ELK安装、部署、调试 (八)logstash配置语法详解
input {#输入插件
}filter {#过滤插件
}output {#输出插件
}1.读取文件。
使用filewatch的ruby gem库来监听文件变化,并通过.sincedb的数据库文件记录被监听日志we年的读取进度(时间
搓)
。sincedb数据文件的默认路径为<path.data>/plugins/inputs/file下面,文件名类似
于.sincedb_234534534sdfgsfd23,<path.data>为logstash的插件存储目录默认是LOGSTASH_HOME/data实验一:本机/var/log/secure为输入日志,标准输出
vi /usr/local/logstash/2logstash-1.confinput {file {path => ["/var/log/messages"],[]type => "ly_system"start_position => "beginning"
#从beginning也就是文件开头进行读取,如果不写,默认是从文件最后开始读取。 #如果不想把文件全部作为输入,就不配置此属性。}
}output {stdout {codec => rubydebug}
}
1.保存10.10.10.74 f-kafka-logs-es.conf的配置信息
[root@localhost logstash]# cat f-kafka-logs-es.conf
input {kafka {bootstrap_servers => "10.10.10.71:9092,10.10.10.72:9092,10.10.10.73:9092"topics => ["osmessages"]}
}
output {elasticsearch {hosts => ["10.10.10.65:9200","10.10.10.66:9200","10.10.10.67:9200"]index => "osmessageslog-%{+YYYY-MM-dd}"}
}2.停止logstash服务
kill -9 13508
3.使用2logstash-1.conf作为配置文件启动logstash
nohup /usr/local/logstash/bin/logstash -f /usr/local/logstash/2logstash-1.conf &4.查看
tail -f nohup.out{"type" => "ly_system","path" => "/var/log/secure","@version" => "1","host" => "localhost.localdomain","message" => "Aug 31 08:43:56 localhost sshd[6920]: Accepted password for root from
172.16.17.234 port 1909 ssh2","@timestamp" => 2023-08-31T00:52:13.054Z
}实验二:input插件添加域和标签
[root@localhost logstash]# cat 2logstash-1.conf
input {file {path => ["/var/log/secure"]type => "ly_system"start_position => "beginning"add_field => {"I'm " => "10.10.10.74"}tags => ["74","logstash1"]
#从beginning也就是文件开头进行读取,如果不写,默认是从文件最后开始读取。
#如果不想把文件全部作为输入,就不配置此属性。
}
}
output {stdout {codec => rubydebug}
}***************************
add_field => {"I'm " => "10.10.10.74"} 添加一个新的域,自己定义的。
tags => ["74","logstash1"] tags是内置的域,可以用来定义标签。
***************************
输出结果
{"@version" => "1","host" => "localhost.localdomain","I'm " => "10.10.10.74","path" => "/var/log/secure","message" => "Aug 31 09:03:33 localhost sshd[14339]: Accepted password for root from
172.16.17.234 port 2684 ssh2","@timestamp" => 2023-08-31T01:03:53.586Z,"type" => "ly_system","tags" => [[0] "74",[1] "logstash1"]
}实验三:input读取syslog日志。
需要完成2个步骤的操作,
1,vi /etc/rsyslog.conf
*.* @@10.10.10.74:5514 #10.10.10.74本机logstash服务器的IP地址,这个配置时使用rsyslog客户端把本机
的日志信息传输到10.10.10.74服务器的5514端口上去。
2.重启rsyslog
systemctl restart rsyslog
logstash配置文件如下:需要先启动,启动后会开启5514端口,用来侦听。
[root@localhost logstash]# cat rsyslog-logstash.conf
input {syslog {port => "5514"}
}
output {stdout {codec => rubydebug}
}
[root@localhost logstash]#查看日志
tail -f nohup.out[2023-08-31T09:51:20,356][INFO ][logstash.inputs.syslog ][main]
[1ac4f1a43da057380f8444a587ee7cb01fe84a0702afb9d46abc9667eeb0ea0c] Starting syslog tcp listener
{:address=>"0.0.0.0:5514"}
[2023-08-31T09:51:20,390][INFO ][logstash.inputs.syslog ][main]
[1ac4f1a43da057380f8444a587ee7cb01fe84a0702afb9d46abc9667eeb0ea0c] Starting syslog udp listener
{:address=>"0.0.0.0:5514"}日志源服务器 10.10.10.56 启动rsyslog客户端
1,vi /etc/rsyslog.conf
*.* @@10.10.10.74:5514 #10.10.10.74本机logstash服务器的IP地址,这个配置时使用rsyslog客户端把本机
的日志信息传输到10.10.10.74服务器的5514端口上去。
2.重启rsyslog
systemctl restart rsyslog[root@node1 ~]# systemctl restart rsyslog[root@node1 ~]# service status rsyslog
The service command supports only basic LSB actions (start, stop, restart, try-restart, reload, force-
reload, status). For other actions, please try to use systemctl.
[root@node1 ~]# systemctl status rsyslog
● rsyslog.service - System Logging ServiceLoaded: loaded (/usr/lib/systemd/system/rsyslog.service; enabled; vendor preset: enabled)Active: active (running) since 四 2023-08-31 10:00:47 CST; 31s agologstash信息输出
{"facility_label" => "system","@version" => "1","timestamp" => "Aug 31 10:02:01","facility" => 3,"host" => "10.10.10.56","logsource" => "node1","priority" => 30,"@timestamp" => 2023-08-31T02:02:01.000Z,"severity" => 6,"severity_label" => "Informational","message" => "Removed slice User Slice of liuyang.\n","program" => "systemd"
}
{"facility_label" => "security/authorization","@version" => "1","timestamp" => "Aug 31 10:02:01","facility" => 10,"host" => "10.10.10.56","logsource" => "node1","priority" => 87,"@timestamp" => 2023-08-31T02:02:01.000Z,"severity" => 7,"severity_label" => "Debug","pid" => "17805","message" => "pam_limits(crond:session): unknown limit item 'noproc'\n","program" => "crond"通过上面的日志输入,发现logstash把接收到的日志进行了详细的划分。会把日志中的时间,主机名,程序,具体信
息拆分成多个字段进行存储。
"timestamp" 为源日志的时间
"@timestamp" 为logstash抓取日志的时间,与上面的时间差了8个小时,这个是时区的配置问题。
**********************************************实验四:读取tcp网络数据
下面的时间配置文件是通过“LogStash::Inputs::TCP”和"LogStash::Filters::Grok"相配合实现实验三rsyslog功能
的日志读取
[root@localhost logstash]# cat tcp-logstash.conf
input {tcp {port => "5514"}
}filter {grok {match => {"message" => "%{SYSLOGLINE}"}}
}output {stdout {codec => rubydebug}
}
[root@l
启动logstash服务
nohup /usr/local/logstash/bin/logstash -f /usr/local/logstash/tcp-logstash.conf &
查看日志
[2023-08-31T10:08:39,596][INFO ][logstash.inputs.tcp ][main]
[e17c63be3a5b12883f975a9f5eaf27f19639714f6267583b2142379ed6c8f22a] Starting tcp input listener
{:address=>"0.0.0.0:5514", :ss l_enable=>"false"}
5514端口已启动
客户端同样适用rsyslog,同上一样的配置
logstash 日志查询
{"port" => 58526,"message" => [[0] "<30>Aug 31 10:17:01 node1 systemd: Started Session 351785 of user liuyang.",[1] "Started Session 351785 of user liuyang."],"program" => "systemd","logsource" => "node1","host" => "10.10.10.56","timestamp" => "Aug 31 10:17:01","@version" => "1","@timestamp" => 2023-08-31T02:10:24.759Z
}
{"port" => 58526,"message" => [[0] "<85>Aug 31 10:17:04 node1 polkitd[1172]: Registered Authentication Agent for unix-
process:20549:1866610077 (system bus name :1.703886 [/usr/bin/pkttyagent --notify-fd 5 --fallback],
object path /org/freedesktop/PolicyKit1/AuthenticationAgent, locale zh_CN.UTF-8)",[1] "Registered Authentication Agent for unix-process:20549:1866610077 (system bus name
:1.703886 [/usr/bin/pkttyagent --notify-fd 5 --fallback], object path
/org/freedesktop/PolicyKit1/AuthenticationAgent, locale zh_CN.UTF-8)"],"program" => "polkitd","logsource" => "node1","pid" => "1172","host" => "10.10.10.56","timestamp" => "Aug 31 10:17:04","@version" => "1","@timestamp" => 2023-08-31T02:10:26.949Z
}
我们可以看出【0】是完整的信息输出
【1】是经过拆分的,如pid 、logsource、 时间、port都进行拆分出来了
tcp方式和rsyslog类似。
******************************************************
实验五 适用nc 的方式将日志导入到logstash
客户端(日志源)10.10.10.56
服务器(logstash)10.10.10.74服务器logstash配置方法如实验四
[root@localhost logstash]# cat tcp-logstash.conf
input {tcp {port => "5514"}
}filter {grok {match => {"message" => "%{SYSLOGLINE}"}}
}output {stdout {codec => rubydebug}
}客户端命令行窗口输入:
nc 10.10.10.74 5514 </var/log/messages
在logstash上查看日志
{"port" => 59322,"message" => [[0] "Aug 27 12:34:57 node1 supervisord: 2023-08-27 12:34:57,594 INFO supervisord started with
pid 4760",[1] "2023-08-27 12:34:57,594 INFO supervisord started with pid 4760"],"program" => "supervisord","logsource" => "node1","host" => "10.10.10.56","timestamp" => "Aug 27 12:34:57","@version" => "1","@timestamp" => 2023-08-31T02:16:27.986Z
}
{"port" => 59322,"message" => [[0] "Aug 27 12:34:58 node1 supervisord",[1] "supervisord"],"logsource" => "node1","host" => "10.10.10.56","timestamp" => "Aug 27 12:34:58","@version" => "1","@timestamp" => 2023-08-31T02:16:27.992Z
}
完成实验。
实验六 编码插件codec
此插件可以放到输入和输出时来处理数据
input -> decode --> filter --> decode --->output decode就是使用codec进行编码
codec支持plain 、json、json_lines等格式。
1.codec插件之plain
plain是一个空解释器,输入什么格式,输出就是什么格式
[root@localhost logstash]# vi codec1-logstash.log
input {stdin { }
}output {stdout {codec => "plain"
#前面的测试我们都使用rubydebug编码,此编码会以json的格式进行输出}
}
[root@localhost logstash]# vi codec1-logstash.log
[root@localhost logstash]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/codec1-logstash.log
此处不能用nohup,否则抓取不到
hello #我用键盘输入的,下面的信息是logstash的输出。
2023-08-31T02:28:31.068Z localhost.localdomain hello
nihao
2023-08-31T02:28:37.572Z localhost.localdomain nihao
仅增加了2个字段一个是时间戳,一个是主机名和以前使用rubydebug的日志来对比一下
hello #我用键盘输入的,下面的信息是logstash的输出。
{"message" => "hello","@version" => "1","host" => "localhost.localdomain","@timestamp" => 2023-08-29T02:22:53.965Z
}2.codec插件之json
发送给logstash的数据如果是json格式的,那必须在input字段加入codec=> json来解析进来的数据,
如果想让logstash输出为json的格式,可以在output字段加入codec=>json,
[root@localhost logstash]# vi codec2-logstash.log
input {stdin { }
}output {stdout {codec => "json" #以json的格式 输出}
}
json模式就是key:values格式
3.codec插件之json_lines
若果json文件比较长,需要换行的话,就会使用json_lines编码格式。
实验七 过滤器插件filter
1.grok正则捕获
grok是一个强大的filter插件,通过正则解析任意文本文件,将非结构化的数据弄成结构化的数据,方便查询。
https://help.aliyun.com/zh/sls/user-guide/grok-patterns
GROK的模式参考及示例
grok的语法规则
%{语法:语义}
语法指的就是匹配模式,例如使用number模式可以匹配数字,ip模式会匹配出127.0.0.1样式的IP地址
例如1.输入内容为:172.16.213.132 [07/Feb/2018:16:24:19 +0800]"GET / HTTP/ 1.1" 403 5039
那么,%{IP:clientip} IP就是语法,要匹配IP地址, clientip为内容
匹配的结果为clientip:172.16.213.132
例如2:
%{HTTPDATE:timestamp}结果为07/feb/2018:16:24 +800
例如3:
%{QS:referrer}匹配的结果
GET / HTTP/ 1.1
以上IP\ Httpdate 、QS都是grok内部定义好的模式,
/usr/local/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns
[root@localhost patterns]# ls
aws bind exim grok-patterns httpd junos maven mcollective-patterns nagios
rails ruby
bacula bro firewalls haproxy java linux-syslog mcollective mongodb
postgresql redis squid
[
这个目录下,有很多匹配模式,我们可以直接拿来应用,其中grok-patterns使我们使用的基础匹配模式
vi grok-patterns
显示一小段内容如下:
IPV6 ((([0-9A-Fa-f]{1,4}:){7}([0-9A-Fa-f]{1,4}|:))|(([0-9A-Fa-f]{1,4}:){6}(:[0-9A-Fa-f]{1,4}|((25[0-
5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){5}(((:[0
-9A-Fa-f]{1,4}){1,2})|:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d))
{3})|:))|(([0-9A-Fa-f]{1,4}:){4}(((:[0-9A-Fa-f]{1,4}){1,3})|((:[0-9A-Fa-f]{1,4})?:((25[0-5]|2[0-4]\d|
1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){3}(((:[0-9A-Fa-f]
{1,4}){1,4})|((:[0-9A-Fa-f]{1,4}){0,2}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1
-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){2}(((:[0-9A-Fa-f]{1,4}){1,5})|((:[0-9A-Fa-f]{1,4}){0,3}:((25[0-
5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){1}(((:
[0-9A-Fa-f]{1,4}){1,6})|((:[0-9A-Fa-f]{1,4}){0,4}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-
4]\d|1\d\d|[1-9]?\d)){3}))|:))|(:(((:[0-9A-Fa-f]{1,4}){1,7})|((:[0-9A-Fa-f]{1,4}){0,5}:((25[0-5]|2[0-
4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:)))(%.+)?
IPV4 (?<![0-9])(?:(?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])
[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5]))(?![0-9])
IP (?:%{IPV6}|%{IPV4})grok在线调试工具,
网址:grokdebug.herokuapp.com 可能需要翻墙
https://www.5axxw.com/tools/v2/grok.html
以上两个都不好使
自己在docker上搭建一个
10.10.10.56上安装了docker
docker pull epurs/grokdebugger:latest
docker images
docker run -d --name grokdebugger -p 8082:80 epurs/grokdebugger
http://10.10.10.56:8082
input输入日志
pattern为模式
[root@localhost logstash]# vi grok1-logstash.log
input {stdin { }
}filter {grok {match => ["message","%{IP:clientip}"]}
}output {stdout {codec => "rubydebug" }
}
[root@localhost logstash]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/grok1-logstash.log
172.16.213.132 [07/Feb/2018:16:24:19 +0800]"GET / HTTP/ 1.1" 403 5039 #输入
{输出为:"clientip" => "172.16.213.132","@timestamp" => 2023-08-31T07:36:18.564Z,"@version" => "1","message" => "172.16.213.132 [07/Feb/2018:16:24:19 +0800]\"GET / HTTP/ 1.1\" 403 5039","host" => "localhost.localdomain"
测试2:
[root@localhost logstash]# vi grok2-logstash.log
input {stdin { }
}filter {grok {match => ["message","%{IP:client-ip} \[%{HTTPDATE:timestamp1}\]%{QS:refer}\ %{NUMBER:nu}
%{NUMBER:bytes1}"]}
}output {stdout {codec => "rubydebug" }
}
输出为:
172.16.213.132 [07/Feb/2018:16:24:19 +0800]"GET / HTTP/ 1.1" 403 5039
{"host" => "localhost.localdomain","timestamp1" => "07/Feb/2018:16:24:19 +0800","refer" => "\"GET / HTTP/ 1.1\"","nu" => "403","@version" => "1","message" => "172.16.213.132 [07/Feb/2018:16:24:19 +0800]\"GET / HTTP/ 1.1\" 403 5039","@timestamp" => 2023-08-31T07:46:51.778Z,"bytes1" => "5039","client-ip" => "172.16.213.132"
我们已将看到message已经分成5部分了,原有的message可以去掉了,系统中存在连个timestamp,其实@timestamp也
不需要了,这个时间是收集日志的时间。而kibana使用@timestamp这个字段来排序。我们可以将timestamp的值付给
@timestamp
[root@localhost logstash]# vi grok-delete-logstash.log
input {stdin {}
}filter {grok {match => ["message","%{IP:client-ip} \[%{HTTPDATE:timestamp1}\]%{QS:refer}\ %{NUMBER:nu}
%{NUMBER:bytes1}"]remove_field => ["message"]}date {match => ["timestamp1","dd/mmm/yyyy:HH:mm:ss Z"]}mutate {remove_field => ["timestamp1"]}}output {stdout {codec => "rubydebug"}
}输出结果
172.16.213.132 [07/Feb/2018:16:24:19 +0800]"GET / HTTP/ 1.1" 403 5039
{"@timestamp" => 2023-08-31T08:16:31.119Z,"refer" => "\"GET / HTTP/ 1.1\"","nu" => "403","host" => "localhost.localdomain","client-ip" => "172.16.213.132","tags" => [[0] "_dateparsefailure"],"bytes1" => "5039","@version" => "1"以上使用了grok、date、mutate插件
时间处理模式 DATE
date插件 就是将值以什么格式赋值给@timestamp
date {
match => ["timestamp1","dd/mmm/yyyy:HH:mm:ss Z"]
}
将timestamp1按照后边dd/mmm/yyyy:HH:mm:ss Z的格式赋值给@timestamp
数据修改插件 mutate
1.正则表达式替换匹配字段
gsub可以通过正则表达式替换字段中匹配到的值,只对字符串段有效,例子
filter {
mutate {
gsub => ["filed_name_1","/","_"]
#表示将field_name_1属性的字段中所有"/"字符替换成"_"
}
}
实例:[root@localhost logstash]# cat grok-mutate-logstash.log input {
stdin {}
}filter {grok {match => ["message","%{IP:client-ip} \[%{HTTPDATE:timestamp1}\]%{QS:refer}\ %{NUMBER:nu}
%{NUMBER:bytes1}"]}date {match => ["timestamp1","dd/mmm/yyyy:HH:mm:ss Z"]}mutate {gsub => ["message","/","_"]}}output {stdout {codec => "rubydebug"}
}/usr/local/logstash/bin/logstash -f /usr/local/logstash/grok-mutate-logstash.log
172.16.213.132 [07/Feb/2018:16:24:19 +0800]"GET / HTTP/ 1.1" 403 5039
{"refer" => "\"GET / HTTP/ 1.1\"","tags" => [[0] "_dateparsefailure"],"client-ip" => "172.16.213.132","bytes1" => "5039","message" => "172.16.213.132 [07_Feb_2018:16:24:19 +0800]\"GET _ HTTP_ 1.1\" 403 5039","@timestamp" => 2023-08-31T08:35:00.815Z,"@version" => "1","host" => "localhost.localdomain","nu" => "403","timestamp1" => "07/Feb/2018:16:24:19 +0800"
}
看到"/"都替换成了"_"
2.分隔字符串为数组
split用分隔符分隔字符串为数组
filter {mutate {split => ["filed_name_2","|"]
#表示将field_name_1属性的字段中所有"/"字符替换成"_"}
}172.16.213.132|[07/Feb/2018:16:24:19 +0800]|"GET / HTTP/ 1.1"|403|5039
实例:
[root@localhost logstash]# cat grok-mutate2-logstash.log
input {stdin {}
}filter {grok {match => ["message","%{IP:client-ip} \[%{HTTPDATE:timestamp1}\]%{QS:refer}\ %{NUMBER:nu}
%{NUMBER:bytes1}"]}date {match => ["timestamp1","dd/mmm/yyyy:HH:mm:ss Z"]}mutate {split => ["message","|"]}}output {stdout {codec => "rubydebug"}
}
结果:
/usr/local/logstash/bin/logstash -f /usr/local/logstash/grok-mutate2-logstash.log172.16.213.132|[07/Feb/2018:16:24:19 +0800]|"GET / HTTP/ 1.1"|403|5039
{"message" => [[0] "172.16.213.132",[1] "[07/Feb/2018:16:24:19 +0800]",[2] "\"GET / HTTP/ 1.1\"",[3] "403",[4] "5039"],"@timestamp" => 2023-08-31T08:39:17.562Z,"host" => "localhost.localdomain","@version" => "1","tags" => [[0] "_grokparsefailure"]
}
我们发现message的信息分成了5部分,以后调用以数组的形式调用
3.重命名字段rename
mutate {
rename => {"message","message_new"}
}
}
实例略
4.删除字段remove_field
mutate {
remove_field => ["message"]
}
}
综合实例:
mutate {
rename => {"nu","number"}
gsub => ["refer","/","_"]
remove_field => ["timestamp1"]
split => ["client-ip","."]
}
重命名 替换 删除 分隔都可以写在一起。
Geoip地址查询归类
geoIP是免费的ip地址归类查询库,可以通过IP地址提供对应的地域信息,包括国别,省市,经纬度等,此插件对可视
化地图和区域统计非常有用。
filter {
geoip {
source => "ip_field"
# ip_field字段是输出ip地址的一个字段
}
}
实例:
logstash配置[root@localhost logstash]# cat grok-geoip.log
input {stdin {}
}filter {grok {match => ["message","%{IP:client-ip} \[%{HTTPDATE:timestamp1}\]%{QS:refer}\ %{NUMBER:nu}
%{NUMBER:bytes1}"]}date {match => ["timestamp1","dd/mmm/yyyy:HH:mm:ss Z"]}geoip {source => "client-ip"}
}output {stdout {codec => "rubydebug"}
}172.16.213.132 [07/Feb/2018:16:24:19 +0800]"GET / HTTP/ 1.1" 403 5039
114.114.114.114 [07/Feb/2018:16:24:19 +0800]"GET / HTTP/ 1.1" 403 5039
输出结果:
202.97.224.68 [07/Feb/2018:16:24:19 +0800]"GET / HTTP/ 1.1" 403 5039
{"timestamp1" => "07/Feb/2018:16:24:19 +0800","bytes1" => "5039","geoip" => {"latitude" => 45.75,"region_name" => "Heilongjiang","country_code2" => "CN","country_name" => "China","longitude" => 126.65,"location" => {"lon" => 126.65,"lat" => 45.75},"country_code3" => "CN","region_code" => "HL","continent_code" => "AS","ip" => "202.97.224.68","timezone" => "Asia/Shanghai"},"message" => "202.97.224.68 [07/Feb/2018:16:24:19 +0800]\"GET / HTTP/ 1.1\" 403 5039","@timestamp" => 2023-09-01T01:27:01.443Z,"client-ip" => "202.97.224.68","refer" => "\"GET / HTTP/ 1.1\"","nu" => "403","@version" => "1","host" => "localhost.localdomain","tags" => [[0] "_dateparsefailure"]
}longitude latitude 经纬度
以上信息有些多,想精简一些
精简geoip信息
geoip {
source => "client-ip"
fields => ["ip","country_code3","longitude","latitude","region_name"]
#仅将需要保留的域显示出来
}[root@localhost logstash]# cat grok-geoip2.log
input {stdin {}
}filter {grok {match => ["message","%{IP:client-ip} \[%{HTTPDATE:timestamp1}\]%{QS:refer}\ %{NUMBER:nu}
%{NUMBER:bytes1}"]}date {match => ["timestamp1","dd/mmm/yyyy:HH:mm:ss Z"]}geoip {source => "client-ip"fields => ["ip","country_code3","longitude","latitude","region_name"]}
}output {stdout {codec => "rubydebug"}
}输出结果:
202.97.224.68 [07/Feb/2018:16:24:19 +0800]"GET / HTTP/ 1.1" 403 5039
{"nu" => "403","@timestamp" => 2023-09-01T01:30:39.227Z,"@version" => "1","tags" => [[0] "_dateparsefailure"],"geoip" => {"ip" => "202.97.224.68","country_code3" => "CN","latitude" => 45.75,"region_name" => "Heilongjiang","longitude" => 126.65},"message" => "202.97.224.68 [07/Feb/2018:16:24:19 +0800]\"GET / HTTP/ 1.1\" 403 5039","client-ip" => "202.97.224.68","host" => "localhost.localdomain","refer" => "\"GET / HTTP/ 1.1\"","timestamp1" => "07/Feb/2018:16:24:19 +0800","bytes1" => "5039"
}logstash的输出插件output
file 将数据写入磁盘文件
elasticsearch :把日志数据发送到es集群
graphite:用于存储和绘制数据指标
还支持输出到redis,email,exec,ngios等等
1.标准输出
output {
stdout {
codec => "rubydebug"
}
}
2.保存到文件
output {
file {
path => "/data/log3/%{+yyyy-MM-dd}/%{host}_%{+HH}.log"
}
}
例子:
[root@localhost logstash]# cat file-log.log
input {stdin {}
}
output {file {path => "/data/log3/%{+yyyy-MM-dd}/%{host}_%{+HH}.log"}
}
/usr/local/logstash/bin/logstash -f /usr/local/logstash/file-log.log
标准输入信息后
114.114.114.114 [07/Feb/2018:16:24:19 +0800]\"GET / HTTP/ 1.1\" 403 5039
asdfasdf
/data/log3/2023-09-01/下文件内容:
[root@localhost 2023-09-01]# cat localhost.localdomain_01.log
{"@timestamp":"2023-09-01T01:57:05.295Z","message":"114.114.114.114 [07/Feb/2018:16:24:19 +0800]\"GET /
HTTP/ 1.1\" 403 5039","host":"localhost.localdomain","@version":"1"}
[root@localhost 2023-09-01]# tail -f localhost.localdomain_01.log
{"@timestamp":"2023-09-01T01:57:05.295Z","message":"114.114.114.114 [07/Feb/2018:16:24:19 +0800]\"GET /
HTTP/ 1.1\" 403 5039","host":"localhost.localdomain","@version":"1"}
{"@timestamp":"2023-09-
01T01:57:53.440Z","message":"asdfasdf","host":"localhost.localdomain","@version":"1"}我们发现输出的内容会在输入的内容上加了一些信息,如@timestamp @version host等属性
如果要让输入和输出一样。我们需要使用codec来格式编码
logstash配置
[root@localhost logstash]# cat file2-log.log
input {stdin {}
}
output {file {path => "/data/log3/%{+yyyy-MM-dd}/%{host}_%{+HH}.log"codec => line { format => "%{message}"}}
}
[root@localhost logstash]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/file2-log.log
标准输入
adfasdfasdf
ELK大规模日志实时处理系统从入门到企业应用实战视频课程
查看输出:
[root@localhost 2023-09-01]# tail -f localhost.localdomain_02.log
adfasdfasdf
ELK大规模日志实时处理系统从入门到企业应用实战视频课程
[root@localhost 2023-09-01]# pwd
/data/log3/2023-09-01
[root@localhost 2023-09-01]#
输出与输入一致了。
八 ELK手机apache访问日志的案例
elk收集日子的几种方法
1.不修改源日志的输出格式,而是通过logstash的grok方式进行过滤、清晰,然后输出
优点,对业务系统无影响,缺点是logstash可能会有瓶颈。
2.修改源日志的输出格式,按要求的格式改变源日志格式进行输出,logstash仅收集和传输。
优点:减轻了logstash的压力,但是需要一定的工作量去处理源日志格式。
elk收集apache日志应用架构
apache(filebeat) -- kafka(zookeeper) -- logstash -- ES集群
使用第二种方式,用改变源日志输出格式来处理。
相关文章:
logstash配置语法详解)
ELK安装、部署、调试 (八)logstash配置语法详解
input {#输入插件 }filter {#过滤插件 }output {#输出插件 } 1.读取文件。 使用filewatch的ruby gem库来监听文件变化,并通过.sincedb的数据库文件记录被监听日志we年的读取进度(时间 搓) 。sincedb数据文件的默认路径为<path.data>/…...
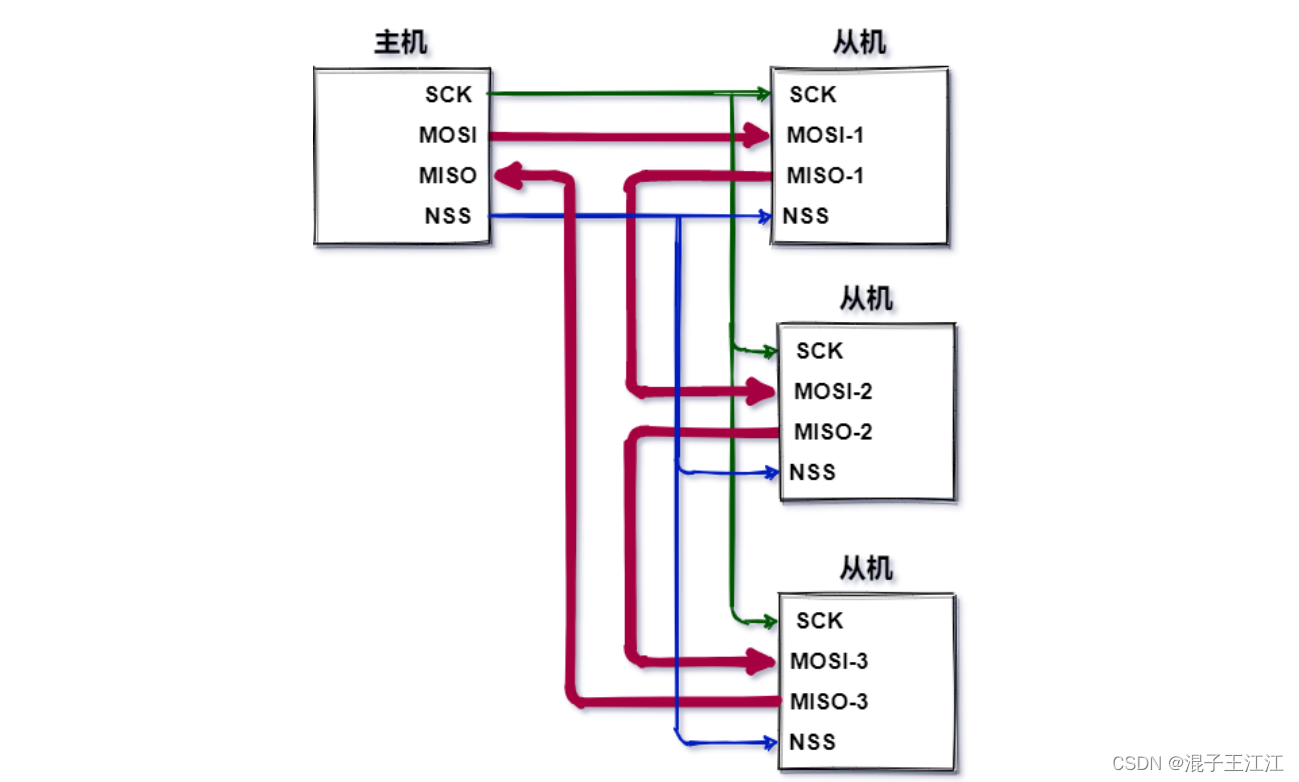
SPI协议
文章目录 前言一、简介1、通信模式2、总线定义3、SPI通信结构4、SPI通讯时序5、SPI数据交互过程 二、多从机模式1、多NSS2、菊花链3、SPI通信优缺点4、UART、IIC、SPI 区别 三、总结四、参考资料 前言 SPI协议是我们的重要通信协议之一,我们需要掌握牢靠。 一、简介…...

机器学习算法系列————决策树(二)
1.什么是决策树 用于解决分类问题的一种算法。 左边是属性,右边是标签。 属性选择时用什么度量,分别是信息熵和基尼系数。 这里能够做出来特征的区分。 下图为基尼系数为例进行计算。 下面两张图是对婚姻和年收入的详细计算过程(为GINI系…...

ACM中的数论
ACM中的数论是计算机科学领域中的一个重要分支,它主要研究整数的性质、运算规律和它们之间的关系。在ACM竞赛中,数论问题经常出现,因此掌握一定的数论知识对于参加ACM竞赛的选手来说是非常重要的。本文将介绍一些常见的数论概念和方法&#x…...
我的创作纪念日 —— 一年之期
前言 大家好!我是荔枝嘿~看到官方私信才发现原来时间又过去了一年,荔枝也在CSDN中创作满一年啦,虽然中间因为种种原因并没有经常输出博文哈哈,但荔枝一直在坚持创作嘿嘿。记得去年的同一时间我也同样写了一篇总结文哈哈哈&#x…...
qt.qpa.plugin:找不到Qt平台插件“wayland“|| (下载插件)Ubuntu上解决方案
相信大家也都知道这个地方应该做什么,当然是下载这个qt平台的插件wayland,但是很多人可能不知道怎么下载这个插件。 那么我现在要说的这个方法就是针对这种的。 sudo apt install qtwayland5完事儿了奥兄弟们。 看看效果 正常了奥。...

详解Spring Boot中@PostConstruct的使用
PostConstruct 在Java中,PostConstruct是一个注解,通常用于标记一个方法,它表示该方法在类实例化之后(通过构造函数创建对象之后)立即执行。 加上PostConstruct注解的方法会在对象的所有依赖项都已经注入完成之后执行…...

判断子序列
判断子序列 题目: 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"…...
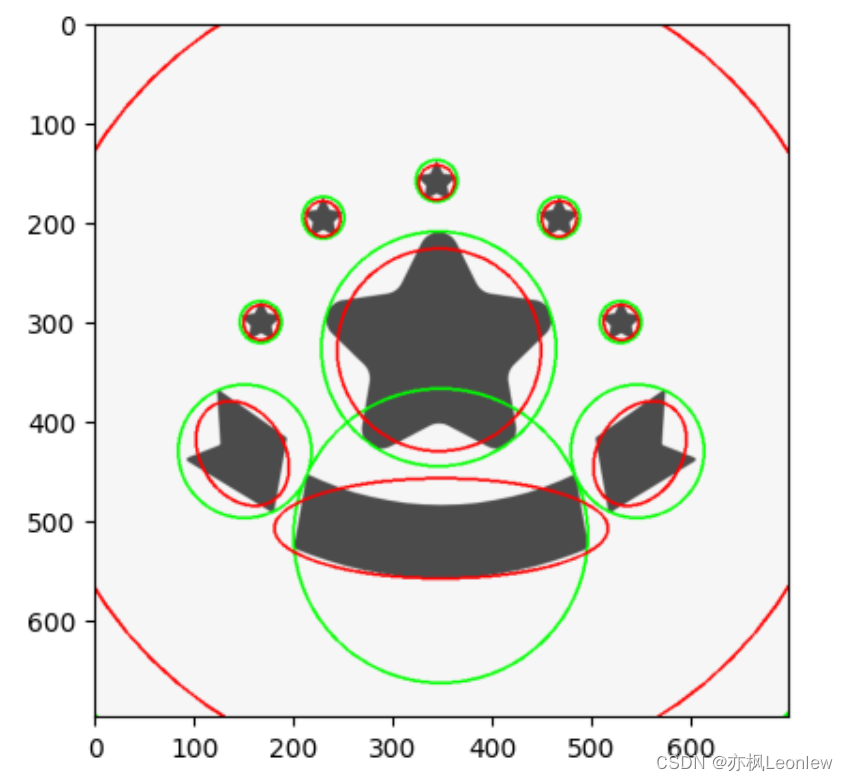
Python Opencv实践 - 轮廓特征(最小外接圆,椭圆拟合)
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/stars.PNG") plt.imshow(img[:,:,::-1])#轮廓检测 img_gray cv.cvtColor(img, cv.COLOR_BGR2GRAY) ret,thresh cv.threshold(img_gray, 127, 255, 0) contou…...

Ubuntu22.04 LTS+NVIDIA 4090+Cuda12.1+cudnn8.8.1
系统环境中: 1.系统驱动安装的是: NVIDIA-Linux-x86_64-530.30.02.run 2.CUDA安装:cuda_12.1.0_530.30.02_linux.run(无需第1步,直接安装它就带配套驱动) wget https://developer.download.nvidia.com/…...
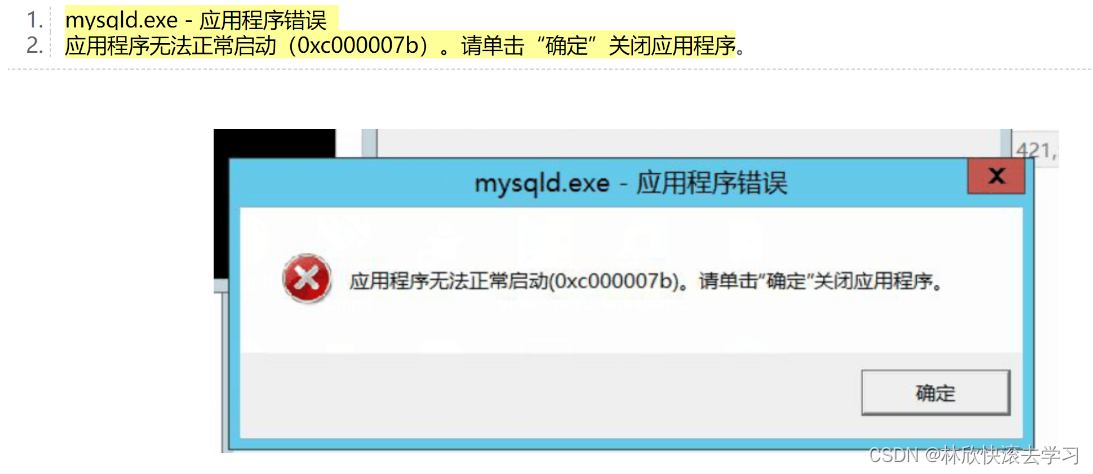
重装系统后,MySQL install错误,找不到dll文件,或者应用程序错误
文章目录 1.找不到某某dll文件2.mysqld.exe - 应用程序错误使用DX工具直接修复 1.找不到某某dll文件 由于找不到VCRUNTIME140_1.dll或者MSVCP120.dll,无法继续执行代码,重新安装程序可能会解决此问题。 在使用一台重装系统过的电脑,再次重新…...
线程同步机制类封装及线程池实现
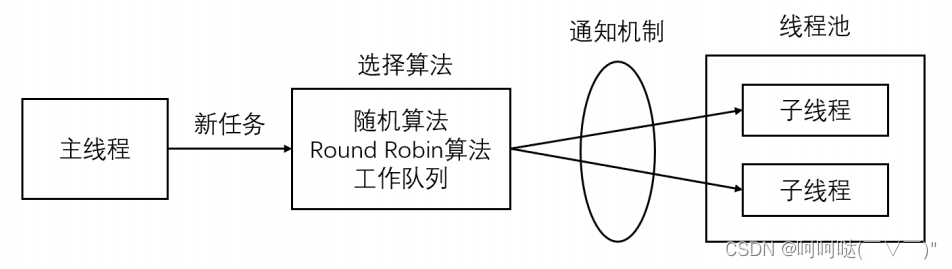
1.线程池 线程池是由服务器预先创建的一组子线程,线程池中的线程数量应该和 CPU 数量差不多。线程池中的所有子线程都运行着相同的代码。当有新的任务到来时,主线程将通过某种方式选择线程池中的某一个子线程来为之服务。相比与动态的创建子线程&#x…...

Linux中的用户、组和权限
一,Linux的安全模型 1.安全3A Authentication(认证),Authorization(授权),Accounting(审计)(AAA)是用于对计算机资源的访问、策略执行、审计使用情况和提供服务账单所需信息等功能进行智能控制的基本组件的一个术语。大多数人认为这三个组合的过程对有效的网络管理和…...

python学习--基本数据类型之字典
python中数据类型 第一类:不可变类型、静态数据类型、不支持增删改操作 数字(number)字符串(string)元组(tuple) 第二类:可变类型、动态数据类型、支持增删改操作 列表ÿ…...
【OpenCV入门】第九部分——模板匹配
文章结构 模板匹配方法单模板匹配单目标匹配多目标匹配 多模板匹配 模板匹配方法 模板是被查找的图像。模板匹配是指查找模板在原始图像中的哪个位置的过程。 result cv2.matchTemplate(image, templ, method, mask)image: 原始图像templ: 模板图像&a…...

在设计web页面时,为移动端设计一套页面,PC端设计一套页面,并且能自动根据设备类型来选择是用移动端的页面还是PC端的页面。
响应式设计,即移动端和PC端共用一个HTML模式,网站的程序和模板自动根据设备类型和屏幕大小进行自适应调整。这种方法我不喜欢,原因是不能很好保证各种客户端的效果,里面存在各种复杂的兼容性等问题。 我喜欢为不同的客户端写不同的…...
微信小程序地图应用总结版
1.应用场景:展示公司位置,并打开第三方app(高德,腾讯)导航到目标位置。 (1)展示位置地图 uniapp官网提供了相关组件,uniapp-map组件https://uniapp.dcloud.net.cn/component/map.ht…...
分支创建查看切换
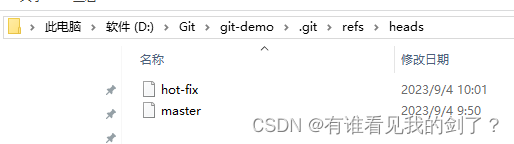
1、初始化git目录,创建文件并将其推送到本地库 git init echo "123" > hello.txt git add hello.txt git commit -m "first commit" hello.txt$ git init Initialized empty Git repository in D:/Git/git-demo/.git/ AdministratorDESKT…...

参编三大金融国标,奇富科技以技术促行业规范化演进
近期,由中国互联网金融协会领导制定的《互联网金融智能风险防控技术要求》《互联网金融个人网络消费信贷信息披露》《互联网金融个人身份识别技术要求》三项国家标准颁布,由国家市场监督管理总局、国家标准化管理委员会发布,奇富科技作为核心…...

芯片开发之难如何破解?龙智诚邀您前往DR IP-SoC China 2023 Day
2023年9月6日(周三),龙智即将亮相D&R IP-SoC China 2023 Day,呈现集成了Perforce与Atlassian产品的芯片开发解决方案,助力企业更好、更快地进行芯片开发。 龙智资深顾问、技术支持部门负责人李培将带来主题演讲—…...

3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南
3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否厌倦了每次运行AutoHotkey脚本都需要安…...

Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案
Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为游戏内置分辨率选项太少而烦恼?是否想在窗口模式下获得全屏游戏…...

STM32F407通过SPI接口高效读写SD卡:CubeMX配置与底层驱动实战
1. SD卡基础与SPI通信原理 SD卡作为嵌入式系统中最常用的存储介质之一,其SPI模式因其接线简单、协议清晰而广受欢迎。先说说我实际项目中遇到的坑:曾经因为没理解清楚SPI模式下SD卡的初始化时序,导致整整两天卡在设备无法识别的困境里。 SD卡…...

基于AI智能体的渗透测试框架:从自动化到智能协同的范式转变
1. 项目概述:一个面向渗透测试的智能体框架最近在整理自己的工具链时,发现了一个挺有意思的项目,叫GH05TCREW/pentestagent。乍一看这个名字,你可能会觉得这又是一个“缝合怪”式的自动化渗透工具,把Nmap、SQLmap之类的…...
)
【稀缺首发】Midjourney达达主义风格提示工程白皮书:含89组对比实验数据+12个独家种子编号(限前500名下载)
更多请点击: https://intelliparadigm.com 第一章:达达主义在AI图像生成中的哲学解构 达达主义并非技术流派,而是一场对逻辑、秩序与意义权威的激进质疑——这一精神正悄然渗透至当代AI图像生成的核心机制中。当Stable Diffusion接收“一只会…...

树莓派扩展板EYESPI Pi Beret:简化硬件连接,加速原型开发
1. 项目概述:为什么我们需要EYESPI Pi Beret?玩树莓派的朋友,尤其是喜欢捣鼓屏幕和传感器的,肯定都经历过那个阶段:面对一堆杜邦线,对照着屏幕驱动板的引脚定义,一个个数着树莓派的GPIO针脚&…...

基于MCP协议构建AI编程助手:unloop-mcp文件系统服务器实战指南
1. 项目概述:一个面向开发者的“解循环”MCP服务器最近在GitHub上看到一个挺有意思的项目,叫Escapepaleolithic247/unloop-mcp。光看这个名字,可能有点摸不着头脑,但如果你是一个经常和AI助手(比如Claude、Cursor等&am…...

柔性3D打印与生物仿生设计:从TPU材料到空气喷涂的完整实践
1. 项目概述:当柔性3D打印遇上生物仿生美学如果你和我一样,玩3D打印玩久了,总会对那些千篇一律的硬质塑料件感到一丝审美疲劳。我们总在追求更高的精度、更强的结构,却常常忽略了材料本身可以带来的、截然不同的体验。直到我开始接…...

Linux权限继承与umask配置实践
Linux权限继承与umask配置实践很多协作目录问题并不是因为当前权限错了,而是因为新建文件的默认权限总是不符合预期。背后的核心变量之一就是 umask。中级阶段如果不理解默认权限是怎么生成的,就会陷入“每次都手工 chmod”的低效循环。一、默认权限不是…...

轻量级协作平台设计:集成Git与敏捷开发的项目管理实践
1. 项目概述与核心价值最近在团队协作和项目管理工具选型上,又和几个技术负责人聊了一圈。大家普遍的感受是,市面上的工具要么太重,像Jira、Confluence,配置复杂,学习成本高,小团队用起来像“杀鸡用牛刀”&…...