对于pytorch和对应pytorch网站的探索
一、关于网站上面的那个教程:
适合PyTorch小白的官网教程:Learning PyTorch With Examples - 知乎 (zhihu.com)
这个链接也是一样的,
总的来说,里面讲了这么一件事:
如果没有pytorch的分装好的nn.module用来继承的话,需要设计一个神经网络就真的有很多需要处理的地方,明明可以用模板nn.module来继承得到自己的neural network的对象
然后,我们自己这个network里面设计我们想要实现的东西
[ Pytorch教程 ] 训练分类器 - pytorch中文网 (ptorch.com)
这个网站底部的链接还是有一些东西的
二、训练分类器中的代码-查漏补缺,加油!!
1.CIFAR-10中的图像大小为3x32x32,即尺寸为32x32像素的3通道彩色图像
2.torchvision.utils.make_grid()函数的参数意义和用法:


3.利用plt输出图像,必须是(h,w,channels)的顺序,所以从tensor过来需要permute或者transpose
def imshow(img): #定义这里的局部imshowimg = img / 2 + 0.5 # unnormalize,还是要回去的好吧,img=(img-0.5)/0.5这是均值normlizenpimg = img.numpy() #plt只能绘制numpy_array类型plt.imshow(np.transpose(npimg, (1, 2, 0))) #好像必须进行permute或者transpose得到(h,w,channels)4.和f.max_pool2d是一个可以调用的函数对象,nn.MaxPool2d是一个模板,需要自己设置:
http://t.csdn.cn/mzqv7

5.torch.max(tensor,1)函数的用法:
http://t.csdn.cn/JMBwW
这篇文章讲得很好,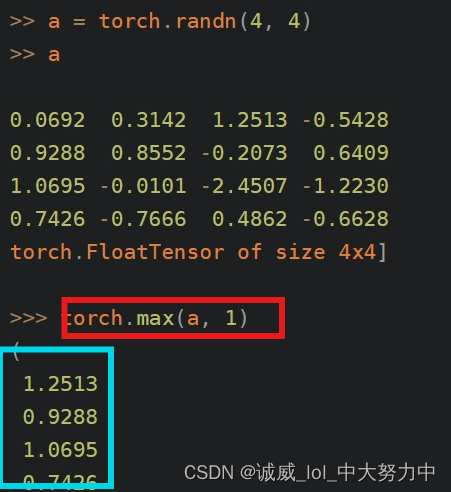
将每一行的最大值组成一个数组
二、代码研读+注释版:
#引入基本的库
import torch
import torchvision
import torchvision.transforms as transforms#利用DataLoader获取train_loader和test_loader
transform = transforms.Compose( #定义ToTensor 和 3个channel上面的(0.5,0.5)正太分布[transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])#获取trainset,需要经过transform处理
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, #设置train_loader参数:batch_size=4,shuffleshuffle=True, num_workers=2) #这个num_woekers子进程不知道会不会报错#同样的处理获取test_loader
testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=2)#定义一个classes数组,其实是用来作为一个map映射使用的
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')#展示一些图像,来点直观的感受
import matplotlib.pyplot as plt
import numpy as np# functions to show an imagedef imshow(img): #定义这里的局部imshowimg = img / 2 + 0.5 # unnormalize,还是要回去的好吧,img=(img-0.5)/0.5这是均值normlizenpimg = img.numpy() #plt只能绘制numpy_array类型plt.imshow(np.transpose(npimg, (1, 2, 0))) #好像必须进行permute或者transpose得到(h,w,channels)# get some random training images
dataiter = iter(trainloader) #dataiter就是迭代器了
images, labels = next(dataiter) #获取第一个images图像数据 和 labels标签 ,注意iter.next()已经改为了next(iter)# show images
imshow(torchvision.utils.make_grid(images)) #以网格的方式显示图像
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4))) #输出labels1-4这样的标题#定义neural network的结构
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5) #定义输入channel=3,输出channel=5,卷积核5*5,stride(default)=1,padding(default)=0self.pool = nn.MaxPool2d(2, 2) #定义pooling池化,kernel_size=2*2,stride 右2,且下2self.conv2 = nn.Conv2d(6, 16, 5) #同上输出channel=16self.fc1 = nn.Linear(16 * 5 * 5, 120) #下面定义了3个Linear函数self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x))) #conv1->relu->poolingx = self.pool(F.relu(self.conv2(x))) #conv2->relu->poolingx = x.view(-1, 16 * 5 * 5) #调整为第二维数16*5*5的大小的tensorx = F.relu(self.fc1(x)) #fc1->relux = F.relu(self.fc2(x)) #fc2->relux = self.fc3(x) #output_linear->得到一个10维度的向量return xnet = Net() #创建一个net对象#定义loss_func和optimizer优化器
import torch.optim as optimcriterion = nn.CrossEntropyLoss() #分类的话,使用nn.CrossEntropyLoss()更好
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) #这里使用初级的SGD#开始train多少个epoch了:
for epoch in range(2): # 0-1总共2个epochrunning_loss = 0.0 #记录loss数值for i, data in enumerate(trainloader, 0): #利用迭代器获取索引和此次batch数据,0代表从第0个索引的batch开始# get the inputsinputs, labels = data #获取inputs图像数据batch 和 labels标签batch# wrap them in Variable#inputs, labels = Variable(inputs), Variable(labels) ,在新版的pytorch中这一行代码已经不需要了# zero the parameter gradientsoptimizer.zero_grad() #每次进行backward方向传播计算gradient之前先调用optimizer.zero_grad()清空,防止积累# forward + backward + optimize ,标准操作:model + criterion + backward + stepoutputs = net(inputs) loss = criterion(outputs, labels)loss.backward()optimizer.step()# print statistics ,每2000个batch进行对应的输出#running_loss += loss.data[0] #将这次batch计算的loss加到running_loss厚葬 ,新版的pytorch中tensor.data弃用#改用tensor.item()了running_loss = loss.item()if i % 2000 == 1999: # print every 2000 mini-batchesprint('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 2000)) #输出:第几个epoch,第几个batch,平均每个batch的lossrunning_loss = 0.0 #归零print('Finished Training')#展示第一批
dataiter = iter(testloader)
images, labels = next(dataiter) #获取一个batch(上面设置了batch_size=4)的images图像数据 和 labels标签# print images
imshow(torchvision.utils.make_grid(images)) #通过网格形式
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))#使用上述的model对第一批进行预测
outputs = net(Variable(images))
#predicted = outputs.data.max(2,keepdim= True)[1] #这样就获得了一个数组
_, predicted = torch.max(outputs.data, 1)
#注意,classes是一个数组,不过是当作map映射使用的
for j in range(4):print(classes[predicted[j]])
#正式开始test了
correct = 0 #正确的数目
total = 0 #总共测试数目
for data in testloader: #每次获取testloader中的1个batchimages, labels = dataoutputs = net(Variable(images)) _, predicted = torch.max(outputs.data, 1) #得到预测的结果数组total += labels.size(0)correct += (predicted == labels).sum() #predicted数组和labels数组逐项比较print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total)) #输出正确率
#对这10种不同的物体对象的检测正确率进行分析:
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
for data in testloader:images, labels = dataoutputs = net(Variable(images))_, predicted = torch.max(outputs.data, 1)c = (predicted == labels).squeeze() #c就是1个1维向量for i in range(4): #一个batch有4张图label = labels[i] #label就是0-9中那个类的indexclass_correct[label] += c[i] #如果c[i]==True就让class_correct+1class_total[label] += 1 #改类图的数目+1for i in range(10): #输出每个类的正确率print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))
相关文章:
对于pytorch和对应pytorch网站的探索
一、关于网站上面的那个教程: 适合PyTorch小白的官网教程:Learning PyTorch With Examples - 知乎 (zhihu.com) 这个链接也是一样的, 总的来说,里面讲了这么一件事: 如果没有pytorch的分装好的nn.module用来继承的话,需要设计…...

和AI聊天:动态规划
动态规划 动态规划(Dynamic Programming,简称 DP)是一种常用于优化问题的算法。它解决的问题通常具有重叠子问题和最优子结构性质,可以通过将问题分解成相互依赖的子问题来求解整个问题的最优解。 动态规划算法主要分为以下几个步…...

微信小程序——使用插槽slot快捷开发
微信小程序的插槽(slot)是一种组件化的技术,用于在父组件中插入子组件的内容。通过插槽,可以将父组件中的一部分内容替换为子组件的内容,实现更灵活的组件复用和定制。 插槽的使用步骤如下: 在父组件的wx…...
大数据技术之Hadoop:使用命令操作HDFS(四)
目录 一、创建文件夹 二、查看指定目录下的内容 三、上传文件到HDFS指定目录下 四、查看HDFS文件内容 五、下载HDFS文件 六、拷贝HDFS文件 七、HDFS数据移动操作 八、HDFS数据删除操作 九、HDFS的其他命令 十、hdfs web查看目录 十一、HDFS客户端工具 11.1 下载插件…...
静态路由配置实验:构建多路由器网络拓扑实现不同业务网段互通
文章目录 一、实验背景与目的二、实验拓扑三、实验需求四、实验解法1. 配置 IP 地址2. 按照需求配置静态路由,实现连接 PC 的业务网段互通 摘要: 本实验旨在通过配置网络设备的IP地址和静态路由,实现不同业务网段之间的互通。通过构建一组具有…...

Python函数的概念以及定义方式
一. 前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 二. 什么是函数? 假设你现在是一个工人,如果你实现就准备好了工具,等你接收到任务的时候, 直接带上工…...
【数学建模竞赛】超详细Matlab二维三维图形绘制
二维图像绘制 绘制曲线图 g 是表示绿色 b--o是表示蓝色/虚线/o标记 c*是表示蓝绿色(cyan)/*标记 ‘MakerIndices,1:5:length(y) 每五个点取点(设置标记密度) 特殊符号的输入 序号 需求 函数字符结构 示例 1 上角标 ^{ } title( $ a…...

2023国赛数学建模E题思路代码 黄河水沙监测数据分析
E题最大的难度是数据处理,可以做一个假设,假设一定时间内流量跟含沙量不变,那么我们可以对数据进行向下填充,把所有的数据进行合并之后可以对其进行展开特性分析,在研究调水调沙的实际效果时,可以先通过分析…...
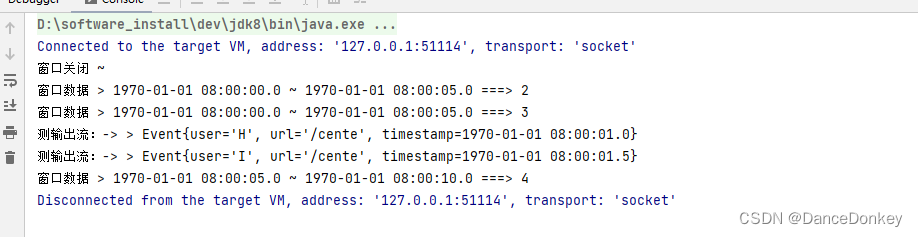
窗口延时、侧输出流数据处理
一 、 AllowedLateness API 延时关闭窗口 AllowedLateness 方法需要基于 WindowedStream 调用。AllowedLateness 需要设置一个延时时间,注意这个时间决定了窗口真正关闭的时间,而且是加上WaterMark的时间,例如 WaterMark的延时时间为2s&…...

发送HTTP请求
HTTP请求是一种客户端向服务器发送请求的协议。它是基于TCP/IP协议的应用层协议,用于在Web浏览器和Web服务器之间传输数据。 HTTP请求由以下几个部分组成: 请求行:包含请求方法、请求的URL和HTTP协议的版本。常见的请求方法有GET、POST、PUT、…...

高等工程数学张韵华版第四章课后题答案
下面答案仅供参考! 章节目录 第4章 欧氏空间和二次型 4.1内积和欧氏空间 4.1.1内积的定义 4.1.2欧氏空间的性质 4.1.3 正交投影 4.1.4 施密特正交化 4.2 正交变换和对称变换 4.2.1 正交变换 4.2.2 正交矩阵 4.2.3 对称变换 4.2.4 对称矩阵 4.3 二…...
wpf C# 用USB虚拟串口最高速下载大文件 每包400万字节 平均0.7s/M,支持批量多设备同时下载。自动识别串口。源码示例可自由定制。
C# 用USB虚拟串口下载大文件 每包400万字节 平均0.7s/M。支持批量多设备同时下载。自动识别串口。可自由定制。 int 32位有符号整数 -2147483648~2147483647 但500万字节时 write时报端口IO异常。可能是驱动限制的。 之前用这个助手发文件,连续发送࿰…...

代码随想录二刷day20
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣654. 最大二叉树二、力扣617. 合并二叉树三、力扣700. 二叉搜索树中的搜索四、力扣98. 验证二叉搜索树 前言 一、力扣654. 最大二叉树 /*** Definitio…...

Yolov5如何训练自定义的数据集,以及使用GPU训练,涵盖报错解决
本文主要讲述了Yolov5如何训练自定义的数据集,以及使用GPU训练,涵盖报错解决,案例是检测图片中是否有救生圈。 最后的效果图大致如下: 效果图1效果图2 前言 系列文章 1、详细讲述Yolov5从下载、配置及如何使用GPU运行 2、…...
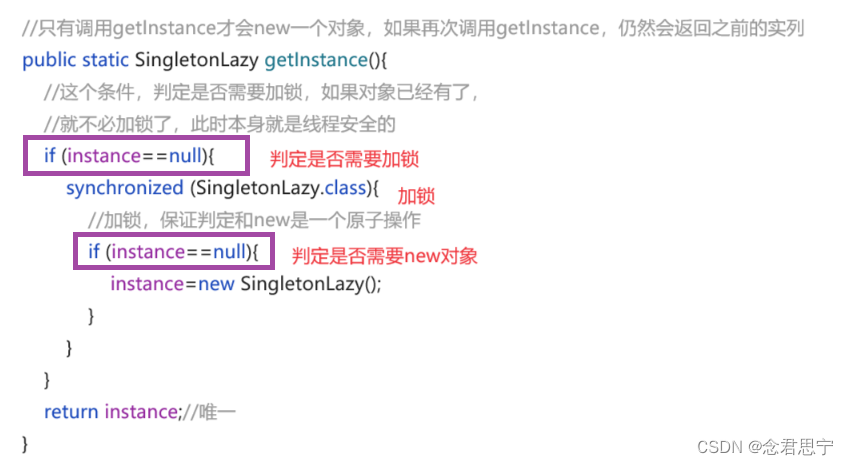
设计模式之单列模式
单列模式是一种经典的设计模式,在校招中最乐意考的设计模式之一~ 设计模式就是软件开发中的棋谱,大佬们针对一些常见的场景,总结出来的代码的编写套路,按照套路来写,不说你写的多好,至少不会太差~ 在校招中…...
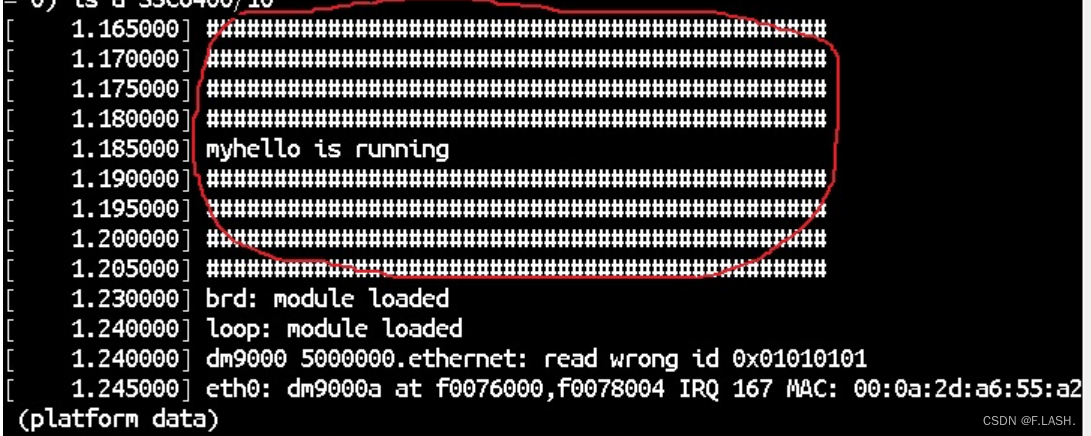
linux内核模块编译方法详解
文章目录 前言一、静态加载法1.1 编写驱动程序1.2 将新功能配置在内核中1.3为新功能代码改写Makefile1.4 make menuconfig界面里将新功能对应的那项选择为<*> 二、动态加载法2.1 新功能源码与Linux内核源码在同一目录结构下2.2 新功能源码与Linux内核源码不在同一目录结构…...

简介shell的关联数组与普通数组
本文首先介绍shell的关联数组,然后介绍shell的普通数组,最后总结它们的共同语法。 shell的关联数组 定义一个关联数组,并打印它的key-value对 #!/bin/sh# 声明一个关联数组 declare -A HASH_MAP# 给关联数组赋值 HASH_MAP["Tom"…...

玩转Mysql系列 - 第17篇:存储过程自定义函数详解
这是Mysql系列第17篇。 环境:mysql5.7.25,cmd命令中进行演示。 代码中被[]包含的表示可选,|符号分开的表示可选其一。 需求背景介绍 线上程序有时候出现问题导致数据错误的时候,如果比较紧急,我们可以写一个存储来…...

自动驾驶:轨迹预测综述
自动驾驶:轨迹预测综述 轨迹预测的定义轨迹预测的分类基于物理的方法(Physics-based)基于机器学习的方法(Classic Machine Learning-based)基于深度学习的方法(Deep Learning-based)基于强化学习…...

【uniapp/uview】u-datetime-picker 选择器的过滤器用法
引入:要求日期选择的下拉框在分钟显示时,只显示 0 和 30 分钟; <u-datetime-picker :show"dateShow" :filter"timeFilter" confirm"selDateConfirm" cancel"dateCancel" v-model"value1&qu…...
:从token消耗策略、种子可控性、多主体一致性到商用合规链路的断代式升级)
Midjourney版本战争白皮书(V7终结篇 vs V8统治纪元):从token消耗策略、种子可控性、多主体一致性到商用合规链路的断代式升级
更多请点击: https://intelliparadigm.com 第一章:V7终结篇与V8统治纪元的战略分水岭 V7 版本的正式 EOL(End-of-Life)标志着一个技术周期的谢幕,而 V8 的全面 GA(General Availability)则开启…...

知识付费浪潮下的技术学习:是捷径,还是新的信息茧房?
当“知识”成为一种商品打开手机,各类技术公众号、知识星球、极客时间专栏、慕课网实战课、B站充电视频……铺天盖地的“测试开发进阶”“性能测试大师班”“自动化测试框架实战”正以9.9元、199元、3999元的价格被明码标价。作为一名软件测试工程师,我们…...

GitHub加速终极指南:3步让你的下载速度提升10倍!
GitHub加速终极指南:3步让你的下载速度提升10倍! 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 还在为Git…...

终极开源硬件控制方案:5分钟实现OMEN游戏本深度性能调优
终极开源硬件控制方案:5分钟实现OMEN游戏本深度性能调优 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub OmenSuperHub是一款专为惠普OMEN游戏本…...

从ARIMA差分到MIM网络:一个老派时间序列技巧如何革新了深度学习预测
从差分思想到记忆网络:传统时间序列技巧如何重塑深度学习架构 在气象预报的雷达回波图中,降水云团的形态每秒钟都在剧烈变化;城市交通流量监测数据里,早晚高峰的波动与平峰期形成鲜明对比;股票市场的价格曲线更是以难以…...
算力优化细节详解)
DeepSeek(V3为主、兼顾V2/R1)算力优化细节详解
DeepSeek(V3为主、兼顾V2/R1)算力优化细节详解以下是针对核心优化模块的深入技术拆解,包含MLA数学原理、FP8精准实现、无辅助损失负载均衡、R1-GRPO算法核心,内容基于DeepSeek-V3官方技术报告及2026年5月公开权威分析。DeepSeek系…...

ClickHouse性能优化:OLAP数据库实战,让查询飞起来
**作者:洛水石** | **更新日期:2026-05-11** | **标签:ClickHouse | OLAP | 数据库优化 | 大数据**前言上个月,运营同学找我抱怨:每天凌晨的报表查询要等5分钟才能出来,数据量大的时候直接超时。作为DBA&am…...

轴承剩余寿命预测 | 基于BP神经网络的轴承剩余寿命预测MATLAB实现!
研究背景 该代码基于IEEE PHM 2012数据挑战赛的轴承全寿命加速退化实验数据,旨在利用数据驱动方法预测滚动轴承的剩余使用寿命(RUL)。实验中轴承在恒定负载下持续运行至失效,期间通过水平/竖直加速度传感器以25.6 kHz采样频率每隔…...

Tinke:免费开源NDS游戏资源提取工具,轻松解密任天堂DS游戏文件
Tinke:免费开源NDS游戏资源提取工具,轻松解密任天堂DS游戏文件 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 你是否曾好奇NDS游戏内部藏着什么秘密?想要提取…...

如何快速恢复加密压缩包密码:ArchivePasswordTestTool完整指南
如何快速恢复加密压缩包密码:ArchivePasswordTestTool完整指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经遇到过…...