短信过滤 APP 开发


本文字数:7033字
预计阅读时间:42分钟

一直想开发一个自己的短信过滤 APP,但是一直没有具体实施,现在终于静下心来,边开发边记录下整体的开发过程。
01
垃圾短信样本
遇到的第一个问题是,既然要过滤垃圾短信,那首先要识别哪些是垃圾短信?如何识别呢?
参考之前训练识别钢管计数的经验,决定通过 CoreML 训练 Text 模型来识别,那问题来了,要训练模型的短信数据集怎么来?
一开始打算网上找到垃圾短信样本,但找了好久没找到,于是就想到用自己和家人手机里的短信,毕竟手机里短信一般不删除,也有小几千条,而且垃圾短信、推销、广告之类的应有尽有。
所以问题就变成了,如何导出 iPhone 短信?
这里笔者也查了好久,找到的第三方软件基本都是需要收费,最终发现了一个免费导出的方案。
首先不加密备份手机到电脑,如下图,选中Back up all the data on your iPhone to this Mac,点击Back Up Now,等待备份完成,备份完成后,再点击Manage Backups :

Manage Backups 点击后,界面如下,可以看到已备份的记录,右键选择 Show In Finder,在文件夹中打开:
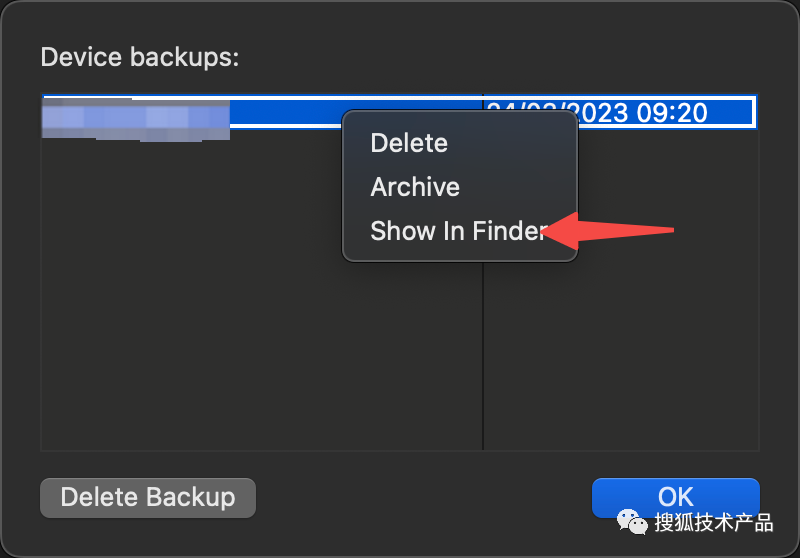
然后可以看到备份所在目录已打开,这时候需要找到文件名为 3d0d7e5fb2ce288813306e4d4636395e047a3d28的文件,这个文件就是短信备份的数据库文件。然后问题来了,怎么找呢?看到备份目录一个个文件夹是不是懵,这怎么找,很简单,搜索,点击右上角的搜索,直接把这个文件名输入即可,注意搜索的范围是当前文件夹:
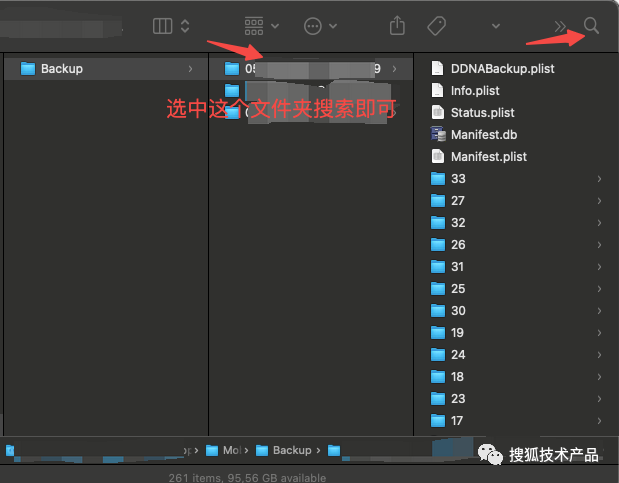
搜索结果如下:
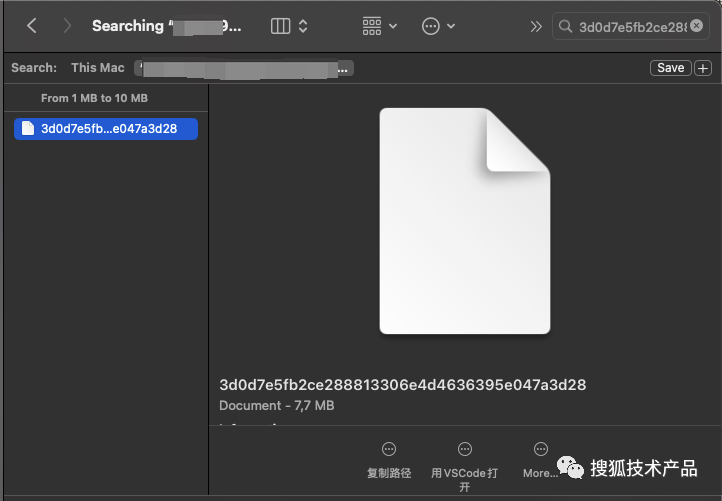
然后把这个文件单独拷贝到另一个地方,比如桌面,再用数据库软件打开,比如SQLPro for SQLLite,打开如下:

然后观察这个文件后发现,手机号和短信记录分布在不同表中,需要写一个 SQL 查出需要的内容,SQL 内容如下,参考 SQL to extract messages from backup,选中上图中Query,输入命令如下:
SELECT datetime(message.date, 'unixepoch', '+31 years', '-6 hours') as Timestamp, handle.id, message.text,case when message.is_from_me then 'From me' else 'To me' end as Sender
FROM message, handle WHERE message.handle_id = handle.ROWID AND message.text NOT NULL;然后点击右上角的执行, 可以看到,把短信都筛选出来了:
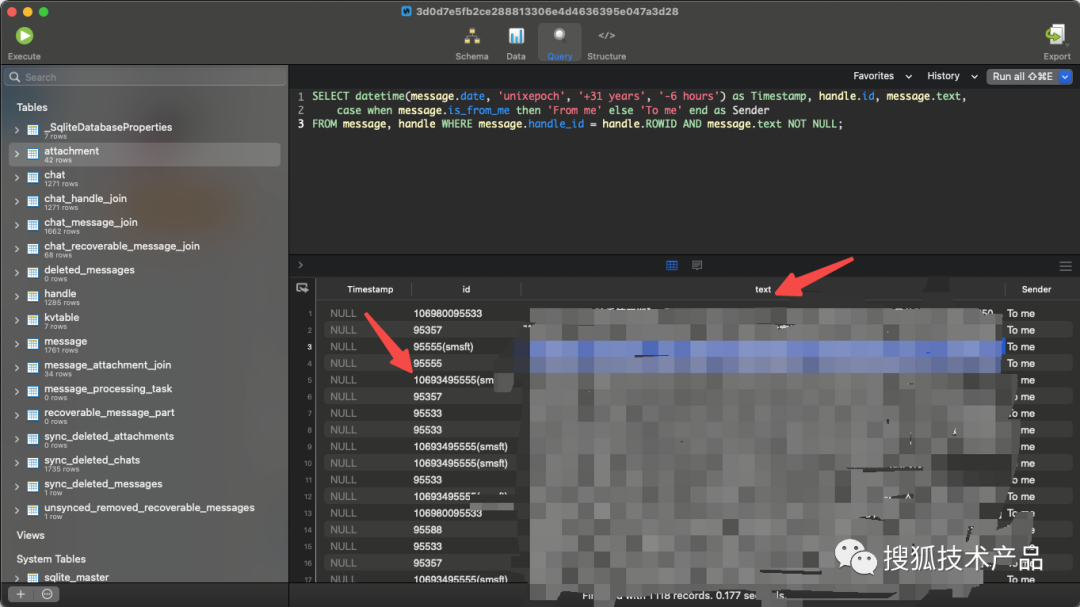
然后选中所有 row,右键选择Export result set as 导出CSV,即可导出 excel 格式的文件:
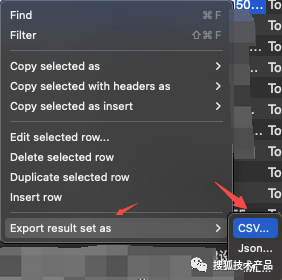
这样就获取到了所需的短信样本。
02
垃圾短信训练识别
有了样本之后,再来看如何训练识别,打算使用苹果的 CoreML识别,那么如何使用?样本格式的要求是什么样?训练需要多久?
先来看,创建一个文字训练的CoreML工程,选中 Xcode,点击Open Developer Tool,选中 CoreML 打开,如下图:

然后选择文件夹,并点击新建New Document, 如下:
然后选中 Text Classification,如下图:

接着输入项目的名字和描述:
点击右下角创建,进入主界面,如下:

点击 Traing Data 的详细说明,可以看到 CoreML 要求的文字识别的格式,支持 JSON 和 CSV 文件,格式如下:

JSON 格式如下:
// JSON file
[{"text": "The movie was fantastic!","label": "positive"}, {"text": "Very boring. Fell asleep.","label": "negative"}, {"text": "It was just OK.","label": "neutral"} ...
]而 CSV 格式则是,一列 text ,一列 label,
| text | label |
|---|---|
这是一条普通短信 | label1 |
| 这是一条垃圾短信 | label2 |
由于再前一步中,已经将短信导出为 CSV 格式,所以这里就需要把格式改为上图中格式即可,只剩下一个问题需要解决,即:label 有哪些取值?
要看 label 有哪些取值,需要先看系统短信的过滤逻辑是什么样?支持的过滤分类有哪些?否则自己想实现的分类,分组好了,最后发现系统不支持就尴尬了。
03
短信过滤分类
系统短信的过滤逻辑
参考 SMS and MMS Message Filtering,可以看到,开发者是没有权限创建新分组的,只能是针对收到未知联系人的 SMS 或者 MMS ,拦截返回指定的分类。
这里需要注意的是,根据文档的说法,短信过滤不支持 iMessage 和通讯录中联系人短信的过滤,仅支持未知联系人的 SMS 和 MMS。
短信过滤,又分为本地判断过滤和服务端判断过滤,示意图如下:
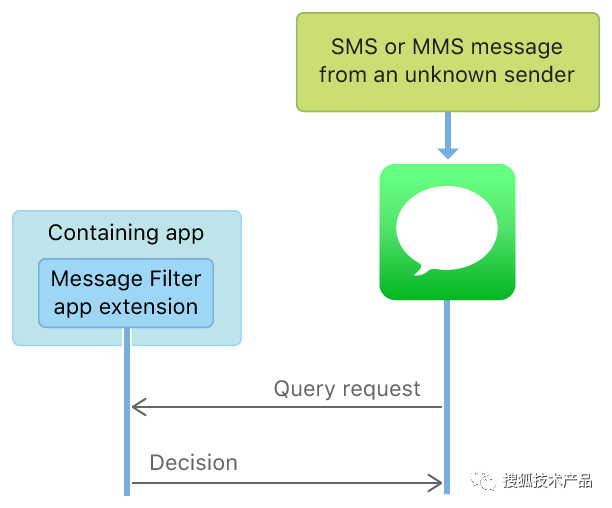
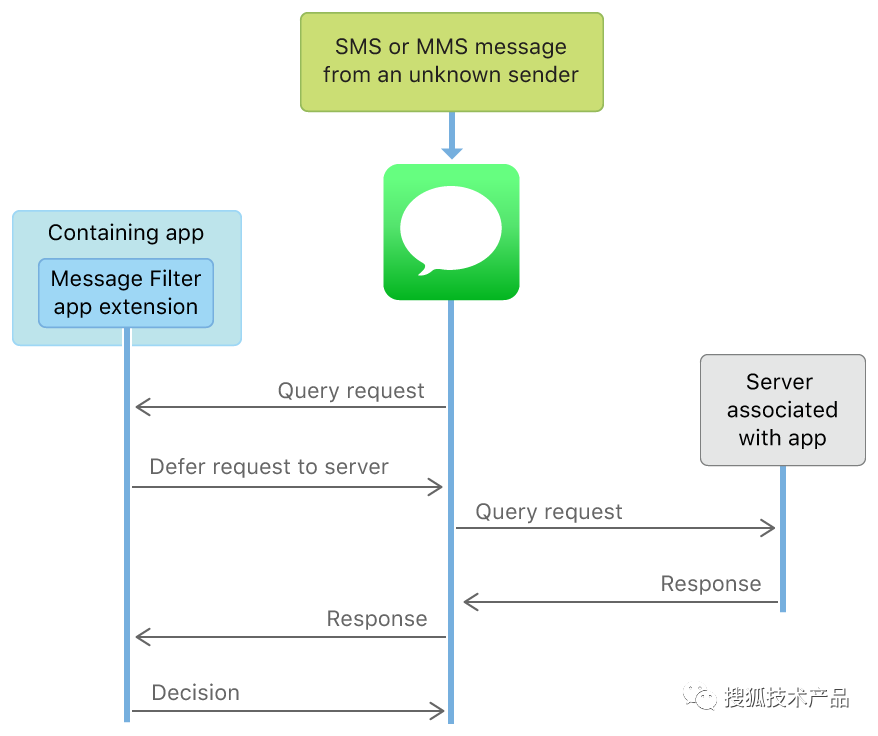
按照文档的说法,即使是服务端过滤,APP 也是不能直接访问网络的,系统会和设置的服务器交互;而且 App Extension 不能通过共享 Group 写数据,故而短信仅能在 App Extension中获取到,不能存储,不能上传,从而保证隐私和安全。关于服务端过滤更多的实现,可以参考 Creating a Message Filter App Extension。
再来看支持的过滤类型,ILMessageFilterAction大分类支持五种:
none 没有足够信息,不能判断,会展示信息,或进一步请求服务端判断过滤
allow 正常展示信息
junk 阻止正常展示信息,显示在垃圾短信分类下
promotion 阻止正常展示信息,显示在推送信息分类下
transation 阻止正常展示信息,显示在交易信息分类下
而其中又可以细分子分类,ILMessageFilterSubAction,具体含义可以参考ILMessageFilterSubAction:
none
promotion 支持的子分类有
others
offers
coupons
transation 支持的子分类有
others
finance
orders
reminders
health
weather
carrier
rewards
publicServices
这里仅针对大分类做处理,具体的子分类不做详细过滤,所以需要训练的 label 有哪些取值就很明确了,过滤垃圾短信、推广信息、交易信息,至于 none 和 allow 不做区分,统一处理为 allow,所以总共需要训练的 label 取值有以下这些:
allow
junk
promotion
transation
然后就是针对导出短信的 CSV 文件,针对每条短信,添加对应的 label,这里只能手工,样本的大小和 label 定义决定后续识别的准确度,同时为了后续子分类的实现,建议实事求是,不要把比如 promotion 里的分到 junk 里。。。
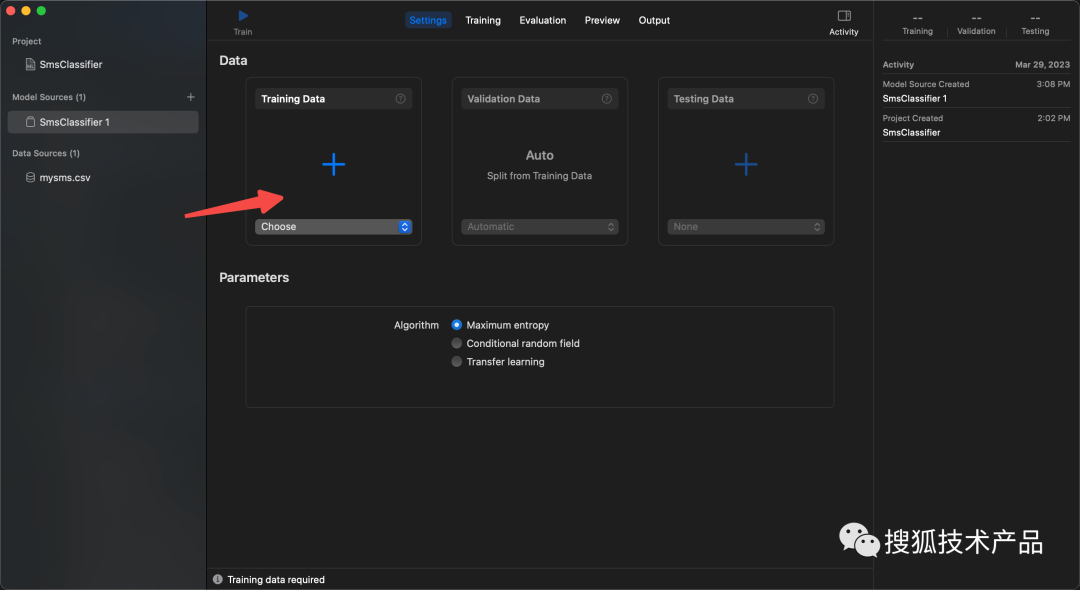
每条短信样本都标记好了之后,就可以导入Create ML来训练,生成需要的模型,步骤如下——
首先导入数据集:
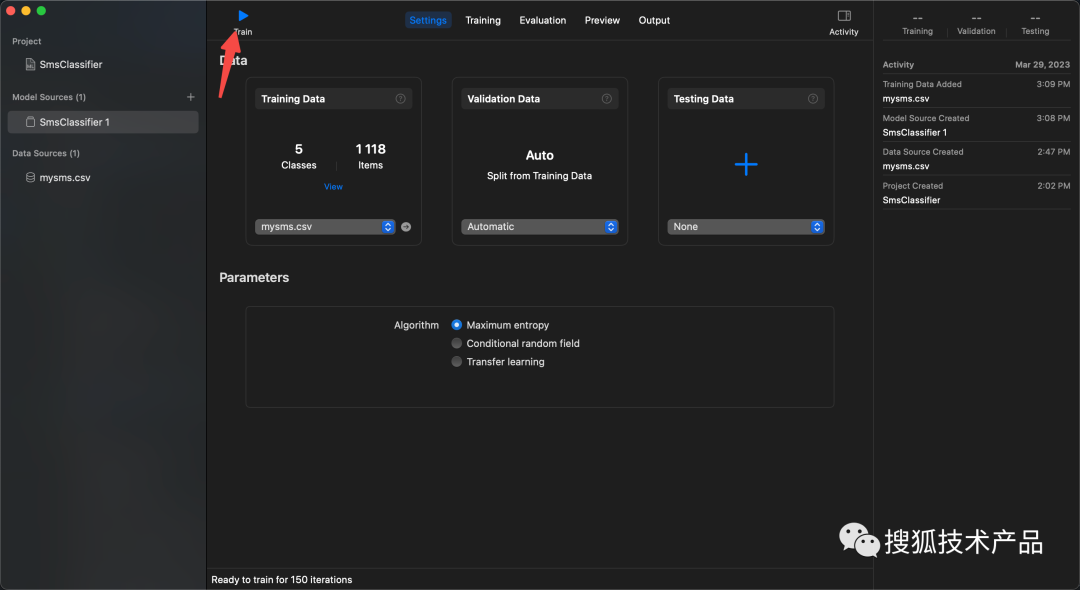
然后点击左上角的 Train:
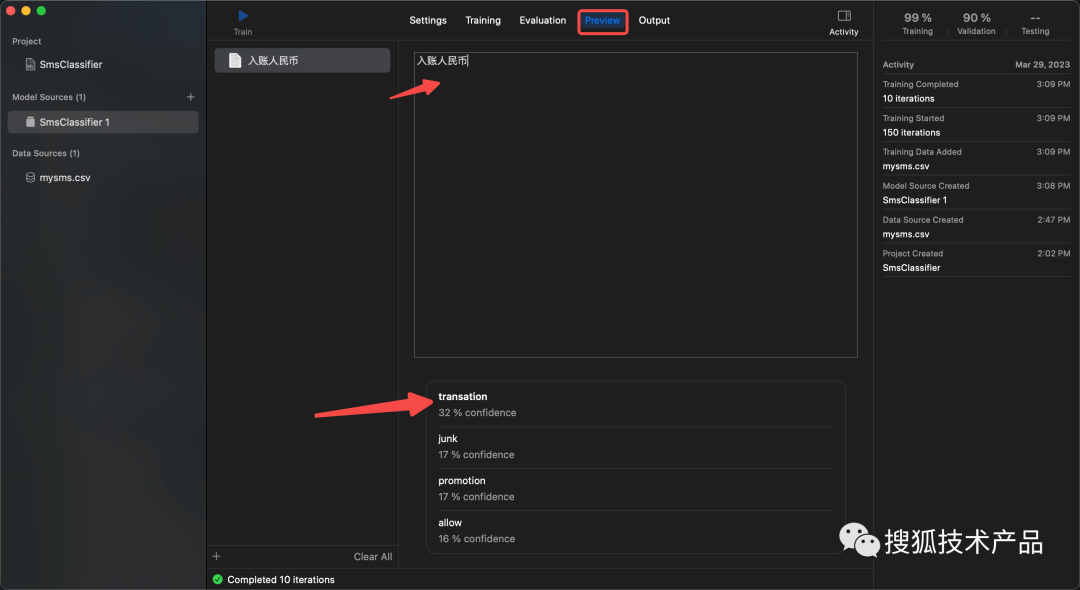
等训练好了之后,可以点击 Preview ,模拟短信文本,看输出的预测,如下图:
最后,导出模型,供 APP 使用:

导出模型
04
APP开发
新建项目,然后使用 "new bing生成图片" 来设计 APPIcon,再用 ChatGPT-4,来生成 APP 名字。然后添加 Message Filter Extension Target,如下图:
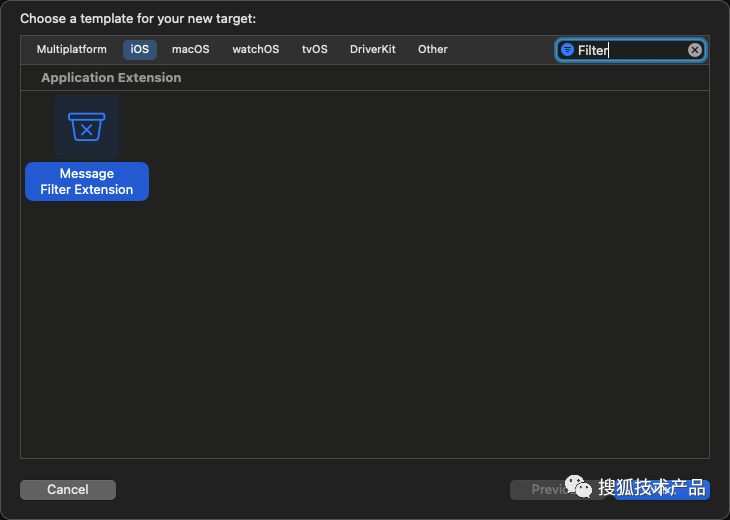
在 MessageFilterExtension.swift 中,能看到苹果已经帮忙实现了基本的框架,只需要在框架对应// TODO: 的地方,加入对应的过滤逻辑即可。
然后导入训练结果集到项目中,注意 Target 要勾选主工程和 Message Filter Extension 的 Target,因为需要在这个 Target 中使用模型来实现过滤。
具体使用如下:
import Foundation
import IdentityLookup
import CoreMLimport IdentityLookupenum SMSFilterActionType: String {case transationcase promotioncase allowcase junkfunc formatFilterAction() -> ILMessageFilterAction {switch self {case .transation:return ILMessageFilterAction.transactioncase .promotion:return ILMessageFilterAction.promotioncase .allow:return ILMessageFilterAction.allowcase .junk:return ILMessageFilterAction.junk}}
}struct SMSFilterUtil {static func filter(with messageBody: String) -> ILMessageFilterAction {var filterAction: ILMessageFilterAction = .nonelet configuration = MLModelConfiguration()do {let model = try SmsClassifier(configuration: configuration)let resultLabel = try model.prediction(text: messageBody).labelif let resultFilterAction = SMSFilterActionType(rawValue: resultLabel)?.formatFilterAction() {filterAction = resultFilterAction}} catch {print(error)}return filterAction}
}然后在MessageFilterExtension.Swift 中 offlineAction(for queryRequest: ILMessageFilterQueryRequest) -> (ILMessageFilterAction, ILMessageFilterSubAction) 方法调用,如下:
@available(iOSApplicationExtension 16.0, *)private func offlineAction(for queryRequest: ILMessageFilterQueryRequest) -> (ILMessageFilterAction, ILMessageFilterSubAction) {guard let messageBody = queryRequest.messageBody else {return (.none, .none)}let action = MWSMSFilterUtil.filter(with: messageBody)return (action, .none)}这里需要注意下 APP 最低版本设置,ILMessageFilterSubAction只有 iOS 16 以上的手机才支持,而 ILMessageFilterSubAction 则是 iOS 14 以上。
如果想实现更精细的 SubAction 的过滤,则上面短信数据集的 label需要改为更精细的 label,然后训练出模型,再用来判断。
另外,ILMessageFilterQueryRequest 中可以获取到 sender 和 messageBody,所以如果想实现自定义规则,比如针对某个手机号设置对应的规则,则需要从 APP 中设置对应的规则,然后通过 Group 共享到 Extension ,然后在上面的方法里通过规则匹配。
05
总结
相信通过上面的步骤,大家都能开发出自己的短信过滤 APP。
上面的步骤是通过固定的训练模型来匹配的逻辑,步骤是:
获取短信数据集
通过
CoreML使用数据集训练并生成模型在项目中使用模型,进行判断
这种方式生成的模型其数据固定,每次更新模型需要重新训练并导入,然后更新 APP。是否有更好的方式呢?比如是否可以在 APP 中边训练边更新?又或者是否可以通过本地规则加本地模型加网络模型这种方式?
假设方案一:
首先,在 APP 中边训练边更新,大概思路如下——
更新模型,需要知道一条数据的内容和数据的分类,所以如果要在 APP 中训练模型,就需要通过另外的办法获取到分类,要不然用模型得到分类再回过头来训练模型,意义不大。所以通过自定义规则获取到数据分类,然后用数据和数据分类来更新模型,这种方式应该是可行的。
假设方案二:
然后来考虑更完善的一种方式,即通过本地规则加本地模型加网络模型的方式:
逻辑是首先通过本地规则匹配,如果本地规则匹配不到,则继续使用本地模型匹配,如果本地模型也匹配不到,则通过请求服务端,服务端另有一套不断训练更新的模型,来获取对应的分类,最后每次更新时把服务端当前对应最新的模型更新到项目中。
假设方案三:
方案二需要通过网络模型,假设的前提是服务端有一套不断训练更新的模型,那如果这个假设不存在?只有本地规则和本地模型,外加偶尔获取到的更新数据集,是否有办法在线更新本地模型?
目前本地模型是直接添加到APP 主 Bundle 中,可以考虑在首次启动时拷贝到 APP 和Extension 的共享 Group 中,每次打开 APP 时,判断模型是否有更新,有更新则下载替换这个目录下的模型文件。在 Extension 中,通过 URL 获取这个目录下的模型文件来进行过滤。
几种方案流程图如下:

总结如下:
参考:
SQL to extract messages from backup
https://apple.stackexchange.com/questions/300866/sql-to-extract-messages-from-backup)
Creating a Text Classifier Model
https://developer.apple.com/documentation/createml/creating-a-text-classifier-model
SMS and MMS Message Filtering
https://developer.apple.com/documentation/sms_and_call_reporting/sms_and_mms_message_filtering
Creating a Message Filter App Extension
https://developer.apple.com/documentation/sms_and_call_reporting/sms_and_mms_message_filtering/creating_a_message_filter_app_extension
ILMessageFilterAction
https://developer.apple.com/documentation/sms_and_call_reporting/ilmessagefilteraction
相关文章:
短信过滤 APP 开发
本文字数:7033字 预计阅读时间:42分钟 一直想开发一个自己的短信过滤 APP,但是一直没有具体实施,现在终于静下心来,边开发边记录下整体的开发过程。 01 垃圾短信样本 遇到的第一个问题是,既然要过滤垃圾短信…...

【计算机基础知识7】垃圾回收机制与内存泄漏
目录 前言 一、垃圾回收机制的工作原理 1. 标记-清除算法的基本原理 2. 垃圾回收器的类型及其工作方式 3. 垃圾回收的回收策略和触发机制 三、内存泄漏的定义和原因 1. 内存泄漏的概念和影响 2. 常见的内存泄漏情况及其原因 四、如何避免和处理内存泄漏 1. 使用合适…...

[学习笔记]CS224W
资料: 课程网址 斯坦福CS224W图机器学习、图神经网络、知识图谱【同济子豪兄】 斯坦福大学CS224W图机器学习公开课-同济子豪兄中文精讲 图的基本表示 图是描述各种关联现象的通用语言。与传统数据分析中的样本服从独立同分布假设不一样,图数据自带关联…...
华为云API对话机器人CBS的魅力—实现简单的对话操作
云服务、API、SDK,调试,查看,我都行 阅读短文您可以学习到:人工智能AI智能的问答管理、全面的对话管理、高效训练部署 1.IntelliJ IDEA 之API插件介绍 API插件支持 VS Code IDE、IntelliJ IDEA等平台、以及华为云自研 CodeArts …...

精益制造、质量管控,盛虹百世慧共同启动MOM(制造运营管理)
百世慧科技依托在电池智能制造行业中的丰富经验,与盛虹动能达成合作,为其提供MOM制造运营管理平台,并以此为起点,全面提升盛虹动能的制造管理水平与运营体系。 行业困境 中国动力电池已然发展为全球最大的电池产业,但…...
【科研论文配图绘制】task7密度图绘制
【科研论文配图绘制】task7密度图绘制 task7 了解密度图的定义,清楚密度图是常用使用常见,掌握密度图绘制。 1.什么是密度图 密度图(Density Plot)是一种用于可视化数据分布的图表类型。它通过在数据中创建平滑的概率密度曲线…...

Python3 集合
Python3 集合 集合(set)是一个无序的不重复元素序列。 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。 创建格式: parame …...

【山河送书第十期】:《Python 自动化办公应用大全》参与活动,送书两本!!
【山河送书第十期】:《Python 自动化办公应用大全》参与活动,送书两本!! 前言一书籍亮点二作者简介三内容简介四购买链接五参与方式六往期赠书回顾 前言 在过去的 5 年里,Python 已经 3 次获得 TIOBE 指数年度大奖&am…...

Java多线程——同步
同步是什么? 当两个线程同时对一个变量进行修改时,不同的访问顺序会造成不一样的结果,这时候就需要同步保证结果的唯一性。 未同步时 新建Bank类,transfer()用于在两个账户之间转账金额 class Bank {private double[] account…...
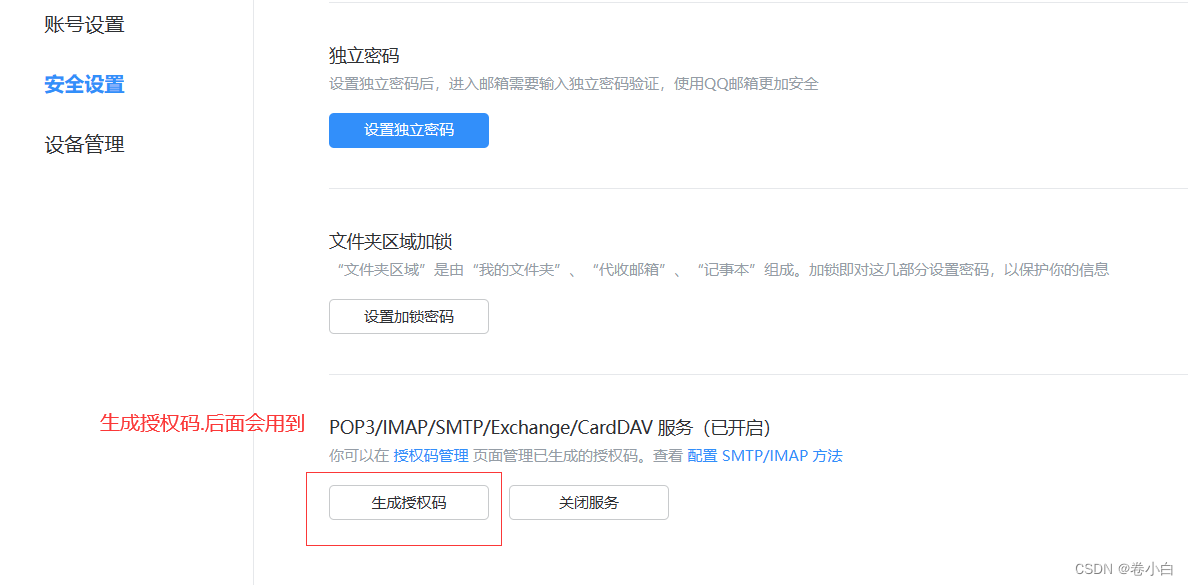
Vue+NodeJS实现邮件发送
一.邮箱配置 这里以QQ邮箱为例,网易邮箱类似. 设置->账号 二.后端服务搭建 index.js const express require(express) const router require(./router); const app express()// 使用路由文件 app.use(/,router);app.listen(3000, () > {console.log(server…...
TCP粘包)
Go语言网络编程(socket编程)TCP粘包
1、TCP粘包 服务端代码如下: // socket_stick/server/main.gofunc process(conn net.Conn) {defer conn.Close()reader : bufio.NewReader(conn)var buf [1024]bytefor {n, err : reader.Read(buf[:])if err io.EOF {break}if err ! nil {fmt.Println("read…...
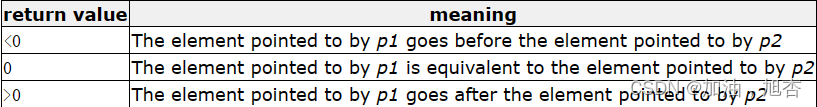
【再识C进阶2(中)】详细介绍指针的进阶——函数指针数组、回调函数、qsort函数
前言 💓作者简介: 加油,旭杏,目前大二,正在学习C,数据结构等👀 💓作者主页:加油,旭杏的主页👀 ⏩本文收录在:再识C进阶的专栏…...
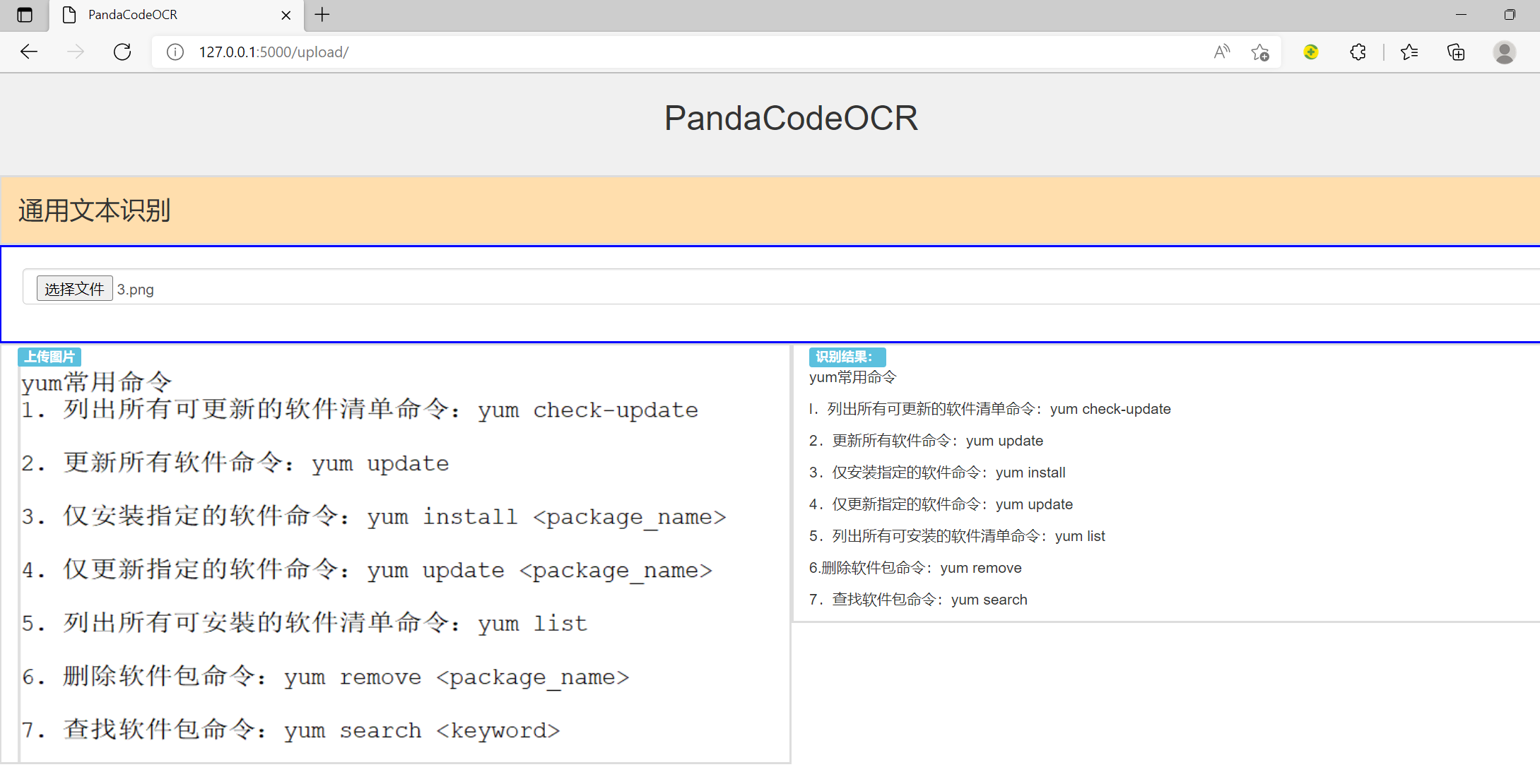
PaddleOCR学习笔记3-通用识别服务
今天优化了下之前的初步识别服务的python代码和html代码。 采用flask paddleocr bootstrap快速搭建OCR识别服务。 代码结构如下: 模板页面代码文件如下: upload.html : <!DOCTYPE html> <html> <meta charset"utf-8"> …...

9.8 校招 实习 内推 面经
绿泡*泡: neituijunsir 交流裙 ,内推/实习/校招汇总表格 1、校招 | 长安福特2024校园招聘正式启动 校招 | 长安福特2024校园招聘正式启动 2、2023校招总结--SLAM岗位 - 5 2023校招总结--SLAM岗位 - 5 3、校招&实习 | 格灵深瞳2024秋季校园招聘启…...

web前段与后端的区别优漫动游
要了解web前后端的区别,首先必须得清楚什么是web前端和web后端。 web前段与后端的区别 首先:web的本意是蜘蛛网和网的意思,在网页设计中我们称为网页的意思。现广泛译作网络、互联网等技术领域。表现为三种形式,即超文本(hyp…...
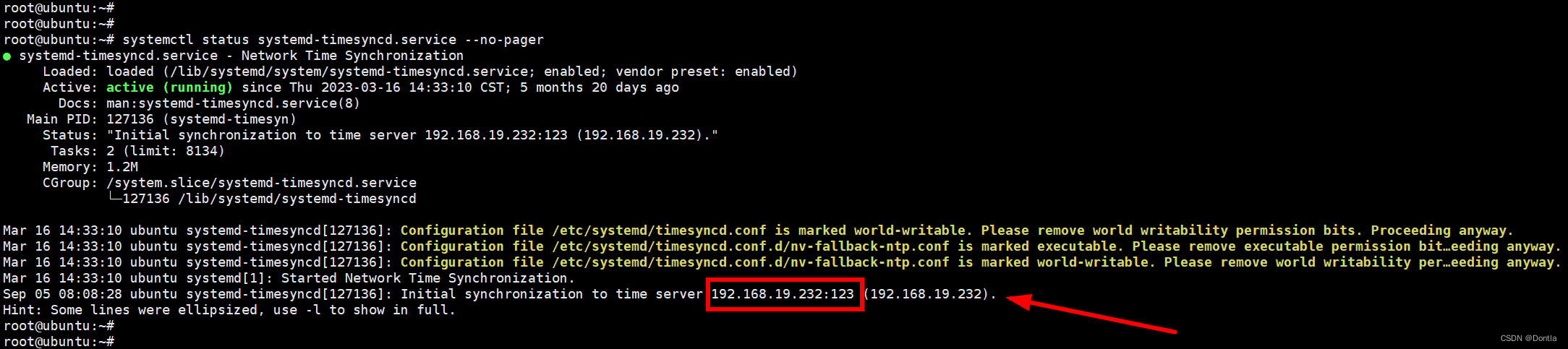
局域网ntp服务器设置(windows时间同步服务器NetTime)(ubuntu systemd-timesyncd ntp客户端)123端口、ntp校时
文章目录 背景windows如何配置ntp服务器手动配置配置参数AnnounceFlags和Enabled含义 使用软件配置(NetTime)实操相关疑问:0.nettime.pool.ntp.org是什么? 注意事项请务必检查windows主机123端口是否已被占用,方法请参…...

【个人博客系统网站】我的博客列表页 · 增删改我的博文 · 退出登录 · 博客详情页 · 多线程应用
【JavaEE】进阶 个人博客系统(4) 文章目录 【JavaEE】进阶 个人博客系统(4)1. 增加博文1.1 预期效果1.1 约定前后端交互接口1.2 后端代码1.3 前端代码1.4 测试 2. 我的博客列表页2.1 期待效果2.2 显示用户信息以及博客信息2.2.1…...

安全狗陈奋:数据安全需要建立在传统网络安全基础之上
8月22日-23日,由创业邦主办的“2023 DEMO WORLD 企业开放式创新大会”在上海顺利举行。 作为国内云原生安全领导厂商,安全狗受邀出席此次活动。 本次大会以“拥抱开放”为主题,聚焦开放式创新,通过演讲分享、专场对接、需求发布…...
【Redis】深入探索 Redis 的数据类型 —— 哈希表 hash
文章目录 前言一、hash 类型相关命令1.1 HSET 和 HSETNX1.2 HGET 和 HMGET1.3 HKEYS、HVALS 和 HGETALL1.4 HEXISTS 和 HDEL1.5 HLEN1.6 HINCRBY 和 HINCRBYFLOAT1.7 哈希相关命令总结 二、hash 类型内部编码三、hash 类型的应用场景四、原生,序列化,哈希…...
)
网络安全应急响应典型案例-(DDOS类、僵尸网络类、数据泄露类)
一、DDOS类事件典型案例 DDOS攻击,即分布式拒绝服务攻击,其目的在于使目标电脑的网络或系统资源耗尽,使服务暂时中断或停止,导致其正常用户无法访问。CC攻击使用代理服务器向受害服务器发送大量貌似合法的请求(通常…...

CVPR2019 Oral论文DVC复现指南:用TensorFlow搭建你的第一个端到端深度学习视频压缩模型
CVPR2019 Oral论文DVC复现实战:从零构建端到端视频压缩模型 视频压缩技术正经历从传统编码标准向深度学习范式的革命性转变。2019年CVPR Oral论文《DVC: An End-to-end Deep Video Compression Framework》首次提出了完整的端到端深度学习视频压缩框架,其…...

运营商网络工程师视角:VoWiFi部署中的ePDG与AAA服务器配置要点及避坑指南
运营商网络工程师实战:VoWiFi部署中ePDG与AAA服务器配置的20个关键细节 当运营商开始规划VoWiFi网络时,会议室的白板上总是画满了各种接口和协议栈。但真正决定项目成败的,往往是那些容易被忽略的配置细节——比如IKEv2协商时DH组的选择会怎样…...

DeepSeek代码能力实测:3大编程范式通过率对比,92.7%准确率背后的5个隐藏陷阱
更多请点击: https://intelliparadigm.com 第一章:DeepSeek HumanEval测试全景概览 HumanEval 是由 OpenAI 提出的函数级代码生成基准测试集,包含 164 道 Python 编程题,每道题提供函数签名、文档字符串(docstring&am…...

将Taotoken作为内部AI中台统一对接各类客户端工具
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将Taotoken作为内部AI中台统一对接各类客户端工具 设想一个中型研发团队,内部已经引入了Claude Code、OpenClaw等多种A…...

科研工作流构建指南:从文献管理到论文写作的全流程工具链实践
1. 项目概述与核心价值 如果你是一名在读的硕士、博士研究生,或者刚刚踏入科研院所、企业研发部门的新人研究员,那么“如何高效地开展研究”这个问题,大概率会持续困扰你很长一段时间。从浩如烟海的文献中精准定位方向,到设计严谨…...

互联网大厂 Java 求职面试技巧揭秘
互联网大厂 Java 求职面试技巧揭秘 在当今互联网大厂求职面试中,技术与场景的交汇点常常成为面试官考察的重点。本文将通过一位搞笑的程序员燕双非与严肃的面试官的对话,展示 Java 技术栈下的面试问题,并深入解答其中的技术要点。第一轮面试 …...

3分钟完成Windows和Office永久激活:KMS智能激活脚本终极指南
3分钟完成Windows和Office永久激活:KMS智能激活脚本终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?Office突然变成只读模式让你工…...

抖音无水印下载神器:douyin-downloader完整指南,轻松保存高清视频
抖音无水印下载神器:douyin-downloader完整指南,轻松保存高清视频 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and …...

京东自动评价工具:3分钟解决购物评价难题的智能助手
京东自动评价工具:3分钟解决购物评价难题的智能助手 【免费下载链接】jd_AutoComment 自动评价,仅供交流学习之用 项目地址: https://gitcode.com/gh_mirrors/jd/jd_AutoComment 还在为购物后的评价烦恼吗?每次收到京东的"待评价"提醒&…...

D26: 向下负责——保护团队免受 AI 焦虑影响
文章目录 D26: 向下负责——保护团队免受 AI 焦虑影响 🎯 为什么这个话题重要? 现实痛点:团队 AI 焦虑的三种表现 一个真实场景 一、理解 AI 焦虑的本质 1.1 焦虑从何而来? 1.2 焦虑的恶性循环 1.3 一个心理学视角 二、建立团队心理安全网 2.1 心理安全:团队韧性的基石 2…...