向,3D手势识别正在VR游戏、医…...

开源AI代码助手实践:从数据到部署的全链路解析
1. 项目概述:从“copaw-code”看AI代码助手的开源实践最近在GitHub上看到一个挺有意思的项目,叫“QSEEKING/copaw-code”。光看这个名字,可能有点摸不着头脑。“copaw”这个词,听起来像是“co-pilot”(副驾驶ÿ…...