java面试题-Redis相关面试题
Redis相关面试题
面试官:什么是缓存穿透 ? 怎么解决 ?
候选人:
嗯~~,我想一下
缓存穿透是指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,可能导致 DB 挂掉。这种情况大概率是遭到了攻击。
解决方案的话,我们通常都会用布隆过滤器来解决它
面试官:好的,你能介绍一下布隆过滤器吗?
候选人:
嗯,是这样~
布隆过滤器主要是用于检索一个元素是否在一个集合中。我们当时使用的是redisson实现的布隆过滤器。
它的底层主要是先去初始化一个比较大数组,里面存放的二进制0或1。在一开始都是0,当一个key来了之后经过3次hash计算,模于数组长度找到数据的下标然后把数组中原来的0改为1,这样的话,三个数组的位置就能标明一个key的存在。查找的过程也是一样的。
当然是有缺点的,布隆过滤器有可能会产生一定的误判,我们一般可以设置这个误判率,大概不会超过5%,其实这个误判是必然存在的,要不就得增加数组的长度,其实已经算是很划分了,5%以内的误判率一般的项目也能接受,不至于高并发下压倒数据库。
面试官:什么是缓存击穿 ? 怎么解决 ?
候选人:
嗯!!
缓存击穿的意思是对于设置了过期时间的key,缓存在某个时间点过期的时候,恰好这时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把 DB 压垮。
解决方案有两种方式:
第一可以使用互斥锁:当缓存失效时,不立即去load db,先使用如 Redis 的 setnx 去设置一个互斥锁,当操作成功返回时再进行 load db的操作并回设缓存,否则重试get缓存的方法
第二种方案可以设置当前key逻辑过期,大概是思路如下:
①:在设置key的时候,设置一个过期时间字段一块存入缓存中,不给当前key设置过期时间
②:当查询的时候,从redis取出数据后判断时间是否过期
③:如果过期则开通另外一个线程进行数据同步,当前线程正常返回数据,这个数据不是最新
当然两种方案各有利弊:
如果选择数据的强一致性,建议使用分布式锁的方案,性能上可能没那么高,锁需要等,也有可能产生死锁的问题
如果选择key的逻辑删除,则优先考虑的高可用性,性能比较高,但是数据同步这块做不到强一致。
面试官:什么是缓存雪崩 ? 怎么解决 ?
候选人:
嗯!!
缓存雪崩意思是设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB 瞬时压力过重雪崩。与缓存击穿的区别:雪崩是很多key,击穿是某一个key缓存。
解决方案主要是可以将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
面试官:redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
候选人:嗯!就说我最近做的这个项目,里面有xxxx(根据自己的简历上写)的功能,需要让数据库与redis高度保持一致,因为要求时效性比较高,我们当时采用的读写锁保证的强一致性。
我们采用的是redisson实现的读写锁,在读的时候添加共享锁,可以保证读读不互斥,读写互斥。当我们更新数据的时候,添加排他锁,它是读写,读读都互斥,这样就能保证在写数据的同时是不会让其他线程读数据的,避免了脏数据。这里面需要注意的是读方法和写方法上需要使用同一把锁才行。
面试官:那这个排他锁是如何保证读写、读读互斥的呢?
候选人:其实排他锁底层使用也是setnx,保证了同时只能有一个线程操作锁住的方法
面试官:你听说过延时双删吗?为什么不用它呢?
候选人:延迟双删,如果是写操作,我们先把缓存中的数据删除,然后更新数据库,最后再延时删除缓存中的数据,其中这个延时多久不太好确定,在延时的过程中可能会出现脏数据,并不能保证强一致性,所以没有采用它。
面试官:redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
候选人:嗯!就说我最近做的这个项目,里面有xxxx(根据自己的简历上写)的功能,数据同步可以有一定的延时(符合大部分业务)
我们当时采用的阿里的canal组件实现数据同步:不需要更改业务代码,部署一个canal服务。canal服务把自己伪装成mysql的一个从节点,当mysql数据更新以后,canal会读取binlog数据,然后在通过canal的客户端获取到数据,更新缓存即可。
面试官:redis做为缓存,数据的持久化是怎么做的?
候选人:在Redis中提供了两种数据持久化的方式:1、RDB 2、AOF
面试官:这两种持久化方式有什么区别呢?
候选人:RDB是一个快照文件,它是把redis内存存储的数据写到磁盘上,当redis实例宕机恢复数据的时候,方便从RDB的快照文件中恢复数据。
AOF的含义是追加文件,当redis操作写命令的时候,都会存储这个文件中,当redis实例宕机恢复数据的时候,会从这个文件中再次执行一遍命令来恢复数据
面试官:这两种方式,哪种恢复的比较快呢?
候选人:RDB因为是二进制文件,在保存的时候体积也是比较小的,它恢复的比较快,但是它有可能会丢数据,我们通常在项目中也会使用AOF来恢复数据,虽然AOF恢复的速度慢一些,但是它丢数据的风险要小很多,在AOF文件中可以设置刷盘策略,我们当时设置的就是每秒批量写入一次命令
面试官:Redis的数据过期策略有哪些 ?
候选人:
嗯~,在redis中提供了两种数据过期删除策略
第一种是惰性删除,在设置该key过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key。
第二种是 定期删除,就是说每隔一段时间,我们就对一些key进行检查,删除里面过期的key
定期清理的两种模式:
- SLOW模式是定时任务,执行频率默认为10hz,每次不超过25ms,以通过修改配置文件redis.conf 的 hz 选项来调整这个次数
- FAST模式执行频率不固定,每次事件循环会尝试执行,但两次间隔不低于2ms,每次耗时不超过1ms
Redis的过期删除策略:惰性删除 + 定期删除两种策略进行配合使用。
面试官:Redis的数据淘汰策略有哪些 ?
候选人:
嗯,这个在redis中提供了很多种,默认是noeviction,不删除任何数据,内部不足直接报错
是可以在redis的配置文件中进行设置的,里面有两个非常重要的概念,一个是LRU,另外一个是LFU
LRU的意思就是最少最近使用,用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
LFU的意思是最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高
我们在项目设置的allkeys-lru,挑选最近最少使用的数据淘汰,把一些经常访问的key留在redis中
面试官:数据库有1000万数据 ,Redis只能缓存20w数据, 如何保证Redis中的数据都是热点数据 ?
候选人:
嗯,我想一下~~
可以使用 allkeys-lru (挑选最近最少使用的数据淘汰)淘汰策略,那留下来的都是经常访问的热点数据
面试官:Redis的内存用完了会发生什么?
候选人:
嗯~,这个要看redis的数据淘汰策略是什么,如果是默认的配置,redis内存用完以后则直接报错。我们当时设置的 allkeys-lru 策略。把最近最常访问的数据留在缓存中。
面试官:Redis分布式锁如何实现 ?
候选人:嗯,在redis中提供了一个命令setnx(SET if not exists)
由于redis的单线程的,用了命令之后,只能有一个客户端对某一个key设置值,在没有过期或删除key的时候是其他客户端是不能设置这个key的
面试官:好的,那你如何控制Redis实现分布式锁有效时长呢?
候选人:嗯,的确,redis的setnx指令不好控制这个问题,我们当时采用的redis的一个框架redisson实现的。
在redisson中需要手动加锁,并且可以控制锁的失效时间和等待时间,当锁住的一个业务还没有执行完成的时候,在redisson中引入了一个看门狗机制,就是说每隔一段时间就检查当前业务是否还持有锁,如果持有就增加加锁的持有时间,当业务执行完成之后需要使用释放锁就可以了
还有一个好处就是,在高并发下,一个业务有可能会执行很快,先客户1持有锁的时候,客户2来了以后并不会马上拒绝,它会自旋不断尝试获取锁,如果客户1释放之后,客户2就可以马上持有锁,性能也得到了提升。
面试官:好的,redisson实现的分布式锁是可重入的吗?
候选人:嗯,是可以重入的。这样做是为了避免死锁的产生。这个重入其实在内部就是判断是否是当前线程持有的锁,如果是当前线程持有的锁就会计数,如果释放锁就会在计算上减一。在存储数据的时候采用的hash结构,大key可以按照自己的业务进行定制,其中小key是当前线程的唯一标识,value是当前线程重入的次数
面试官:redisson实现的分布式锁能解决主从一致性的问题吗
候选人:这个是不能的,比如,当线程1加锁成功后,master节点数据会异步复制到slave节点,此时当前持有Redis锁的master节点宕机,slave节点被提升为新的master节点,假如现在来了一个线程2,再次加锁,会在新的master节点上加锁成功,这个时候就会出现两个节点同时持有一把锁的问题。
我们可以利用redisson提供的红锁来解决这个问题,它的主要作用是,不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁,并且要求在大多数redis节点上都成功创建锁,红锁中要求是redis的节点数量要过半。这样就能避免线程1加锁成功后master节点宕机导致线程2成功加锁到新的master节点上的问题了。
但是,如果使用了红锁,因为需要同时在多个节点上都添加锁,性能就变的很低了,并且运维维护成本也非常高,所以,我们一般在项目中也不会直接使用红锁,并且官方也暂时废弃了这个红锁
面试官:好的,如果业务非要保证数据的强一致性,这个该怎么解决呢?
**候选人:**嗯~,redis本身就是支持高可用的,做到强一致性,就非常影响性能,所以,如果有强一致性要求高的业务,建议使用zookeeper实现的分布式锁,它是可以保证强一致性的。
面试官:Redis集群有哪些方案, 知道嘛 ?
候选人:嗯~~,在Redis中提供的集群方案总共有三种:主从复制、哨兵模式、Redis分片集群
面试官:那你来介绍一下主从同步
候选人:嗯,是这样的,单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,可以搭建主从集群,实现读写分离。一般都是一主多从,主节点负责写数据,从节点负责读数据,主节点写入数据之后,需要把数据同步到从节点中
面试官:能说一下,主从同步数据的流程
候选人:嗯~~,好!主从同步分为了两个阶段,一个是全量同步,一个是增量同步
全量同步是指从节点第一次与主节点建立连接的时候使用全量同步,流程是这样的:
第一:从节点请求主节点同步数据,其中从节点会携带自己的replication id和offset偏移量。
第二:主节点判断是否是第一次请求,主要判断的依据就是,主节点与从节点是否是同一个replication id,如果不是,就说明是第一次同步,那主节点就会把自己的replication id和offset发送给从节点,让从节点与主节点的信息保持一致。
第三:在同时主节点会执行bgsave,生成rdb文件后,发送给从节点去执行,从节点先把自己的数据清空,然后执行主节点发送过来的rdb文件,这样就保持了一致
当然,如果在rdb生成执行期间,依然有请求到了主节点,而主节点会以命令的方式记录到缓冲区,缓冲区是一个日志文件,最后把这个日志文件发送给从节点,这样就能保证主节点与从节点完全一致了,后期再同步数据的时候,都是依赖于这个日志文件,这个就是全量同步
增量同步指的是,当从节点服务重启之后,数据就不一致了,所以这个时候,从节点会请求主节点同步数据,主节点还是判断不是第一次请求,不是第一次就获取从节点的offset值,然后主节点从命令日志中获取offset值之后的数据,发送给从节点进行数据同步
面试官:怎么保证Redis的高并发高可用
候选人:首先可以搭建主从集群,再加上使用redis中的哨兵模式,哨兵模式可以实现主从集群的自动故障恢复,里面就包含了对主从服务的监控、自动故障恢复、通知;如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主;同时Sentinel也充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端,所以一般项目都会采用哨兵的模式来保证redis的高并发高可用
面试官:你们使用redis是单点还是集群,哪种集群
候选人:嗯!,我们当时使用的是主从(1主1从)加哨兵。一般单节点不超过10G内存,如果Redis内存不足则可以给不同服务分配独立的Redis主从节点。尽量不做分片集群。因为集群维护起来比较麻烦,并且集群之间的心跳检测和数据通信会消耗大量的网络带宽,也没有办法使用lua脚本和事务
面试官:redis集群脑裂,该怎么解决呢?
候选人:嗯! 这个在项目很少见,不过脑裂的问题是这样的,我们现在用的是redis的哨兵模式集群的
有的时候由于网络等原因可能会出现脑裂的情况,就是说,由于redis master节点和redis salve节点和sentinel处于不同的网络分区,使得sentinel没有能够心跳感知到master,所以通过选举的方式提升了一个salve为master,这样就存在了两个master,就像大脑分裂了一样,这样会导致客户端还在old master那里写入数据,新节点无法同步数据,当网络恢复后,sentinel会将old master降为salve,这时再从新master同步数据,这会导致old master中的大量数据丢失。
关于解决的话,我记得在redis的配置中可以设置:第一可以设置最少的salve节点个数,比如设置至少要有一个从节点才能同步数据,第二个可以设置主从数据复制和同步的延迟时间,达不到要求就拒绝请求,就可以避免大量的数据丢失
面试官:redis的分片集群有什么作用
候选人:分片集群主要解决的是,海量数据存储的问题,集群中有多个master,每个master保存不同数据,并且还可以给每个master设置多个slave节点,就可以继续增大集群的高并发能力。同时每个master之间通过ping监测彼此健康状态,就类似于哨兵模式了。当客户端请求可以访问集群任意节点,最终都会被转发到正确节点
面试官:Redis分片集群中数据是怎么存储和读取的?
候选人:
嗯~,在redis集群中是这样的
Redis 集群引入了哈希槽的概念,有 16384 个哈希槽,集群中每个主节点绑定了一定范围的哈希槽范围, key通过 CRC16 校验后对 16384 取模来决定放置哪个槽,通过槽找到对应的节点进行存储。
取值的逻辑是一样的
面试官:Redis是单线程的,但是为什么还那么快?
候选人:
嗯,这个有几个原因吧~~~
1、完全基于内存的,C语言编写
2、采用单线程,避免不必要的上下文切换可竞争条件
3、使用多路I/O复用模型,非阻塞IO
例如:bgsave 和 bgrewriteaof 都是在后台执行操作,不影响主线程的正常使用,不会产生阻塞
面试官:能解释一下I/O多路复用模型?
候选人:嗯~~,I/O多路复用是指利用单个线程来同时监听多个Socket ,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。目前的I/O多路复用都是采用的epoll模式实现,它会在通知用户进程Socket就绪的同时,把已就绪的Socket写入用户空间,不需要挨个遍历Socket来判断是否就绪,提升了性能。
其中Redis的网络模型就是使用I/O多路复用结合事件的处理器来应对多个Socket请求,比如,提供了连接应答处理器、命令回复处理器,命令请求处理器;
在Redis6.0之后,为了提升更好的性能,在命令回复处理器使用了多线程来处理回复事件,在命令请求处理器中,将命令的转换使用了多线程,增加命令转换速度,在命令执行的时候,依然是单线程
相关文章:

java面试题-Redis相关面试题
Redis相关面试题 面试官:什么是缓存穿透 ? 怎么解决 ? 候选人: 嗯~~,我想一下 缓存穿透是指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询&…...

你用过 Maven Shade 插件吗?
文章首发地址 Maven Shade插件是Maven构建工具的一个插件,用于构建可执行的、可独立运行的JAR包。它解决了依赖冲突的问题,将项目及其所有依赖(包括传递依赖)合并到一个JAR文件中。 下面是对Maven Shade插件的一些详解ÿ…...

Android 后台启动Activity适配
在Android 9及以下版本,后台启动Activity相对自由,但是如果在Activity上下文之外启动Activity会有限制。 Calling startActivity() from outside of an Activity context requires the FLAG_ACTIVITY_NEW_TASK flag所以此时需要给intent添加flag&#x…...
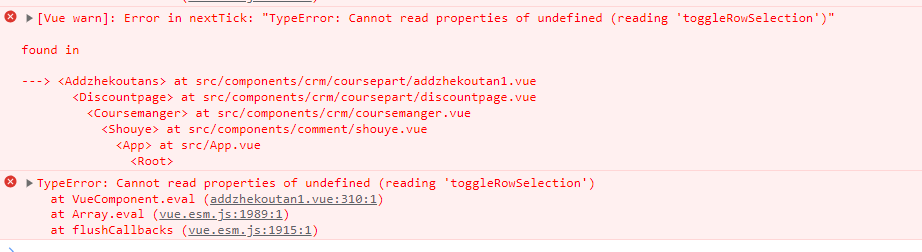
使用element-ui中的el-table回显已选中数据时toggleRowSelection报错
最近在写一个后台,需要在表格中多选,然后点击编辑按钮的时候,需要回显已经选中的表单项 <el-table v-loading"loading" :data"discountList" :row-key"(row) > row.id" refmultipleTable selection-cha…...

Ubuntu18.04系统下通过ROS控制Kinova真实机械臂-多种实现方式
所用测试工作空间test_ws:包含官网最原始的功能包 一、使用Kinova官方Development center控制真实机械臂 0.在ubuntu系统安装Kinova机械臂的Development center,这一步自行安装,很简单。 1.使用USB连接机械臂和电脑 2.Development center…...
聊聊如何玩转spring-boot-admin
前言 1、何为spring-boot-admin? Spring Boot Admin 是一个监控工具,旨在以良好且易于访问的方式可视化 Spring Boot Actuators 提供的信息 快速开始 如何搭建spring-boot-admin-server 1、在服务端项目的POM引入相应的GAV <dependency><grou…...
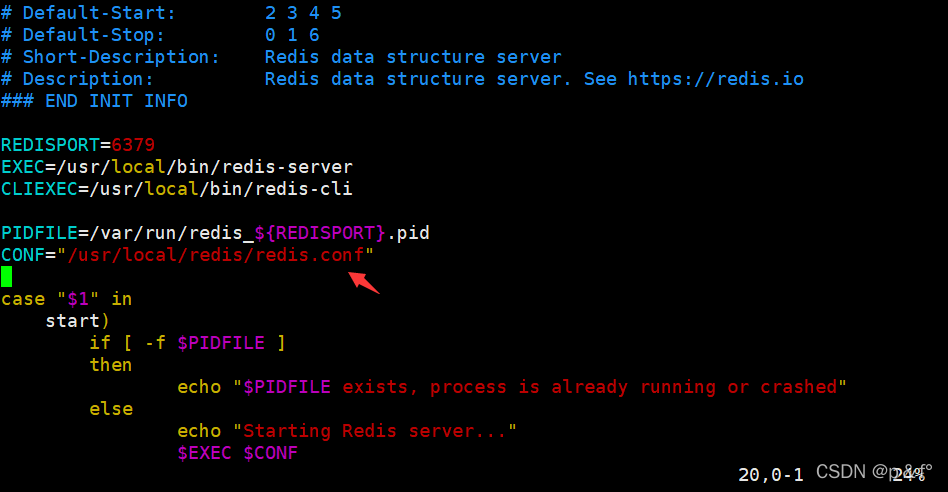
rocky(centos) 安装redis,并设置开机自启动
一、下载并安装 1、官网下载Redis 并安装 Download | RedisRedisYou can download the last Redis source files here. For additional options, see the Redis downloads section below.Stable (7.2)Redis 7.2 …https://redis.io/download/ 2、上传下载好的redis压缩包到 /…...

Flask狼书笔记 | 06_电子邮件
文章目录 6 电子邮件6.1 使用Flask-Mail发送6.2 使用事务邮件服务SendGrid6.3 电子邮件进阶6.4 小结 6 电子邮件 Web中,我们常在用户注册账户时发送确认邮件,或是推送信息。邮件必要的字段包含发信方(sender),收信方(to),邮件主题…...

ChatGPT追祖寻宗:GPT-1论文要点解读
论文地址:《Improving Language Understanding by Generative Pre-Training》 最近一直忙着打比赛,好久没更文了。这两天突然想再回顾一下GPT-1和GPT-2的论文, 于是花时间又整理了一下,也作为一个记录~话不多说,让我们…...
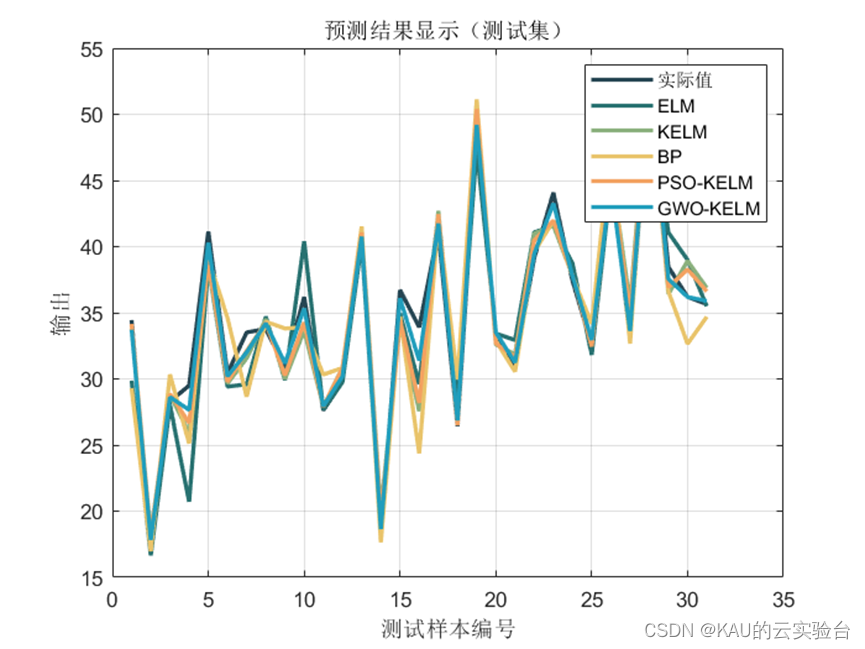
回归拟合 | 灰狼算法优化核极限学习机(GWO-KELM)MATLAB实现
这周有粉丝私信想让我出一期GWO-KELM的文章,因此乘着今天休息就更新了(希望不算晚) 作者在前面的文章中介绍了ELM和KELM的原理及其实现,ELM具有训练速度快、复杂度低、克服了传统梯度算法的局部极小、过拟合和学习率的选择不合适等优点,而KEL…...
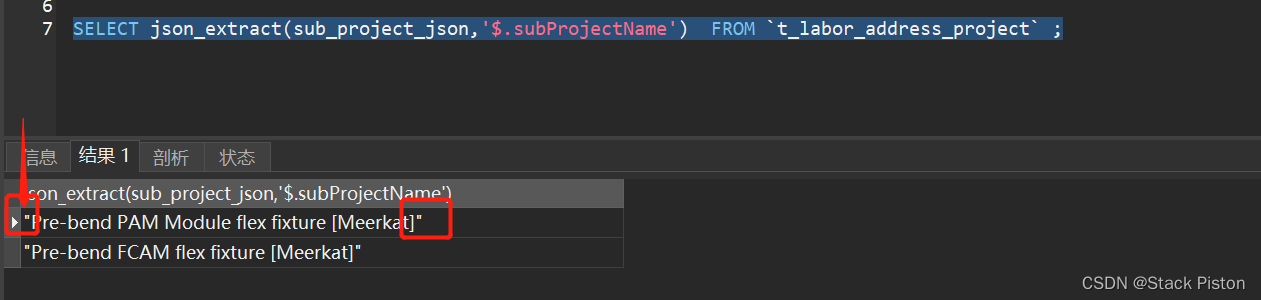
Mysql JSON
select json_extract(c2, $.a) select c2->"$.a" // json_extract的语法糖 (取出的值会保留"双引号" so不适合实战) 注:mysql若是引擎Mariadb则不支持json操作符->>语法糖 select c2->…...
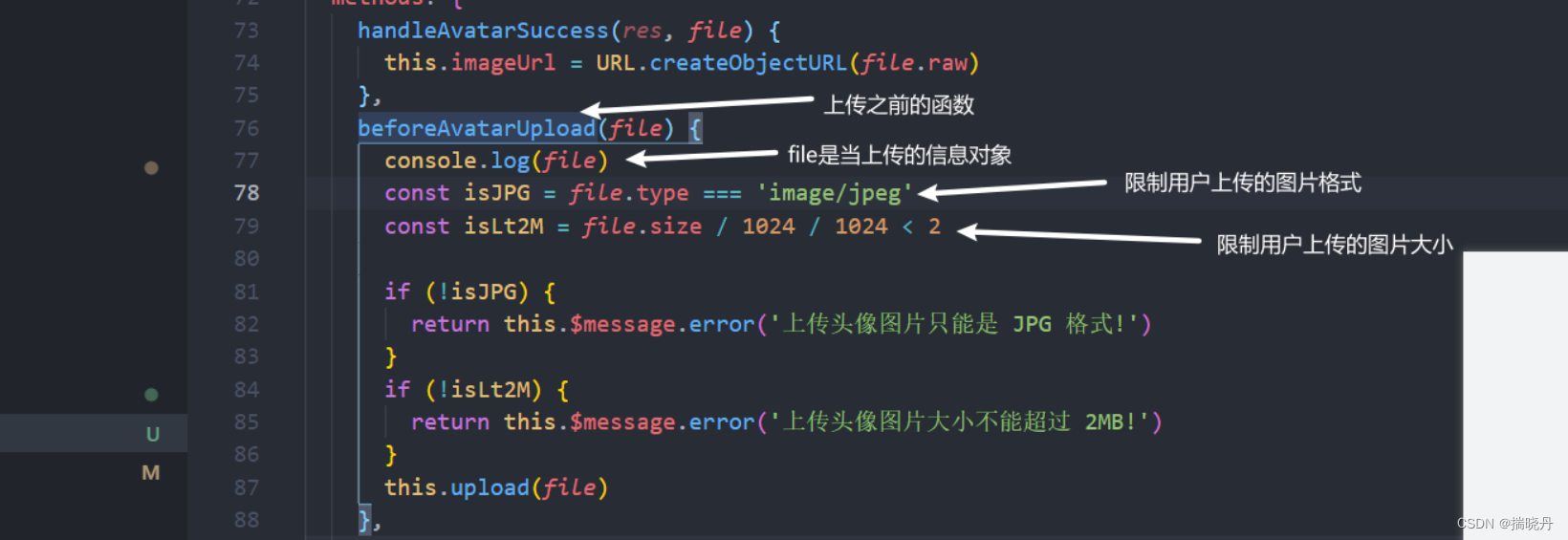
使用Vue + axios实现图片上传,轻松又简单
目录 一、Vue框架介绍 二、Axios 介绍 三、实现图片上传 四、Java接收前端图片 一、Vue框架介绍 Vue是一款流行的用于构建用户界面的开源JavaScript框架。它被设计用于简化Web应用程序的开发,特别是单页面应用程序。 Vue具有轻量级、灵活和易学的特点…...

C# 中什么是重写(子类改写父类方法)
方法重写是指在继承关系中,子类重新实现父类或基类的某个方法。这种方法允许子类根据需要修改或扩展父类或基类的方法功能。在面向对象编程中,方法重写是一种多态的表现形式,它使得子类可以根据不同的需求和场景提供不同的方法实现。 方法重…...
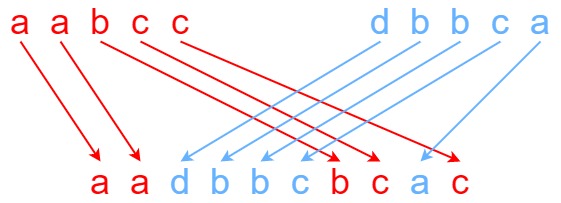
【Leetcode-面试经典150题-day22】
目录 97. 交错字符串 97. 交错字符串 题意: 给定三个字符串 s1、s2、s3,请你帮忙验证 s3 是否是由 s1 和 s2 交错 组成的。 两个字符串 s 和 t 交错 的定义与过程如下,其中每个字符串都会被分割成若干 非空 子字符串: s s1 s2 …...
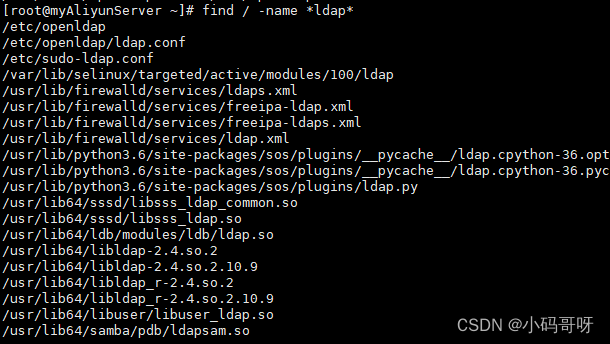
LDAP服务器如何重启
1、find / -name ldap 该命令只会从根路径下查看ldap文件夹 find / -name ldap2、该命令会从根路径/查看所有包含ldap路径的文件夹,会查询出所有,相当于全局查询 find / -name *ldap*2、启动OpenLADP 找到LDAP安装目录后,执行以下命令 #直…...

AP51656 LED车灯电源驱动IC 兼容替代PT4115 PT4205 PWM和线性调光
产品描述 AP51656是一款连续电感电流导通模式的降压恒流源 用于驱动一颗或多颗串联LED 输入电压范围从 5V 到 60V,输出电流 可达 1.5A 。根据不同的输入电压和 外部器件, 可以驱动高达数十瓦的 LED。 内置功率开关,采用高端电流采样设置 …...
浅析安防视频监控平台EasyCVR视频融合平台接入大量设备后是如何维持负载均衡的
安防视频监控平台EasyCVR视频融合平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。视频汇聚融合管理平台EasyCVR既具备…...

SIEM 中不同类型日志监控及分析
安全信息和事件管理(SIEM)解决方案通过监控来自网络的不同类型的数据来确保组织网络的健康安全状况,日志数据记录设备上发生的每个活动以及整个网络中的应用程序,若要评估网络的安全状况,SIEM 解决方案必须收集和分析不…...
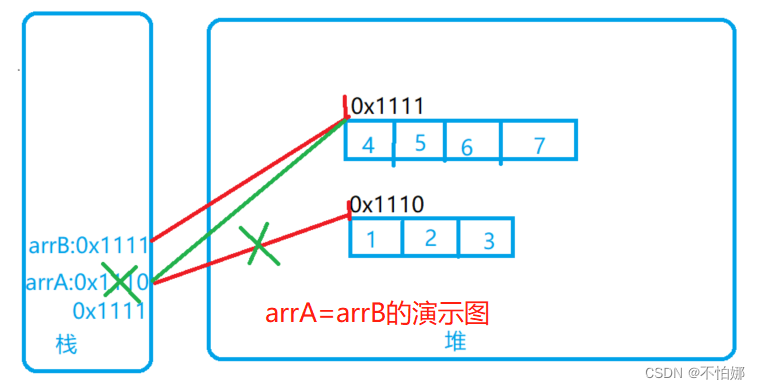
【java基础复习】java中的数组在内存中是如何存储的?
基本数据类型与内存存储数组类型与内存存储为什么数组需要两块空间?感谢 💖 基本数据类型与内存存储 首先,让我们回顾一下基本数据类型的内存存储方式。对于一个基本类型变量,例如int类型的变量a,内存中只有一块内存空…...

MySQL数据库 MHA高可用
MySQL MHA 什么是 MHA MHA(MasterHigh Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。 MHA 的出现就是解决MySQL 单点的问题。 MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。 MHA能在故障切换的…...

从零到一:Android Studio集成Uniapp离线SDK打包实战
1. 环境准备:工具选择与版本匹配 第一次接触Uniapp离线打包时,最让我头疼的就是工具版本匹配问题。记得去年接手一个混合开发项目时,因为HBuilderX和SDK版本不兼容,整整浪费了两天时间排查问题。为了避免大家重蹈覆辙,…...

AI智能体生态的包管理器:agenticmarket-cli 设计与实践
1. 项目概述:一个面向AI智能体生态的命令行工具如果你和我一样,长期在AI智能体(Agent)这个领域里折腾,那你肯定经历过这样的场景:为了测试一个最新的开源智能体框架,你需要先找到它的GitHub仓库…...

芯片老化座的工作温度范围?
在芯片测试领域,老化座(Burn-in Socket)是保障半导体器件长期可靠性的关键设备。它不仅要在极端温度下稳定工作,还要确保测试数据的精准度。今天,我们以HMILU(深圳市鸿怡电子有限公司)为例&…...

猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧
猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&#…...

AI原生产品管理:多智能体协作如何重塑产品开发工作流
1. 项目概述:当AI成为你的产品经理最近在GitHub上看到一个挺有意思的项目,叫NathanJCW/ai-native-pm-cortex。光看名字,你大概能猜到它想做什么——“AI原生的产品经理大脑”。这可不是一个简单的聊天机器人插件,它试图构建一个完…...

告别时间混乱:一份超全的Hive日期函数使用手册与常见错误排查
告别时间混乱:一份超全的Hive日期函数使用手册与常见错误排查 在数据开发领域,时间数据处理一直是高频且易错的环节。无论是日志分析、用户行为追踪还是财务报表生成,准确的时间计算都是确保数据质量的基础。Hive作为大数据生态中广泛使用的数…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十三)用户指引自助教学源码—东方仙盟
代码<!DOCTYPE html> <html lang"zh-CN"> <head> <meta charset"UTF-8"> <meta http-equiv"X-UA-Compatible" content"IEedge,chrome1"> <title>你的导师-未来之窗</title> <style>*…...

Linux内存使用分析与泄漏排查
Linux内存使用分析与泄漏排查内存问题往往不像磁盘满那样直观,也不像进程崩溃那样立刻可见。很多服务在内存异常初期仍然可以运行,只是响应逐渐变慢、交换开始活跃、最终被系统回收或触发 OOM。中级 Linux 工程师需要掌握的,不只是看“还剩多…...

OpenAgents开源框架:模块化AI智能体开发实战指南
1. 项目概述:一个面向未来的智能体开发框架最近在AI智能体这个圈子里,OpenAgents这个项目讨论度挺高的。简单来说,它不是一个单一的AI应用,而是一个旨在降低智能体开发门槛、加速智能体应用落地的开源框架。你可以把它想象成一个“…...

告别玄学调试:用英飞凌TC37X/TC38X的DSADC做旋变软解码,这些配置坑你别再踩了
英飞凌TC37X/TC38X DSADC旋变解码实战避坑指南 从实验室到产线:那些DSADC配置中容易忽视的细节 在新能源汽车电机控制领域,旋转变压器(Resolver)作为位置传感器的主力军,其解码稳定性直接决定了矢量控制的精度。英飞凌…...