NLP(1)--NLP基础与自注意力机制
目录
一、词向量
1、概述
2、向量表示
二、词向量离散表示
1、one-hot
2、Bag of words
3、TF-IDF表示
4、Bi-gram和N-gram
三、词向量分布式表示
1、Skip-Gram表示
2、CBOW表示
四、RNN
五、Seq2Seq
六、自注意力机制
1、注意力机制和自注意力机制
2、单个输出
3、矩阵计算
4、multi-head self-attention
5、positional encoding
一、词向量
1、概述
在自然语言处理中,用词向量表示一个词,将词映射为向量的形式。
词向量:又叫Word嵌入式自然语言处理中的一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。
2、向量表示
词向量可以有两种表示方法:dispersed representation和distribution representation
dispersed representation:离散表示,一般使用one-hot独热编码。
distribution representation:分布式表示,词嵌入就是分布式表示的形式,可以将一个词通过嵌入空间(embedding)映射为一个定长,稠密且存在语义关系的高维向量,这样可以保证语义接近的词之间的向量相似度较高。
二、词向量离散表示
1、one-hot
one-hot:就是独热编码,将一句话中的每个词都对应一个独热编码,如“我爱学习人工智能”,编码后为:
“我”:[1,0,0,0]
“爱”:[0,1,0,0]
“学习”:[0,0,1,0]
“人工智能”:[0,0,0,1]
独热编码存在问题:缺少词与词之间的关系,由于单词量巨大而产生的维度爆炸和词向量稀疏。
2、Bag of words
将每个单词在语料库中出现的次数加到one-hot编码中。
存在问题:仍没有解决词与词之间关系问题和维度爆炸问题,单词顺序也没有考虑。
3、TF-IDF表示
将罕见的单词加上高权重,常见的加上低权重,其实跟上面一种方法类似。
上述公式中,N为文档总数,表示词t的文档数。
存在问题:同上
4、Bi-gram和N-gram
将两个单词再次组成单词表,或多个单词组成单词表。
存在问题:仍没有解决词义关系问题。
三、词向量分布式表示
一般以Word2Vec作为分布式表示的示例。
Word2Vec:从大量文本中以无监督学习方式训练语义知识的模型,通过学习文本来用词向量的方式表征词的语义信息,也就是在嵌入空间中两个词的空间距离近,则相似度更高。
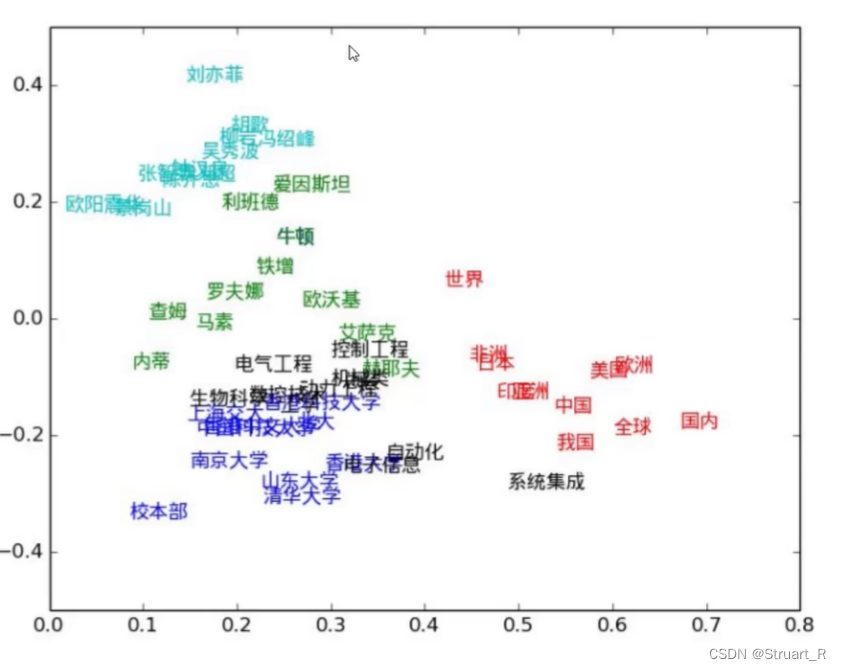
1、Skip-Gram表示
通过中心词预测上下文词,在中心词已知情况下,预测上下文词出现概率
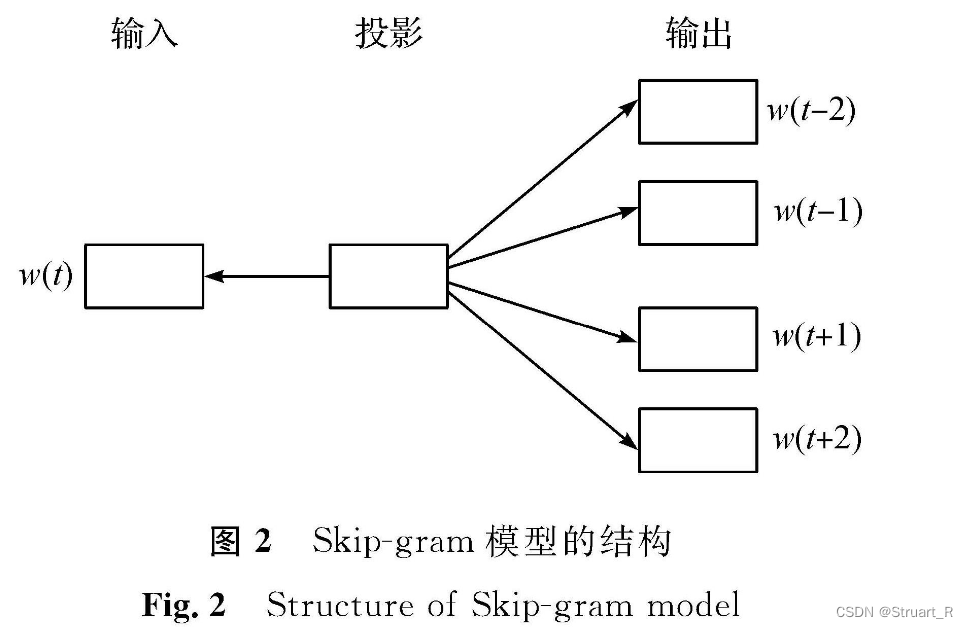
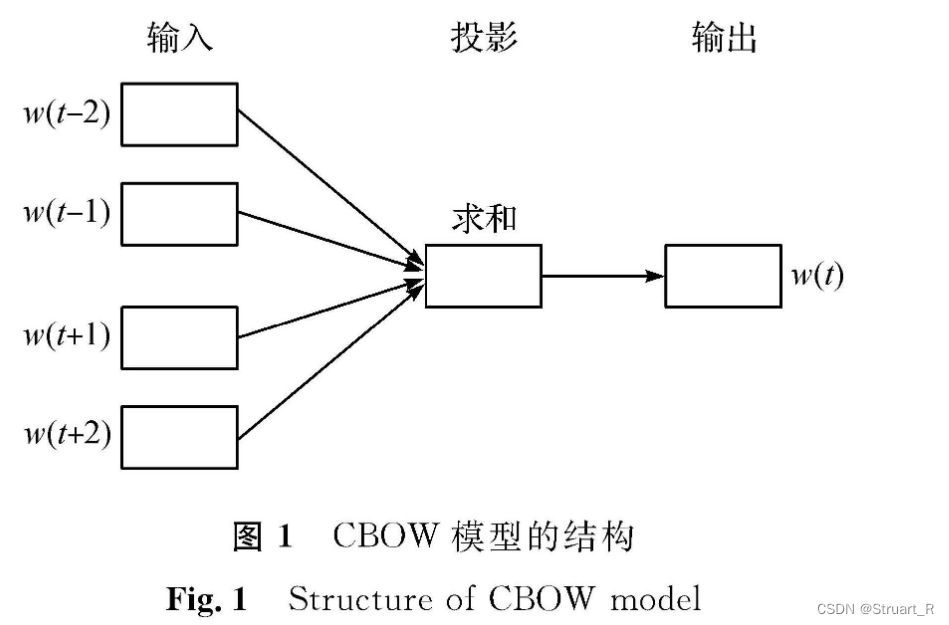
2、CBOW表示
通过上下文词,推理中心词,预测中心词出现的概率。在具体实现中,会使用滑动窗口的方式,读取上下文的词,来计算输出的中心词的极大似然值,训练输出词与真实中心词的相关性,利用梯度下降来进行迭代训练。
四、RNN
RNN:循环神经网络,指在全连接神经网络的基础上增加了前后时序上的关系。RNN的目的是用来处理序列数据,通过在网络中引入循环连接,使得RNN可以记忆之前的信息,并用于当前的输入。
RNN结构:输入层+隐藏层+输出层。RNN结构中的隐藏层,会在每个时间点进行更新,作为网络对序列数据的内部表示,也会收到当前输入和之前隐藏层的影响。
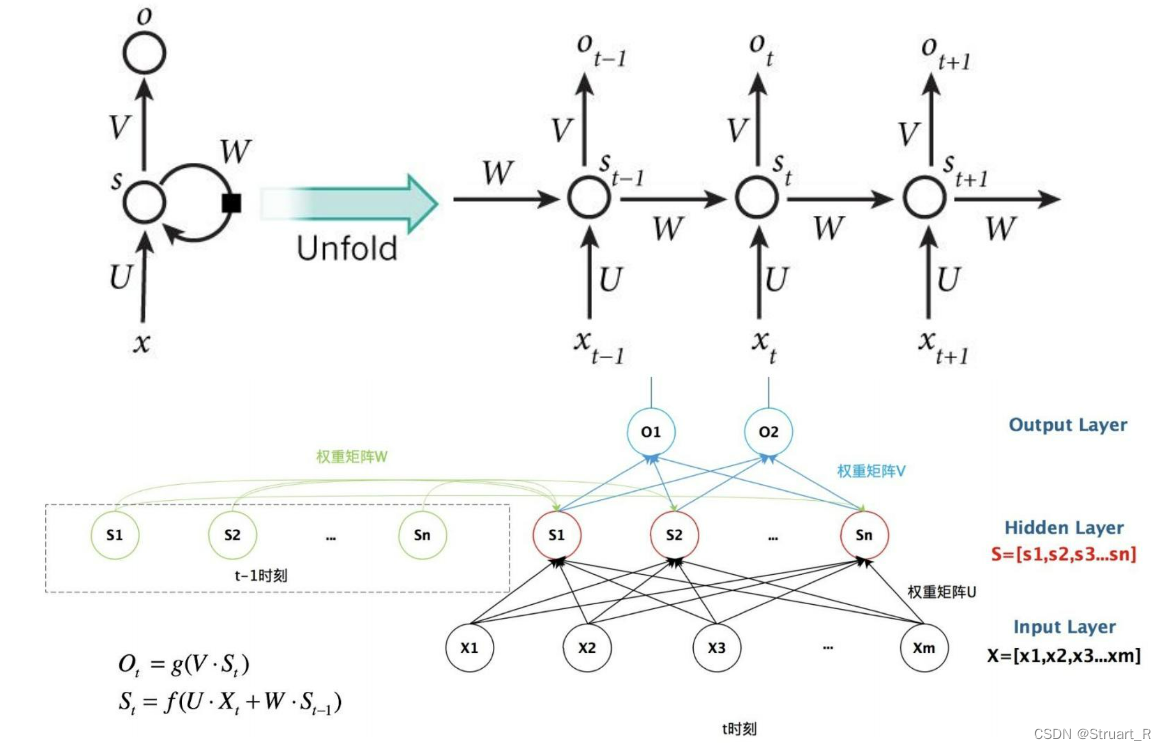
RNN的优点:适用于处理序列数据,具有记忆能力,可以处理变长序列数据。
RNN的缺点:处理长期依赖性问题时,容易产生梯度消失或梯度爆炸问题。由于每个时间点都要进行计算隐藏层和输出,计算效率过低,在长序列数据中会面临资源爆炸问题。
如何解决梯度消失:合理的初始化权重,保证避免梯度消失(有点好笑了),使用ReLU函数作为激活函数,使用LSTM等新型结构。
五、Seq2Seq
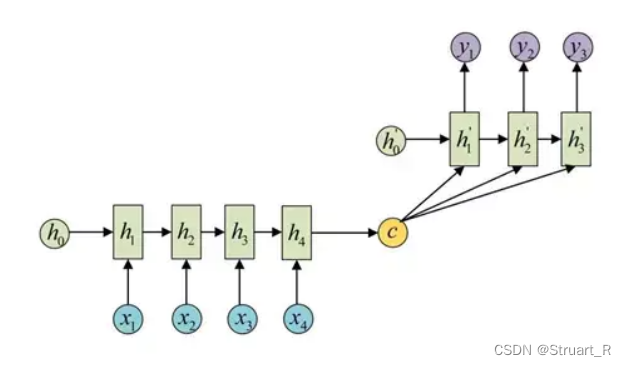
Seq2Seq:序列到序列模型,根据给定的序列,通过特定的生成方法生成另一个序列的方法,这两个序列可以不等长。这种结构又叫做Encoder-Decoder模型(编码-解码模型),也可以称为RNN的一个变种,解决了RNN序列等长的问题。
Seq2Seq由三部分构成,Encoder编码器,语义编码c,Decoder解码器构成,编码器通过学习将输入序列编码成一个固定大小的向量c,解码器通过对c的学习进行输出。一般来说编码器和解码器都会代表一个RNN,如LSTM或GRU。(也有一般的RNN模型)
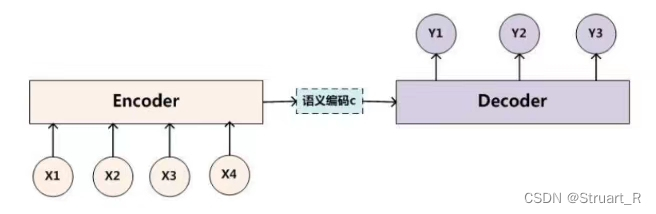
另外另一种方式下,语义编码c将参加解码的每一个过程,而不是只作为初始化参数。
六、自注意力机制
1、注意力机制和自注意力机制
传统注意力机制发生在Target元素和Source元素的所有元素中,权重的计算需要Target来参与。
自注意力机制存在于输入语句内部元素之间或者输出语句内部元素之间,计算权重时也不需要Target来参与。
2、单个输出
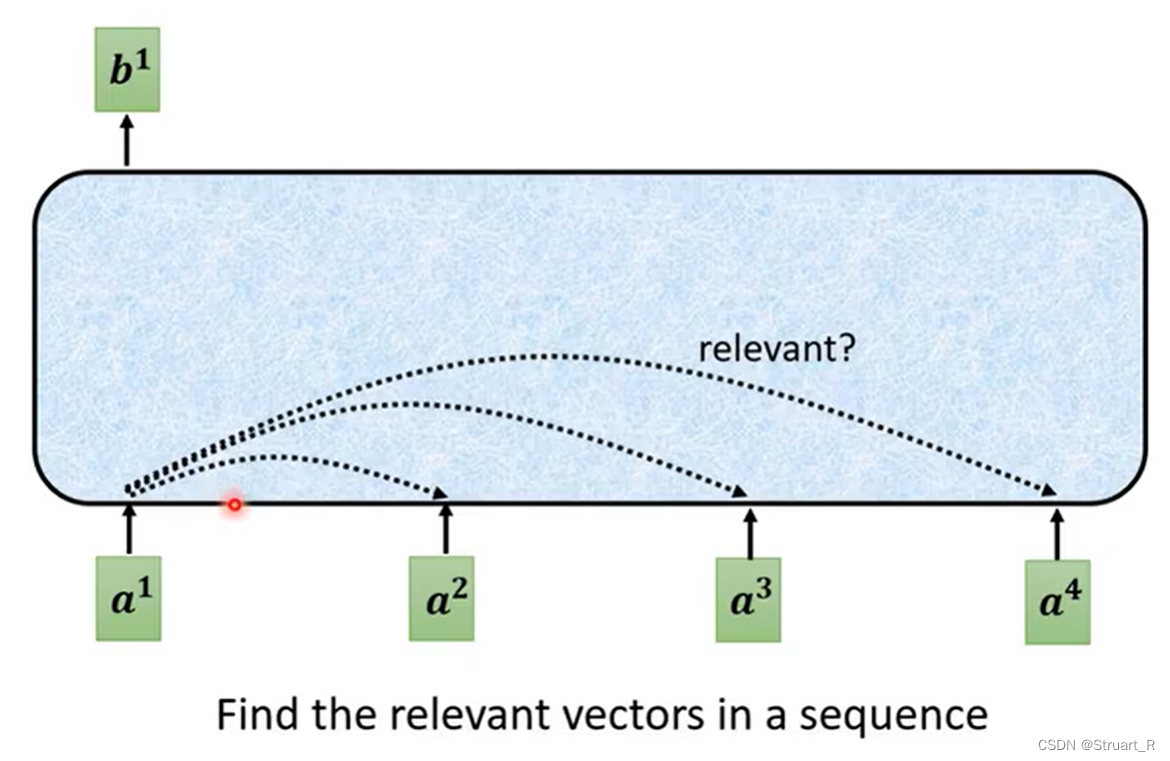
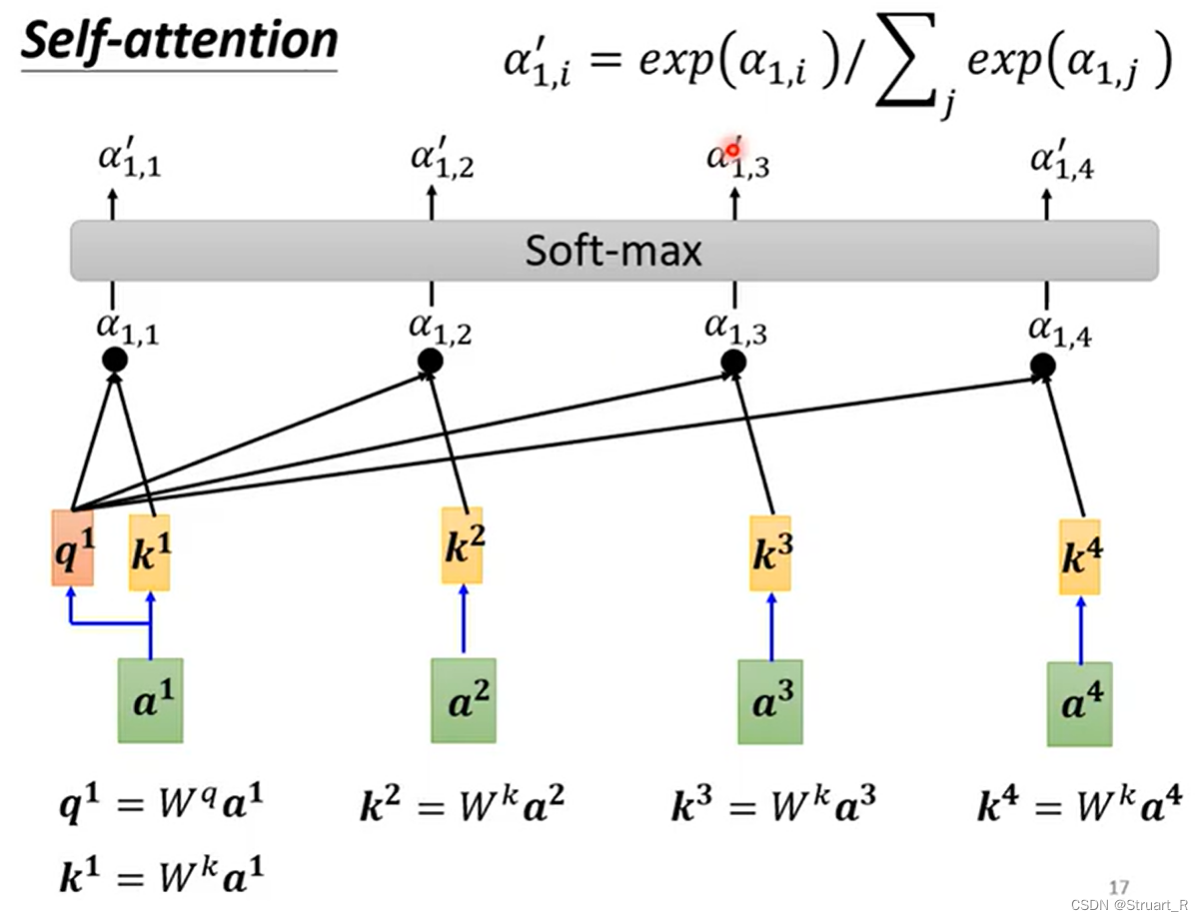
对于每一个输入向量a1,经过self-attention后都会输出一个向量b1,而这个b1是考虑了所有的输入向量a1,a2,...对a1产生的作用才得到的。首先我们将计算两个输入向量之间的α也就是相关性。
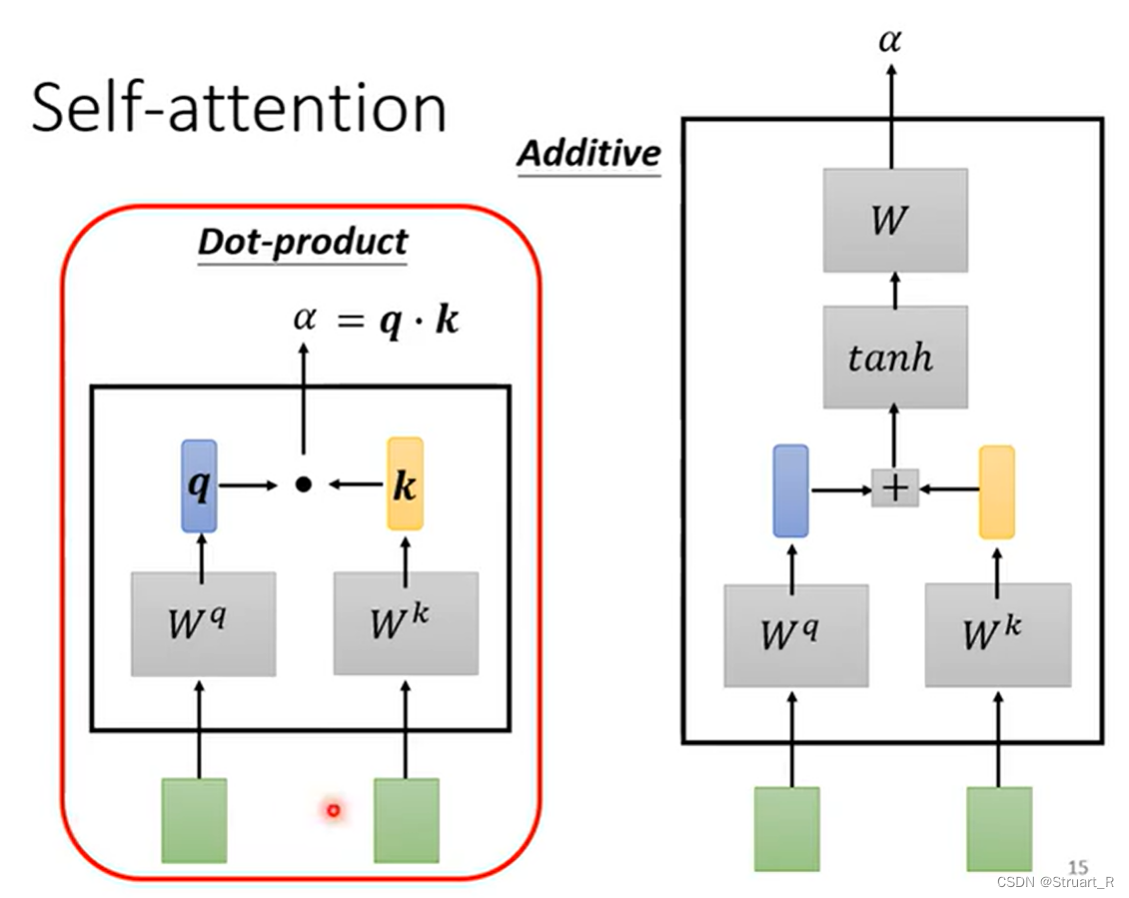
下图中两个绿框,可以代表任意两个输入,比如a1和a2,左侧方法为,a1经过一个矩阵得到q(乘积运算),a2经过一个
矩阵得到k(乘积运算),将q和k做内积运算得到
,也就是图中的α。右侧方法为,a1经过一个
矩阵得到q,a2经过一个
矩阵得到k,将q和k做concat运算后投射到tanh激活函数,在与W矩阵(权重矩阵)做一次乘积得到
。
接下来的操作计算每一个相关性α,下图中为,
,
,
。
几个注意点:都是超参数,是输入进去的,通过与不同的a进行乘积运算得到的
也是不同的。
将,
,
,
放入softmax中进行归一化处理,获得
,
,
,
,softmax的数学公式如下图右上角。
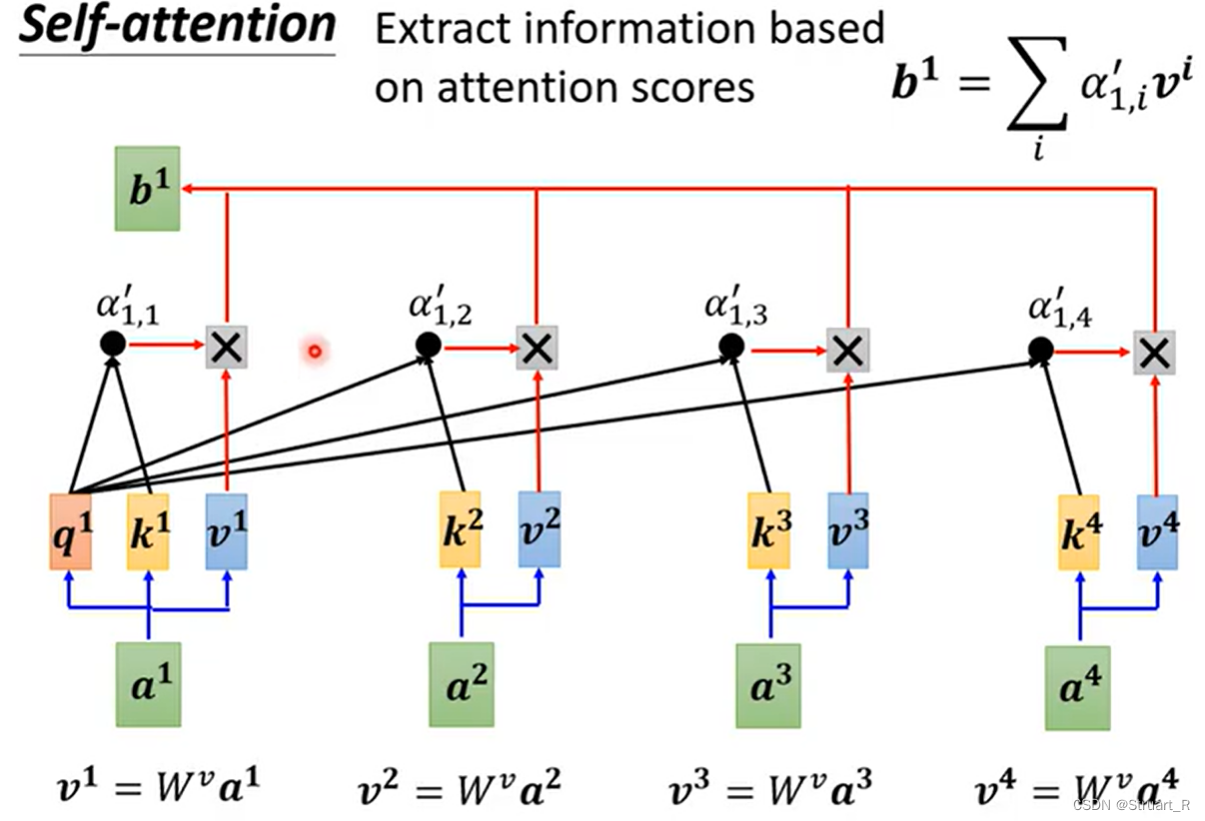
最后将每一个乘以矩阵
得到
,
再与α进行相乘,将每一个相乘后的值相加求和,得到输出的b。b的计算公式如下图的右上角。
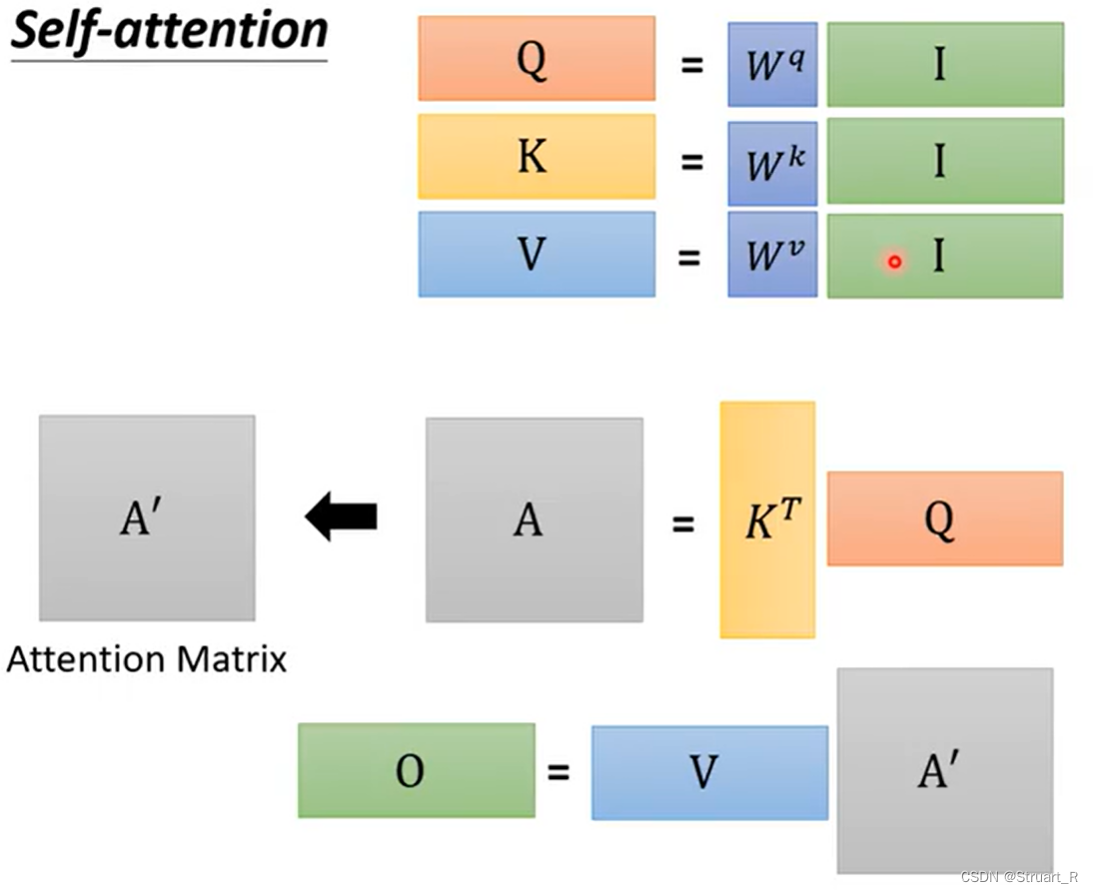
3、矩阵计算
首先可以将一个序列sequence的每一个a都进行concat这样形成了一个矩阵I,分别与进行矩阵乘法,就可以得到相应的q,k,v。
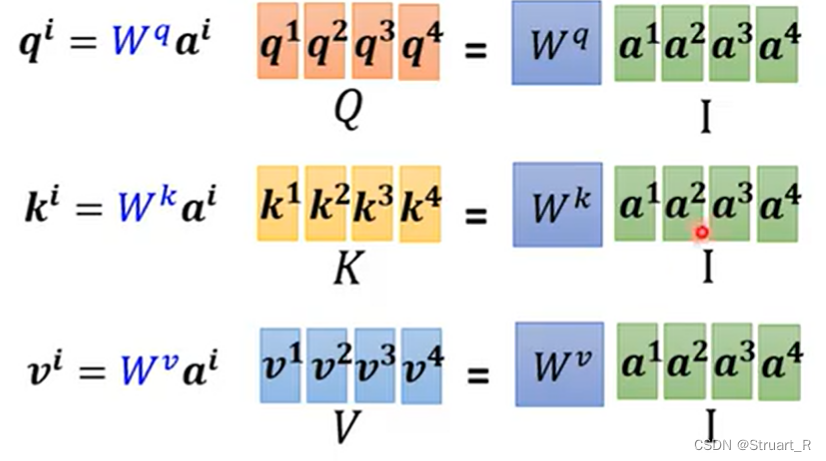
再将生成的每一个q和每一个k分别在x轴和y轴进行concat,形成Q和(K的转置),
与Q进行矩阵乘法,就得到了A(也就是所有α所构成的二维矩阵),经过softmax就得到了A'(α'所构成的二维矩阵)

第三步,将每一个v进行concat操作得到V,将V与A'做矩阵乘法,就得到了O(b进行concat构成的矩阵)
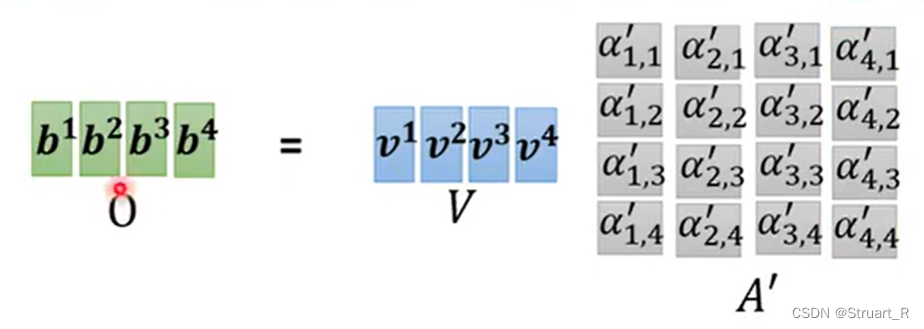
整体来看,就是下图这样的一个矩阵运算操作。
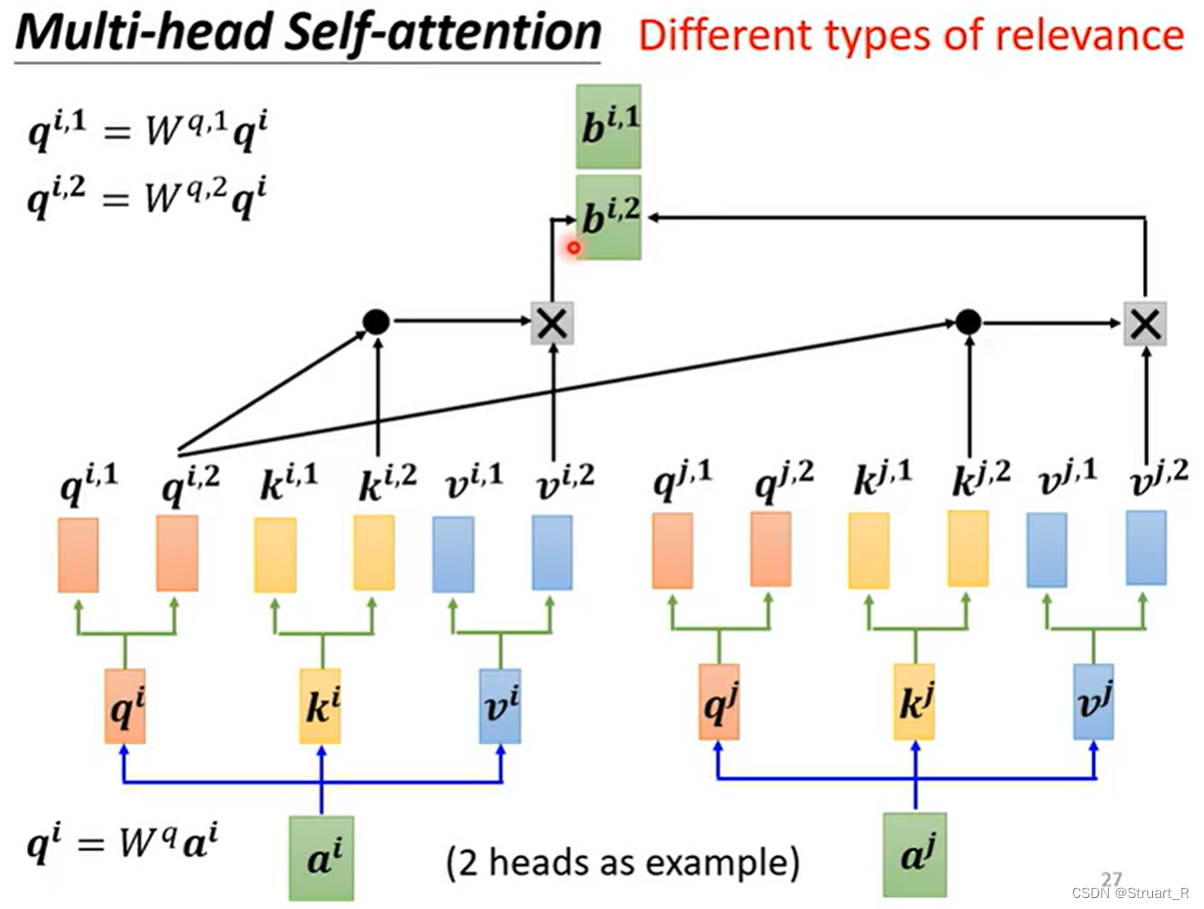
4、multi-head self-attention
多头自注意力机制,由于相关性可能有不同的形式,有不同的定义,所以可以有多个q,k,v来表示多种类型的相关性,也就是在超参数中存在
,
,...。对应的k,v也有多个。
计算每一个的方式如下,最后需要对多个
进行y轴方向的concat,也就是
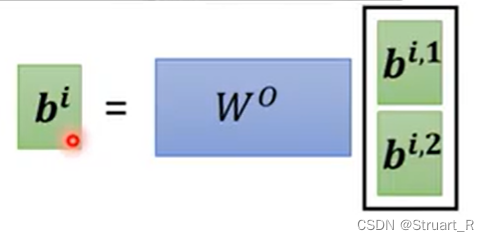
,将
乘上权重矩阵W,得到
5、positional encoding
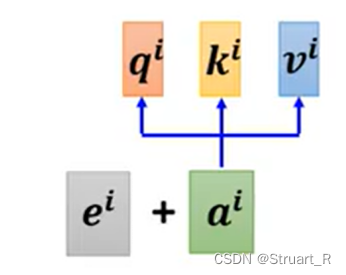
对于训练self-attention时,存在位置信息缺失的问题,位置信息引入到训练数据中,所以我们可以在Self-attention中加入位置信息。
通过设置一个新的positional vector,用表示,对于不同的
处都有一个
体现位置信息,vector的长度时人为规定,也可以通过大量数据训练出适合数据的vector。
参考视频:
37.39、 自注意力机制P37_哔哩哔哩_bilibili
3-注意力机制的作用_哔哩哔哩_bilibili
相关文章:
NLP(1)--NLP基础与自注意力机制
目录 一、词向量 1、概述 2、向量表示 二、词向量离散表示 1、one-hot 2、Bag of words 3、TF-IDF表示 4、Bi-gram和N-gram 三、词向量分布式表示 1、Skip-Gram表示 2、CBOW表示 四、RNN 五、Seq2Seq 六、自注意力机制 1、注意力机制和自注意力机制 2、单个输出…...

Ubuntu 升级cuda版本与切换
下载cuda版本 进:CUDA Toolkit 12.2 Downloads | NVIDIA Developer wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.runsudo sh ./cuda_12.2.0_535.54.03_linux.run --toolkit --silent --overrid…...

精讲算法的时间复杂度
目录 一、算法效率 1.算法效率 1.1如何衡量一个算法的好坏 1.2算法的复杂度 二、时间复杂度 1.时间复杂度的概念 2.大O的渐进表示法 3.常见时间复杂度的计算举例 三、空间复杂度 一、算法效率 1.算法效率 1.1如何衡量一个算法的好坏 long long Fib(int N) {if(N <…...
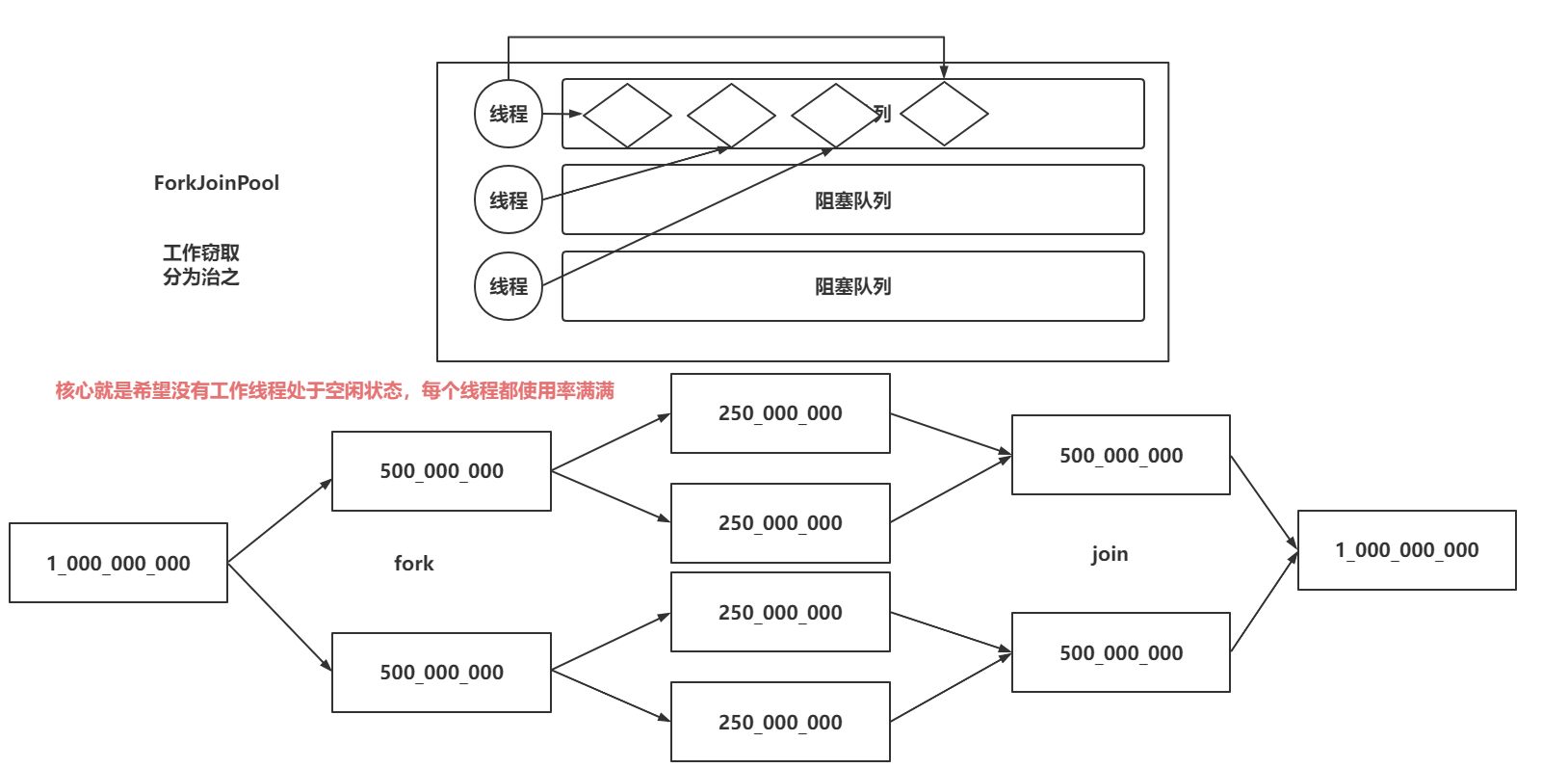
java八股文面试[多线程]——newWorkStealingPool
newWorkStealingPool是什么? newWorkStealingPool简单翻译是任务窃取线程池。 newWorkStealingPool 是Java8添加的线程池。和别的4种不同,它用的是ForkJoinPool。 使用ForkJoinPool的好处是,把1个任务拆分成多个“小任务”,把这…...

STM32--RTC实时时钟
文章目录 Unix时间戳时间戳转换BKPRTC简介RTC框图硬件电路RTC的注意事项RTC时钟实验工程 Unix时间戳 Unix 时间戳是从1970年1月1日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒。 时间戳存储在一个秒计数器中,秒计数器为32位/64…...

【N2】例题学习笔记
N2例题 《新"日本语能力测试"例题集》 听力原稿(PDF) 【10】 【問い】この筆者から見た「仕事ができる人」の特徴はどんなことか。 【提问】这位作者认为,仕事能力强的人具有什么特点呢? 【11】 文章 下の文章は、企業のあり方について…...

【数据分享】2006-2021年我国城市级别的道路、桥梁、管线建设相关指标(10多项指标)
《中国城市建设统计年鉴》中细致地统计了我国城市市政公用设施建设与发展情况,在之前的文章中,我们分享过基于2006-2021年《中国城市建设统计年鉴》整理的2006—2021年我国城市级别的市政设施水平相关指标、2006-2021年我国城市级别的各类建设用地面积数…...

视觉SLAM14讲笔记-第7讲-视觉里程计2
直接法的引出 直接法是视觉里程计另一个主要分支,它与特征点法有很大的不同。 使用特征点法估计相机运动时,我们把特征点看作固定在三维空间的不动点。根据它们在相机中的投影位置,通过最小化重投影误差来优化相机运动。 相对地,…...

MySQL——单行函数和分组函数
2023.9.3 单行函数的SQL语句学习笔记如下: #常见单行函数介绍(部分省略) #字符函数 #将姓变大写,名变小写,然后拼接。 SELECT CONCAT(UPPER(last_name), ,LOWER(first_name)) AS 姓名 FROM employees; # 姓名中首字符…...

百度百科词条怎么更新?怎么能顺利更新百科词条?
企业和个人百度百科词条的更新对于他们来说都具有重要的意义,具体如下: 对企业来说: 塑造品牌形象:百度百科是一个常被用户信任并参考的知识平台,通过更新企业词条可以提供准确、全面的企业信息,帮助企业塑…...

PPT怎么转换为PDF格式,收藏这两个在线工具。
PPT是一种常用的演示文稿格式,它可以包含丰富的动画效果和超链接,让你的内容更加生动和有趣。但是,如果你想将PPT分享给别人,或者在不同的设备上查看,你可能会遇到一些问题,比如: PPT文件太大&a…...

八大排序算法----堆排序
堆排序的基本步骤:(以从大到小的顺序排序为例) 1.构建大顶堆(每个结点的值都大于或等于其左右孩子结点的值) 2.排序:每次堆顶的元素取出来(整个堆中值最大),与最后一个…...
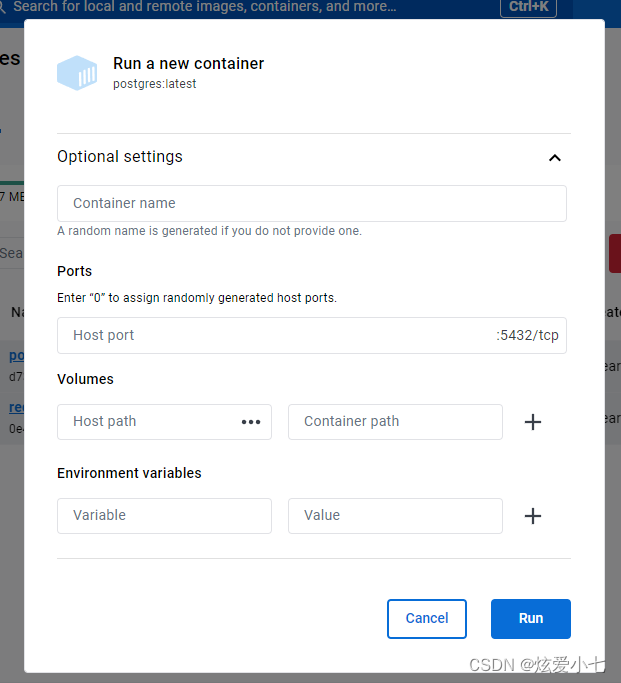
Docker Desktop 设置镜像环境变量
点击run 展开Optional settings container name :容器名称 Ports:根据你需要的端口进行输入,不输入则默认 后面这个 比如我这个 5432 Volumes:卷,也就是做持久化 需要docker 数据保存的地方 Environment variables…...
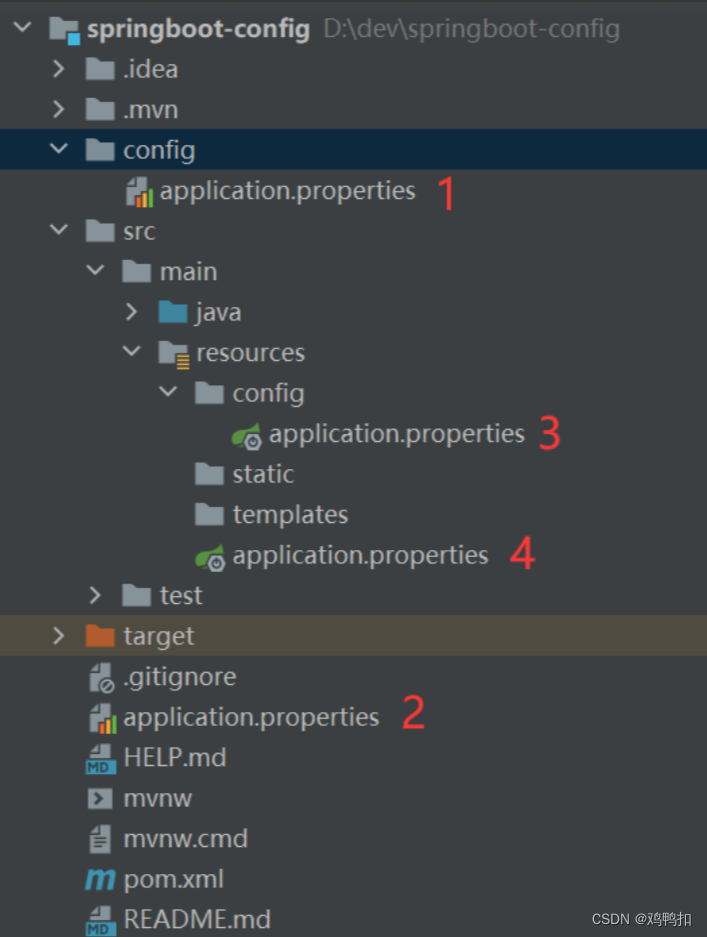
springboot之一:配置文件(内外部配置优先顺序+properties、xml、yaml基础语法+profile动态切换配置、激活方式)
配置的概念: Spring Boot是基于约定的,所以很多配置都有默认值,但如果想使用自己的配置替换默认配置的话,就可以使用application.properties或者application.yml(application.yaml)进行配置。 注意配置文件的命名必须是applicat…...

涛然自得周刊(第 5 期):蝲蛄吟唱的地方
作者:何一涛 日期:2023 年 8 月 20 日 涛然自得周刊主要精选作者阅读过的书影音内容,不定期发。历史周刊内容可以看这里。 电影 《沼泽深处的女孩》 改编自小说《蝲蛄吟唱的地方》,主角是一位在沼泽地独自生活并长大的女孩&…...

Android Ble蓝牙App(七)扫描过滤
Ble蓝牙App(七)扫描过滤 前言目录正文一、增加菜单二、使用MMKV① 添加依赖② 封装MMKV③ 使用MMKV 三、过滤空设备名四、过滤Mac地址五、过滤RSSI六、源码 前言 在上一篇文章中了解了MTU的相关知识以及对于设备操作信息的展示,本篇文章中将增…...

小程序当前页面栈以及跳转
1.调用页面栈刷新接口 let pages getCurrentPages(); //当前页面栈 if (pages.length > 1) { let beforePage pages[pages.length - 2]; //获取上一个页面实例对象 beforePage.$vm.getActivityLi…...
)
jQuery获取表单的值val()
(1)页面中有很多元素,包括表单中的输入项,如输入文本框等;获取、设置、输入文本框的值;val()方法。 (2)也包括<p>、<span>等元素;获取、设置这些元素的文本…...

【专栏必读】数字图像处理(MATLAB+Python)专栏目录导航及学习说明
文章目录 第一章:绪论第二章:数字图像处理基础第三章:图像基本运算第四章:图像的正交变换第五章:图像增强第六章:图像平滑第七章:图像锐化第八章:图像复原第九章:图像形态…...

2023年非证券类投资银行业发展报告
第一章 行业概况 非证券投资银行业是一个专门为公司、政府和高净值个人提供金融服务的行业,与传统的证券投资银行不同,其主要业务不涉及证券交易,而是注重为客户提供咨询服务、融资和投资管理等服务。 非证券投资银行通常涉及的业务领域包括…...

通用运放设计挑战:扫地机器人传感器信号调理实战解析
1. 项目概述:当扫地机器人遇上通用放大器最近在帮一个做智能硬件的朋友优化他们新一代扫地机器人的主控板,聊到传感器信号调理这块,他跟我大倒苦水。他说,现在的扫地机为了更“聪明”,身上集成的传感器越来越多&#x…...

STM32CubeMX实战:5分钟搞定MAX31865 PT100测温,从SPI配置到温度读取全流程
STM32CubeMX实战:5分钟搞定MAX31865 PT100测温,从SPI配置到温度读取全流程 在工业测温领域,PT100凭借其优异的线性度和稳定性成为温度测量的黄金标准。而MAX31865作为专为RTD传感器设计的信号调理器,极大简化了前端电路设计。本文…...

30天试用期重置神器:JetBrains IDE免费使用终极解决方案
30天试用期重置神器:JetBrains IDE免费使用终极解决方案 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 还在为JetBrains IDE试用期到期而烦恼吗?每次30天试用结束后,那些强大的…...

ITK-SNAP医学图像分割:精准医疗影像分析的利器
ITK-SNAP医学图像分割:精准医疗影像分析的利器 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 面对复杂的医学影像数据,如何快速准确地进行三维解剖结构分割ÿ…...
)
烟草叶部病害-目标检测数据集(包括VOC格式、YOLO格式)
烟草叶部病害-目标检测数据集(包括VOC格式、YOLO格式) 数据集(文章最后关注公众号获取数据集): 链接: https://pan.baidu.com/s/1-4LCiMULEf7OT9JHzL38BQ?pwdytbu 提取码: ytbu 数据集信息介绍: 共有 156…...

如何在Windows电脑上安装安卓应用:APK Installer完整使用指南
如何在Windows电脑上安装安卓应用:APK Installer完整使用指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接运行安卓应用吗&#x…...

Mac用户必看:彻底解决NTFS读写难题的终极免费方案
Mac用户必看:彻底解决NTFS读写难题的终极免费方案 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management for NT…...

原神玩家信息查询完整指南:如何快速掌握账号详情
原神玩家信息查询完整指南:如何快速掌握账号详情 【免费下载链接】GenshinPlayerQuery 根据原神uid查询玩家信息(基础数据、角色&装备、深境螺旋战绩等) 项目地址: https://gitcode.com/gh_mirrors/ge/GenshinPlayerQuery 还在为无法全面了解自己的原神账…...
)
别再乱写Flash了!W25Q128JV SPI Flash寿命管理与日志记录实战(附STM32代码)
W25Q128JV SPI Flash寿命优化与高可靠日志系统设计实战 在嵌入式设备开发中,数据持久化存储是确保设备可靠运行的关键环节。W25Q128JV作为128Mbit容量的SPI Flash存储器,凭借其高性价比和易用性,成为众多嵌入式项目的首选。然而,许…...

别再只当扫码枪用了!用Python+GM861S模块,DIY一个智能物料盘点小工具
用PythonGM861S模块打造智能物料盘点系统 在仓库管理和生产制造场景中,物料盘点是项耗时又容易出错的工作。传统扫码枪往往只作为简单数据采集工具,而结合Python编程能力,我们可以将GM861S这类高性能扫码模块升级为智能终端。这个项目将展示如…...