day31 IO流
文章目录
- 回顾collection
- ArrayTestList
- HashSetTset
- HashMapTest
- Properties
- TreeSetTest
- IO流
- FileInputStreamTest01 文件流初步
- FileInputStreamTest02 循环读
- FileStreamTest03
- FileInputStreamTes04 需要掌握
- FiLeInputStreamTest5
- FileOutputStreamTest01
- Copy1 文件拷贝
- FileReaderTest
- FileWriterTest
- Copy02
- BufferedReaderTest01
- BufferedReaderTest02 转换流
- BufferWriterTest
- DataOutputStream
- DataInputStream
- PrintStreamTest 标准输出流
- Logger
- LogTest
- FileTest01
- FileTest02 File类常用方法
- FileTest03
- CopyAll 目录拷贝
- ObjectInputStreamTest01 序列号
- ObjectOutputStreamTest01
- ObjectInputStreamTest02
- ObjectOutputStreamTest02
- IoPropertiesTest01 配置文件
回顾collection
day31课堂笔记
1、集合这块最主要掌握什么内容?
1.1、每个集合对象的创建(new)
1.2、向集合中添加元素
1.3、从集合中取出某个元素
1.4、遍历集合
1.5、主要的集合类:
ArrayList
LinkedList
HashSet (HashMap的key,存储在HashMap集合key的元素需要同时重写hashCode + equals)
TreeSet
HashMap
Properties
TreeMap
ArrayTestList
package com.bjpowernode.javase.review;import java.util.ArrayList;
import java.util.Iterator;
import java.util.LinkedList;/*1.1、每个集合对象的创建(new)1.2、向集合中添加元素1.3、从集合中取出某个元素1.4、遍历集合*/
public class ArrayListTest {public static void main(String[] args) {// 创建集合对象//ArrayList<String> list = new ArrayList<>();LinkedList<String> list = new LinkedList<>();// 添加元素list.add("zhangsan");list.add("lisi");list.add("wangwu");// 从集合中取出某个元素// List集合有下标String firstElt = list.get(0);System.out.println(firstElt);// 遍历(下标方式)for(int i = 0; i < list.size(); i++){String elt = list.get(i);System.out.println(elt);}// 遍历(迭代器方式,这个是通用的,所有Collection都能用)Iterator<String> it = list.iterator();while(it.hasNext()){System.out.println(it.next());}// while循环修改为for循环/*for(Iterator<String> it2 = list.iterator(); it2.hasNext(); ){System.out.println("====>" + it2.next());}*/// 遍历(foreach方式)for(String s : list){System.out.println(s);}}
}HashSetTset
package com.bjpowernode.javase.review;import java.util.HashSet;
import java.util.Iterator;
import java.util.Objects;
import java.util.Set;/*1.1、每个集合对象的创建(new)1.2、向集合中添加元素1.3、从集合中取出某个元素1.4、遍历集合1.5、测试HashSet集合的特点:无序不可重复。*/
public class HashSetTest {public static void main(String[] args) {// 创建集合对象HashSet<String> set = new HashSet<>();// 添加元素set.add("abc");set.add("def");set.add("king");// set集合中的元素不能通过下标取了。没有下标// 遍历集合(迭代器)Iterator<String> it = set.iterator();while(it.hasNext()){System.out.println(it.next());}// 遍历集合(foreach)for(String s : set){System.out.println(s);}set.add("king");set.add("king");set.add("king");System.out.println(set.size()); //3 (后面3个king都没有加进去。)set.add("1");set.add("10");set.add("2");for(String s : set){System.out.println("--->" + s);}// 创建Set集合,存储Student数据Set<Student> students = new HashSet<>();Student s1 = new Student(111, "zhangsan");Student s2 = new Student(222, "lisi");Student s3 = new Student(111, "zhangsan");students.add(s1);students.add(s2);students.add(s3);System.out.println(students.size()); // 2// 遍历for(Student stu : students){System.out.println(stu);}}
}class Student {int no;String name;public Student() {}public Student(int no, String name) {this.no = no;this.name = name;}@Overridepublic String toString() {return "Student{" +"no=" + no +", name='" + name + '\'' +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return no == student.no &&Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(no, name);}
}HashMapTest
package com.bjpowernode.javase.review;import java.util.HashMap;
import java.util.Map;
import java.util.Set;/*1.1、每个集合对象的创建(new)1.2、向集合中添加元素1.3、从集合中取出某个元素1.4、遍历集合*/
public class HashMapTest {public static void main(String[] args) {// 创建Map集合Map<Integer, String> map = new HashMap<>();// 添加元素map.put(1, "zhangsan");map.put(9, "lisi");map.put(10, "wangwu");map.put(2, "king");map.put(2, "simth"); // key重复value会覆盖。// 获取元素个数System.out.println(map.size());// 取key是2的元素System.out.println(map.get(2)); // smith// 遍历Map集合很重要,几种方式都要会。// 第一种方式:先获取所有的key,遍历key的时候,通过key获取valueSet<Integer> keys = map.keySet();for(Integer key : keys){System.out.println(key + "=" + map.get(key));}// 第二种方式:是将Map集合转换成Set集合,Set集合中每一个元素是Node// 这个Node节点中有key和valueSet<Map.Entry<Integer,String>> nodes = map.entrySet();for(Map.Entry<Integer,String> node : nodes){System.out.println(node.getKey() + "=" + node.getValue());}}
}Properties
package com.bjpowernode.javase.review;import java.util.Properties;public class PropertiesTest {public static void main(String[] args) {// 创建对象Properties pro = new Properties();// 存pro.setProperty("username", "test");pro.setProperty("password", "test123");// 取String username = pro.getProperty("username");String password = pro.getProperty("password");System.out.println(username);System.out.println(password);}
}TreeSetTest
package com.bjpowernode.javase.review;import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;/*1.1、每个集合对象的创建(new)1.2、向集合中添加元素1.3、从集合中取出某个元素1.4、遍历集合1.5、测试TreeSet集合中的元素是可排序的。1.6、测试TreeSet集合中存储的类型是自定义的。1.7、测试实现Comparable接口的方式1.8、测试实现Comparator接口的方式(最好测试以下匿名内部类的方式)*/
public class TreeSetTest {public static void main(String[] args) {// 集合的创建(可以测试以下TreeSet集合中存储String、Integer的。这些类都是SUN写好的。)//TreeSet<Integer> ts = new TreeSet<>();// 编写比较器可以改变规则。TreeSet<Integer> ts = new TreeSet<>(new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2 - o1; // 自动拆箱}});// 添加元素ts.add(1);ts.add(100);ts.add(10);ts.add(10);ts.add(10);ts.add(10);ts.add(0);// 遍历(迭代器方式)Iterator<Integer> it = ts.iterator();while(it.hasNext()) {Integer i = it.next();System.out.println(i);}// 遍历(foreach)for(Integer x : ts){System.out.println(x);}// TreeSet集合中存储自定义类型TreeSet<A> atree = new TreeSet<>();atree.add(new A(100));atree.add(new A(200));atree.add(new A(500));atree.add(new A(300));atree.add(new A(400));atree.add(new A(1000));// 遍历for(A a : atree){System.out.println(a);}//TreeSet<B> btree = new TreeSet<>(new BComparator());// 匿名内部类方式。TreeSet<B> btree = new TreeSet<>(new Comparator<B>() {@Overridepublic int compare(B o1, B o2) {return o1.i - o2.i;}});btree.add(new B(500));btree.add(new B(100));btree.add(new B(200));btree.add(new B(600));btree.add(new B(300));btree.add(new B(50));for(B b : btree){System.out.println(b);}}
}// 第一种方式:实现Comparable接口
class A implements Comparable<A>{int i;public A(int i){this.i = i;}@Overridepublic String toString() {return "A{" +"i=" + i +'}';}@Overridepublic int compareTo(A o) {//return this.i - o.i;return o.i - this.i;}
}class B {int i;public B(int i){this.i = i;}@Overridepublic String toString() {return "B{" +"i=" + i +'}';}
}// 比较器
class BComparator implements Comparator<B> {@Overridepublic int compare(B o1, B o2) {return o1.i - o2.i;}
}
IO流
2、IO流,什么是IO?
I : Input
O : Output
通过IO可以完成硬盘文件的读和写。
3、IO流的分类?
有多种分类方式:一种方式是按照流的方向进行分类:以内存作为参照物,往内存中去,叫做输入(Input)。或者叫做读(Read)。从内存中出来,叫做输出(Output)。或者叫做写(Write)。另一种方式是按照读取数据方式不同进行分类:有的流是按照字节的方式读取数据,一次读取1个字节byte,等同于一次读取8个二进制位。这种流是万能的,什么类型的文件都可以读取。包括:文本文件,图片,声音文件,视频文件等....假设文件file1.txt,采用字节流的话是这样读的:a中国bc张三fe第一次读:一个字节,正好读到'a'第二次读:一个字节,正好读到'中'字符的一半。第三次读:一个字节,正好读到'中'字符的另外一半。有的流是按照字符的方式读取数据的,一次读取一个字符,这种流是为了方便读取普通文本文件而存在的,这种流不能读取:图片、声音、视频等文件。只能读取纯文本文件,连word文件都无法读取。假设文件file1.txt,采用字符流的话是这样读的:a中国bc张三fe第一次读:'a'字符('a'字符在windows系统中占用1个字节。)第二次读:'中'字符('中'字符在windows系统中占用2个字节。)综上所述:流的分类输入流、输出流字节流、字符流
4、Java中的IO流都已经写好了,我们程序员不需要关心,我们最主要还是掌握,
在java中已经提供了哪些流,每个流的特点是什么,每个流对象上的常用方法有
哪些????
java中所有的流都是在:java.io.*;下。
java中主要还是研究:怎么new流对象。调用流对象的哪个方法是读,哪个方法是写。
5、java IO流这块有四大家族:
四大家族的首领:
java.io.InputStream 字节输入流
java.io.OutputStream 字节输出流
java.io.Reader 字符输入流java.io.Writer 字符输出流四大家族的首领都是抽象类。(abstract class)所有的流都实现了:java.io.Closeable接口,都是可关闭的,都有close()方法。流毕竟是一个管道,这个是内存和硬盘之间的通道,用完之后一定要关闭,不然会耗费(占用)很多资源。养成好习惯,用完流一定要关闭。所有的输出流都实现了:java.io.Flushable接口,都是可刷新的,都有flush()方法。养成一个好习惯,输出流在最终输出之后,一定要记得flush()刷新一下。这个刷新表示将通道/管道当中剩余未输出的数据强行输出完(清空管道!)刷新的作用就是清空管道。注意:如果没有flush()可能会导致丢失数据。注意:在java中只要“类名”以Stream结尾的都是字节流。以“Reader/Writer”结尾的都是字符流。
6、java.io包下需要掌握的流有16个:
文件专属:java.io.FileInputStream(掌握)java.io.FileOutputStream(掌握)java.io.FileReaderjava.io.FileWriter转换流:(将字节流转换成字符流)java.io.InputStreamReaderjava.io.OutputStreamWriter缓冲流专属:java.io.BufferedReaderjava.io.BufferedWriterjava.io.BufferedInputStreamjava.io.BufferedOutputStream数据流专属:java.io.DataInputStreamjava.io.DataOutputStream标准输出流:java.io.PrintWriterjava.io.PrintStream(掌握)对象专属流:java.io.ObjectInputStream(掌握)java.io.ObjectOutputStream(掌握)
7、java.io.File类。
File类的常用方法。
8、java io这块还剩下什么内容:
第一:ObjectInputStream ObjectOutputStream的使用。
第二:IO流+Properties集合的联合使用。
1、拷贝目录。
2、关于对象流
ObjectInputStream
ObjectOutputStream
重点:参与序列化的类型必须实现java.io.Serializable接口。并且建议将序列化版本号手动的写出来。private static final long serialVersionUID = 1L;
3、IO + Properties联合使用。
IO流:文件的读和写。
Properties:是一个Map集合,key和value都是String类型。
FileInputStreamTest01 文件流初步
package com.bjpowernode.java.io;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;/*
java.io.FileInputStream:1、文件字节输入流,万能的,任何类型的文件都可以采用这个流来读。2、字节的方式,完成输入的操作,完成读的操作(硬盘---> 内存)*/
public class FileInputStreamTest01 {public static void main(String[] args) {FileInputStream fis = null;try {// 创建文件字节输入流对象// 文件路径:D:\course\JavaProjects\02-JavaSE\temp (IDEA会自动把\编程\\,因为java中\表示转义)// 以下都是采用了:绝对路径的方式。//FileInputStream fis = new FileInputStream("D:\\course\\JavaProjects\\02-JavaSE\\temp");// 写成这个/也是可以的。fis = new FileInputStream("D:/course/JavaProjects/02-JavaSE/temp");// 开始读int readData = fis.read(); // 这个方法的返回值是:读取到的“字节”本身。System.out.println(readData); //97readData = fis.read();System.out.println(readData); //98readData = fis.read();System.out.println(readData); //99readData = fis.read();System.out.println(readData); //100readData = fis.read();System.out.println(readData); //101readData = fis.read();System.out.println(readData); //102// 已经读到文件的末尾了,再读的时候读取不到任何数据,返回-1.readData = fis.read();System.out.println(readData);readData = fis.read();System.out.println(readData);readData = fis.read();System.out.println(readData);} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {// 在finally语句块当中确保流一定关闭。if (fis != null) { // 避免空指针异常!// 关闭流的前提是:流不是空。流是null的时候没必要关闭。try {fis.close();} catch (IOException e) {e.printStackTrace();}}}}
}FileInputStreamTest02 循环读
package com.bjpowernode.java.io;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;/*
对第一个程序进行改进。循环方式。分析这个程序的缺点:一次读取一个字节byte,这样内存和硬盘交互太频繁,基本上时间/资源都耗费在交互上面了。能不能一次读取多个字节呢?可以。*/
public class FileInputStreamTest02 {public static void main(String[] args) {FileInputStream fis = null;try {fis = new FileInputStream("D:\\course\\JavaProjects\\02-JavaSE\\temp");/*while(true) {int readData = fis.read();if(readData == -1) {break;}System.out.println(readData);}*/// 改造while循环int readData = 0;while((readData = fis.read()) != -1){System.out.println(readData);}} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {if (fis != null) {try {fis.close();} catch (IOException e) {e.printStackTrace();}}}}
}FileStreamTest03
package com.bjpowernode.java.io;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;/*
int read(byte[] b)一次最多读取 b.length 个字节。减少硬盘和内存的交互,提高程序的执行效率。往byte[]数组当中读。*/
public class FileInputStreamTest03 {public static void main(String[] args) {FileInputStream fis = null;try {// 相对路径的话呢?相对路径一定是从当前所在的位置作为起点开始找!// IDEA默认的当前路径是哪里?工程Project的根就是IDEA的默认当前路径。//fis = new FileInputStream("tempfile3");//fis = new FileInputStream("chapter23/tempfile2");//fis = new FileInputStream("chapter23/src/tempfile3");fis = new FileInputStream("chapter23/src/com/bjpowernode/java/io/tempfile4");// 开始读,采用byte数组,一次读取多个字节。最多读取“数组.length”个字节。byte[] bytes = new byte[4]; // 准备一个4个长度的byte数组,一次最多读取4个字节。// 这个方法的返回值是:读取到的字节数量。(不是字节本身)int readCount = fis.read(bytes);System.out.println(readCount); // 第一次读到了4个字节。// 将字节数组全部转换成字符串//System.out.println(new String(bytes)); // abcd// 不应该全部都转换,应该是读取了多少个字节,转换多少个。System.out.println(new String(bytes,0, readCount));readCount = fis.read(bytes); // 第二次只能读取到2个字节。System.out.println(readCount); // 2// 将字节数组全部转换成字符串//System.out.println(new String(bytes)); // efcd// 不应该全部都转换,应该是读取了多少个字节,转换多少个。System.out.println(new String(bytes,0, readCount));readCount = fis.read(bytes); // 1个字节都没有读取到返回-1System.out.println(readCount); // -1} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {if (fis != null) {try {fis.close();} catch (IOException e) {e.printStackTrace();}}}}
}FileInputStreamTes04 需要掌握
package com.bjpowernode.java.io;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;/*
最终版,需要掌握。*/
public class FileInputStreamTest04 {public static void main(String[] args) {FileInputStream fis = null;try {fis = new FileInputStream("chapter23/src/tempfile3");// 准备一个byte数组byte[] bytes = new byte[4];/*while(true){int readCount = fis.read(bytes);if(readCount == -1){break;}// 把byte数组转换成字符串,读到多少个转换多少个。System.out.print(new String(bytes, 0, readCount));}*/int readCount = 0;while((readCount = fis.read(bytes)) != -1) {System.out.print(new String(bytes, 0, readCount));}} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {if (fis != null) {try {fis.close();} catch (IOException e) {e.printStackTrace();}}}}
}FiLeInputStreamTest5
package com.bjpowernode.java.io;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;/*
FileInputStream类的其它常用方法:int available():返回流当中剩余的没有读到的字节数量long skip(long n):跳过几个字节不读。*/
public class FileInputStreamTest05 {public static void main(String[] args) {FileInputStream fis = null;try {fis = new FileInputStream("tempfile");System.out.println("总字节数量:" + fis.available());// 读1个字节//int readByte = fis.read();// 还剩下可以读的字节数量是:5//System.out.println("剩下多少个字节没有读:" + fis.available());// 这个方法有什么用?//byte[] bytes = new byte[fis.available()]; // 这种方式不太适合太大的文件,因为byte[]数组不能太大。// 不需要循环了。// 直接读一次就行了。//int readCount = fis.read(bytes); // 6//System.out.println(new String(bytes)); // abcdef// skip跳过几个字节不读取,这个方法也可能以后会用!fis.skip(3);System.out.println(fis.read()); //100} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {if (fis != null) {try {fis.close();} catch (IOException e) {e.printStackTrace();}}}}
}FileOutputStreamTest01
package com.bjpowernode.java.io;import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;/*** 文件字节输出流,负责写。* 从内存到硬盘。*/
public class FileOutputStreamTest01 {public static void main(String[] args) {FileOutputStream fos = null;try {// myfile文件不存在的时候会自动新建!// 这种方式谨慎使用,这种方式会先将原文件清空,然后重新写入。//fos = new FileOutputStream("myfile");//fos = new FileOutputStream("chapter23/src/tempfile3");// 以追加的方式在文件末尾写入。不会清空原文件内容。fos = new FileOutputStream("chapter23/src/tempfile3", true);// 开始写。byte[] bytes = {97, 98, 99, 100};// 将byte数组全部写出!fos.write(bytes); // abcd// 将byte数组的一部分写出!fos.write(bytes, 0, 2); // 再写出ab// 字符串String s = "我是一个中国人,我骄傲!!!";// 将字符串转换成byte数组。byte[] bs = s.getBytes();// 写fos.write(bs);// 写完之后,最后一定要刷新fos.flush();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {if (fos != null) {try {fos.close();} catch (IOException e) {e.printStackTrace();}}}}
}Copy1 文件拷贝
package com.bjpowernode.java.io;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;/*
使用FileInputStream + FileOutputStream完成文件的拷贝。
拷贝的过程应该是一边读,一边写。
使用以上的字节流拷贝文件的时候,文件类型随意,万能的。什么样的文件都能拷贝。*/
public class Copy01 {public static void main(String[] args) {FileInputStream fis = null;FileOutputStream fos = null;try {// 创建一个输入流对象fis = new FileInputStream("D:\\course\\02-JavaSE\\video\\chapter01\\动力节点-JavaSE-杜聚宾-001-文件扩展名的显示.avi");// 创建一个输出流对象fos = new FileOutputStream("C:\\动力节点-JavaSE-杜聚宾-001-文件扩展名的显示.avi");// 最核心的:一边读,一边写byte[] bytes = new byte[1024 * 1024]; // 1MB(一次最多拷贝1MB。)int readCount = 0;while((readCount = fis.read(bytes)) != -1) {fos.write(bytes, 0, readCount);}// 刷新,输出流最后要刷新fos.flush();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {// 分开try,不要一起try。// 一起try的时候,其中一个出现异常,可能会影响到另一个流的关闭。if (fos != null) {try {fos.close();} catch (IOException e) {e.printStackTrace();}}if (fis != null) {try {fis.close();} catch (IOException e) {e.printStackTrace();}}}}
}FileReaderTest
package com.bjpowernode.java.io;import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;/*
FileReader:文件字符输入流,只能读取普通文本。读取文本内容时,比较方便,快捷。*/
public class FileReaderTest {public static void main(String[] args) {FileReader reader = null;try {// 创建文件字符输入流reader = new FileReader("tempfile");//准备一个char数组char[] chars = new char[4];// 往char数组中读reader.read(chars); // 按照字符的方式读取:第一次e,第二次f,第三次 风....for(char c : chars) {System.out.println(c);}/*// 开始读char[] chars = new char[4]; // 一次读取4个字符int readCount = 0;while((readCount = reader.read(chars)) != -1) {System.out.print(new String(chars,0,readCount));}*/} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {if (reader != null) {try {reader.close();} catch (IOException e) {e.printStackTrace();}}}}
}FileWriterTest
package com.bjpowernode.java.io;import java.io.FileWriter;
import java.io.IOException;/*
FileWriter:文件字符输出流。写。只能输出普通文本。*/
public class FileWriterTest {public static void main(String[] args) {FileWriter out = null;try {// 创建文件字符输出流对象//out = new FileWriter("file");out = new FileWriter("file", true);// 开始写。char[] chars = {'我','是','中','国','人'};out.write(chars);out.write(chars, 2, 3);out.write("我是一名java软件工程师!");// 写出一个换行符。out.write("\n");out.write("hello world!");// 刷新out.flush();} catch (IOException e) {e.printStackTrace();} finally {if (out != null) {try {out.close();} catch (IOException e) {e.printStackTrace();}}}}
}Copy02
package com.bjpowernode.java.io;import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;/*
使用FileReader FileWriter进行拷贝的话,只能拷贝“普通文本”文件。*/
public class Copy02 {public static void main(String[] args) {FileReader in = null;FileWriter out = null;try {// 读in = new FileReader("chapter23/src/com/bjpowernode/java/io/Copy02.java");// 写out = new FileWriter("Copy02.java");// 一边读一边写:char[] chars = new char[1024 * 512]; // 1MBint readCount = 0;while((readCount = in.read(chars)) != -1){out.write(chars, 0, readCount);}// 刷新out.flush();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {if (in != null) {try {in.close();} catch (IOException e) {e.printStackTrace();}}if (out != null) {try {out.close();} catch (IOException e) {e.printStackTrace();}}}}
}BufferedReaderTest01
package com.bjpowernode.java.io;import java.io.BufferedReader;
import java.io.FileReader;/*
BufferedReader:带有缓冲区的字符输入流。使用这个流的时候不需要自定义char数组,或者说不需要自定义byte数组。自带缓冲。*/
public class BufferedReaderTest01 {public static void main(String[] args) throws Exception{FileReader reader = new FileReader("Copy02.java");// 当一个流的构造方法中需要一个流的时候,这个被传进来的流叫做:节点流。// 外部负责包装的这个流,叫做:包装流,还有一个名字叫做:处理流。// 像当前这个程序来说:FileReader就是一个节点流。BufferedReader就是包装流/处理流。BufferedReader br = new BufferedReader(reader);// 读一行/*String firstLine = br.readLine();System.out.println(firstLine);String secondLine = br.readLine();System.out.println(secondLine);String line3 = br.readLine();System.out.println(line3);*/// br.readLine()方法读取一个文本行,但不带换行符。String s = null;while((s = br.readLine()) != null){System.out.print(s);}// 关闭流// 对于包装流来说,只需要关闭最外层流就行,里面的节点流会自动关闭。(可以看源代码。)br.close();}
}BufferedReaderTest02 转换流
package com.bjpowernode.java.io;import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.InputStreamReader;/*转换流:InputStreamReader*/
public class BufferedReaderTest02 {public static void main(String[] args) throws Exception{/*// 字节流FileInputStream in = new FileInputStream("Copy02.java");// 通过转换流转换(InputStreamReader将字节流转换成字符流。)// in是节点流。reader是包装流。InputStreamReader reader = new InputStreamReader(in);// 这个构造方法只能传一个字符流。不能传字节流。// reader是节点流。br是包装流。BufferedReader br = new BufferedReader(reader);*/// 合并BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("Copy02.java")));String line = null;while((line = br.readLine()) != null){System.out.println(line);}// 关闭最外层br.close();}
}BufferWriterTest
package com.bjpowernode.java.io;import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.OutputStreamWriter;/*
BufferedWriter:带有缓冲的字符输出流。
OutputStreamWriter:转换流*/
public class BufferedWriterTest {public static void main(String[] args) throws Exception{// 带有缓冲区的字符输出流//BufferedWriter out = new BufferedWriter(new FileWriter("copy"));BufferedWriter out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("copy", true)));// 开始写。out.write("hello world!");out.write("\n");out.write("hello kitty!");// 刷新out.flush();// 关闭最外层out.close();}
}DataOutputStream
package com.bjpowernode.java.io;import java.io.DataOutputStream;
import java.io.FileOutputStream;/*
java.io.DataOutputStream:数据专属的流。
这个流可以将数据连同数据的类型一并写入文件。
注意:这个文件不是普通文本文档。(这个文件使用记事本打不开。)*/
public class DataOutputStreamTest {public static void main(String[] args) throws Exception{// 创建数据专属的字节输出流DataOutputStream dos = new DataOutputStream(new FileOutputStream("data"));// 写数据byte b = 100;short s = 200;int i = 300;long l = 400L;float f = 3.0F;double d = 3.14;boolean sex = false;char c = 'a';// 写dos.writeByte(b); // 把数据以及数据的类型一并写入到文件当中。dos.writeShort(s);dos.writeInt(i);dos.writeLong(l);dos.writeFloat(f);dos.writeDouble(d);dos.writeBoolean(sex);dos.writeChar(c);// 刷新dos.flush();// 关闭最外层dos.close();}
}DataInputStream
package com.bjpowernode.java.io;import java.io.DataInputStream;
import java.io.FileInputStream;/*
DataInputStream:数据字节输入流。
DataOutputStream写的文件,只能使用DataInputStream去读。并且读的时候你需要提前知道写入的顺序。
读的顺序需要和写的顺序一致。才可以正常取出数据。*/
public class DataInputStreamTest01 {public static void main(String[] args) throws Exception{DataInputStream dis = new DataInputStream(new FileInputStream("data"));// 开始读byte b = dis.readByte();short s = dis.readShort();int i = dis.readInt();long l = dis.readLong();float f = dis.readFloat();double d = dis.readDouble();boolean sex = dis.readBoolean();char c = dis.readChar();System.out.println(b);System.out.println(s);System.out.println(i + 1000);System.out.println(l);System.out.println(f);System.out.println(d);System.out.println(sex);System.out.println(c);dis.close();}
}PrintStreamTest 标准输出流
package com.bjpowernode.java.io;import java.io.FileOutputStream;
import java.io.PrintStream;/*
java.io.PrintStream:标准的字节输出流。默认输出到控制台。*/
public class PrintStreamTest {public static void main(String[] args) throws Exception{// 联合起来写System.out.println("hello world!");// 分开写PrintStream ps = System.out;ps.println("hello zhangsan");ps.println("hello lisi");ps.println("hello wangwu");// 标准输出流不需要手动close()关闭。// 可以改变标准输出流的输出方向吗? 可以/*// 这些是之前System类使用过的方法和属性。System.gc();System.currentTimeMillis();PrintStream ps2 = System.out;System.exit(0);System.arraycopy(....);*/// 标准输出流不再指向控制台,指向“log”文件。PrintStream printStream = new PrintStream(new FileOutputStream("log"));// 修改输出方向,将输出方向修改到"log"文件。System.setOut(printStream);// 再输出System.out.println("hello world");System.out.println("hello kitty");System.out.println("hello zhangsan");}
}Logger
package com.bjpowernode.java.io;import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
import java.text.SimpleDateFormat;
import java.util.Date;/*
日志工具*/
public class Logger {/*记录日志的方法。*/public static void log(String msg) {try {// 指向一个日志文件PrintStream out = new PrintStream(new FileOutputStream("log.txt", true));// 改变输出方向System.setOut(out);// 日期当前时间Date nowTime = new Date();SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");String strTime = sdf.format(nowTime);System.out.println(strTime + ": " + msg);} catch (FileNotFoundException e) {e.printStackTrace();}}
}LogTest
package com.bjpowernode.java.io;public class LogTest {public static void main(String[] args) {//测试工具类是否好用Logger.log("调用了System类的gc()方法,建议启动垃圾回收");Logger.log("调用了UserService的doSome()方法");Logger.log("用户尝试进行登录,验证失败");Logger.log("我非常喜欢这个记录日志的工具哦!");}
}FileTest01
package com.bjpowernode.java.io;import java.io.File;/*
File1、File类和四大家族没有关系,所以File类不能完成文件的读和写。2、File对象代表什么?文件和目录路径名的抽象表示形式。C:\Drivers 这是一个File对象C:\Drivers\Lan\Realtek\Readme.txt 也是File对象。一个File对象有可能对应的是目录,也可能是文件。File只是一个路径名的抽象表示形式。3、需要掌握File类中常用的方法*/
public class FileTest01 {public static void main(String[] args) throws Exception {// 创建一个File对象File f1 = new File("D:\\file");// 判断是否存在!System.out.println(f1.exists());// 如果D:\file不存在,则以文件的形式创建出来/*if(!f1.exists()) {// 以文件形式新建f1.createNewFile();}*/// 如果D:\file不存在,则以目录的形式创建出来/*if(!f1.exists()) {// 以目录的形式新建。f1.mkdir();}*/// 可以创建多重目录吗?File f2 = new File("D:/a/b/c/d/e/f");/*if(!f2.exists()) {// 多重目录的形式新建。f2.mkdirs();}*/File f3 = new File("D:\\course\\01-开课\\学习方法.txt");// 获取文件的父路径String parentPath = f3.getParent();System.out.println(parentPath); //D:\course\01-开课File parentFile = f3.getParentFile();System.out.println("获取绝对路径:" + parentFile.getAbsolutePath());File f4 = new File("copy");System.out.println("绝对路径:" + f4.getAbsolutePath()); // C:\Users\Administrator\IdeaProjects\javase\copy}
}FileTest02 File类常用方法
package com.bjpowernode.java.io;import java.io.File;
import java.text.SimpleDateFormat;
import java.util.Date;/*
File类的常用方法*/
public class FileTest02 {public static void main(String[] args) {File f1 = new File("D:\\course\\01-开课\\开学典礼.ppt");// 获取文件名System.out.println("文件名:" + f1.getName());// 判断是否是一个目录System.out.println(f1.isDirectory()); // false// 判断是否是一个文件System.out.println(f1.isFile()); // true// 获取文件最后一次修改时间long haoMiao = f1.lastModified(); // 这个毫秒是从1970年到现在的总毫秒数。// 将总毫秒数转换成日期?????Date time = new Date(haoMiao);SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");String strTime = sdf.format(time);System.out.println(strTime);// 获取文件大小System.out.println(f1.length()); //216064字节。}
}FileTest03
package com.bjpowernode.java.io;import java.io.File;/*
File中的listFiles方法。*/
public class FileTest03 {public static void main(String[] args) {// File[] listFiles()// 获取当前目录下所有的子文件。File f = new File("D:\\course\\01-开课");File[] files = f.listFiles();// foreachfor(File file : files){//System.out.println(file.getAbsolutePath());System.out.println(file.getName());}}
}CopyAll 目录拷贝
package com.bjpowernode.java.io;import java.io.*;/*
拷贝目录*/
public class CopyAll {public static void main(String[] args) {// 拷贝源File srcFile = new File("D:\\course\\02-JavaSE\\document");// 拷贝目标File destFile = new File("C:\\a\\b\\c");// 调用方法拷贝copyDir(srcFile, destFile);}/*** 拷贝目录* @param srcFile 拷贝源* @param destFile 拷贝目标*/private static void copyDir(File srcFile, File destFile) {if(srcFile.isFile()) {// srcFile如果是一个文件的话,递归结束。// 是文件的时候需要拷贝。// ....一边读一边写。FileInputStream in = null;FileOutputStream out = null;try {// 读这个文件// D:\course\02-JavaSE\document\JavaSE进阶讲义\JavaSE进阶-01-面向对象.pdfin = new FileInputStream(srcFile);// 写到这个文件中// C:\course\02-JavaSE\document\JavaSE进阶讲义\JavaSE进阶-01-面向对象.pdfString path = (destFile.getAbsolutePath().endsWith("\\") ? destFile.getAbsolutePath() : destFile.getAbsolutePath() + "\\") + srcFile.getAbsolutePath().substring(3);out = new FileOutputStream(path);// 一边读一边写byte[] bytes = new byte[1024 * 1024]; // 一次复制1MBint readCount = 0;while((readCount = in.read(bytes)) != -1){out.write(bytes, 0, readCount);}out.flush();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {if (out != null) {try {out.close();} catch (IOException e) {e.printStackTrace();}}if (in != null) {try {in.close();} catch (IOException e) {e.printStackTrace();}}}return;}// 获取源下面的子目录File[] files = srcFile.listFiles();for(File file : files){// 获取所有文件的(包括目录和文件)绝对路径//System.out.println(file.getAbsolutePath());if(file.isDirectory()){// 新建对应的目录//System.out.println(file.getAbsolutePath());//D:\course\02-JavaSE\document\JavaSE进阶讲义 源目录//C:\course\02-JavaSE\document\JavaSE进阶讲义 目标目录String srcDir = file.getAbsolutePath();String destDir = (destFile.getAbsolutePath().endsWith("\\") ? destFile.getAbsolutePath() : destFile.getAbsolutePath() + "\\") + srcDir.substring(3);File newFile = new File(destDir);if(!newFile.exists()){newFile.mkdirs();}}// 递归调用copyDir(file, destFile);}}
}ObjectInputStreamTest01 序列号
package com.bjpowernode.java.io;import java.io.FileInputStream;
import java.io.ObjectInputStream;/*
反序列化*/
public class ObjectInputStreamTest01 {public static void main(String[] args) throws Exception{ObjectInputStream ois = new ObjectInputStream(new FileInputStream("students"));// 开始反序列化,读Object obj = ois.readObject();// 反序列化回来是一个学生对象,所以会调用学生对象的toString方法。System.out.println(obj);ois.close();}
}ObjectOutputStreamTest01
package com.bjpowernode.java.io;import com.bjpowernode.java.bean.Student;import java.io.FileOutputStream;
import java.io.ObjectOutputStream;/*
1、java.io.NotSerializableException:Student对象不支持序列化!!!!2、参与序列化和反序列化的对象,必须实现Serializable接口。3、注意:通过源代码发现,Serializable接口只是一个标志接口:public interface Serializable {}这个接口当中什么代码都没有。那么它起到一个什么作用呢?起到标识的作用,标志的作用,java虚拟机看到这个类实现了这个接口,可能会对这个类进行特殊待遇。Serializable这个标志接口是给java虚拟机参考的,java虚拟机看到这个接口之后,会为该类自动生成一个序列化版本号。4、序列化版本号有什么用呢?java.io.InvalidClassException:com.bjpowernode.java.bean.Student;local class incompatible:stream classdesc serialVersionUID = -684255398724514298(十年后),local class serialVersionUID = -3463447116624555755(十年前)java语言中是采用什么机制来区分类的?第一:首先通过类名进行比对,如果类名不一样,肯定不是同一个类。第二:如果类名一样,再怎么进行类的区别?靠序列化版本号进行区分。小鹏编写了一个类:com.bjpowernode.java.bean.Student implements Serializable胡浪编写了一个类:com.bjpowernode.java.bean.Student implements Serializable不同的人编写了同一个类,但“这两个类确实不是同一个类”。这个时候序列化版本就起上作用了。对于java虚拟机来说,java虚拟机是可以区分开这两个类的,因为这两个类都实现了Serializable接口,都有默认的序列化版本号,他们的序列化版本号不一样。所以区分开了。(这是自动生成序列化版本号的好处)请思考?这种自动生成序列化版本号有什么缺陷?这种自动生成的序列化版本号缺点是:一旦代码确定之后,不能进行后续的修改,因为只要修改,必然会重新编译,此时会生成全新的序列化版本号,这个时候java虚拟机会认为这是一个全新的类。(这样就不好了!)最终结论:凡是一个类实现了Serializable接口,建议给该类提供一个固定不变的序列化版本号。这样,以后这个类即使代码修改了,但是版本号不变,java虚拟机会认为是同一个类。*/
public class ObjectOutputStreamTest01 {public static void main(String[] args) throws Exception{// 创建java对象Student s = new Student(1111, "zhangsan");// 序列化ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("students"));// 序列化对象oos.writeObject(s);// 刷新oos.flush();// 关闭oos.close();}
}ObjectInputStreamTest02
package com.bjpowernode.java.io;import com.bjpowernode.java.bean.User;import java.io.FileInputStream;
import java.io.ObjectInputStream;
import java.util.List;/*
反序列化集合*/
public class ObjectInputStreamTest02 {public static void main(String[] args) throws Exception{ObjectInputStream ois = new ObjectInputStream(new FileInputStream("users"));//Object obj = ois.readObject();//System.out.println(obj instanceof List);List<User> userList = (List<User>)ois.readObject();for(User user : userList){System.out.println(user);}ois.close();}
}ObjectOutputStreamTest02
package com.bjpowernode.java.io;import com.bjpowernode.java.bean.User;import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.List;/*
一次序列化多个对象呢?可以,可以将对象放到集合当中,序列化集合。
提示:参与序列化的ArrayList集合以及集合中的元素User都需要实现 java.io.Serializable接口。*/
public class ObjectOutputStreamTest02 {public static void main(String[] args) throws Exception{List<User> userList = new ArrayList<>();userList.add(new User(1,"zhangsan"));userList.add(new User(2, "lisi"));userList.add(new User(3, "wangwu"));ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("users"));// 序列化一个集合,这个集合对象中放了很多其他对象。oos.writeObject(userList);oos.flush();oos.close();}
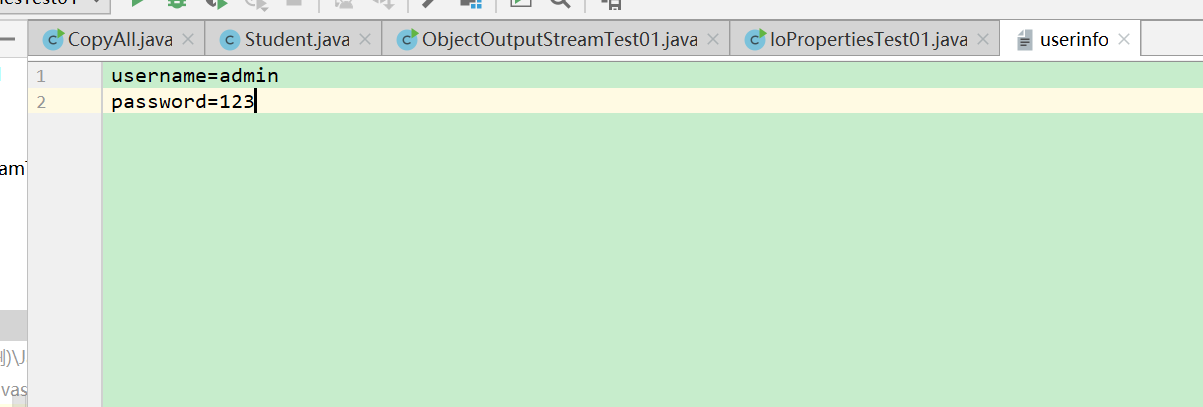
}IoPropertiesTest01 配置文件
package com.bjpowernode.java.io;import java.io.FileReader;
import java.util.Properties;/*
IO+Properties的联合应用。
非常好的一个设计理念:以后经常改变的数据,可以单独写到一个文件中,使用程序动态读取。将来只需要修改这个文件的内容,java代码不需要改动,不需要重新编译,服务器也不需要重启。就可以拿到动态的信息。类似于以上机制的这种文件被称为配置文件。并且当配置文件中的内容格式是:key1=valuekey2=value的时候,我们把这种配置文件叫做属性配置文件。java规范中有要求:属性配置文件建议以.properties结尾,但这不是必须的。这种以.properties结尾的文件在java中被称为:属性配置文件。其中Properties是专门存放属性配置文件内容的一个类。*/
public class IoPropertiesTest01 {public static void main(String[] args) throws Exception{/*Properties是一个Map集合,key和value都是String类型。想将userinfo文件中的数据加载到Properties对象当中。*/// 新建一个输入流对象FileReader reader = new FileReader("chapter23/userinfo.properties");// 新建一个Map集合Properties pro = new Properties();// 调用Properties对象的load方法将文件中的数据加载到Map集合中。pro.load(reader); // 文件中的数据顺着管道加载到Map集合中,其中等号=左边做key,右边做value// 通过key来获取value呢?String username = pro.getProperty("username");System.out.println(username);String password = pro.getProperty("password");System.out.println(password);String data = pro.getProperty("data");System.out.println(data);String usernamex = pro.getProperty("usernamex");System.out.println(usernamex);}
}
相关文章:
day31 IO流
文章目录回顾collectionArrayTestListHashSetTsetHashMapTestPropertiesTreeSetTestIO流FileInputStreamTest01 文件流初步FileInputStreamTest02 循环读FileStreamTest03FileInputStreamTes04 需要掌握FiLeInputStreamTest5FileOutputStreamTest01Copy1 文件拷贝FileReaderTes…...

Linux 防火墙配置(iptables和firewalld)
目录 防火墙基本概念 Iptables讲解 Iptables表 Iptables规则链 Iptables控制类型 Iptables命令配置 firewalld讲解 Firewalld区域概念 Firewalld两种配置方法 firewall-cmd命令行基础配置 firewall-config图形化配置 防火墙基本概念 防火墙就是根据系统管理员设定的…...
深度学习基础(一)
记得17年第一次阅读深度学习相关文献及代码觉得不是很顺畅,做客户端开发时间久了,思维惯性往往觉得比较迷茫。 而且文章中涉及的数学公式及各种符号又觉得很迷惑,虽然文章读下来了,代码也调试过了,意识里并没有轻松的…...

Maven 常用命令
mvn archetype: create :创建Maven 项目mvn compile :编译源代码。mvn deploy:发布项目。mvn test-compile :编译测试源代码mvn test:运行应用程序中的单元测试mvn site:生成项目相关信息的网站mvn clean:清除项目目录中的生成结果mvn package:根据项目生成的iar/war等mvn inst…...

2023年100道最新Android面试题,常见面试题及答案汇总
除了需要掌握牢固的专业技术之外,还需要刷更多的面试去在众多的面试者中杀出重围。小编特意整理了100道Android面试题,送给大家,希望大家都能顺利通过面试,拿下高薪。赶紧拿去吧~~文末有答案Q1.组件化和arouter原理Q2.自定义view&…...
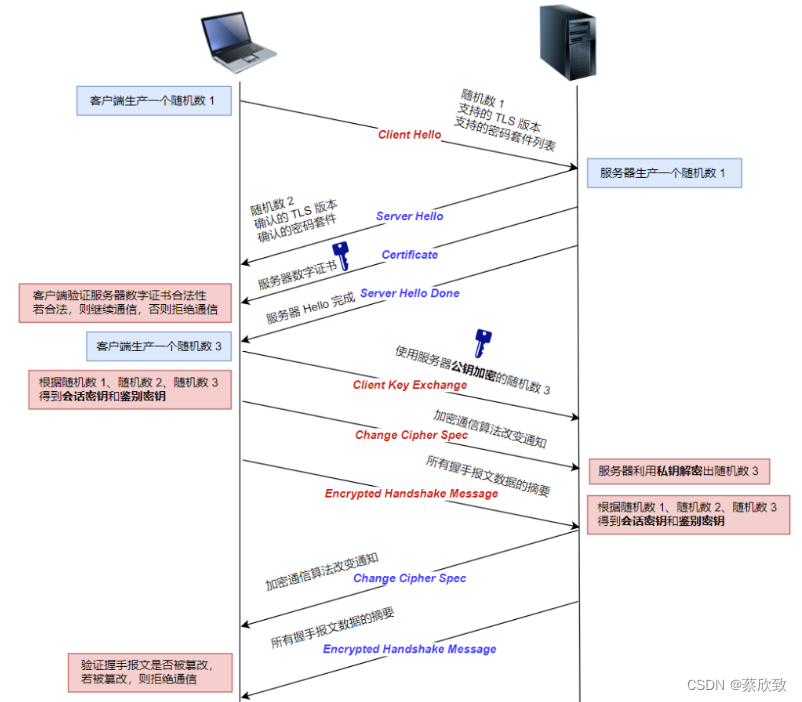
[JavaEE系列] 详解面试中HTTP协议HTTPS协议
文章目录HTTP不安全HTTPS中的加密算法对称加密非对称加密混合加密HTTPS中的摘要算法HTTPS中的数字证书SSL /TLS握手TCP建立连接(三次握手)三次握手中常见的面试题:TCP断开连接(四次挥手)四次挥手中常见的面试题&#x…...
mac 好用的类似Xshell工具
下载royal TSX 5.1.1 http://share.uleshi.com/f/9490615-685692355-33bf1e修改mac的etc/hosts文件权限访达(鼠标右键) -> 前往文件夹 ->输入/private --> 打开etc/hosts --> 显示简洁(鼠标右键) --> 权限改成读和写hosts文件写入如下内容:# Royal T…...

浅谈SQL中的union和union all
文章目录概念基础语法使用技巧区别总结概念 MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。 UNION 操作符选取不同的值,如果允许得到重复的值,可以使用 UNION ALL 基础语法 -- u…...

P6软件应用的核心收益
卷首语 提供了多用户、多项目的功能模块,支持多层次项目等级划分,资源分配计划,记录实际数据,自定义视图,并具有用户定义字段的扩展功能。 利用最佳实践,建立企业模板库 P6软件支持用户使用模板编制项目…...
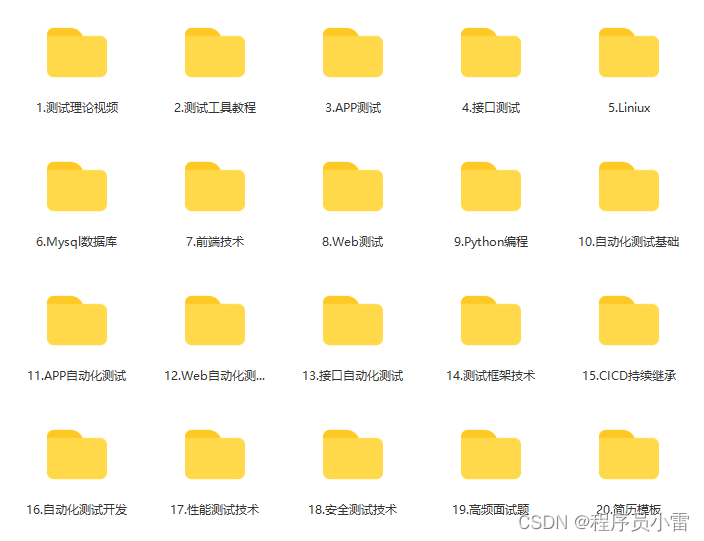
性能测试中,我遇到的8个常见问题总结
性能压测中我们需要明白以下几点: 1、好的开始是成功的一半,前期的准备非常重要; 2、过程中,关注每个细节,多个维度监控; 3、在调优中多积累经验; 4、对结果负责,测试报告要清晰…...
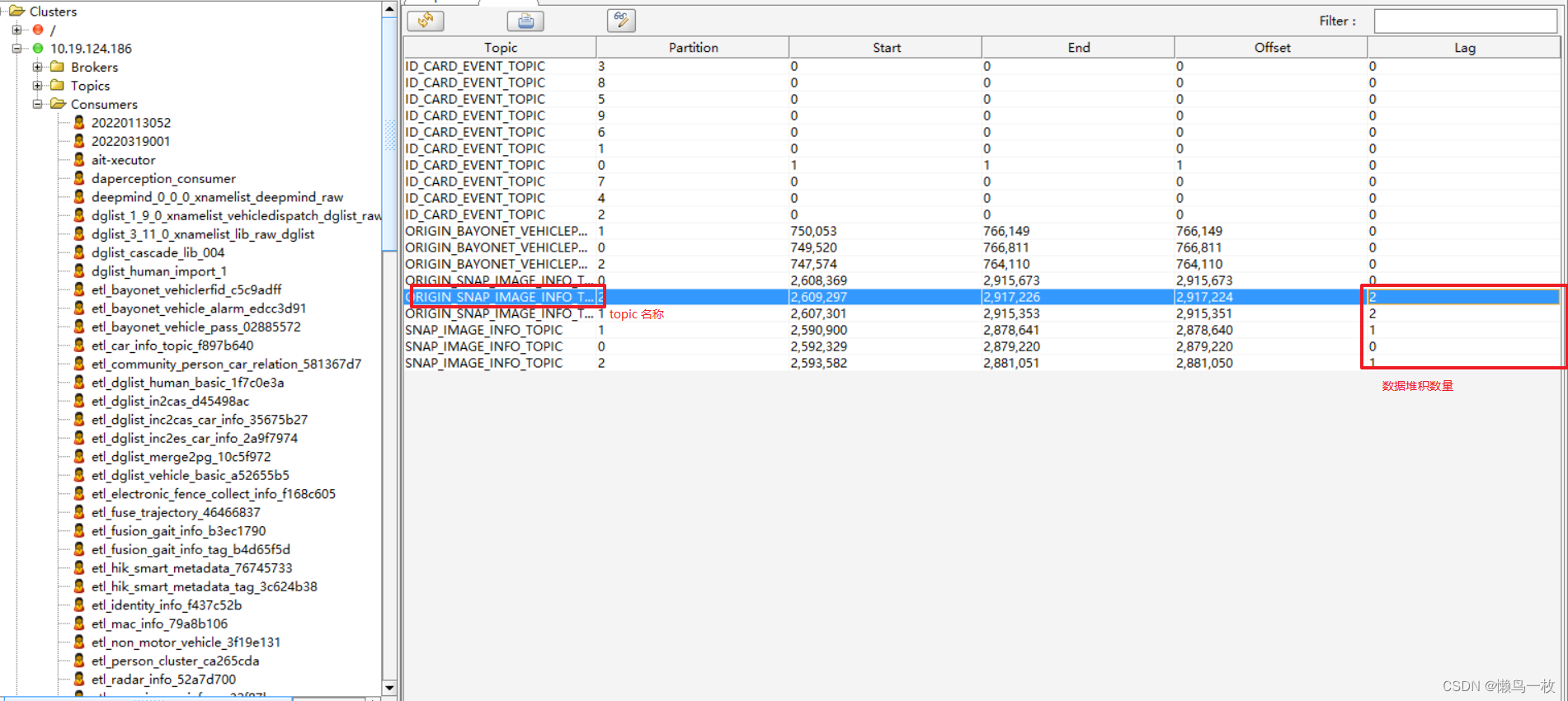
kafka架构体系
Kafka简介 Kafka是一个由Scala和Java编写的企业级的消息发布和订阅系统,最早是由Linkedin公司开发,最终开源到Apache软件基金会的项目。Kafka是一个分布式的,支持分区的,多副本的和多订阅者的高吞吐量的消息系统,被广…...
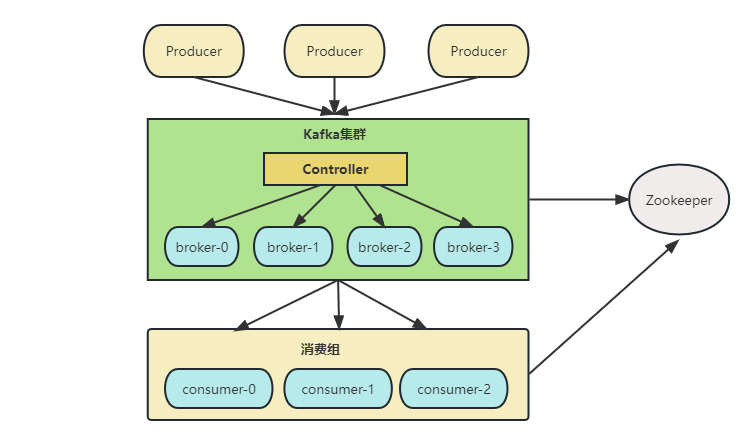
【Kafka】三.Kafka怎么保证高可用 学习总结
Kafka 的副本机制 Kafka 的高可用实现主要依赖副本机制。 Broker 和 Partition 的关系 在分析副本机制之前,先来看一下 Broker 和 Partition 之间的关系。Broker 在英文中是代理、经纪人的意思,对应到 Kafka 集群中,是一个 Kafka 服务器节…...

Python学习笔记7:再谈抽象
再谈抽象 对象 多态 即便你不知道变量指向的是哪种对象,也能够对其执行操作封装 向外部隐藏不必要的细节。继承 类 class Person: def set_name(self, name): self.name name def get_name(self): return self.name def greet(self): print("Hello, world…...

钣金行业mes解决方案,缩短产品在制周期
钣金加工行业具有多品种、小批量离散制造行业的典型特点。一些常见的下料车间、备料车间、冲压车间、冲剪生产线等。一般来说,核心业务是钣金加工的生产单位。 一般来说,与大规模生产相比,这种生产方式效率低、成本高,自动化难度…...

【Linux】——git和gdb的简单使用技巧
目录 1.\r&&\n 2.缓冲区 3.做一个Linux的小程序——进度条 1.makefile代码: 2.proc.h代码 3.proc.c代码 4.main.c代码 4.git(上传做好的小程序) 5.Linux调试器-gdb使用 1.\r&&\n 在Linux中,可以将\r看成…...

Fiddler的简单使用
目录 1.断点应用 2.网络限速测试 2.1.为什么需要弱网测试 2.2.Fiddler弱网测试配置 1.断点应用 通过断点功能,可以在测试时方便的篡改request,response以达到测试的目的,如果:在请求头中的参数修改成错误的,或在响应…...
MySql 事务
概述 事务 是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 注意: 默认MySQL的事务是自动提交的,也就是…...
微信社区小程序/h5/圈子论坛贴吧交友/博客/社交/陌生人社交/宠物/话题/私域/同城交友
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 小程序/app/H5多端圈子社区论坛系统,交友/博客/社交/陌生人社交,即时聊天,私域话题,社区论坛圈子,信息引流小程序源码,广场/微校园/微小区/微同城/ 圈子论坛社区系统,含完整…...
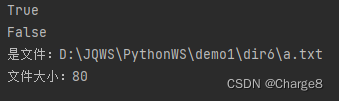
Python os和sys模块
一、os模块 os 模块是 Python中的一个内置模块,也是 Python中整理文件和目录最为常用的模块。 该模块提供了非常丰富的方法用来处理文件和目录。比如:显示当前目录下所有文件/删除某个文件/获取文件大小 1、获取当前的工作路径 在 Python 中࿰…...

JS中数组如何去重(ES6新增的Set集合类型)+经典two sum面试题
现在有这么一个重复数组:const arr [a,a,b,a,b,c]只推荐简单高效的方法,复杂繁琐的方法不做推荐方法一:const res [...new Set(arr)]Set类型是什么呢?Set 是ES6新增的一种新集合类型。具体知识点可以看下面附录:根据…...
)
Veo 2提示词效能跃迁实战(工业级Prompt链构建全图谱)
更多请点击: https://codechina.net 第一章:Veo 2提示词编写的核心范式演进 Veo 2作为新一代视频生成模型,其提示词(prompt)工程已从早期的“关键词堆叠”转向结构化、语义分层与意图对齐的复合范式。这一演进并非简…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

Simulink中Repeating Sequence锯齿波显示恒为0解决方案
锯齿波设置如图1时,其示波器显示恒为0(如图2)。图1图2于是新建模型,只添加Repeating Sequence模块,采用原始设置发现可以正常输出锯齿波,于是调整时间参数,发现当时间设置为≥[0 0.06]时可以正常…...

腾讯 Marvis 初级使用教程——从安装到上手
腾讯最新系统级AI助手Marvis(2026年5月20日发布),官网 https://marvis.qq.com,主打“一句话操作电脑”、跨端协同、GUI Agent执行。虽然是个【小龙虾】,但上手其实不难。这篇就简单写写 Marvis 的安装和基础使用&#…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

正视孩童情绪波动,耐心陪伴平稳疏导
孩子的情绪就像夏天的天气,前一秒还晴空万里,后一秒可能就乌云密布。面对突如其来的哭闹、发脾气或者闷闷不乐,很多家长会急着“灭火”——要么讲道理,要么直接制止。但其实,情绪波动本身不是问题,它是孩子…...

基于晶体管逻辑的水箱自动控制器设计与实现
1. 项目概述:一个基于晶体管逻辑的自动水箱/湿度灌溉控制器 如果你也像我一样,曾经为家里的花园、阳台植物或者农村老家的储水塔手动开关水泵而烦恼,那么这个项目就是为你准备的。我设计并制作了一个完全自动化的水箱水位控制器,它…...

昇腾CANN elec-ops-simulation 实战:电力系统仿真——潮流计算与暂态稳定分析在 NPU 上的加速
电力系统仿真:500 节点电网的牛顿-拉夫逊潮流计算 → 解 10001000 稀疏雅可比矩阵(每迭代 1 次矩阵求逆)→ CPU 迭代 15 次 2.4s。实时调度要求 < 100ms → NPU 加速:雅可比矩阵求解用 Cube 单元做批量小矩阵 LU 分解 → 每迭…...

如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南
如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重新焕发活力&a…...