Python数据分析-Pandas
Pandas
个人笔迹,建议不看
import pandas as pd
import numpy as np
Series类型
s=pd.Series([1,3,5,np.nan,6,8],index=['a','b','c','d','e'])
print(s) # 默认0-n-1,否则用index数组作行标
s.index
s.value # array()
s['a'] => 1 # 取值
s[0:3] # 切片
s[::2] # 其实跟 array 类似,就是输出不一样
# 索引赋值
s.index.name = '索引'
s.index = list('abcdef');
s['a':'c']; # 切片左闭右闭DataFrame类型
是一个二维结构,类似于一张excel表
1)构造时间序列
date = pd.date_range('20180101',periods=6)
print(date)
2)创建一个DataFrame结构
## 传入二维数组
df = pd.DateFrame(np.random.randn(6,4))
df = pd.DateFrame(np.random.randn(6,4),index = date, columns=list('ABCD'))
## 用字典创建
df2 = pd.DataFrame({'A':1.,'B':pd.Timestamp('20181001'),'C':pd.Series(1,index=list(range(4)),dtype = float),'D':np.array([3]*4,dtype=float),'E':
pd.Categorical(['test','train','test','train']),'F':abc});
DateFrame只要求每列的数据类型相同就可以了
- 查看数据
df.head() # 默认产生前五行
df.tail(3)
df2.dtypes # 查看各列的数据类型
## 下标用index属性查看
df.index
df.columns
df.values # 只看值
- 读取数据及数据操作
# 读取excel,同一目录下
df=pd.read_excel('name.xlsx')
df=pd.read_csv('name.csv')
df=pd.read_excel(r'C:\Users\Administrator\Desktop\name.xlsx') # r 代表不需要转义- 行操作
# iloc的参数为具体的数字行列号,loc的参数为设置的index值和列名
df.iloc[0] 看第0行
df.iloc[0:5] # 左闭右开,df.loc[0:4].左闭右闭
## 添加一行
##先定义Series
dit={'名字':'复仇者联盟3','投票人数':123456,'类型':'剧情','产地':'美国',上映时间':'2018-05-04'}
s=pd.Series(dit)
s.name = 38737
df = df.append(s);
df[-5:];# 查看后5行
df[0:2]
## 删除行
df=df.drop([0,1,2]) # 给的是索引
## 查看
df['columnName'] # 显示名字这一列的所有信息
df['columnName'][:5]# 先取系列,后取下标
## 增加字段
df['newCol'] = range(1,len(df)+1)
## 删除列
df = df.drop('序号',axis=1)
## 通过标签进行数据选择, 先行后列用loc
df.loc[[index],[column]]
df.loc['a','名字']
df.loc[[1,3,5,7,9],['名字','评分']]
- 条件选择
df['产地'] == '美国' # bool series
df[df['产地'] == '美国'][:5]
## 选取产地为美国并且评分大于9
df[(df.产地=='美国')&(df.评分>9)][:5]
## 产地为美国或中国并且评分大于9
df[((df.产地=='美国')|(df.产地=='中国'))&(df.评分>9)] # 其实是位运算,注意加括号
- 缺失值及异常值处理
dropna
fillna
isnull
notnull
判断缺失值:
df.isnull()
返回二维bool数组
df['名字'].isnull()
df.col.notnull()
df[df.col.isnull][:5]
填充缺失值:
fillna() # NaN
df['评分'].fillna(value)
删除缺失值
df.dropna()
参数:
how = 'all' : 某行某列全为0时删除
inplace = true : 覆盖掉原先的数据,即直接变为新数据
axis=0:选择行或者列
练习
import pandas as pd
data = pd.read_excel('豆瓣电影数据.xlsx')
print(type(data))
<class 'pandas.core.frame.DataFrame'>
data.to_excel(r'C:/Users/xxx/desktop/movie.xlsx')
df = pd.DataFrame({'name':['zs','ls'],'age':[1,2]})
df
df.describe()
#type(df)
| age | |
|---|---|
| count | 2.000000 |
| mean | 1.500000 |
| std | 0.707107 |
| min | 1.000000 |
| 25% | 1.250000 |
| 50% | 1.500000 |
| 75% | 1.750000 |
| max | 2.000000 |
data.columns
Index(['Unnamed: 0', '名字', '投票人数', '类型', '产地', '上映时间', '时长', '年代', '评分','首映地点'],dtype='object')
df = pd.read_excel(r'C:/Users/xxx/desktop/附件.xlsx')
df.drop(['Unnamed: 15','Unnamed: 16'],axis = 1)
df.drop(df.columns[15:22],axis=1,inplace = True)
df.to_excel(r'C:/Users/xxx/desktop/test.xlsx')
df.fillna(df.mean())
| 编号 | 母亲年龄 | 婚姻状况 | 教育程度 | 妊娠时间(周数) | 分娩方式 | CBTS | EPDS | HADS | 婴儿行为特征 | 婴儿性别 | 婴儿年龄(月) | 整晚睡眠时间(时:分:秒) | 睡醒次数 | 入睡方式 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 34 | 2 | 5 | 37.0 | 1 | 3 | 13 | 9 | 中等型 | 1 | 1 | 10:00:00 | 3.000000 | 2.000000 |
| 1 | 2 | 33 | 2 | 5 | 42.0 | 1 | 0 | 0 | 3 | 安静型 | 2 | 3 | 11:00:00 | 0.000000 | 4.000000 |
| 2 | 3 | 37 | 2 | 5 | 41.0 | 1 | 4 | 8 | 9 | 安静型 | 1 | 1 | 12:00:00 | 1.000000 | 2.000000 |
| 3 | 4 | 31 | 2 | 5 | 37.5 | 1 | 6 | 16 | 13 | 安静型 | 2 | 3 | 11:00:00 | 2.000000 | 1.000000 |
| 4 | 5 | 36 | 1 | 5 | 40.0 | 1 | 1 | 3 | 3 | 中等型 | 2 | 3 | 10:30:00 | 1.000000 | 4.000000 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 405 | 406 | 31 | 2 | 3 | 39.5 | 1 | 1 | 4 | 4 | NaN | 2 | 2 | NaN | 1.461538 | 3.025641 |
| 406 | 407 | 26 | 2 | 2 | 37.0 | 1 | 4 | 9 | 14 | NaN | 2 | 2 | NaN | 1.461538 | 3.025641 |
| 407 | 408 | 26 | 2 | 5 | 39.0 | 1 | 0 | 3 | 3 | NaN | 1 | 1 | NaN | 1.461538 | 3.025641 |
| 408 | 409 | 27 | 2 | 5 | 41.2 | 1 | 0 | 0 | 4 | NaN | 1 | 1 | NaN | 1.461538 | 3.025641 |
| 409 | 410 | 31 | 2 | 5 | 38.0 | 1 | 3 | 7 | 7 | NaN | 2 | 2 | NaN | 1.461538 | 3.025641 |
410 rows × 15 columns
df[df.婴儿行为特征 == '安静型']
| 编号 | 母亲年龄 | 婚姻状况 | 教育程度 | 妊娠时间(周数) | 分娩方式 | CBTS | EPDS | HADS | 婴儿行为特征 | 婴儿性别 | 婴儿年龄(月) | 整晚睡眠时间(时:分:秒) | 睡醒次数 | 入睡方式 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 33 | 2 | 5 | 42.0 | 1 | 0 | 0 | 3 | 安静型 | 2 | 3 | 11:00:00 | 0.0 | 4.0 |
| 2 | 3 | 37 | 2 | 5 | 41.0 | 1 | 4 | 8 | 9 | 安静型 | 1 | 1 | 12:00:00 | 1.0 | 2.0 |
| 3 | 4 | 31 | 2 | 5 | 37.5 | 1 | 6 | 16 | 13 | 安静型 | 2 | 3 | 11:00:00 | 2.0 | 1.0 |
| 5 | 6 | 32 | 2 | 5 | 41.0 | 1 | 1 | 2 | 3 | 安静型 | 1 | 1 | 12:00:00 | 0.0 | 4.0 |
| 9 | 10 | 34 | 1 | 3 | 37.2 | 1 | 3 | 5 | 10 | 安静型 | 1 | 3 | 11:00:00 | 0.0 | 4.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 377 | 378 | 29 | 2 | 4 | 41.0 | 1 | 6 | 7 | 9 | 安静型 | 2 | 2 | 11:00:00 | 1.0 | 4.0 |
| 378 | 379 | 41 | 2 | 3 | 39.4 | 1 | 10 | 13 | 11 | 安静型 | 1 | 1 | 10:00:00 | 0.0 | 4.0 |
| 380 | 381 | 32 | 2 | 5 | 40.0 | 1 | 5 | 5 | 3 | 安静型 | 1 | 1 | 09:00:00 | 0.0 | 5.0 |
| 387 | 388 | 31 | 2 | 5 | 41.6 | 1 | 0 | 3 | 1 | 安静型 | 1 | 1 | 10:30:00 | 2.0 | 1.0 |
| 388 | 389 | 27 | 2 | 3 | 40.0 | 1 | 1 | 10 | 5 | 安静型 | 1 | 1 | 06:00:00 | 2.0 | 1.0 |
120 rows × 15 columns
import numpy as np
d = dict(A = np.array([1,2]),B =np.array([1,2,3,4]))
df1 = pd.DataFrame({'name':['zs','ls'],'age':[1,2]})
df2 = pd.DataFrame({'mane':['ww','ll'],'sex':[0,1]})
pd.concat([df1,df2])
| name | age | mane | sex | |
|---|---|---|---|---|
| 0 | zs | 1.0 | NaN | NaN |
| 1 | ls | 2.0 | NaN | NaN |
| 0 | NaN | NaN | ww | 0.0 |
| 1 | NaN | NaN | ll | 1.0 |
df1 = pd.DataFrame({'name':['zs','ls'],'age':[1,2]})
df2 = pd.DataFrame({'name':['ww','ll'],'age':[0,1]})
df3 = pd.concat([df1,df2])
df3['age+1'] =df3['age'] + 1
df3.dtypes
df3| name | age | age+1 | |
|---|---|---|---|
| 0 | zs | 1 | 2 |
| 1 | ls | 2 | 3 |
| 0 | ww | 0 | 1 |
| 1 | ll | 1 | 2 |
df2.size # 面积 4 * 3
df.shape
df.var()
# df.discribe()
df.std()
编号 118.501055
母亲年龄 4.362262
婚姻状况 0.359970
教育程度 1.001642
妊娠时间(周数) 1.900777
分娩方式 0.109890
CBTS 4.963365
EPDS 6.757595
HADS 4.259715
婴儿性别 0.500319
婴儿年龄(月) 0.821911
睡醒次数 1.612071
入睡方式 1.408516
dtype: float64
相关文章:

Python数据分析-Pandas
Pandas 个人笔迹,建议不看 import pandas as pd import numpy as npSeries类型 spd.Series([1,3,5,np.nan,6,8],index[a,b,c,d,e]) print(s) # 默认0-n-1,否则用index数组作行标 s.index s.value # array() s[a] &g…...

golang 多线程管理 -- chatGpt
提问: 用golang写一个启动函数 start(n) 和对应的停止函数stopAll(),. start函数功能:启动n个线程,线程循环打印日志,stopAll()函数功能:停止start启动的线程 以下是一个示例的Golang代码,其中包括 start…...

【Math】导数、梯度、雅可比矩阵、黑塞矩阵
导数、梯度、雅可比矩阵、黑塞矩阵都是与求导相关的一些概念,比较容易混淆,本文主要是对它们的使用场景和定义进行区分。 首先需要先明确一些函数的叫法(是否多元,以粗体和非粗体进行区分): 一元函数&…...

【C语言】——调试技巧
目录 编辑 ①前言 1.什么是Bug? 2.什么是调试? 2.1调试的基本步骤 2.2Release与Debug 3.常用快捷键 4.如何写出好的代码 4.1常见的coding技巧 👉assert() 👉const() const修饰指针: ①前言 调试是每个程序员都…...
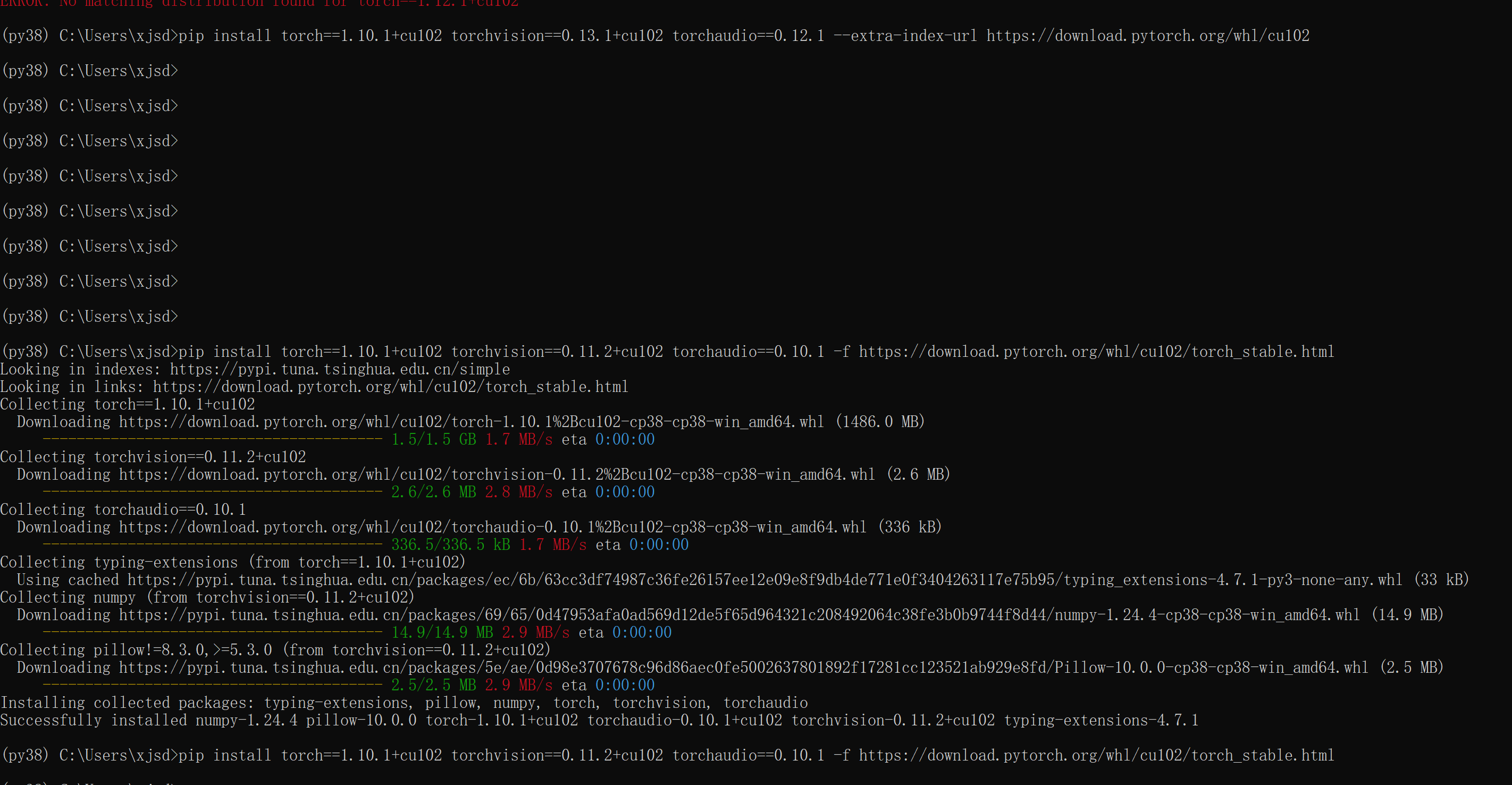
【Python】pytorch,CUDA是否可用,查看显卡显存剩余容量
CUDA可用,共有 1 个GPU设备可用。 当前使用的GPU设备索引:0 当前使用的GPU设备名称:NVIDIA T1000 GPU显存总量:4.00 GB 已使用的GPU显存:0.00 GB 剩余GPU显存:4.00 GB PyTorch版本:1.10.1cu102 …...

React16入门到入土
搭建环境 默认你已经安装好 node.js 安装 react 脚手架 学习的过程中,我们采用React官方出的脚手架工具 create-react-app npm install -g create-react-app如果提示没有权限,win 用户可以管理员打开终端,mac 用户 可以在前面加上 sudo …...
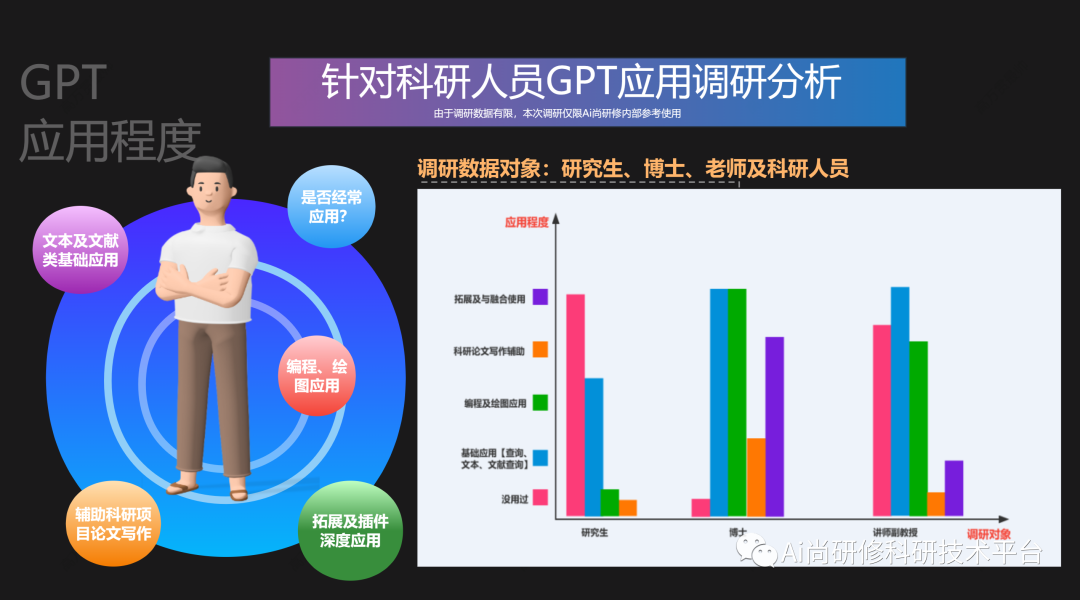
【GPT引领前沿】GPT4技术与AI绘图
推荐阅读: 1、遥感云大数据在灾害、水体与湿地领域典型案例实践及GPT模型应用 2、GPT模型支持下的Python-GEE遥感云大数据分析、管理与可视化技术 GPT对于每个科研人员已经成为不可或缺的辅助工具,不同的研究领域和项目具有不同的需求。例如在科研编程…...

【LeetCode】19. 删除链表的倒数第 N 个结点
19. 删除链表的倒数第 N 个结点(中等) 方法:快慢指针 思路 为了找到倒数第 n 个节点,我们应该先找到最后一个节点,然后从它开始往前数 n-1 个节点就是要删除的节点。 对于一般情况:设置 fast 和 slow 两个…...

spring boot3.x集成swagger出现Type javax.servlet.http.HttpServletRequest not present
1. 问题出现原因 spring boot3.x版本依赖于jakarta依赖包,但是swagger依赖底层应用的javax依赖包,所以只要已启动就会报错。 2. 解决方案 移除swagger2依赖 <dependency><groupId>io.springfox</groupId><artifactId>springfo…...

《低代码指南》——智能化低代码开发实践案例
大模型能通过自然语言理解自动生成需求文档及代码供给低代码开发者使用,也具备自动检测和修复代码错误、自动优化代码、找出冗余并提供高效方案等自动化能力,为开发者带来需求模式、设计模式、开发模式的变化,节省时间成本、代码质量更优、进…...
 + 7) / 8)、字节对齐(((number) + 3) / 4 * 4))
268_C++_字节计算(((bits) + 7) / 8)、字节对齐(((number) + 3) / 4 * 4)
这段代码中包含了两个宏的定义,它们似乎用于进行位操作和字节对齐操作。让我们逐个来解析这两个宏: BITS_TO_BYTES(bits) 宏:#define BITS_TO_BYTES(bits) (((bits) + 7) / 8)这个宏的作用是将位数(bits)转换为字节数(bytes)。它的计算方式是将位数加上7,然后除以8,这…...
JavaWeb知识梳理(后端部分)
JavaWeb 静态web资源(如html 页面):指web页面中供人们浏览的数据始终是不变。 动态web资源:指web页面中供人们浏览的数据是由程序产生的,不同时间点访问web页面看到的内容各不相同。 静态web资源开发技术࿱…...

AI:07-基于卷积神经网络的海洋生物的识别
当涉及海洋生物的识别和研究时,基于深度学习的方法已经展现出了巨大的潜力。深度学习模型可以利用大量的图像和标记数据来自动学习特征,并实现高准确度的分类任务。本文将介绍如何使用深度学习技术来实现海洋生物的自动识别,并提供相应的代码示例。 数据收集和预处理 要训…...

centos7下docker设置新的下载镜像源并调整存放docker下载镜像的仓库位置
目录 1.设置镜像源 2.调整存放下载镜像的仓库位置 1.设置镜像源 在 /etc/docker下创建一个daemon.json文件。在json中下入 "registry-mirrors": ["https://docker.mirrors.ustc.edu.cn/"] 完成配置 加载配置 systemctl daemon-reload 重启docker sy…...

Gitea--私有git服务器搭建详细教程
一.官方文档 https://docs.gitea.com/zh-cn/说明 gitea 是一个自己托管的Git服务程序。他和GitHub, Gitlab等比较类似。他是从 Gogs 发展而来,gitea的创作团队重新fork了代码,并命名为giteagitea 功能特性多,能够满足我们所有的的代码管理需…...

SOLIDWORKS放样是什么意思?
SOLIDWORKS是一款广受欢迎的三维计算机辅助设计(CAD)软件,提供了许多强大的功能来帮助工程师实现他们的创意。其中一个重要的功能是放样功能,它在设计过程中起着至关重要的作用。本文将介绍SOLIDWORKS放样的概念、特点和应用。 放…...
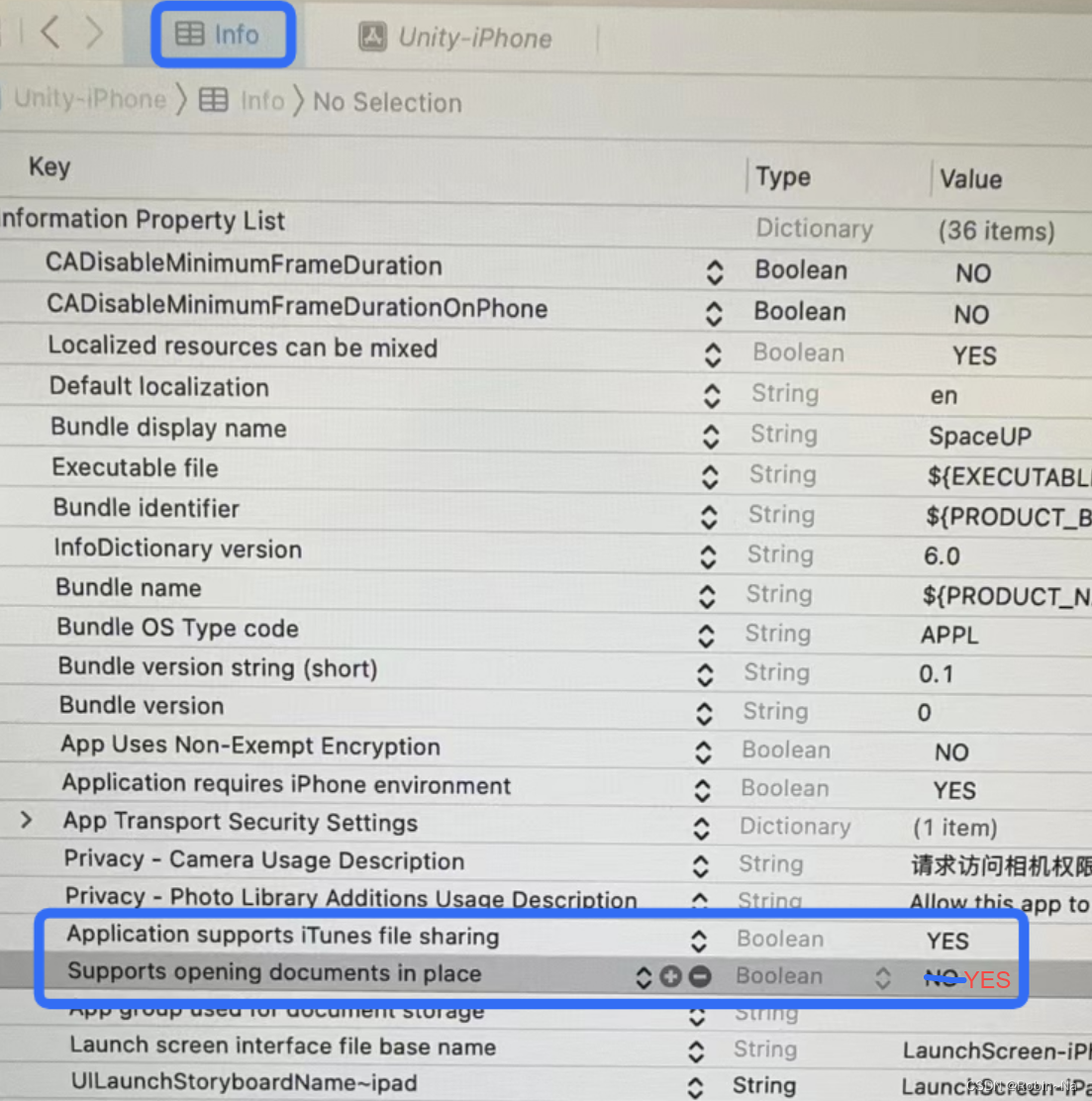
Xcode打包ipa文件,查看app包内文件
1、Xcode发布ipa文件前,在info中打开如下两个选项,即可在手机上查看app包名文件夹下的文件及数据。...
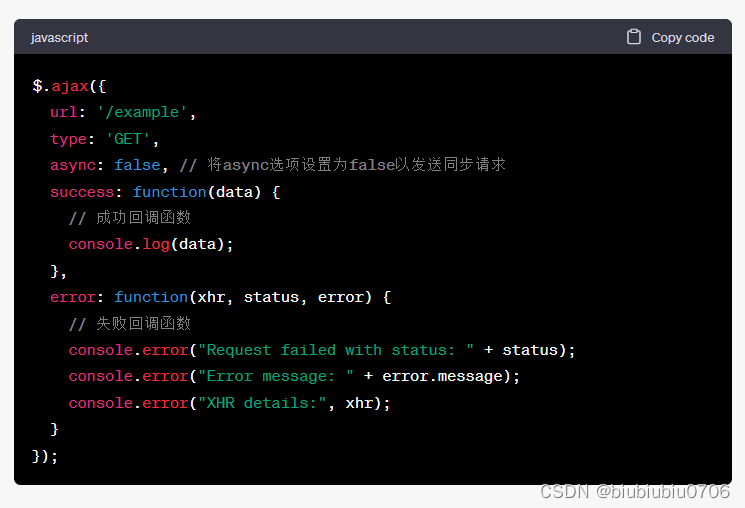
AJAX学习笔记6 JQuery对AJAX进行封装
AJAX学习笔记5同步与异步理解_biubiubiu0706的博客-CSDN博客 AJAX请求相关的代码都是类似的,有很多重复的代码,这些重复的代码能不能不写,能不能封装一个工具类。要发送ajax请求的话,就直接调用这个工具类中的相关函数即可。 用J…...
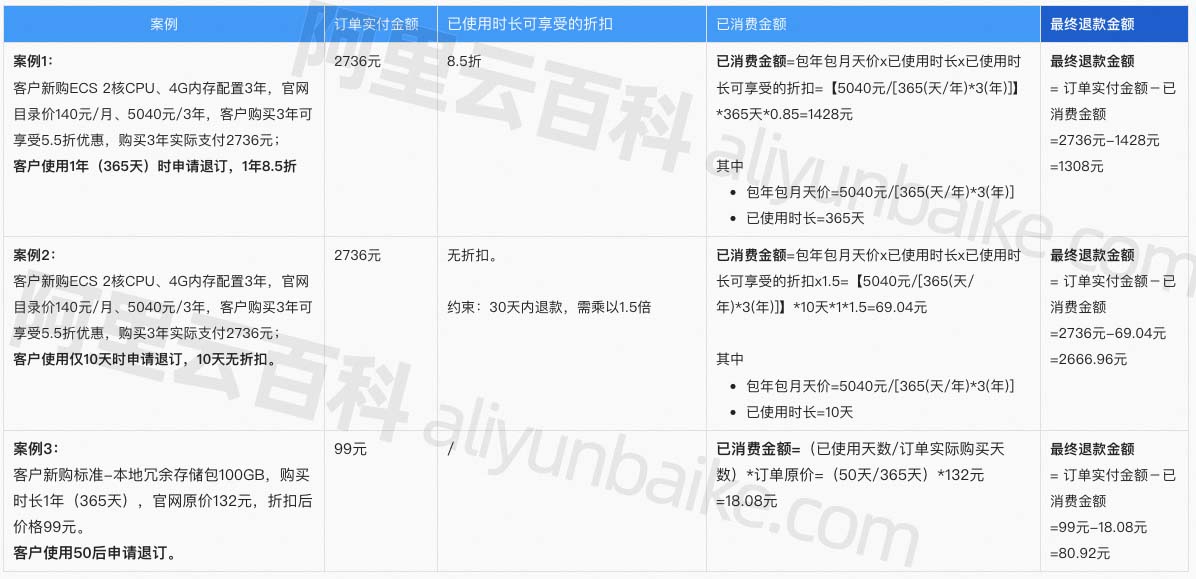
阿里云服务器退款规则_退款政策全解析
阿里云退款政策全解析,阿里云退款分为五天无理由全额退和非全额退订两种,阿里云百科以云服务器为例,阿里云服务器包年包月支持五天无理由全额退订,可申请无理由全额退款,如果是按量付费的云服务器直接释放资源即可。阿…...
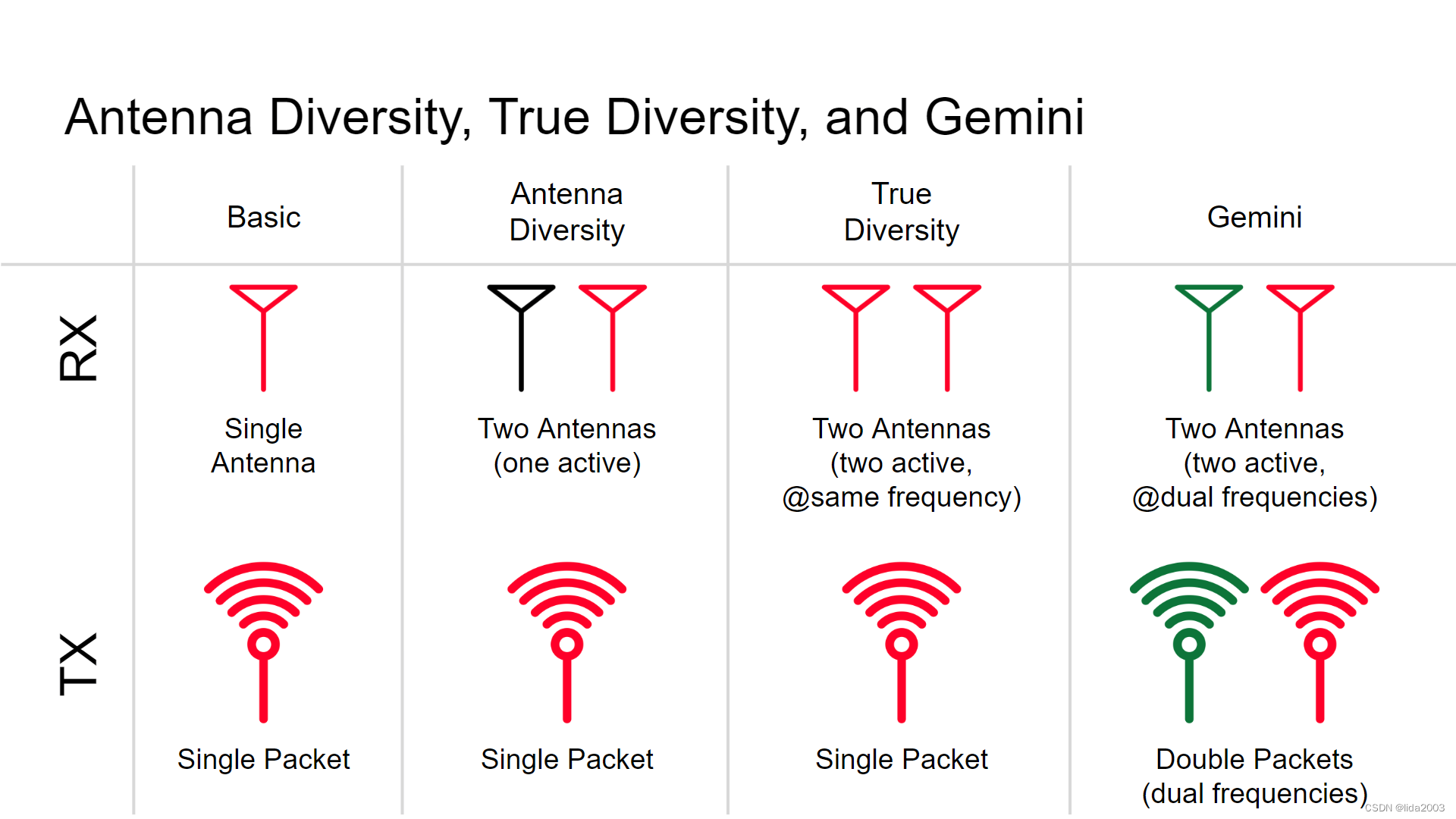
ExpressLRS开源之基本调试数据含义
ExpressLRS开源之基本调试数据含义 1. 源由2. 代码2.1 debugRcvrLinkstats2.2 debugRcvrSignalStats 3. 含义解释3.1 ID(packetCounter),Antenna,RSSI(dBm),LQ,SNR,PWR,FHSS,TimingOffset3.2 IRQ_CNT,RSSI_AVE,SNR_AVE,SNV_MAX,TELEM_CNT,FAIL_CNT 4. 总结5. 参考资料 1. 源由 …...

杰理701N可视化SDK:从stream.bin生成到工程导入的EQ调音闭环
1. 杰理701N可视化SDK与EQ调音基础 第一次接触杰理701N的开发者可能会好奇,这个可视化SDK到底能做什么?简单来说,它就像给声学工程师配了一把"声音雕刻刀"。通过图形化界面,你可以实时调整蓝牙耳机、音箱等设备的音效表…...

Flutter GetX实战:从Provider迁移到GetX,我的开发效率提升了多少?
Flutter GetX实战:从Provider迁移到GetX的效率革命 当Flutter开发团队面临状态管理方案的选择时,往往会陷入一种甜蜜的烦恼——官方推荐的Provider虽然稳定可靠,但第三方库GetX却以"全家桶"式的解决方案不断吸引开发者的目光。作为…...

手把手教你用三菱FX3U PLC的RS指令和RS2指令与电脑串口调试助手‘对话’
三菱FX3U PLC串口通信实战:从零搭建RS485数据收发系统 第一次接触工业控制系统的串口通信时,我被那些密密麻麻的接线和晦涩的协议参数弄得晕头转向。直到在自动化生产线上亲眼看到PLC通过两根电线与十几台设备稳定通信,才意识到串口技术的精妙…...

Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧
Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧 在高速PCB设计领域,Allegro 16.6作为行业标杆工具,其深度功能往往决定了设计效率的天花板。当面对BGA封装密度突破1000pin、信号速率迈入10Gbps时代的复杂主板时&#x…...

开源自动驾驶系统终极指南:从入门到精通
开源自动驾驶系统终极指南:从入门到精通 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trending/op/openpilo…...

Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行
Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为macOS软件安装更新而烦恼吗?…...
,全程复制粘贴即可)
从0到1:手把手教你搭建VSCode(附避坑指南,拒绝报错),全程复制粘贴即可
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南
如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_…...

本地化AI代码助手LLMDog:模块化框架与开源模型集成实践
1. 项目概述:一个为开发者设计的本地化AI代码助手最近在GitHub上闲逛,发现了一个挺有意思的项目叫“LLMDog”,作者是doganarif。乍一看这个名字,可能会联想到“AI狗”或者某种宠物,但它的全称其实是“Large Language M…...

基于MCP协议构建AI金融数据可视化服务器:从原理到实战部署
1. 项目概述:一个为AI智能体提供实时金融数据可视化的MCP服务器最近在折腾AI智能体(Agent)的生态,发现一个挺有意思的痛点:当你想让AI帮你分析股票、基金或者加密货币时,它往往只能给你干巴巴的数字和文字描…...