MybatisPlus 核心功能 条件构造器 自定义SQL Service接口 静态工具
MybatisPlus 快速入门 常见注解 配置_软工菜鸡的博客-CSDN博客
2.核心功能
刚才的案例中都是以id为条件的简单CRUD,一些复杂条件的SQL语句就要用到一些更高级的功能了。
2.1.条件构造器
除了新增以外,修改、删除、查询的SQL语句都需要指定where条件。因此BaseMapper中提供的相关方法除了以id作为where条件以外,还支持更加复杂的where条件。

参数中的Wrapper就是条件构造的抽象类,其下有很多默认实现,继承关系如图:

Wrapper的子类AbstractWrapper提供了where中包含的所有条件构造方法:

而QueryWrapper在AbstractWrapper的基础上拓展了一个select方法,允许指定查询字段:

而UpdateWrapper在AbstractWrapper的基础上拓展了一个set方法,允许指定SQL中的SET部分:

接下来,我们就来看看如何利用Wrapper实现复杂查询。

2.1.1.QueryWrapper
无论是修改、删除、查询,都可以使用QueryWrapper来构建查询条件。接下来看一些例子:
查询:查询出名字中带o的,存款大于等于1000元的人。代码如下:
@Test
void testQueryWrapper() {// 1.构建查询条件 where name like "%o%" AND balance >= 1000QueryWrapper<User> wrapper = new QueryWrapper<User>().select("id", "username", "info", "balance").like("username", "o").ge("balance", 1000);// 2.查询数据List<User> users = userMapper.selectList(wrapper);users.forEach(System.out::println);
}更新:更新用户名为jack的用户的余额为2000,代码如下:
@Test
void testUpdateByQueryWrapper() {// 1.构建查询条件 where name = "Jack"QueryWrapper<User> wrapper = new QueryWrapper<User>().eq("username", "Jack");// 2.更新数据,user中非null字段都会作为set语句User user = new User();user.setBalance(2000);userMapper.update(user, wrapper);
}2.1.2.UpdateWrapper
基于BaseMapper中的update方法更新时只能直接赋值,对于一些复杂的需求就难以实现。
例如:更新id为1,2,4的用户的余额,扣200,对应的SQL应该是:
UPDATE user SET balance = balance - 200 WHERE id in (1, 2, 4)SET的赋值结果是基于字段现有值的,这个时候就要利用UpdateWrapper中的setSql功能 来-200了:
@Test
void testUpdateWrapper() {List<Long> ids = List.of(1L, 2L, 4L);// 1.生成SQLUpdateWrapper<User> wrapper = new UpdateWrapper<User>().setSql("balance = balance - 200") // SET balance = balance - 200.in("id", ids); // WHERE id in (1, 2, 4)// 2.更新,注意第一个参数可以给null,也就是不填更新字段和数据,// 而是基于UpdateWrapper中的setSQL来更新userMapper.update(null, wrapper);
}2.1.3.LambdaQueryWrapper
无论是QueryWrapper还是UpdateWrapper在构造条件的时候都需要写死字段名称,会出现字符串魔法值。这在编程规范中显然是不推荐的。
那怎么样才能不写字段名,又能知道字段名呢?
其中一种办法是基于变量的gettter方法结合反射技术。因此我们只要将条件对应的字段的getter方法传递给MybatisPlus,它就能计算出对应的变量名了。而传递方法可以使用JDK8中的方法引用和Lambda表达式。
因此MybatisPlus又提供了一套基于Lambda的Wrapper,包含两个:
- LambdaQueryWrapper
- LambdaUpdateWrapper
分别对应QueryWrapper和UpdateWrapper
其使用方式如下:
@Test
void testLambdaQueryWrapper() {// 1.构建条件 WHERE username LIKE "%o%" AND balance >= 1000QueryWrapper<User> wrapper = new QueryWrapper<>();wrapper.lambda().select(User::getId, User::getUsername, User::getInfo, User::getBalance).like(User::getUsername, "o").ge(User::getBalance, 1000);// 2.查询List<User> users = userMapper.selectList(wrapper);users.forEach(System.out::println);
}2.2.自定义SQL
在演示UpdateWrapper的案例中,我们在代码中编写了更新的SQL语句:

这种写法在某些企业也是不允许的,因为SQL语句最好都维护在持久层,而不是业务层。就当前案例来说,由于条件是in语句,只能将SQL写在Mapper.xml文件,利用foreach来生成动态SQL。
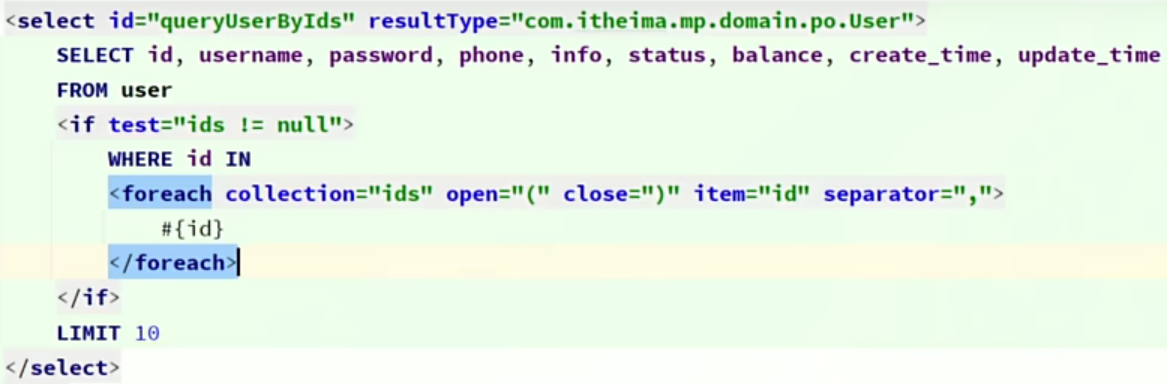
这实在是太麻烦了。假如查询条件更复杂,动态SQL的编写也会更加复杂。
所以,MybatisPlus提供了自定义SQL功能,可以让我们利用Wrapper生成查询条件,再结合Mapper.xml编写SQL

2.2.1.基本用法
以当前案例来说,我们可以这样写:
@Test
void testCustomWrapper() {// 1.准备自定义查询条件List<Long> ids = List.of(1L, 2L, 4L);QueryWrapper<User> wrapper = new QueryWrapper<User>().in("id", ids);// 2.调用mapper的自定义方法,直接传递WrapperuserMapper.deductBalanceByIds(200, wrapper);
}然后在UserMapper中自定义SQL:
public interface UserMapper extends BaseMapper<User> {@Select("UPDATE user SET balance = balance - #{money} ${ew.customSqlSegment}")void deductBalanceByIds(@Param("money") int money, @Param("ew") QueryWrapper<User> wrapper);
}这样就省去了编写复杂查询条件的烦恼了。
2.2.2.多表关联
理论上来将MyBatisPlus是不支持多表查询的,不过我们可以利用Wrapper中自定义条件结合自定义SQL来实现多表查询的效果。
例如,我们要查询出所有收货地址在北京的并且用户id在1、2、4之中的用户
要是自己基于mybatis实现SQL,大概是这样的:
<select id="queryUserByIdAndAddr" resultType="com.itheima.mp.domain.po.User">SELECT *FROM user uINNER JOIN address a ON u.id = a.user_idWHERE u.id<foreach collection="ids" separator="," item="id" open="IN (" close=")">#{id}</foreach>AND a.city = #{city}</select>可以看出其中最复杂的就是WHERE条件的编写,如果业务复杂一些,这里的SQL会更变态。但是基于自定义SQL结合Wrapper的玩法,我们就可以利用Wrapper来构建查询条件,然后手写SELECT及FROM部分,实现多表查询。
查询条件这样来构建:
@Test
void testCustomJoinWrapper() {// 1.准备自定义查询条件QueryWrapper<User> wrapper = new QueryWrapper<User>().in("u.id", List.of(1L, 2L, 4L)).eq("a.city", "北京");// 2.调用mapper的自定义方法List<User> users = userMapper.queryUserByWrapper(wrapper);users.forEach(System.out::println);
}然后在UserMapper中自定义方法:
@Select("SELECT u.* FROM user u INNER JOIN address a ON u.id = a.user_id ${ew.customSqlSegment}")
List<User> queryUserByWrapper(@Param("ew")QueryWrapper<User> wrapper);当然,也可以在UserMapper.xml中写SQL:
<select id="queryUserByIdAndAddr" resultType="com.itheima.mp.domain.po.User">SELECT * FROM user u INNER JOIN address a ON u.id = a.user_id ${ew.customSqlSegment}
</select>2.3.Service接口
关于mybatis-plus中Service和Mapper的分析
MybatisPlus不仅提供了BaseMapper,还提供了通用的Service接口及默认实现,封装了一些常用的service模板方法。

通用接口为IService,默认实现为ServiceImpl,其中封装的方法可以分为几类:
save:新增remove:删除update:更新get:查询单个结果list:查询集合结果count:计数page:分页查询
2.3.1.CRUD
我们先俩看下基本的CRUD接口。
新增:
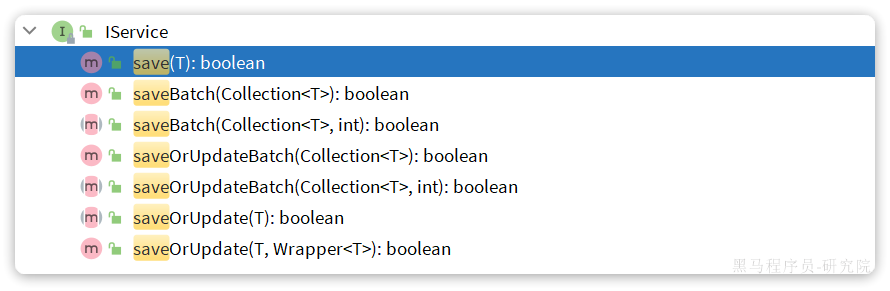
save是新增单个元素saveBatch是批量新增saveOrUpdate是根据id判断,如果数据存在就更新,不存在则新增saveOrUpdateBatch是批量的新增或修改
删除:
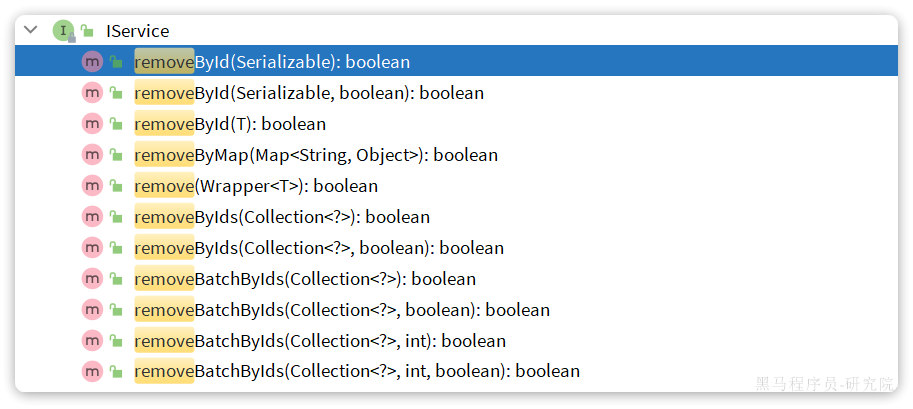
removeById:根据id删除removeByIds:根据id批量删除removeByMap:根据Map中的键值对为条件删除remove(Wrapper<T>):根据Wrapper条件删除~~removeBatchByIds~~:暂不支持
修改:
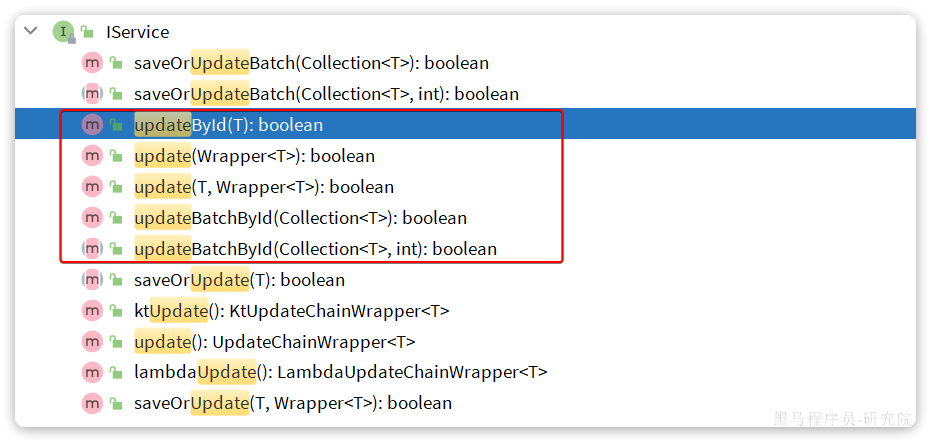
updateById:根据id修改update(Wrapper<T>):根据UpdateWrapper修改,Wrapper中包含set和where部分update(T,Wrapper<T>):按照T内的数据修改与Wrapper匹配到的数据updateBatchById:根据id批量修改
Get:
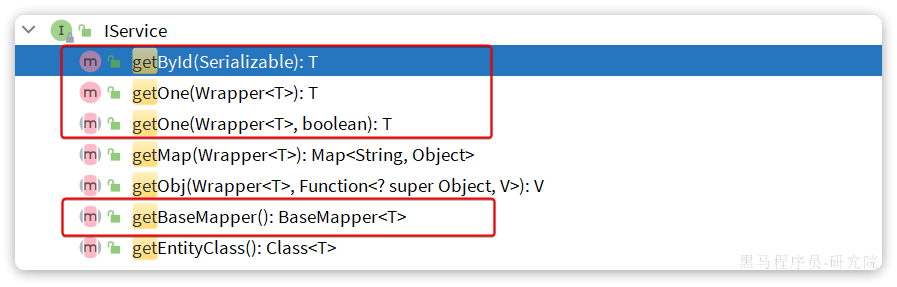
getById:根据id查询1条数据getOne(Wrapper<T>):根据Wrapper查询1条数据getBaseMapper:获取Service内的BaseMapper实现,某些时候需要直接调用Mapper内的自定义SQL时可以用这个方法获取到Mapper
List:

listByIds:根据id批量查询list(Wrapper<T>):根据Wrapper条件查询多条数据list():查询所有
Count:

count():统计所有数量count(Wrapper<T>):统计符合Wrapper条件的数据数量
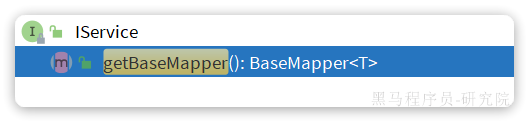
getBaseMapper:
当我们在service中要调用Mapper中自定义SQL时,就必须获取service对应的Mapper,就可以通过这个方法:
2.3.2.基本用法
由于Service中经常需要定义与业务有关的自定义方法,因此我们不能直接使用IService,而是自定义Service接口,然后继承IService以拓展方法。同时,让自定义的Service实现类继承ServiceImpl,这样就不用自己实现IService中的接口了。

首先,定义UserService,继承IService:
package com.itheima.mp.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.itheima.mp.domain.po.User;public interface UserService extends IService<User> {// 拓展自定义方法
}然后,编写UserServiceImpl类,继承ServiceImpl,实现UserService:
package com.itheima.mp.service.impl;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.itheima.mp.domain.po.User;
import com.itheima.mp.domain.po.service.UserService;
import com.itheima.mp.mapper.UserMapper;
import org.springframework.stereotype.Service;@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}项目结构如下:
最后,编写一个测试类,测试一下:
package com.itheima.mp.service;import com.itheima.mp.domain.po.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.util.List;import static org.junit.jupiter.api.Assertions.*;@SpringBootTest
class UserServiceTest {@AutowiredUserService userService;@Testvoid testService() {List<User> list = userService.list();list.forEach(System.out::println);}
}2.3.3.批量新增
IService中的批量新增功能使用起来非常方便,但有一点注意事项,我们来测试一下。
首先我们测试逐条插入数据:
@Test
void testSaveOneByOne() {long b = System.currentTimeMillis();for (int i = 1; i <= 100000; i++) {userService.save(buildUser(i));}long e = System.currentTimeMillis();System.out.println("耗时:" + (e - b));
}private User buildUser(int i) {User user = new User();user.setUsername("user_" + i);user.setPassword("123");user.setPhone("" + (18688190000L + i));user.setBalance(2000);user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");user.setCreateTime(LocalDateTime.now());user.setUpdateTime(user.getCreateTime());return user;
}执行结果如下:

可以看到速度非常慢。
然后再试试MybatisPlus的批处理:
@Test
void testSaveBatch() {// 准备10万条数据List<User> list = new ArrayList<>(1000);long b = System.currentTimeMillis();for (int i = 1; i <= 100000; i++) {list.add(buildUser(i));// 每1000条批量插入一次if (i % 1000 == 0) {userService.saveBatch(list);list.clear();}}long e = System.currentTimeMillis();System.out.println("耗时:" + (e - b));
}执行最终耗时如下:

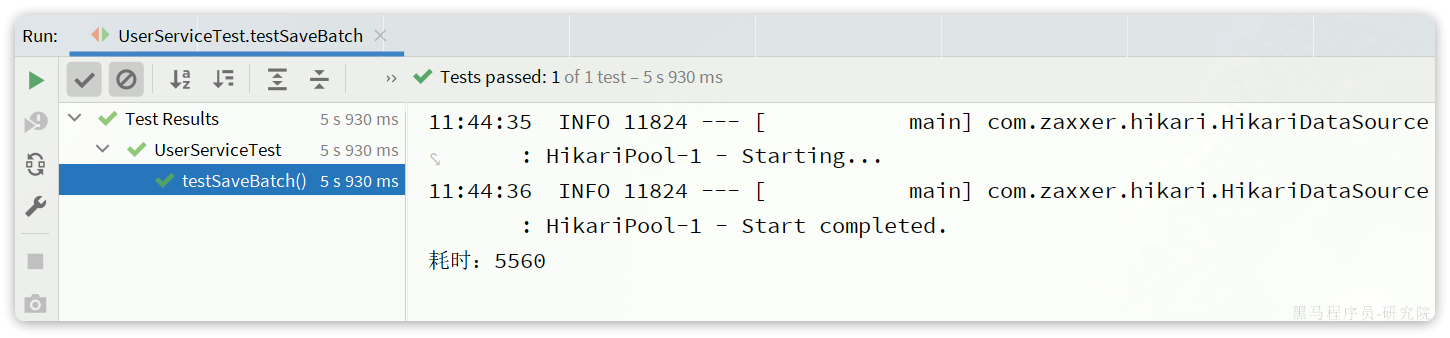
可以看到使用了批处理以后,比逐条新增效率提高了10倍左右,性能还是不错的。
不过,我们简单查看一下MybatisPlus源码:
@Transactional(rollbackFor = Exception.class)
@Override
public boolean saveBatch(Collection<T> entityList, int batchSize) {String sqlStatement = getSqlStatement(SqlMethod.INSERT_ONE);return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));
}
// ...SqlHelper
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {Assert.isFalse(batchSize < 1, "batchSize must not be less than one");return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, sqlSession -> {int size = list.size();int idxLimit = Math.min(batchSize, size);int i = 1;for (E element : list) {consumer.accept(sqlSession, element);if (i == idxLimit) {sqlSession.flushStatements();idxLimit = Math.min(idxLimit + batchSize, size);}i++;}});
}可以发现其实MybatisPlus的批处理是基于PrepareStatement的预编译模式,然后批量提交,最终在数据库执行时还是有多条insert语句,逐条插入数据。SQL类似这样:
Preparing: INSERT INTO user ( username, password, phone, info, balance, create_time, update_time ) VALUES ( ?, ?, ?, ?, ?, ?, ? )
Parameters: user_1, 123, 18688190001, "", 2000, 2023-07-01, 2023-07-01
Parameters: user_2, 123, 18688190002, "", 2000, 2023-07-01, 2023-07-01
Parameters: user_3, 123, 18688190003, "", 2000, 2023-07-01, 2023-07-01而如果想要得到最佳性能,最好是将多条SQL合并为一条,像这样:
INSERT INTO user ( username, password, phone, info, balance, create_time, update_time )
VALUES
(user_1, 123, 18688190001, "", 2000, 2023-07-01, 2023-07-01),
(user_2, 123, 18688190002, "", 2000, 2023-07-01, 2023-07-01),
(user_3, 123, 18688190003, "", 2000, 2023-07-01, 2023-07-01),
(user_4, 123, 18688190004, "", 2000, 2023-07-01, 2023-07-01);该怎么做呢?
MySQL的客户端连接参数中有这样的一个参数:rewriteBatchedStatements。顾名思义,就是重写批处理的statement语句。参考文档:
cj-conn-prop_rewriteBatchedStatements
这个参数的默认值是false,我们需要修改连接参数,将其配置为true
修改项目中的application.yml文件,在jdbc的url后面添加参数&rewriteBatchedStatements=true:
spring:datasource:url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=truedriver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: MySQL123再次测试插入10万条数据,可以发现速度有非常明显的提升:
在ClientPreparedStatement的executeBatchInternal中,有判断rewriteBatchedStatements值是否为true并重写SQL的功能:
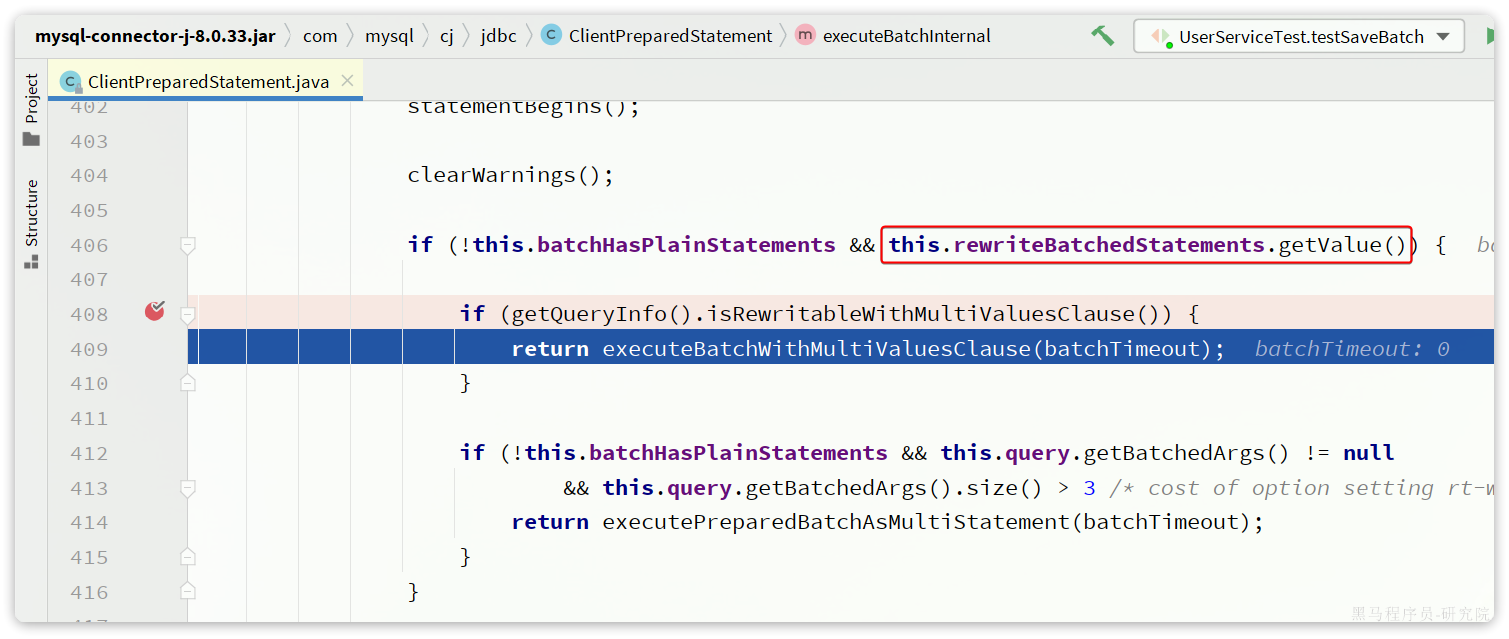
最终,SQL被重写了:


2.3.4.Lambda
Service中对LambdaQueryWrapper和LambdaUpdateWrapper的用法进一步做了简化。我们无需自己通过new的方式来创建Wrapper,而是直接调用lambdaQuery和lambdaUpdate方法:
基于Lambda查询:
@Test
void testLambdaQuery() {// 1.查询1个User rose = userService.lambdaQuery().eq(User::getUsername, "Rose").one(); // .one()查询1个System.out.println("rose = " + rose);// 2.查询多个List<User> users = userService.lambdaQuery().like(User::getUsername, "o").list(); // .list()查询集合users.forEach(System.out::println);// 3.count统计Long count = userService.lambdaQuery().like(User::getUsername, "o").count(); // .count()则计数System.out.println("count = " + count);
}可以发现lambdaQuery方法中除了可以构建条件,而且根据链式编程的最后一个方法来判断最终的返回结果,可选的方法有:
.one():最多1个结果.list():返回集合结果.count():返回计数结果
lambdaQuery还支持动态条件查询。比如下面这个需求:
定义一个方法,接收参数为username、status、minBalance、maxBalance,参数可以为空。
如果username参数不为空,则采用模糊查询;
如果status参数不为空,则采用精确匹配;
如果minBalance参数不为空,则余额必须大于minBalance
如果maxBalance参数不为空,则余额必须小于maxBalance
这个需求就是典型的动态查询,在业务开发中经常碰到,实现如下:
@Test
void testQueryUser() {List<User> users = queryUser("o", 1, null, null);users.forEach(System.out::println);
}public List<User> queryUser(String username, Integer status, Integer minBalance, Integer maxBalance) {return userService.lambdaQuery().like(username != null , User::getUsername, username).eq(status != null, User::getStatus, status).ge(minBalance != null, User::getBalance, minBalance).le(maxBalance != null, User::getBalance, maxBalance).list();
}基于Lambda更新:
@Test
void testLambdaUpdate() {userService.lambdaUpdate().set(User::getBalance, 800) // set balance = 800.eq(User::getUsername, "Jack") // where username = "Jack".update(); // 执行Update
}lambdaUpdate()方法后基于链式编程,可以添加set条件和where条件。但最后一定要跟上update(),否则语句不会执行。
lambdaUpdate()同样支持动态条件,例如下面的需求:
基于IService中的lambdaUpdate()方法实现一个更新方法,满足下列需求:
1 参数为balance、id、username
2 id或username至少一个不为空,根据id或username精确匹配用户
3 将匹配到的用户余额修改为balance
4 如果balance为0,则将用户status修改为冻结状态(2)
实现如下:
@Test
void testUpdateBalance() {updateBalance(0L, 1L, null);
}public void updateBalance(Long balance, Long id, String username){userService.lambdaUpdate().set(User::getBalance, balance).set(balance == 0, User::getStatus, 2).eq(id != null, User::getId, id).eq(username != null, User::getId, username).update();
}2.4.静态工具
有的时候Service之间也会相互调用,为了避免出现循环依赖问题,可以调用Service 的mapper或者MybatisPlus提供一个静态工具类:Db,其中的一些静态方法与IService中方法签名基本一致,也可以帮助我们实现CRUD功能:
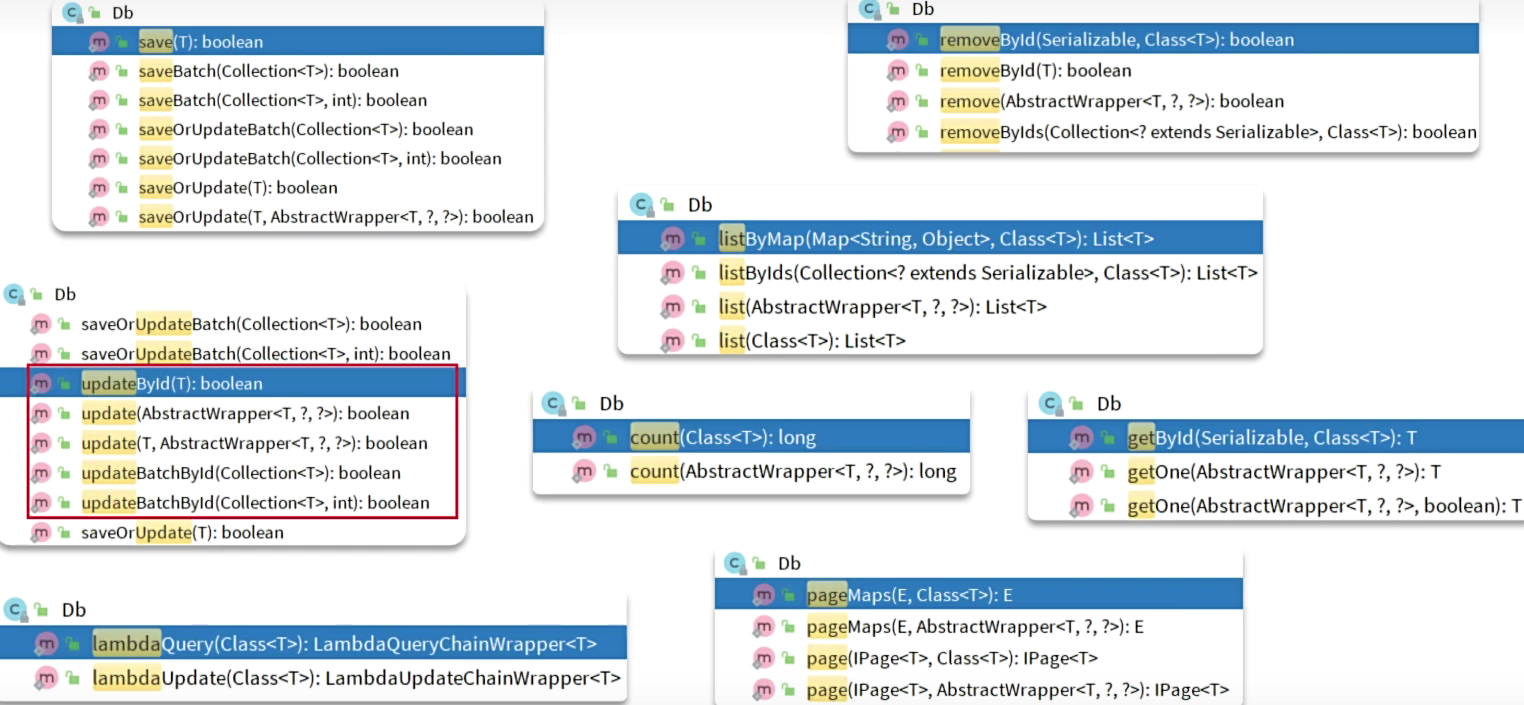
Db的静态方法与IService中方法区别:除了save、update其他的参数带class类,然后就知道要操作哪个表了
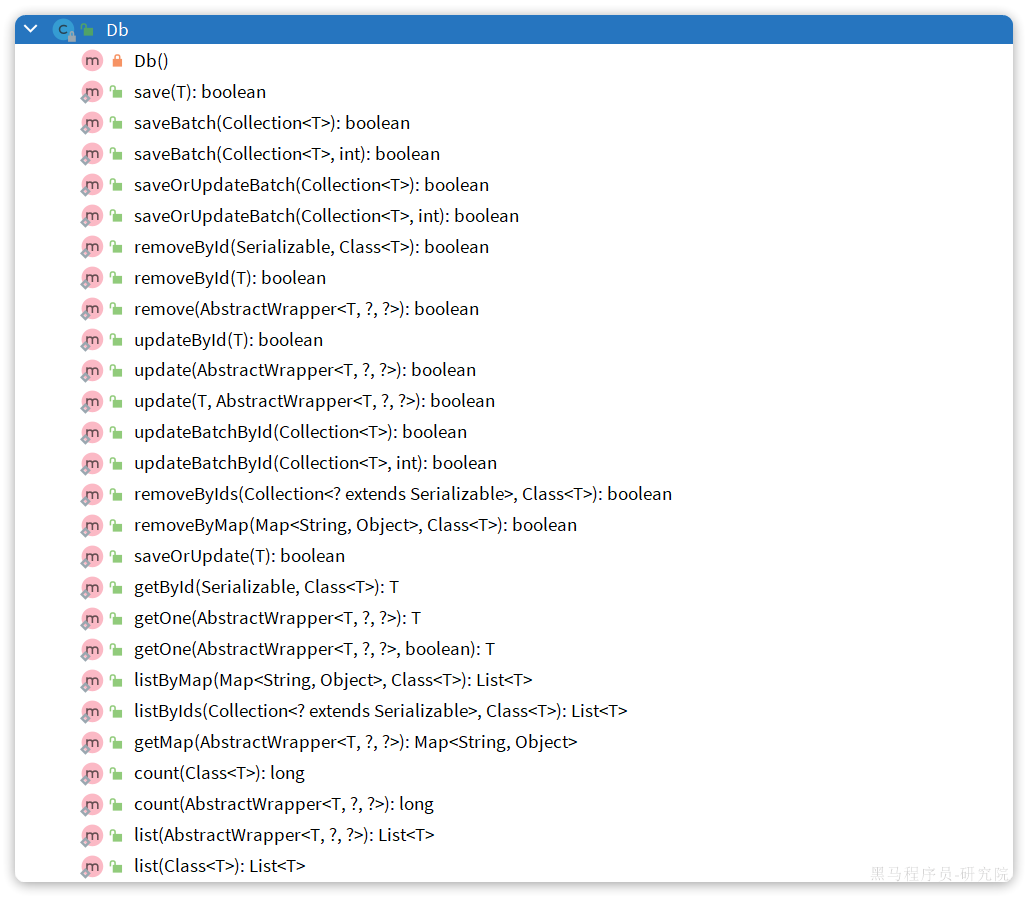
示例:
@Test
void testDbGet() {User user = Db.getById(1L, User.class);System.out.println(user);
}@Test
void testDbList() {// 利用Db实现复杂条件查询List<User> list = Db.lambdaQuery(User.class).like(User::getUsername, "o").ge(User::getBalance, 1000).list();list.forEach(System.out::println);
}@Test
void testDbUpdate() {Db.lambdaUpdate(User.class).set(User::getBalance, 2000).eq(User::getUsername, "Rose");
}相关文章:
MybatisPlus 核心功能 条件构造器 自定义SQL Service接口 静态工具
MybatisPlus 快速入门 常见注解 配置_软工菜鸡的博客-CSDN博客 2.核心功能 刚才的案例中都是以id为条件的简单CRUD,一些复杂条件的SQL语句就要用到一些更高级的功能了。 2.1.条件构造器 除了新增以外,修改、删除、查询的SQL语句都需要指定where条件。因此…...
TSN时间敏感网络
目录 时间敏感网络介绍 子协议介绍 时间同步 IEEE802.1AS 调度和流量整形 IEEE802.1Q IEEE802.1Qbv IEEE802.1cr IEEE802.1Qbu IEEE802.1Qch IEEE802.1Qav IEEE802.1Qcc 纠错机制与安全 IEEE802.1Qci IEEE802.1CB IEEE802.1Qca 参考 时间敏感网络介绍 TSN(Tim…...

【2023年数学建模国赛】C题解题思路
第一问 要求分析分析蔬菜各品类及单品销售量的分布规律及相互关系。该问题可以拆分成三个角度进行剖析。 1)各种类蔬菜的销售量分布、蔬菜种类与销售量之间的关系;2)各种类蔬菜的销售量的月份分布、各种类蔬菜销售量与月份之间的相关关系&a…...

5分钟 将“.py”文件转为“.pyd”文件
代码: from distutils.core import setup from distutils.extension import Extension from Cython.Build import cythonize import osfile_list os.listdir("./") extensions [] for file in file_list:if file.endswith(".py") and file !…...
)
python 入门到精通(一)
文章目录 1.使用pycharm进行第一个程序的编写2.python基础语法篇2.1 常用的值类型2.2 注释2.3 变量2.4 数据类型2.5 数据类型转换2.6 什么是标识符2.7 运算符2.8 字符串扩展2.8.1 字符串拼接2.8.2 字符串格式化2.8.3 格式化的精度控制2.8.4 字符串格式化 - 快速写法2.8.5 字符串…...
异步的JavaScript 和 XML)
AJAX (Asynchronous JavaScript And XML)异步的JavaScript 和 XML
1、概念 Asynchronous JavaScript And XML 异步的JavaScript 和 XML异步和同步:客户端和服务器端相互通信的基础上 同步:客户端必须等待服务端的响应。在等待的期间客户端不能做其他操作。异步:客户端不需要等待服务器端的响应。在服务器…...
华为云云耀云服务器L实例评测|安装Java8环境 配置环境变量 spring项目部署 【!】存在问题未解决
目录 引出安装JDK8环境查看是否有默认jar上传Linux版本的jar包解压压缩包配置环境变量 上传jar包以及运行问题上传Jar包运行控制台开放端口访问失败—见问题记录关闭Jar的方式1.进程kill -92.ctrl c退出 问题记录:【!】未解决各种方式查看端口情况联系工程师最后排查…...
安卓多渠道打包(五)360加固walle多渠道打包
背景: 1、360加固宝,签名收費了,脚本上传加固也针对特定帐号才可实现。 内容 本文将会分享安卓项目中,使用360加固,再用walle签名,产出多渠道加固包的全流程。 环境 win10 jdk11 as2022 gradle7.5 最…...

Jmeter 实现 mqtt 协议压力测试
1. 下载jmeter,解压 https://jmeter.apache.org/download_jmeter.cgi 以 5.4.3 为例,下载地址: https://dlcdn.apache.org//jmeter/binaries/apache-jmeter-5.4.3.zip linux下解压: unzip apache-jmeter-5.4.3.zip 2. 下载m…...
蓝桥杯官网练习题(凑算式)
类似填空题: ①算式900: https://blog.csdn.net/s44Sc21/article/details/132746513?spm1001.2014.3001.5501https://blog.csdn.net/s44Sc21/article/details/132746513?spm1001.2014.3001.5501 ②九宫幻方③七星填数④幻方填空:https:/…...
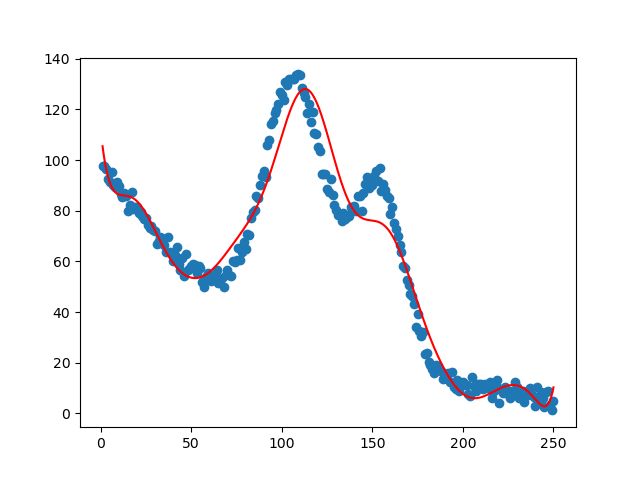
机器学习实战-系列教程5:手撕线性回归4之非线性回归(项目实战、原理解读、源码解读)
🌈🌈🌈机器学习 实战系列 总目录 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 手撕线性回归1之线性回归类的实现 手撕线性回归2之单特征线性回归 手撕线性回归3之多特征线性回归 手撕线性回归4之非线性回归 1…...

【C语言基础】那些你可能不知道的C语言“潜规则”
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...
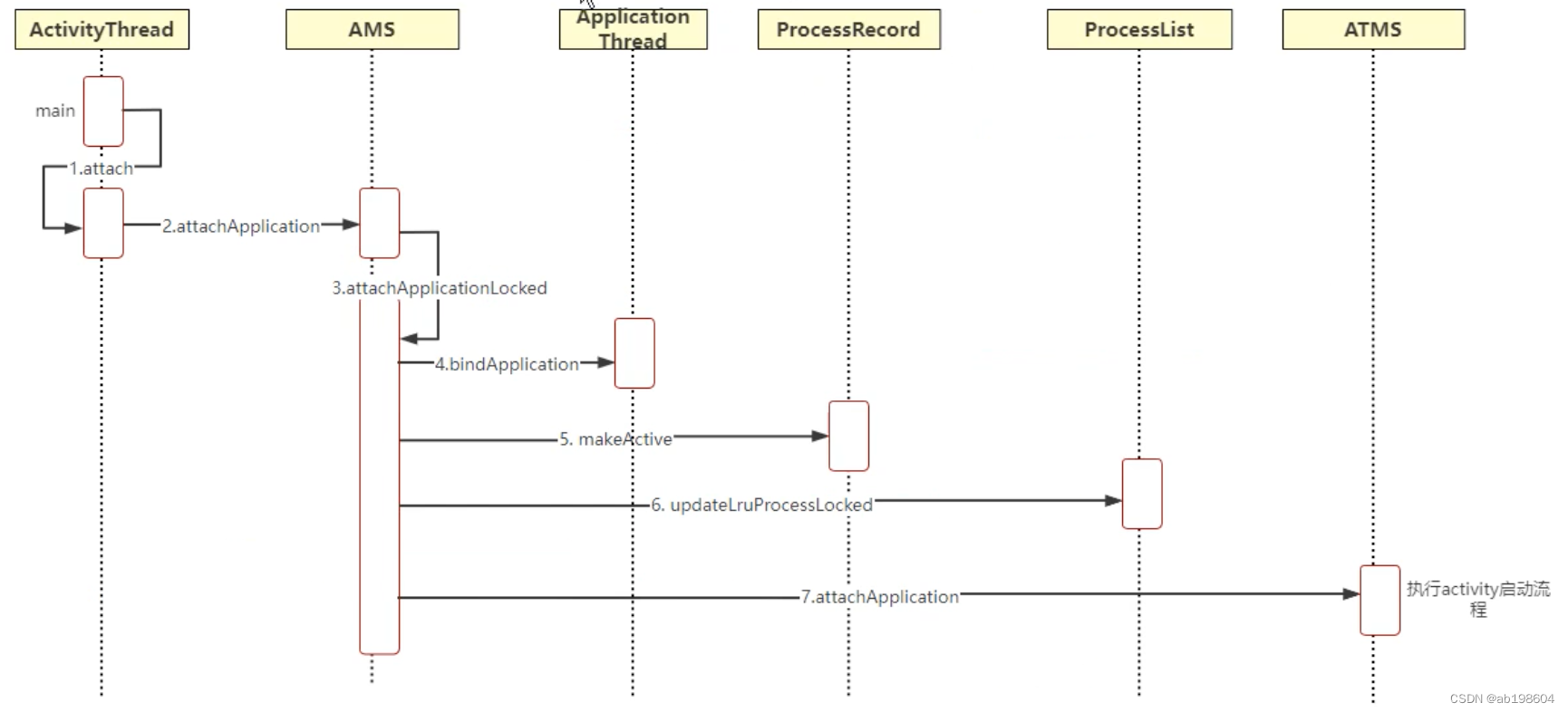
android framework之Applicataion启动流程分析(三)
现在再回顾一下Application的启动流程,总的来说,虽然进程的发起是由ATMS服务发起的,但是进程的启动还是由AMS负责,所以需要调用AMS的startProcess()接口完成进程启动流程,AMS要处理的事情很多,它将事务交给…...

使用Scrapy框架集成Selenium实现高效爬虫
引言: 在网络爬虫的开发中,有时候我们需要处理一些JavaScript动态生成的内容或进行一些复杂的操作,这时候传统的基于请求和响应的爬虫框架就显得力不从心了。为了解决这个问题,我们可以使用Scrapy框架集成Selenium来实现高效的爬…...

Maven 和 Gradle 官方文档及相关资料的网址集合
文章目录 官方MavenGradle 笔者MavenGradle 官方 Maven Maven 仓库依赖包官方查询通道:https://mvnrepository.com/ Maven 插件官方文档:https://maven.apache.org/plugins/ 安卓依赖包官方查询通道*:https://maven.google.com/web/ Gra…...
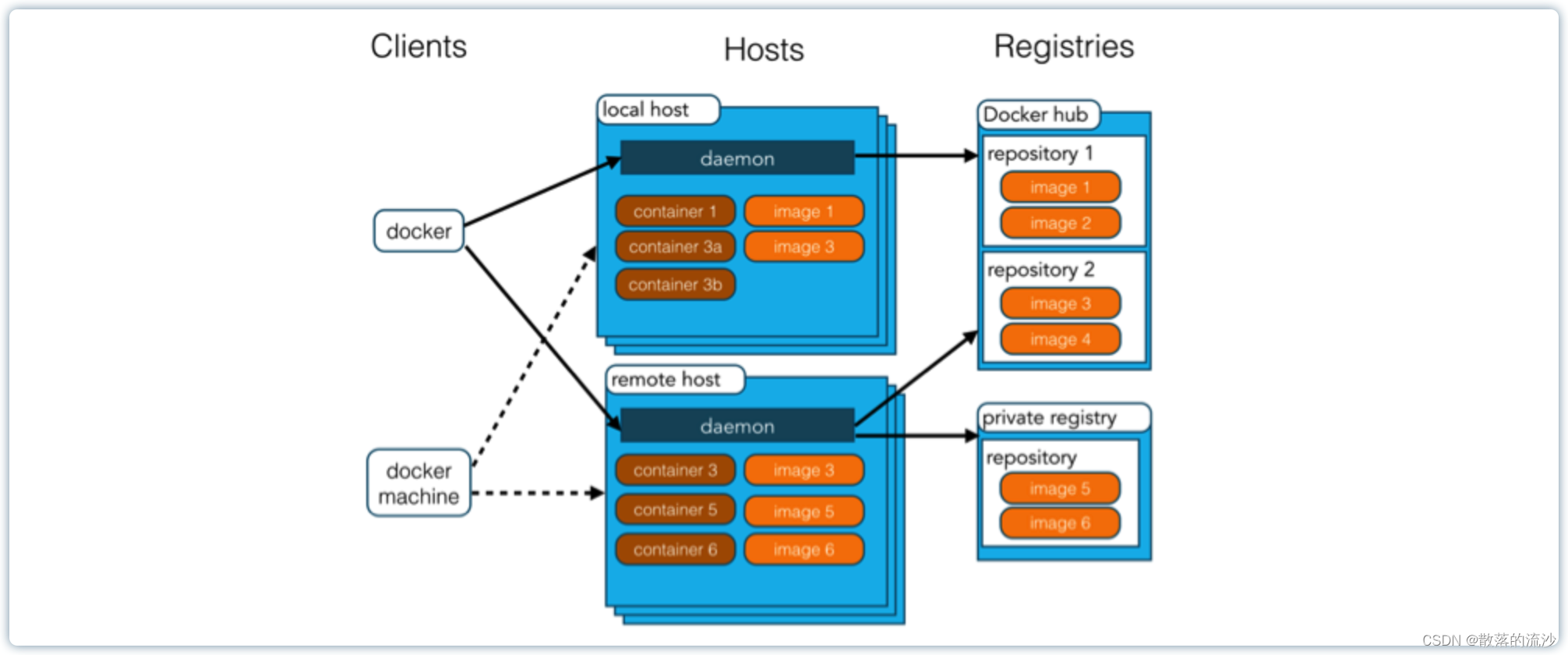
docker概念、安装与卸载
第一章 docker概念 Docker 是一个开源的应用容器引擎。 Docker 诞生于2013年初,基于 Go 语言实现,dotCloud 公司出品,后改名为 Docker Inc。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发…...
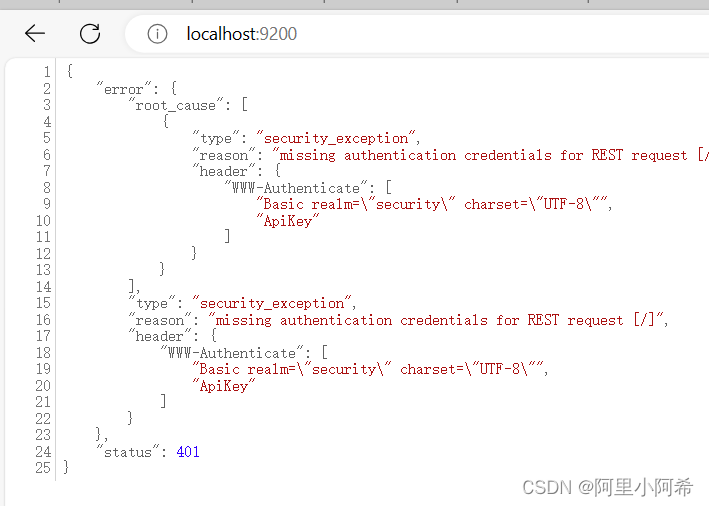
elasticsearch访问9200端口 提示需要登陆
项目场景: 提示:这里简述项目相关背景: elasticsearch访问9200端口 提示需要登陆 问题描述 提示:这里描述项目中遇到的问题: 在E:\elasticsearch-8.9.1-windows-x86_64\elasticsearch-8.9.1\bin目录下输入命令 ela…...
:Python基本数据类型:1、数字(整数、浮点数)及相关运算;2、布尔值)
【深度学习】 Python 和 NumPy 系列教程(一):Python基本数据类型:1、数字(整数、浮点数)及相关运算;2、布尔值
目录 一、前言 二、实验环境 三、Python基本数据类型 1. 数字 a. 整数(int) b. 浮点数(float) c. 运算 运算符 增强操作符 代码整合 d. 运算中的类型转换 e. 运算函数abs、max、min、int、float 2. 布尔值(…...
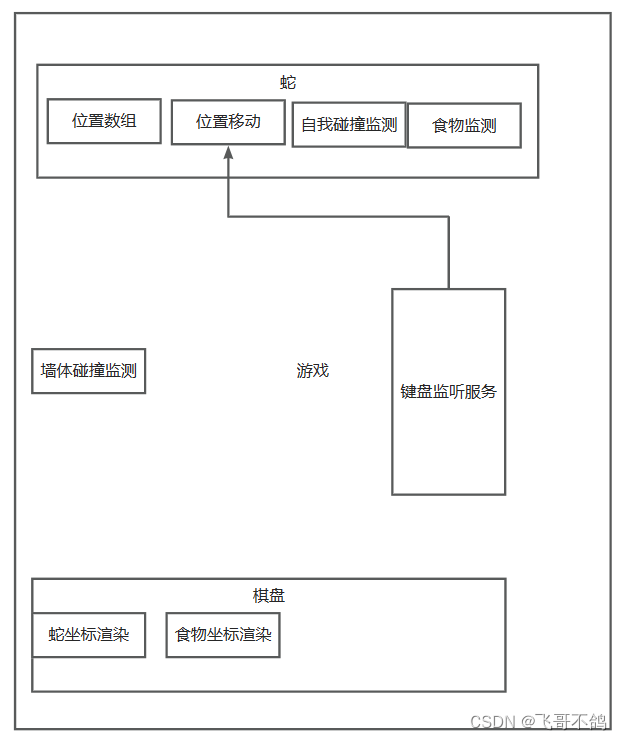
无swing,高级javaSE毕业之贪吃蛇游戏(含模块构建,多线程监听服务)
JavaSE,无框架实现贪吃蛇 文章目录 JavaSE,无框架实现贪吃蛇1.整体思考2.可能的难点思考2.1 如何表示游戏界面2.2 如何渲染游戏界面2.3 如何让游戏动起来2.4 蛇如何移动 3.流程图制作4.模块划分5.模块完善5.0常量优化5.1监听键盘服务i.输入存储ii.键盘监…...
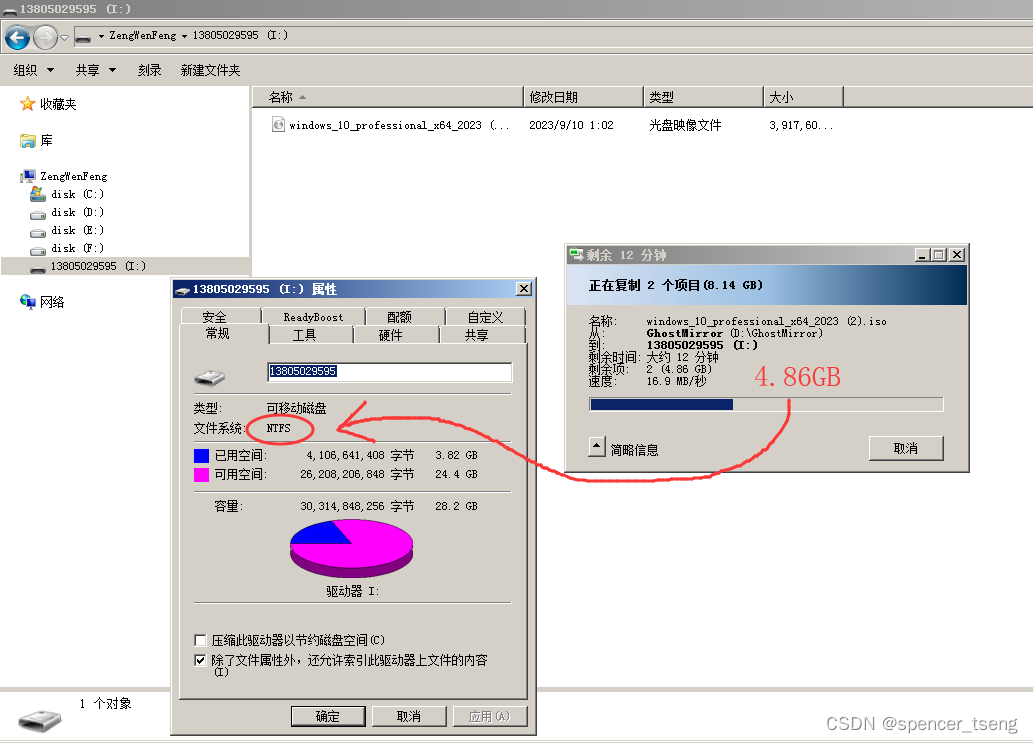
HDD-FAT32 ZIP-FAT32 HDD-FAT16 ZIP-FAT16 HDD-NTFS
FAT32、FAT16指的是分区格式, FAT16单个文件最大2G FAT32单个文件最大4G NTFS单个文件大于4G HDD是硬盘启动 ZIP是软盘启动 U盘选HDD HDD-NTFS...

终极指南:如何一键下载国家智慧教育平台电子课本PDF
终极指南:如何一键下载国家智慧教育平台电子课本PDF 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容。 项目地址: …...

大数据量存储终极指南:10个高效数据分片技巧
大数据量存储终极指南:10个高效数据分片技巧 【免费下载链接】til :memo: Today I Learned 项目地址: https://gitcode.com/gh_mirrors/ti/til 在当今数据爆炸的时代,高效处理和存储海量数据已成为企业技术架构的核心挑战。数据分片作为一种关键的…...
 深度诊断与流量整形方案)
lsyncd rsyncssh同步中断:Broken pipe (32) 深度诊断与流量整形方案
1. 问题现象与初步诊断 最近在帮客户部署lsyncdrsyncssh方案时,遇到了一个典型问题:同步25GB目录时,总是在传输4GB左右中断。日志里反复出现"Broken pipe (32)"错误,就像下面这样: packet_write_wait: Conne…...

OpenClaw 接入微信 / 企业微信完整教程
本文介绍如何通过 OpenClaw 框架,将个人微信和企业微信接入 AI Agent,实现「AI 自动回复」的功能。适用于树莓派、Mac/Windows 电脑、NAS 或云服务器等各类设备。 一、环境准备 1.1 安装 OpenClaw OpenClaw 是核心运行环境,负责加载插件、管…...

PDPI Spec:规格驱动开发协议,让AI编程告别“氛围编码”
1. 项目概述:从“感觉对了”到“规格对了”在软件开发的江湖里,我们可能都经历过这样的场景:产品经理丢过来一个模糊的需求,开发同学凭着一腔热血和“感觉对了”的直觉,一头扎进代码里。几周后,功能上线了&…...

STM32模拟I2C驱动PCF8591避坑指南:为什么你的AD/DA数据总在跳?
STM32模拟I2C驱动PCF8591避坑指南:为什么你的AD/DA数据总在跳? 调试STM32与PCF8591的模拟I2C通信时,AD/DA数据跳动是开发者最常遇到的棘手问题。本文将深入分析数据不稳定的根源,并提供一套完整的解决方案。不同于基础教程&#x…...

NHSE:5分钟掌握动物森友会存档编辑,打造你的完美岛屿
NHSE:5分钟掌握动物森友会存档编辑,打造你的完美岛屿 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 你是否曾经为了收集某个稀有家具而花费数周时间?是否因为地…...

基于MCP协议与HaE工具构建AI安全情报助手实战指南
1. 项目概述:一个为安全工程师量身定制的“情报雷达”如果你是一名安全工程师、渗透测试人员或者负责企业安全运营的从业者,那么你一定对“信息收集”和“威胁情报”这两个词深有体会。每天,我们都需要从海量的数据源中——无论是公开的漏洞库…...

redis之典型应用-缓存cache
什么是缓存缓存 (cache) 是计算机中的一个经典的概念. 在很多场景中都会涉及到. 核心思路就是把一些常用的数据放到触手可及(访问速度更快)的地方, 方便随时读取。大部分的时候, 缓存只放一些 热点数据 (访问频繁的数据),对于硬件的访问速度来说, 通常情况下: CPU 寄存器 > …...

Loop习惯追踪:从零开始构建你的长期习惯养成系统
Loop习惯追踪:从零开始构建你的长期习惯养成系统 【免费下载链接】uhabits Loop Habit Tracker, a mobile app for creating and maintaining long-term positive habits 项目地址: https://gitcode.com/gh_mirrors/uh/uhabits 你是否曾下定决心培养一个好习…...