玩转Mysql系列 - 第17篇:存储过程自定义函数详解
这是Mysql系列第17篇。
环境:mysql5.7.25,cmd命令中进行演示。
代码中被[]包含的表示可选,|符号分开的表示可选其一。
需求背景介绍
线上程序有时候出现问题导致数据错误的时候,如果比较紧急,我们可以写一个存储来快速修复这块的数据,然后再去修复程序,这种方式我们用到过不少。
存储过程相对于java程序对于java开发来说,可能并不是太好维护以及阅读,所以不建议在程序中去调用存储过程做一些业务操作。
关于自定义函数这块,若mysql内部自带的一些函数无法满足我们的需求的时候,我们可以自己开发一些自定义函数来使用。
所以建议大家掌握mysql中存储过程和自定义函数这块的内容。
本文内容
-
详解存储过程的使用
-
详解自定义函数的使用
准备数据
/*建库javacode2018*/
drop database if exists javacode2018;
create database javacode2018;/*切换到javacode2018库*/
use javacode2018;/*建表test1*/
DROP TABLE IF EXISTS t_user;
CREATE TABLE t_user (id INT NOT NULL PRIMARY KEY COMMENT '编号',age SMALLINT UNSIGNED NOT NULL COMMENT '年龄',name VARCHAR(16) NOT NULL COMMENT '姓名'
) COMMENT '用户表';
存储过程
概念
一组预编译好的sql语句集合,理解成批处理语句。
好处:
-
提高代码的重用性
-
简化操作
-
减少编译次数并且减少和数据库服务器连接的次数,提高了效率。
创建存储过程
create procedure 存储过程名([参数模式] 参数名 参数类型)
begin存储过程体
end
参数模式有3种:
in:该参数可以作为输入,也就是该参数需要调用方传入值。
out:该参数可以作为输出,也就是说该参数可以作为返回值。
inout:该参数既可以作为输入也可以作为输出,也就是说该参数需要在调用的时候传入值,又可以作为返回值。
参数模式默认为IN。
一个存储过程可以有多个输入、多个输出、多个输入输出参数。
调用存储过程
call 存储过程名称(参数列表);
注意:调用存储过程关键字是
call。
删除存储过程
drop procedure [if exists] 存储过程名称;
存储过程只能一个个删除,不能批量删除。
if exists:表示存储过程存在的情况下删除。
修改存储过程
存储过程不能修改,若涉及到修改的,可以先删除,然后重建。
查看存储过程
show create procedure 存储过程名称;
可以查看存储过程详细创建语句。
示例
示例1:空参列表
创建存储过程
/*设置结束符为$*/
DELIMITER $
/*如果存储过程存在则删除*/
DROP PROCEDURE IF EXISTS proc1;
/*创建存储过程proc1*/
CREATE PROCEDURE proc1()BEGININSERT INTO t_user VALUES (1,30,'路人甲Java');INSERT INTO t_user VALUES (2,50,'刘德华');END $/*将结束符置为;*/
DELIMITER ;
delimiter用来设置结束符,当mysql执行脚本的时候,遇到结束符的时候,会把结束符前面的所有语句作为一个整体运行,存储过程中的脚本有多个sql,但是需要作为一个整体运行,所以此处用到了delimiter。
mysql默认结束符是分号。
上面存储过程中向t_user表中插入了2条数据。
调用存储过程:
CALL proc1();
验证效果:
mysql> select * from t_user;
+----+-----+---------------+
| id | age | name |
+----+-----+---------------+
| 1 | 30 | 路人甲Java |
| 2 | 50 | 刘德华 |
+----+-----+---------------+
2 rows in set (0.00 sec)
存储过程调用成功,test1表成功插入了2条数据。
示例2:带in参数的存储过程
创建存储过程:
/*设置结束符为$*/
DELIMITER $
/*如果存储过程存在则删除*/
DROP PROCEDURE IF EXISTS proc2;
/*创建存储过程proc2*/
CREATE PROCEDURE proc2(id int,age int,in name varchar(16))BEGININSERT INTO t_user VALUES (id,age,name);END $/*将结束符置为;*/
DELIMITER ;
调用存储过程:
/*创建了3个自定义变量*/
SELECT @id:=3,@age:=56,@name:='张学友';
/*调用存储过程*/
CALL proc2(@id,@age,@name);
验证效果:
mysql> select * from t_user;
+----+-----+---------------+
| id | age | name |
+----+-----+---------------+
| 1 | 30 | 路人甲Java |
| 2 | 50 | 刘德华 |
| 3 | 56 | 张学友 |
+----+-----+---------------+
3 rows in set (0.00 sec)
张学友插入成功。
示例3:带out参数的存储过程
创建存储过程:
delete a from t_user a where a.id = 4;
/*如果存储过程存在则删除*/
DROP PROCEDURE IF EXISTS proc3;
/*设置结束符为$*/
DELIMITER $
/*创建存储过程proc3*/
CREATE PROCEDURE proc3(id int,age int,in name varchar(16),out user_count int,out max_id INT)BEGININSERT INTO t_user VALUES (id,age,name);/*查询出t_user表的记录,放入user_count中,max_id用来存储t_user中最小的id*/SELECT COUNT(*),max(id) into user_count,max_id from t_user;END $/*将结束符置为;*/
DELIMITER ;
proc3中前2个参数,没有指定参数模式,默认为in。
调用存储过程:
/*创建了3个自定义变量*/
SELECT @id:=4,@age:=55,@name:='郭富城';
/*调用存储过程*/
CALL proc3(@id,@age,@name,@user_count,@max_id);
验证效果:
mysql> select @user_count,@max_id;
+-------------+---------+
| @user_count | @max_id |
+-------------+---------+
| 4 | 4 |
+-------------+---------+
1 row in set (0.00 sec)
示例4:带inout参数的存储过程
创建存储过程:
/*如果存储过程存在则删除*/
DROP PROCEDURE IF EXISTS proc4;
/*设置结束符为$*/
DELIMITER $
/*创建存储过程proc4*/
CREATE PROCEDURE proc4(INOUT a int,INOUT b int)BEGINSET a = a*2;select b*2 into b;END $/*将结束符置为;*/
DELIMITER ;
调用存储过程:
/*创建了2个自定义变量*/
set @a=10,@b:=20;
/*调用存储过程*/
CALL proc4(@a,@b);
验证效果:
mysql> SELECT @a,@b;
+------+------+
| @a | @b |
+------+------+
| 20 | 40 |
+------+------+
1 row in set (0.00 sec)
上面的两个自定义变量@a、@b作为入参,然后在存储过程内部进行了修改,又作为了返回值。
示例5:查看存储过程
mysql> show create procedure proc4;
+-------+-------+-------+-------+-------+-------+
| Procedure | sql_mode | Create Procedure | character_set_client | collation_connection | Database Collation |
+-------+-------+-------+-------+-------+-------+
| proc4 | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION | CREATE DEFINER=`root`@`localhost` PROCEDURE `proc4`(INOUT a int,INOUT b int)
BEGINSET a = a*2;select b*2 into b;END | utf8 | utf8_general_ci | utf8_general_ci |
+-------+-------+-------+-------+-------+-------+
1 row in set (0.00 sec)
函数
概念
一组预编译好的sql语句集合,理解成批处理语句。类似于java中的方法,但是必须有返回值。
创建函数
create function 函数名(参数名称 参数类型)
returns 返回值类型
begin函数体
end
参数是可选的。
返回值是必须的。
调用函数
select 函数名(实参列表);
删除函数
drop function [if exists] 函数名;
查看函数详细
show create function 函数名;
示例
示例1:无参函数
创建函数:
/*删除fun1*/
DROP FUNCTION IF EXISTS fun1;
/*设置结束符为$*/
DELIMITER $
/*创建函数*/
CREATE FUNCTION fun1()returns INTBEGINDECLARE max_id int DEFAULT 0;SELECT max(id) INTO max_id FROM t_user;return max_id;END $
/*设置结束符为;*/
DELIMITER ;
调用看效果:
mysql> SELECT fun1();
+--------+
| fun1() |
+--------+
| 4 |
+--------+
1 row in set (0.00 sec)
示例2:有参函数
创建函数:
/*删除函数*/
DROP FUNCTION IF EXISTS get_user_id;
/*设置结束符为$*/
DELIMITER $
/*创建函数*/
CREATE FUNCTION get_user_id(v_name VARCHAR(16))returns INTBEGINDECLARE r_id int;SELECT id INTO r_id FROM t_user WHERE name = v_name;return r_id;END $
/*设置结束符为;*/
DELIMITER ;
运行看效果:
mysql> SELECT get_user_id(name) from t_user;
+-------------------+
| get_user_id(name) |
+-------------------+
| 1 |
| 2 |
| 3 |
| 4 |
+-------------------+
4 rows in set (0.00 sec)
存储过程和函数的区别
存储过程的关键字为procedure,返回值可以有多个,调用时用call,一般用于执行比较复杂的的过程体、更新、创建等语句。
函数的关键字为function,返回值必须有一个,调用用select,一般用于查询单个值并返回。
| 存储过程 | 函数 | |
|---|---|---|
| 返回值 | 可以有0个或者多个 | 必须有一个 |
| 关键字 | procedure | function |
| 调用方式 | call | select |
相关文章:

玩转Mysql系列 - 第17篇:存储过程自定义函数详解
这是Mysql系列第17篇。 环境:mysql5.7.25,cmd命令中进行演示。 代码中被[]包含的表示可选,|符号分开的表示可选其一。 需求背景介绍 线上程序有时候出现问题导致数据错误的时候,如果比较紧急,我们可以写一个存储来…...

自动驾驶:轨迹预测综述
自动驾驶:轨迹预测综述 轨迹预测的定义轨迹预测的分类基于物理的方法(Physics-based)基于机器学习的方法(Classic Machine Learning-based)基于深度学习的方法(Deep Learning-based)基于强化学习…...

【uniapp/uview】u-datetime-picker 选择器的过滤器用法
引入:要求日期选择的下拉框在分钟显示时,只显示 0 和 30 分钟; <u-datetime-picker :show"dateShow" :filter"timeFilter" confirm"selDateConfirm" cancel"dateCancel" v-model"value1&qu…...

如何使用Docker部署Nacos服务?Nacos Docker 快速部署指南: 一站式部署与配置教程
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

yocto stm32mp1集成ros
yocto stm32mp1集成ros yocto集成ros下载meta-rosyocto集成rosrootfs验证 yocto集成ros 本章节介绍yocto如何集成ros系统用来作机器人开发。 下载meta-ros 第一步首先需要下载meta-ros layer,meta-ros的链接如下:https://github.com/ros/meta-ros/tre…...
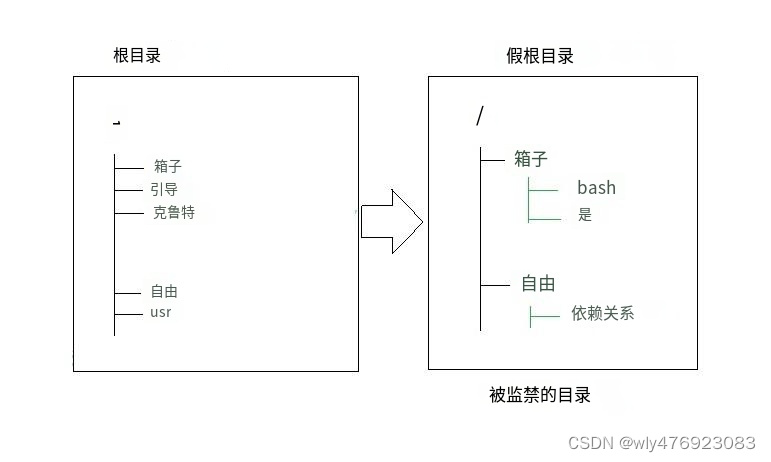
Linux 中的 chroot 命令及示例
Linux/Unix系统中的chroot命令用于更改根目录。Linux/Unix 类系统中的每个进程/命令都有一个称为root 目录的当前工作目录。它更改当前正在运行的进程及其子进程的根目录。 在此类修改的环境中运行的进程/命令无法访问根目录之外的文件。这种修改后的环境称为“ chroot监狱”或…...

oracle的redo与postgreSQL的WAL以及MySQL的binlog区别
Oracle的redo日志、PostgreSQL的WAL(Write-Ahead Log)以及MySQL的binlog(二进制日志)都是数据库的事务日志,但它们在实现和功能上有一些区别。 1. 实现方式: - Oracle的redo日志是通过在事务提交前将事务操作记录到磁盘上的重做日志文件中来实现的。 - PostgreSQL…...

进入低功耗和唤醒
休眠模式 进入休眠模式 如果使用 WFI 指令进入睡眠模式,则嵌套向量中断控制器 (NVIC) 确认的任意外设中断都会 将器件从睡眠模式唤醒。 如果使用 WFE 指令进入睡眠模式,MCU 将在有事件发生时立即退出睡眠模式。唤醒事件可 通过以下方式产生ÿ…...
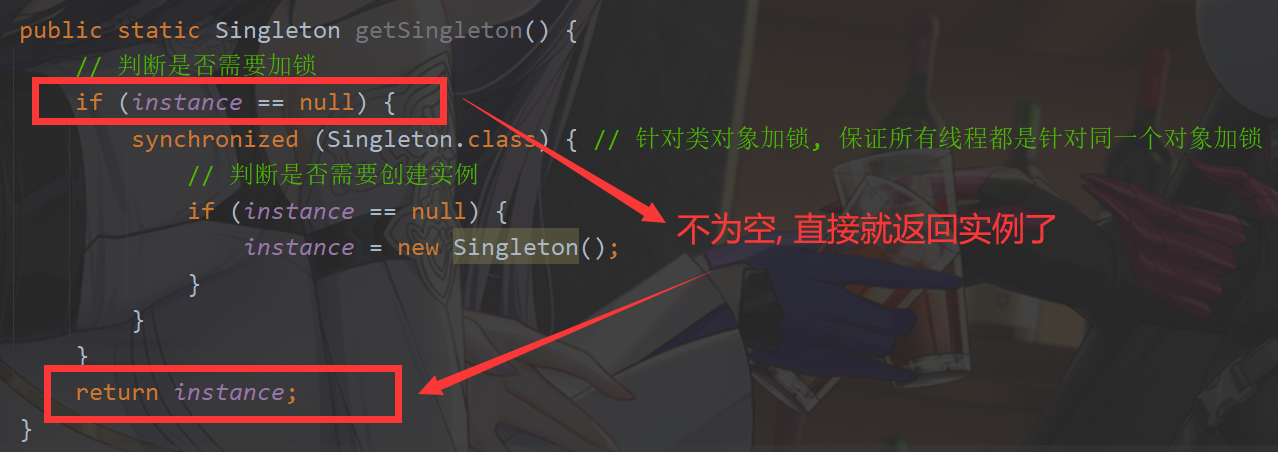
【多线程】volatile 关键字
volatile 关键字 1. 保证内存可见性2. 禁止指令重排序3. 不保证原子性 1. 保证内存可见性 内存可见性问题: 一个线程针对一个变量进行读取操作,另一个线程针对这个变量进行修改操作, 此时读到的值,不一定是修改后的值,即这个读线…...

【Windows注册表内容详解】
Windows注册表内容详解 第一章节 注册表基础 一、什么是注册表 注册表是windows操作系统、硬件设备以及客户应用程序得以正常运行和保存设置的核心“数据库”,也可以说是一个非常巨大的树状分层结构的数据库系统。 注册表记录了用户安装在计算机上的软件和每个程…...
大数据Hadoop入门之集群的搭建
hadoop的三种运行模式 本地模式:测试本地的hadoop是否能够运行,用来运行官方的代码。伪分布模式:原先有人拿来测试,目前测试都不用这个模式了。完全分布模式:多台服务器组成分布式环境,生产环境使用 分布式主机文件同步命令 sc…...

华为云云耀云服务器L实例评测|基于云服务器的minio部署手册
华为云云耀云服务器L实例评测|基于云服务器的minio部署手册 【软件安装版本】【集群安装(是)(否)】 版本 创建人 修改人 创建时间 备注 1.0 jz jz 2023.9.2 minio华为云耀服务器 一. 部署规划与架…...

龙智携手Atlassian和JFrog举办线下研讨会,探讨如何提升企业级开发效率与质量
2023年9月8日,龙智将携手Atlassian和JFrog于上海举办线下研讨会,以“大规模开发创新:如何提升企业级开发效率与质量”为主题,邀请龙智高级咨询顾问、Atlassian认证专家叶燕秀,紫龙游戏上海研发中心高级项目管理主管叶凯…...

2023数学建模国赛A题定日镜场的优化设计- 全新思路及代码
背景资料关键信息和要点如下: 定日镜:塔式太阳能光热发电站的基本组件,由纵向转轴和水平转轴组成,用于反射太阳光。 定日镜场:由大量的定日镜组成的阵列。 集热器:位于吸收塔顶端,用于收集太…...

CSS笔记(黑马程序员pink老师前端)圆角边框
圆角边框 border-radius:length; 效果显示 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Documen…...
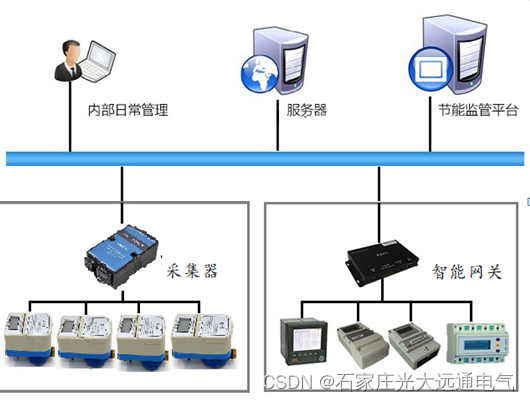
水表电表集中远程抄表系统分析
电表水表远程抄表系统石家庄光大远通电气有限公司主要经营自动抄表,远程抄表,集中抄表,新供应信息,是石家庄光大远通电气有限公司自动远程抄表系统集信号采集、网络通信于一体的高性能抄表装置,该系统以485通讯方式读取水表电表的数据,以MBUS通讯方式读取…...

Android 通知
1. 原生Android通知的几种显示方式: 状态栏的图标:发出通知后,通知会先以图标的形式显示在状态栏中。 抽屉式通知栏:用户可以在状态栏向下滑动以打开抽屉式通知栏,并在其中查看更多详情及对通知执行操作。在应用或用户…...
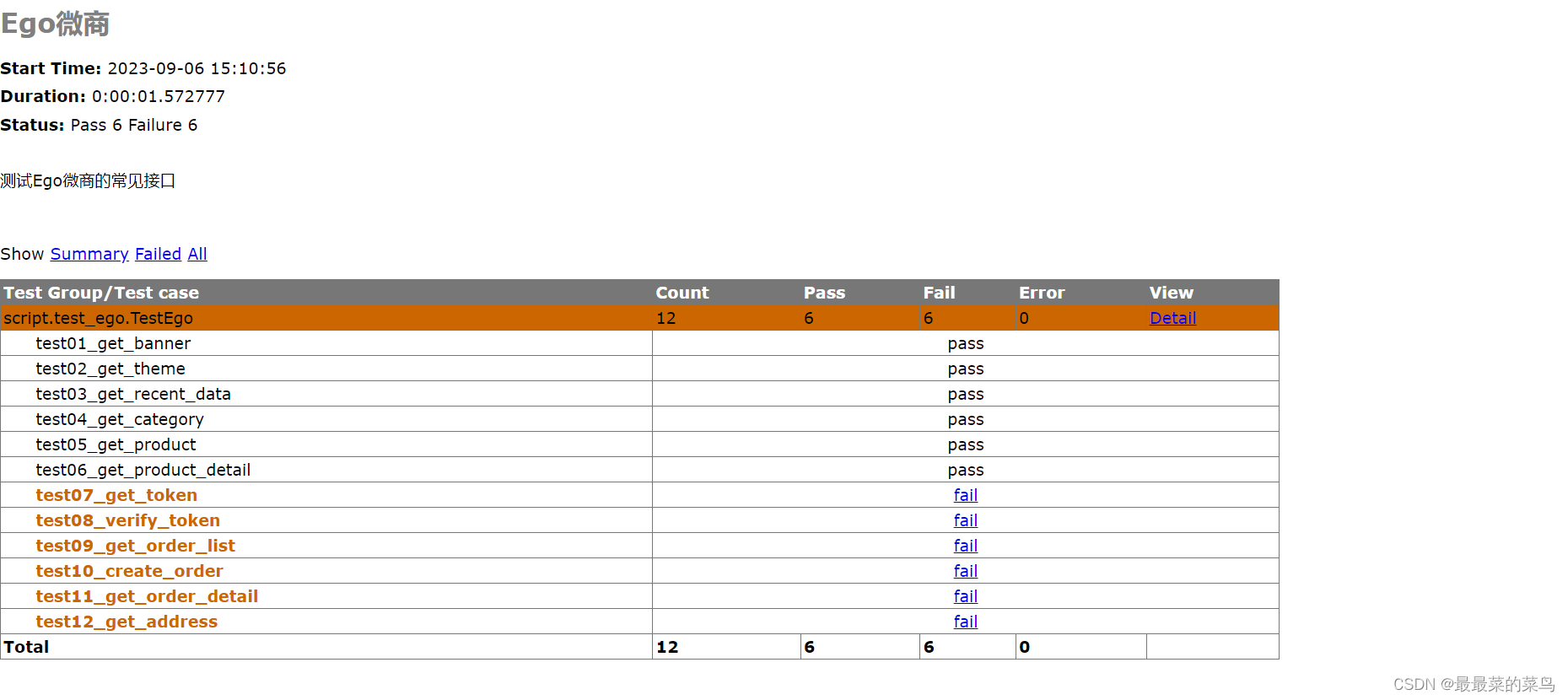
【Unittest】Requests实现小程序项目接口测试
文章目录 一、搭建接口测试框架二、初始化日志三、定义全局变量四、封装接口五、编写测试用例六、生成测试报告 一、搭建接口测试框架 目录结构如下。 二、初始化日志 在utils.py文件中编写如下如下代码,初始化日志。 # 导入app.py全局变量文件 import app import l…...
Mac 搭建本地服务器
文章目录 一、启动服务器二、添加文件到本地服务三、手机/其他电脑 访问本机服务器 MacOS 自带Apatch 服务器。所以我这里选择Apatch服务器搭建 一、启动服务器 在safari中输入 http://127.0.0.1/ ,如果页面出现 it works,则代表访问成功。启动服务器 …...

区块链基础之编写合约二
一、了解solidity中的关键字。 二、了解solidity中的类型。 三、编写合约 1.这里列出一些solidity中的关键字,有哪些。 pragma 作用:是告知编译器如何处理源代码的通用指令(例如, pragma once )。public 作用&#…...

AI编程助手文档自动化:dev-docs-skill实现PRD、API与CHANGELOG高效管理
1. 项目概述:一个为AI编程助手“赋能”的文档自动化工具 如果你和我一样,是个在多个项目间穿梭、既要写代码又要维护文档的开发者,那你一定对“文档债”深恶痛绝。代码写完了,功能上线了,但更新API文档、记录变更日志、…...

Python开发进阶之路:探索异步编程与高性能应用
在当今快节奏的软件开发环境中,构建高性能、可扩展的应用程序已成为开发者的首要任务。随着互联网应用的普及,用户对响应速度和并发处理能力的要求越来越高。Python,作为一种广泛使用的高级编程语言,凭借其简洁的语法和强大的生态…...

IP2366至为芯支持C口双向快充的140W多串锂电池充放电SOC芯片
英集芯IP2366是一款应用于移动电源、电动工具、智能家居、储能电源等方案的多串锂电池充电SOC芯片。支持高达140W的双向同步升降压充放电,充电电流可达5A。支持2至6节锂电池/磷酸铁锂电池串联,集成PD3.1、QC3.0等多种快充协议。内置14bit ADC,…...

Arm DDT:高性能计算并行程序调试利器
1. Arm DDT调试工具概述Arm DDT(Distributed Debugging Tool)是Arm公司开发的一款专业级并行程序调试工具,专为高性能计算(HPC)领域设计。作为Arm Forge工具套件的重要组成部分,DDT提供了强大的MPI程序调试…...
)
人工智能体共情能力模块设计与实践(下)
八、实验设计方案 8.1 数据集设计 建议构建一个多场景中文共情对话数据集。 场景分类 场景 示例 客服投诉 订单、退款、物流、系统故障 学习辅导 学不会、考试焦虑、代码报错 工作压力 加班、沟通冲突、任务失败 情绪倾诉 难过、焦虑、失落 决策支持 不知道如何选择 高风险表…...

妙趣AI:开源Agent工具链与AI导航平台的工程实践
1. 妙趣AI:一个AI工具导航与开源Agent生态的实践如果你和我一样,每天被各种新冒出来的AI工具、模型和概念搞得眼花缭乱,同时又对“AI Agent”这个听起来很酷但落地很虚的东西充满好奇,那么“妙趣AI”这个项目可能正是你需要的。它…...
)
STM32L4低功耗实战:用RTC内部唤醒定时1秒,让设备续航翻倍(附CubeIDE配置)
STM32L4低功耗实战:RTC唤醒中断与CubeIDE配置全解析 在电池供电的物联网终端设计中,每微安电流都关乎产品寿命。曾有个智能农业项目,原本预计6个月的传感器续航,因未优化低功耗模式,实际仅维持了3周。这促使我们深入研…...

PFC2D几何操作避坑指南:geometry命令导出STL成功,DXF却报错?手把手教你排查
PFC2D几何操作避坑指南:geometry命令导出STL成功,DXF却报错?手把手教你排查 在岩土工程和颗粒流分析领域,PFC2D/3D作为一款强大的离散元分析软件,其几何操作功能是构建复杂模型的关键。许多用户在尝试使用geometry exp…...
让你的直播码率稳如老狗)
告别I帧卡顿!用H.264帧内刷新(Intra Refresh)让你的直播码率稳如老狗
告别I帧卡顿!用H.264帧内刷新(Intra Refresh)让你的直播码率稳如老狗 直播技术发展到今天,画面流畅度已经成为用户体验的核心指标之一。但许多开发者在实际推流中常遇到一个棘手问题:明明网络带宽充足,却在…...

音频变压器关键参数深度解析:Z值与最大电流的工程实践
音频变压器关键参数深度解析:Z值与最大电流的工程实践引言在专业音频系统、高保真音响以及工业信号隔离场景中,音频变压器始终扮演着不可替代的角色。它的核心使命是在保持信号完整性的同时,完成阻抗匹配、地环路隔离和信号平衡转换三大任务。…...