使用Scrapy框架集成Selenium实现高效爬虫
引言:
在网络爬虫的开发中,有时候我们需要处理一些JavaScript动态生成的内容或进行一些复杂的操作,这时候传统的基于请求和响应的爬虫框架就显得力不从心了。为了解决这个问题,我们可以使用Scrapy框架集成Selenium来实现高效的爬虫。
1. Scrapy框架简介
Scrapy是一个使用Python编写的开源网络爬虫框架,具有高效、灵活和可扩展的特点。通过Scrapy,我们可以轻松地定义和管理爬虫的规则,实现对网页的抓取和数据的提取。
2. Selenium简介
Selenium是一个自动化测试工具,它可以模拟用户在浏览器上的操作,如点击、输入等。通过Selenium,我们可以实现对JavaScript动态生成的内容进行抓取,以及处理一些需要交互的页面。
3. Scrapy集成Selenium的优势
Scrapy结合Selenium可以充分发挥两者的优势,实现更高效的爬虫。Selenium可以解决Scrapy无法处理的动态页面和JavaScript生成的内容,而Scrapy可以提供更好的抓取和数据提取的能力。
4. Scrapy集成Selenium的步骤
在Scrapy中集成Selenium需要以下几个步骤:
4.1 安装Selenium和相应的浏览器驱动
当我们在Scrapy中集成Selenium时,首先需要安装Selenium和相应的浏览器驱动。Selenium支持多种浏览器,例如Chrome、Firefox等,我们根据需要选择一个合适的浏览器。
4.1.1 安装Selenium
我们可以使用以下命令来安装Selenium:
pip install selenium
此命令将会安装最新版本的Selenium。
4.1.2 下载浏览器驱动
根据我们选择的浏览器,我们需要下载相应的驱动程序。常见的浏览器驱动程序有ChromeDriver和GeckoDriver。
-
ChromeDriver:用于控制Chrome浏览器。
官方文档:https://chromedriver.chromium.org/home
下载地址:https://chromedriver.chromium.org/downloads -
GeckoDriver:用于控制Firefox浏览器。
官方文档:https://github.com/mozilla/geckodriver
下载地址:https://github.com/mozilla/geckodriver/releases
下载完成后,将驱动程序文件解压到一个合适的位置,并记住该位置。
4.1.3 配置驱动程序路径
在我们的Scrapy项目中,我们需要指定驱动程序的路径,以便Scrapy能够找到并使用它。在Scrapy的配置文件中,找到settings.py文件,并添加以下配置:
SELENIUM_DRIVER_NAME = 'chrome' # 使用的浏览器驱动名称,如chrome或firefox
SELENIUM_DRIVER_EXECUTABLE_PATH = '/path/to/driver' # 驱动程序的路径
请将/path/to/driver替换为实际的驱动程序路径。
4.1.4 配置浏览器选项
如果需要,我们还可以配置一些浏览器选项,例如设置浏览器窗口大小、启用无头模式等。继续编辑settings.py文件,并添加以下配置:
SELENIUM_OPTIONS = {'arguments': ['--headless'] # 启用无头模式
}
可以根据需要添加其他浏览器选项。
4.1.5 安装其他依赖库
除了Selenium和浏览器驱动程序外,我们还需要安装其他依赖库,以确保Scrapy和Selenium的顺利集成。这些库包括:
scrapy_selenium:用于在Scrapy中集成Selenium。webdriver_manager:用于自动下载和管理浏览器驱动程序。
可以使用以下命令安装这些库:
pip install scrapy_selenium webdriver_manager
安装完成后,我们已经完成了Selenium的安装和配置。
接下来,我们可以编写中间件和爬虫代码,并在Scrapy项目中使用Selenium来实现高效的爬虫。
4.2 编写一个中间件
当我们在Scrapy中集成Selenium时,我们需要创建一个中间件来处理请求并使用Selenium来渲染动态页面。以下是详细步骤:
4.2.1 创建Selenium中间件
在Scrapy项目中创建一个新的Python文件,命名为selenium_middleware.py(或者其他合适的名称)。在该文件中,我们需要导入必要的库并定义一个中间件类。
from scrapy import signals
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManagerclass SeleniumMiddleware:@classmethoddef from_crawler(cls, crawler):middleware = cls()crawler.signals.connect(middleware.spider_opened, signal=signals.spider_opened)crawler.signals.connect(middleware.spider_closed, signal=signals.spider_closed)return middlewaredef spider_opened(self, spider):options = Options()options.add_argument('--headless') # 启用无头模式self.driver = webdriver.Chrome(executable_path=ChromeDriverManager().install(), options=options)def spider_closed(self, spider):self.driver.quit()def process_request(self, request, spider):self.driver.get(request.url)body = self.driver.page_source.encode('utf-8')return HtmlResponse(self.driver.current_url, body=body, encoding='utf-8', request=request)
在上面的代码中,我们定义了一个SeleniumMiddleware中间件类,其中包括以下几个方法:
from_crawler方法:用于创建中间件实例,并注册信号处理函数。spider_opened方法:在爬虫启动时创建浏览器实例。spider_closed方法:在爬虫关闭时关闭浏览器实例。process_request方法:处理请求并使用Selenium渲染动态页面,返回渲染后的响应。
注意,在spider_opened方法中,我们使用webdriver.Chrome创建Chrome浏览器实例,并通过ChromeDriverManager().install()自动下载和管理Chrome驱动程序。
4.2.2 配置中间件
在Scrapy的配置文件中,找到settings.py文件,并添加以下配置:
DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, # 禁用默认的UserAgentMiddleware'myproject.middlewares.SeleniumMiddleware': 543, # 添加自定义的SeleniumMiddleware
}
将myproject.middlewares.SeleniumMiddleware替换为实际的中间件路径。
注意,我们禁用了Scrapy默认的UserAgentMiddleware,因为在Selenium中间件中已经处理了请求。
4.2.3 使用Selenium进行页面渲染
在我们的爬虫代码中,我们可以像平常一样定义parse方法,并在其中发送请求。Scrapy将会使用我们的Selenium中间件来处理这些请求并返回渲染后的响应。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'def start_requests(self):yield scrapy.Request(url='http://example.com', callback=self.parse)def parse(self, response):# 在这里编写解析响应的代码
在上面的代码中,我们定义了一个名为myspider的爬虫类,并在start_requests方法中发送一个初始请求。在parse方法中,我们可以编写代码来解析响应并提取所需的数据。
当我们运行爬虫时,Scrapy将会使用Selenium中间件来处理请求,自动渲染页面并返回渲染后的响应。这样,我们就能够轻松地处理动态页面和JavaScript渲染了。
4.3 配置Scrapy启用中间件
在Scrapy中集成Selenium是一种处理动态页面和JavaScript渲染的常用方法。以下是详细步骤:
4.3.1 安装必要的库
首先,确保已经安装了Scrapy和Selenium库,可以使用以下命令安装:
pip install scrapy selenium webdriver_manager
4.3.2 创建Scrapy项目
使用以下命令创建一个新的Scrapy项目:
scrapy startproject myproject
这将在当前目录下创建一个名为myproject的新项目。
4.3.3 创建爬虫
在Scrapy项目中,使用以下命令创建一个新的爬虫:
cd myproject
scrapy genspider myspider example.com
这将在myproject/spiders目录下创建一个名为myspider.py的爬虫文件,同时以example.com为起始URL。
4.3.4 配置爬虫
打开myproject/spiders/myspider.py文件,并编辑start_urls列表,将其替换为要爬取的实际URL。也可以在allowed_domains列表中添加要爬取的域名。
4.3.5 配置中间件
在Scrapy项目的配置文件settings.py中,找到DOWNLOADER_MIDDLEWARES字典,并添加以下配置:
DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, # 禁用默认的UserAgentMiddleware'myproject.middlewares.SeleniumMiddleware': 543, # 添加自定义的SeleniumMiddleware
}
将myproject.middlewares.SeleniumMiddleware替换为实际的中间件路径。
注意,我们禁用了Scrapy默认的UserAgentMiddleware,因为在Selenium中间件中已经处理了请求。
4.3.6 创建Selenium中间件
在Scrapy项目的middlewares目录下创建一个新的Python文件,命名为selenium_middleware.py。在该文件中,我们需要导入必要的库并定义一个中间件类。
from scrapy import signals
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManagerclass SeleniumMiddleware:@classmethoddef from_crawler(cls, crawler):middleware = cls()crawler.signals.connect(middleware.spider_opened, signal=signals.spider_opened)crawler.signals.connect(middleware.spider_closed, signal=signals.spider_closed)return middlewaredef spider_opened(self, spider):options = Options()options.add_argument('--headless') # 启用无头模式self.driver = webdriver.Chrome(executable_path=ChromeDriverManager().install(), options=options)def spider_closed(self, spider):self.driver.quit()def process_request(self, request, spider):self.driver.get(request.url)body = self.driver.page_source.encode('utf-8')return HtmlResponse(self.driver.current_url, body=body, encoding='utf-8', request=request)
在上面的代码中,我们定义了一个SeleniumMiddleware中间件类,其中包括以下几个方法:
from_crawler方法:用于创建中间件实例,并注册信号处理函数。spider_opened方法:在爬虫启动时创建浏览器实例。spider_closed方法:在爬虫关闭时关闭浏览器实例。process_request方法:处理请求并使用Selenium渲染动态页面,返回渲染后的响应。
注意,在spider_opened方法中,我们使用webdriver.Chrome创建Chrome浏览器实例,并通过ChromeDriverManager().install()自动下载和管理Chrome驱动程序。
4.3.7 使用Selenium进行页面渲染
在我们的爬虫代码中,我们可以像平常一样定义parse方法,并在其中发送请求。Scrapy将会使用我们的Selenium中间件来处理这些请求并返回渲染后的响应。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'def start_requests(self):yield scrapy.Request(url='http://example.com', callback=self.parse)def parse(self, response):# 在这里编写解析响应的代码
在上面的代码中,我们定义了一个名为myspider的爬虫类,并在start_requests方法中发送一个初始请求。在parse方法中,我们可以编写代码来解析响应并提取所需的数据。
当我们运行爬虫时,Scrapy将会使用Selenium中间件来处理请求,自动渲染页面并返回渲染后的响应。这样,我们就能够轻松地处理动态页面和JavaScript渲染了。
4.4 编写爬虫代码
最后,我们需要编写爬虫代码来定义抓取规则和数据提取。在需要使用Selenium的地方,我们可以通过调用Selenium来实现。
5. 示例代码
下面是一个简单的示例代码,演示了如何使用Scrapy集成Selenium:
import scrapy
from scrapy_selenium import SeleniumRequestclass MySpider(scrapy.Spider):name = 'myspider'def start_requests(self):yield SeleniumRequest(url='https://www.example.com', callback=self.parse)def parse(self, response):# 使用Scrapy的Selector进行数据提取title = response.css('h1::text').get()yield {'title': title}
6. 总结
通过将Scrapy和Selenium结合起来使用,我们可以处理一些复杂的爬虫需求,如抓取JavaScript动态生成的内容和处理需要交互的页面。这样可以使我们的爬虫更加强大和高效。
然而,需要注意的是,使用Selenium会增加爬虫的复杂度和资源消耗。因此,在使用Scrapy集成Selenium时,需要权衡利弊,并合理使用这两个工具。
相关文章:

使用Scrapy框架集成Selenium实现高效爬虫
引言: 在网络爬虫的开发中,有时候我们需要处理一些JavaScript动态生成的内容或进行一些复杂的操作,这时候传统的基于请求和响应的爬虫框架就显得力不从心了。为了解决这个问题,我们可以使用Scrapy框架集成Selenium来实现高效的爬…...

Maven 和 Gradle 官方文档及相关资料的网址集合
文章目录 官方MavenGradle 笔者MavenGradle 官方 Maven Maven 仓库依赖包官方查询通道:https://mvnrepository.com/ Maven 插件官方文档:https://maven.apache.org/plugins/ 安卓依赖包官方查询通道*:https://maven.google.com/web/ Gra…...
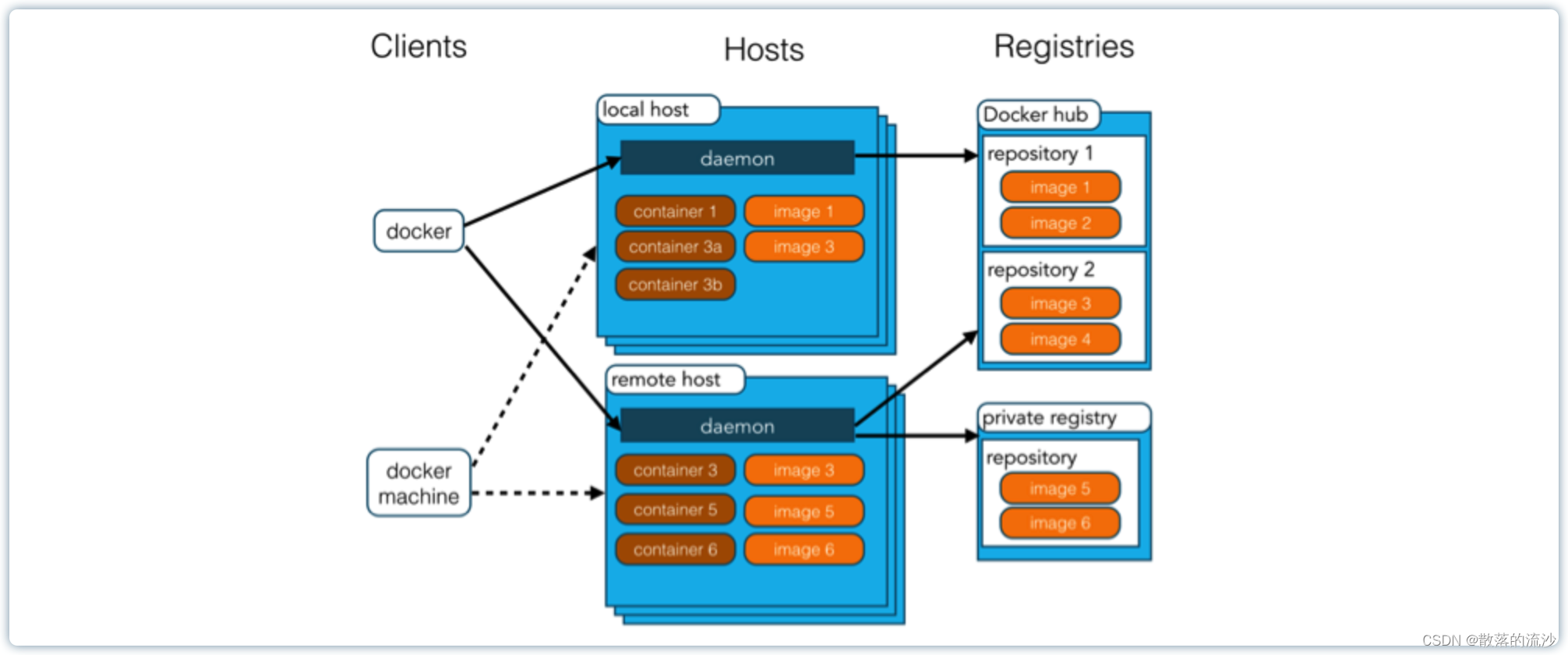
docker概念、安装与卸载
第一章 docker概念 Docker 是一个开源的应用容器引擎。 Docker 诞生于2013年初,基于 Go 语言实现,dotCloud 公司出品,后改名为 Docker Inc。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发…...
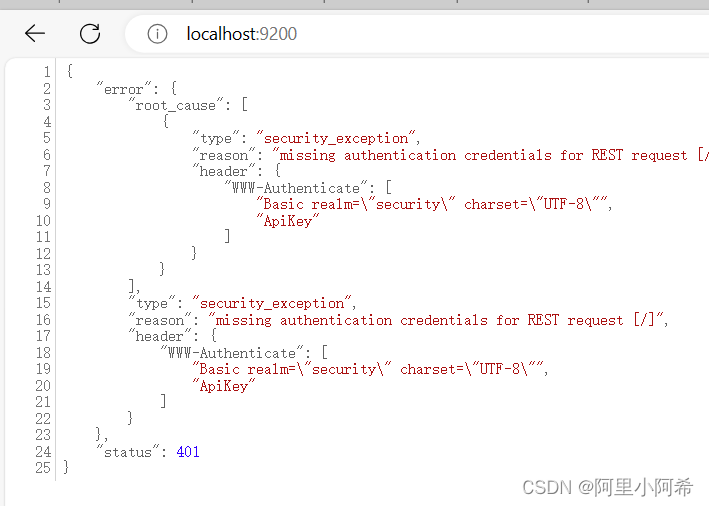
elasticsearch访问9200端口 提示需要登陆
项目场景: 提示:这里简述项目相关背景: elasticsearch访问9200端口 提示需要登陆 问题描述 提示:这里描述项目中遇到的问题: 在E:\elasticsearch-8.9.1-windows-x86_64\elasticsearch-8.9.1\bin目录下输入命令 ela…...
:Python基本数据类型:1、数字(整数、浮点数)及相关运算;2、布尔值)
【深度学习】 Python 和 NumPy 系列教程(一):Python基本数据类型:1、数字(整数、浮点数)及相关运算;2、布尔值
目录 一、前言 二、实验环境 三、Python基本数据类型 1. 数字 a. 整数(int) b. 浮点数(float) c. 运算 运算符 增强操作符 代码整合 d. 运算中的类型转换 e. 运算函数abs、max、min、int、float 2. 布尔值(…...
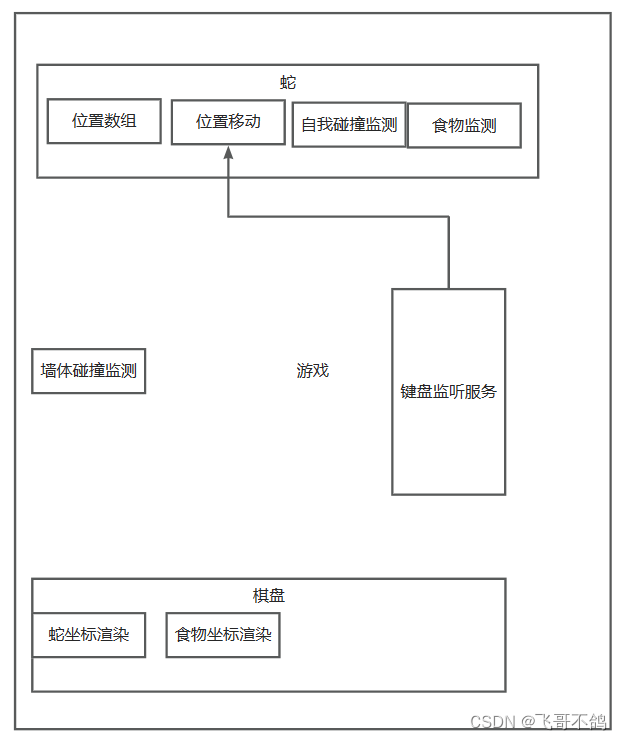
无swing,高级javaSE毕业之贪吃蛇游戏(含模块构建,多线程监听服务)
JavaSE,无框架实现贪吃蛇 文章目录 JavaSE,无框架实现贪吃蛇1.整体思考2.可能的难点思考2.1 如何表示游戏界面2.2 如何渲染游戏界面2.3 如何让游戏动起来2.4 蛇如何移动 3.流程图制作4.模块划分5.模块完善5.0常量优化5.1监听键盘服务i.输入存储ii.键盘监…...
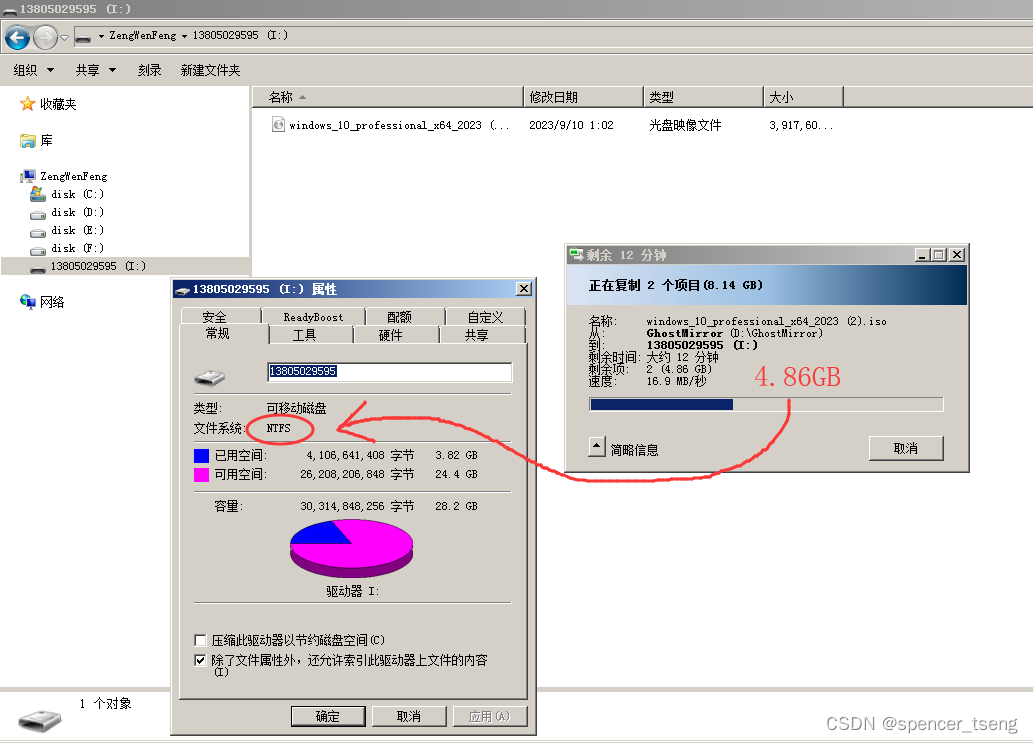
HDD-FAT32 ZIP-FAT32 HDD-FAT16 ZIP-FAT16 HDD-NTFS
FAT32、FAT16指的是分区格式, FAT16单个文件最大2G FAT32单个文件最大4G NTFS单个文件大于4G HDD是硬盘启动 ZIP是软盘启动 U盘选HDD HDD-NTFS...

王道数据结构编程题 二叉树
二叉树定义 以下为本文解题代码的二叉树定义。 struct TreeNode {int val;TreeNode* left, *right;TreeNode(int val 0, TreeNode* left nullptr, TreeNode* right nullptr): val(val), left(left), right(right) {} };非递归后序遍历 题目描述 编写后序遍历二叉树的非递…...

登录怎么实现的,密码加密了嘛?使用明文还是暗文,知道怎么加密嘛?
在Java中登录功能的实现通常包括以下步骤,其中密码应该以加密形式存储在数据库中,而不以明文形式存储,以增强安全性: 登录功能的实现步骤: 用户输入: 用户在登录页面上输入用户名和密码。 传输到服务器&a…...

Nginx和Tomcat负载均衡实现session共享
以前的项目使用Nginx作为反向代理实现了多个Tomcat的负载均衡,为了实现多个Tomcat之间的session共享,使用了开源的Memcached-Session-Manager框架。 此框架的优势: 1、支持Tomcat6和Tomcat7 2、操作粘性或不黏性Session 3、没有单点故障 4、T…...

【算法题】210. 课程表 II
题目: 现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] [ai, bi] ,表示在选修课程 ai 前 必须 先选修 bi 。 例如,想要学习课程 0 ,…...

“数据类型不一致”会走索引吗?
分析&回答 字符串类型的索引 id_1 varchar(20) NOT NULL这样下面两条语句的结果是一样的: SELECT * FROM ix_test WHERE id_11; SELECT * FROM ix_test WHERE id_11;执行计划是不同的: mysql> explain select * from ix_test where id_11; | 1 …...

Leetcode 1572.矩阵对角线元素之和
给你一个正方形矩阵 mat,请你返回矩阵对角线元素的和。 请你返回在矩阵主对角线上的元素和副对角线上且不在主对角线上元素的和。 示例 1: 输入:mat [[1,2,3],[4,5,6],[7,8,9]] 输出:25 解释:对角线的和为ÿ…...
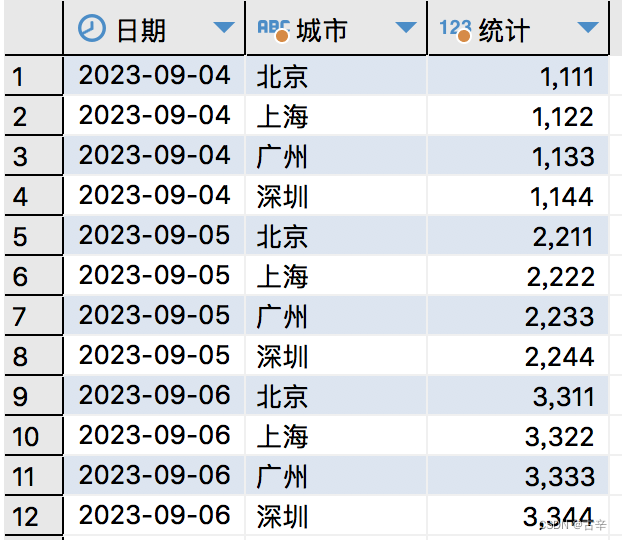
[PG]将一行数据打散成多行数据
原始数据 比如有如此表结构定义: 假如查询数据如下: select dt as "日期",bj_count as "北京", sh_count as "上海",gz_count as "广州", sz_count as "深圳" from city_stats order by dt--------------------…...

二蛋赠书一期:《快捷学习Spring》
文章目录 前言活动规则参与方式本期赠书《快捷学习Spring》关于本书作者介绍内容简介读者对象 结语 前言 大家好!我是二蛋,一个热爱技术、乐于分享的工程师。在过去的几年里,我一直通过各种渠道与大家分享技术知识和经验。我深知,…...
Threejs汽车展厅
2023-09-06-16-29-40 预览:https://9kt8fy-1234.csb.app/ 源码链接...
)
LeetCode:207. 课程表、210. 课程表 II(拓扑排序 C++)
目录 207. 课程表 题目描述: 实现代码与解析: 拓扑排序 210. 课程表 II 题目描述: 实现代码与解析: 拓扑排序 原理思路: 207. 课程表 题目描述: 你这个学期必须选修 numCourses 门课程࿰…...

如何使用组件
可以复用的代码写到组件里面,比如左侧的导航栏 1.写好一个组件 记得结构写在template标签里面,当然div也可以 2.在需要使用的地方,用标签使用组件 3.在使用的文件内import此组件 import CommonAside from /components/CommonAside.vue; …...
)
Android 13.0 Launcher3定制之双层改单层(去掉抽屉式二)
1.概述 在13.0的系统产品开发中,对于在Launcher3中的抽屉模式也就是双层模式,在系统原生的Launcher3中就是双层抽屉模式的, 但是在通过抽屉上滑的模式拉出app列表页,但是在一些产品开发中,对于单层模式的Launcher3的产品模式也是常用的功能, 所以需要了解抽屉模式,然后修…...
对卷积的一点具象化理解
前言 卷积的公式一般被表示为下式: 对新手来说完全看不懂这是干什么,这个问题需要结合卷积的应用场景来说。 原理 卷积比较广泛的应用是在信号与系统中,所以有些公式的定义会按照信息流的习惯。假设存在一串信号g(x)经过一个响应h(x)时他的响…...

codebase-digest:自动化代码库分析工具的设计原理与工程实践
1. 项目概述:当代码库变成“黑盒”,我们如何快速理解它?你有没有接手过一个庞大而陌生的代码库?面对成千上万的文件和错综复杂的依赖关系,那种感觉就像被扔进了一个没有地图的迷宫。传统的做法是,你得像考古…...

Windows安装安卓APK的完整指南:APK Installer免费工具使用教程
Windows安装安卓APK的完整指南:APK Installer免费工具使用教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为电脑无法运行安卓应用而烦恼吗&#x…...

WindowResizer:轻松掌控Windows窗口的终极解决方案
WindowResizer:轻松掌控Windows窗口的终极解决方案 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为Windows应用程序窗口尺寸无法调整而烦恼吗?Window…...

星际软件开发:为火星殖民地编写第一批代码
一、引言:当测试左移到大气层之外2041年,第一批火星殖民者即将启程。他们携带的不仅是氧气和速食,还有一座预装在密封舱里的微型数据中心。在这片红色荒漠上,代码将比氧气更早醒来——生命维持系统的控制逻辑、通讯中继的协议栈、…...

别再折腾Anaconda了!用PyCharm 2024.1自带工具5分钟搞定TensorFlow 2.15 + Keras 3环境
PyCharm 2024.1极简指南:5分钟无痛部署TensorFlow 2.15 Keras 3深度学习环境 深度学习环境配置曾是无数开发者的噩梦——直到PyCharm 2024.1彻底改变了游戏规则。最新版本集成的环境管理工具让TensorFlow和Keras的安装变得像点外卖一样简单,完全跳过了传…...

Sora 2如何“唤醒”3D Gaussian Splatting?:从神经辐射场到毫秒级动态场景生成的4层技术跃迁解析
更多请点击: https://intelliparadigm.com 第一章:Sora 2与3D Gaussian Splatting融合的范式革命 传统视频生成模型受限于体素网格或NeRF隐式表示的计算开销与几何保真度瓶颈,而Sora 2通过引入时空一致性token压缩机制,与3D Gaus…...

原神帧率解锁技术解析:三步突破60FPS限制的完整方案
原神帧率解锁技术解析:三步突破60FPS限制的完整方案 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 你是否曾为《原神》PC版的60FPS限制感到困扰?当你的高性能显卡…...

体验Taotoken多模型聚合在内容生成任务中的效果差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken多模型聚合在内容生成任务中的效果差异 在实际的开发与创作工作中,我们常常面临一个选择:针对…...

在Nodejs后端服务中集成Taotoken实现稳定可靠的大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成Taotoken实现稳定可靠的大模型调用 将大模型能力集成到后端服务是现代应用开发的常见需求。对于Node.js开发…...

JavaScript自动化PPT生成:如何用代码解放你的演示文稿生产力
JavaScript自动化PPT生成:如何用代码解放你的演示文稿生产力 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 还在为…...