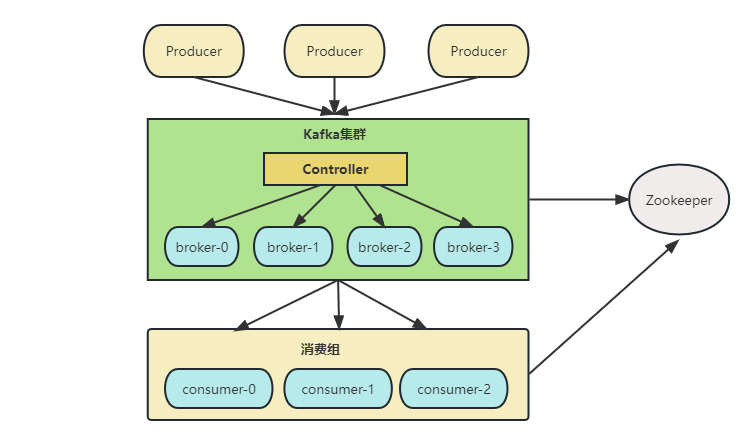
kafka架构体系
Kafka简介
Kafka是一个由Scala和Java编写的企业级的消息发布和订阅系统,最早是由Linkedin公司开发,最终开源到Apache软件基金会的项目。Kafka是一个分布式的,支持分区的,多副本的和多订阅者的高吞吐量的消息系统,被广泛应用在应用解耦、异步处理、限流削峰和消息驱动等场景。本文将针对Kafka的架构和相关组件进行简单的介绍。在介绍Kafka的架构之前,我们先了解一下Kafk的核心概念。
Kafka核心概念
在详细介绍Kafka的架构和基本组件之前,需要先了解一下Kafka的一些核心概念。
Producer:消息的生产者,负责往Kafka集群中发送消息;
Consumer:消息的消费者,主动从Kafka集群中拉取消息。
Consumer Group:每个Consumer属于一个特定的Consumer Group,新建Consumer的时候需要指定对应的Consumer Group ID。
Broker:Kafka集群中的服务实例,也称之为节点,每个Kafka集群包含一个或者多个Broker(一个Broker就是一个服务器或节点)。
Message:通过Kafka集群进行传递的对象实体,存储需要传送的信息。
Topic:消息的类别,主要用于对消息进行逻辑上的区分,每条发送到Kafka集群的消息都需要有一个指定的Topic,消费者根据Topic对指定的消息进行消费。
Partition:消息的分区,Partition是一个物理上的概念,相当于一个文件夹,Kafka会为每个topic的每个分区创建一个文件夹,一个Topic的消息会存储在一个或者多个Partition中。
Segment:一个partition当中存在多个segment文件段(分段存储),每个Segment分为两部分,.log文件和 .index 文件,其中 .index 文件是索引文件,主要用于快速查询.log 文件当中数据的偏移量位置;
.log文件:存放Message的数据文件,在Kafka中把数据文件就叫做日志文件。一个分区下面默认有n多个.log文件(分段存储)。一个.log文件大默认1G,消息会不断追加在.log文件中,当.log文件的大小超过1G的时候,会自动新建一个新的.log文件。
.index文件:存放.log文件的索引数据,每个.index文件有一个对应同名的.log文件。
后面我们会对上面的一些核心概念进行更深入的介绍。在介绍完Kafka的核心概念之后,我们来看一下Kafka的对外提供的基本功能,组件及架构设计。
Kafka API
如上图所示,Kafka主要包含四个主要的API组件:
-
Producer API
应用程序通过Producer API向Kafka集群发送一个或多个Topic的消息。 -
Consumer API
应用程序通过Consumer API,向Kafka集群订阅一个或多个Topic的消息,并处理这些Topic下接收到的消息。 -
Streams API
应用程序通过使用Streams API充当流处理器(Stream Processor),从一个或者多个Topic获取输入流,并生产一个输出流到一个或者多个Topic,能够有效地将输入流进行转变后变成输出流输出到Kafka集群。 -
Connect API
允许应用程序通过Connect API构建和运行可重用的生产者或者消费者,大数据培训能够把kafka主题连接到现有的应用程序或数据系统。Connect实际上就做了两件事情:使用Source Connector从数据源(如:DB)中读取数据写入到Topic中,然后再通过Sink Connector读取Topic中的数据输出到另一端(如:DB),以实现消息数据在外部存储和Kafka集群之间的传输。
Kafka架构
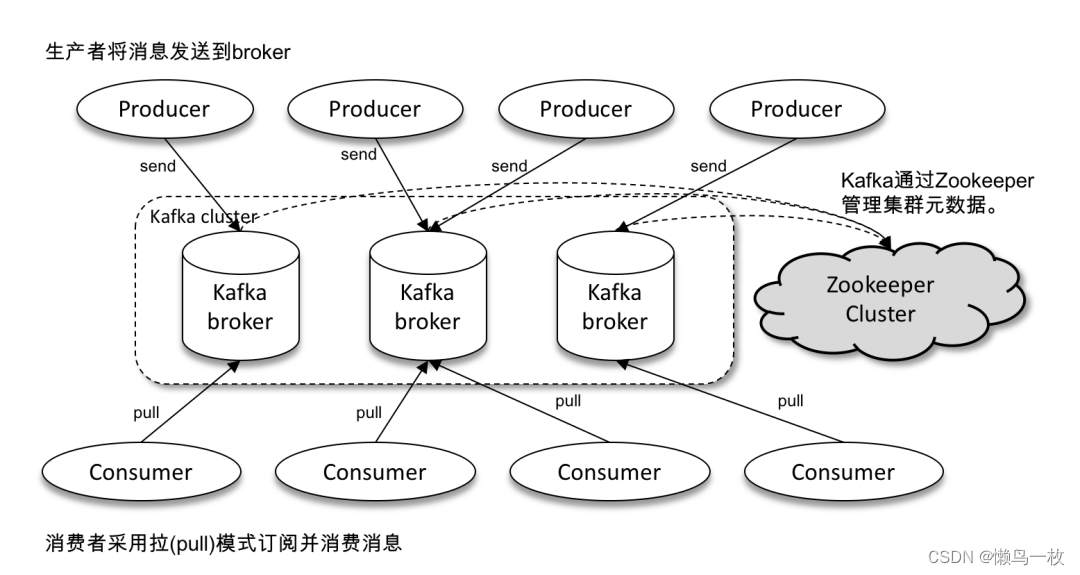
接下来我们将从Kafka的架构出发,重点介绍Kafka的主要组件及实现原理。Kafka支持消息持久化,消费端是通过主动拉取消息进行消息消费的,订阅状态和订阅关系由客户端负责维护,消息消费完后不会立刻删除,会保留历史消息,一般默认保留7天,因此可以通过在支持多订阅者时,消息无需复制多分,只需要存储一份就可以。下面将详细介绍每个组件的实现原理。
1. Producer
Producer是Kafka中的消息生产者,主要用于生产带有特定Topic的消息,生产者生产的消息通过Topic进行归类,保存在Kafka 集群的Broker上,具体的是保存在指定的partition 的目录下,以Segment的方式(.log文件和.index文件)进行存储。
2. Consumer
Consumer是Kafka中的消费者,主要用于消费指定Topic的消息,Consumer是通过主动拉取的方式从Kafka集群中消费消息,消费者一定属于某一个特定的消费组。
3. Topic
Kafka中的消息是根据Topic进行分类的**,Topic是支持多订阅的,一个Topic可以有多个不同的订阅消息的消费者。Kafka集群Topic的数量没有限制,同一个Topic的数据会被划分在同一个目录下,一个Topic可以包含1至多个分区,所有分区的消息加在一起就是一个Topic的所有消息**。
4. Partition
在Kafka中,为了提升消息的消费速度,可以为每个Topic分配多个Partition,这也是就之前我们说到的,Kafka是支持多分区的。默认情况下,一个Topic的消息只存放在一个分区中。Topic的所有分区的消息合并起来,就是一个Topic下的所有消息。每个分区都有一个从0开始的编号,每个分区内的数据都是有序的,但是不同分区直接的数据是不能保证有序的,大数据培训因为不同的分区需要不同的Consumer去消费,每个Partition只能分配一个Consumer,但是一个Consumer可以同时一个Topic的多个Partition。
Replica机制
Kafka 为分区引入了多副本(Replica)机制,通过增加副本数量可以提升容灾能力。同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中 leader 副本负责处理读写请求,follower 副本只负责与 leader 副本的消息同步。当 leader 副本出现故障时,从 follower 副本中重新选举新的 leader 副本对外提供服务。
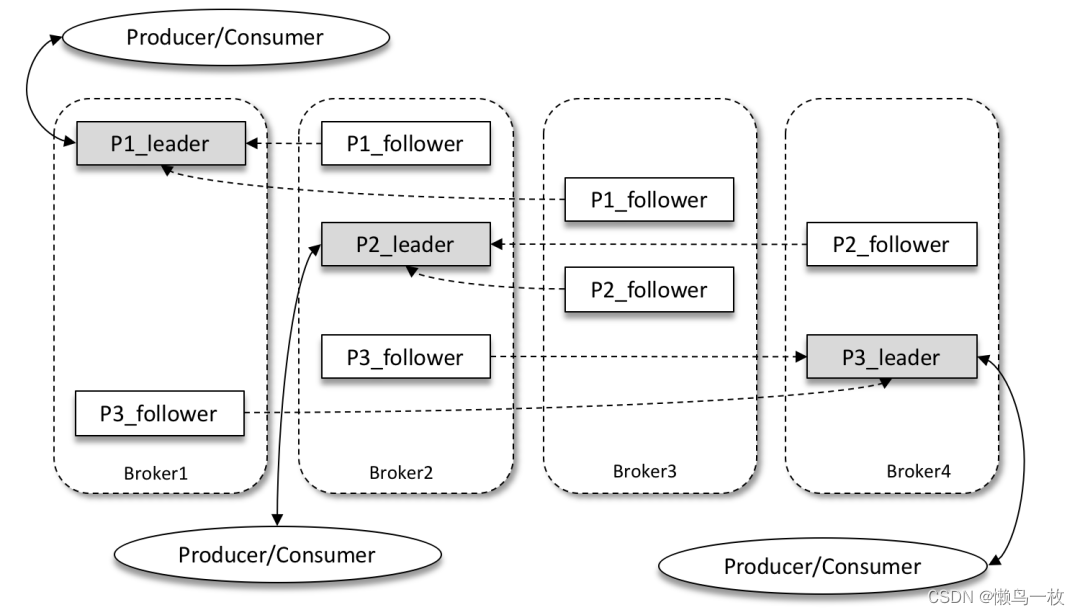
如上图所示,Kafka 集群中有4个 broker,某个主题中有3个分区,且副本因子(即副本个数)也为3,如此每个分区便有1个 leader 副本和2个 follower 副本。
5. Consumer Group
Kafka中的每一个Consumer都归属于一个特定的Consumer Group,如果不指定,那么所有的Consumer都属于同一个默认的Consumer Group。Consumer Group由一个或多个Consumer组成,同一个Consumer Group中的Consumer对同一条消息只消费一次。每个Consumer Group都有一个唯一的ID,即Group ID,也称之为Group Name。Consumer Group内的所有Consumer协调在一起订阅一个Topic的所有Partition,且每个Partition只能由一个Consuemr Group中的一个Consumer进行消费,但是可以由不同的Consumer Group中的一个Consumer进行消费。如下图所示:
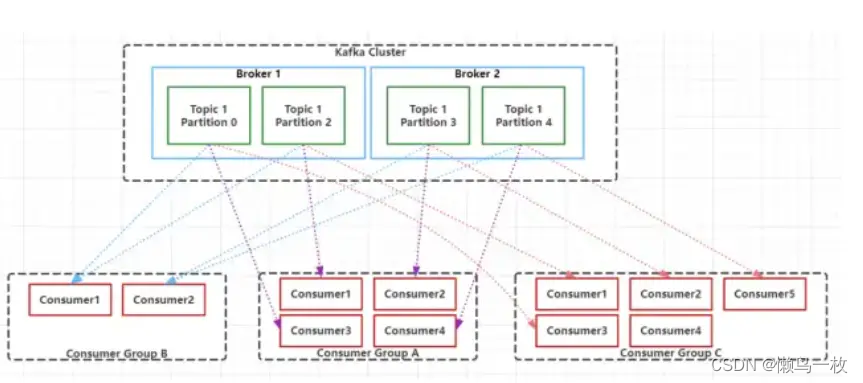
在层级关系上来说Consumer好比是跟Topic对应的,而Consumer就对应于Topic下的Partition。Consumer Group中的Consumer数量和Topic下的Partition数量共同决定了消息消费的并发量,且Partition数量决定了最终并发量,因为一个Partition只能由一个Consumer进行消费。当一个Consumer Group中Consumer数量超过订阅的Topic下的Partition数量时,Kafka会为每个Partition分配一个Consumer,多出来的Consumer会处于空闲状态。当Consumer Group中Consumer数量少于当前定于的Topic中的Partition数量是,单个Consumer将承担多个Partition的消费工作。如上图所示,Consumer Group B中的每个Consumer需要消费两个Partition中的数据,而Consumer Group C中会多出来一个空闲的Consumer4。总结下来就是:同一个Topic下的Partition数量越多,同一时间可以有越多的Consumer进行消费,消费的速度就会越快,吞吐量就越高。同时,Consumer Group中的Consumer数量需要控制为小于等于Partition数量,且最好是整数倍:如1,2,4等。
6. Segment
考虑到消息消费的性能,Kafka中的消息在每个Partition中是以分段的形式进行存储的,即每1G消息新建一个Segment,每个Segment包含两个文件:.log文件和.index文件。之前我们已经说过,.log文件就是Kafka实际存储Producer生产的消息,而.index文件采用稀疏索引的方式存储.log文件中对应消息的逻辑编号和物理偏移地址(offset),以便于加快数据的查询速度。.log文件和.index文件是一一对应,成对出现的。下图展示了.log文件和.index文件在Partition中的存在方式。
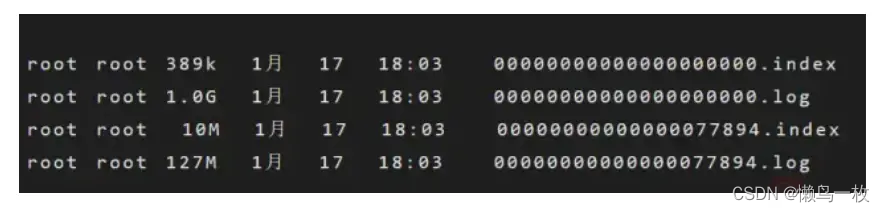
Kafka里面每一条消息都有自己的逻辑offset(相对偏移量)以及存在物理磁盘上面实际的物理地址便宜量Position,也就是说在Kafka中一条消息有两个位置:offset(相对偏移量)和position(磁盘物理偏移地址)。在kafka的设计中,将消息的offset作为了Segment文件名的一部分。Segment文件命名规则为:Partition全局的第一个Segment从0开始,后续每个segment文件名为上一个Partition的最大offset(Message的offset,非实际物理地偏移地址,实际物理地址需映射到.log中,后面会详细介绍在.log文件中查询消息的原理)。数值最大为64位long大小,由20位数字表示,前置用0填充。

上图展示了.index文件和.log文件直接的映射关系,通过上图,我们可以简单介绍一下Kafka在Segment中查找Message的过程:
1.根据需要消费的下一个消息的offset,这里假设是7,使用二分查找在Partition中查找到文件名小于(一定要小于,因为文件名编号等于当前offset的文件里存的都是大于当前offset的消息)当前offset的最大编号的.index文件,这里自然是查找到了00000000000000000000.index。
2.在.index文件中,使用二分查找,找到offset小于或者等于指定offset(这里假设是7)的最大的offset,这里查到的是6,然后获取到index文件中offset为6指向的Position(物理偏移地址)为258。
3.在.log文件中,从磁盘位置258开始顺序扫描,直到找到offset为7的Message。
至此,我们就简单介绍完了Segment的基本组件.index文件和.log文件的存储和查询原理。但是我们会发现一个问题:.index文件中的offset并不是按顺序连续存储的,为什么Kafka要将索引文件设计成这种不连续的样子?这种不连续的索引设计方式称之为稀疏索引,Kafka中采用了稀疏索引的方式读取索引,kafka每当.log中写入了4k大小的数据,就往.index里以追加的写入一条索引记录。使用稀疏索引主要有以下原因:
(1)索引稀疏存储,可以大幅降低.index文件占用存储空间大小。
(2)稀疏索引文件较小,可以全部读取到内存中,可以避免读取索引的时候进行频繁的IO磁盘操作,以便通过索引快速地定位到.log文件中的Message。
7. Message
Message是实际发送和订阅的信息是实际载体,Producer发送到Kafka集群中的每条消息,都被Kafka包装成了一个Message对象,之后再存储在磁盘中,而不是直接存储的。Message在磁盘中的物理结构如下所示。
On-disk format of a message
offset : 8 bytes
message length : 4 bytes (value: 4 + 1 + 1 + 8(if magic value > 0) + 4 + K + 4 + V)
crc : 4 bytes
magic value : 1 byte
attributes : 1 byte
timestamp : 8 bytes (Only exists when magic value is greater than zero)
key length : 4 bytes
key : K bytes
value length : 4 bytes
value : V bytes
其中key和value存储的是实际的Message内容,长度不固定,而其他都是对Message内容的统计和描述,长度固定。因此在查找实际Message过程中,磁盘指针会根据Message的offset和message length计算移动位数,以加速Message的查找过程。之所以可以这样加速,因为Kafka的.log文件都是顺序写的,往磁盘上写数据时,就是追加数据,没有随机写的操作。
8.Partition Replicas
最后我们简单聊一下Kafka中的Partition Replicas(分区副本)机制,0.8版本以前的Kafka是没有副本机制的。创建Topic时,可以为Topic指定分区,也可以指定副本个数。kafka 中的分区副本如下图所示:
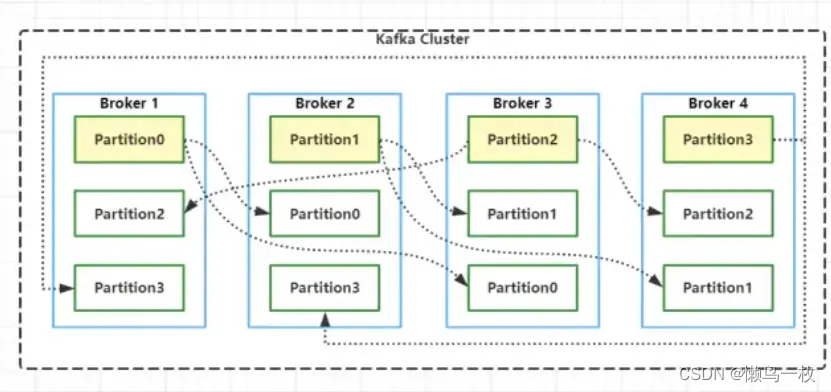
Kafka通过副本因子(replication-factor)控制消息副本保存在几个Broker(服务器)上,一般情况下副本数等于Broker的个数,且同一个副本因子不能放在同一个Broker中。副本因子是以分区为单位且区分角色;主副本称之为Leader(任何时刻只有一个),从副本称之为 Follower(可以有多个),处于同步状态的副本叫做in-sync-replicas(ISR)。Leader负责读写数据,Follower不负责对外提供数据读写,只从Leader同步数据,消费者和生产者都是从leader读写数据,不与follower交互,因此Kafka并不是读写分离的。同时使用Leader进行读写的好处是,降低了数据同步带来的数据读取延迟,因为Follower只能从Leader同步完数据之后才能对外提供读取服务。
如果一个分区有三个副本因子,就算其中一个挂掉,那么只会剩下的两个中,选择一个leader,如下图所示。但不会在其他的broker中,另启动一个副本(因为在另一台启动的话,必然存在数据拷贝和传输,会长时间占用网络IO,Kafka是一个高吞吐量的消息系统,这个情况不允许发生)。如果指定分区的所有副本都挂了,Consumer如果发送数据到指定分区的话,将写入不成功。Consumer发送到指定Partition的消息,会首先写入到Leader Partition中,写完后还需要把消息写入到ISR列表里面的其它分区副本中,写完之后这个消息才能提交offset。
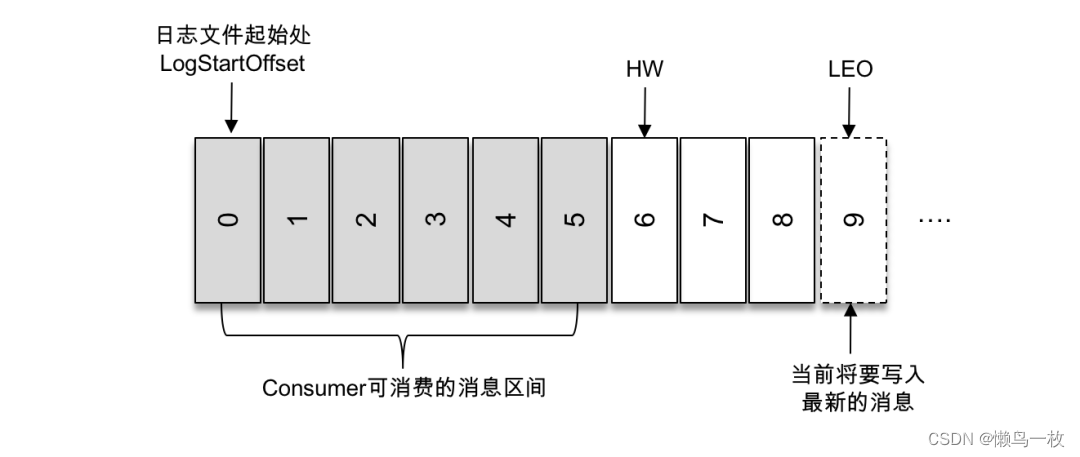
如上图所示,第一条消息的 offset(LogStartOffset)为0,最后一条消息的 offset 为8,offset 为9的消息用虚线框表示,代表下一条待写入的消息。日志文件的 HW 为6,表示消费者只能拉取到 offset 在0至5之间的消息,而 offset 为6的消息对消费者而言是不可见的。
数据同步
分区中的所有副本统称为 AR(Assigned Replicas)。所有与 leader 副本保持一定程度同步的副本(包括 leader 副本在内)组成ISR(In-Sync Replicas),ISR 集合是 AR 集合中的一个子集。
与 leader 副本同步滞后过多的副本(不包括 leader 副本)组成 OSR(Out-of-Sync Replicas),由此可见,AR=ISR+OSR。在正常情况下,所有的 follower 副本都应该与 leader 副本保持一定程度的同步,即 AR=ISR,OSR 集合为空。
Leader 副本负责维护和跟踪 ISR 集合中所有 follower 副本的滞后状态,当 follower 副本落后太多或失效时,leader 副本会把它从 ISR 集合中剔除。默认情况下,当 leader 副本发生故障时,只有在 ISR 集合中的副本才有资格被选举为新的 leader。
HW 是 High Watermark 的缩写,俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个 offset 之前的消息。
LEO 是 Log End Offset 的缩写,它标识当前日志文件中下一条待写入消息的 offset。
linux 服务下创建分区
去服务器kafka文件夹下创建相应的kafka topic,创建命令如下:bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor ${n} --partitions ${m} --topic ${topic},
其中:
${n}→副本个数,kafka单机情况下为1,集群一般为3;
${m}→分区个数,一般为10;
${topic}→需要创建的topic:(BAYONET_VEHICLEPASS_NOTIFY_JSON_TOPIC、XSINK_PLATE_ALARM_NOTIFY、XSINK_PERSON_NOTIFY_ALARM、ORIGIN_BAYONET_VEHICLEPASS_NOTIFY_JSON_TOPIC)
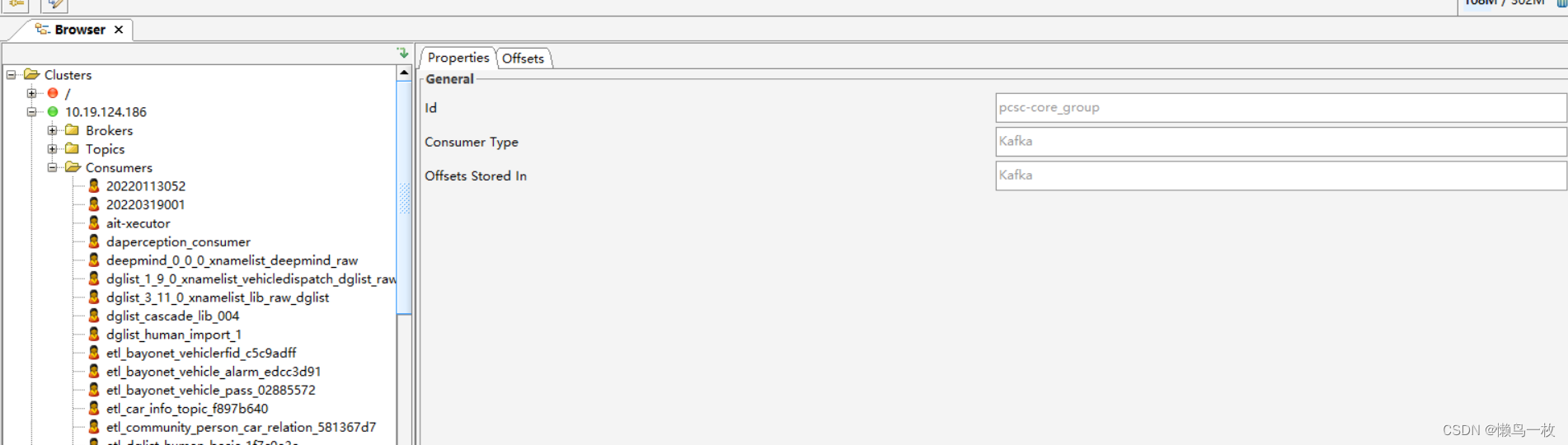
Kafka Tool 简单使用
在这里插入图片描述
kafka 客户端发送流程
kafka 高并发实践设计
相关文章:
kafka架构体系
Kafka简介 Kafka是一个由Scala和Java编写的企业级的消息发布和订阅系统,最早是由Linkedin公司开发,最终开源到Apache软件基金会的项目。Kafka是一个分布式的,支持分区的,多副本的和多订阅者的高吞吐量的消息系统,被广…...
【Kafka】三.Kafka怎么保证高可用 学习总结
Kafka 的副本机制 Kafka 的高可用实现主要依赖副本机制。 Broker 和 Partition 的关系 在分析副本机制之前,先来看一下 Broker 和 Partition 之间的关系。Broker 在英文中是代理、经纪人的意思,对应到 Kafka 集群中,是一个 Kafka 服务器节…...

Python学习笔记7:再谈抽象
再谈抽象 对象 多态 即便你不知道变量指向的是哪种对象,也能够对其执行操作封装 向外部隐藏不必要的细节。继承 类 class Person: def set_name(self, name): self.name name def get_name(self): return self.name def greet(self): print("Hello, world…...

钣金行业mes解决方案,缩短产品在制周期
钣金加工行业具有多品种、小批量离散制造行业的典型特点。一些常见的下料车间、备料车间、冲压车间、冲剪生产线等。一般来说,核心业务是钣金加工的生产单位。 一般来说,与大规模生产相比,这种生产方式效率低、成本高,自动化难度…...

【Linux】——git和gdb的简单使用技巧
目录 1.\r&&\n 2.缓冲区 3.做一个Linux的小程序——进度条 1.makefile代码: 2.proc.h代码 3.proc.c代码 4.main.c代码 4.git(上传做好的小程序) 5.Linux调试器-gdb使用 1.\r&&\n 在Linux中,可以将\r看成…...

Fiddler的简单使用
目录 1.断点应用 2.网络限速测试 2.1.为什么需要弱网测试 2.2.Fiddler弱网测试配置 1.断点应用 通过断点功能,可以在测试时方便的篡改request,response以达到测试的目的,如果:在请求头中的参数修改成错误的,或在响应…...
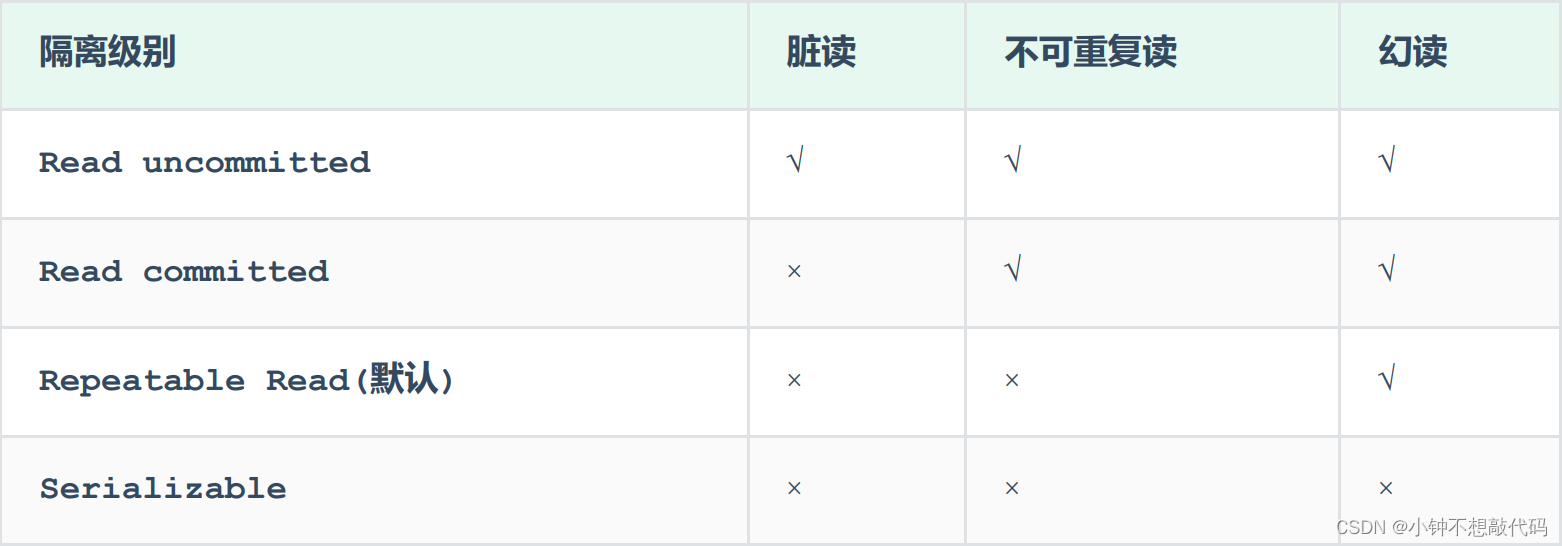
MySql 事务
概述 事务 是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 注意: 默认MySQL的事务是自动提交的,也就是…...
微信社区小程序/h5/圈子论坛贴吧交友/博客/社交/陌生人社交/宠物/话题/私域/同城交友
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 小程序/app/H5多端圈子社区论坛系统,交友/博客/社交/陌生人社交,即时聊天,私域话题,社区论坛圈子,信息引流小程序源码,广场/微校园/微小区/微同城/ 圈子论坛社区系统,含完整…...
Python os和sys模块
一、os模块 os 模块是 Python中的一个内置模块,也是 Python中整理文件和目录最为常用的模块。 该模块提供了非常丰富的方法用来处理文件和目录。比如:显示当前目录下所有文件/删除某个文件/获取文件大小 1、获取当前的工作路径 在 Python 中࿰…...

JS中数组如何去重(ES6新增的Set集合类型)+经典two sum面试题
现在有这么一个重复数组:const arr [a,a,b,a,b,c]只推荐简单高效的方法,复杂繁琐的方法不做推荐方法一:const res [...new Set(arr)]Set类型是什么呢?Set 是ES6新增的一种新集合类型。具体知识点可以看下面附录:根据…...
HDLC简介及相应hdlc实训
HDLC简介 HDLC 协议 高级数据链路控制(HDLC,High-level Data Link Control)是一种面向比特的链路层协议, 其最大特点是对任何一种比特流,均可以实现透明的传输。HDLC协议具有以下优点。 透明传输:HDLC不…...
公司技术团队为什么选择使用 YApi 作为 Api 管理平台?
在 2021 年 12 月份的时候我就推荐过一款软件程序员软件推荐:Apifox,当时体验了一下里面的功能确实很实用,但是当时公司有一套自己的 API 管理方案,所有 Apifox 暂时就没在内部使用。 直到最近要使用其他的 API 管理方案的时候才…...

ts知识点整理
1、ts 中的 any 和 unknown 有什么区别? any 和 unknown 都是顶级类型,但是 unknown 更加严格,不像 any 那样不做类型检查,反而 unknown 因为未知性质,不允许访问属性,不允许赋值给其他有明确类型的变量。…...

技术分享 | OceanBase 数据处理之控制文件
作者:杨文 DBA,负责客户项目的需求与维护,会点数据库,不限于MySQL、Redis、Cassandra、GreenPlum、ClickHouse、Elastic、TDSQL等等。 本文来源:原创投稿 *爱可生开源社区出品,原创内容未经授权不得随意使用…...
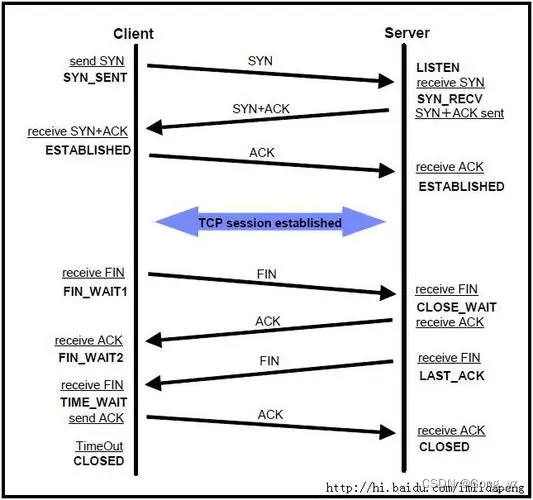
TCP的三次握手、四次挥手
文章目录前言一、一些重要字段的含义二、TCP总括图三、三次握手详细过程1.第一次握手2.第二次握手3.第三次握手三次握手小结4.为什么必须要进行三次握手,两次或四次就不行四、四次挥手1.第一次挥手2.第二次挥手3.第三次挥手4.第四次挥手四次挥手简述前言 一个TCP的…...

C++---特殊类的设计
文章目录前言一、请设计一个类,不能被拷贝二、请设计一个类,只能在堆上创建对象三、请设计一个类,只能在栈上创建对象四、请设计一个类,不能被继承五、请设计一个类,只能创建一个对象(单例模式)总结前言 正文开始! 一、请设计一个类,不能被拷贝 拷贝只会发生在两个…...

buu [WUSTCTF2020]dp_leaking_1s_very_d@angerous 1
题目描述: e 65537 n 1568083435985787749573756968151889806821667406093028310996964920682463371987925108988184962391663390152073051021014316342831685444929845865667999964711502523821441482572367072472675061656708775063702531276953141639870840764…...

基于SVPWM改进的永磁同步电机直接转矩控制二更
导读:本期对基于SVPWM的永磁同步电机直接转矩控制进行全面的分析和仿真搭建。之后与传统的DTC进行比较,凸显基于SVPWM改进的DTC方法的有效性。如果需要文中的仿真模型,关注微信公众号:浅谈电机控制,留言获取。一、 传统…...

ubuntu下磁盘管理
一. ubuntu 磁盘文件 在做 Linux 嵌入式开发中,一般选择 U 盘的要求是:确保 U 盘是 FAT格式,即选用 FAT32 格式的U盘或 SD 卡。不要用 NTFS 格式的 U 盘或 SD卡,因为Linux 大多数系统都不支持 NTFS格式的,NTFS 格式的…...

Python学习-----排序问题1.0(冒泡排序、选择排序、插入排序)
目录 前言: 1.冒泡排序 2.选择排序 3.插入排序 前言: 学过C语言肯定接触过排序问题,我们最常用的也就是冒泡排序、选择排序、插入排序……等等,同样在Python中也有排序问题,这里我也会讲解Python中冒泡排序、选择排…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

Windows文件夹共享
目标:同一局域网实现在一台计算机上共享文件夹,在另一台电脑访问一、电脑A 1.点击要共享的文件夹 -> 属性 -> 共享2.添加Everyone用户组3.控制面板中网络共享关闭密码保存,在访问时不用输入账号密码。二、电脑B 1.在文件资源管理器路径…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...

避坑指南:Unity中AABB碰撞检测失效的5种常见原因及解决方法
Unity中AABB碰撞检测失效的深度排查与解决方案在Unity开发中,AABB(轴对齐包围盒)碰撞检测是基础但容易出问题的环节。许多开发者都遇到过这样的情况:明明逻辑正确,测试时却出现物体穿透、碰撞时有时无等诡异现象。本文…...

Taotoken的稳定性与低延迟在实时对话应用中的实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的稳定性与低延迟在实时对话应用中的实际体验 在开发需要快速响应的AI聊天应用时,后端API的稳定性和延迟表现是…...

JMeter实现RSA签名验签全流程实战
1. 为什么RSA加密接口测试总卡在“连通但失败”这一步? 你有没有遇到过这种情况:接口文档写得清清楚楚,Postman里填好URL、Header、Body,一发请求——返回 {"code":4001,"msg":"签名验证失败"} …...

失传34年的南极DOS游戏LAN - LOK重见天日,背后藏着怎样的历史?
LAN - LOK:失传34年的南极DOS破坏游戏这是一次对历史进行重构(或许还会进行现代化改造)的尝试。AlphaPixel常处理遗留代码库,接触到80年代和90年代用各种方言和语言编写、存储在难处理容器和介质中的代码。因保密协议,…...