Linux操作系统
线程竞争
那么初始化一个整型为 0,使用一万个线程,每个线程都对该整型加 1,最后结果不一定会是 10000。这是因为整型变量的赋值操作不是原子操作,也就是说它不是一个不可分割的操作,而是由多条指令组成的。例如,对一个整型变量执行 a++ 操作,实际上包含了三个步骤:
- 将变量 a 的值从内存中读取到寄存器中。
- 将寄存器中的值加 1。
- 将寄存器中的值写回到内存中。
-
在多线程环境中,如果没有同步机制,那么这三个步骤可能会被打断或重排,导致数据不一致或丢失。例如,假设有两个线程 A 和 B 同时对变量 a 执行
a++操作,初始时 a 的值为 0,那么可能出现以下情况:- 线程 A 执行第一步,将 a 的值读取到寄存器中,此时寄存器中的值为 0。
- 线程 B 执行第一步,将 a 的值读取到寄存器中,此时寄存器中的值也为 0。
- 线程 A 执行第二步,将寄存器中的值加 1,此时寄存器中的值为 1。
- 线程 B 执行第二步,将寄存器中的值加 1,此时寄存器中的值也为 1。
- 线程 A 执行第三步,将寄存器中的值写回到内存中,此时内存中 a 的值为 1。
- 线程 B 执行第三步,将寄存器中的值写回到内存中,此时内存中 a 的值也为 1。
-
这样就出现了一个问题,虽然两个线程都对 a 加了 1,但是最后 a 的值只增加了 1。这就是多线程操作共享变量时可能出现的竞态条件(race condition),也就是多个线程同时访问和修改同一个数据时导致结果不正确或不可预测的情况。
-
要避免这个问题,有两种常见的方法:
- 使用原子操作(atomic operation),也就是一种不可分割的操作,它可以保证在执行过程中不会被其他线程打断或干扰。C++ 提供了
<atomic>头文件来支持原子操作。例如,可以使用std::atomic<int>类型来声明一个原子整型变量,并使用fetch_add方法来对其进行原子加法操作。这样就可以保证每个线程都能正确地对该变量加 1,并返回旧值或新值。
#include <atomic> #include <thread> #include <iostream>std::atomic<int> a(0); // 声明一个原子整型变量,并初始化为 0void add_one() {// 对原子整型变量执行原子加法操作,并返回旧值int old = a.fetch_add(1);// 输出旧值和新值std::cout << "Old value: " << old << ", new value: " << old + 1 << std::endl; }int main() {// 创建一万个线程std::thread threads[10000];for (int i = 0; i < 10000; i++) {threads[i] = std::thread(add_one);}// 等待所有线程结束for (int i = 0; i < 10000; i++) {threads[i].join();}// 输出最终结果std::cout << "Final value: " << a << std::endl;return 0; }- 使用互斥锁(mutex),也就是一种同步机制,它可以保证在某一时刻只有一个线程可以访问和修改共享数据。C++ 提供了
<mutex>头文件来支持互斥锁。例如,可以使用std::mutex类型来声明一个互斥锁,并使用lock和unlock方法来对其进行加锁和解锁操作。这样就可以保证每个线程在对共享变量加 1 时,不会被其他线程干扰。
#include <mutex> #include <thread> #include <iostream>int a = 0; // 声明一个普通整型变量,并初始化为 0 std::mutex m; // 声明一个互斥锁void add_one() {// 对互斥锁进行加锁m.lock();// 对普通整型变量执行加法操作a++;// 输出当前值std::cout << "Current value: " << a << std::endl;// 对互斥锁进行解锁m.unlock(); }int main() {// 创建一万个线程std::thread threads[10000];for (int i = 0; i < 10000; i++) {threads[i] = std::thread(add_one);}// 等待所有线程结束for (int i = 0; i < 10000; i++) {threads[i].join();}// 输出最终结果std::cout << "Final value: " << a << std::endl;return 0; } - 使用原子操作(atomic operation),也就是一种不可分割的操作,它可以保证在执行过程中不会被其他线程打断或干扰。C++ 提供了
-
原子操作的优点是效率高,不需要额外的同步开销,但是它只能对简单的数据类型进行操作,而且不能保证内存顺序性(memory order),也就是说多个原子操作之间的执行顺序可能会被编译器或处理器重排,导致结果不符合预期。互斥锁的优点是灵活性高,可以对任意复杂的数据类型进行操作,而且可以保证内存顺序性,但是它需要额外的同步开销,而且可能导致死锁(deadlock),也就是说多个线程相互等待对方释放锁,导致程序无法继续执行。
除了原子操作和互斥锁之外,还有一些其他的方法可以避免多线程操作共享变量时出现的问题,例如:
-
使用条件变量(condition variable),也就是一种同步机制,它可以让一个线程等待另一个线程的通知,从而避免不必要的轮询或竞争。条件变量通常和互斥锁一起使用,以保证数据的一致性。C++ 提供了
<condition_variable>头文件来支持条件变量。例如,可以使用std::condition_variable类型来声明一个条件变量,并使用wait和notify_one或notify_all方法来进行等待和通知操作。这样就可以实现生产者-消费者模式,也就是一个线程负责生产数据,另一个线程负责消费数据,两者之间通过条件变量进行协调。#include <mutex> #include <condition_variable> #include <queue> #include <thread> #include <iostream>std::mutex m; // 声明一个互斥锁 std::condition_variable cv; // 声明一个条件变量 std::queue<int> q; // 声明一个队列 bool done = false; // 声明一个标志位void producer() {// 生产 10 个数据for (int i = 0; i < 10; i++) {// 对互斥锁进行加锁std::unique_lock<std::mutex> lock(m);// 向队列中插入数据q.push(i);// 输出生产的数据std::cout << "Produced " << i << std::endl;// 对互斥锁进行解锁lock.unlock();// 通知消费者cv.notify_one();}// 设置标志位为 truedone = true;// 通知消费者cv.notify_one(); }void consumer() {while (true) {// 对互斥锁进行加锁std::unique_lock<std::mutex> lock(m);// 等待生产者的通知或标志位为 truecv.wait(lock, []{return !q.empty() || done;});// 如果队列不为空,则取出数据并消费if (!q.empty()) {int x = q.front();q.pop();std::cout << "Consumed " << x << std::endl;lock.unlock();} else {// 如果队列为空且标志位为 true,则退出循环if (done) {break;}lock.unlock();}} }int main() {// 创建两个线程std::thread t1(producer);std::thread t2(consumer);// 等待两个线程结束t1.join();t2.join();return 0; } -
使用信号量(semaphore),也就是一种同步机制,它可以限制对共享资源的访问数量,从而避免过载或冲突。信号量有一个整数值,表示可用的资源数量,当一个线程想要访问资源时,它必须先获取信号量,如果信号量大于零,则信号量减一,并允许访问资源;如果信号量等于零,则线程必须等待其他线程释放信号量。当一个线程访问完资源后,它必须释放信号量,使信号量加一,并唤醒等待的线程。C++ 提供了
<semaphore>头文件来支持信号量。例如,可以使用std::counting_semaphore类型来声明一个计数信号量,并使用acquire和release方法来进行获取和释放操作。这样就可以实现多个线程同时访问有限数量的资源。#include <semaphore> #include <thread> #include <iostream>std::counting_semaphore<3> sem(3); // 声明一个计数信号量,初始值为 3void access_resource(int id) {// 获取信号量sem.acquire();// 输出访问资源的线程 idstd::cout << "Thread " << id << " is accessing resource" << std::endl;// 模拟访问资源的时间std::this_thread::sleep_for(std::chrono::seconds(1));// 输出释放资源的线程 idstd::cout << "Thread " << id << " is releasing resource" << std::endl;// 释放信号量sem.release(); }int main() {// 创建 10 个线程std::thread threads[10];for (int i = 0; i < 10; i++) {threads[i] = std::thread(access_resource, i);}// 等待 10 个线程结束for (int i = 0; i < 10; i++) {threads[i].join();}return 0; }
IO多路复用
-
IO 多路复用:IO 多路复用是一种技术,它可以让一个进程或线程同时监视多个 IO 事件(如文件描述符、套接字等),并在其中一个或多个 IO 事件发生时,通知该进程或线程进行相应的处理。IO 多路复用可以提高 IO 效率,避免不必要的阻塞和轮询,适用于高并发的网络编程场景。
-
IO 多路复用的原理:IO 多路复用的原理是利用操作系统提供的一些系统调用(如 select, poll, epoll 等),将多个 IO 事件注册到一个事件集合中,然后让操作系统负责监视这些事件的状态变化,并在有事件发生时返回给用户程序。用户程序只需要调用一次系统调用,就可以处理多个 IO 事件,而不需要自己去轮询每个 IO 事件的状态,从而节省了 CPU 资源和时间。
-
IO 多路复用的优缺点:IO 多路复用的优点是它可以实现高效的 IO 处理,减少了进程或线程的切换开销,提高了并发性能。IO 多路复用的缺点是它需要额外的系统调用开销,而且不同的系统调用有各自的局限性和兼容性问题。
-
Linux 中常见的 IO 多路复用系统调用:Linux 中常见的 IO 多路复用系统调用有以下几种:
- select:select 是最早出现的 IO 多路复用系统调用,它可以监视一组文件描述符(file descriptor),并在其中一个或多个文件描述符就绪(可读、可写或有异常)时返回。select 的原型如下:
#include <sys/select.h> int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);其中,nfds 是要监视的文件描述符的数量,一般为最大文件描述符值加一;readfds, writefds, exceptfds 分别是指向读、写、异常文件描述符集合的指针,如果对某种类型不感兴趣,可以传入 NULL;timeout 是指定等待时间的指针,如果为 NULL,则表示无限等待;如果为零,则表示立即返回;否则表示等待指定的秒数和微秒数。select 的返回值是就绪文件描述符的数量,如果超时则返回零,如果出错则返回 -1,并设置 errno。
select 的优点是它可以跨平台使用,兼容性好;缺点是它只能监视 1024 个文件描述符(受 FD_SETSIZE 的限制),而且每次调用都需要将文件描述符集合从用户空间拷贝到内核空间,效率低。
- poll:poll 是对 select 的改进,它也可以监视一组文件描述符,并在其中一个或多个文件描述符就绪时返回。poll 的原型如下:
#include <poll.h> int poll(struct pollfd *fds, nfds_t nfds, int timeout);其中,fds 是指向一个 pollfd 结构体数组的指针,每个 pollfd 结构体包含了一个文件描述符和一个事件掩码(表示要监视哪些事件);nfds 是要监视的文件描述符的数量;timeout 是指定等待时间的毫秒数,如果为 -1,则表示无限等待;如果为零,则表示立即返回;否则表示等待指定的毫秒数。poll 的返回值是就绪文件描述符的数量,如果超时则返回零,如果出错则返回 -1,并设置 errno。
poll 的优点是它没有监视文件描述符的数量限制,而且不需要每次调用都重新设置文件描述符集合;缺点是它仍然需要将整个文件描述符数组从用户空间拷贝到内核空间,而且返回时需要遍历整个数组来找出就绪的文件描述符,效率低。
- epoll:epoll 是 Linux 特有的 IO 多路复用系统调用,它可以监视一组文件描述符,并在其中一个或多个文件描述符就绪时返回。epoll 的原型如下:
#include <sys/epoll.h> int epoll_create(int size); int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);其中,epoll_create 用于创建一个 epoll 实例,并返回一个文件描述符 epfd,size 参数已经被忽略,只是为了兼容旧版本的接口;epoll_ctl 用于向 epoll 实例中添加、修改或删除一个文件描述符,op 参数表示操作类型(EPOLL_CTL_ADD, EPOLL_CTL_MOD, EPOLL_CTL_DEL),fd 参数表示要操作的文件描述符,event 参数是指向一个 epoll_event 结构体的指针,该结构体包含了一个事件掩码和一个用户数据(可以是一个指针或一个整数);epoll_wait 用于等待 epoll 实例中的文件描述符就绪,并将就绪的文件描述符填充到 events 数组中,maxevents 参数表示 events 数组的大小,timeout 参数表示等待时间的毫秒数,如果为 -1,则表示无限等待;如果为零,则表示立即返回;否则表示等待指定的毫秒数。epoll_wait 的返回值是就绪文件描述符的数量,如果超时则返回零,如果出错则返回 -1,并设置 errno。
epoll 的优点是它使用了内核与用户空间共享内存的机制,避免了不必要的拷贝开销,而且它只返回就绪的文件描述符,不需要遍历整个集合,效率高;缺点是它只能在 Linux 上使用,而且对于某些特殊的文件描述符(如 pipe 的写端),它可能产生惊群效应(thundering herd),也就是说多个线程都被唤醒,但只有一个线程能够处理事件,其他线程又重新进入等待状态。
进程间通通信(IPC)的方法。
-
进程间通信:进程间通讯是指不同的进程之间如何传递和共享数据的技术,它可以实现进程之间的协作和同步,提高系统的并发性能和可靠性。Linux 操作系统中提供了多种进程间通讯的方法,主要有以下几种:
- 管道(pipe):管道是一种最简单的进程间通讯的方法,它可以在有亲缘关系的进程(如父子进程)之间建立一个单向的数据流,一个进程向管道的写端写入数据,另一个进程从管道的读端读取数据。管道的优点是使用方便,不需要额外的文件或内存空间;缺点是只能在有亲缘关系的进程之间使用,而且只能实现单向的通讯。Linux 提供了
pipe系统调用来创建一个管道,并返回两个文件描述符,分别表示管道的读端和写端。
#include <unistd.h> int pipe(int pipefd[2]);- 命名管道(named pipe):命名管道是对管道的改进,它可以在没有亲缘关系的进程之间建立一个双向的数据流,它通过在文件系统中创建一个特殊的文件来实现,任何知道该文件名的进程都可以打开该文件,并进行读写操作。命名管道的优点是可以在任意的进程之间使用,而且可以实现双向的通讯;缺点是需要额外的文件空间,而且数据传输速度较慢。Linux 提供了
mkfifo系统调用来创建一个命名管道,并返回一个文件描述符。
#include <sys/types.h> #include <sys/stat.h> int mkfifo(const char *pathname, mode_t mode);- 消息队列(message queue):消息队列是一种更高级的进程间通讯的方法,它可以在没有亲缘关系的进程之间传递一组消息,每个消息都有一个类型和一个长度,消息队列按照先进先出(FIFO)或者优先级的顺序存储和发送消息。消息队列的优点是可以避免数据同步和阻塞问题,而且可以根据消息类型进行选择性地接收;缺点是需要额外的内核空间,而且消息格式和长度有限制。Linux 提供了
msgget,msgsnd和msgrcv等系统调用来创建、发送和接收消息队列。
#include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> int msgget(key_t key, int msgflg); int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg); ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg); - 管道(pipe):管道是一种最简单的进程间通讯的方法,它可以在有亲缘关系的进程(如父子进程)之间建立一个单向的数据流,一个进程向管道的写端写入数据,另一个进程从管道的读端读取数据。管道的优点是使用方便,不需要额外的文件或内存空间;缺点是只能在有亲缘关系的进程之间使用,而且只能实现单向的通讯。Linux 提供了
进程崩溃(crash)的原因和处理方法
-
进程崩溃:进程崩溃是指一个进程在运行过程中由于某些原因意外地终止,无法正常地完成其任务。进程崩溃通常会导致系统资源的浪费,用户数据的丢失,甚至系统的不稳定或死机。
-
进程崩溃的原因:进程崩溃的原因有很多,主要有以下几种:
- 非法操作:如果一个进程试图执行一些非法的操作,例如访问非法的内存地址,除以零,执行无效的指令等,那么操作系统会检测到这些错误,并向该进程发送一个信号(signal),通常是 SIGSEGV(段错误),SIGFPE(浮点异常),SIGILL(非法指令)等。如果该进程没有注册相应的信号处理函数(signal handler),那么该进程就会被终止,并生成一个核心转储文件(core dump file),用于记录进程崩溃时的内存和寄存器状态。
- 资源不足:如果一个进程在运行过程中需要申请更多的资源,例如内存,文件描述符,线程等,而操作系统无法满足其需求,那么操作系统也会向该进程发送一个信号,通常是 SIGXFSZ(文件大小超限),SIGXCPU(CPU 时间超限),ENOMEM(内存不足)等。如果该进程没有注册相应的信号处理函数,那么该进程也会被终止,并可能生成一个核心转储文件。
- 程序逻辑错误:如果一个进程在运行过程中出现了程序逻辑错误,例如死循环,死锁,内存泄漏等,那么该进程可能会陷入无法正常退出的状态,或者消耗过多的系统资源,影响其他进程的运行。这种情况下,操作系统不一定会主动终止该进程,而是需要用户或管理员手动地杀死(kill)该进程,并分析其日志文件(log file)或调试信息(debug info)来找出错误原因。
-
进程崩溃的处理方法:进程崩溃的处理方法有以下几种:
- 预防:预防是最好的处理方法,它要求程序员在编写程序时遵循良好的编码规范和风格,避免使用不安全的函数或语句,检查各种可能的边界条件和异常情况,并使用合适的工具和方法进行调试和测试,以消除程序中潜在的错误和漏洞。
- 恢复:恢复是在进程崩溃后尽可能地恢复其正常状态或最小化其损失的方法,它要求程序员在编写程序时注册合适的信号处理函数,并在信号处理函数中执行一些必要的操作,例如释放资源,保存数据,记录日志等。此外,还可以使用一些工具和方法来分析核心转储文件或日志文件,以确定进程崩溃时的上下文信息和错误原因,并根据这些信息进行修复或优化。
- 重启:重启是在进程崩溃后重新启动该进程或整个系统的方法,它是一种简单而暴力的处理方法,它可以快速地恢复服务或功能,但是它不能解决根本的问题,而且可能会导致数据丢失或不一致。重启可以通过手动或自动的方式来实现,例如使用 shell 命令,编写守护进程(daemon process),使用 systemd 服务等。
套接字
-
套接字:套接字是一种通信机制,它可以在不同的进程或不同的主机之间进行数据交换,类似于文件描述符(file descriptor),它也是一个整数,表示一个打开的通信端点。套接字的头文件是
<sys/socket.h>,它提供了一些函数和数据结构来创建和操作套接字。 -
套接字的类型:Linux 操作系统中支持以下几种类型的套接字:
- 流式套接字(stream socket):流式套接字使用 TCP 协议来提供可靠的、有序的、双向的字节流服务,它可以保证数据不会丢失或重复,也不会出现边界问题。流式套接字适用于需要高可靠性的应用,例如文件传输,远程登录等。流式套接字的类型常量是
SOCK_STREAM。 - 数据报套接字(datagram socket):数据报套接字使用 UDP 协议来提供无连接的、不可靠的、无序的数据报服务,它不保证数据的到达或顺序,也不进行重传或确认,但是它可以避免连接建立和维护的开销,提高传输效率。数据报套接字适用于需要高效率或实时性的应用,例如视频流,语音通话等。数据报套接字的类型常量是
SOCK_DGRAM。 - 原始套接字(raw socket):原始套接字使用 IP 协议来提供直接访问网络层的服务,它可以自定义或修改 IP 数据包的内容和格式,也可以处理一些特殊的协议,例如 ICMP,IGMP 等。原始套接字适用于需要高灵活性或定制性的应用,例如网络诊断,网络安全等。原始套接字的类型常量是
SOCK_RAW。
- 流式套接字(stream socket):流式套接字使用 TCP 协议来提供可靠的、有序的、双向的字节流服务,它可以保证数据不会丢失或重复,也不会出现边界问题。流式套接字适用于需要高可靠性的应用,例如文件传输,远程登录等。流式套接字的类型常量是
-
套接字的地址:每个套接字都有一个地址(address),用于标识通信的源和目的地。不同类型的套接字有不同格式的地址,但是它们都使用一个通用的数据结构来表示,即
sockaddr结构体,它定义如下:
struct sockaddr {sa_family_t sa_family; // 地址族char sa_data[14]; // 地址信息
};
其中,sa_family 表示地址族(address family),也就是通信协议的类型,常见的地址族有 AF_INET(IPv4 协议),AF_INET6(IPv6 协议),AF_UNIX(Unix 域协议)等;sa_data 表示地址信息,也就是具体的通信地址,它根据不同的地址族有不同的含义和格式。
为了方便使用不同地址族的地址信息,Linux 操作系统还提供了一些专门针对某种地址族的数据结构来表示地址,例如:
- 对于 IPv4 地址族(
AF_INET),使用sockaddr_in结构体来表示地址,它定义如下:
struct sockaddr_in {sa_family_t sin_family; // 地址族in_port_t sin_port; // 端口号struct in_addr sin_addr; // IP 地址
};
其中,sin_family 表示地址族,必须为 AF_INET;sin_port 表示端口号,使用网络字节序(big-endian)表示;sin_addr 表示 IP 地址,使用一个 in_addr 结构体表示,它定义如下:
struct in_addr {uint32_t s_addr; // IP 地址
};
其中,s_addr 表示 IP 地址,使用网络字节序表示。为了方便地将 IP 地址和端口号转换为字符串或数字,Linux 操作系统提供了一些函数,例如 inet_ntop,inet_pton,htons,ntohs 等。
- 对于 IPv6 地址族(
AF_INET6),使用sockaddr_in6结构体来表示地址,它定义如下:
struct sockaddr_in6 {sa_family_t sin6_family; // 地址族in_port_t sin6_port; // 端口号uint32_t sin6_flowinfo; // 流信息struct in6_addr sin6_addr; // IP 地址uint32_t sin6_scope_id; // 作用域
};
其中,sin6_family 表示地址族,必须为 AF_INET6;sin6_port 表示端口号,使用网络字节序表示;sin6_flowinfo 表示流信息,用于区分同一主机上的不同流;sin6_addr 表示 IP 地址,使用一个 in6_addr 结构体表示,它定义如下:
struct in6_addr {unsigned char s6_addr[16]; // IP 地址
};
其中,s6_addr 表示 IP 地址,使用网络字节序表示。为了方便地将 IP 地址和端口号转换为字符串或数字,Linux 操作系统提供了一些函数,例如 inet_ntop,inet_pton,htons,ntohs 等。
- 对于 Unix 域地址族(
AF_UNIX),使用sockaddr_un结构体来表示地址,它定义如下:
#define UNIX_PATH_MAX 108
struct sockaddr_un {sa_family_t sun_family; // 地址族char sun_path[UNIX_PATH_MAX]; // 路径名
};
其中,sun_family 表示地址族,必须为 AF_UNIX;sun_path 表示路径名,也就是 Unix 域套接字所对应的文件名。
-
套接字的操作:Linux 操作系统中提供了一些函数来创建和操作套接字,主要有以下几种:
- socket:socket 函数用于创建一个套接字,并返回一个文件描述符,它的原型如下:
#include <sys/types.h> #include <sys/socket.h> int socket(int domain, int type, int protocol);其中,domain 参数表示地址族的类型,可以是
AF_INET,AF_INET6,AF_UNIX等;type 参数表示套接字的类型,可以是SOCK_STREAM,SOCK_DGRAM,SOCK_RAW等;protocol 参数表示具体的协议类型,通常为 0,表示使用默认的协议。socket 函数的返回值是一个文件描述符,如果出错则返回 -1,并设置 errno。- bind:bind 函数用于将一个套接字绑定到一个地址上,它的原型如下:
#include <sys/types.h> #include <sys/socket.h> int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);其中,sockfd 参数是由 socket 函数返回的文件描述符;addr 参数是指向一个 sockaddr 结构体或其子结构体(如 sockaddr_in, sockaddr_in6, sockaddr_un 等)的指针;addrlen 参数是该结构体的大小。bind 函数的返回值是 0,表示成功;如果出错则返回 -1,并设置 errno。
- listen:listen 函数用于将一个流式套接字转换为被动模式(passive mode),也就是说该套接字可以接受其他进程的连接请求,它的原型如下:
#include <sys/types.h> #include <sys/socket.h> int listen(int sockfd, int backlog);其中,sockfd 参数是由 socket 函数返回的文件描述符;backlog 参数表示等待连接队列(pending connection queue)的最大长度,也就是说该套接字可以等待的最大连接数。listen 函数的返回值是 0,表示成功;如果出错则返回 -1,并设置 errno。
-
accept:accept 函数用于接受一个连接请求,并返回一个新的文件描述符,该文件描述符用于与客户端进行通信,它的原型如下:
#include <sys/types.h>
#include <sys/socket.h>
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
其中,sockfd 参数是由 listen 函数创建的套接字的文件描述符;addr 参数是一个指向 sockaddr 结构体的指针,用于存储客户端的地址信息;addrlen 参数是一个指向整数的指针,用于表示 addr 结构体的大小。accept 函数的返回值是一个新的文件描述符,用于与客户端进行通信;如果出错则返回 -1,并设置 errno。
- connect:connect 函数用于发起一个连接请求,将套接字连接到指定的地址,它的原型如下:
#include <sys/types.h>
#include <sys/socket.h>
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
其中,sockfd 参数是由 socket 函数创建的套接字的文件描述符;addr 参数是一个指向 sockaddr 结构体的指针,用于指定目标地址;addrlen 参数是 addr 结构体的大小。connect 函数的返回值是 0,表示成功;如果出错则返回 -1,并设置 errno。
- send 和 recv:send 函数用于向已连接的套接字发送数据,recv 函数用于从已连接的套接字接收数据,它们的原型分别如下:
#include <sys/types.h>
#include <sys/socket.h>
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
其中,sockfd 参数是已连接的套接字的文件描述符;buf 参数是一个指向数据缓冲区的指针;len 参数表示数据的长度;flags 参数用于指定发送或接收数据的选项。send 和 recv 函数的返回值是实际发送或接收的数据长度,如果出错则返回 -1,并设置 errno。
- close:close 函数用于关闭一个套接字,释放相关的资源,它的原型如下:
#include <unistd.h>
int close(int sockfd);
其中,sockfd 参数是要关闭的套接字的文件描述符。close 函数的返回值是 0,表示成功;如果出错则返回 -1,并设置 errno。
这些是套接字在 Linux 操作系统中的基本操作和数据结构,可以用于实现各种网络通信应用。根据不同的需求和场景,可以选择合适的套接字类型、地址族和操作来构建应用程序。同时,还需要考虑网络安全性、性能优化等方面的问题,以确保应用程序的稳定性和可靠性。
相关文章:

Linux操作系统
线程竞争 那么初始化一个整型为 0,使用一万个线程,每个线程都对该整型加 1,最后结果不一定会是 10000。这是因为整型变量的赋值操作不是原子操作,也就是说它不是一个不可分割的操作,而是由多条指令组成的。例如&#…...

华为OD:VLAN资源池
题目描述: VLANO 是一种对局域网设备进行逻辑划分的技术,为了标识不同的VLAN,引入VLAN ID(1-4094之间的整数)的概念。 定义一个VLAN ID的资源池(下称VLAN资源池),资源池中连续的VLAN用开始VLAN-结束VLAN表…...

大学大创项目:手机室内AR导航APP项目思路
文章目录 一、最初的项目思路二、建图和定位分离的项目思路1、建图2、定位 个人见解,如有错误,请多包涵 一、最初的项目思路 在大创项目的开始,将手机确定为应用设备,传感器确定为相机。 由于知识储备的原因,在头一次…...

OpenSSL加解密算法使用方法
下面简单记录一下 Linux上openssl命令的使用方法,包括 OpenSSL中加解密算法的使用方法和性能测试方法,以便让新手朋友们能快速用起来。持续更新中 … sm3算法 $ openssl sm3 /tmp/1.txt SM3(/tmp/1.txt) baafadbe43559b7043abd1682a4e12be05692cae175…...
Excel VSTO开发10 -自定义任务面板
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 10 自定义任务面板 自定义任务面板(有些地方称为侧边面板)即CustomTaskPane,这个类在Microsoft…...

百度智能云千帆大模型丨未来人手必备的代码助手
文章目录 1. 前言2. 千帆大模型平台3. 十分友好的功能4. comate代码助手5. 总结 1. 前言 我之前给大家推荐过Poe这个网站,它用的人比较少,但一旦接触后会发现它其实挺强大的。 因为它是一个可以同时支持好几个大模型的在线聚合平台。常用的GPT4&#x…...

美客多平台经营秘籍:为何测评补单操作是必要的?
许多经营美客多平台的商家有一种观念,他们认为美客多平台的规则与亚马逊有所区别。在美客多上,店铺比产品更重要,而且平台的竞争相对较小。因此,他们认为在美客多平台进行补单操作是不必要的。 然而,根据美客多平台的…...

AArch64内存管理
概述 本指南介绍AArch64中的内存转换,这是内存管理的关键。本文介绍了如何将虚拟地址转换为物理地址、转换表格式以及软件如何管理页表缓存 (TLB)。 这些对于底层代码(例如启动代码或驱动程序)开发人员都很有用。对于编写软件来设置或管理内…...
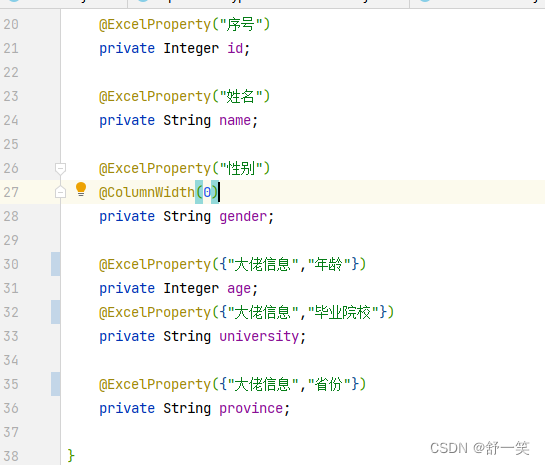
导出Excel的技术分享-综合篇
导出Excel的技术分享-综合篇 简单的EasyExcel使用 /*** 最简单的写*/public void simpleWrite() {// 注意 simpleWrite在数据量不大的情况下可以使用(5000以内,具体也要看实际情况),数据量大参照 重复多次写入// 写法1 JDK8// s…...

iPhone 14四款机型电池容量详细参数揭秘
苹果推出的iPhone 14系列与2021系列的设计和外形尺寸相同(仅缩小了几分之一毫米),所以这并不奇怪,但电池容量也大致相同。 虽然可能不足以对电池寿命产生可衡量的影响,但也存在微小的差异。不同的是,现在有…...

Python功能强大、灵活可扩展的Statsmodels库
Statsmodels是一个功能强大、灵活可扩展的Python库,用于进行统计建模和数据分析。它提供了一系列丰富的统计模型和方法,可以帮助研究人员和数据科学家在Python环境中进行高级统计分析。 概述 在Statsmodels中,线性回归是最常用的统计模型之…...

AcWing 4405. 统计子矩阵(每日一题)
如果你觉得这篇题解对你有用,可以点点关注再走呗~ 题目描述 给定一个 NM 的矩阵 A,请你统计有多少个子矩阵 (最小 11,最大 NM) 满足子矩阵中所有数的和不超过给定的整数 K ? 输入格式 第一行包含三个整数 N,M 和 K。 之后 N 行每行包含 …...

Kali Linux渗透测试技术介绍【文末送书】
文章目录 写在前面一、什么是Kali Linux二、渗透测试基础概述和方法论三、好书推荐1. 书籍简介2. 读者对象3. 随书资源 写作末尾 写在前面 对于企业网络安全建设工作的质量保障,业界普遍遵循PDCA(计划(Plan)、实施(Do…...
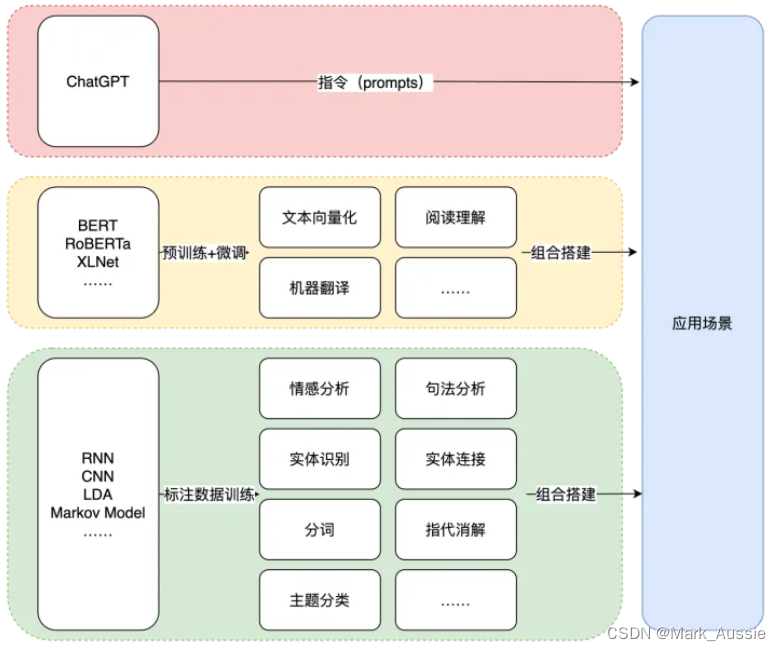
GPT与BERT模型
NLP任务的核心逻辑是“猜概率”的游戏。BERT和GPT都是基于预训练语言模型的思想,通过大量语料训练得到语言模型。两种模型都是基于Transformer模型。 Bert 类似于Transformer的Encoder部分,GPT类似于Transformer的Decoder部分。两者最明显的在结构上的差…...

2023-09-06力扣每日一题-摆烂暴力
链接: [1123. 最深叶节点的最近公共祖先](https://leetcode.cn/problems/form-smallest-number-from-two-digit-arrays/) 题意: 如题 解: 今天搞一手暴力,按层存,按层取,直到只取到一个 实际代码&…...

【Flutter】Flutter 使用 timego 将日期转换为时间描述
【Flutter】Flutter 使用 timego 将日期转换为时间描述 文章目录 一、前言二、安装与基本使用三、如何添加新的语言四、如何覆盖现有的语言或添加自定义消息五、完整示例六、总结 一、前言 你好!我是小雨青年,今天我要为你介绍一个非常实用的 Flutter 包…...
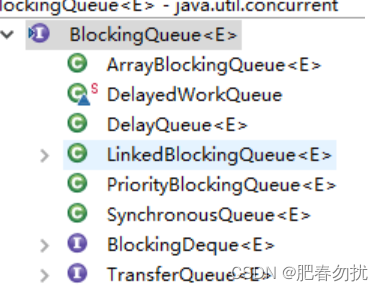
并发容器11
一 JDK 提供的并发容器总结 JDK 提供的这些容器大部分在 java.util.concurrent 包中。 ConcurrentHashMap: 线程安全的 HashMap CopyOnWriteArrayList: 线程安全的 List,在读多写少的场合性能非常好,远远好于 Vector. ConcurrentLinkedQueue: 高效的并…...
Java8实战-总结22
Java8实战-总结22 使用流数值流原始类型流特化数值范围数值流应用:勾股数 使用流 数值流 可以使用reduce方法计算流中元素的总和。例如,可以像下面这样计算菜单的热量: int calories menu.stream().map(Dish::getcalories).reduce(0, Int…...

matlab 实现点云ICP 配准算法
一、算法步骤 (1)在目标点云P中取点集pi∈P; (2)找出源点云Q中的对应点集qi∈Q,使得||qi-pi||=min; (3)计算旋转矩阵R和平移矩阵t,使得误差函数最小; (4)对pi使用上一步求得的旋转矩阵R和平移矩阵t进行旋转和平移变换,的到新的对应点集pi’={pi’=Rpi+t,pi∈P};…...

python提取word文本和word图片
提取文本 docx只支持docx格式,所以如果想读取doc需要另存为docx格式即可 import docx # pip3 install python-docx doc docx.Document(three.docx) for paragraph in doc.paragraphs:print(paragraph.text)提取图片 import zipfile import os, re # docx本质上…...

5分钟掌握Snap.Hutao:免费开源的Windows原神桌面工具箱完全指南
5分钟掌握Snap.Hutao:免费开源的Windows原神桌面工具箱完全指南 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn…...

Python量化交易框架moltfi:从回测到实盘的轻量级解决方案
1. 项目概述:一个为现代金融科技而生的开源量化框架如果你在金融科技或者量化交易领域摸爬滚打过一段时间,大概率会和我有同样的感受:市面上的开源量化框架,要么是“巨无霸”级别的庞然大物,功能齐全但学习曲线陡峭&am…...
引发的音素错位故障)
ElevenLabs旁遮普语TTS突然失真?3步定位Gurmukhi Unicode变体(U+0A02/U+0A3C/U+0A4D)引发的音素错位故障
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs旁遮普文语音合成异常现象综述 ElevenLabs 目前官方文档明确标注支持旁遮普语(Gurmukhi script, language code: pa),但在实际调用其 REST API 进行语音合…...

抖音无水印下载器终极指南:两种高效方法实现高清视频保存
抖音无水印下载器终极指南:两种高效方法实现高清视频保存 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downloader 抖音无水…...

CanFestival实战:从心跳、TPDO/RPDO配置到回调函数的完整链路解析
1. CanFestival协议栈基础认知 第一次接触CanFestival时,我也被各种专业术语搞得晕头转向。简单来说,它就是个开源的CANopen协议栈实现,专门用于嵌入式设备间的通信。就像两个说同一种方言的人能顺畅交流一样,CanFestival让不同厂…...

MA730/MT6835/MT6825/MT6709磁编码器SPI通信实战:从寄存器配置到角度解析
1. 磁编码器SPI通信基础与选型指南 磁编码器作为现代电机控制和机器人系统中的核心传感器,其精度和响应速度直接影响整个系统的性能。MA730、MT6835、MT6825和MT6709这几款磁编码器在工业界应用广泛,它们都采用SPI接口进行通信,但在具体实现上…...

别再死记硬背了!用面包板和Arduino Nano,5分钟搞懂MOS管开关控制LED
用面包板和Arduino Nano轻松掌握MOS管控制LED的奥秘 记得第一次接触MOS管时,我被那些复杂的参数曲线和公式搞得晕头转向。直到有一天,导师扔给我一块面包板、几个元器件说:"别盯着书本看了,动手试试看!"那天…...

SysML v2系统建模语言:2025年模型驱动系统工程实战指南
SysML v2系统建模语言:2025年模型驱动系统工程实战指南 【免费下载链接】SysML-v2-Release The latest incremental release of SysML v2. Start here. 项目地址: https://gitcode.com/gh_mirrors/sy/SysML-v2-Release SysML v2系统建模语言作为新一代系统工…...

【独家首发】Midjourney像素艺术训练数据集反向推演报告:基于12,843张高质量样本的风格迁移规律白皮书
更多请点击: https://intelliparadigm.com 第一章:Midjourney像素艺术风格的定义与边界判定 像素艺术(Pixel Art)在 Midjourney 中并非原生风格类别,而是一种通过提示词工程、参数约束与后处理协同达成的视觉范式。其…...

别再傻傻分不清!CANoe里CAPL节点到底该放Measurement Setup还是Simulation Setup?
CANoe实战指南:CAPL节点在Measurement与Simulation Setup中的精准选择策略 在汽车电子系统开发与测试领域,CANoe作为行业标准工具,其CAPL(CAN Access Programming Language)节点的正确配置直接影响测试结果的准确性和可…...