在Spring Boot项目中使用JPA
1.集成Spring Data JPA
Spring Boot提供了启动器spring-boot-starter-data-jpa,只需要添加启动器(Starters)就能实现在项目中使用JPA。下面一步一步演示集成Spring Data JPA所需的配置。
步骤01 添加JPA依赖。
首先创建新的Spring Boot项目,在项目的pom.xml中增加JPA相关依赖,具体代码如下:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId>
</dependency>
在上面的示例中,除了引用spring-boot-starter-data-jpa之外,还需要依赖MySQL驱动mysql-connector-java。
步骤02 添加配置文件。
在application.properties中配置数据源和JPA的基本相关属性,具体代码如下:
spring.datasource.url=jdbc:mysql://Localhost:3306/ceshi?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#JPA配置
spring.jpa.properties.hibernate.hbm2ddl.auto=create
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialect
#SQL输出
spring.jpa.show-sql=true
#format 下SQL输出
spring.jpa.properties.hibernate.format_sql=true
在上面的参数中,主要是配置数据库的连接以及JPA的属性。下面重点分析一下JPA中的4个配置。
1)spring.jpa.properties.hibernate.hbm2ddl.auto:该配置比较常用,配置实体类维护数据库表结构的具体行为。当服务首次启动时会在数据库中生成相应的表,后续启动服务时,如果实体类有增加属性就会在数据中添加相应字段,原来的数据仍然存在。
- update:常用的属性,表示当实体类的属性发生变化时,表结构跟着更新。
- create:表示启动时删除上一次生成的表,并根据实体类重新生成表,之前表中的数据会被清空。
- create-drop:表示启动时根据实体类生成表,但是当sessionFactory关闭时表会被删除。
- validate:表示启动时验证实体类和数据表是否一致。
- none:什么都不做。
2)spring.jpa.show-sql:表示hibernate在操作时在控制台打印真实的SQL语句,便于调试。
3)spring.jpa.properties.hibernate.format_sql:表示格式化输出的JSON字符串,便于查看。
4)spring.jpa.properties.hibernate.dialect:指定生成表名的存储引擎为InnoDB。
步骤03 添加实体类。
首先,创建User实体类,它是一个实体类,同时也是定义数据库中的表结构的类,示例代码如下:
@Entity
@Table(name= "Users")
public class User {@GeneratedValue(strategy = GenerationType.IDENTITY)@Idprivate Long id;@Column(length = 64)private String name;@Column(length = 64)private String password;private int age;public User() {}public User(String name,String password, int age) {this.name=name;this.password=password;this.age=age;}public Long getId() {return id;}public void setId(Long id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public String getPassword() {return password;}public void setPassword(String password) {this.password = password;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "User{" +"id=" + id +", name='" + name + '\'' +", password='" + password + '\'' +", age=" + age +'}';}
}
在上面的示例中,使用@Table注解映射数据库中的表,使用@Column注解映射数据库中的字段。具体说明如下:
1)@Entity:必选的注解,声明这个类对应了一个数据库表。
2)@Table:可选的注解,声明了数据库实体对应的表信息,包括表名称、索引信息等。这里声明这个实体类对应的表名是Users。如果没有指定,则表名和实体的名称保持一致,与@Entity注解配合使用。
3)@Id注解:声明了实体唯一标识对应的属性。
4)@Column注解:用来声明实体属性的表字段的定义。默认的实体每个属性都对应表的一个字段,字段名默认与属性名保持一致。字段的类型根据实体属性类型自动对应。这里主要声明了字符字段的长度,如果不这么声明,则系统会采用255作为该字段的长度。
5)@GeneratedValue注解:设置数据库主键自动生成规则。strategy属性提供4种值:
- AUTO:主键由程序控制,是默认选项。
- IDENTITY:主键由数据库自动生成,即采用数据库ID自增长的方式,Oracle不支持这种方式。
- SEQUENCE:通过数据库的序列产生主键,通过@SequenceGenerator注解指定序列名,MySQL不支持这种方式。
- TABLE:通过特定的数据库表产生主键,使用该策略可以使应用更易于数据库移植。
除了上面使用到的@Entity注解、@Table注解等之外,还有一些常用的实体注解,具体说明如表9-1所示。这些注解用于描述实体对象与数据库字段的对应关系,需要注意的是,JPA与MyBatis是有区别的,千万别混淆。
步骤04 测试验证。
以上几步就是集成JPA的全部配置,配置完之后启动项目,就可以看到日志中显示如图所示的内容。
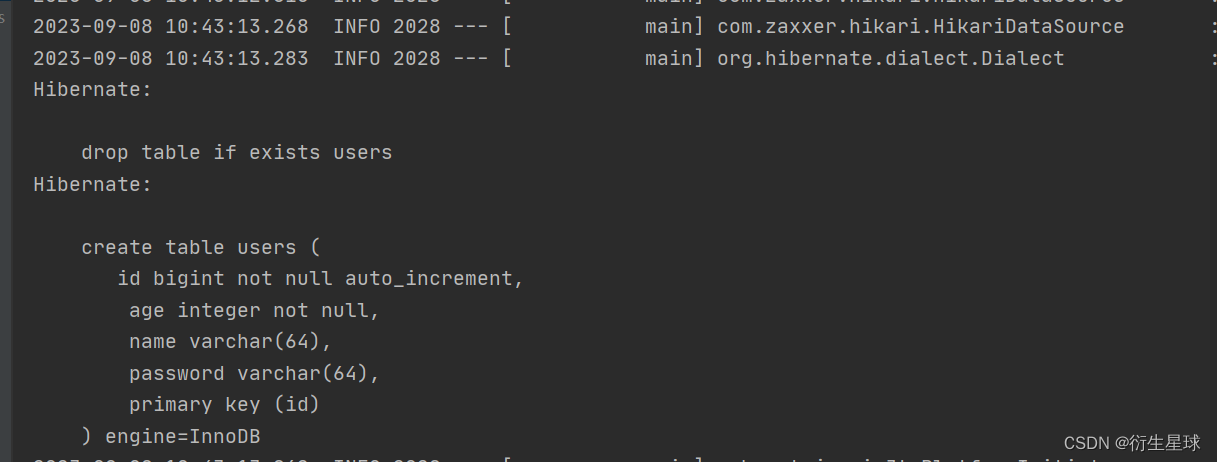
由图可知,系统启动后自动连接数据库,创建数据表结构,并打印出执行的SQL语句。如果查看数据库,可以看到数据库中对应的Users表也创建成功了,说明项目已经成功集成JPA并创建实体表。
2.JpaRepository简介
JpaRepository是Spring Data JPA中非常重要的类。它继承自Spring Data的统一数据访问接口——Repository,实现了完整的增、删、改、查等数据操作方法。JpaRepository提供了30多个默认方法,基本能满足项目中的数据库操作功能。
JpaRepository是实现Spring Data JPA技术访问数据库的关键接口。JpaRepository继承自PagingAndSortingRepository接口,而PagingAndSortingRepository接口继承自CrudRepository接口。CrudRepository和Repository接口则是Spring Data底层通用的接口,定义了几乎所有的数据库接口方法,统一了数据访问的操作。
另外,JPA提供了非常完善的数据查询功能,包括自定义查询、自定义SQL、已命名查询等多种数据查询方式。
3.实战:实现人员信息管理模块
JpaRespository默认实现完整的增、删、改、查等数据操作。只需定义一个Repository数据访问接口并继承JpaRepository类即可。下面通过之前创建的User用户类和表实现用户的增、删、改、查功能来演示用户管理模块的实现。
1. 定义Repository
首先创建UserRepository接口并加上@Repository注解,然后继承JpaRepository类,不需要编写任何代码,即可实现人员信息管理模块的全部功能。具体示例代码如下:
@Repository
public interface UserRepository extends JpaRepository<Users, Long> {}
我们看到UserRepository虽然什么方法都没有定义,但是继承了JpaRepository之后,自然就拥有JpaRepository中的所有方法。
2. 实现新增、修改、删除、查询
(1)新增
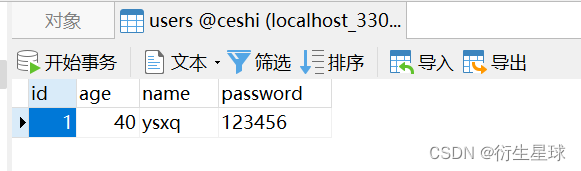
接下来创建UserRepositoryTests单元测试类,并实现用户新增的测试方法。示例代码如下:
@RunWith(SpringRunner.class)
@SpringBootTest
public class UserRepositoryTest {@Resourceprivate UserRepository userRepository;@Testpublic void testSave() {User user = new User("ysxq","123456",40);userRepository.save(user);}
}
在上面的示例中,在UserRepositoryTests单元测试类中注入UserRepository对象,然后使用JpaRespository预生成的save()方法实现人员数据保存的功能。如下图所示:

(2)修改
修改与新增都使用save()方法,传入数据实体即可。JPA自动根据主键id修改user数据。示例代码如下:
@Testpublic void testUpdate() {User user = userRepository.findById(1L).get();user.setPassword("z123456");userRepository.save(user);}
(3)删除
删除也非常简单,使用的是JpaRespository预生成的delete()方法,可以直接将对象删除,同时也可以使用deleteByXXX方法。示例代码如下:
@Testpublic void testDetle() {User user = new User("ysxq","123456",40);userRepository.delete(user); }
(4)查询
JPA对于数据查询的支持非常完善,有预生成的findById()、findAll()、findOne()等方法,也可以使用自定义的简单查询,还可以自定义SQL查询。示例代码如下:
@Testpublic void testSelect() {userRepository.findById(1L);}
3. 验证测试
单击Run Test或在方法上右击,选择Run 'UserRepositoryTest’命令,运行全部测试方法,结果如图所示。
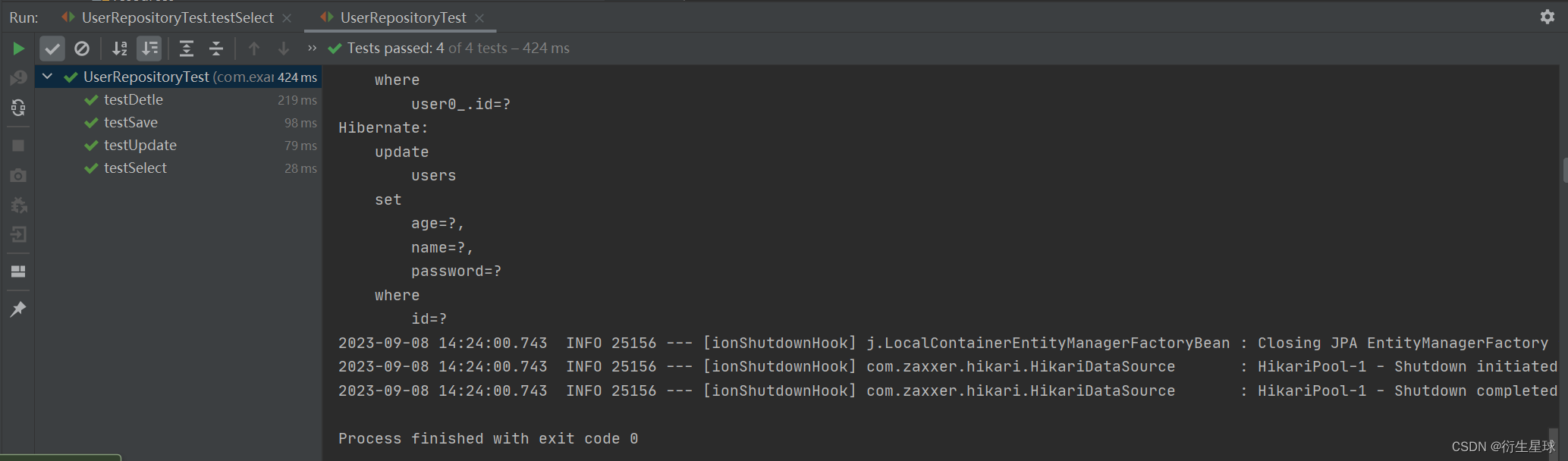
结果表明人员信息的增、删、改、查单元测试全部运行成功,并输出了相应的查询结果,说明使用JPA实现了人员信息管理功能。
相关文章:
在Spring Boot项目中使用JPA
1.集成Spring Data JPA Spring Boot提供了启动器spring-boot-starter-data-jpa,只需要添加启动器(Starters)就能实现在项目中使用JPA。下面一步一步演示集成Spring Data JPA所需的配置。 步骤01 添加JPA依赖。 首先创建新的Spring Boot项目…...

探讨Socks5代理IP在跨境电商与网络游戏中的网络安全应用
随着全球互联网的迅猛发展,跨境电商和在线游戏成为了跨国公司和游戏开发商的新战场。然而,与此同时,网络安全问题也日益突出。本文将探讨如何利用Socks5代理IP来增强跨境电商和网络游戏的网络安全,保障数据传输的隐私和安全性。 …...

T检验的前提条件|独立性|方差齐性|随机抽样
T检验是一种用于比较两组数据均值是否存在显著差异的统计方法,但在进行T检验之前,有一些前提条件需要满足,以确保结果的准确性和可靠性。这些前提条件包括: 正态性:T检验要求数据在每个组内都服从正态分布。正态性可以…...
【GO语言基础】变量常量
系列文章目录 【Go语言学习】ide安装与配置 【GO语言基础】前言 【GO语言基础】变量常量 【GO语言基础】数据类型 【GO语言基础】运算符 文章目录 系列文章目录常量和枚举变量声明全局变量声明大小写敏感 总结 常量和枚举 使用const关键字声明常量,并为每个常量提…...

C++QT day3
1> 自行封装一个栈的类,包含私有成员属性:栈的数组、记录栈顶的变量 成员函数完成:构造函数、析构函数、拷贝构造函数、入栈、出栈、清空栈、判空、判满、获取栈顶元素、求栈的大小 2> 自行封装一个循环顺序队列的类,包含…...
AI时代的较量,MixTrust能否略胜一筹?
人工智能的能力正在迅速接近人类,而在许多细分领域,已经超越了人类。虽然短期内这个突破是否会导致人工通用智能(AGI)还不清楚,但我们现在有的模型被训练成在数字交互中完美地模仿高能人类。尽管AGI仍不确定࿰…...
Ubuntu22.04 安装 MongoDB 7.0
稍微查了一些文章发现普遍比较过时。有的是使用旧版本的Ubuntu,或者安装的旧版本的MongoDB。英语可以的朋友可以移步Install MongoDB Community Edition on Ubuntu — MongoDB Manual,按照官方安装文档操作。伸手党或者英语略差的朋友可以按照本文一步步…...

【日志技术——Logback日志框架】
日志技术 1.引出 我们通常展示信息使用的是输出语句,但它有弊端,只能在控制台展示信息,不能灵活的指定日志输出的位置(文件,数据库),想加入或取消日志,需要修改源代码 2.日志技术…...

mysql存储过程和函数
存储过程语法 设置变量: set dogNum 1002; 1、无参的存储过程 delimiter $ CREATE PROCEDURE 存储过程名() begin 存储过程体 end $; 2、有参数的存储过程 delimiter $ CREATE PROCEDURE 存储过程名(in|out|inout 参数名1 参数类型,参数名2 参数类型……...

【HDFS】Hadoop-RPC:客户端侧通过Client.Connection#sendRpcRequest方法发送RPC序列化数据
org.apache.hadoop.ipc.Client.Connection#sendRpcRequest: 这个方法是客户端侧向服务端发送RPC请求的地方。调用点是Client#call方法过来的。 此方法代码注释里描述了一个细节:这个向服务端发送RPC请求数据的过程并不是由Connection线程发送的,而是其他的线程(sendParams…...
Java基于 SpringBoot 的车辆充电桩系统
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝30W,Csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 文章目录 1、效果演示效果图技术栈 2、 前言介绍(完整源码请私聊)3、主要技术3.4.1 …...

excel表导出
dto:查询条件所在的类 GetMapping(value "/downloadProject")ApiOperation("导出台账数据")AnonymousAccesspublic void queryDownload(Dto dto, HttpServletResponse response) throws IOException, ParseException {service.queryDownload(byPageDto, re…...

YOLOv8 快速入门
前言 本文是 YOLOv8 入门指南(大佬请绕过),将会详细讲解安装,配置,训练,验证,预测等过程 YOLOv8 官网:ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONN…...

HJ48 从单向链表中删除指定值的节点
Powered by:NEFU AB-IN Link 文章目录 HJ48 从单向链表中删除指定值的节点题意思路代码 HJ48 从单向链表中删除指定值的节点 题意 输入一个单向链表和一个节点的值,从单向链表中删除等于该值的节点,删除后如果链表中无节点则返回空指针。 思路 单向链表…...

Java缓存理解
CPU占用:如果你有某些应用需要消耗大量的cpu去计算,比如正则表达式,如果你使用正则表达式比较频繁,而其又占用了很多CPU的话,那你就应该使用缓存将正则表达式的结果给缓存下来。 数据库IO性能:如果发现有大…...

MHA高可用及故障切换
一、什么是 MHA MHA(MasterHigh Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。 MHA 的出现就是解决MySQL 单点的问题。 MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。 MHA能在故障切换的过程中最大…...

1000元订金?华为折叠屏手机MateX5今日开始预订,售价尚未公布
华为最新款折叠屏手机Mate X5今日在华为商城开始预订,吸引了众多消费者的关注。预订时需交纳1000元的订金,而具体售价尚未公布。据华为商城配置表显示,Mate X5预计将搭载Mate 60系列同款麒麟9000S处理器,或可能搭载麒麟9100处理器…...
Golang编写客户端SDK,并开源发布包到GitHub,供其他项目import使用
目录 编写客户端SDK,并开源发布包到GitHub1. 创建 GitHub 仓库2. 构建项目,编写代码Go 代码示例:项目目录结构展示: 3. 提交代码到 GitHub仓库4. 发布版本5. 现在其他人可以引用使用你的模块包了 编写客户端SDK,并开源…...

手写Mybatis:第10章-使用策略模式,调用参数处理器
文章目录 一、目标:参数处理器二、设计:参数处理器三、实现:参数处理器3.1 工程结构3.2 参数处理器关系图3.3 入参数校准3.4 参数策略处理器3.4.1 JDBC枚举类型修改3.4.2 类型处理器接口3.4.3 模板模式:类型处理器抽象基类3.4.4 类…...

pair 是 C++ 标准库中的一个模板类,用于存储两个对象的组合
pair 是 C 标准库中的一个模板类,用于存储两个对象的组合。它位于 <utility> 头文件中。 pair 类的定义如下: template <class T1, class T2> struct pair {T1 first;T2 second;pair();pair(const T1& x, const T2& y);template&l…...

51单片机实战:从零构建电子密码锁系统
1. 项目背景与硬件准备 第一次接触51单片机时,我就被它的实用性深深吸引。作为电子爱好者入门的最佳选择,STC89C52这款经典芯片就像乐高积木的基础模块——价格亲民(某宝20元就能买到开发板)、资源丰富(8K Flash、512…...

500套帐篷发往西非:我们凭什么拿下这单?
一句吐槽,让我们抓住了机会年初,天津京路发科技收到一封西非询盘:500套支架帐篷,用于安置点。客户顺带吐槽了一句:“之前的帐篷,没撑过上一个雨季。”我们懂了——价格不是关键,耐造才是。先看气…...

论文AI率高怎么降最安全?2026保姆级降AIGC工作流:实测权威指令揭秘与3款工具横评
辛辛苦苦肝了三个月的论文,可是一经过学校的AI检测系统,却给我标了个醒目的65%!这我真是百口莫辩!明明每一个观点、每一处引用,都是我一点点阅读文献琢磨出来的! 为了把要命的 AI率 打下来,我之…...

英雄联盟智能工具League Akari:从效率提升到战术优化的全方位解决方案
英雄联盟智能工具League Akari:从效率提升到战术优化的全方位解决方案 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾在英…...

Vue3+Element Plus+Sortable.js:构建可定制化表格拖拽配置中心
1. 为什么需要表格拖拽配置中心 后台管理系统中最常见的需求之一就是表格展示数据。但不同用户对表格的展示需求往往不同:产品经理可能更关注日期和状态字段,运营人员则更看重用户行为和转化数据。传统解决方案是开发多个固定表格页面,但这会…...
)
快速掌握C#语言基础知识点(17.委托)
关注我的动态 namespace _17.委托 {public delegate void doMyAction(); //委托,无参,无返回值public delegate int doPlus(int a, int b);//委托,有参,有返回值internal class Program{//委托成员变量public static doMyAction a…...
)
BeanUtils vs MapStruct:Java对象拷贝工具选型指南(附性能对比测试)
BeanUtils vs MapStruct:Java对象拷贝工具深度评测与选型指南 在Java开发中,对象属性拷贝是几乎每个项目都会遇到的常见需求。从简单的DTO转换到复杂的领域模型映射,选择高效、稳定的拷贝工具直接影响代码质量和系统性能。本文将深入对比Apac…...

考研数学二高数公式太多记不住?我用Python+Anki做了一个自动出题复习工具
用PythonAnki打造考研数学二高数公式智能复习系统 备考考研数学二的同学,最头疼的莫过于海量高数公式的记忆。泰勒展开、微分方程解法、伽玛函数...这些公式不仅抽象难懂,还容易混淆。传统死记硬背效率低下,而市面上的公式手册又缺乏互动性。…...

intv_ai_mk11实际作品:面向管理层的OKR撰写建议与周报优化样例
intv_ai_mk11实际作品:面向管理层的OKR撰写建议与周报优化样例 1. 为什么管理者需要AI辅助撰写OKR和周报 在快节奏的商业环境中,管理者常常面临一个共同挑战:如何高效地制定清晰可衡量的目标(OKR),同时保…...

颠覆级植物大战僵尸修改工具:一站式资源管理与战局掌控解决方案
颠覆级植物大战僵尸修改工具:一站式资源管理与战局掌控解决方案 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 还在为植物大战僵尸中阳光不足而焦虑吗?面对海量僵尸浪潮却束…...