python3 简易 http server:实现本地与远程服务器传大文件
在个人目录下创建新文件httpserver.py :
vim httpserver.py
文件内容为python3代码:
# !/usr/bin/env python3
import datetime
import email
import html
import http.server
import io
import mimetypes
import os
import posixpath
import re
import shutil
import sys
import urllib.error
import urllib.parse
import urllib.request
from http import HTTPStatus__version__ = "0.1"
__all__ = ["SimpleHTTPRequestHandler"]class SimpleHTTPRequestHandler(http.server.BaseHTTPRequestHandler):server_version = "SimpleHTTP/" + __version__extensions_map = _encodings_map_default = {'.gz': 'application/gzip','.Z': 'application/octet-stream','.bz2': 'application/x-bzip2','.xz': 'application/x-xz',}def __init__(self, *args, directory=None, **kwargs):if directory is None:directory = os.getcwd()self.directory = os.fspath(directory)super().__init__(*args, **kwargs)def do_GET(self):f = self.send_head()if f:try:self.copyfile(f, self.wfile)finally:f.close()def do_HEAD(self):f = self.send_head()if f:f.close()def send_head(self):path = self.translate_path(self.path)f = Noneif os.path.isdir(path):parts = urllib.parse.urlsplit(self.path)if not parts.path.endswith('/'):# redirect browser - doing basically what apache doesself.send_response(HTTPStatus.MOVED_PERMANENTLY)new_parts = (parts[0], parts[1], parts[2] + '/',parts[3], parts[4])new_url = urllib.parse.urlunsplit(new_parts)self.send_header("Location", new_url)self.end_headers()return Nonefor index in "index.html", "index.htm":index = os.path.join(path, index)if os.path.exists(index):path = indexbreakelse:return self.list_directory(path)ctype = self.guess_type(path)if path.endswith("/"):self.send_error(HTTPStatus.NOT_FOUND, "File not found")return Nonetry:f = open(path, 'rb')except OSError:self.send_error(HTTPStatus.NOT_FOUND, "File not found")return Nonetry:fs = os.fstat(f.fileno())# Use browser cache if possibleif ("If-Modified-Since" in self.headersand "If-None-Match" not in self.headers):# compare If-Modified-Since and time of last file modificationtry:ims = email.utils.parsedate_to_datetime(self.headers["If-Modified-Since"])except (TypeError, IndexError, OverflowError, ValueError):# ignore ill-formed valuespasselse:if ims.tzinfo is None:# obsolete format with no timezone, cf.# https://tools.ietf.org/html/rfc7231#section-7.1.1.1ims = ims.replace(tzinfo=datetime.timezone.utc)if ims.tzinfo is datetime.timezone.utc:# compare to UTC datetime of last modificationlast_modif = datetime.datetime.fromtimestamp(fs.st_mtime, datetime.timezone.utc)# remove microseconds, like in If-Modified-Sincelast_modif = last_modif.replace(microsecond=0)if last_modif <= ims:self.send_response(HTTPStatus.NOT_MODIFIED)self.end_headers()f.close()return Noneself.send_response(HTTPStatus.OK)self.send_header("Content-type", ctype)self.send_header("Content-Length", str(fs[6]))self.send_header("Last-Modified",self.date_time_string(fs.st_mtime))self.end_headers()return fexcept:f.close()raisedef list_directory(self, path):try:list_dir = os.listdir(path)except OSError:self.send_error(HTTPStatus.NOT_FOUND, "No permission to list_dir directory")return Nonelist_dir.sort(key=lambda a: a.lower())r = []try:display_path = urllib.parse.unquote(self.path, errors='surrogatepass')except UnicodeDecodeError:display_path = urllib.parse.unquote(path)display_path = html.escape(display_path, quote=False)enc = sys.getfilesystemencoding()form = """<h1>文件上传</h1>\n<form ENCTYPE="multipart/form-data" method="post">\n<input name="file" type="file"/>\n<input type="submit" value="upload"/>\n</form>\n"""title = 'Directory listing for %s' % display_pathr.append('<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" ''"http://www.w3.org/TR/html4/strict.dtd">')r.append('<html>\n<head>')r.append('<meta http-equiv="Content-Type" ''content="text/html; charset=%s">' % enc)r.append('<title>%s</title>\n</head>' % title)r.append('<body>%s\n<h1>%s</h1>' % (form, title))r.append('<hr>\n<ul>')for name in list_dir:fullname = os.path.join(path, name)displayname = linkname = name# Append / for directories or @ for symbolic linksif os.path.isdir(fullname):displayname = name + "/"linkname = name + "/"if os.path.islink(fullname):displayname = name + "@"# Note: a link to a directory displays with @ and links with /r.append('<li><a href="%s">%s</a></li>' % (urllib.parse.quote(linkname, errors='surrogatepass'),html.escape(displayname, quote=False)))r.append('</ul>\n<hr>\n</body>\n</html>\n')encoded = '\n'.join(r).encode(enc, 'surrogate escape')f = io.BytesIO()f.write(encoded)f.seek(0)self.send_response(HTTPStatus.OK)self.send_header("Content-type", "text/html; charset=%s" % enc)self.send_header("Content-Length", str(len(encoded)))self.end_headers()return fdef translate_path(self, path):# abandon query parameterspath = path.split('?', 1)[0]path = path.split('#', 1)[0]# Don't forget explicit trailing slash when normalizing. Issue17324trailing_slash = path.rstrip().endswith('/')try:path = urllib.parse.unquote(path, errors='surrogatepass')except UnicodeDecodeError:path = urllib.parse.unquote(path)path = posixpath.normpath(path)words = path.split('/')words = filter(None, words)path = self.directoryfor word in words:if os.path.dirname(word) or word in (os.curdir, os.pardir):# Ignore components that are not a simple file/directory namecontinuepath = os.path.join(path, word)if trailing_slash:path += '/'return pathdef copyfile(self, source, outputfile):shutil.copyfileobj(source, outputfile)def guess_type(self, path):base, ext = posixpath.splitext(path)if ext in self.extensions_map:return self.extensions_map[ext]ext = ext.lower()if ext in self.extensions_map:return self.extensions_map[ext]guess, _ = mimetypes.guess_type(path)if guess:return guessreturn 'application/octet-stream'def do_POST(self):r, info = self.deal_post_data()self.log_message('%s, %s => %s' % (r, info, self.client_address))enc = sys.getfilesystemencoding()res = ['<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" ''"http://www.w3.org/TR/html4/strict.dtd">','<html>\n<head>','<meta http-equiv="Content-Type" content="text/html; charset=%s">' % enc,'<title>%s</title>\n</head>' % "Upload Result Page",'<body><h1>%s</h1>\n' % "Upload Result"]if r:res.append('<p>SUCCESS: %s</p>\n' % info)else:res.append('<p>FAILURE: %s</p>' % info)res.append('<a href=\"%s\">back</a>' % self.headers['referer'])res.append('</body></html>')encoded = '\n'.join(res).encode(enc, 'surrogate escape')f = io.BytesIO()f.write(encoded)length = f.tell()f.seek(0)self.send_response(200)self.send_header("Content-type", "text/html")self.send_header("Content-Length", str(length))self.end_headers()if f:self.copyfile(f, self.wfile)f.close()def deal_post_data(self):content_type = self.headers['content-type']if not content_type:return False, "Content-Type header doesn't contain boundary"boundary = content_type.split("=")[1].encode()remain_bytes = int(self.headers['content-length'])line = self.rfile.readline()remain_bytes -= len(line)if boundary not in line:return False, "Content NOT begin with boundary"line = self.rfile.readline()remain_bytes -= len(line)fn = re.findall(r'Content-Disposition.*name="file"; filename="(.*)"', line.decode())if not fn:return False, "Can't find out file name..."path = self.translate_path(self.path)fn = os.path.join(path, fn[0])line = self.rfile.readline()remain_bytes -= len(line)line = self.rfile.readline()remain_bytes -= len(line)try:out = open(fn, 'wb')except IOError:return False, "Can't create file to write, do you have permission to write?"preline = self.rfile.readline()remain_bytes -= len(preline)while remain_bytes > 0:line = self.rfile.readline()remain_bytes -= len(line)if boundary in line:preline = preline[0:-1]if preline.endswith(b'\r'):preline = preline[0:-1]out.write(preline)out.close()return True, "File '%s' upload success!" % fnelse:out.write(preline)preline = linereturn False, "Unexpect Ends of data."if __name__ == '__main__':try:port = int(sys.argv[1])except Exception:port = 8000print('-------->> Warning: Port is not given, will use deafult port: 8000 ')print('-------->> if you want to use other port, please execute: ')print('-------->> python SimpleHTTPServerWithUpload.py port ')print("-------->> port is a integer and it's range: 1024 < port < 65535 ")http.server.test(HandlerClass=SimpleHTTPRequestHandler,ServerClass=http.server.HTTPServer,port=port)
在需要暴露的目录下启动http服务,如/data/codes/
cd /data/codes/
python3 httpserver.py 8888
随后在个人电脑访问http://ip:8888即可浏览文件、上传文件:
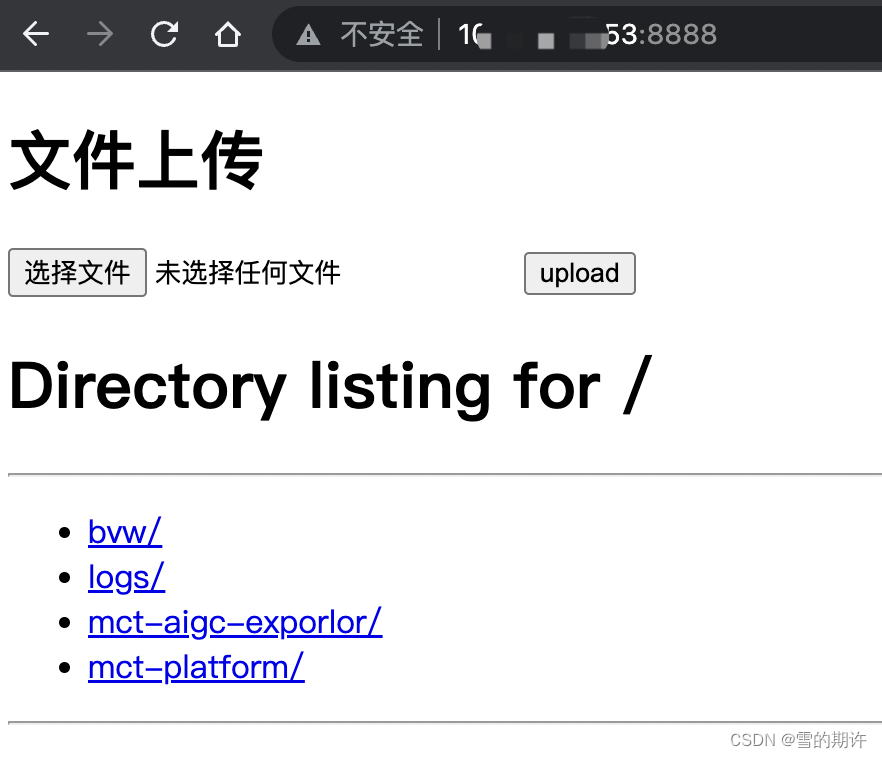
相关文章:
python3 简易 http server:实现本地与远程服务器传大文件
在个人目录下创建新文件httpserver.py : vim httpserver.py文件内容为python3代码: # !/usr/bin/env python3 import datetime import email import html import http.server import io import mimetypes import os import posixpath import re import…...
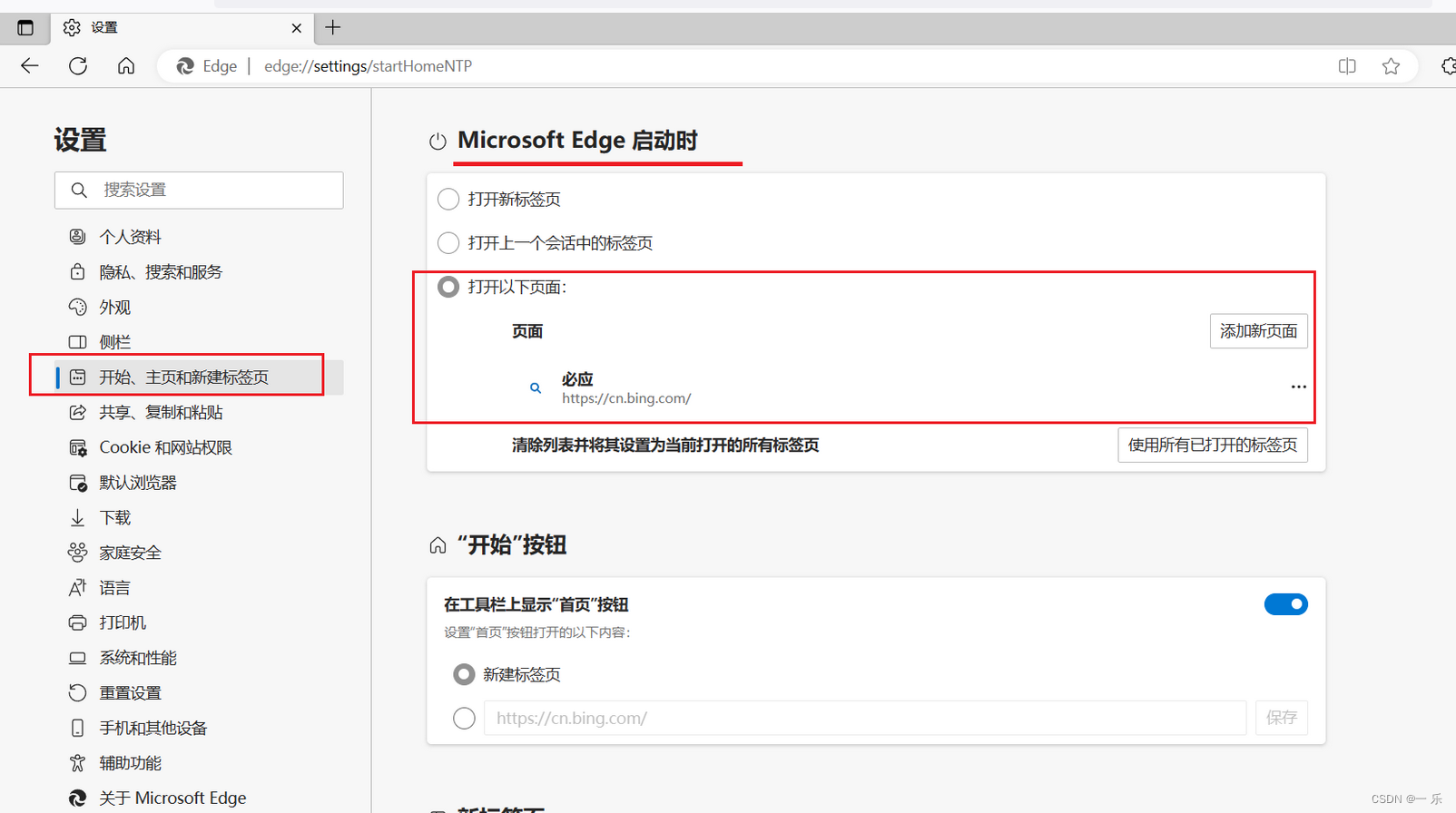
Microsoft Edge 主页启动diy以及常用的扩展、收藏夹的网站
一、Microsoft Edge 主页启动diy 二、常用的扩展 1、去广告:uBlock Origin 2、翻译: 页面翻译:右键就有了,已经内置了划词翻译 3、超级复制 三、收藏夹的网站...

文末送书!谈谈原型模式在JAVA实战开发中的应用(附源码+面试题)
作者主页:Designer 小郑 作者简介:3年JAVA全栈开发经验,专注JAVA技术、系统定制、远程指导,致力于企业数字化转型,CSDN博客专家,蓝桥云课认证讲师。 本文讲解了 Java 设计模式中的原型模式,并给…...

视频汇聚/视频云存储/视频监控管理平台EasyCVR启动时打印starting server:listen tcp,该如何解决?
视频云存储/安防监控EasyCVR视频汇聚平台基于云边端智能协同,可实现视频监控直播、视频轮播、视频录像、云存储、回放与检索、智能告警、服务器集群、语音对讲、云台控制、电子地图、H.265自动转码H.264、平台级联等。为了便于用户二次开发、调用与集成,…...
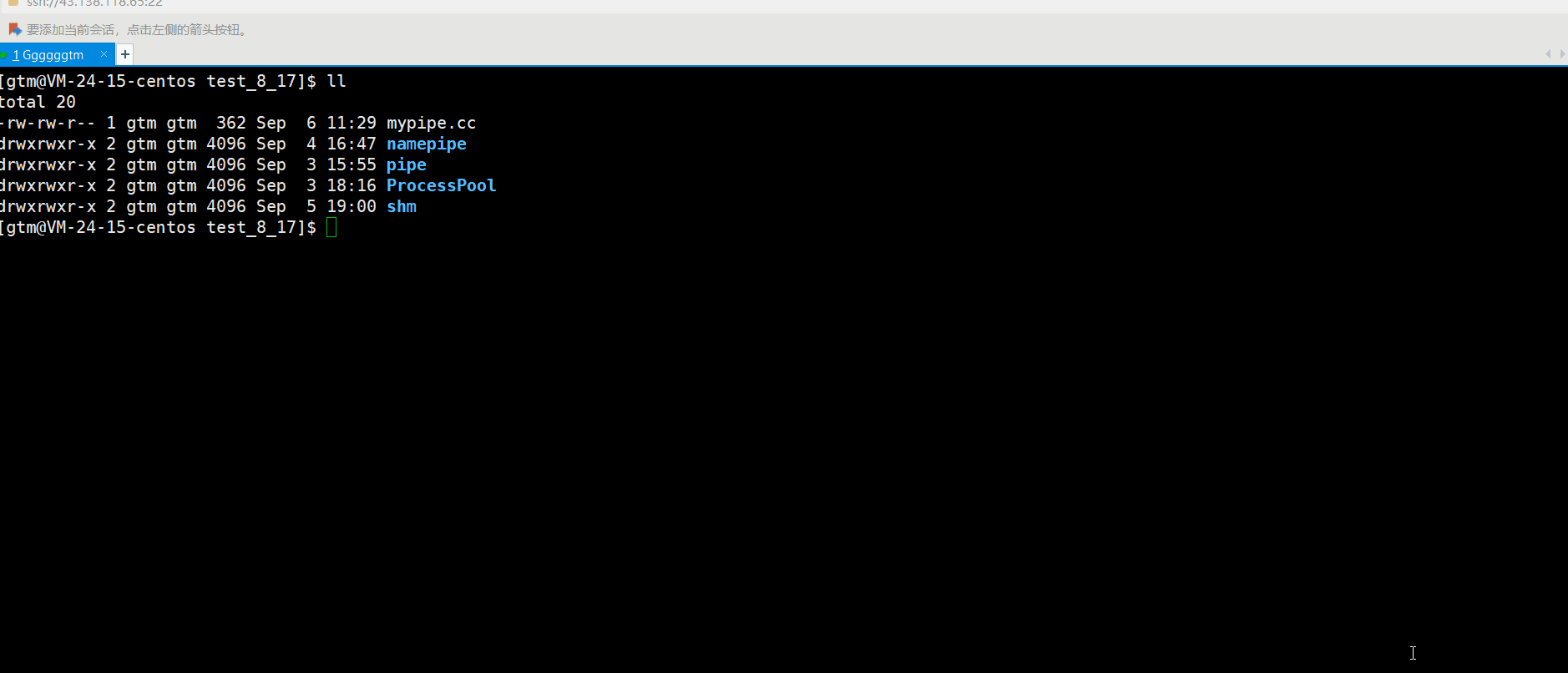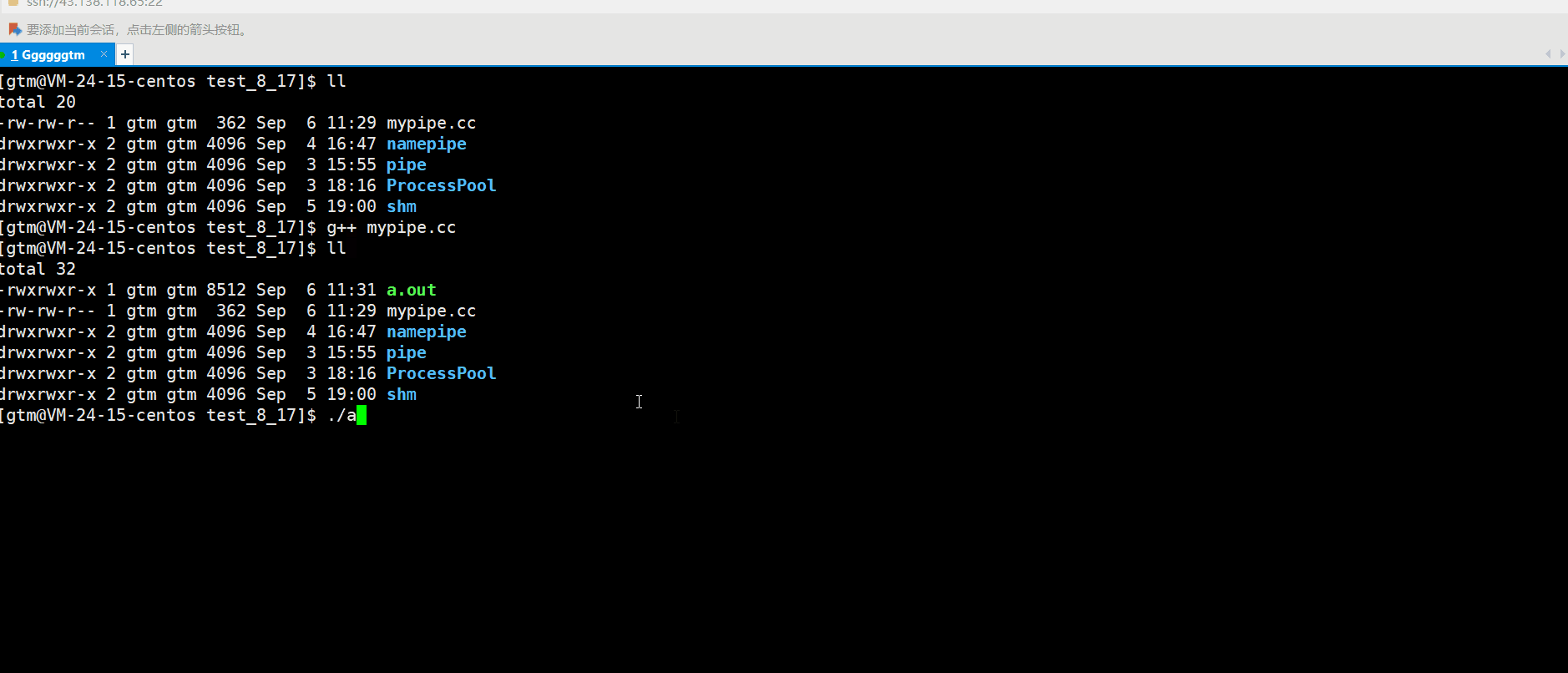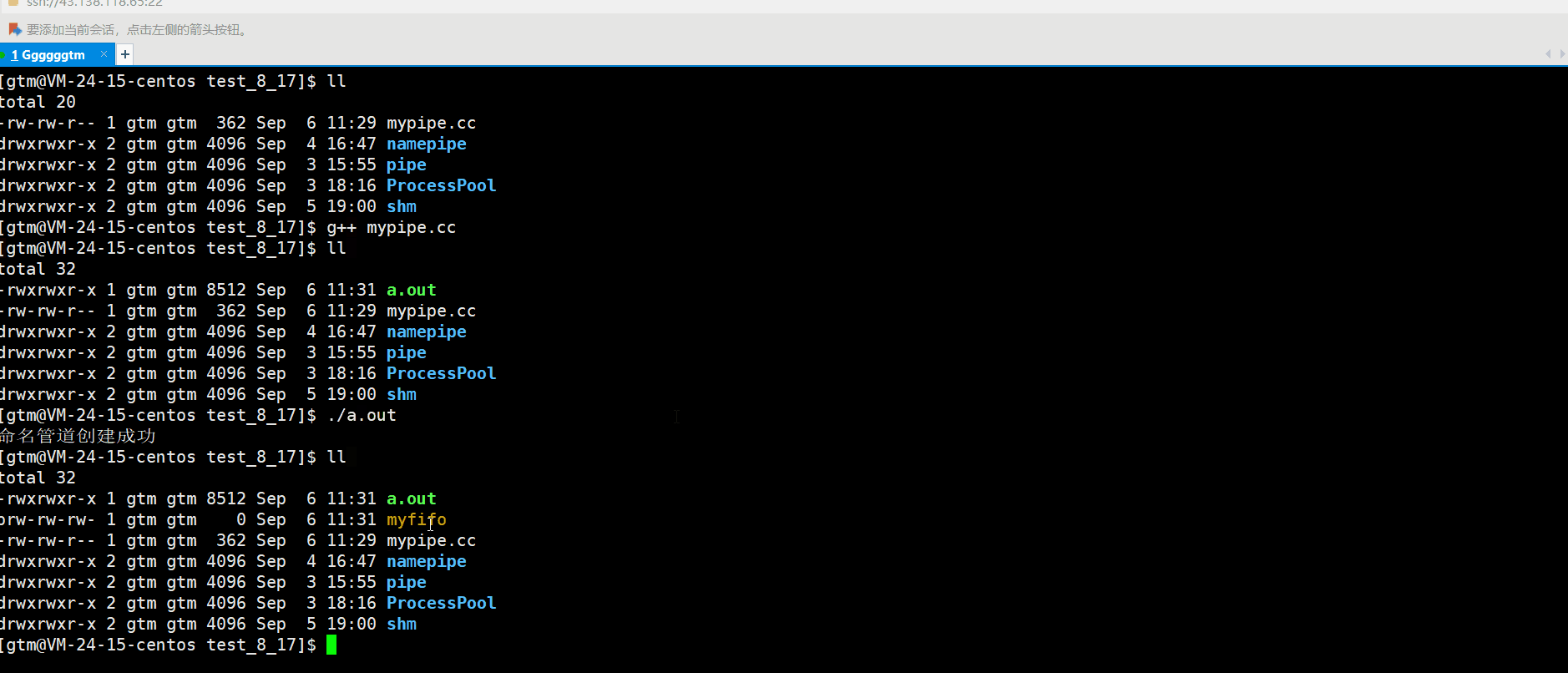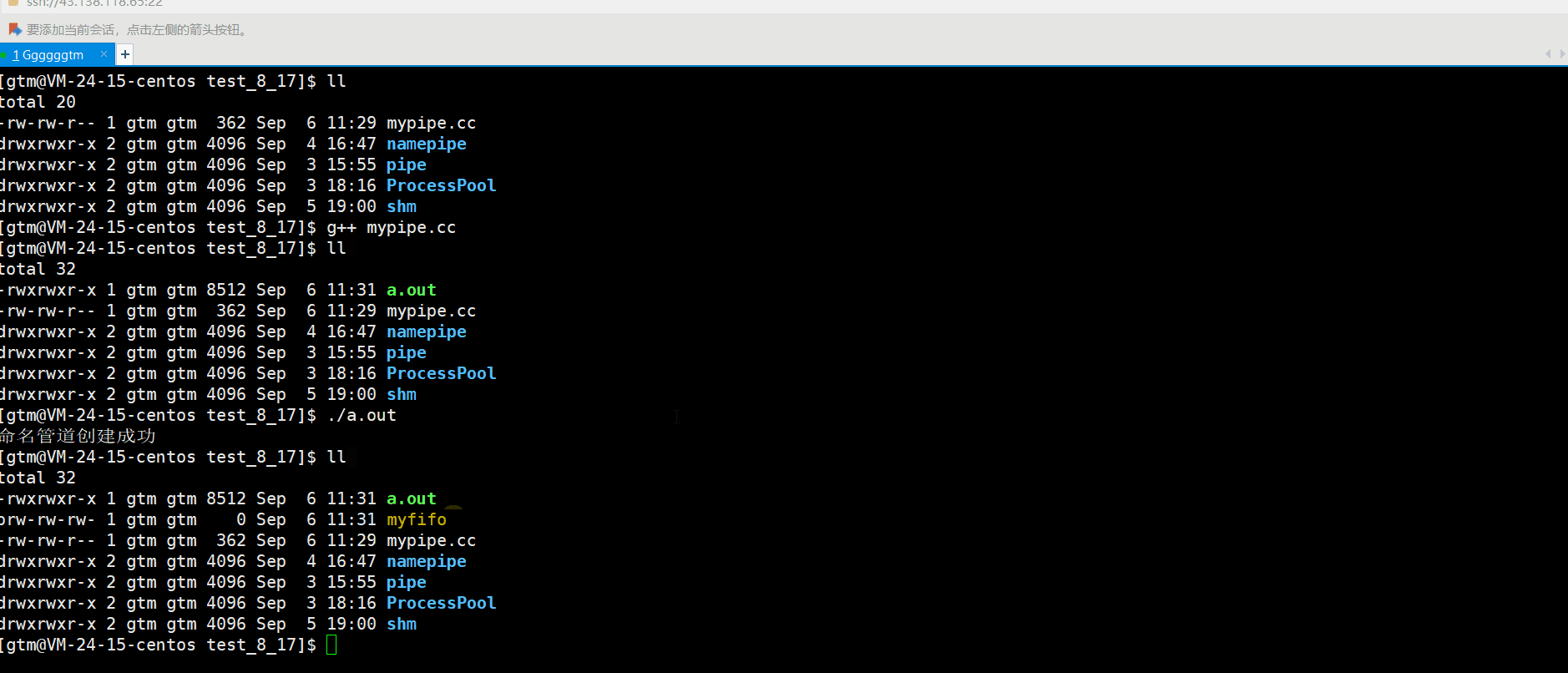
【Linux从入门到精通】通信 | 管道通信(匿名管道 命名管道)
本派你文章主要是对进程通信进行详解。主要内容是介绍 为什么通信、怎么进行通信。其中本篇文章主要讲解的是管道通信。希望本篇文章会对你有所帮助。 文章目录 一、进程通信简单介绍 1、1 什么是进程通信 1、2 为什么要进行通信 1、3 进程通信的方式 二、匿名管道 2、1 什么是…...

实践和项目:解决实际问题时,选择合适的数据结构和算法
文章目录 选择合适的数据结构数组链表栈队列树图哈希表 选择合适的算法实践和项目 🎉欢迎来到数据结构学习专栏~实践和项目:解决实际问题时,选择合适的数据结构和算法 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT…...
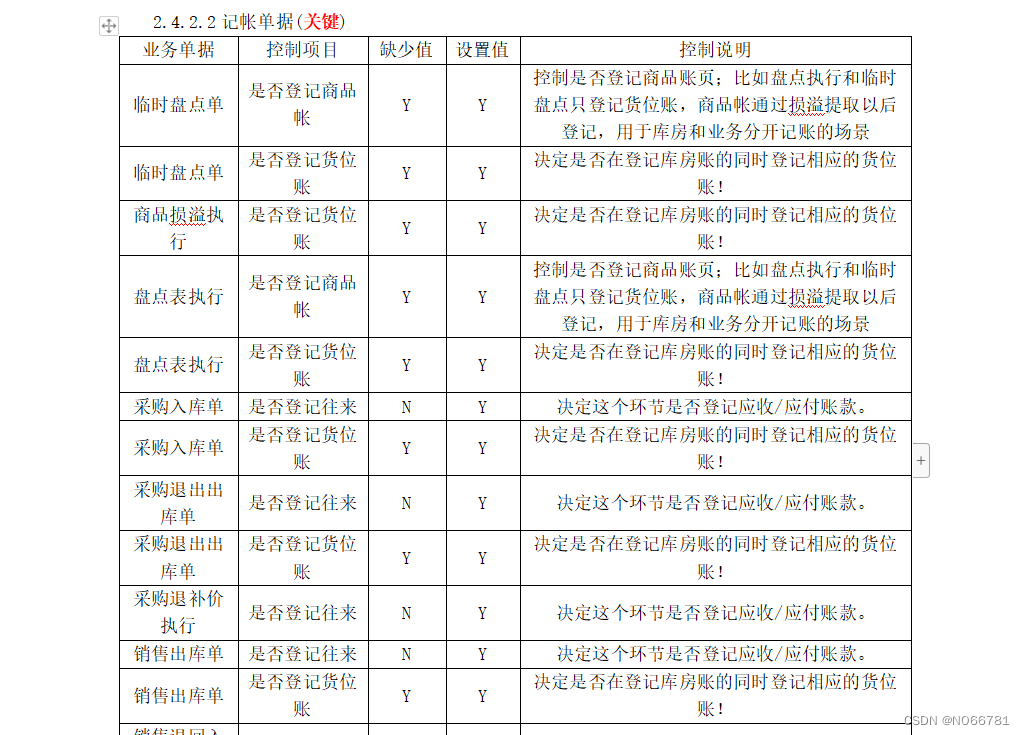
上线检查工具(待完善)
根据V11《CEBPM系统上线CheckList》整理而得,适用于V11,DHERP,Oracle和MSSQL数据库,检查内容还不完善。 上图: 1)数据库连接 2)双击[连接别名],可选择历史连接 3)主界面…...
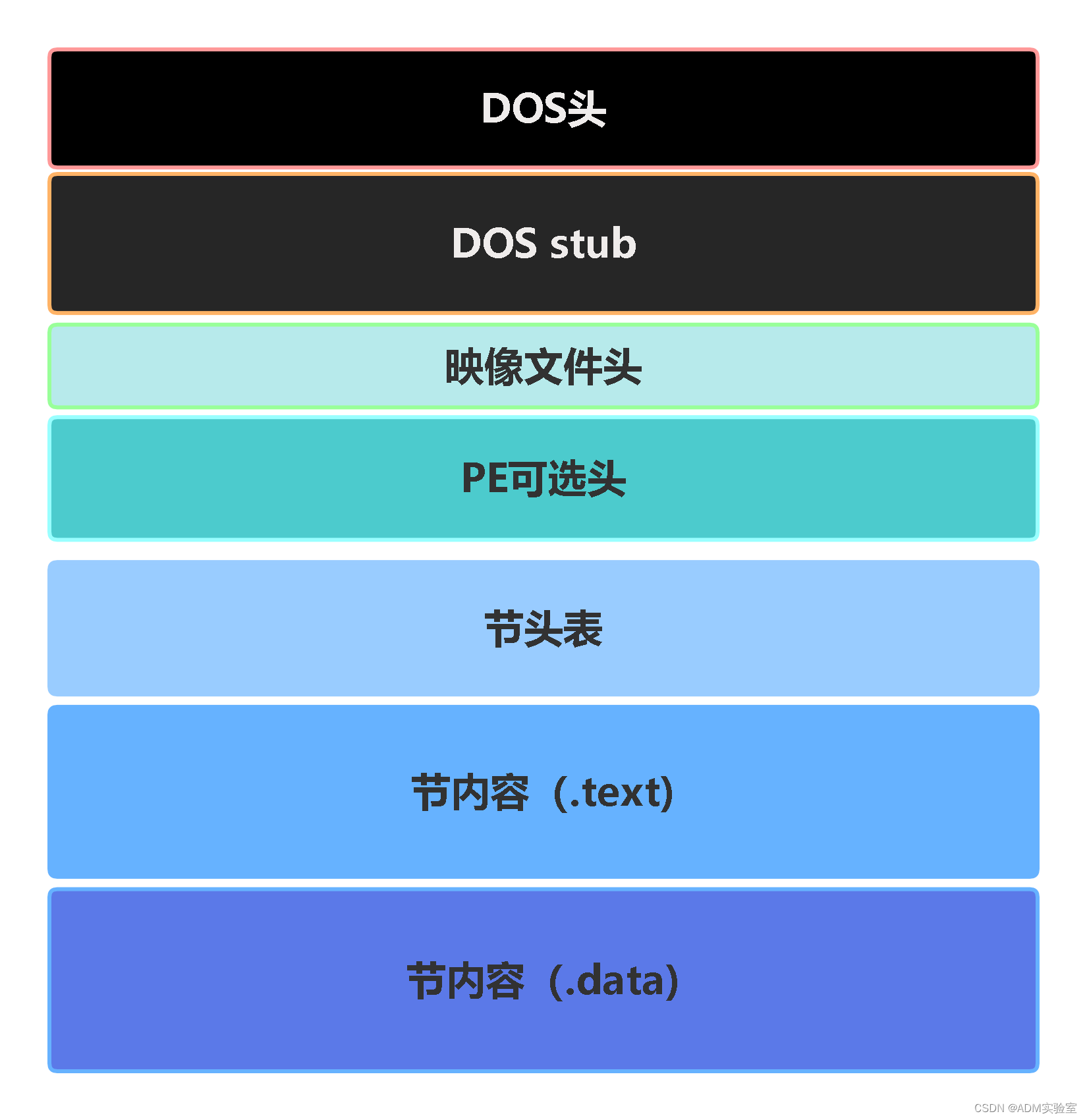
PE文件格式详解
摘要 本文描述了Windows系统的PE文件格式。 PE文件格式简介 PE(Portable Executable)文件格式是一种Windows操作系统下的可执行文件格式。PE文件格式是由Microsoft基于COFF(Common Object File Format)格式所定义的,…...

【Alibaba中间件技术系列】「RocketMQ技术专题」RocketMQ消息发送的全部流程和落盘原理分析
RocketMQ目前在国内应该是比较流行的MQ 了,目前本人也在公司的项目中进行使用和研究,借着这个机会,分析一下RocketMQ 发送一条消息到存储一条消息的过程,这样会对以后大家分析和研究RocketMQ相关的问题有一定的帮助。 分析的总体…...

关于vue首屏加载loading问题
注意:网上搜索出来的都是教你在index.html里面<div id"app"><div class"loading"></div>或者在app.vue Mounte生命周期函数控制app和loading的显示和隐藏,这里会有一个问题,就是js渲染页面需要时间,一…...

数据库性能测试实践:慢查询统计分析
01、慢查询 查看是否开启慢查询 mysql> show variables like %slow%’; 如图所示: 系统变量log_slow_admin_statements 表示是否将慢管理语句例如ANALYZE TABLE和ALTER TABLE等记入慢查询日志启用log_slow_extra系统变量 (从MySQL 8.0.14开始提供&a…...
)
windows wsl ssh 配置流程 Permission denied (publickey)
wsl ssh连接失败配置流程 1、wsl2 ifconfig的网络ip是虚拟的ip,所以采用wsl1 2、wsl1的安装教程。 3、openssh-server重装 sudo apt-get update sudo apt-get remove openssh-server sudo apt-get install openssh-server4、修改ssh配置文件 sudo vim /etc/ss…...

OpenCV(五):图像颜色空间转换
目录 1.图像颜色空间介绍 RGB 颜色空间 2.HSV 颜色空间 3.RGBA 颜色空间 2.图像数据类型间的互相转换convertTo() 3.不同颜色空间互相转换cvtColor() 4.Android JNI demo 1.图像颜色空间介绍 RGB 颜色空间 RGB 颜色空间是最常见的颜色表示方式之一,其中 R、…...

一图胜千言!数据可视化多维讲解(Python)
数据聚合、汇总和可视化是支撑数据分析领域的三大支柱。长久以来,数据可视化都是一个强有力的工具,被业界广泛使用,却受限于 2 维。在本文中,作者将探索一些有效的多维数据可视化策略(范围从 1 维到 6 维)。…...

Hbase相关总结
Hbase 1、Hbase的数据写入流程 由客户端发起写入数据的请求, 首先会先连接zookeeper 从zookeeper中获取到当前HMaster的信息,并与HMaster建立连接从HMaster中获取RegionServer列表信息 连接meta表对应的RegionServer地址, 从meta表获取当前要写入的表对应region被那个RegionS…...

C++ Primer Plus第二章编程练习答案
答案仅供参考,实际运行效果取决于运行平台和运行软件 1.编写一个C程序,它显示您的姓名和地址。 #include <iostream> using namespace std;int main() {cout << "My name is sakuraaa0908 C Primer Plus." << endl;cout &…...
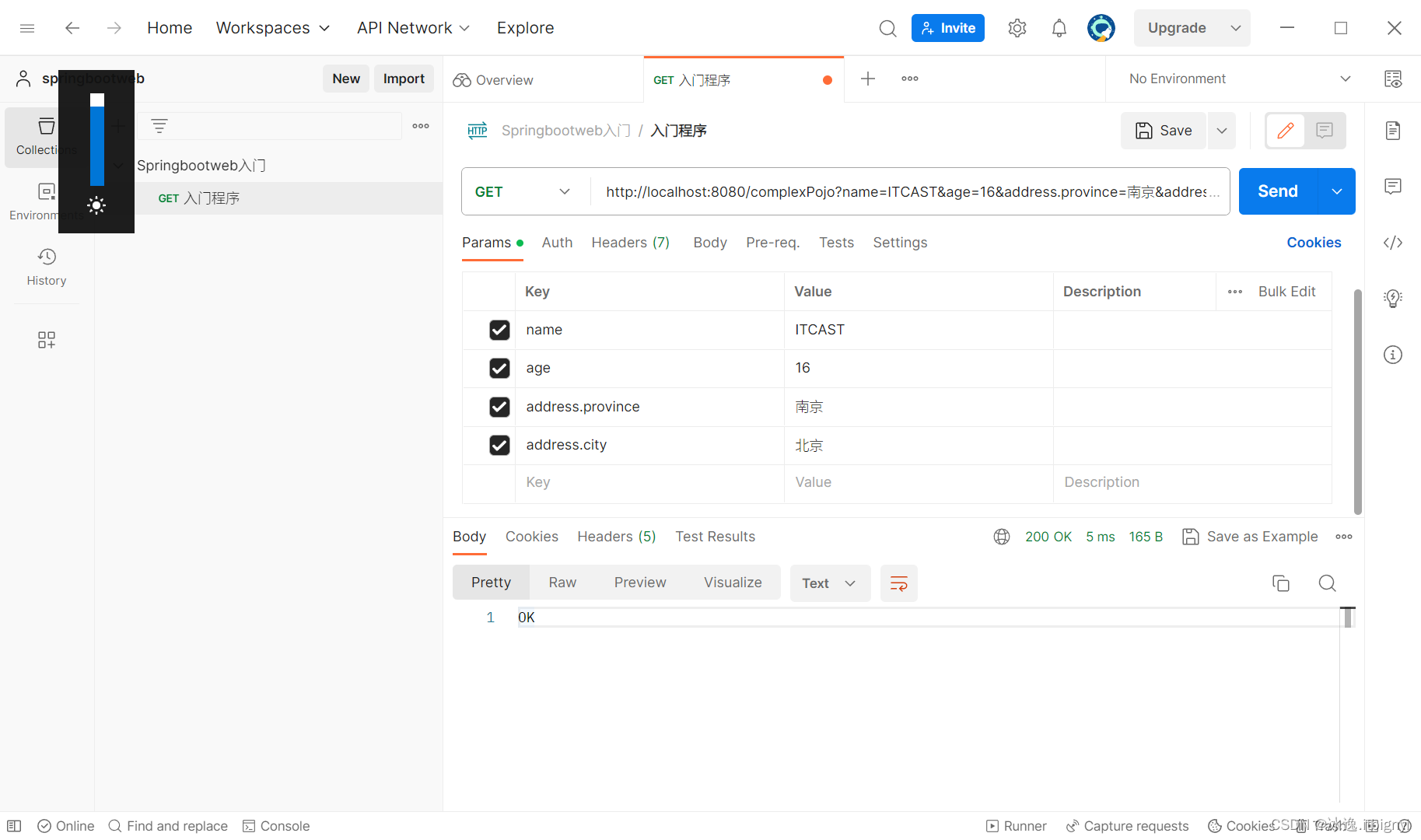
Web后端开发(请求响应)上
请求响应的概述 浏览器(请求)<--------------------------(HTTP协议)---------------------->(响应)Web服务器 请求:获取请求数据 响应:设置响应数据 BS架构:浏览器/服务器架构模式。…...

LeetCode 338. Counting Bits【动态规划,位运算】简单
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

解释 Git 的基本概念和使用方式。
Git 是一种分布式版本控制系统,它可以跟踪文件的修改历史、协调多个人员的工作、将分支合并到一起等。下面是 Git 的一些基本概念和使用方式。 - 仓库(Repository):存储代码、版本控制历史记录等的地方。 - 分支(Bran…...
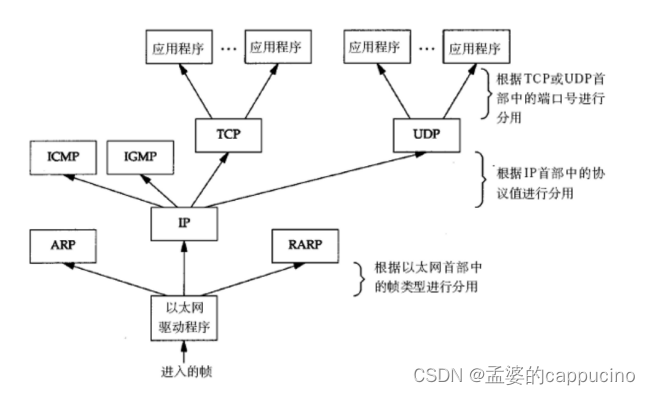
计算机网络初识
目录 1、计算机网络背景 网络发展 认识 "协议" 2、网络协议初识 OSI七层模型 TCP/IP五层(或四层)模型 3、网络传输基本流程 网络传输流程图 数据包封装和分用 4、网络中的地址管理 认识IP地址 认识MAC地址 1、计算机网络背景 网络发展 在之前呢&…...

100x-dev项目解析:从高效工具链到架构思维,打造10倍效能开发者
1. 项目概述与核心价值 最近在开发者社区里,一个名为 rajitsaha/100x-dev 的项目引起了我的注意。乍一看这个标题,可能会让人联想到某种“百倍效率”的开发工具或框架,充满了极客式的夸张与诱惑。作为一名在软件工程一线摸爬滚打了十多年的…...
)
别再只用默认密码了!手把手教你用Hydra和Burp Suite搞定SSH、Web后台的弱口令检测(附实战避坑指南)
企业安全自查实战:Hydra与Burp Suite弱口令检测全流程解析 当你的服务器突然被植入挖矿程序,或是客户数据在暗网明码标价出售时,80%的情况都始于一个被忽视的弱口令。这不是危言耸听——2023年Verizon数据泄露调查报告显示,弱口令…...

3分钟搞定!终极游戏模组管理器XXMI-Launcher完整使用指南
3分钟搞定!终极游戏模组管理器XXMI-Launcher完整使用指南 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI-Launcher是一款专业的游戏模组启动器,专为…...

单目视频分析系统实现乒乓球轨迹与旋转实时检测
1. 项目背景与核心价值乒乓球运动中的轨迹和旋转分析一直是体育科技领域的热点问题。传统方法依赖高速摄像机阵列或多传感器融合方案,成本高昂且部署复杂。我们开发的这套单目视频分析系统,仅需普通智能手机或监控摄像头拍摄的视频流,就能实时…...

Nacos客户端日志太吵?Spring Boot/Cloud项目里这样配置,瞬间清净
Nacos客户端日志优化实战:Spring Boot/Cloud项目静音指南 微服务架构下,Nacos作为配置中心和注册中心的核心组件,其客户端日志输出常常成为开发者调试时的"甜蜜负担"。想象一下这样的场景:你在IDEA中启动Spring Cloud服…...

【优化求解】基于Sarsa强化学习的异构网络切换算法matlab仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &…...

NanoPi M6硬件解析与嵌入式开发实践
1. NanoPi M6 硬件架构深度解析NanoPi M6 是一款基于 Rockchip RK3588S SoC 设计的单板计算机,其硬件配置在当前 SBC 领域堪称旗舰级。作为长期从事嵌入式开发的工程师,我认为这款板卡最值得关注的是其平衡的性能与扩展性设计。1.1 核心处理器性能剖析RK…...

PREM、AK135、STW105:三大地球模型在负荷变形计算中的表现差异与选择建议
PREM、AK135与STW105:地球模型选型实战指南与位移计算优化 当我们站在青藏高原的冰川旁,看着GPS监测站记录的地表每年几厘米的垂直运动时,很少有人会想到,这些位移数据背后隐藏着地球内部结构的奥秘。地球并非刚体,而是…...

Arm Cortex-A75错误记录寄存器架构与RAS机制解析
1. Cortex-A75错误记录寄存器架构解析 在Arm Cortex-A75处理器架构中,错误记录寄存器(Error Record Registers)构成了可靠性、可用性和可维护性(RAS)功能的核心基础设施。这套机制通过专用寄存器组捕获和分类硬件运行时错误,为系统级错误诊断提供硬件支持…...

Newton性能分析工具:找出仿真瓶颈的实用方法
Newton性能分析工具:找出仿真瓶颈的实用方法 【免费下载链接】newton An open-source, GPU-accelerated physics simulation engine built upon NVIDIA Warp, specifically targeting roboticists and simulation researchers. 项目地址: https://gitcode.com/Git…...