从一到无穷大 #13 How does Lindorm TSDB solve the high cardinality problem?
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- 优势
- 挑战
- 系统架构
- 细节/优化
- 存储引擎
- 索引
- 写入
- 查询
- 经验
- Ablation Study
- 总结
引言
云原生时序数据库目前来看还是一个没有行业标准架构特殊数据库分支,各大云厂商都有自己的集群化实现,从谷歌的Monarch,阿里的Lindorm,腾讯的CTSDB,到垂直领域的InfluxDB IOX,TDengine,IotDB,都是各有的特点和适合的领域。终究不存在银弹,强如各大头部厂商也只是在做Trade off…
优势
- 大量活跃时间线下高写入吞吐和低延迟读取
- 允许用户使用SQL直接进行异常检测和时间序列预测算法
- 在节点扩展的过程中也能保证稳定的性能
挑战
- 海量时间线下的写入,Lindorm认为挑战在于海量时间线导致
forward index过大,占用空间大,导致查询写入过程中造成大量的内存交换。 - 海量时间线查询的高延迟,Lindorm认为挑战在于从索引中通过tags获取时间线的后的聚合过程,以及计算的过程无法很好的并行化
- 认为基于规则的度量数据分析通常无法准确识别性能问题,所以需要引入机器学习分析时序数据
- 认为现有存储与计算没有分离的TSDB存在扩容时的性能问题
系统架构
Lindorm Tsdb包含四个主要组件,其中TSProxy和TSCore允许水平扩容:
- TSProxy
- TSCore
- Lindorm ML
- Lindorm DFS

路由策略非常简洁,TSProxy负责路由请求,通过时间和serieskey两个维度路由请求,对于一个请求先基于时间判断shard group的归属,其次在一个shard group内部基于series key hash做分片。
一个用户的读写请求会拆分到多个shard上,每个TsCore管理多个shard,这可以使得一段时间内一个serieskey的所有数据位于同一个shard。在单独的shard上,数据以及其对应的索引数据首先存储在内存中,随后持久化到所有TsCore共享的DFS中。
其次TsCore扩容时可以选择创建一个新的shard group,不改变历史数据的物理分布,这样在扩容时无需迁移数据,不影响线上服务质量。当然时序的分裂要做成类似于kv的分裂也很困难,因为数据的组织格式是series key+field级别的列存,路由方式是serieskey hash,而查询的维度是time+tags,在分裂期间很难在一个引擎中支持两个哈希区间的查询,其次迁移期间索引和数据都需要拆分。

可以看到这个架构融合了shared-nothing 和 shared-storage的设计,计算与存储分离。
TsCore/TsProxy层面shared-nothing,可水平扩展提升读写性能。DFS层面shared-storage,负责提供高可用。
可以看到TsCore层面没有选择一致性算法提供高可用,而是依赖于共享存储;我个人觉得这样的做法并不是最优,因为当一个TsCore故障时立马补充一个TsCore,需要先重放没有落DFS的WAL后才能提供服务。而一致性算法中副本可以是一个状态机,切主后立即提供服务。
值得一提的是路由信息,也就是TsCore到shards的映射关系存储在ZooKeeper中,这让我有理由怀疑Lindorm集群的路由推送效率,其次ZooKeeper作为控制面也无法完成一些高级的调度策略(比如基于集群的各种指标判断是否分裂和配置项下发)。
细节/优化
存储引擎
- TSD文件和索引携带TTL,在后台压缩期间判断是否删除
- DFS中可以根据TSD的时间戳判断是否要存入更便宜的介质中(DFS由
ESSD cloud disk和Object Storage Service构成) - 无锁压缩用于内存数据,以提高内存利用率;WAL日志采用字典批量压缩,以减少IO;TSD中采用Delta-of-delta, XOR, ZigZag, RLE等常规算法压缩
索引
- 由于大量短时间序列的存在(容器的创建销毁,会议号,视频ID等),很多序列会迅速失效,所以在一个shard内部需要继续基于时间划分
time partitions,每个time partitions内部包含独立的索引。 - 当
time partitions过多时,启动采用lazy loading,优先加载最新分区,异步加载历史分区。 forward index和inverted index在memtable中写入,触发刷新时memtable中的两个索引分别生成FwdIdx和InvIdx文件- 为了加速索引的查找速度,后台合并减少文件数,其次每个文件中添加
bloom filter[1],最后使用Block Cache缓存部分文件内容 forward index访问频率远大于inverted index,写入过程中需要判断是否存在某个serieskey,查询时需要获取tsid对应的serieskey;所以引入seriescache,Block cache缓存文件数据,而seriescache缓存ID到serieskey之间的映射,采用LRU淘汰,因为serieskey较大,选择MD5替换serieskey。- 根据不同的Tag在倒排索引中获取ID List,利用RoaringBitmap做列表合并
- 考虑到历史时间序列处于非活跃状态,采用时间分区来提高内存利用率,历史shard的常驻内存适当减少
写入
- SQL引擎采用
Apache Calcite,写入采用insert语句,但是写路径通过引擎性能较差,所以实现了一个简易的写入解析器,bypass SQL引擎 - SQL prepare可以用于客户端的批量写入优化
查询
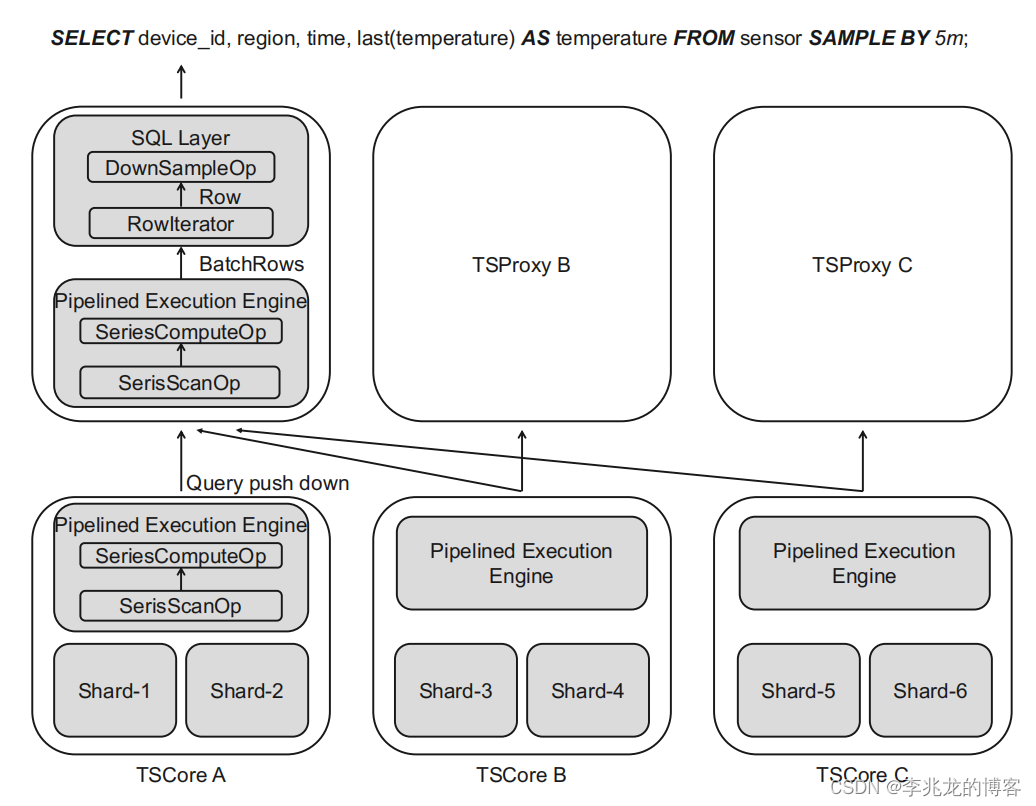
TSProxy和TsCore均实现的pipelined execution engine,支持计算下推,允许多个TsCore之间并行计算,此外一个TsCore的多个partition,一个partition的多个shard之间都可以并行计算。行迭代器驱动整个流水线引擎执行,可以在流水线中自定义时间线维度的算子,数据会流经pipeline中所有的算子,完成后释放这部分内存。- 引擎中的算子基于是否
downsampling被划分为两类;
a.downsampling: aggregation (DSAgg) , interpolation (Filling)
b.non-downsampling: rate of change (Rate) , obtaining the difference (Delta). - 预降采样,为了减小预将采样对于写入的影响,只有在memtable被下刷到共享存储和压缩时才会执行预降采样。
- 实现了跨time-series的算子(series_max?)
经验
- 节点故障很常见,新
TSCore在接管故障TSCore时需要重放完WAL才能提供服务,这可能造成服务中断,所以设计了WAL异步载入,先允许写,重放完成后允许读 - 采用图表化多字段模型,并支持SQL不但有助于用户理解,而且方便DBA解决问题
- 启动预降采样可以用8%的存储空间换取80%的查询延迟,DFS中存储分层,允许历史数据存储在对象存储,且于实时查询和连续查询相比资源消耗极低
- 没有流水线执行引擎必须一次读出所有数据,导致内存耗尽
- first/last使用频繁,这需要高qps和低延迟,为此Lindorm专门设计了一种缓存,在查询时,每个时间序列的最新值都会被缓存起来,并在该时间序列写入新数据点时进行更新,实施这种缓存后查询响应时间缩短了 85%
Ablation Study
Lindorm认为性能的关键在于两点:
- push-down optimization in the pipeline streaming execution engine
- seriescache for the forward index.
对照实验结果如下:

很好理解,没有计算下推的情况TsProxy需要计算全部的数据,第一数据传输量大,第二没有节点级别并行化

效果非常明显,写吞吐提升在23.8%到232%,而且对于where time > now() -2h group by * , time(5m)的查询时延也降低了15.3到32.2%
总结
文章中可以看出不少地方存在改进空间,但是不得不承认Lindorm TSDB可学习的地方很多,感谢Lindorm团队的无私奉献。
参考:
- 比 Bloom Filter 节省25%空间!Ribbon Filter 在 Lindorm中的应用
相关文章:
从一到无穷大 #13 How does Lindorm TSDB solve the high cardinality problem?
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 引言优势挑战系统架构细节/优化存储引擎索引写入查询 经验Ablation Study总结 引言 …...

三维模型OBJ格式轻量化的纹理压缩和质量关系分析
三维模型OBJ格式轻量化的纹理压缩和质量关系分析 三维模型的OBJ格式通常包含纹理信息,而对纹理进行轻量化压缩可以减小文件大小和提高加载性能。然而,在进行纹理压缩时需要权衡压缩比率和保持质量之间的关系,并根据具体应用场景选择合适的压缩…...

【每日一题】54. 螺旋矩阵
54. 螺旋矩阵 - 力扣(LeetCode) 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 示例 1: 输入:matrix [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5…...
git:一些撤销操作
参考自 如何撤销 Git 操作?[1] 一、撤销提交 git revert HEAD 撤销上次提交. (会在当前提交后面,新增一次提交,抵消掉上一次提交导致的所有变化,所有记录都会保留) 二、撤销某次merge git merge --abort 三、替换上一次提交 git commit --ame…...

leetcode 209. 长度最小的子数组
题目链接:leetcode 209 1.题目 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的 连续子数组 [numsl, numsl1, …, numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,…...

《rk3399:各显示接口的dts配置》
这里写目录标题 一、前言二、平台支持的显示接口三、两个VOP支持的最大输出分辨率四、VOPL的dts配置五、VOPB的dts配置六、display_subsystem的配置七、backlight 背光配置八、针对eDP接口的配置 以firefly为例8.1 原生配置8.2 启用eDP屏接口配置九、针对MIPI接口屏的配置 以fi…...

Python数据分析-Pandas
Pandas 个人笔迹,建议不看 import pandas as pd import numpy as npSeries类型 spd.Series([1,3,5,np.nan,6,8],index[a,b,c,d,e]) print(s) # 默认0-n-1,否则用index数组作行标 s.index s.value # array() s[a] &g…...

golang 多线程管理 -- chatGpt
提问: 用golang写一个启动函数 start(n) 和对应的停止函数stopAll(),. start函数功能:启动n个线程,线程循环打印日志,stopAll()函数功能:停止start启动的线程 以下是一个示例的Golang代码,其中包括 start…...

【Math】导数、梯度、雅可比矩阵、黑塞矩阵
导数、梯度、雅可比矩阵、黑塞矩阵都是与求导相关的一些概念,比较容易混淆,本文主要是对它们的使用场景和定义进行区分。 首先需要先明确一些函数的叫法(是否多元,以粗体和非粗体进行区分): 一元函数&…...

【C语言】——调试技巧
目录 编辑 ①前言 1.什么是Bug? 2.什么是调试? 2.1调试的基本步骤 2.2Release与Debug 3.常用快捷键 4.如何写出好的代码 4.1常见的coding技巧 👉assert() 👉const() const修饰指针: ①前言 调试是每个程序员都…...
【Python】pytorch,CUDA是否可用,查看显卡显存剩余容量
CUDA可用,共有 1 个GPU设备可用。 当前使用的GPU设备索引:0 当前使用的GPU设备名称:NVIDIA T1000 GPU显存总量:4.00 GB 已使用的GPU显存:0.00 GB 剩余GPU显存:4.00 GB PyTorch版本:1.10.1cu102 …...

React16入门到入土
搭建环境 默认你已经安装好 node.js 安装 react 脚手架 学习的过程中,我们采用React官方出的脚手架工具 create-react-app npm install -g create-react-app如果提示没有权限,win 用户可以管理员打开终端,mac 用户 可以在前面加上 sudo …...
【GPT引领前沿】GPT4技术与AI绘图
推荐阅读: 1、遥感云大数据在灾害、水体与湿地领域典型案例实践及GPT模型应用 2、GPT模型支持下的Python-GEE遥感云大数据分析、管理与可视化技术 GPT对于每个科研人员已经成为不可或缺的辅助工具,不同的研究领域和项目具有不同的需求。例如在科研编程…...

【LeetCode】19. 删除链表的倒数第 N 个结点
19. 删除链表的倒数第 N 个结点(中等) 方法:快慢指针 思路 为了找到倒数第 n 个节点,我们应该先找到最后一个节点,然后从它开始往前数 n-1 个节点就是要删除的节点。 对于一般情况:设置 fast 和 slow 两个…...

spring boot3.x集成swagger出现Type javax.servlet.http.HttpServletRequest not present
1. 问题出现原因 spring boot3.x版本依赖于jakarta依赖包,但是swagger依赖底层应用的javax依赖包,所以只要已启动就会报错。 2. 解决方案 移除swagger2依赖 <dependency><groupId>io.springfox</groupId><artifactId>springfo…...

《低代码指南》——智能化低代码开发实践案例
大模型能通过自然语言理解自动生成需求文档及代码供给低代码开发者使用,也具备自动检测和修复代码错误、自动优化代码、找出冗余并提供高效方案等自动化能力,为开发者带来需求模式、设计模式、开发模式的变化,节省时间成本、代码质量更优、进…...
 + 7) / 8)、字节对齐(((number) + 3) / 4 * 4))
268_C++_字节计算(((bits) + 7) / 8)、字节对齐(((number) + 3) / 4 * 4)
这段代码中包含了两个宏的定义,它们似乎用于进行位操作和字节对齐操作。让我们逐个来解析这两个宏: BITS_TO_BYTES(bits) 宏:#define BITS_TO_BYTES(bits) (((bits) + 7) / 8)这个宏的作用是将位数(bits)转换为字节数(bytes)。它的计算方式是将位数加上7,然后除以8,这…...
JavaWeb知识梳理(后端部分)
JavaWeb 静态web资源(如html 页面):指web页面中供人们浏览的数据始终是不变。 动态web资源:指web页面中供人们浏览的数据是由程序产生的,不同时间点访问web页面看到的内容各不相同。 静态web资源开发技术࿱…...

AI:07-基于卷积神经网络的海洋生物的识别
当涉及海洋生物的识别和研究时,基于深度学习的方法已经展现出了巨大的潜力。深度学习模型可以利用大量的图像和标记数据来自动学习特征,并实现高准确度的分类任务。本文将介绍如何使用深度学习技术来实现海洋生物的自动识别,并提供相应的代码示例。 数据收集和预处理 要训…...

centos7下docker设置新的下载镜像源并调整存放docker下载镜像的仓库位置
目录 1.设置镜像源 2.调整存放下载镜像的仓库位置 1.设置镜像源 在 /etc/docker下创建一个daemon.json文件。在json中下入 "registry-mirrors": ["https://docker.mirrors.ustc.edu.cn/"] 完成配置 加载配置 systemctl daemon-reload 重启docker sy…...
)
别再死记硬背了!用MATLAB手把手教你画根轨迹图(附代码与避坑指南)
MATLAB实战:从零绘制根轨迹图的完整指南与避坑技巧 在控制系统的设计与分析中,根轨迹图是理解系统动态特性的重要工具。传统教学中,学生往往被要求死记硬背绘制规则,却难以理解其实际应用价值。本文将彻底改变这一现状——通过MAT…...

AutoCut终极指南:如何用文本编辑器快速剪辑100个视频
AutoCut终极指南:如何用文本编辑器快速剪辑100个视频 【免费下载链接】autocut 用文本编辑器剪视频 项目地址: https://gitcode.com/GitHub_Trending/au/autocut 还在为手动剪辑视频而烦恼吗?AutoCut项目让你告别复杂的视频编辑软件,通…...

告别ET1100?聊聊AX58100这颗高性价比EtherCAT从站芯片的升级体验
告别ET1100?AX58100高性价比EtherCAT从站芯片的工业升级实战 当工业设备制造商面临从传统控制架构向实时以太网迁移时,EtherCAT从站芯片的选型往往成为关键转折点。十年前,ET1100凭借其稳定的性能和相对友好的开发门槛,成为许多工…...

如何5分钟掌握N_m3u8DL-RE:流媒体下载终极解决方案
如何5分钟掌握N_m3u8DL-RE:流媒体下载终极解决方案 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

qmcdump终极指南:三步解锁QQ音乐加密音频文件
qmcdump终极指南:三步解锁QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 还在为QQ音乐下…...

激光切割外壳设计全流程:从创客工具到产品级制造的实战指南
1. 项目概述:为什么选择激光切割来做外壳?如果你和我一样,捣鼓过不少电子项目,从简单的Arduino温湿度计到复杂的树莓派家庭服务器,那你一定为“给它们找个家”这件事头疼过。3D打印太慢,开模注塑成本又高得…...
:含12组经大英博物馆湿版藏品验证的Reference Prompt库)
Midjourney湿版摄影风格实战手册(从胶片化学原理到Prompt工程):含12组经大英博物馆湿版藏品验证的Reference Prompt库
更多请点击: https://intelliparadigm.com 第一章:湿版摄影的历史溯源与Midjourney风格化转译本质 湿版摄影(Wet Plate Collodion Process)诞生于1851年,由弗雷德里克斯科特阿彻(Frederick Scott Archer&a…...

基于语义搜索的AI代码理解工具copaw-code深度解析
1. 项目概述:一个面向代码搜索与理解的AI工具 最近在GitHub上看到一个挺有意思的项目,叫 QSEEKING/copaw-code 。乍一看这个标题,可能会有点摸不着头脑,“copaw”是什么?但结合“code”和项目托管在QSEEKING这个组织…...

构建个人知识库:从碎片化代码到结构化知识体系
1. 项目概述:从“ClawCode”看个人知识库的构建与价值最近在和一些开发者朋友交流时,发现一个普遍现象:大家电脑里都散落着无数代码片段、配置脚本、临时笔记和项目心得。这些“数字碎片”价值巨大,但往往因为缺乏有效的组织&…...

Python Reddit数据采集与分析实战:从API调用到舆情监控
1. 项目概述与核心价值最近在开源社区里,一个名为openshrug/reddit-intel的项目引起了我的注意。乍一看,这像是一个针对 Reddit 平台的数据抓取或分析工具,但深入探究后,我发现它的定位远不止于此。它更像是一个为开发者、数据分析…...