【100天精通Python】Day59:Python 数据分析_Pandas高级功能-多层索引创建访问切片和重塑操作,pandas自定义函数和映射功能
目录
1 多层索引(MultiIndex)
1.1 创建多层索引
1.1.1 从元组创建多层索引
1.1.2 使用 set_index() 方法创建多层索引
1.2 访问多层索引数据
1.3 多层索引的层次切片
1.4 多层索引的重塑
2 自定义函数和映射
2.1 使用 apply() 方法进行自定义函数操作
2.2 使用 map() 方法进行映射操作
2.3 使用 applymap() 进行元素级的自定义函数操作
3 Pandas性能优化常用技巧和操作
1 多层索引(MultiIndex)
Pandas 的多层索引(MultiIndex)允许你在一个DataFrame的行或列上拥有多个层次化的索引,这使得你能够处理更复杂的数据结构,例如多维时间序列数据或具有层次结构的数据。以下是多层索引的详细说明和示例:
1.1 创建多层索引
你可以使用多种方式来创建多层索引,包括从元组、列表或数组创建,或者通过设置 set_index() 方法。以下是一些示例:
1.1.1 从元组创建多层索引
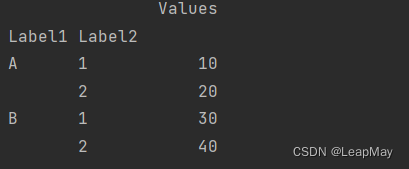
import pandas as pd# 从元组创建多层索引
index = pd.MultiIndex.from_tuples([('A', 1), ('A', 2), ('B', 1), ('B', 2)], names=['Label1', 'Label2'])# 创建带多层索引的DataFrame
data = {'Values': [10, 20, 30, 40]}
df = pd.DataFrame(data, index=index)
print(df)
1.1.2 使用 set_index() 方法创建多层索引
import pandas as pd# 创建一个普通的DataFrame
data = {'Label1': ['A', 'A', 'B', 'B'],'Label2': [1, 2, 1, 2],'Values': [10, 20, 30, 40]}
df = pd.DataFrame(data)# 使用set_index()方法将列转换为多层索引
df.set_index(['Label1', 'Label2'], inplace=True)
print(df)
1.2 访问多层索引数据
你可以使用 .loc[] 方法来访问多层索引中的数据。通过提供多个索引级别的标签,你可以精确地选择所需的数据。以下是一些示例:
# 访问指定多层索引的数据
print(df.loc['A']) # 访问Label1为'A'的所有数据
print(df.loc['A', 1]) # 访问Label1为'A'且Label2为1的数据
1.3 多层索引的层次切片
你可以使用切片操作来选择多层索引的一部分数据。如下:
# 切片操作:选择Label1为'A'到'B'的数据
print(df.loc['A':'B'])# 切片操作:选择Label1为'A'且Label2为1到2的数据
print(df.loc['A', 1:2])
1.4 多层索引的重塑
你可以使用 .stack() 和 .unstack() 方法来重塑具有多层索引的数据。.stack() 可以将列标签转换为索引级别,而 .unstack() 可以将索引级别转换为列标签。如下:
# 使用stack()方法将列标签转换为索引级别
stacked_df = df.stack()# 使用unstack()方法将索引级别转换为列标签
unstacked_df = stacked_df.unstack()
这些是关于Pandas多层索引的基本说明和示例。多层索引是处理复杂数据的重要工具,使你能够更灵活地组织和访问数据。你可以根据数据的特点和需求来选择使用多层索引的方式。
2 自定义函数和映射
在 Pandas 中,你可以使用自定义函数和映射来对数据进行转换和处理。这些方法非常有用,因为它们允许你根据自己的需求自定义数据操作。以下是有关如何在 Pandas 中使用自定义函数和映射的详细说明和示例:
2.1 使用 apply() 方法进行自定义函数操作
apply() 方法可以用于在DataFrame的行或列上应用自定义函数。你可以将一个函数应用到一列,也可以将其应用到整个DataFrame。以下是示例:
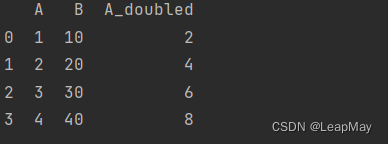
import pandas as pd# 创建一个示例DataFrame
data = {'A': [1, 2, 3, 4],'B': [10, 20, 30, 40]}
df = pd.DataFrame(data)# 自定义函数,将A列的值加倍
def double(x):return x * 2# 使用apply()将自定义函数应用到A列
df['A_doubled'] = df['A'].apply(double)print(df)
输出:
2.2 使用 map() 方法进行映射操作
map() 方法可以用于将一个Series的值映射为另一个Series的值,通常用于对某一列进行值替换或映射。以下是示例:
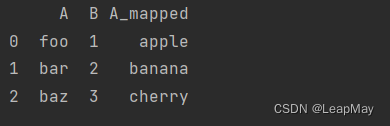
import pandas as pd# 创建一个示例DataFrame
data = {'A': ['foo', 'bar', 'baz'],'B': [1, 2, 3]}
df = pd.DataFrame(data)# 创建一个字典来映射A列的值
mapping = {'foo': 'apple', 'bar': 'banana', 'baz': 'cherry'}# 使用map()将A列的值映射为新的值
df['A_mapped'] = df['A'].map(mapping)print(df)
输出:
2.3 使用 applymap() 进行元素级的自定义函数操作
applymap() 方法用于对DataFrame的每个元素应用自定义函数。这是一种适用于整个DataFrame的元素级别的操作。以下是示例:
import pandas as pd# 创建一个示例DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6]}
df = pd.DataFrame(data)# 自定义函数,将每个元素乘以2
def double(x):return x * 2# 使用applymap()将自定义函数应用到整个DataFrame
df_doubled = df.applymap(double)print(df_doubled)
输出:

这些是在 Pandas 中使用自定义函数和映射的基本示例。通过使用这些方法,你可以自定义数据操作,使其满足你的需求。无论是进行数据清理、数值计算还是进行值映射,自定义函数和映射都是非常有用的工具。
3 Pandas性能优化常用技巧和操作
Pandas 性能优化是一个重要的主题,特别是当你处理大规模数据集时。以下是一些用于提高 Pandas 性能的一般性建议和技巧:
选择合适的数据结构: 在 Pandas 中,有两种主要的数据结构,DataFrame 和 Series。确保选择最适合你数据的结构。例如,如果你只需要处理一维数据,使用 Series 比 DataFrame 更高效。
避免使用循环: 尽量避免使用显式的循环来处理数据,因为它们通常比 Pandas 内置的向量化操作慢。使用 Pandas 内置的函数和方法,如
apply()、map()和groupby()来替代循环操作。使用
at和iat访问元素: 如果只需要访问单个元素而不是整个行或列,请使用.at[]和.iat[]方法,它们比.loc[]和.iloc[]更快。使用
.loc[]和.iloc[]进行切片: 使用.loc[]和.iloc[]可以实现更快的切片和索引,避免复制数据。使用.loc[]和.iloc[]进行索引: 使用.loc[]和.iloc[]索引器来访问数据,这比直接使用中括号[]更高效,特别是当你需要选择多行或多列时。适当设置内存选项: 通过设置 Pandas 的内存选项,如
pd.set_option('max_rows', None)和pd.set_option('max_columns', None),可以控制显示的最大行数和列数。这有助于防止在大型数据集上显示大量数据。合并和连接优化: 使用合适的合并和连接方法,如
pd.merge()和pd.concat(),并使用on、how和suffixes等参数来优化操作。使用合适的数据类型:尽量使用
astype()方法来显式指定数据类型,而不是让 Pandas 自动推断。这可以减少内存使用并提高性能。 Pandas 会自动为每一列选择数据类型,但你可以显式指定数据类型来减少内存使用并提高性能。使用pd.to_numeric()、pd.to_datetime()等方法将列转换为正确的数据类型。使用 HDF5 存储: 对于大型数据集,考虑将数据存储在 HDF5 格式中,以便快速读取和写入数据。
适时使用
inplace参数: 在 Pandas 中,许多方法默认不会修改原始数据,而是返回一个新的对象。如果你确定要在原始数据上进行操作而不需要创建新对象,可以使用inplace=True参数来节省内存和提高性能。并行处理: 对于大数据集,考虑使用并行计算来加速数据处理。Pandas 提供了
multiprocessing库来实现并行处理。
相关文章:
【100天精通Python】Day59:Python 数据分析_Pandas高级功能-多层索引创建访问切片和重塑操作,pandas自定义函数和映射功能
目录 1 多层索引(MultiIndex) 1.1 创建多层索引 1.1.1 从元组创建多层索引 1.1.2 使用 set_index() 方法创建多层索引 1.2 访问多层索引数据 1.3 多层索引的层次切片 1.4 多层索引的重塑 2 自定义函数和映射 2.1 使用 apply() 方法进行自定义函…...
javaee springMVC 一个案例
项目结构 pom.xml <?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/P…...
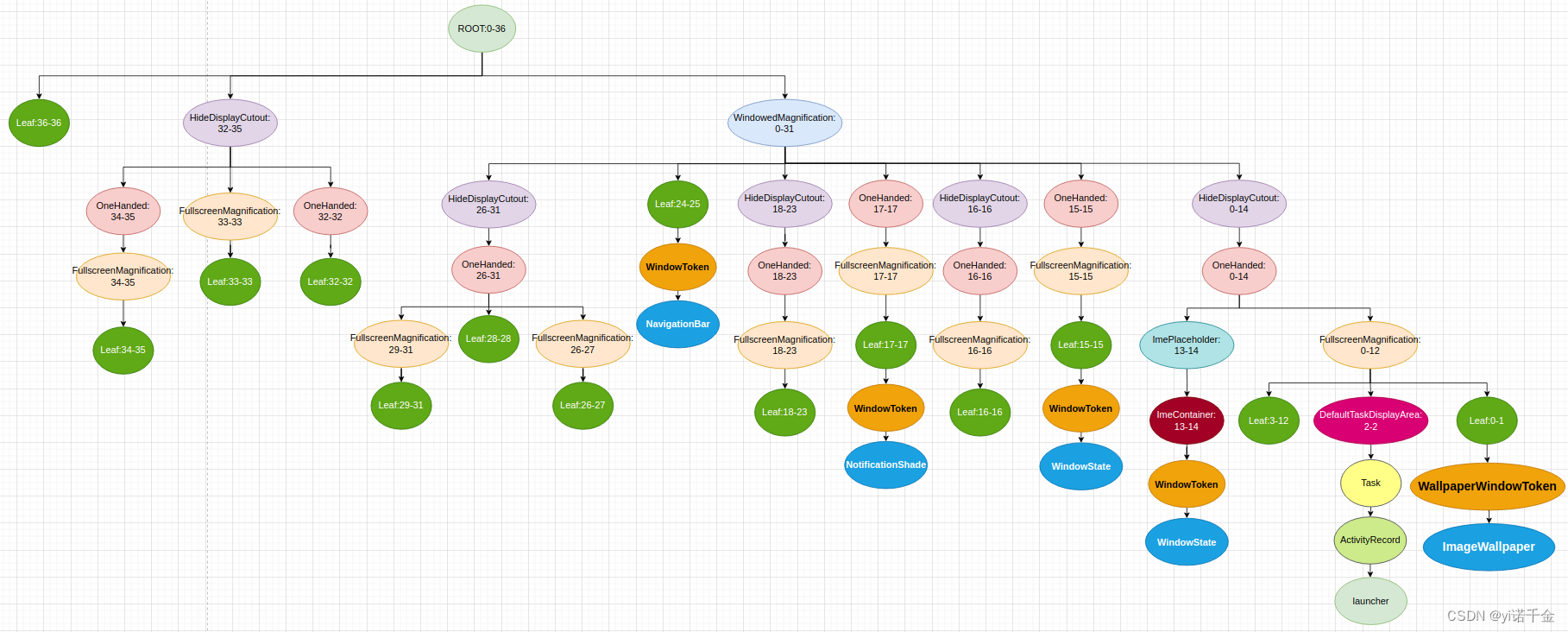
Android T 窗口层级其三 —— 层级结构树添加窗口(更新中)
序 尚未添加窗口的层级结构树,如图 DisplayArea层级结构中的每一个DisplayArea,都包含着一个层级值范围,这个层级值范围表明了这个DisplayArea可以容纳哪些类型的窗口。 每种窗口类型,都可以通过WindowManagerPolicy.getWindowLa…...
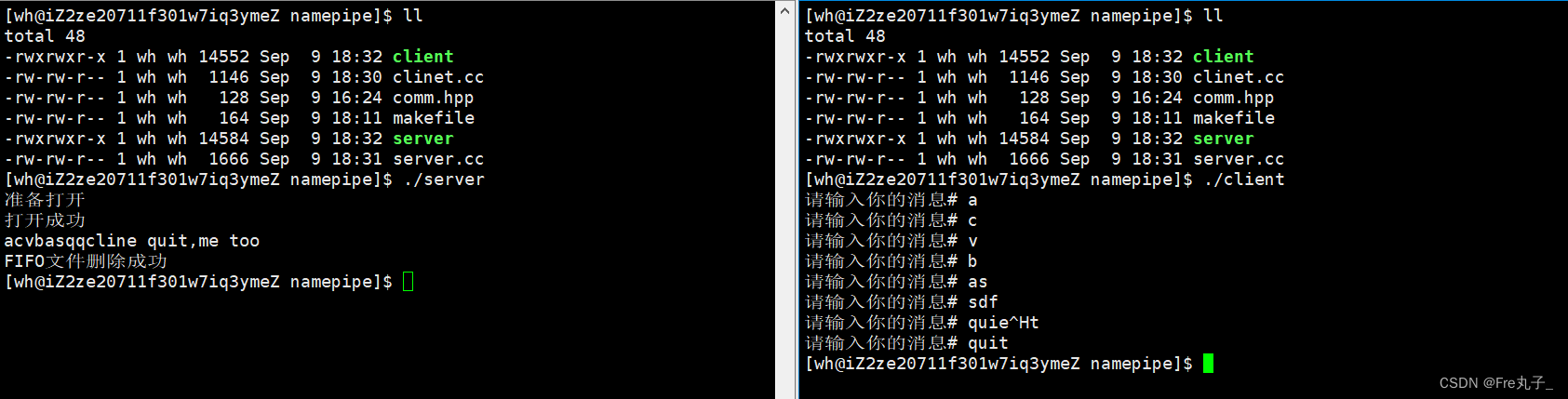
【Linux】管道
管道命令 #include <unistd.h> int pipe(int pipefd[2]); 在Linux中,管道(pipe)的返回值是一个整数数组,包含两个文件描述符。这两个文件描述符分别代表管道的读端和写端。 当成功创建一个管道时,pipe() 系统调用…...
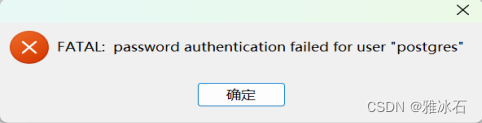
postgre 12.11单实例安装文档
一 下载 访问https://www.postgresql.org/download/,点击左侧的‘source进行下载,一般选择bz2的安装包。 二 安装 这里安装12.11版本的postgre,数据目录路径为/data/server/pgdata,端口为5432. 2.1 安装依赖包 #安装 yum in…...

使用LightPicture开源搭建私人图床:详细教程及远程访问配置方法
文章目录 1.前言2. Lightpicture网站搭建2.1. Lightpicture下载和安装2.2. Lightpicture网页测试2.3.cpolar的安装和注册 3.本地网页发布3.1.Cpolar云端设置3.2.Cpolar本地设置 4.公网访问测试5.结语 1.前言 现在的手机越来越先进,功能也越来越多,而手机…...
:最初的项目思路(SLAM))
基于视觉重定位的室内AR导航项目思路(1):最初的项目思路(SLAM)
文章目录 最初的项目思路(SLAM):后文: 前情提要: 是第一次做项目的小白,文章内的资料介绍如有错误,请多包含! 最初的项目思路(SLAM): 由于我们在…...
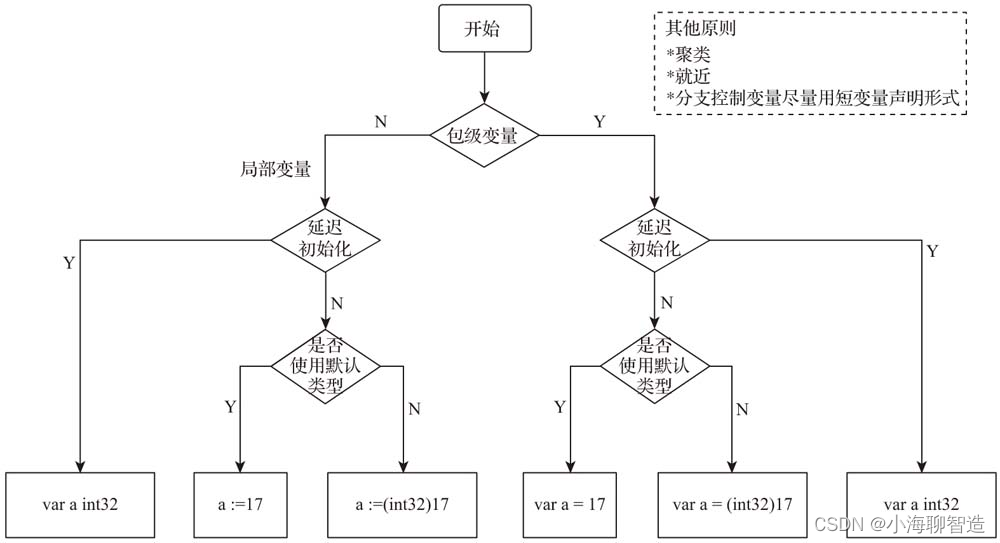
小白学go基础05-变量声明形式
和Python、Ruby等动态脚本语言不同,Go语言沿袭了静态编译型语言的传统:使用变量之前需要先进行变量的声明。 变量声明形式使用决策流程图 这里大致列一下Go语言常见的变量声明形式: var a int32 var s string "hello" var i 13 …...

高可用Kuberbetes部署Prometheus + Grafana
概述 阅读官方文档部署部署Prometheus Grafana GitHub - prometheus-operator/kube-prometheus at release-0.10 环境 步骤 下周官方github仓库 git clone https://github.com/prometheus-operator/kube-prometheus.git git checkout release-0.10 进入工作目录 cd kube…...
ardupilot 安装gcc-arm-none-eabi编译工具
目录 文章目录 目录摘要0简介1.下载网站2.安装摘要 本节主要记录ardupilot使用的编译器安装过程。 0简介 gcc-arm-none-eabi是GNU项目下的软件,是一个面向裸机arm的编译器。那么说了这么多介绍,它都包含什么具体功能又怎么安装与使用呢,我们继续。 1.下载网站 gcc-arm-n…...

ORACLE集群管理-19C RAC重新配置IPV6
1 问题概述 数据库已经配置和IPV6和 IPV4双线协议,需要重新配置IPV6 2 关闭相关资源 1 root用户执行 ./srvctl stop scan_listener -i 1 ./srvctl stop scan ./srvctl stop listener -n orcldb1 ./srvctl stop listener -n orcldb2 ./srvctl stop vip -n orcldb…...
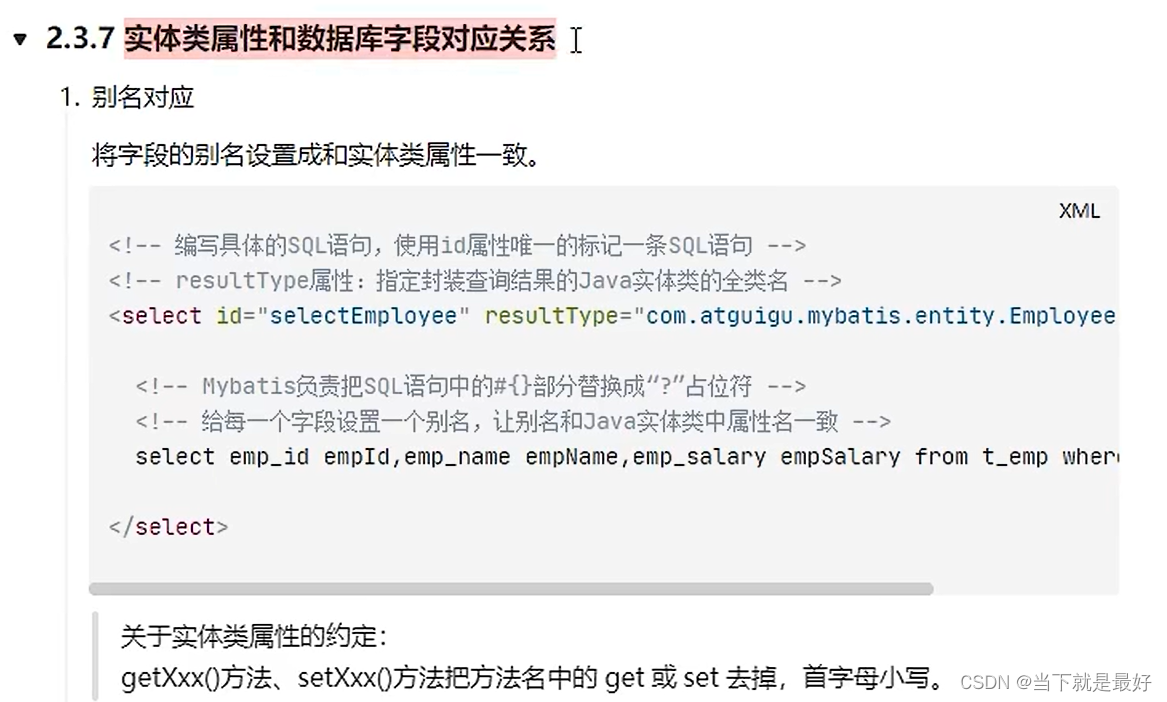
Mybatis实体类属性与数据库字段的对应关系
方法一:起别名 select t_id(数据库字段) tId(类的属性), ... , ...from 表名 方法二:开启驼峰映射 <!-- 开启驼峰映射 数据库 s_id java类 sId--><setting name"mapUnderscoreToCamelCase" value"true"/> 当java类中属性命名…...

Unity(三) Shader着色器初探
学习3D开发技术的时候无可避免的要接触到Shader,那么Shader是个什么概念呢?其实对于开发同事来说还是比较难理解的,一般来说Shader是服务于图形渲染的一类技术,开发人员可以通过其shader语言来自定义显卡渲染页面的算法࿰…...
苹果电脑要安装杀毒软件吗?mac用什么杀毒软件好?
对于这个问题让人很是纠结,Mac不需要杀毒这个理论一直都深入人心,Mac OS X权限管理特性可以防毒的说法也一直甚嚣尘上,很多小伙伴如我一样搞不清楚到底要不要安装杀毒软件。,毕竟当前个人信息安全泄露泛滥不穷的年代,我…...

MySQL——索引
索引在 MySQL 数据库中分三类: B 树索引Hash 索引全文索引 目的:在查询的时候提升效率 b树 参考:https://blog.csdn.net/qq_40649503/article/details/115799935 数据库索引,是数据库管理系统中一个排序的数据结构…...

110. 平衡二叉树
题目链接: 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 递归法: 我的代码: *** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* Tree…...
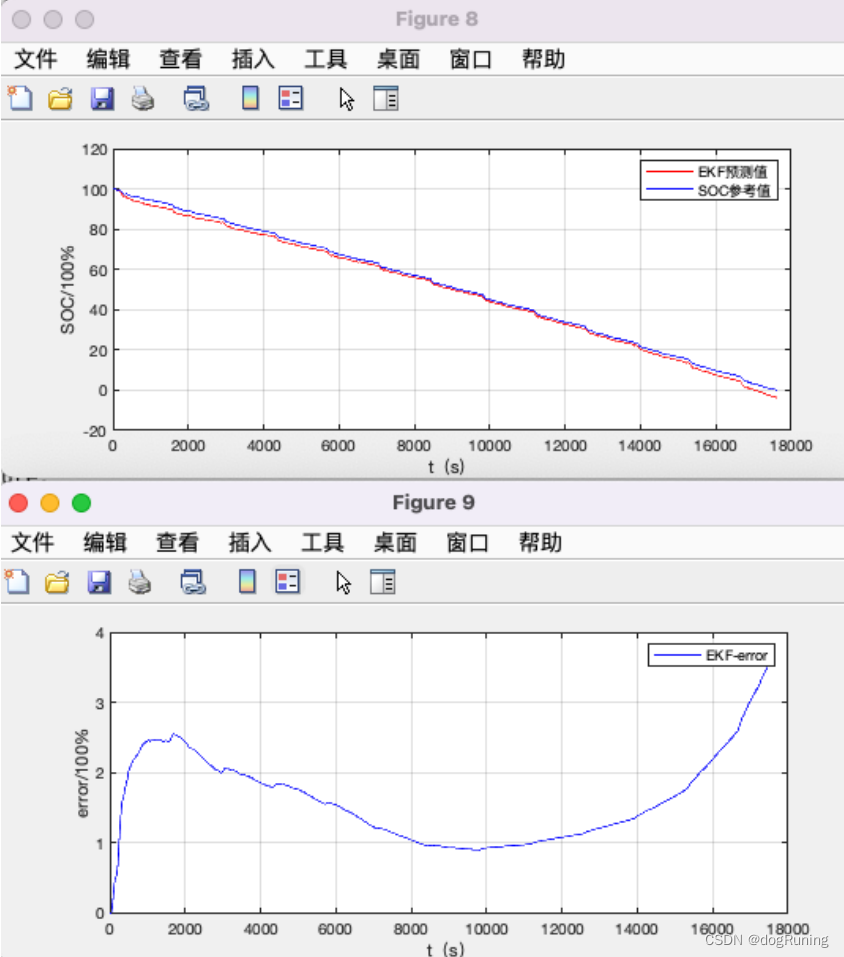
遗忘因子递推最小二乘参数估计(FFRLS)
基于遗忘因子的最小二乘法电池参数辨识 最小二乘法是系统辨识中最常用的一种估算方法。为了克服最小二乘法存在”数据饱和”的问题,我们通常采用含有遗忘因子的递推最小二乘法(Forgetting Factor Recursive Least Square,FFRLS)算法进行电池模型的参数辨识。 1、二…...
【redis进阶】基础知识简要回顾
1. 常见功能介绍 聚合统计 使用list集合的差集、并集来统计 排序统计 SortedSet(ZSet)统计,再利用分页列出权重高的元素 二值状态统计 BitMap存储,获取并统计 SETBIT uid:sign:3000:202008 2 1 GETBIT uid:sign:3000:202008 2…...
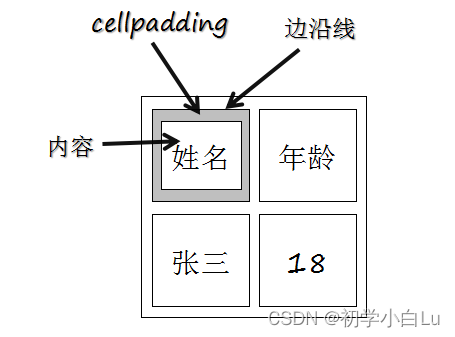
HTML5-3-表格
文章目录 属性边框属性标题跨行和跨列单元格边距 HTML 表格由 <table> 标签来定义。 tr:tr 是 table row 的缩写,表示表格的一行。td:td 是 table data 的缩写,表示表格的数据单元格。th:th 是 table header的缩…...

Spring Boot + Vue的前后端项目结构及联调查询
Spring Boot Vue的前后端项目结构及联调查询 当你刚开始学习前后端开发时,可能会感到有些困惑和不知所措。下面是一些建议,希望能为你的学习之旅提供一些启示: 建立坚实的基础知识:学习前后端开发的第一步是建立坚实的基础知识。…...

Linux下Cursor AI编辑器自动化安装脚本设计与实现
1. 项目概述:为什么我们需要一个Cursor的Linux安装脚本如果你是一个在Linux环境下工作的开发者,并且对AI辅助编程工具感兴趣,那么Cursor这个名字你一定不陌生。作为一款集成了强大AI能力的代码编辑器,它正迅速成为许多程序员的新宠…...

光纤链路故障排查:从指示灯误导到光功率测量的工程实践
1. 项目概述:一个关于“指示灯谎言”的工程教训在电子工程和测试测量领域,我们习惯于依赖设备上的指示灯——那些绿色、红色或琥珀色的小灯——来快速判断系统状态。它们是我们与复杂硬件对话的直观语言。然而,今天我想分享一个十多年前的真实…...

AI工作流框架实战:从脚本到自动化流程的架构设计与应用
1. 项目概述:当AI遇上工作流最近在折腾自动化工具链,发现一个挺有意思的项目叫ai-flow。这名字听起来就挺直白,AI 工作流。简单来说,它就是一个用代码来编排和自动化AI任务(比如调用大语言模型、处理数据、执行特定操…...

ARM Firmware Suite与Evaluator-7T开发板实战指南
1. ARM Firmware Suite与Evaluator-7T开发板概述在嵌入式系统开发领域,ARM架构处理器因其出色的能效比和丰富的生态系统支持,已成为工业控制、物联网设备和消费电子等领域的首选方案。ARM Firmware Suite(AFS)是ARM公司针对其处理…...
)
LaTeX引用中文文献总出乱码?可能是你BibTeX引擎和编码没选对(XeLaTeX+BibTeX实战)
LaTeX中文文献引用乱码全解析:从编码原理到XeLaTeX实战方案 当你熬夜赶论文时,参考文献列表突然变成一堆乱码方块,引用标记全部显示为"??"——这种崩溃瞬间,每个用LaTeX写过中文论文的人都经历过。传统解决方案往往停…...

AI技能学习路径全解析:从数学基础到RAG实战与项目构建
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“HieuNghi-AI-Skills”。光看这个名字,你可能会有点摸不着头脑,这到底是做什么的?是教AI新技能,还是整理AI工具的使用技巧?点进去之后&…...

从音频处理到IoT数据:用scipy.signal.resample_poly搞定实际项目中的采样率转换
从音频处理到IoT数据:用scipy.signal.resample_poly搞定实际项目中的采样率转换 采样率转换是数字信号处理中的常见需求,无论是音频处理、传感器数据分析还是通信系统仿真,都会遇到不同采样率设备间的数据交互问题。想象一下,当你…...

OSINT自动化框架openeir:模块化设计与情报收集流水线构建
1. 项目概述:一个面向开源情报的现代化工具箱最近在整理自己的技术栈时,发现一个挺有意思的项目,叫heyeir/openeir。乍一看这个名字,可能会有点摸不着头脑,但如果你对开源情报(OSINT)领域有所涉…...

Ctool:一站式解决开发者的日常编码烦恼
Ctool:一站式解决开发者的日常编码烦恼 【免费下载链接】Ctool 程序开发常用工具 chrome / edge / firefox / utools / windows / linux / mac 项目地址: https://gitcode.com/gh_mirrors/ct/Ctool 在日常开发工作中,我们常常需要处理各种编码转换…...

Gemini自动生成PPT实战手册:从零输入到专业演示文稿,3步完成95%的幻灯片工作流
更多请点击: https://intelliparadigm.com 第一章:Gemini自动生成PPT的核心原理与能力边界 Gemini 生成 PPT 的本质并非传统模板填充,而是基于多模态理解与结构化内容重构的端到端推理过程。其核心依赖于对用户输入(文本、大纲、…...