数据挖掘的学习路径
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️
🐴作者:秋无之地🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。
🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、留言💬
上一篇文章已经跟大家介绍过《数据分析综述》,相信大家对数据分析都有一个清楚的认识。下面我讲一下数据分析中比较重要的一环:数据挖掘的学习路径。
一、数据挖掘的重要组成
一开始可能大家对数据挖掘还很陌生,有点无从下手的感觉。不用担心,接下来听我讲解就行。
想象一下,茫茫的大海上,孤零零地屹立着钻井,想要从大海中开采出宝贵的石油。对于普通人来说,大海是很难感知的,就更不用说找到宝藏了。但对于熟练的石油开采人员来说,大海是有坐标的。他们对地质做勘探,分析地质构造,从而发现哪些地方更可能有石油。然后用开采工具,进行深度挖掘,直到打到石油为止。
大海、地质信息、石油对开采人员来说就是数据源、地理位置、以及分析得到的结果。而我们要做的数据挖掘工作,就好像这个钻井一样,通过分析这些数据,从庞大的数据中发现规律,找到宝藏。

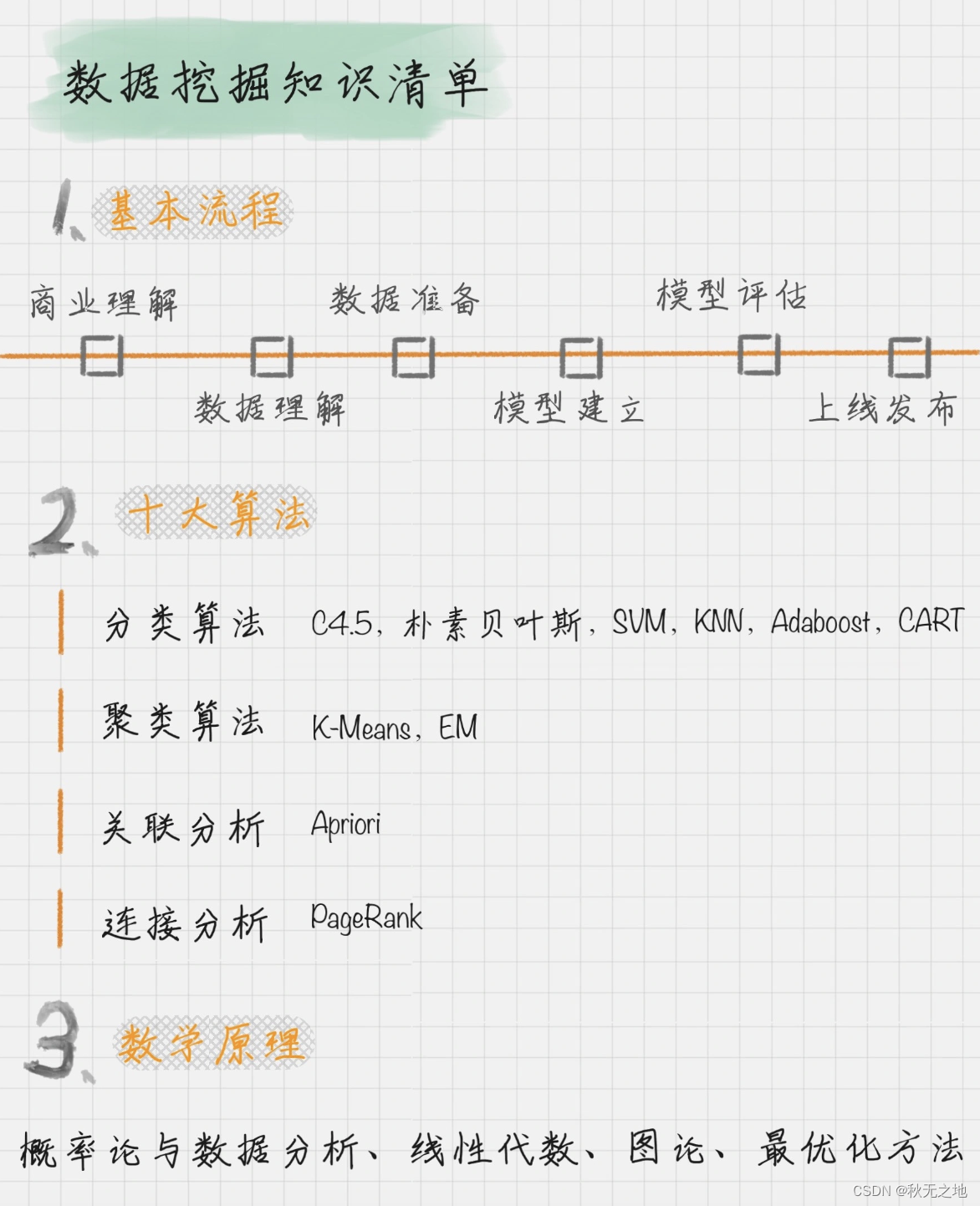
二、数据挖掘的基本流程
数据挖掘主要分为下面6个流程:
- 商业理解:数据挖掘不是我们的目的,我们的目的是更好地帮助业务,所以第一步我们要从商业的角度理解项目需求,在这个基础上,再对数据挖掘的目标进行定义。
- 数据理解:尝试收集部分数据,然后对数据进行探索,包括数据描述、数据质量验证等。这有助于你对收集的数据有个初步的认知。
- 数据准备:开始收集数据,并对数据进行清洗、数据集成等操作,完成数据挖掘前的准备工作。
- 模型建立:选择和应用各种数据挖掘模型,并进行优化,以便得到更好的分类结果。
- 模型评估:对模型进行评价,并检查构建模型的每个步骤,确认模型是否实现了预定的商业目标。
- 上线发布:模型的作用是从数据中找到金矿,也就是我们所说的“知识”,获得的知识需要转化成用户可以使用的方式,呈现的形式可以是一份报告,也可以是实现一个比较复杂的、可重复的数据挖掘过程。数据挖掘结果如果是日常运营的一部分,那么后续的监控和维护就会变得重要。
三、数据挖掘的十大算法
在众多的数据挖掘模型中,国际权威的学术组织 ICDM (the IEEE International Conference on Data Mining)评选出了十大经典的算法。
1. C4.5
C4.5 算法是得票最高的算法,可以说是十大算法之首。C4.5 是决策树的算法,它创造性地在决策树构造过程中就进行了剪枝,并且可以处理连续的属性,也能对不完整的数据进行处理。它可以说是决策树分类中,具有里程碑式意义的算法。
2. 朴素贝叶斯(Naive Bayes)
朴素贝叶斯模型是基于概率论的原理,它的思想是这样的:对于给出的未知物体想要进行分类,就需要求解在这个未知物体出现的条件下各个类别出现的概率,哪个最大,就认为这个未知物体属于哪个分类。
3. SVM
SVM 的中文叫支持向量机,英文是 Support Vector Machine,简称 SVM。SVM 在训练中建立了一个超平面的分类模型。
4. KNN
KNN 也叫 K 最近邻算法,英文是 K-Nearest Neighbor。所谓 K 近邻,就是每个样本都可以用它最接近的 K 个邻居来代表。如果一个样本,它的 K 个最接近的邻居都属于分类 A,那么这个样本也属于分类 A。
5. AdaBoost
Adaboost 在训练中建立了一个联合的分类模型。boost 在英文中代表提升的意思,所以 Adaboost 是个构建分类器的提升算法。它可以让我们多个弱的分类器组成一个强的分类器,所以 Adaboost 也是一个常用的分类算法。
6. CART
CART 代表分类和回归树,英文是 Classification and Regression Trees。像英文一样,它构建了两棵树:一棵是分类树,另一个是回归树。和 C4.5 一样,它是一个决策树学习方法。
7. Apriori
Apriori 是一种挖掘关联规则(association rules)的算法,它通过挖掘频繁项集(frequent item sets)来揭示物品之间的关联关系,被广泛应用到商业挖掘和网络安全等领域中。频繁项集是指经常出现在一起的物品的集合,关联规则暗示着两种物品之间可能存在很强的关系。
8. K-Means
K-Means 算法是一个聚类算法。假设每个类别里面,都有个“中心点”,即意见领袖,它是这个类别的核心。现在我有一个新点要归类,这时候就只要计算这个新点与 K 个中心点的距离,距离哪个中心点近,就变成了哪个类别。
9. EM
EM 算法也叫最大期望算法,是求参数的最大似然估计的一种方法。原理是这样的:假设我们想要评估参数 A 和参数 B,在开始状态下二者都是未知的,并且知道了 A 的信息就可以得到 B 的信息,反过来知道了 B 也就得到了 A。可以考虑首先赋予 A 某个初值,以此得到 B 的估值,然后从 B 的估值出发,重新估计 A 的取值,这个过程一直持续到收敛为止。EM 算法经常用于聚类和机器学习领域中。
10. PageRank
PageRank 起源于论文影响力的计算方式,如果一篇文论被引入的次数越多,就代表这篇论文的影响力越强。同样 PageRank 被 Google 创造性地应用到了网页权重的计算中:当一个页面链出的页面越多,说明这个页面的“参考文献”越多,当这个页面被链入的频率越高,说明这个页面被引用的次数越高。基于这个原理,我们可以得到网站的权重划分。
算法可以说是数据挖掘的灵魂,也是最精华的部分。看完上面的介绍,相信大家对十大算法有一个初步的了解,具体内容不理解没有关系,后面我会详细给大家进行讲解。
四、数据挖掘的数学原理
之前已经提到过,学好数据分析,数据基础是必须的。那是因为数据挖掘中的经典算法,如果不了解概率论和数理统计,是很难掌握算法的本质;如果不懂线性代数,就很难理解矩阵和向量运作在数据挖掘中的价值;如果没有最优化方法的概念,就对迭代收敛理解不深。所以说,想要更深刻地理解数据挖掘的方法,就非常有必要了解它后背的数学原理。
1. 概率论与数理统计
概率论在我们上大学的时候,基本上都学过,不过大学里老师教的内容,偏概率的多一些,统计部分讲得比较少。在数据挖掘里使用到概率论的地方就比较多了。比如条件概率、独立性的概念,以及随机变量、多维随机变量的概念。
2. 线性代数
向量和矩阵是线性代数中的重要知识点,它被广泛应用到数据挖掘中,比如我们经常会把对象抽象为矩阵的表示,一幅图像就可以抽象出来是一个矩阵,我们也经常计算特征值和特征向量,用特征向量来近似代表物体的特征。这个是大数据降维的基本思路。
3. 图论
社交网络的兴起,让图论的应用也越来越广。人与人的关系,可以用图论上的两个节点来进行连接,节点的度可以理解为一个人的朋友数。我们都听说过人脉的六度理论,在 Facebook 上被证明平均一个人与另一个人的连接,只需要 3.57 个人。当然图论对于网络结构的分析非常有效,同时图论也在关系挖掘和图像分割中有重要的作用。
4. 最优化方法
最优化方法相当于机器学习中自我学习的过程,当机器知道了目标,训练后与结果存在偏差就需要迭代调整,那么最优化就是这个调整的过程。一般来说,这个学习和迭代的过程是漫长、随机的。最优化方法的提出就是用更短的时间得到收敛,取得更好的效果
五、总结
版权声明
本文章版权归作者所有,未经作者允许禁止任何转载、采集,作者保留一切追究的权利。
相关文章:
数据挖掘的学习路径
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…...
逻辑回归Logistic
回归 概念 假设现在有一些数据点,我们用一条直线对这些点进行拟合(这条直线称为最佳拟合直线),这个拟合的过程就叫做回归。进而可以得到对这些点的拟合直线方程。 最后结果用sigmoid函数输出 因此,为了实现 Logisti…...
Flink提交jar出现错误RestHandlerException: No jobs included in application.
今天打包一个flink的maven工程为jar,通过flink webUI提交,发现居然报错。 如上图所示,提示错误为: Server Response Message: org.apache.flink.runtime.rest.handler.RestHandlerException: No jobs included in application. …...
】基础概念:数据仓库【用于决策的数据集合】的概念、建立数据仓库的原因与好处)
【数仓基础(一)】基础概念:数据仓库【用于决策的数据集合】的概念、建立数据仓库的原因与好处
文章目录 一. 数据仓库的概念1. 面向主题2. 集成3. 随时间变化4. 非易失粒度 二. 建立数据仓库的原因三. 使用数据仓库的好处 一. 数据仓库的概念 数据仓库的主要作用: 数据仓库概念主要是解决多重数据复制带来的高成本问题。 在没有数据仓库的时代,需…...
电商类面试问题--01Elasticsearch与Mysql数据同步问题
在实现基于关键字的搜索时,首先需要确保MySQL数据库和ES库中的数据是同步的。为了解决这个问题,可以考虑两层方案。 全量同步:全量同步是在服务初始化阶段将MySQL中的数据与ES库中的数据进行全量同步。可以在服务启动时,对ES库进…...
天线材质介绍--FPC天线
...

vue3 的 ref、 toRef 、 toRefs
1、ref: 对原始数据进行拷贝。当修改 ref 响应式数据的时候,模版中引用 ref 响应式数据的视图处会发生改变,但原始数据不会发生改变 <template><div>{{refA}}</div> </template><script lang"ts" setup> impor…...
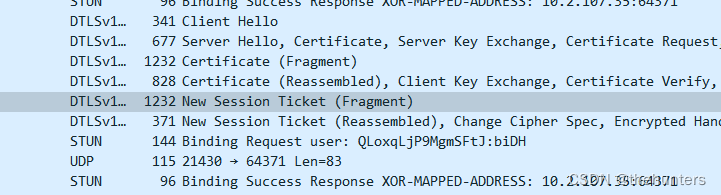
WebRTC中 setup:actpass、active、passive
1、先看一下整个DTLS的流程 setup:actpass、active、passive就发生在Offer sdp和Anser SDP中 Offer的SDP是setup:actpass,这个是服务方: v0\r o- 1478416022679383738 2 IN IP4 127.0.0.1\r s-\r t0 0\r agroup:BUNDLE 0 1\r aextmap-allow-mixed\r amsid-semanti…...

ModuleNotFoundError: No module named ‘lavis‘解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

双指针的问题解法以及常见的leetcode例题。
目录 介绍: 问题1:双指针 剑指offer57 和为S的两个数字。 问题2:剑指Offer 21. 调整数组顺序使奇数位于偶数前面 问题3:连续奇数子串(笔试遇到的真题) 问题4:滑动窗口的最大值 介绍&#…...

python容器模块Collections
Python附带一个模块,它包含许多容器数据类型,名字叫作collections defaultdict defaultdict与dict类型不同,你不需要检查key是否存在,所以我们能这样做: from collections import defaultdict colours ((Yasoob, Y…...
排序算法学习记录-快速排序
快速排序 快速排序关键在于确定一个中间值,使得小于这个中间值的数在左边,大于这个中间值的数在右边。那么中间值该如何确定呢?有以下几种做法 首元素,也就是arr[l]尾元素,也就是arr[r]中间元素,也就是ar…...

安装windows版本的ros2 humble的时候,最后报错
"[rti_connext_dds_cmake_module][warning] RTI Connext DDS environment script not found (\resource\scripts\rtisetenv_x64Win64VS2017.bat). RTI Connext DDS will not be available at runtime, unless you already configured PATH manually." 意思是没找到。…...

Nginx 学习(十)高可用中间件的配置与实现
一 Keepalived热备 1 概述 调度器出现单点故障,如何解决?Keepalived实现了高可用集群Keepalived最初是为LVS设计的,专门监控各服务器节点的状态Keepalived后来加入了VRRP功能,防止单点故障 2 运行原理 Keepalived检测每个服务器节点状…...

[刷题记录]牛客面试笔刷TOP101
牛客笔试算法必刷TOP101系列,每日更新中~ 1.合并有序链表2023.9.3 合并两个排序的链表_牛客题霸_牛客网 (nowcoder.com) 题意大致为: 将两个链表中的元素按照从小到大的顺序合并成为一个链表. 所给予的条件: 给出的所要合并的链表都是从小到大顺序排列的. 思路: 创建一…...

降水预报之双重惩罚
在降水预报中,通常会出现 "双重惩罚问题 "的指标或度量包括那些常用于预报验证的指标或度量。当假阴性(漏报降水事件)和假阳性(误报)受到同等惩罚或加权时,就会出现双重惩罚问题,这在…...
)
一条SQL语句的执行过程(附一次两段式提交)
一条SQL语句的完整执行过程是怎样的呢?我们用select和update语句来举例。 注意在mysql8后,进入服务层后,取消了去查询缓存(属于Server服务层)这个步骤,缓存中key是SQL语句,value是值,这样其实并不会提升性…...

Python基础知识详解:数据类型、对象结构、运算符完整分析
文章目录 python基础知识数据类型类型检查对象(object)对象的结构变量和对象类型转换运算符(操作符)1. 算术运算符2. 赋值运算符3. 比较运算符(关系运算符)4. 逻辑运算符5. 条件运算符(三元运算符) 总结 py…...
基于Streamlit的应用如何通过streamlit-authenticator组件实现用户验证与隔离
Streamlit框架中默认是没有提供用户验证组件的,大家在基于streamlit快速实现web应用服务过程中,不可避免的需要配置该应用的访问范围和权限,即用户群体,一般的做法有两种,一种是通过用户密码验证机制,要求只…...
[虚幻引擎插件介绍] DTGlobalEvent 蓝图全局事件, Actor, UMG 相互回调,自由回调通知事件函数,支持自定义参数。
本插件可以在虚幻的蓝图 Actor, Obiect,UMG 里面指定绑定和执行消息,可带自定义参数。 参数支持 Bool,Byte,Int,Int64,Float,Name,String,Text,Ve…...

Arm编译器与64位inode文件系统兼容性问题解析
1. 64位inode文件系统与Arm编译器的兼容性问题解析在嵌入式开发领域,Arm编译器工具链是构建可靠、高效嵌入式系统的核心工具。然而,当开发者使用现代网络文件系统(如NFSv3)或分布式文件系统(如Ceph、CXFS)时…...

Office技巧速成:3个让效率翻倍的实用方法
表格操作总出错怎么办众多人于运用Excel开展数据处理工作之际,时常会被合并单元格以及公式报错等情形搞得疲惫不堪,焦头烂额。实际上,要是认真细细探究一番,便会发觉,大部分这类问题均是起因于对 Excel 基本功能欠缺熟…...

Appium Android自动化稳定性实战:从环境踩坑到三层熔断
1. 为什么现在还在手点Android测试?Appium不是“老古董”,而是最稳的工业级选择 很多人一听到Appium,第一反应是“这玩意儿2015年就火了,现在还讲它?”——我去年在给一家做金融类App的客户做质量体系升级时ÿ…...

星火动漫 × 火山引擎:用Seedance重构创作链路加速释放AI漫剧生产力
20 天能做什么?在传统动漫制作的管线里,这点时间或许只够画完一套分镜稿。但就是在这短短 20 天内,一部名为《西游:五指山上贴瓷砖》的漫剧不仅完成了全流程制作,更一路杀出重围,连续多日霸榜。若按常规路径…...

Midscene.js技术深度解析:视觉驱动UI自动化的架构演进与实践路径
Midscene.js技术深度解析:视觉驱动UI自动化的架构演进与实践路径 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 在传统UI自动化测试领域,…...

为OpenClaw智能体工作流配置Taotoken聚合端点的教程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken聚合端点的教程 OpenClaw是一款功能强大的智能体开发工具,它允许开发者构建和编排…...
)
告别MCUXpresso IDE:手把手教你用VSCode + CMake + Ninja搭建NXP MCU开发环境(附SDK离线配置避坑指南)
告别MCUXpresso IDE:手把手教你用VSCode CMake Ninja搭建NXP MCU开发环境(附SDK离线配置避坑指南) 嵌入式开发者常年在资源受限的环境中工作,却不得不忍受传统IDE的资源挥霍。当MCUXpresso IDE占用2GB内存只为编辑一个头文件时&…...

跨越语言障碍:为MASA模组系列打造专业级中文体验解决方案
跨越语言障碍:为MASA模组系列打造专业级中文体验解决方案 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 在Minecraft的模组生态系统中,MASA系列模组以其强大的功…...

3分钟搞定!Windows性能优化神器CPUDoc零基础上手指南
3分钟搞定!Windows性能优化神器CPUDoc零基础上手指南 【免费下载链接】CPUDoc 项目地址: https://gitcode.com/gh_mirrors/cp/CPUDoc 你有没有遇到过这样的情况?明明电脑配置不错,玩游戏时帧数却忽高忽低;多开几个软件就感…...
)
ESP32连接阿里云物联网平台实战:从设备创建到APP控制,一个教程全搞定(避坑指南)
ESP32连接阿里云物联网平台实战:从设备创建到APP控制全流程解析 在智能硬件产品开发中,物联网平台的选择与集成往往是决定项目成败的关键环节。阿里云物联网平台凭借其稳定的服务、丰富的功能生态和本土化优势,已成为国内物联网开发者的首选。…...