保留网络[02/3]:大型语言模型转换器的继任者”
一、说明
二、关于RetNet的开源处
保留网络(RetNet)具有与相同大小的转换器相当的性能,可以并行训练,但支持递归模式,允许每个令牌的O(1)推理复杂性。
非官方但完整的实现可以在下面的我的回购中找到:
GitHub - syncdoth/RetNet:RetNet 的完整实现(Retentive Networks...
RetNet(保留网络,https://arxiv.org/pdf/2307.08621.pdf)的完整实现,包括并行...
github.com
三、生成序列模型的“不可能三角”

对于序列模型,尤其是生成模型,我们有上述三个特点:快速推理、并行训练和强大的性能。(在我看来,还有一个维度:序列长度外推。RetNet 可能支持这一点,但没有明确的实验。
RNN 具有快速推理但训练缓慢,线性变压器的性能较弱,变压器每个令牌推理具有 O(n)。RetNet满足所有三个条件: 并行训练、O(1) 推理和节拍变压器。
四、快速历史记录
有多种方法可以减轻生成变压器的昂贵推理。著名的作品包括Linear Transformers,Attention-Free Transformers(AFT;来自Apple)和RWKV(来自BlinkDL,基于AFT)。
这些值得单独发布,所以我不会详细介绍:但在我看来,它们在数学上都非常优雅,尤其是 RNN 如何并行化的推导。而我发现 RetNet 更有趣,因为它也有块表示和一些漂亮的技巧,如 xpos。
五、那么这是如何工作的呢?
RetNet 是在同一 Transformer 架构中将“注意力”替换为“保留”的即插即用替代。
我将以自上而下的方式介绍它们。
5.1. 每个 RetNet 块
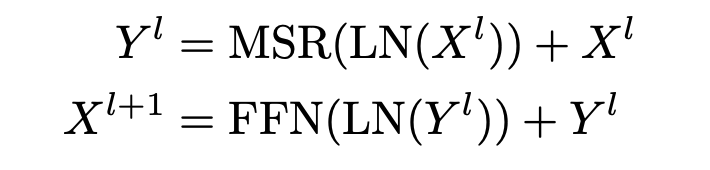
每个 RetNet 块的公式。
在最高级别,RetNet 由几个相同的块堆栈组成,每个堆栈都包含 MultiScaleRetention (MSR) 和 FeedForwardNetwork (FFN)。它们还具有层规范和跳过连接,与变形金刚相同。FFN也几乎与变形金刚相同,后者是2层MLP,隐藏的暗光尺寸= 2倍嵌入尺寸,并具有gelu激活功能。
如果我们用MultiHeadAttention代替MSR,这只是Transformer。因此,所有差异都可以在MSR中找到。
5.2. 门控多尺度保留
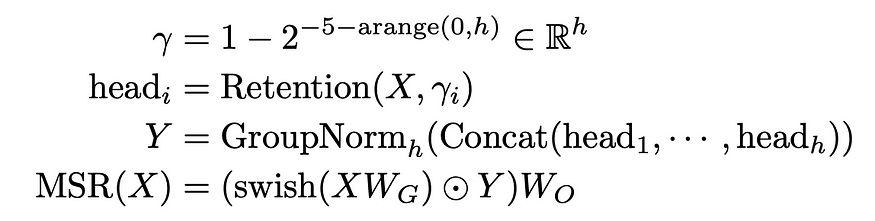
多尺度类似于多头。在上面的等式中,γ是一些用于保留的超参数,这是为每个头部单独定义的。在群体规范之前,这是普通的多头关注,但保留。
门控MSR在输出端增加了组范数、旋门和输出投影,可视为辅助设计选择。(组规范允许缩放点积,但目前并不那么重要。 最重要的区别(保留模块)尚未到来。
5.3. 保留
最后,让我们看看什么是保留。保留有 3 种范式:并行、循环和块递归。让我们一一看一下。
并行保留

保留的并行表示
专注于最后一行。忽略 D,再次,这是没有 softmax 的点积关注。所以重要的细节又在D和Theta中。
- Theta(和bar(Theta),复共轭)是“xpos编码”的复杂表示 - 它建立在旋转嵌入的基础上,以便模型可以更好地推断序列长度。在非复杂空间中存在相同的表示,这正是基于 RoPE 构建的 xpos。
请参阅 xpos 白皮书。我还发现这篇讲义有助于理解这一点。
- D是因果掩蔽+衰变矩阵。
如果绘制 D,则 D 如下所示:
gamma = 0.9
exponent = [[0, 0, 0, 0],[1, 0, 0, 0],[2, 1, 0, 0],[3, 2, 1, 0]]D = tril(gamma**exponent)
# [[1., 0., 0., 0.],
# [0.9000, 1., 0., 0.],
# [0.8100, 0.9000, 1., 0.],
# [0.7290, 0.8100, 0.9000, 1.]])- 上三角形为 0 →因果掩蔽。
- 指数 = 前一个令牌表示被衰减的次数。当我们看到反复出现的表示时,这一点将变得更加清晰。
经常性保留
![]()
经常性保留
Sn类似于变压器中的KV缓存。RetNet 不是按顺序连接所有这些矩阵,而是将它们聚合成一个矩阵,循环在第一行。然后,此值乘以当前步骤的查询。
这与并行保留完全相同。
非正式证明草图:
设 S_0 = 0。 如果我们解决了S_n的复发,
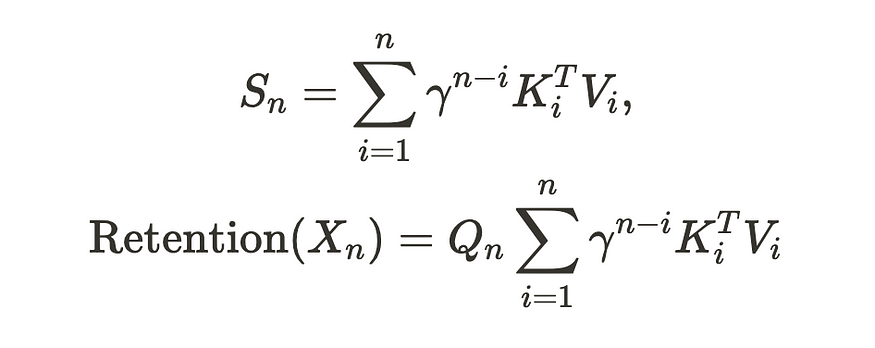
回想一下平行表示中 D 的指数矩阵的最后一行,即 [3, 2, 1, 0]。请注意,n=4。当我们计算第 4 个代币与第 1 个代币的保留期时,我们将其衰减 3 倍,相当于上式中的 n — i = 3! 由于其余部分相同,因此并行表示和循环表示彼此相同。
分块保留
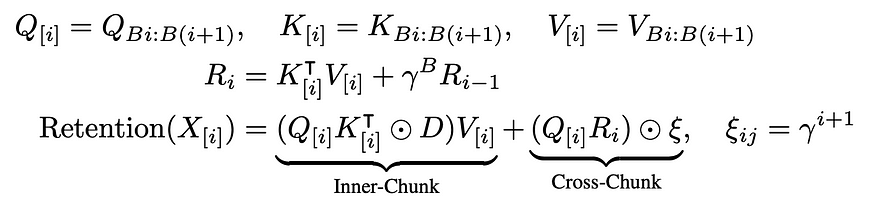
这看起来很复杂,但它实际上是每个块的并行计算 + 块的循环连接。 唯一重要的是应用的衰减次数。
5.4 论文中的错误
实际上,论文对 Ri 的分块表示(上面的等式)是错误的!事实上,它应该是

其中 X 运算符是叉积,D_B 是 D 矩阵的最后一行。直观地说,这是从平行表示和循环表示的衰减乘法得出的。
5.5 示意图

就是这样!以上是两种表示的摘要图。
六、为什么衰变?
所以基本上,最重要的细节是它使用了一种叫做衰减的东西,并且应用正确的衰减次数允许并行化。但我们必须了解这种衰败背后的动机是什么。推导(在高级别)非常简单。

- 我们将循环状态(s_n)定义为kv_cache。然后,递归关系在上图的第一行。
- 然后,我们将时间 n 的输出定义为 Q_n * s_n。上面的第二行写了这个并解决了重复周期以推出完整的依赖项。请注意,矩阵被多次应用。
3.现在,我们将A矩阵对角化为以下内容。
![]()
4. 然后,可以将 Λ 符号吸收到其他可学习的参数中(Q_n = X * W_k,因此 Λ 可以吸收到 W_k!因此,我们只剩下中间部分。
中间部分正是我们之前观察到的γ(衰变)和θ。
直观地说,它们作为一种“封闭式位置编码”工作,它也具有递归形式,因此可以提前计算时间n的编码,从而实现并行化。
七、实证发现

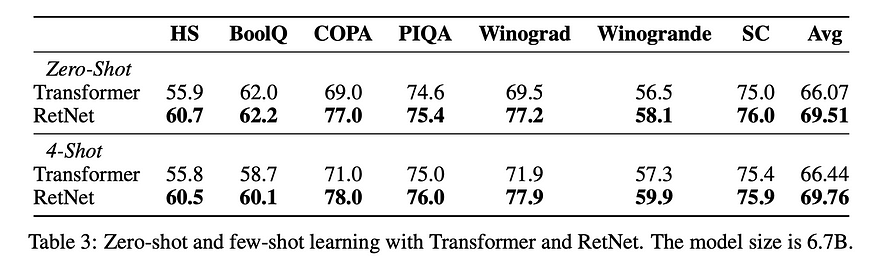
- RetNet击败了Transformer,因为它变得更大了。(评论家:不确定这种趋势是否会持续下去)
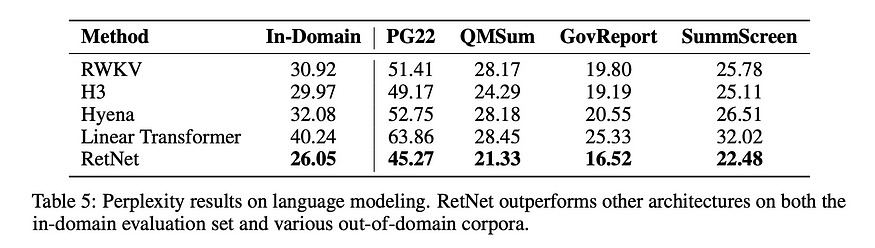
- RetNet在性能上击败了其他线性时间转换器。

- RetNet很快。(批评者:根据架构,这是显而易见的。显示 3 个数字来强调这一点毫无意义。TBH,甚至不需要运行实验来绘制这些情节......
八、评论家
- 论文中缺少一些细节,在官方代码出来之前不会明确。
- RWKV也支持训练并行化,但在论文中被歪曲为不可能。
- 有点吹嘘 RetNet 很快,有 3 个数字说同样的事情。:-)
- 很好奇这种趋势是否会扩展到更大的模型。
- 不确定他们是否会释放预先训练的体重。
- 不确定他们是否会击败像LLaMA这样的模型。
九、优点
- 快!(我批评他们吹牛,但确实很快,这很好)
- 性能相当。如果这种趋势继续下去,并且大型型号的性能没有下降,这可能会成为LLM的事实,因为它们便宜得多。
崔世贤
对于那些感兴趣的人,请看一下我对RetNet的实现:
GitHub - syncdoth/RetNet: Huggingface compatible implementation of RetNet (Retentive Networks, https://arxiv.org/pdf/2307.08621.pdf) including parallel, recurrent, and chunkwise forward.
相关文章:
保留网络[02/3]:大型语言模型转换器的继任者”
一、说明 在这项工作中,我们提出保留网络(RETNET)作为基础架构大型语言模型的结构,同时实现训练并行, 推理成本低,性能好。我们从理论上推导出这种联系 复发与关注之间。然后我们提出保留机制 序列建模&…...

微信小程序-生成canvas图片并保存到手机相册
wxml页面 <button class"rightbtn bottomBtnCss" catch:tap"canvasImg"><image src{{imgUrl}}/images/mine/jspj-icon.png class"restNumImg"></image><text class"btnText">生成图片</text></but…...

设计模式8:代理模式-动态代理
上一篇:设计模式8:代理模式-静态代理 目录 如何理解“动态”这两个字?动态代理简单的代码实例一个InvocationHandler代理多个接口有动态代理,为什么还要用Cglib代理? 如何理解“动态”这两个字? “动态”…...
-自定义包头和数据识别)
tcp字节传输(java)-自定义包头和数据识别
1、背景 tcp传输的时候会自动拆包,因此服务端接收的数据段可能跟客户端发送过来的数据段长度不一致,比如客户端一次发送10000个字节。但是服务端接收了两次才接收完整(例如第一次接收6000字节,第二次接收4000字节)。但…...

pyspark 系统找不到指定的路径; \Java\jdk1.8.0_172\bin\java
使用用具PyCharm 2023.2.1 1:pyspark 系统找不到指定的路径, Java not found and JAVA_HOME environment variable is not set. Install Java and set JAVA_HOME to point to the Java installation directory. 解决方法:配置正确环境变量…...

UE4 Physics Constraint Actor 实现钟摆效果
放入场景,然后将一个球体放入场景 选择小球 将小球改为Movable 选择模拟物理,并将小球移除平衡点 就实现了...

UE4/UE5 动画控制
工程下载 https://mbd.pub/o/bread/ZJ2cm5pu 蓝图控制sequence播放/倒播动画: 设置开启鼠标指针,开启鼠标事件 在场景中进行过场动画制作 设置控制事件...

Springboot整合shiro
导入依赖 <!-- 引入springboot的web项目的依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency> <!-- shiro --><depende…...

阻塞/非阻塞、同步/异步(网络IO)
1.阻塞/非阻塞、同步/异步(网络IO) 【思考】典型的一次 IO 的两个阶段是什么? 数据就绪 和 数据读写 数据就绪 :根据系统 IO 操作的就绪状态 阻塞 非阻塞 数据读写 :根据应用程序和内核的交互方式 同步 异步 陈硕:在处理 IO …...

为什么大家会觉得考PMP没用?
一是在于PMP这套知识体系,是一套底层的项目管理逻辑框架,整体是比较抽象的。大家在学习工作之后,会有人告诉你很多职场的一些做事的规则,比如说对于沟通,有人就会告诉如何跟客户沟通跟同事相处等等,这其实就…...

AVR128单片机 USART通信控制发光二极管显示
一、系统方案 二、硬件设计 原理图如下: 三、单片机软件设计 1、首先是系统初始化 void port_init(void) { PORTA 0xFF; DDRA 0x00;//输入 PORTB 0xFF;//低电平 DDRB 0x00;//输入 PORTC 0xFF;//低电平 DDRC 0xFF;//输出 PORTE 0xFF; DDRE 0xfE;//输出 PO…...

为什么5G 要分离 CU 和DU?(4G分离RRU 和BBU)
在 Blog 一文中,5G--BBU RRU 如何演化到 CU DU?_5g rru_qq_38480311的博客-CSDN博客 解释了4G的RRU BBU 以及 5G CU DU AAU,主要是讲了它们分别是什么。但是没有讲清楚 为什么,此篇主要回答why。 4G 为什么分离基站为 RRU 和 BBU…...

Python中的数据输入
获取键盘输入 input语句 使用input()可以从键盘获取输入,使用一个变量来接收 print("你是谁?") name input() print(f"我知道了,你是{name}")# print("你是谁?") name input("你是谁&…...

cms系统稳定性压力测试出现TPS抖动和毛刺的性能bug【杭州多测师_王sir】
一、并发线程数100,分10个阶梯,60秒加载时间,运行1小时进行压测,到10分钟就出现如下 二、通过jstat -gcutil 16689 1000进行监控...

【UE】材质描边、外发光、轮廓线
原教学视频链接: ue4 材质描边、外发光、轮廓线_哔哩哔哩_bilibili 步骤 1. 首先新建一个材质,这里命名为“Mat_outLine” 在此基础上创建一个材质实例 2. 在视口中添加一个后期处理体积 设置后期处理体积为无限范围 点击添加一个数组 选择“资产引用”…...

百模大战,打响AI应用生态的新赛点
点击关注 文|郝鑫 黄小艺,编|刘雨琦 “宇宙中心”五道口,又泛起了昔日的光芒。 十字路口一角的华清嘉园里,各种互联网大佬们,王兴、程一笑、张一鸣等人的创业传说似乎还有余音,后脚搬进来的AI…...
【C++二叉树】进阶OJ题
【C二叉树】进阶OJ题 目录 【C二叉树】进阶OJ题1.二叉树的层序遍历II示例代码解题思路 2.二叉搜索树与双向链表示例代码解题思路 3.从前序与中序遍历序列构造二叉树示例代码解题思路 4.从中序与后序遍历序列构造二叉树示例代码解题思路 5.二叉树的前序遍历(非递归迭…...

C++——vector:resize与reserve的区别,验证写入4GB大数据时相比原生操作的效率提升
resize和reserve的区别 reserve:预留空间,但不实例化元素对象。所以在没有添加新的对象之前,不能引用容器内的元素。而要通过调用push_back或者insert。 resize:改变容器元素的数量,且会实例化对象(指定或…...

基础配置xml
# 配置端口 server.port8081# 文件上传配置 # 是否支持文件上传 spring.servlet.multipart.enabledtrue # 是否支持文件写入磁盘 spring.servlet.multipart.file-size-threshold0 # 上传文件的临时目录 spring.servlet.multipart.locationd:/opt/tmp # 最大支持上传文件大小 sp…...

win环境安装SuperMap iserver和配置许可
SuperMap iServer是我国北京超图公司研发的基于跨平台GIS内核的云GIS应用服务器产品,通过服务的方式,面向网络客户端提供与专业GIS桌面产品相同功能的GIS服务,能够管理、发布多源服务,包括REST服务、OGC服务等。 SuperMap iserve…...
)
教师今晚必须做的1件事:用Claude 3.5 Sonnet重写你的公开课逐字稿——实测课堂语言感染力提升58%(附对比音频+评分报告)
更多请点击: https://codechina.net 第一章:Claude 3.5 Sonnet在教育内容创作中的范式跃迁 传统教育内容生产长期受限于人力密集、周期冗长与个性化不足三大瓶颈。Claude 3.5 Sonnet凭借其增强的推理深度、100K上下文窗口及显著优化的指令遵循能力&…...

8051开发中禁用自动代码分区的实践指南
1. 禁用自动代码分区的技术背景在8051架构的嵌入式开发中,代码分区(Bank Switching)是一种扩展程序存储器空间的常用技术。传统8051芯片的寻址空间有限,通过分区切换机制可以将代码分布到不同的物理存储区域。Keil C51开发工具链默…...

FPGA在材料测试中的高精度控制与并行处理应用
1. FPGA在材料测试领域的革新价值 材料测试设备作为工业质量控制的核心装备,其性能直接影响着从汽车安全气囊到医疗植入物的产品可靠性。传统基于通用微控制器的测试系统正面临三大技术瓶颈:首先是测试标准迭代速度快,ASTM、ISO等组织每年新增…...

AI时代版权新范式:智能代理如何重塑数据交易与创作者权益
1. 项目概述:当AI遇见版权,一场静默的“数据战争”正在上演如果你是一位内容创作者,无论是撰写深度文章的记者、绘制插画的艺术家,还是谱写旋律的音乐人,过去几年可能都经历过一种复杂的情绪:看着自己的作品…...

LLM多智能体驱动微服务自治:从架构设计到Sock Shop实战评估
1. 项目概述:当微服务遇见大模型,自管理不再是空谈在云原生和微服务架构成为主流的今天,我们运维工程师面对的早已不是几台物理服务器,而是一个由成百上千个容器化服务实例构成的、动态且复杂的生态系统。服务间的调用链路像一张错…...
)
别再只盯着MSE了!用Python实战对比5大回归评估指标(附避坑指南)
别再只盯着MSE了!用Python实战对比5大回归评估指标(附避坑指南)当你的回归模型在测试集上表现不佳时,第一个浮现在脑海的问题往往是:"该用哪个指标来评估才最合理?"这个问题远比想象中复杂——我…...

类和对象概括
类与对象的概念在Java中,类是对象的模板或蓝图,定义了对象的属性和行为。对象是类的实例,具有类定义的属性和方法。类的定义类通过class关键字定义,包含成员变量(属性)和方法(行为)。…...

小波分析多尺度数据融合算法应用【附算法】
✨ 长期致力于小波分析、多尺度数据融合、MEMS陀螺、Allan方差研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)小波域多尺度融合定理证明与算法框架&a…...

SQL 数据库从免费到付费选型实战:支撑真实规模产品的能力分析与选择指南
引言:为什么 SQL 数据库选型如此重要? 在当今数据驱动的时代,数据库是任何数字产品的核心基础设施。无论是初创公司的 MVP(最小可行产品),还是日活百万的成熟应用,数据库的选择直接影响着产品的性能、成本、可扩展性和开发效率。 对于技术决策者而言,面对琳琅满目的 …...
牛牛走迷宫【牛客tracker 每日一题】
牛牛走迷宫 时间限制:1秒 空间限制:256M 网页链接 牛客tracker 牛客tracker & 每日一题,完成每日打卡,即可获得牛币。获得相应数量的牛币,能在【牛币兑换中心】,换取相应奖品!助力每日有…...