使用Python轻松实现文档编写
大家好,本文将介绍如何使用Python轻松实现文档编写,减少报告撰写的痛苦,使用Microsoft Word、python和python-docx库来简化报告撰写和从报告中提取信息。
案例
-
读取一个Word文档并进行编辑。
虽然听起来可能不那么令人振奋,但根据支持系统的不同,可以通过巧妙运用这个设置来大大减少制作报告所需的时间。代码将在下面分享和解释,但用户可以在GitHub上获取代码的基础版本。强烈建议根据特定用例修改代码,以适应具体使用情况。
开始
在使用pip3安装python-docx之后,建议将程序拆分为读取两种不同类型内容的部分,即段落和表格。
def tableSearch(doc):""" Takes doc file
Purpose: Scrapes all tables and pulls back text
Returns: Dictionary of tables
"""tables = {}table = 0x = 0y = 0while table != len(doc.tables):logging.debug("Table {} Row: {}".format(table, len(doc.tables[table].rows)))logging.debug("Table {} Column: {}".format(table, len(doc.tables[table].columns)))logging.debug("Table {}".format(table))table_test = doc.tables[table]run = doc.add_paragraph().add_run()font = run.fontwhile x != len(table_test.rows):while y != len(table_test.columns):logging.debug("Table: {}, X: {}, Y: {}\n{}\n".format(table, x,y,table_test.cell(x,y).text))tables[str(table)+"."+str(x)+"."+str(y)] = {"row": x, "column": y, "text": table_test.cell(x,y).text}y += 1x += 1y = 0x = 0y = 0table += 1return tables# 读取Word文档
def wordDocx(file):""" Takes file
Purpose: Reads the Word Doc
Returns: Nothing
"""logging.debug("File: {}".format(file))doc = docx.Document(file)fullText = []for para in doc.paragraphs:logging.debug("Paragraph: {}".format(para.text))fullText.append(para.text)tableInfo = tableSearch(doc)return [fullText, tableInfo]段落
段落的解析非常简单。它们被设置为一个列表,可以以类似的方式访问(doc.paragraphs[n])。
如果想更改段落中的文本,只需使用下面的代码即可修改文本:
oldText = doc.paragraphs[indexOfParagraph].textreplacedText = oldText.replace("<CLIENT_LONGNAME>",clientLongName)doc.paragraphs[indexOfParagraph].text = "{} + Text to add".format(oldText)
doc.paragraphs[indexOfParagraph].text = "{} + Replaced text".format(replacedText)正如上文所述,可以通过制作一个包含关键词(如<CLIENT_LONGNAME>)的普通文档模板,然后使用类似这样的程序去更改每个关键词的所有实例。虽然这也可以通过打开文档并执行查找和替换操作来实现,但支持此操作的基础结构可以使手动更改的快速过程变得更快。
表格
表格要稍微复杂一些,原因在于表格是二维的,而段落是一维的(段落是0至n的,而表格有一个X坐标和一个Y坐标)。由于表格的处理方式不同,因此需要一种更复杂的方式来循环遍历所有表格,并索引其中的某些内容。
关于在表格中选择元素的另一个重要注意事项。虽然选择单元格需要使用x和y值,但还需要选择要引用的表格。
table = 0
x = 0
y = 0while table != len(doc.tables):table_test = doc.tables[table]while x != len(table_test.rows):while y != len(table_test.columns):logging.debug("Table: {}, X: {}, Y: {}\n{}\n".format(table, x,y,table_test.cell(x,y).text))y += 1x += 1y = 0x = 0y = 0table += 1像这样对程序进行迭代有多个目的。
-
不论每个表格的结构如何,程序都会以相同方式循环遍历每个表格。
-
记录和显示单元格的位置可以进行有趣的集成。
一个有趣集成的例子是创建包含值及其位置的字典,以便插入信息。
虽然为此设计一个查询系统超出了本文的讨论范围,但本文已经提供了一个基本设置,可以帮助你入门:
ref = {
"Date": [0,2,12]
}info = {
"Date": "08/24/2023"
}for key,value in ref.items:if table == value[0] and x == value[1] and y == value[2]:table_test.cell(x,y).text = info[key]扩展用途
使用与前面相同的循环系统,还可以让某个程序解析已完成报告中的信息,并将其导出为CSV文件,以便在其他报告撰写程序中使用。本文使用过并推荐的两个报告撰写平台是PlexTrac和AttackForge。这两个平台都允许通过一个特殊格式的CSV文件或JSON文件导入调查结果。
如何简化向其他报告/系统导入信息的过程:
在上面的代码中,每次循环遍历段落或表格中的一个段落或单元格时,都会有代码可以查看对象中的内容。这不仅可以用于调试,本文将文本添加到字典中。这样可以节省从中提取数据的时间,而将更多时间用于解析和重新格式化提取回来的数据。
# 段落
fullText = []
# 表格
tables = {}fullText.append(para.text)
tables[str(table)+"."+str(x)+"."+str(y)] = {"row": x, "column": y, "text": table_test.cell(x,y).text}
分别添加这几行后,就可以抓取数据,并以类似于访问数据的格式保存数据。一旦获得了数据并知道在哪里可以找到它,就可以在各自的对象中循环遍历,并使用这些数据创建一个新文件。
举个简单的例子,本文将在GitHub上的代码中添加一个函数,将数据保存为CSV格式。
import docx
import logging
import argparse
import re
import syslogging.basicConfig(level=logging.DEBUG)# 设置日志记录
def get_arg():""" Takes nothing
Purpose: Gets arguments from command line
Returns: Argument's values
"""parser = argparse.ArgumentParser()# CLI 版本# parser.add_argument("-d","--debug",dest="debug",action="store_true",help="Turn on debugging",default=False)parser.add_argument("-d","--debug",dest="debug",action="store_false",help="Turn on debugging",default=True)# 文件版本parser.add_argument("-f","--file",dest="file", help="Name of the Word Doc.")parser.add_argument("-o","--output",dest="output", help="Name of the file to output the results.")options = parser.parse_args()if not options.output:options.output = "output.csv"if not options.file:logging.error("Please provide a file name.")sys.exit()if options.debug:logging.basicConfig(level=logging.DEBUG)global DEBUGDEBUG = Trueelse:logging.basicConfig(level=logging.INFO)return optionsdef tableSearch(doc):""" Takes doc file
Purpose: Scrapes all tables and pulls back text
Returns: Dictionary of tables
"""tables = {}table = 0x = 0y = 0while table != len(doc.tables):logging.debug("Table {} Row: {}".format(table, len(doc.tables[table].rows)))logging.debug("Table {} Column: {}".format(table, len(doc.tables[table].columns)))logging.debug("Table {}".format(table))table_test = doc.tables[table]run = doc.add_paragraph().add_run()font = run.fontwhile x != len(table_test.rows):while y != len(table_test.columns):logging.debug("Table: {}, X: {}, Y: {}\n{}\n".format(table, x,y,table_test.cell(x,y).text))tables[str(table)+"."+str(x)+"."+str(y)] = {"row": x, "column": y, "text": table_test.cell(x,y).text}y += 1x += 1y = 0x = 0y = 0table += 1return tables# 读取word文档
def wordDocx(file):""" Takes file
Purpose: Reads the Word Doc
Returns: Nothing
"""logging.debug("File: {}".format(file))doc = docx.Document(file)fullText = []for para in doc.paragraphs:logging.debug("Paragraph: {}".format(para.text))fullText.append(para.text)tableInfo = tableSearch(doc)return [fullText, tableInfo]def infoToCSV(para, table):""" Takes a list and a dictionary
Purpose: Convert dictionary and paragraph into a CSV file
Returns: Nothing
"""csvHeaders = "Name,Description,Recommendation\n"for key, values in table.items():Name = ""Description= ""Recommendation= ""nameRegex = re.search("0\.\d+\.1",key) desRegex = re.search("0\.\d+\.3",key)recRegex = re.search("0\.\d+\.6",key)if nameRegex:Name = value["text"]if desRegex:Description = value["text"]if recRegex:Recommendation = value["text"] csvHeaders += "{},{},{}\n".format(Name,Description,Recommendation)for item in para:values = re.findall("Name\":\"(.+?)\".+?Description\":\"(.+?)\".+?Recommendation\":\"(.+?)\"",item)try:csvHeaders += "{},{},{}\n".format(values[0],values[1],values[2])except IndexError:continuef = open("Output.csv", "w")f.write(csvHeaders)f.close()def main():options = get_arg()logging.debug("Options: {}".format(options))info = wordDocx(options.file)logging.debug("Info: {}".format(info))infoToCSV(info[0], info[1])if __name__ == '__main__':main()
需要根据尝试要导入信息的程序来修改infoToCSV函数。虽然这可能有点烦人,但在必须制作多份报告时,在这里花费的5-20分钟来使函数适应需求是值得的。根据本文的经验,手动重新输入这些信息很快就会变得非常枯燥。
局限性
在本文中,你可能已经注意到没有涉及图片的任何内容,这有一个令人遗憾的原因:python-docx无法处理图片文件,除非在添加图片时使用它,否则它似乎根本不会注意到图片文件。要解决这个问题,要么需要进入库的源代码并对其进行集成,要么需要解压缩.docx文件并解析图像标签的XML,然后从媒体文件夹中查找图片。
相关文章:

使用Python轻松实现文档编写
大家好,本文将介绍如何使用Python轻松实现文档编写,减少报告撰写的痛苦,使用Microsoft Word、python和python-docx库来简化报告撰写和从报告中提取信息。 案例 读取一个Word文档并进行编辑。 虽然听起来可能不那么令人振奋,但根…...

前后端分离项目,整合成jar包,刷新404或空白页,解决方法
问题解决 1、注销遇到404,或刷新遇到404 # 添加错误跳转 Component public class ErrorConfig implements ErrorPageRegistrar {Overridepublic void registerErrorPages(ErrorPageRegistry registry) {ErrorPage error404Page new ErrorPage(HttpStatus.NOT_FOU…...
前端、后端面试集锦
诸位读者,我们在工作的过程中,经常会因跳槽而面试。 你开发能力很强,懂得技术也很多,若加上条理清晰的面试话术,可以让您的面试事半功倍。 个人博客阅读量破170万,为尔倾心打造的 面试专栏-前端、后端面试…...

Web存储
目录 什么是 HTML5 Web 存储? 方法 cookie webStorage 会话存储 sessionStorage 本地存储localStorage 什么是 HTML5 Web 存储? 使用HTML5可以在本地存储用户的浏览数据。 早些时候,本地存储使用的是 cookie。但是Web 存储需要更加的安全与快速. 这些数据不会被保存在服…...
)
字节对齐(C++,C#)
C#字节对齐示例 结构体定义 [StructLayoutAttribute(LayoutKind.Sequential, CharSet CharSet.Ansi, Pack 1)],这是C#引用非托管的C/C的DLL的一种定义定义结构体的方式,主要是为了内存中排序,LayoutKind有两个属性Sequential和Explicit&a…...

使用mybatisplus查询sql时,报Error attempting to get column ‘ID‘ from result set错误
问题描述: 在使用如下代码进行查询时,报Error attempting to get column ‘ID’ from result set错误: LambdaQueryWrapper<TimeFeature> wrapper new LambdaQueryWrapper<>();wrapper.eq(TimeFeature::getDate, currentDateTim…...

ElementUI浅尝辄止32:NavMenu 导航菜单
为网站提供导航功能的菜单。常用于网站平台顶部或侧边栏菜单导航。 1.如何使用?顶栏 /*导航菜单默认为垂直模式,通过mode属性可以使导航菜单变更为水平模式。另外,在菜单中通过submenu组件可以生成二级菜单。Menu 还提供了background-color、…...

@Value的注入与静态注入 与 组件中静态工具类的注入
一、Value 的注入 首先时一般的注入,例如你的配置文件中: vod: access-key: 123456那么,你就可以在你的方法中进行注入: Component public class VodService{Value("${vod.access-key}")private String accessKey; }…...
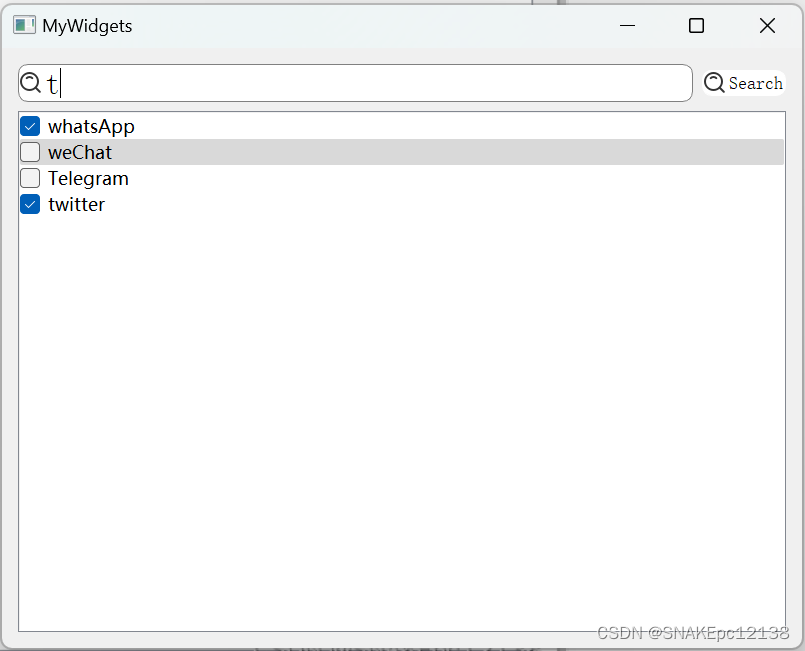
Qt--自定义搜索控件,QLineEdit带前缀图标
写在前面 这里自定义一个搜索控件,通过自定义LineEdit的textChange信号,搜索指定内容,并以QCheckBox的方式显示在QListWidget中。 开发版本 Qt: 5.15.2 Qt: Creator10.0.2 编译环境:msvc2019_64bit release 效果 代码 自定义…...

8月AI实战:工业视觉缺陷检测
8月AI实战:工业视觉缺陷检测 –基于tflite的yolov8模型优化和推理 操作视频见B站连接:aidlux模型优化工业缺陷检测~~完美用我的华为手机实现缺陷检测的推理bilibiliaidlux模型优化工业缺陷检测~~完美用我…...

Kubernetes的ExternalName详解
ExternalName类型的Service在Kubernetes中用于将外部服务(不是Kubernetes集群内的服务)映射到Kubernetes集群内的Service。 样例 其创建方法如下: kind: Service apiVersion: v1 metadata:name: my-external-servicenamespace: cv-console…...

使用 Pandera 的 PySpark 应用程序的数据验证
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景 本文简要介绍了 Pandera 的主要功能,然后继续解释 Pandera 数据验证如何与自最新版本 (Pandera 0.16.0) 以来使用本机 PySpark SQL 的数据处理工作流集成。 Pandera 旨在与其他流行…...

README
一、Markdown 简介 Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档。 应用 当前许多网站都广泛使用 Markdown 来撰写帮助文档或是用于论坛上发表消息。例如:GitHub、简书、知乎等 编辑器 推荐使用Typora,官…...
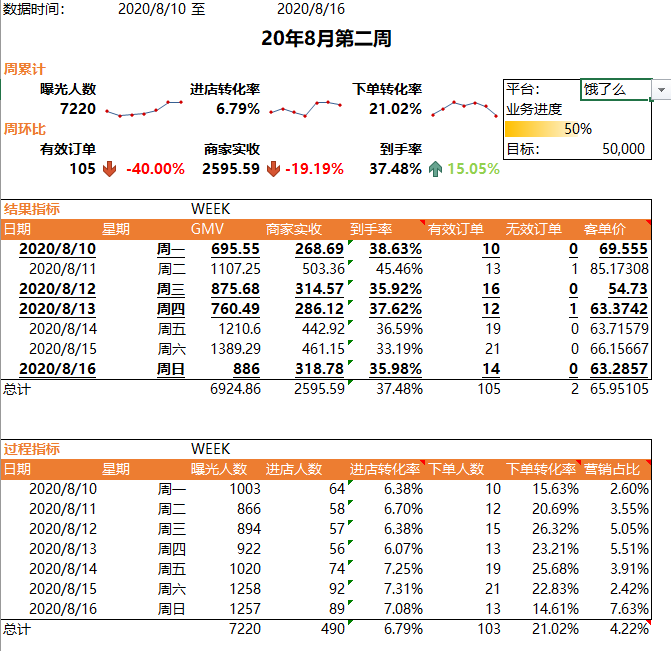
Excel周报制作
Excel周报制作 文章目录 Excel周报制作一、理解数据二、数据透视表三、常用函数1.sum-求和2.sumif-单条件求和3.sumifs-多条件求和4.sum和subtotal的区别5.if函数6.if嵌套7.vlookup函数和数据透视表聚合8.index和match函数 四、周报开发五、报表总览 一、理解数据 这是一个线上…...

Qt QtCreator 所有官方下载地址
Qt QtCreator 所有版本官方下载地址 1.所有版本QT下载地址 : Index of /archive/qt 所有Qt Creator下载地址: Index of /archive/qtcreator 所有Qt VS开发插件下载地址: Index of /archive/vsaddin 4.Qt官网镜像下载地址: Index of /…...
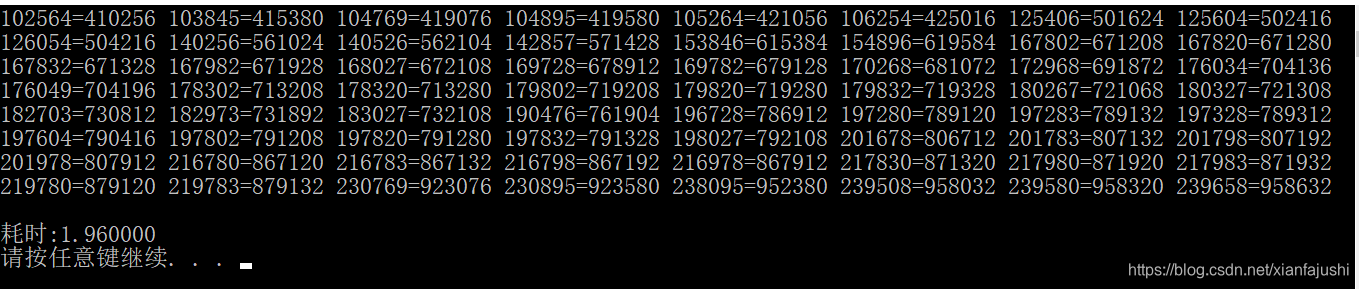
C++包含整数各位重组
void 包含整数各位重组() {//缘由https://bbs.csdn.net/topics/395402016int shu 100000, bs 4, bi shu * bs, a 0, p 0, d 0;while (shu < 500000)if (a<6 && (p to_string(shu).find(to_string(bi)[a], p)) ! string::npos && (d to_string(bi…...
)
数学建模--模型总结(5)
优化问题: 线性规划,半定规划、几何规划、非线性规划,整数规划,多目标规划(分层序列法),最优控制(结合微分方程组)、变分法、动态规划,存贮论、代理模型、响…...

JavaScript 中的原型到底该如何理解?
JavaScript作为一个基于原型的OOP,和我们熟知的基于类的面向对象编程语言有很大的差异。如果不理解其中的本质含义,则无法深入理解JavaScript的诸多特性,以及由此产生的诸多“坑”。在讨论“原型”的概念之前,我们先来讨论一下“类…...
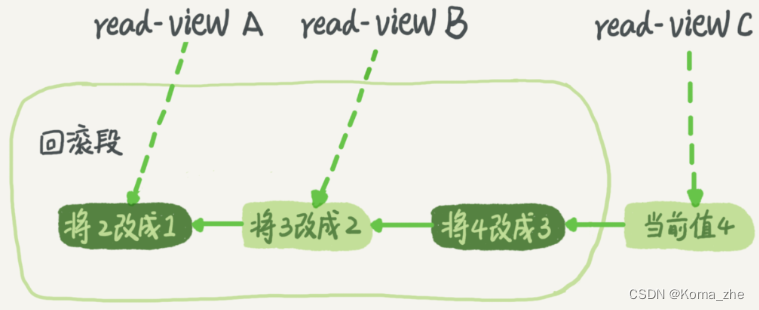
【MySQL基础】事务隔离03
目录 隔离性与隔离级别事务隔离的实现事务的启动方式MySQL事务代码示例 在MySQL中,事务支持是在引擎层实现的。MySQL是一个支持多引擎的系统,但并不是所有的引擎都支持事务。比如 MySQL 原生的 MyISAM 引擎就不支持事务,这也是 MyISAM 被 Inn…...

2023高教社杯数学建模C题思路分析 - 蔬菜类商品的自动定价与补货决策
# 1 赛题 在生鲜商超中,一般蔬菜类商品的保鲜期都比较短,且品相随销售时间的增加而变差, 大部分品种如当日未售出,隔日就无法再售。因此, 商超通常会根据各商品的历史销售和需 求情况每天进行补货。 由于商超销售的蔬菜…...

3步告别GitHub英文界面:GitHub中文化插件终极解决方案
3步告别GitHub英文界面:GitHub中文化插件终极解决方案 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 还在为GitHub的英文…...

Seraphine终极指南:英雄联盟免费智能助手,5分钟提升排位胜率15%
Seraphine终极指南:英雄联盟免费智能助手,5分钟提升排位胜率15% 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 还在为英雄联盟排位赛中的战绩查询和BP决策烦恼吗?Seraphin…...

基于RA4M2的便携GPS定位器开发:从硬件选型到低功耗优化全解析
1. 项目概述与核心价值最近在做一个挺有意思的小玩意儿,用瑞萨的RA4M2-SENSOR开发板,折腾出了一个巴掌大小的便携式GPS定位器。这玩意儿听起来好像没啥新鲜的,市面上成品一大堆,但自己从头到尾搭一遍,从选型、画板、写…...

零基础学 Web 安全 20256最全系统入门攻略
“未知攻,焉知防”——真正的安全始于理解攻击者的思维 在日益数字化的世界中,Web安全工程师已成为企业防护体系的“数字盾牌”。本文将提供一条清晰的进阶路径,助你在2025年的网络安全领域脱颖而出。 一、认知篇:理解安全本质 …...

如何做好费用率数据分析?巧用费用率研判企业盈利现状
企业经营发展过程中,盈利水平高低直接决定长远发展实力,而费用率数据是看透企业真实盈利水平最直观、最核心的指标。很多经营者在日常管理中,往往只看重账面营收的增长,却忽略了费用率数据的深层分析与解读,最终出现营…...

软件架构分析方法SAAM、ATAM与CBAM
一、SAAM(软件架构分析方法) 1. 核心思路 基于场景,评估架构对可修改性(以及可移植性、可扩充性)的支持程度。 关键是区分 直接场景(现有架构直接支持)和 间接场景(需要修改架构)。 通过分析间接场景的数量与修改代价,定位高风险、高耦合的模块。 2. 典型案例:内…...

零极点分析:从系统稳定性到滤波器设计的核心工程工具
1. 项目概述:从“系统行为”的根源说起在信号处理、控制理论乃至电路设计的日常工作中,我们常常需要面对一个核心问题:如何预测、分析和设计一个系统的动态行为?无论是设计一个能稳定跟踪目标的控制器,还是优化一个音频…...
)
微波遥感杂谈五(微波辐射计)
前言微波辐射计是通过被动的接收各个高度传来的温度辐射的微波信号来判断温度、 湿度曲线,能定量测量目标(如地物和大气各成分)的低电平微波辐射的高灵敏度接收装置。目前机载微波辐射计实测温度分辨率达0.02K,星载微波辐射计温度分辨率达 0.2࿵…...

机器学习论文阅读的解码协议:从扫读到复现的四步实战法
1. 为什么读论文这件事,比写代码还容易让人焦虑“How to Read Machine Learning Papers Effectively”——这个标题乍看像是一篇方法论指南,但在我带过三十多个算法实习生、审过两百多份顶会投稿、自己连续七年保持每周精读2–3篇NeurIPS/ICML/ACL论文的…...

向量化智能矩阵系统的语义坍塌:当10万条内容同时找“相似“,为什么你的数据库扛不住?
摘要:智能矩阵系统从"关键词匹配"进化到"语义匹配"之后,遇到了一个被严重低估的性能瓶颈——向量检索的语义坍塌。本文从向量数据库原理、ANN近似最近邻算法、HNSW图索引、向量量化技术四个底层技术出发,拆解向量化智能矩…...