C++初阶:C++入门
目录
一.iostream文件
二.命名空间
2.1.命名空间的定义
2.2.命名空间的使用
三.C++的输入输出
四.缺省参数
4.1.缺省参数概念
4.2.缺省参数分类
4.3.缺省参数注意事项
4.4.缺省参数用途
五.函数重载
5.1.重载函数概念
5.2.C++支持函数重载的原理--名字修饰(name Mangling)
5.3.extern "C"
六.引用
6.1.引用的概念
6.2.引用的特性
6.3.引用的使用场景
6.3.1.引用作为函数参数
6.3.2.引用作为函数返回值
6.4.传值和传引用效率比较
值和引用的作为参数的性能比较
值和引用的作为返回值类型的性能比较
6.5.常引用
6.6.引用和指针的区别
七.内联函数
7.1.内联函数定义
7.2.内联函数特性
7.3.内联函数与宏函数的区别
八.auto关键字
8.1.auto简介
8.2.auto的使用细则
8.3.auto不能推导的场景
九.基于范围的for循环
9.1.范围for的语法
9.2.范围for的使用条件
十.指针空值nullptr
前言:
C++是在C的基础之上,容纳进去了面向对象编程思想,并增加了许多有用的库,以及编程范式
等。熟悉C语言之后,对C++学习有一定的帮助,本章节主要目标:
- 补充C语言语法的不足,以及C++是如何对C语言设计不合理的地方进行优化的,比如:作用
- 域方面、IO方面、函数方面、指针方面、宏方面等;
- 为后续类和对象学习打基础。
首先,我们先来编写一个简单的C++程序:
#include<iostream>
using namespace std;int main()
{cout << "hello C++" << endl;return 0;
}接下来针对该程序中的主要语法进行详细讲解。
一.iostream文件
iostream是标准的C++头文件,在旧的标准C++中,使用的是iostream.h,实际上这两个文件是不同的,在编译器include文件夹里它是两个文件,并且内容不同。现在C++标准明确提出不支持后缀为.h的头文件,为了和C语言区分开,C++标准规定不使用后缀.h的头文件。这不只是形式上的改变,其实现也有所不同。
二.命名空间
using namespace std:该段代码是引用全局命名空间,在讲解全局命名空间之前,先来学习一下什么是命名空间。命名空间实际上是由程序设计者命名的内存区域,程序设计者可以根据需要指定一些有名字的空间区域,把一些自己定义的变量,函数等标识符存放在这个空间中,从而与其他实体定义分隔开来。
案例分析:
#include <stdio.h>int rand = 0;int main()
{printf("%d\n", rand);return 0;
}
运行结果:
![]()
但是,当我们加上头文件:#include<stdlib.h>
#include <stdio.h>
#include <stdlib.h>int rand = 0;int main()
{printf("%d\n", rand);return 0;
}
运行结果:
![]()
可以看出, 在加上头文件stdlib之后,程序却运行出错。究其原因可以发现:在头文件stdlib中已经定义了名为rand的函数,而编译器又无法区分所打印的rand是函数还是变量,所以编译器在运行程序的过程中会提示“rand”重定义,最终导致程序运行出错。
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存
在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,
以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
2.1.命名空间的定义
namespace 空间名 {......}namespace是定义命名空间的关键字,空间名可以用任意合法的标识符,在{ }内声明空间成员,例如定义一个命名空间A1,代码如下所示:
namespace A1
{int a = 10;
}则变量a只在A1空间内({ }作用域)有效,命名空间的作用就是建立一些互相分隔的作用域,把一些实体定义分隔开来。
正常的命名空间定义:
namespace N
{//命名空间中可以定义变量/函数/类型//定义变量int rand = 10;//定义函数int Add(int left, int right){return left + right;}//定义类型struct Node{struct Node* next;int val;};
}嵌套的命名空间定义
namespace N1
{int a;int b;int Add(int left, int right){return left + right;}namespace N2{int c;int d;int Sub(int left, int right){return left - right;}}
}同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中
注意:一个工程中的test.h和上面test.cpp中两个N1会被合并成一个
namespace N1
{int Mul(int left, int right){return left * right;}
}注意:
一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中。
2.2.命名空间的使用
当命名空间外的作用域要使用空间内定义的标识符时,有三种方法可以使用:
a.用空间名加上作用域标识符“::” 来标识要引用的实体
namespace sql
{namespace A{int rand = 0;//定义函数void func(){printf("func()\n");}}
}int main()
{printf("%d\n", sql::A::rand);return 0;
}在引用处指明变量所属的空间,就可以对变量进行操作了。
b.使用using关键字,在要引用空间实体的上面,使用using关键字引入要使用的空间变量
namespace sql
{namespace A{int sum = 0;//定义函数void func(){printf("func()\n");}}
}int main()
{printf("%d\n",sql::A::sum);return 0;
}这种情况下,只能使用using引入的标识符,如以上代码中只引入了sum,如果sql空间里还有标识符b,则b不能被使用,但可以使用sql::A::b的形式。
c.使用using关键字直接引入要使用的变量所属的空间
namespace sql
{namespace A{int sum = 0;//定义函数void func(){printf("func()\n");}}
}using namespace sql::A;int main()
{printf("%d\n",sum);return 0;
}但这种情况如果引入多个命名空间往往容易出错,例如,定义了两个命名空间,两个空间都定义了变量a,如下所示:
namespace A1
{int a = 10;
}namespace A2
{int a = 20;
}using namespace A1;
using namespace A2;int main()
{printf("%d\n",a);//引起编译错误
}这样在输出a时就会出错,因为A1和A2空间都定义了a变量,引入不明确,编译出错。因此只有在使用命名空间数量很少,以及确保这些命名空间中没有同名成员时才使用using namespace语句。
在编写C++程序时,由于C++标准库中的所有标识符都被定义于一个名为std的namespace中,所以std又叫作标准命名空间,要使用其中定义的标识符就要引入std空间。
三.C++的输入输出
当我们在屏幕上输出“hello C++”时,读者或许会吃惊,为什么不是printf()。其实printf()函数也可以,但它是C语言的标准输出函数。在C++中输入输出都是以“流”的形式实现的,C++定义了iostream流类库,它包含两个基础类istream和ostream,用于表示输入流和输出流,并在库中定义了标准输入流对象cin和标准输出流对象cout,分别用于处理输入和输出。
cin与提取运算符“>>”结合使用,用于读入用户输入,以空白(包括空格,回车,TAB)为分隔符。
cout与插入运算符“<<”结合使用,用于打印消息。通常它还会与操作符endl使用,endl的效果是结束当前行,并将与设备关联的缓冲区(buffer)中的数据刷新到设备中,保证程序所产生的的所有输出都被写入输出流,而不是仅停留在内存中。
注意:
使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件
以及按命名空间使用方法使用std。
案例:
#include<iostream>
using std::cout;
using std::endl;int main()
{//<<:流插入运算符std::cout << "hello world!\n" << std::endl;//等价于//std::cout << "hello world!\n" << "\n";cout << "hello world!\n" << "\n";int i = 11;double d = 11.11;printf("%d %lf\n", i, d);//自动识别类型//std::cout << i << " " << d << std::endl;cout << i << " " << d << std::endl;//>>:流提取scanf("%d%lf",&i,&d);std::cin >> i >> d;std::cout << i << " " << d << std::endl;return 0;
}运行结果:

std命名空间的使用惯例:
std是C++标准库的命名空间,如何展开std使用更合理呢?
- 在日常练习中,建议直接using namespace std即可,这样就很方便;
- using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对象/函数,就存在冲突问题。该问题在日常练习中很少出现,但是项目开发中代码较多、规模大,就很容易出现。所以建议在项目开发中使用,像std::cout这样使用时指定命名空间 +using std::cout展开常用的库对象/类型等方式。
四.缺省参数
C++的函数也支持默认参数机制,即在定义定义或声明函数时给形参一个初始值,在调用函数时,如果不传递实参就使用默认参数数值。
4.1.缺省参数概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实
参则采用该形参的缺省值,否则使用指定的实参。
案例:
void Func(int a = 0)
{cout << a << endl;
}int main()
{Func(1);Func(2);Func(3);//当不传实际参数时,则用缺省值Func();return 0;
}运行结果:

4.2.缺省参数分类
全缺省参数
全缺省参数是声明或定义函数时为函数的参数全都指定一个缺省值。
void TestFunc(int a = 10, int b = 20, int c = 30)
{cout << "a= " << a << endl;cout << "b= " << b << endl;cout << "c= " << c << endl << endl;
}int main()
{//有参数传入它会先从左向右依次匹配TestFunc();//a,b,c使用默认形参TestFunc(1);//只传递1给形参a,b,c使用默认形参值TestFunc(1, 2);//传递1给a,2给b,c使用默认形参TestFunc(1, 2, 3);//传递三个参数,不使用默认形参值//TestFunc(,1,);//不可以return 0;
}运行结果:

半缺省参数
半缺省参数是声明或定义函数时为函数的部分参数自右向左连续指定缺省值,且中间不能有间隔。
void TestFunc(int a, int b = 20, int c = 30)
{cout << "a= " << a << endl;cout << "b= " << b << endl;cout << "c= " << c << endl << endl;
}int main()
{//TestFunc();//必须传入一个值TestFunc(1);//只传递1给形参a,b,c使用默认形参值TestFunc(1, 2);//传递1给a,2给b,c使用默认形参TestFunc(1, 2, 3);//传递三个参数,不使用默认形参值return 0;
}运行结果:

4.3.缺省参数注意事项
a.默认参数只可在函数声明中出现一次,如果没有函数声明,只有函数定义,才可以在函数定义中设定。
b.默认参数定义的顺序是自右向左,即如果一个参数设定了默认参数,则其右边不能再有普通参数。
c.默认参数调用时,遵循参数调用顺序,即有参数传入它会先从左向右依次匹配。
d.默认参数值可以是全局变量、全局常量,甚至可以是一个函数,但不可以是局部变量,因为默认参数的值是在编译时确定的,而局部变量位置与默认值在编译时无法确定。
4.4.缺省参数用途
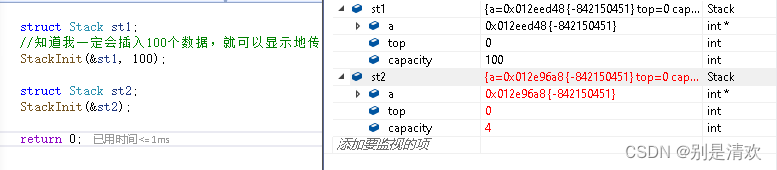
在学习数据结构中的栈时,当我们在对栈进行初始化过程中并不知道要为该栈开辟多少字节的内存空间,起始状态我们都是为该栈开辟4个int类型的空间,当栈满时,再将栈空间扩容至原来的2倍。但是,如果我们使用缺省参数,当明确知道不需要太大空间时就使用默认的空间大小,当明确知道需要很大空间时就使用缺省参数。
需要注意的是,默认参数只可在函数声明中出现一次,如果没有函数声明,只有函数定义,才可以在函数定义中设定。
案例:
#include<iostream>using namespace std;struct Stack
{int* a;int top;int capacity;
};//声明
//缺省参数不能在函数声明和定义中同时出现
//默认参数只可在函数声明中出现一次,如果没有函数声明,只有函数定义,才可以在函数定义中设定
void StackInit(struct Stack* ps, int capacity = 4);int main()
{struct Stack st1;//知道我一定会插入100个数据,就可以显示地传参数100,这样就提前开好空间,插入数据避免扩容StackInit(&st1, 100);struct Stack st2;StackInit(&st2);return 0;
}//定义
void StackInit(struct Stack* ps, int capacity)
{ps->a = (int*)malloc(sizeof(int) * capacity);//...ps->top = 0;ps->capacity = capacity;
}运行结果:
五.函数重载
所谓重载(overload)函数就是在同一个作用域内函数名字相同但形参列表不同的函数。
5.1.重载函数概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这
些同名函数的形参列表(参数个数或类型或类型顺序)不同,常用来处理实现功能类似数据类型
不同的问题。
它们的函数名相同但参数列表却不同,参数列表的不同有三种含义:参数个数不同,或者参数类型不同或者参数个数和类型都不同。
参数类型不同:
//参数类型不同
int Add(int left, int right)
{return left + right;
}double Add(double left, double right)
{return left + right;
}int main()
{cout << Add(1, 2) << endl;cout << Add(1.1, 2.2) << endl;return 0;
}运行结果:
![]()
参数个数不同:
//参数个数不同
void f()
{cout << "f()" << endl;
}void f(int a)
{cout << "f(int a):" << a << endl;
}int main()
{f();f(1);return 0;
}运行结果:
![]()
参数类型顺序不同:
//参数类型顺序不同
void func(int i, char ch)
{cout << "void func(int i,char ch):" << i << " " << ch << endl;
}void func(char ch, int i)
{cout << "void func(char ch,int i):" << ch << " " << i << endl;
}int main()
{func(1, 'a');func('a', 1);return 0;
}运行结果:
![]()
注意:
1.返回值不同,不能构成重载,只有涉及到参数不同,才会构成重载。
案例:
//返回值不同,不构成重载,只有涉及到参数不同,才会构成重载
short Add(short left, short right)
{return left + right;
}int Add(short left, short right)
{return left + right;
}int main()
{Add(1, 3);return 0;
}运行结果:

2.当使用具有默认参数的函数重载形式时须注意防止调用的二义性,例如下面的两个函数:
int add(int x, int y = 1);
void add(int x);当使用函数调用语句“add(10);”时会产生歧义,因为它既可以调用第一个add()函数也可以调用第二个add()函数,编译器无法确认到底要调用哪个重载函数,这就产生了调用的二义性。在使用时要防止这种情况的发生。
5.2.C++支持函数重载的原理--名字修饰(name Mangling)
为什么C++支持函数重载,而C语言不支持函数重载呢?
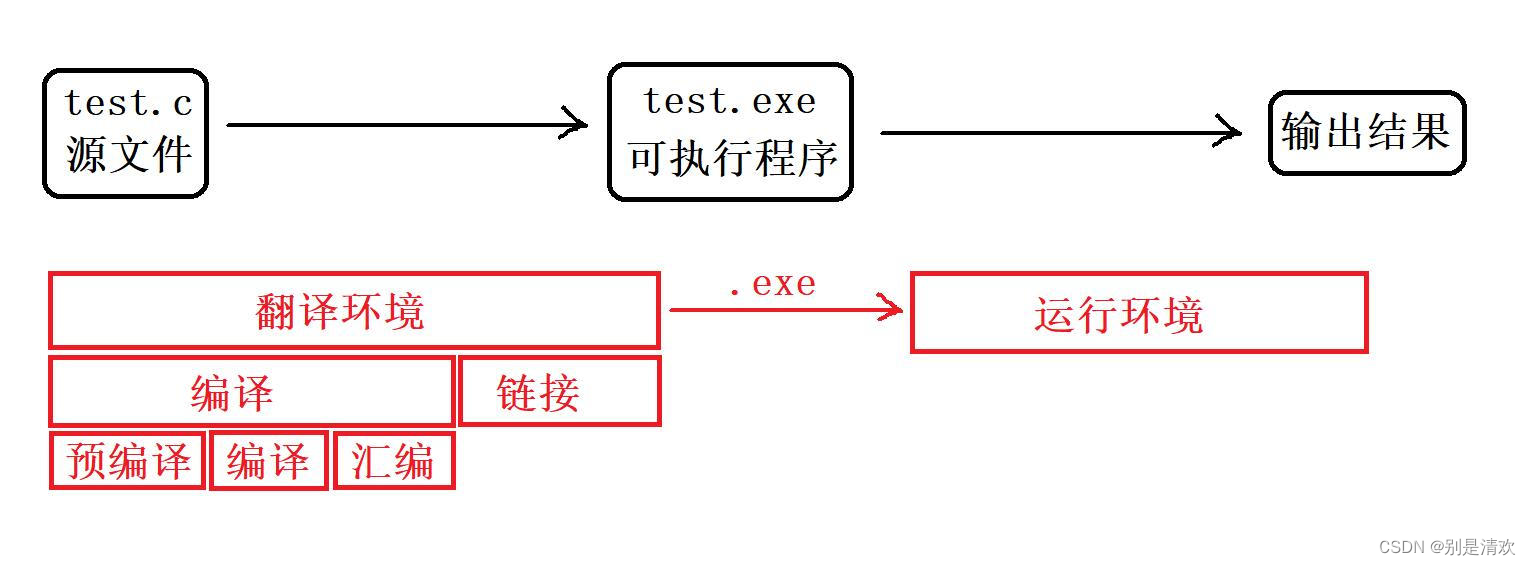
在C/C++中,一个程序要运行起来,需要经历以下几个阶段:预处理、编译、汇编、链接。假设在Linux环境下,要处理的程序为:func.h func.c test.c,则在每个阶段对应的执行操作分别为:

- 预处理:头文件展开,宏替换,条件编译,去掉注释 func.i main.i
- 编译:语法检查,生成汇编代码 func.s main.s
- 汇编:把汇编代码转换成二进制机器码 func.o main.o
- 链接:将.o的目标文件合并到一起,其次还需要找一些只给声明的函数变量的地址,合并段表,符号表的合并和符号表的重定位 a.out
实际项目通常是由多个头文件和多个源文件构成,而通过C语言阶段学习的编译链接,我们可以知道,当前test.cpp中调用了func.cpp中定义的Add函数时,编译后链接前,test.o的目标文件中没有Add的函数地址,因为Add是在func.cpp中定义的,所以Add的地址在func.o中。那么怎么办呢?
所以链接阶段就是专门处理这种问题,链接器看到test.o调用Add,但是没有Add的地址,就会到func.o的符号表中找Add的地址,然后链接到一起。
那么链接时,面对Add函数,链接接器会使用哪个名字去找呢?这里每个编译器都有自己的函数名修饰规则。
由于Windows下vs的修饰规则过于复杂,而Linux下g++的修饰规则简单易懂,下面我们使用g++演示这个修饰后的名字。
通过编译我们可以看出gcc的函数修饰后名字不变。而g++的函数修饰后变成【_Z+函数长度+函数名+类型首字母】。可以得出,在Linux下,采用gcc编译完成后,函数名字的修饰没有发生改变;而采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改后的名字中。
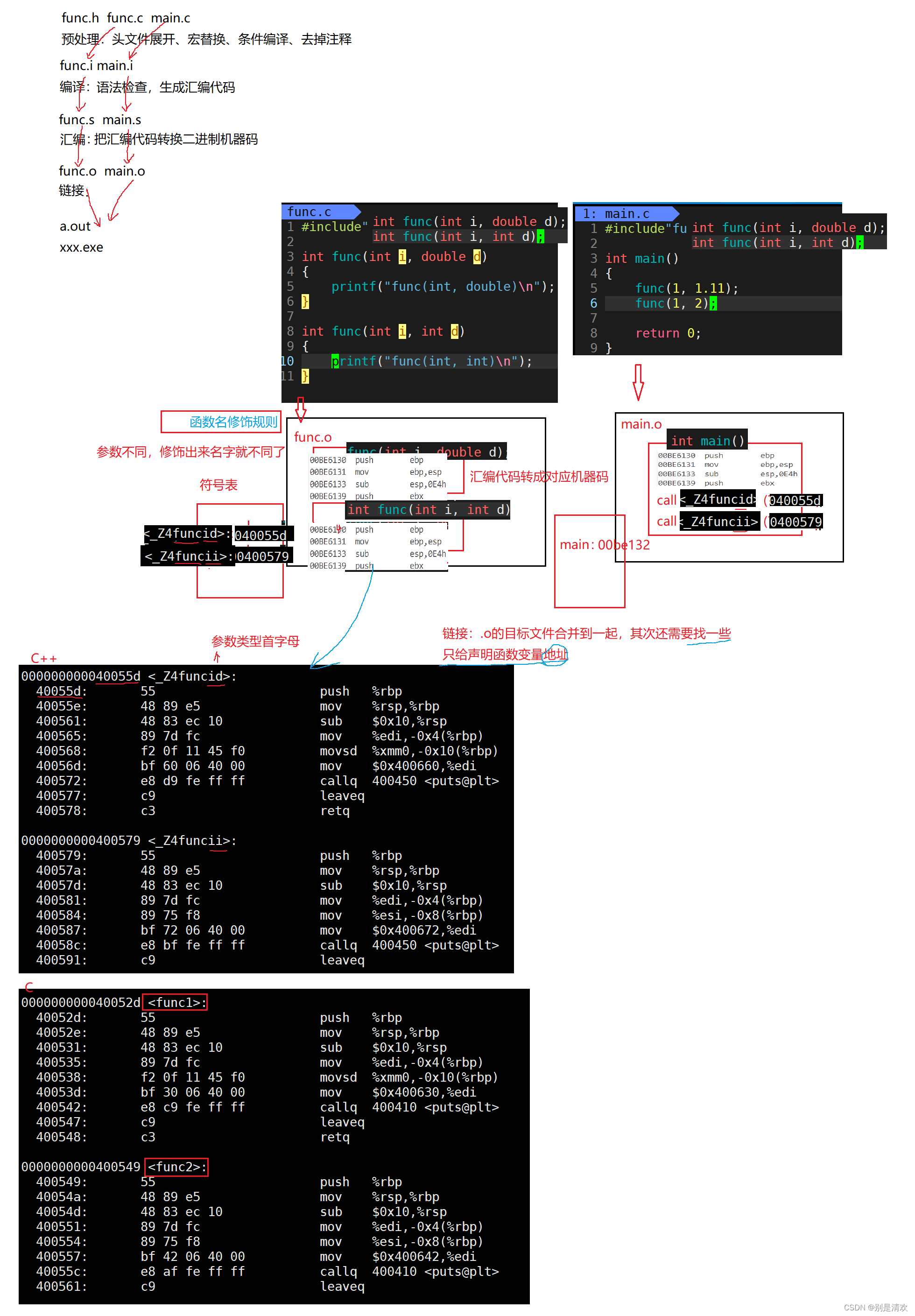
因此,可以得出:C语言是没办法支持重载的,因为同名函数没办法区分;而C++是通过函数修饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载。
5.3.extern "C"
extern "C"的主要作用是为了能够正确实现C++代码调用其他C语言代码。加上extern "C"后,会指示编译器这部分代码按C语言的进行编译,而不是C++的。由于C++支持函数重载,因此编译器编译函数的过程中会将函数的参数类型也加到编译后的代码中,而不仅仅是函数名;而C语言并不支持函数重载,因此编译C语言代码的函数时不会带上函数的参数类型,一般只包括函数名。
六.引用
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空
间,它和它引用的变量共用同一块内存空间。
6.1.引用的概念
引用就是给一个变量起一个别名,用“&”标识符来标识,其格式如下所示:
数据类型 &引用名=变量名;上述格式中,“&”并不是取地址操作符,而是起标识作用,标识所定义的标识符是一个引用。引用声明完成以后相当于目标变量有两个名称,如下面代码所示:
int a = 0;
int& b = a;在上述代码中,b就是变量a的引用,b和a标识的是同一块内存,相当于一个人有两个名字。对a与b进行操作,都会更改内存中的数据。
6.2.引用的特性
a.引用在定义时必须初始化,如“int &b;”语句是错误的。
案例:
int main()
{int a = 10;int& b = a;int& c;
}运行结果:
![]()
b.引用在初始化时只能绑定左值,不能绑定常量值,如“int &b=10;”语句是错误的;
案例:
int main()
{int a = 10;int& b = a;int& c = 100;
}运行结果:
![]()
c.引用一旦初始化,其值就不能再更改,即不能再做别的变量的引用,代码如下所示:
int a = 10;
int b = 20;
int& p = a;
p = b;//为p赋值p为变量a的引用,当p=b执行时,并不是把p指向了变量b,而是使用变量b给变量a赋值;
d.数组不能定义引用,因为数组是一组数据,无法定义其别名;
e.一个变量可以有多个引用。
案例:
int main()
{int a = 0;//引用int& b = a;int& c = a;int& d = c;//取地址cout << &a << endl;cout << &b << endl;cout << &c << endl;cout << &d << endl;return 0;
}运行结果:

6.3.引用的使用场景
6.3.1.引用作为函数参数
C++增加引用的类型,主要的应用就是把它作为函数的参数,以扩充函数传递数据的功能,引用作函数参数时区别于值传递与地址传递。我们以交换两个数据的值为例来分析引用作为函数参数的用法。
案例:
//地址传递
void Swap2(int* p1, int* p2)
{int temp = *p1;*p1 = *p2;*p2 = temp;
}//引用传递
void Swap3(int& rx, int& ry)
{int temp = rx;rx = ry;ry = temp;
}int main()
{int x = 3, y = 5;Swap1(x, y);cout << x << " " << y << endl;int m = 3, n = 5;Swap2(&m, &n);cout << m << " " << n << endl;int i = 3, j = 5;Swap3(i, j);cout << i << " " << j << endl;return 0;
}
运行结果:

分析:
这是一个典型的区分值传递与址传递的函数,如果是值传递,由于副本机制无法实现两个数据的交换;址传递则可以完成两个数据的交换,但也需要为形参(指针)分配存储单元,在调用时要反复使用“*指针名”,且实参传递时要取地址,这样很容易出现错误且程序的可读性也会下降。而引用传递就完全克服了它们的缺点,使用引用就是直接操作变量,简单高效可读性好。
6.3.2.引用作为函数返回值
案例1:
int Add(int a, int b)
{int c = a + b;return c;
}int main()
{int ret = Add(1, 2);cout << ret << endl;return 0;
}运行结果:
![]()
分析:
返回普通类型对象其实是返回这个对象的拷贝,c++其实会创建一个临时变量,这个临时变量被隐藏了,它会把c的值拷贝给这个临时变量,当执行语句“int ret = Add(1, 2);”的时候就会把临时变量的值再拷贝给ret,假设这个临时变量是t,相当于做了这两个赋值的步骤:t = c; ret = t。
函数中的普通变量是存放在当前所开辟函数的栈帧中的,即存放在内存中的栈区;而存放在栈区中的临时变量当函数调用结束后整个函数栈帧就会被销毁,那么存放在这个栈帧中的临时变量也随之消亡,不复存在。
案例2:
int& Add(int a, int b)
{int c = a + b;return c;
}int main()
{int& ret = Add(1, 2);cout << ret << endl;return 0;
}运行结果:
![]()
分析:
返回引用实际返回的是一个指向返回值的隐式指针,在内存中不会产生副本,是直接将c拷贝给ret,这样就避免产生临时变量,相比返回普通类型的执行效率更高,而且这个返回引用的函数也可以作为赋值运算符的左操作数。
案例3:
int& Add(int a, int b)
{int c = a + b;return c;
}int main()
{int& ret = Add(1, 2);Add(3, 4);cout << "Add(1, 2) is :" << ret << endl;return 0;
}运行结果:
![]()
分析:
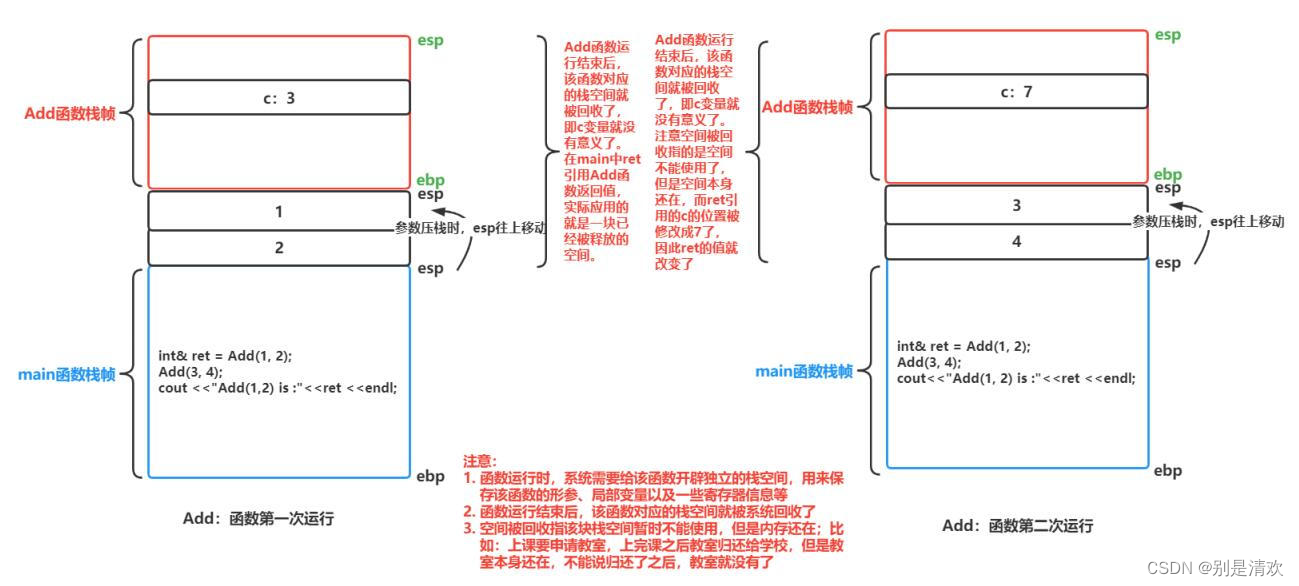
在Add函数调用结束后,为add函数创建的栈帧会被销毁,这块栈空间会还给操作系统。此时再使用Add函数的返回值,就会造成对内存空间的非法访问,而大部分情况下,编译器不会对非法访问内存报错。下一次的函数调用可能还是在这块空间上建立栈帧,但是上一次的栈帧是否清理取决于编译器,可能清理了,也可能没清理:
- 如果编译器没有清理这个栈帧的话,那么这个c就还是3
- 如果编译器清理了这个栈帧的话,这个c就有可能是个随机值。
小结:
引用返回的语法含义就是返回返回对象的别名,使用引用返回本质是不对的,因为结果是没有保障的。
出了函数作用域,返回对象就销毁了,那么一定不能用引用返回(使用static时,可以使用引用返回),一定要用传值返回。
不要将局部变量作为返回值:因为局部变量存放在栈区,函数调用结束之后就释放;第一次结果正确,是因为编译器做了保留,第二次结果错误,是因为局部变量被释放了。
函数的返回值可以左值存在:静态变量存放在全局区,是在整个程序运行结束才释放。
引用作为返回的情况:
- 使用static修饰的静态变量作为返回对象;
- 返回对象为调用函数中开辟的一块内存空间中的内容(调用函数中开辟的空间是用malloc开辟的,存放在堆上,所以可以引用返回)。
案例:
int& Count()
{static int n=0;//可以使用引用//int n = 0;//不可以使用引用n++;//...return n;
}char& func2(char* str, int i)
{return str[i];
}int main()
{//int ret = Count();//ret的结果是未定义的,如果栈帧结束时,系统会清理栈帧并置成随机值,那么这里ret的结果就是随机值int& ret = Count();Count() = 10;//如果函数的返回值作为左值,必须使用引用cout << ret << endl;cout << ret << endl;//返回一个随机值char ch[] = "abcdef";for (int i = 0; i < strlen(ch); ++i){func2(ch, i) = '0' + i;}cout << ch << endl; //012345return 0;
}运行结果:

总结:
引用作为函数参数:
- 输出型参数;
- 大对象传参,提高效率。
引用作为函数返回值:
- 输出型返回对象,调用者可以修改返回对象;
- 减少拷贝,提高效率。
6.4.传值和传引用效率比较
值和引用的作为参数的性能比较
案例:
#include <time.h>
struct A
{ int a[10000];
};void TestFunc1(A a)
{}
void TestFunc2(A& a)
{}void TestRefAndValue()
{A a;//以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}int main()
{TestRefAndValue();return 0;
}运行结果:
![]()
值和引用的作为返回值类型的性能比较
案例:
#include <time.h>
struct A
{ int a[10000];
};A a;//值返回
A TestFunc1()
{ return a;
}//引用返回
A& TestFunc2()
{return a;
}void TestReturnByRefOrValue()
{//以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();//以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}int main()
{TestReturnByRefOrValue();return 0;
}运行结果:
![]()
小结:
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
通过上述代码的比较,发现值和引用在作为传参以及返回值类型上效率相差很大。
6.5.常引用
我们知道引用不能绑定常量值,如果想要用常量值去初始化引用,则引用必须用const来修饰,这样的引用我们称之为const引用。
const引用可以用cons对象和常量值来初始化,例如:
const int& a = 10;//常量值初始化const引用
const int a = 10;
const int& b = a;//const对象初始化const引用一般来说,对于const对象而言,只能采用const引用,如果没有对引用进行限定,那么就可以通过引用对数据进行修改,这是不允许的。但const引用不一定都得用const对象初始化,还可以用非const对象来初始化,例如:
int a = 10;
const int& b = a;用非const对象初始化const引用,只是不允许通过该引用修改变量值。除此之外,const引用甚至可以用不同类型的变量来初始化const引用,例如:
double d = 1.2;
const int& b = d;
这是连指针都没有的优越性,此处b引用了一个double类型的数值,编译器在编译这两行代码时,先把d进行了一下转换,转换为int类型数据,然后又赋值给了引用b,其转换过程如下面代码所示:
double d = 1.2;
const int temp = (int)d;
const int& b = temp;在这种情况下,b绑定的是一个临时变量。而当非const引用时,如果绑定到临时变量,那么可以通过引用修改临时变量的值,修改一个临时变量的值是没有任何一样的,因此编译器把这种行为定位非法的,那么用不同类型的变量初始化一个普通引用自然也是非法的。
案例:
int main()
{int a = 10;int& b = a;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;//权限不能放大const int c = 20;//int& d = c;//权限放大,从const变为非const,不合法const int& d = c;//权限能够缩小int e = 30;const int& f = e;//权限缩小,从非const变为const,合法int ii = 1;//强制类型转换,并不会改变原变量类型,中间会产生一个临时变量double dd = ii;//ii会生成一个临时变量,然后dd会拷贝这个临时变量,而临时变量具有常性//double& rdd = ii;//会造成权限的放大,ii生成的临时变量是const类型,而rdd是非const类型,不能从const变为非const,是不合法的const double& rdd = ii;const int& x = 10;//可以为常量return 0;
}6.6.引用和指针的区别
语法概念:
引用就是一个别名,没有独立空间,和其引用实体共用同一块空间;而指针开辟了4字节或者8字节的空间,存储变量的地址。
底层实现:
在底层实现上,引用实际上是有空间的,因为引用在底层是按照指针方式来实现的。
使用场景:
指针更强大,更危险,更复杂;而引用相对局限一些,更安全,更简单。
二者不同:
- 引用概念上定义一个变量的别名,指针存储一个变量地址;
- 引用在定义时必须初始化,指针没有要求;
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体;
- 没有NULL引用,但有NULL指针;
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节);
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小;
- 有多级指针,但是没有多级引用;
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理;
- 引用比指针使用起来相对更安全。
案例:
int main()
{//语法的角度,ra没有开空间int a = 10;int& ra = a;ra = 20;cout << a << endl;//语法的角度,pa没有开辟4或8字节的空间//底层实现角度,引用底层是用指针实现的int b = 20;int* pa = &b;*pa = 20;cout << b << endl;return 0;
}运行结果:
![]()
七.内联函数
我们都直到函数的调用有利于代码重用,提高效率,但有时频繁的函数调用也会增加时间与空间的开销反而造成效率低下。因为调用函数实际上是将程序执行顺序从函数调用处跳转到函数所存放在内存中的某个地址,将调用现场保留,跳转到那个地址将函数执行,执行完毕后再回到调用现场,所以频繁的函数调用会带来很大开销。为了解决这个问题,C++提供了内联(inline)函数,在编译时将函数体嵌入到调用处。
7.1.内联函数定义
以inline修饰的函数叫作内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调
用建立栈帧的开销,内联函数提升程序运行的效率。其格式如下:
inline 返回值类型 函数名(参数列表)
{函数体;
}
案例:
#include<iostream>
using namespace std;//Add就会在调用的地方展开
inline int Add(int x, int y)
{return x + y;
}int main()
{int ret = Add(10, 20);cout << ret << endl;return 0;
}
如果在上述函数前增加inline关键字会将其改成内联函数,在编译期间编译器会用函数体替换函数的调用。
查看方式:
在release模式下,查看编译器生成的汇编代码中是否存在call Add;
- 使用内联函数时,汇编语言中不再有call Add指令,函数指令直接在主函数中展开。

- 不使用内联函数时,要先通过call指令调用Add函数,然后建立函数栈帧并执行函数指令。
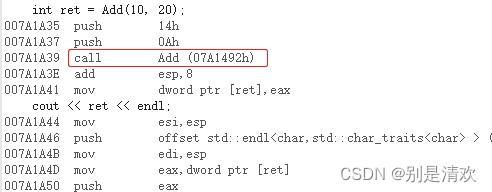
在debug模式下,需要对编译器进行设置,否则不会展开(因为debug模式下,编译器默认不会对代码进行优化,以下给出vs2019的设置方式)。在Debug版本下内联函数展开的方法:
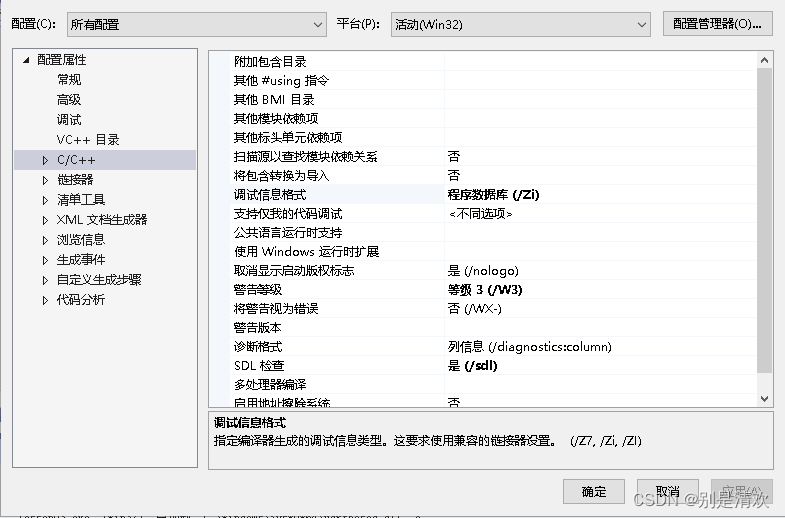
- 打开属性设置,选择C/C++ -> 常规,将调试信息格式改为程序数据库;
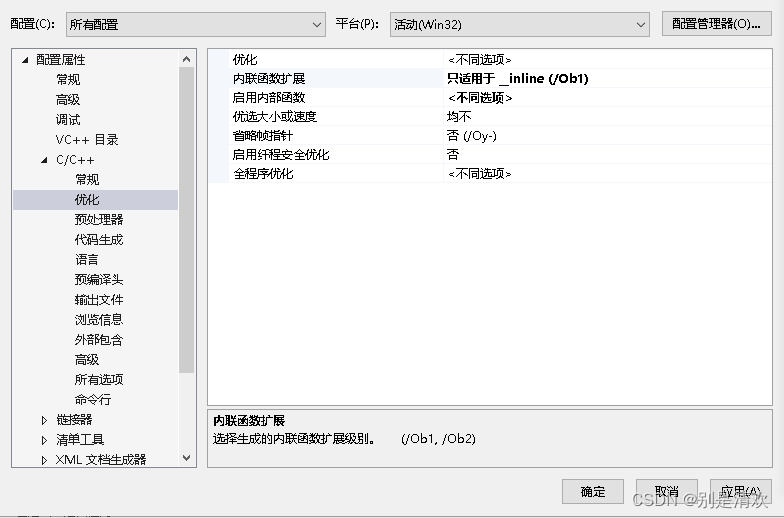
- 选择C/C++ -> 优化,将内联函数扩展改为:只适用于_inline (Ob1)。
7.2.内联函数特性
a.inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用。缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率;

b.inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性;

c.inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。

7.3.内联函数与宏函数的区别
宏函数:使用宏函数,在预处理阶段进行替换 。
- 宏的缺点:可读性差,较为复杂;没有类型安全检查;不方便调试;
- 宏的优点:复用性变强;宏函数提高效率,减少栈帧建立。
C++中基本不再建议使用宏,尽量使用const,enum,inline去替代宏。inline几乎解决了宏函数的缺点,同时兼具了它的缺点 。
八.auto关键字
C++11之前,auto默认修饰函数的局部变量,限定变量的作用域及存储期。C++11中,auto称为类型说明符,使用它可以让编译器根据初始化代码推断出所声明变量的真实类型。
8.1.auto简介
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的是一直没有人去使用它。C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
案例:
int TestAuto()
{return 10;
}int main()
{int a = 10;auto b = a;//自动推导类型auto c = 'a';auto d = TestAuto();cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;return 0;
}运行结果:

注意:
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
8.2.auto的使用细则
auto与指针和引用结合起来使用 用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&。
案例:
int main()
{//用auto声明指针类型时,用auto和auto*没有任何区别int x = 10;auto a = &x;//a的类型是:int*auto* b = &x;//显示地加*,表示用于接收一个指针类型的数据cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;//用auto声明引用类型时则必须加&auto& c = x;//显示地加&,表示用于接收一个引用类型的数据cout << typeid(c).name() << endl;
}运行结果:

在同一行定义多个变量 当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
案例:
int main()
{//在同一行定义多个变量auto a = 1, b = 2;auto c = 3, d = 4.0;//该行代码会编译失败,因为c和d的初始化表达式类型不同return 0;
}运行结果:

8.3.auto不能推导的场景
auto不能作为函数参数 auto不能作为形参类型,因为编译器无法对其的实际类型进行推导。
案例:
void func(auto x)
{cout << x << endl;
}int main()
{func(10);return 0;
}运行结果:
![]()
auto不能直接用来声明数组
案例:
int main()
{int a[] = { 1,2,3 };auto b[] = { 1,2,3 };return 0;
}
运行结果:

注意:
为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法;
auto在实际中最常见的优势用法就是跟以后会讲到的C++11提供的新式for循环,还有lambda表达式等进行配合使用。
九.基于范围的for循环
9.1.范围for的语法
在C++98中如果要遍历一个数组,可以按照以下方式进行:
int main()
{int a[] = { 1,2,3,4,5,6 };for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++){a[i]++;}for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++){cout << a[i] << " ";}cout << endl;return 0;
}对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
int main()
{int a[] = { 1,2,3,4,5,6 };//范围for//自动地依次取a的数据,赋值给e//自动迭代,自动判断结束for (auto& e : a)//加&,可以对数组进行更改;加*,不可以对数组进行修改,因为无法从“int”转换为“int *”{e--;}for (auto e : a){cout << e << " ";}cout << endl;return 0;
}注意:
与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环。
9.2.范围for的使用条件
for循环迭代的范围必须是确定的 对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。
void TestFor(int array[])
{for (auto& e : array)//for的范围不确定cout << e << endl;
}int main()
{int a[] = { 1,2,3,4,5,6 };TestFor(a);}迭代的对象要实现++和==的操作
十.指针空值nullptr
在良好的C/C++编程习惯中,声明一个变量时最好给该变量一个合适的初始值,否则可能会出现
不可预料的错误,比如未初始化的指针。如果一个指针没有合法的指向,我们基本都是按照如下
方式对其进行初始化:
void TestPtr()
{int* p1 = NULL;int* p2 = 0;// ……
}NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif可以看到,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。不论采取何
种定义,在使用空值的指针时,都不可避免的会遇到一些麻烦,比如:
void f(int)
{cout << "f(int)" << endl;
}void f(int*)
{cout << "f(int*)" << endl;
}int main()
{//NULL实际是一个宏,在传统的C头文件(stddef.h)中,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。int* p = NULL;f(0);//f(int)f(NULL);//f(int)f(p);//f(int*)//C++11 nullptr//在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。//在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同f(nullptr);int* ptr = nullptr;return 0;
}程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖。
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void
*)0。
注意:
1. 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的; 2. 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同;
3. 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
相关文章:
C++初阶:C++入门
目录 一.iostream文件 二.命名空间 2.1.命名空间的定义 2.2.命名空间的使用 三.C的输入输出 四.缺省参数 4.1.缺省参数概念 4.2.缺省参数分类 4.3.缺省参数注意事项 4.4.缺省参数用途 五.函数重载 5.1.重载函数概念 5.2.C支持函数重载的原理--名字修饰(name Mangl…...

golang操作数据库--gorm框架、redis
目录 1.数据库相关操作(1)非orm框架①引入②初始化③增删改查 (2) io版orm框架 (推荐用这个)①引入②初始化③增删改查④gorm gen的使用 (3) jinzhu版orm框架①引入②初始化③增删改查 2.redis(1)引入(2)初始化①普通初始化②v8初始化③get/set示例 1.数据库相关操作 (1)非orm…...

10 种常用的字符串方法
10 种常用的字符串方法 1.concat() 字符串拼接 const str1 12345678;const str2 abcdefgh;const str3 -【】;‘;console.log(str1.concat(str2,str3))//12345678abcdefgh-【】;‘ 2.includes() 判断字符串中是否包含指定值,返回布尔值…...

CSDN每日一练 |『生命进化书』『订班服』『c++难题-大数加法』2023-09-06
CSDN每日一练 |『生命进化书』『订班服』『c++难题-大数加法』2023-09-06 一、题目名称:生命进化书二、题目名称:订班服三、题目名称:c++难题-大数加法一、题目名称:生命进化书 时间限制:1000ms内存限制:256M 题目描述: 小A有一本生命进化书,以一个树形结构记载了所有生…...

echarts饼图label自定义样式
生成的options {"tooltip": {"trigger": "item","axisPointer": {"type": "shadow"},"backgroundColor": "rgba(9, 24, 48, 0.5)","borderColor": "rgba(255,255,255,0.4)&q…...
Unity汉化一个插件 制作插件汉化工具
我是编程一个菜鸟,英语又不好,有的插件非常牛!我想学一学,页面全是英文,完全不知所措,我该怎么办啊...尝试在Unity中汉化一个插件 效果: 思路: 如何在Unity中把一个自己喜欢的插件…...
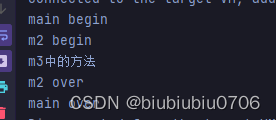
从过滤器初识责任链设计模式
下面用的过滤器都是注解方式 可以使用非注解方式,就是去web.xml配置映射关系 上面程序的执行输出是 再加一个过滤器 下面来看一段程序 输出结果 和过滤器是否非常相识 但是上面这段程序存在的问题:在编译阶段已经完全确定了调用关系,如果你想改变他们的调用顺序或者继续添加一…...
Redis7安装配置
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: Java从入门到精通 ✨特色专栏…...

切分支解决切不走因为未合并的路径如何解决
改代码的时候改做分支了,本来是在另一个分支上面改代码,结果改到另一个放置上面,然后想着使用git stash进行保存,然后切到另外一个分支再pop,结果不行。 报这个错误,导致切不过去,因为我这边pop…...

自动化运维:Ansible之playbook基于ROLES部署LNMP平台
目录 一、理论 1.playbook剧本 2.ROLES角色 3.关系 4.Roles模块搭建LNMP架构 二、实验 1.Roles模块搭建LNMP架构 三、问题 1.剧本启动php报错语法问题 2.剧本启动mysql报错语法问题 3.剧本启动nginx开启失败 4.剧本安装php失败 5.使用yum时报错 6.rpm -Uvh https…...

SpringBoot整合MQ
1.创建工程并引入依赖 <!-- 添加rocketmq的启动器--><dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version>2.1.1</version></dependency>2.编写…...
)
算法训练day37|贪心算法 part06(LeetCode738.单调递增的数字)
文章目录 738.单调递增的数字思路分析代码实现 738.单调递增的数字 题目链接🔥🔥 给定一个非负整数 N,找出小于或等于 N 的最大的整数,同时这个整数需要满足其各个位数上的数字是单调递增。 (当且仅当每个相邻位数上的…...
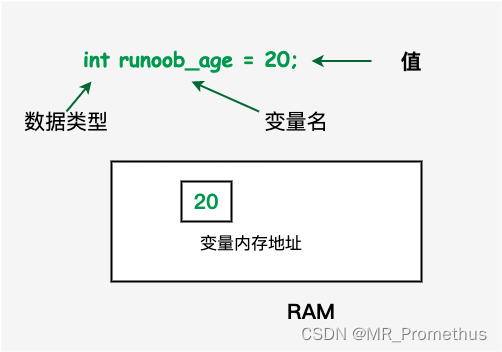
【C++基础】4. 变量
文章目录 【 1. 变量的定义 】【 2. 变量的声明 】示例 【 3. 左值和右值 】 变量:相当于是程序可操作的数据存储区的名称。在 C 中,有多种变量类型可用于存储不同种类的数据。C 中每个变量都有指定的类型,类型决定了变量存储的大小和布局&am…...
jmeter setUp Thread Group
SetUp Thread Group 是一种特殊类型的线程组,它用于在主测试计划执行之前执行一些初始化任务。 SetUp Thread Group 通常用于以下几种情况: 用户登录:在模拟用户执行实际测试之前,模拟用户登录到系统以获取访问权限。 创建会话&a…...

图神经网络教程之GCN(pyG)
图神经网络-pyG版本的GCN Data(数据) data.x、data.edge_index、data.edge_attr、data.y、data.pos 举个例子 import torch from torch_geometric.data import Data edge_index torch.tensor([[0, 1, 1, 2],[1, 0, 2, 1]], dtypetorch.long) #代表…...

python中的逻辑运算
逻辑运算 逻辑运算符是python用来进行逻辑判断的运算符,虽然运算符只有and、or、not三种,但是理解这三个运算符的原理才是最重要的 python中对false的认定 逻辑运算符是python用来进行逻辑判断的运算符,虽然运算符只有and、or、not三种&…...
TortoiseGit设置作者信息和用户名、密码存储
前言 Git 客户端每次与服务器交互,都需要输入密码,但是我们可以配置保存密码,只需要输入一次,就不再需要输入密码。 操作说明 在任意文件夹下,空白处,鼠标右键点击 在弹出菜单中按照下图点击 依次点击下…...

Fragment.OnPause的事情
我们知道Fragment的生命周期依附于相应Activity的生命周期,如果activity A调用了onPause,则A里面的fragment也会相应收到onPause回调,这里以support27.1.1版本的源码来说明Fragment生命周期onPause的事情。 当activity执行onPause时ÿ…...
【C++基础】5. 变量作用域
文章目录 【 1. 局部变量 】【 2. 全局变量 】【 3. 局部变量和全局变量的初始化 】 作用域是程序的一个区域,一般来说有三个地方可以定义变量: 在函数或一个代码块内部声明的变量,称为局部变量。 在函数参数的定义中声明的变量,称…...

Python列表排序
介绍一个关于列表排序的sort方法,看下面的案例: """ 列表的sort方法来对列表进行自定义排序 """# 准备列表 my_list [["a", 33], ["b", 55], ["c", 11]]# 排序,基于带名函数 …...

终极免费音频智能分割工具:快速解放你的音频处理工作流
终极免费音频智能分割工具:快速解放你的音频处理工作流 【免费下载链接】audio-slicer A simple GUI application that slices audio with silence detection 项目地址: https://gitcode.com/gh_mirrors/aud/audio-slicer 还在为处理长音频文件而烦恼吗&…...

基于Arduino与GPS的物联网数据采集器:从硬件搭建到地图可视化
1. 项目概述:一个硬件极客的万圣节“寻宝图” 又到万圣节了,除了琢磨穿什么奇装异服,你是不是也在头疼怎么规划“不给糖就捣蛋”的路线?每年都像开盲盒,有的门口堆满南瓜灯的人家只给了一根棒棒糖,而某个其…...

DDrawCompat:让经典DirectX游戏在现代Windows系统上重获新生的兼容神器
DDrawCompat:让经典DirectX游戏在现代Windows系统上重获新生的兼容神器 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_m…...

构建个人数字生活数据中心:从数据采集到可视化的全栈实践
1. 项目概述:一个全自动化的个人数字生活记录器 最近在GitHub上看到一个挺有意思的项目,叫 nex-life-logger 。光看名字,你可能会觉得这又是一个花里胡哨的“量化自我”工具,无非是记录一下步数、睡眠时间。但当我深入研究了它…...

[安全攻防实验] 环境变量:Set-UID程序中的隐形攻击向量
1. 环境变量与Set-UID程序的安全隐患 在Linux系统中,环境变量就像是一个随身携带的"工具箱",里面装着各种程序运行时需要的信息。但你可能不知道,这个看似普通的工具箱,在遇到Set-UID程序时,可能会变成黑客…...
)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码) 高速数据采集系统中,时序同步问题往往是工程师的噩梦。当AD7961工作在回声时钟模式时,数据信号与时钟信号的微妙相位关系可能导致采样结果出…...

终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点
终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上畅玩Switch游戏却总是遇到各种问题?yuzu模拟器作为全球最受欢迎的开源任…...

Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏
Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏 【免费下载链接】godot-card-game-framework A framework which comes with prepared scenes and classes to kickstart your card game, as well as a powerful scripting engine to use to provide full r…...

英雄联盟智能助手Seraphine:告别手动查询,实现高效游戏决策自动化
英雄联盟智能助手Seraphine:告别手动查询,实现高效游戏决策自动化 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟排位赛中,你是否曾因错过接受对局而懊恼不已&a…...

Iris API错误处理机制与嵌入式系统优化实践
1. Iris API错误处理机制解析在嵌入式系统开发中,API的健壮性直接影响整个系统的稳定性。Iris框架作为ARM架构下的核心组件,其错误处理机制基于JSON-RPC 2.0规范进行了深度定制,特别适合资源受限的嵌入式环境。与通用Web API不同,…...