Elasticsearch:wildcard - 通配符搜索
Elasticsearch 是一个分布式、免费和开放的搜索和分析引擎,适用于所有类型的数据,例如文本、数字、地理空间、结构化和非结构化数据。 它基于 Apache Lucene 构建,Apache Lucene 是一个全文搜索引擎,可用于各种编程语言。 由于其速度、可扩展性以及对不同类型内容进行索引的能力,Elasticsearch 已在多种用例中得到应用,例如:
- 企业搜索
- 日志记录和日志分析
- 应用搜索
- 商业分析
- 地理空间数据分析和可视化
它是如何工作的?
Elasticsearch 不是将信息存储为列式数据行,而是存储已序列化为 JSON 文档的复杂数据结构。 每个文档由一组键(文档中的字段或属性的名称)及其相应的值(字符串、数字、布尔值、日期、值数组、地理位置或其他类型的数据)组成。 它使用一种称为倒排索引的数据结构,列出任何文档中出现的每个唯一单词,并标识每个单词出现的所有文档。
字段类型 - 分析或未分析
Elasticsearch 中的字符串文字要么被分析,要么未被分析。 那么分析到底是什么意思呢? 已分析字段是指在索引之前经过分析过程的字段。 然后,该分析的结果存储在倒排索引中。 分析过程基本上涉及对文本块进行分词和规范化。 这些字段被分词为术语,并且术语被转换为小写字母。 这是标准分析器的行为,也是默认行为。 但是,如果需要,我们可以指定我们自己的分析器,例如,如果你还想索引特殊字符,而标准分析器则不会这样做。如果你想对 analyzer 有更多的了解,请阅读文章 “Elasticsearch: analyzer”。

我们尝试使用如下的命令来进行分词:
GET _analyze
{"analyzer": "standard","text" : "Beijing is a beautiful city"
}Elasticsearch 的标准分析器会将此文本转换为以下内容:
{"tokens": [{"token": "beijing","start_offset": 0,"end_offset": 7,"type": "<ALPHANUM>","position": 0},{"token": "is","start_offset": 8,"end_offset": 10,"type": "<ALPHANUM>","position": 1},{"token": "a","start_offset": 11,"end_offset": 12,"type": "<ALPHANUM>","position": 2},{"token": "beautiful","start_offset": 13,"end_offset": 22,"type": "<ALPHANUM>","position": 3},{"token": "city","start_offset": 23,"end_offset": 27,"type": "<ALPHANUM>","position": 4}]
}通配符(wildcard)搜索快速介绍
通配符是特殊字符,充当文本值中未知字符的占位符,并且可以方便地查找具有相似但不相同数据的多个项目。 通配符搜索基于查询中提到的字符与包含这些字符模式的文档中的单词之间的字符模式匹配。
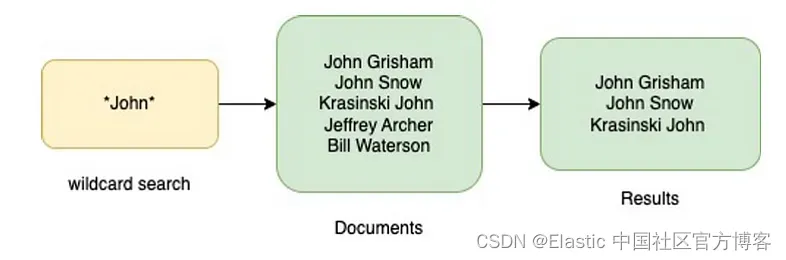
现在我们已经基本了解了 Elasticsearch 的工作原理、分析字段和通配符搜索是什么,让我们更深入地了解本文的主题 — 字符串字段并对其运行通配符搜索。
字符串字段和通配符搜索
Elasticsearch 中的每个字段都有一个字段数据类型。 此类型指示字段包含的数据类型(例如字符串或布尔值)及其预期用途。 Elasticsearch 中可用于字符串的两种字段类型是 — text(默认)和 keyword。 它们之间的主要区别在于,文本字段在索引时进行分析,而关键字字段则不然。 这意味着,文本字段在索引之前会被标准化并分解为单独的分词,而关键字字段则按原样存储。 此外,由于文本字段已标准化,因此它们支持不区分大小写的搜索。 为了对关键字字段实现相同的效果,我们必须在创建索引时定义一个 normalizer,然后在定义字段映射时指定相同的 normalizer。有关 nomalizer 的详细介绍,请阅读文章 “Elasticsearch:词分析中的 Normalizer 的使用”。
PUT wildcard
{"settings": {"analysis": {"normalizer": {"lowercase_normalizer": {"type": "custom","char_filter": [],"filter": ["lowercase","asciifolding"]}}}},"mappings": {"properties": {"text-field": {"type": "text"},"keyword-field": {"type": "keyword","normalizer": "lowercase_normalizer"}}}
}现在进行通配符查询,假设我们有以下文档,并且我们想要对其运行一些通配符搜索:
PUT wildcard/_doc/1
{"text-field": "Mockingbirds don’t do one thing but make music for us to enjoy.","keyword-field": "Mockingbirds don’t do one thing but make music for us to enjoy."
}如下所示的查询可以很好地处理文本字段:
GET wildcard/_search?filter_path=**.hits
{"_source": false, "fields": ["text-field"], "query": {"wildcard": {"text-field": {"value": "*birds*"}}}
}上面的搜索返回结果:
{"hits": {"hits": [{"_index": "wildcard","_id": "1","_score": 1,"fields": {"text-field": ["Mockingbirds don’t do one thing but make music for us to enjoy."]}}]}
}然而,下面的搜索则不会:
GET wildcard/_search?filter_path=**.hits
{"_source": false, "fields": ["text-field"], "query": {"wildcard": {"text-field": {"value": "*birds*music*"}}}
}它返回的结果是:
{"hits": {"hits": []}
}原因是,该字段的单词已被分析并存储为分词。 因此,elasticsearch 无法找到与给定表达式(*birds*music*)对应的分词。
但是,这适用于关键字字段,因为它们按原样存储。我们来尝试如下的搜索:
GET wildcard/_search?filter_path=**.hits
{"_source": false,"fields": ["keyword-field"],"query": {"wildcard": {"keyword-field": {"value": "*birds*music*"}}}
}上面的命令返回的结果是:
{"hits": {"hits": [{"_index": "wildcard","_id": "1","_score": 1,"fields": {"keyword-field": ["mockingbirds don't do one thing but make music for us to enjoy."]}}]}
}现在,让我们讨论从 ElasticSearch v7.9 引入的另一个字符串字段——通配符。 这是一种专门的字段类型,主要用于非结构化机器生成的内容。更多阅读,请参阅文章 “Elasticsearch:使用新的 wildcard 字段更快地在字符串中查找字符串 - 7.9 新功能”。
以下是对这 3 种字段类型运行几个通配符查询的性能统计数据:
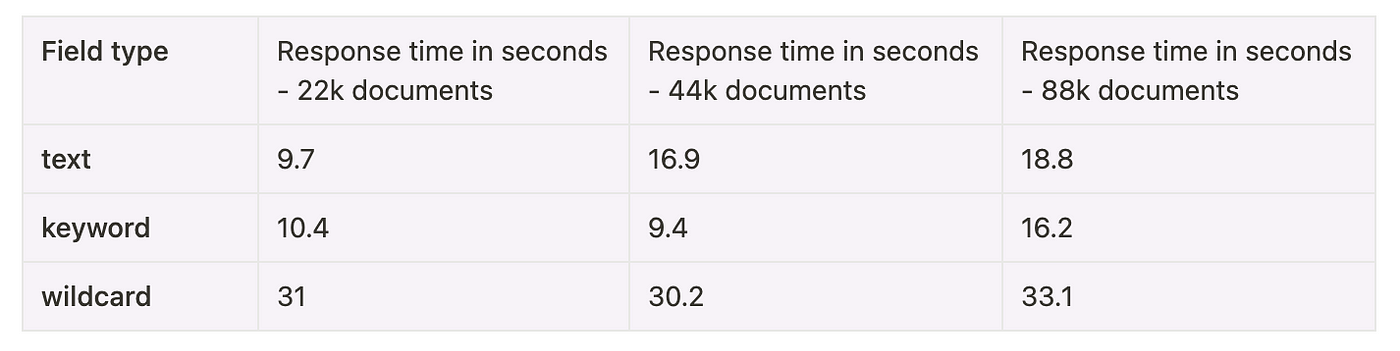
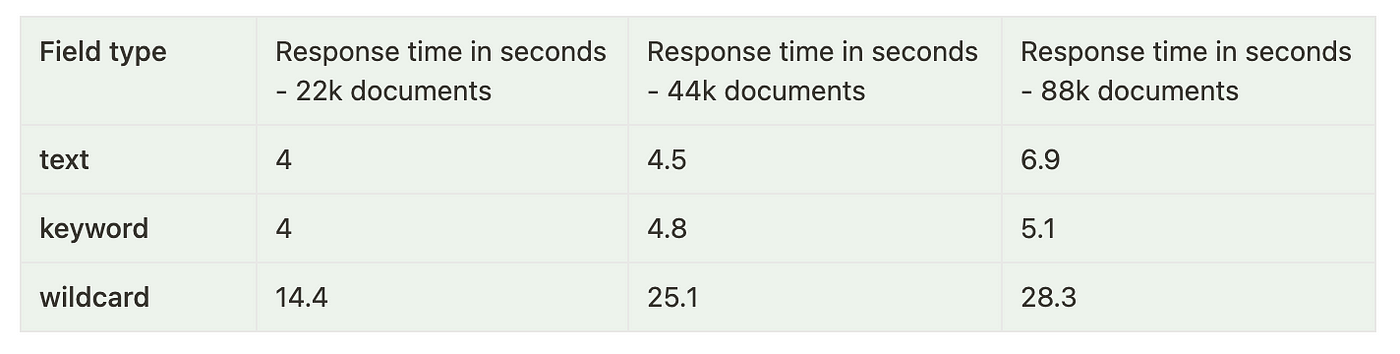
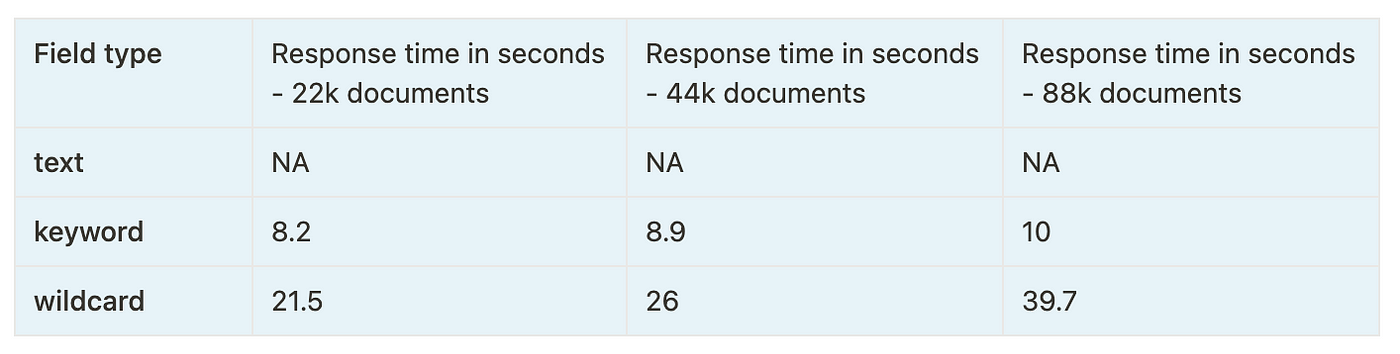
我们可以清楚地看到,关键字字段的性能在所有搜索查询和索引大小中是最一致的。 文本字段也做得不错,但它们不能用于搜索像 *Elastic*stash* 这样的值,这使得关键字类型成为明显的赢家。
那么为什么要引入通配符字段呢? 那么,引入通配符字段是为了解决文本和关键字字段存在的以下限制:
- 文本字段 - 将任何通配符表达式的匹配限制为单个分词,而不是字段中保存的原始整个值。
- 关键字字段 - 当搜索子字符串和有许多唯一值时,关键字字段的速度很慢。 关键字字段还存在数据大小限制的缺点。 默认字符串映射会忽略长度超过 256 个字符的字符串。 这可以扩展到单个令牌 32k 的 Lucene 硬限制。 当您尝试搜索系统日志和类似文档时,这可能会产生问题。
通配符字段解决了上述限制。 它不会将字符串视为由标点符号分隔的标记集合,而是通过首先对所有文档进行近似匹配,然后对通过匹配接收到的文档子集应用详细比较来执行模式匹配。
文本、关键字和通配符字段之间的详细比较可以在此处阅读。
上述统计信息是通过在 v8.9 上运行的 elasticsearch 索引上运行搜索获得的,映射如下:
{"wildcard-search-demo-index": {"mappings": {"properties": {"field1": {"type": "text"},"field2": {"type": "keyword"},"field3": {"type": "wildcard"}}}}
}索引的文档在所有字段中具有统一的数据,即文档中的所有 3 个字段都具有相同的值。 例如,
"hits": [{"_index": "wildcard-search-demo-index","_type": "_doc","_id": "vlPiHYYB6ikeelRg4I8n","_score": 1.0,"_source": {"field1": "It started as a scalable version of the Lucene open-source search framework then added the ability to horizontally scale Lucene indices.","field2": "It started as a scalable version of the Lucene open-source search framework then added the ability to horizontally scale Lucene indices.","field3": "It started as a scalable version of the Lucene open-source search framework then added the ability to horizontally scale Lucene indices."}},{"_index": "wildcard-search-demo-index","_type": "_doc","_id": "v1PiHYYB6ikeelRg4I87","_score": 1.0,"_source": {"field1": "Elasticsearch allows you to store, search, and analyze huge volumes of data quickly and in near real-time and give back answers in milliseconds.","field2": "Elasticsearch allows you to store, search, and analyze huge volumes of data quickly and in near real-time and give back answers in milliseconds.","field3": "Elasticsearch allows you to store, search, and analyze huge volumes of data quickly and in near real-time and give back answers in milliseconds."}}]综上所述,字段类型的选择并没有固定的规则。 它取决于多种因素,例如数据类型、必须涵盖的不同用例集等。
在设置数据存储时,决定字段类型是一个非常关键的因素,因为它极大地影响性能,并且应该通过考虑所有可能的场景和因素来决定。
Elasticsearch 还有一种称为通配符的查询类型,可用于运行通配符查询。
另外值得指出的是:由于通配符搜索带来很多的性能问题,有时甚至会吃掉很多的系统资源。在生成环境中,有的建议关掉这个功能以避免影响系统的运行。建议阅读文章:
-
Kibana:如何在 Kibana 中禁止查询中使用前置通配符(wildcard)查询
-
Elasticsearch:如何提高查询性能
相关文章:
Elasticsearch:wildcard - 通配符搜索
Elasticsearch 是一个分布式、免费和开放的搜索和分析引擎,适用于所有类型的数据,例如文本、数字、地理空间、结构化和非结构化数据。 它基于 Apache Lucene 构建,Apache Lucene 是一个全文搜索引擎,可用于各种编程语言。 由于其速…...

配置类安全问题学习小结
目录 一、前言 二、漏洞类型 目录 一、前言 二、漏洞类型 2.1 Strict Transport Security Not Enforced 2.2 SSL Certificate Cannot Be Trusted 2.3 SSL Anonymous Cipher Suites Supported 2.4 "Referrer Policy”Security 头值不安全 2.5 “Content-Security-…...

IMX6ULL移植篇-uboot源码目录
一. uboot 源码分析前提 由于 uboot 会使用到一些经过编译才会生成的文件,因此,我们在分析 uboot的时候,需要先编译一下 uboot 源码工程。 这里所用的开发板是 nand-flash版本。 二. uboot 源码目录及编译 1. uboot 源码目录 uboot源码目…...
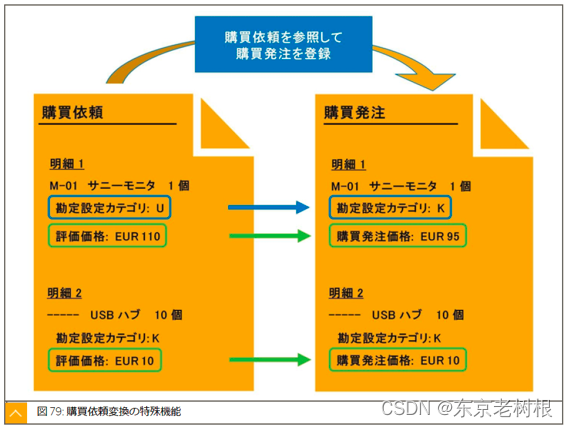
SAP MM学习笔记27- 购买依赖(采购申请)
前面已经努力的学习了 购买发注,入库,请求书照合 等功能,还是蛮多内容的哈。 剩下的功能,比如 右侧的 所要量决定,供给元决定,仕入先选择 还没学。 从这章开始,要开始学习它们了。 这一章先来…...
)
C++零碎记录(八)
14. 运算符重载简介 14.1 运算符重载简介 ① 运算符重载:对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型。 ② 对于内置的数据类型的表达式的运算符是不可能改变的。 14.2 加号运算符重载 ① 加号运算符作用&#x…...

基于matlab的扩频解扩误码率完整程序分享
clc; clear; close all; warning off; addpath(genpath(pwd)); r5; N2^r-1;%周期31 aones(1,r); mzeros(1,N); for i1:(2^r-1) temp mod((a(5)a(2)),2); for jr:-1:2 a(j)a(j-1); end a(1)temp; m(i)a(r); end mm*2-1;%双极性码 %产生随…...

算法:轮转数组---循环取模运算
1、题目: 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 2、分析特点: 轮转 > 取模运算 我们可以使用额外的数组来将每个元素放至正确的位置。用 n 表示数组的长度,我们遍历原数组&a…...
Vue教程
官网vue快速上手 vue示例图 请点击下面工程名称,跳转到代码的仓库页面,将工程 下载下来 Demo Code 里有详细的注释 代码:LearnVue...
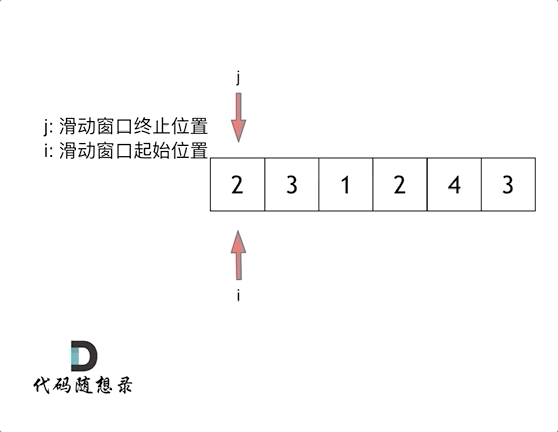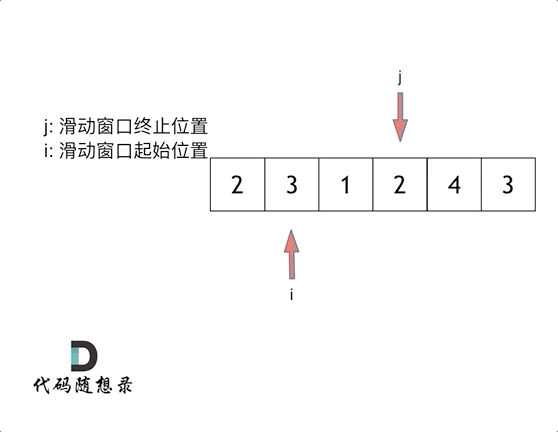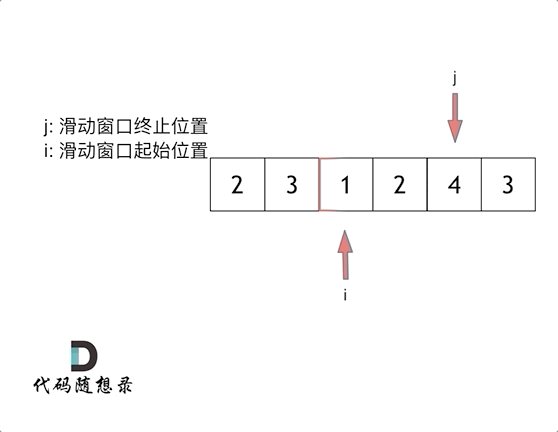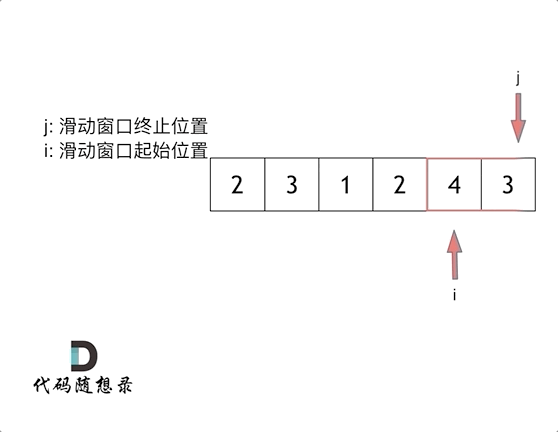
算法之双指针题型:
双指针例题小总结: 力扣27: 移除元素 力扣题目链接 双指针分为: 快慢双指针:同一个起点,同向出发 相向双指针:从两端出发,方向相反,终会相遇 经典的双指针(快慢双指…...

vue传递给后端时间格式问题
前端处理 首先前端使用moment.js进行处理 data.userEnrolDate moment(data.userEnrolDate).format(YYYY-MM-DD HH:mm:ss);后端处理 JsonFormat(timezone "GMT8", pattern "yyyy-MM-dd HH:mm:ss") DateTimeFormat(pattern "yyyy-MM-dd HH:mm:ss…...
php使用jwt作登录验证
1 在项目根目录下,安装jwt composer require firebase/php-jwt 2 在登录控制器中加入生成token的代码 use Firebase\JWT\JWT; use Firebase\JWT\Key; class Login extends Cross {/*** 显示资源列表** return \think\Response*/public function index(Request $r…...

【zlm】 PTS DTS
在音视频编码和传输中,PTS(Presentation Time Stamp)和DTS(Decoding Time Stamp)是两个关键的时间戳,用于确保音视频帧的顺序和同步。它们在多媒体处理中扮演重要的角色: PTS(Presen…...

【两周学会FPGA】从0到1学习紫光同创FPGA开发|盘古PGL22G开发板学习之DDR3 IP简单读写测试(六)
本原创教程由深圳市小眼睛科技有限公司创作,版权归本公司所有,如需转载,需授权并注明出处 适用于板卡型号: 紫光同创PGL22G开发平台(盘古22K) 一:盘古22K开发板(紫光同创PGL22G开发…...

第6章 内核模块符号导出实验(iTOP-RK3568开发板驱动开发指南 )
在上一小节中,给大家讲解了驱动模块传参实验,使用insmod命令加载驱动时可以进行参数的传递,但是每一个内核模块之间是相互独立的,那模块间的符号传递要怎样进行呢,让我们带着疑问来进行本章节的学习吧! 6.…...
第二种方法)
Android12.0首次开机默认授予app运行时权限(去掉运行时授权弹窗)第二种方法
1.概述 在12.0的系统产品开发中,在6.0以后对于权限的申请,都需要动态申请,所以会在系统首次启动后,在app的首次运行时,会弹出授权窗口,会让用户手动授予app运行时权限,在由于系统产品开发需要要求默认授予app运行时权限,不需要用户默认授予运行时弹窗,所以需要在首次开…...

conda和Python的虚拟环境如何结合使用,以及二者之间到底有什么区别?
问题描述 今天在复现streamlit的代码时(参考Streamlit 讲解专栏(一):安装以及初步应用),根据这篇博文指导,要先用以下指令创建一个虚拟环境: # 创建虚拟环境(使用venv&a…...

宇凡微YE09合封芯片,集成高性能32位mcu和2.4G芯片
合封芯片是指将主控芯片和外部器件合并封装的芯片,能大幅降低开发成本、采购成本、减少pcb面积等等。宇凡微YE09合封芯片,将技术领域推向新的高度。这款高度创新性的芯片融合了32位MCU和2.4G芯片,为各种应用场景提供卓越的功能和性能。 32位M…...

使用perf_analyzer和model-analyzer测试tritonserver的模型性能超详细完整版
导读 当我们在使用tritonserver部署模型之后,通常需要测试一下模型的服务QPS的能力,也就是1s我们的模型能处理多少的请求,也被称为吞吐量。 测试tritonserver模型服务的QPS通常有两种方法,一种是使用perf_analyzer 来测试&#…...
docker 部署springboot(成功、截图)
1.新建sringboot工程并打包 2.编写Dockerfile文件 # 基础镜像使用java FROM openjdk:8 # 作者 MAINTAINER feng # VOLUME 指定了临时文件目录为/tmp。 # 其效果是在主机 /var/lib/docker 目录下创建了一个临时文件,并链接到容器的/tmp VOLUME /tmp # 将jar包添加…...
VMware ubuntu空间越用越大
前言 用Ubuntu 1604编译了RK3399的SDK,之后删了一些多余的文件,df - h 已用21G,但window硬盘上还总用了185GB,采用了碎片整理,压缩无法解决 1 启动Ubuntu后, 安装 VMware Tools(T) 、 2 打开ubuntu终端,压…...

mRNA疫苗序列生物信息学分析:从密码子优化到免疫原性预测
1. 项目概述:解码两大mRNA疫苗的“核心蓝图”作为一名在生物信息学和基因组学领域摸爬滚打了十多年的“老码农”,我见过太多令人兴奋的数据集,但当我第一次在GitHub上看到这个名为“Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-se…...

穿越机老鸟踩坑实录:MPU6000传感器在F4飞控上的IMU方向“玄学”配置
穿越机IMU方向配置实战:从MPU6000异常自旋到飞控底层校准 当你的穿越机在通电瞬间像被无形大手狠狠抽了一记耳光般疯狂自旋,而Betaflight地面站里陀螺仪数据却显示"一切正常"时,这往往意味着你正遭遇IMU方向配置的"量子纠缠态…...

NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南
NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾为游戏卡顿而烦恼?是否觉得显卡性能总差那么一点&#x…...

终极指南:如何为PotPlayer配置百度翻译插件实现实时字幕翻译
终极指南:如何为PotPlayer配置百度翻译插件实现实时字幕翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu PotPlayer_Sub…...

解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南
解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 还在为《崩坏:星穹铁道》中重复的…...

Steam成就管理器终极指南:3步修复错失的游戏成就
Steam成就管理器终极指南:3步修复错失的游戏成就 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&a…...

Biomni:生物医学图像分析从入门到精通,AI与传统CV融合实战
1. 项目概述:当AI学会“看”懂生物医学图像如果你在生物医学研究、药物发现或者临床诊断领域工作,大概率会和我一样,对海量的生物医学图像数据感到既兴奋又头疼。兴奋的是,这些图像——无论是显微镜下的细胞切片、组织病理学玻片&…...

3步掌握yfinance:从金融数据获取到智能分析的完整指南
3步掌握yfinance:从金融数据获取到智能分析的完整指南 【免费下载链接】yfinance Download market data from Yahoo! Finances API 项目地址: https://gitcode.com/GitHub_Trending/yf/yfinance yfinance是一个强大的Python库,能够轻松从Yahoo! F…...

AXI交叉开关IP核:SoC内部高并发数据传输的核心枢纽设计与实战
1. 项目概述:一个高效、可配置的片上总线交叉开关在复杂的数字系统设计,尤其是片上系统(SoC)领域,多个主设备(如CPU、DMA控制器)需要同时访问多个从设备(如内存、外设控制器…...

开源技能安全仪表盘:从架构解析到CI/CD集成的DevSecOps实践
1. 项目概述:一个面向技能开发者的安全仪表盘最近在折腾一些智能设备上的技能开发,发现一个挺普遍但容易被忽视的问题:我们花大量时间在功能实现和用户体验上,但技能本身的安全性评估,往往只能等到上线后,通…...