C语言对单链表所有操作与一些相关面试题
目录
单链表的特性
单链表的所有操作
定义一个单链表
创建一个链表头
插入数据(头插法)
插入数据(尾插法)
查找节点
修改数据节点
删除节点
打印数据
销毁链表
翻转链表
打印链表长度
冒泡排序
快排
堆排
查找倒数第K个节点(双指针法)
完整测试代码
单链表的特性
单链表是一种线性数据结构,它由一系列的节点组成,每个节点包含一个数据域和一个指向下一个节点的指针域。单链表的特性有:
- 单链表的长度是可变的,可以动态地插入和删除节点。
- 单链表的访问是顺序的,要访问某个节点,必须从头节点开始遍历,直到找到该节点或者到达链表尾部。
- 单链表不需要连续的内存空间,可以利用零散的空间存储数据。
- 单链表的优势是:
- 插入和删除操作比较简单,只需要修改指针域即可,不需要移动其他节点。
- 单链表可以实现一些特殊的功能,如栈、队列、循环链表等。
- 单链表的劣势是:
- 访问操作比较慢,需要遍历整个链表,时间复杂度为O(n)。
- 单链表需要额外的空间存储指针域,增加了空间开销。
- 单链表容易产生内存碎片,如果频繁地插入和删除节点,可能导致内存不连续。
单链表的所有操作
定义一个单链表
// 声明并定义个单链表结构体
typedef struct _ListNode
{int val; //数据 成员变量struct _ListNode * next;//结构体调用自己的类型
}ListNode;创建一个链表头
void listCreate(ListNode *node)
{//初始化链表内数据node->val = -1;node->next = NULL;
}插入数据(头插法)
void listInsert(ListNode *node, int data)
{// 创建一个节点,并申请内存ListNode *t_node = (ListNode *)malloc(sizeof(ListNode));// 节点内容赋值t_node->val = data;// 头插法,新数据在前t_node->next = node->next;node->next = t_node;
}插入数据(尾插法)
void listTailInsert(ListNode *node, int data)
{// 创建一个节点ListNode *t_node = (ListNode*)malloc(sizeof(ListNode));// 节点内容赋值t_node->val = data;t_node->next = NULL;// 声明一个尾节点ListNode* t_tail = node;// 获取最后一个节点while(t_tail->next != NULL){// 后移t_tail = t_tail->next;}//添加节点t_tail->next = t_node;
}查找节点
ListNode* listFind(ListNode *node, int data)
{//申明一个空节点ListNode *t_node = NULL;//遍历链表ListNode *t_temp;for(t_temp = node->next; t_temp != NULL; t_temp = t_temp->next){//如果找到该节点if(t_temp->val == data){t_node = t_temp;//跳出循环break;}}return t_node;
}修改数据节点
void listModify(ListNode *node, int oldData, int newData)
{// 查找值是否存在ListNode *t_node = listFind(node, oldData);// 判断值是否存在if(t_node == NULL){printf("该值不存在\n");return;}t_node->val = newData;
}删除节点
void listDelete(ListNode *node, int data)
{// 查找是否存在改制的数据ListNode *t_node = listFind(node, data);// 如果该值对应的节点不存在if(NULL == t_node){printf("该值不存在\n");return;}// 求出被删节点的前一个节点ListNode *t_prev = node;// 遍历链表while(t_prev->next != t_node){t_prev = t_prev->next;}// 前一个节点的next指向被删除节点的下一个节点t_prev->next = t_node->next;// 释放内存free(t_node);// 指针置空t_node = NULL;
}打印数据
void listDisplay(ListNode *node)
{// 遍历链表ListNode *t_temp;for(t_temp = node->next; t_temp != NULL; t_temp = t_temp->next){printf("%d ",t_temp->val);}printf("\n");
}销毁链表
void listDestroy(ListNode *node)
{// 遍历链表ListNode *t_temp = node->next;while(t_temp != NULL){// 先将当前节点保存ListNode *t_node = t_temp;// 移动到下一各节点t_temp = t_temp->next;// 释放保存内容的节点free(t_node);}
}翻转链表
void listReverse(ListNode *node)
{ListNode * head = NULL, *now = NULL, *temp = NULL;head = node->next;// head是来保存我们翻转以后链表中的头节点的now = head->next;// now用来保存我们当前待处理的节点head->next = NULL;// 一定要置为NULL,否则可能导致循环while(now){temp = now->next; // 利用一个临时指针来保存下一个待处理的节点now->next = head; // 将当前节点插入到逆序节点的第一个节点之前,并更改head指向head = now;node->next = head; // 使链表头指针指向逆序后的第一个节点now = temp; // 更新链表到下一个待处理的节点}
}打印链表长度
int listLength(ListNode *node)
{ListNode *t_temp;int t_length = 0;for(t_temp = node->next; t_temp != NULL; t_temp = t_temp->next){t_length++;}return t_length;
}冒泡排序
void listBubbleSort(ListNode *node)
{int t_length = listLength(node);int i,j;ListNode *t_temp;for(i = 0; i < t_length; i++){t_temp = node->next;for(j = 0;j < t_length - i - 1; j++){if(t_temp->val > t_temp->next->val){int t_data = t_temp->val;t_temp->val = t_temp->next->val;t_temp->next->val = t_data;}t_temp = t_temp->next;}}
}快排
void quickSort(struct _ListNode *head, struct _ListNode *tail) {// 如果链表为空或只有一个节点,直接返回if (head == NULL || head == tail) return;// 定义两个指针p和q,用于分割链表struct _ListNode *p = head, *q = head->next;// 选取第一个节点作为基准值int pivot = head->val;// 遍历链表,将小于基准值的节点放到p的后面while (q != tail->next) {if (q->val < pivot) {p = p->next;// 交换p和q指向的节点的值int temp = p->val;p->val = q->val;q->val = temp;}q = q->next;}// 交换head和p指向的节点的值,使得p指向的节点为基准值int temp = head->val;head->val = p->val;p->val = temp;// 对左右两部分递归进行快速排序quickSort(head, p);quickSort(p->next, tail);
}堆排
// 待实现查找倒数第K个节点(双指针法)
ListNode* listFindKthToTail(ListNode *node, int k)
{// 超过长度直接返回空if(node == NULL || k >= listLength(node))return NULL;ListNode *first = node, *second = node;for(int i = 0; i < k; i++){first = first->next;}while (first){first = first->next;second = second->next;}return second;
}完整测试代码
#include <stdio.h>
#include <stdlib.h>// 声明并定义个单链表结构体
typedef struct _ListNode
{int val; //数据 成员变量struct _ListNode * next;//结构体调用自己的类型
}ListNode;/*** 创建链表
*/
void listCreate(ListNode *node)
{//初始化链表内数据node->val = -1;node->next = NULL;
}/*** 插入数据,头插法
*/
void listInsert(ListNode *node, int data)
{// 创建一个节点,并申请内存ListNode *t_node = (ListNode *)malloc(sizeof(ListNode));// 节点内容赋值t_node->val = data;// 头插法,新数据在前t_node->next = node->next;node->next = t_node;
}/*** 插入数据,尾插法
*/
void listTailInsert(ListNode *node, int data)
{// 创建一个节点ListNode *t_node = (ListNode*)malloc(sizeof(ListNode));// 节点内容赋值t_node->val = data;t_node->next = NULL;// 声明一个尾节点ListNode* t_tail = node;// 获取最后一个节点while(t_tail->next != NULL){// 后移t_tail = t_tail->next;}//添加节点t_tail->next = t_node;
}/*** 查找数据
*/
ListNode* listFind(ListNode *node, int data)
{//申明一个空节点ListNode *t_node = NULL;//遍历链表ListNode *t_temp;for(t_temp = node->next; t_temp != NULL; t_temp = t_temp->next){//如果找到该节点if(t_temp->val == data){t_node = t_temp;//跳出循环break;}}return t_node;
}/*** 修改数据
*/
void listModify(ListNode *node, int oldData, int newData)
{// 查找值是否存在ListNode *t_node = listFind(node, oldData);// 判断值是否存在if(t_node == NULL){printf("该值不存在\n");return;}t_node->val = newData;
}/*** 删除数据
*/
void listDelete(ListNode *node, int data)
{// 查找是否存在改制的数据ListNode *t_node = listFind(node, data);// 如果该值对应的节点不存在if(NULL == t_node){printf("该值不存在\n");return;}// 求出被删节点的前一个节点ListNode *t_prev = node;// 遍历链表while(t_prev->next != t_node){t_prev = t_prev->next;}// 前一个节点的next指向被删除节点的下一个节点t_prev->next = t_node->next;// 释放内存free(t_node);// 指针置空t_node = NULL;
}/*** 打印数据
*/
void listDisplay(ListNode *node)
{// 遍历链表ListNode *t_temp;for(t_temp = node->next; t_temp != NULL; t_temp = t_temp->next){printf("%d ",t_temp->val);}printf("\n");
}/*** 销毁链表
*/
void listDestroy(ListNode *node)
{// 遍历链表ListNode *t_temp = node->next;while(t_temp != NULL){// 先将当前节点保存ListNode *t_node = t_temp;// 移动到下一各节点t_temp = t_temp->next;// 释放保存内容的节点free(t_node);}
}/*** 翻转链表
*/
void listReverse(ListNode *node)
{ListNode * head = NULL, *now = NULL, *temp = NULL;head = node->next;// head是来保存我们翻转以后链表中的头节点的now = head->next;// now用来保存我们当前待处理的节点head->next = NULL;// 一定要置为NULL,否则可能导致循环while(now){temp = now->next; // 利用一个临时指针来保存下一个待处理的节点now->next = head; // 将当前节点插入到逆序节点的第一个节点之前,并更改head指向head = now;node->next = head; // 使链表头指针指向逆序后的第一个节点now = temp; // 更新链表到下一个待处理的节点}
}/*** 求长度
*/
int listLength(ListNode *node)
{ListNode *t_temp;int t_length = 0;for(t_temp = node->next; t_temp != NULL; t_temp = t_temp->next){t_length++;}return t_length;
}/*** 冒泡排序
*/
void listBubbleSort(ListNode *node)
{int t_length = listLength(node);int i,j;ListNode *t_temp;for(i = 0; i < t_length; i++){t_temp = node->next;for(j = 0;j < t_length - i - 1; j++){if(t_temp->val > t_temp->next->val){int t_data = t_temp->val;t_temp->val = t_temp->next->val;t_temp->next->val = t_data;}t_temp = t_temp->next;}}
}/*** 定义快速排序算法
*/
void quickSort(struct _ListNode *head, struct _ListNode *tail) {// 如果链表为空或只有一个节点,直接返回if (head == NULL || head == tail) return;// 定义两个指针p和q,用于分割链表struct _ListNode *p = head, *q = head->next;// 选取第一个节点作为基准值int pivot = head->val;// 遍历链表,将小于基准值的节点放到p的后面while (q != tail->next) {if (q->val < pivot) {p = p->next;// 交换p和q指向的节点的值int temp = p->val;p->val = q->val;q->val = temp;}q = q->next;}// 交换head和p指向的节点的值,使得p指向的节点为基准值int temp = head->val;head->val = p->val;p->val = temp;// 对左右两部分递归进行快速排序quickSort(head, p);quickSort(p->next, tail);
}/*** 快速排序
*/
void listQuickSort(ListNode *node)
{ListNode *tail = node->next;while (tail->next){tail = tail->next;}quickSort(node, tail);
}/*** 堆排序
*/
void listHeapSort(ListNode *node)
{}/*** 获取链表倒数第k个节点,双指针方法
*/
ListNode* listFindKthToTail(ListNode *node, int k)
{// 超过长度直接返回空if(node == NULL || k >= listLength(node))return NULL;ListNode *first = node, *second = node;for(int i = 0; i < k; i++){first = first->next;}while (first){first = first->next;second = second->next;}return second;
}/*** 测试所有函数是否正确有效
*/
int main(int argc, char* argv[])
{//创建一个ListNode变量ListNode node;//创建链表listCreate(&node);int i = 0;for(i = 0;i < 10;i++){
#if 0 listInsert(&node,i); // 插入数据头插法
#elselistTailInsert(&node, i); // 插入数据尾插法
#endif}listDisplay(&node);ListNode* nodeFind = listFind(&node, 3);if(nodeFind)printf("listFind:%d\n", nodeFind->val); const int k = 5;ListNode* nodeFindK = listFindKthToTail(&node, k);if(nodeFindK)printf("listFindKthToTail step:%d :%d\n", k, nodeFindK->val); listModify(&node, 1, 999); //修改节点1为999listDisplay(&node);listDelete(&node, 5); // 删除节点5listDisplay(&node);// listBubbleSort(&node); // 冒泡排序listQuickSort(&node); // quick sortlistDisplay(&node); // 打印链表数据listReverse(&node); // 翻转链表listDisplay(&node); // 打印反转后的链表listDestroy(&node); // 销毁链表return 0;
}相关文章:

C语言对单链表所有操作与一些相关面试题
目录 单链表的特性 单链表的所有操作 定义一个单链表 创建一个链表头 插入数据(头插法) 插入数据(尾插法) 查找节点 修改数据节点 删除节点 打印数据 销毁链表 翻转链表 打印链表长度 冒泡排序 快排 堆排 查找倒数第K个节点(双指针法) …...

高防服务器如何抵御大规模攻击
高防服务器如何抵御大规模攻击?高防服务器是一种专门设计用于抵御大规模攻击的服务器,具备出色的安全性和可靠性。在当今互联网时代,网络安全问题日益严重,DDOS攻击(分布式拒绝服务攻击)等高强度攻击已成为…...

Go 接口和多态
在讲解具体的接口之前,先看如下问题。 使用面向对象的方式,设计一个加减的计算器 代码如下: package mainimport "fmt"//父类,这是结构体 type Operate struct {num1 intnum2 int }//加法子类,这是结构体…...

Git忽略文件的几种方法,以及.gitignore文件的忽略规则
目录 .gitignore文件Git忽略规则以及优先级.gitignore文件忽略规则常用匹配示例: 有三种方法可以实现忽略Git中不想提交的文件。1、在Git项目中定义 .gitignore 文件(优先级最高,推荐!)2、在Git项目的设置中指定排除文…...
C语言——指针进阶(2)
继续上次的指针,想起来还有指针的内容还没有更新完,今天来补上之前的内容,上次我们讲了函数指针,并且使用它来实现一些功能,今天我们就讲一讲函数指针数组等内容,废话不多说,我们开始今天的学习…...

【汇编中的寄存器分类与不同寄存器的用途】
汇编中的寄存器分类与不同寄存器的用途 寄存器分类 在计算机体系结构中,8086CPU,寄存器可以分为以下几类: 1. 通用寄存器: 通用寄存器是用于存储数据和执行算术运算的寄存器。在 x86 架构中,这些通用寄存器通常包括…...
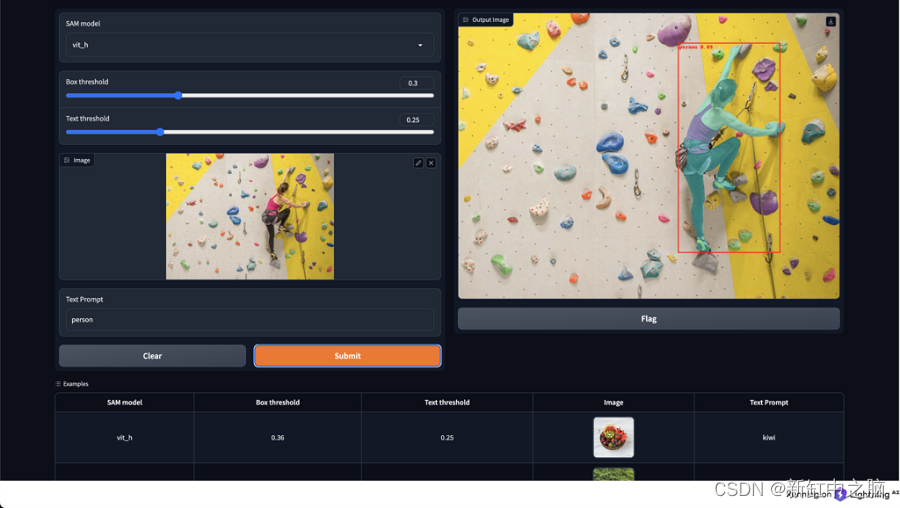
基于文本提示的图像目标检测与分割实践
近年来,计算机视觉取得了显着的进步,特别是在图像分割和目标检测任务方面。 最近值得注意的突破之一是分段任意模型(SAM),这是一种多功能深度学习模型,旨在有效地从图像和输入提示中预测对象掩模。 通过利用…...

【4-5章】Spark编程基础(Python版)
课程资源:(林子雨)Spark编程基础(Python版)_哔哩哔哩_bilibili 第4章 RDD编程(21节) Spark生态系统: Spark Core:底层核心(RDD编程是针对这个)Spark SQL:…...
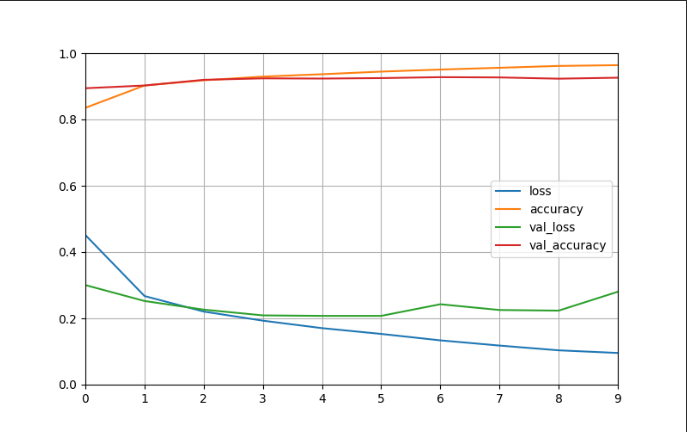
04 卷积神经网络搭建
一、数据集 MNIST数据集是从NIST的两个手写数字数据集:Special Database 3 和Special Database 1中分别取出部分图像,并经过一些图像处理后得到的[参考]。 MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。所有图…...

【hadoop运维】running beyond physical memory limits:正确配置yarn中的mapreduce内存
文章目录 一. 问题描述二. 问题分析与解决1. container内存监控1.1. 虚拟内存判断1.2. 物理内存判断 2. 正确配置mapReduce内存2.1. 配置map和reduce进程的物理内存:2.2. Map 和Reduce 进程的JVM 堆大小 3. 小结 一. 问题描述 在hadoop3.0.3集群上执行hive3.1.2的任…...
)
数据结构--6.5二叉排序树(插入,查找和删除)
目录 一、创建 二、插入 三、删除 二叉排序树(Binary Sort Tree)又称为二叉查找树,它或者是一棵空树,或者是具有下列性质的二叉树: ——若它的左子树不为空,则左子树上所有结点的值均小于它的根结构的值…...
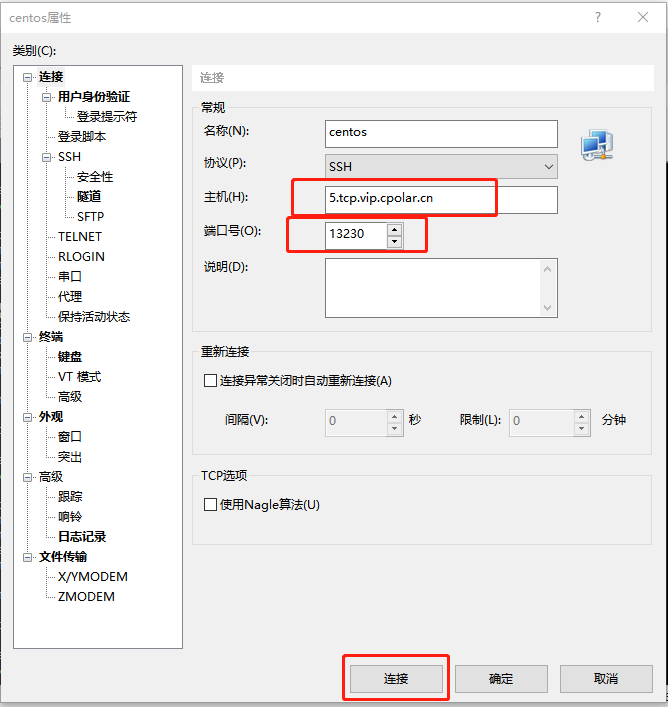
无需公网IP,在家SSH远程连接公司内网服务器「cpolar内网穿透」
文章目录 1. Linux CentOS安装cpolar2. 创建TCP隧道3. 随机地址公网远程连接4. 固定TCP地址5. 使用固定公网TCP地址SSH远程 本次教程我们来实现如何在外公网环境下,SSH远程连接家里/公司的Linux CentOS服务器,无需公网IP,也不需要设置路由器。…...

Java工具类
一、org.apache.commons.io.IOUtils closeQuietly() toString() copy() toByteArray() write() toInputStream() readLines() copyLarge() lineIterator() readFully() 二、org.apache.commons.io.FileUtils deleteDirectory() readFileToString() de…...

makefile之使用函数wildcard和patsubst
Makefile之调用函数 调用makefile机制实现的一些函数 $(function arguments) : function是函数名,arguments是该函数的参数 参数和函数名用空格或Tab分隔,如果有多个参数,之间用逗号隔开. wildcard函数:让通配符在makefile文件中使用有效果 $(wildcard pattern) 输入只有一个参…...

算法通关村第十八关——排列问题
LeetCode46.给定一个没有重复数字的序列,返回其所有可能的全排列。例如: 输入:[1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] 元素1在[1,2]中已经使…...

基于STM32设计的生理监测装置
一、项目功能要求 设计并制作一个生理监测装置,能够实时监测人体的心电图、呼吸和温度,并在LCD液晶显示屏上显示相关数据。 随着现代生活节奏的加快和环境的变化,人们对身体健康的关注程度越来越高。为了及时掌握自身的生理状况,…...

Go-Python-Java-C-LeetCode高分解法-第五周合集
前言 本题解Go语言部分基于 LeetCode-Go 其他部分基于本人实践学习 个人题解GitHub连接:LeetCode-Go-Python-Java-C Go-Python-Java-C-LeetCode高分解法-第一周合集 Go-Python-Java-C-LeetCode高分解法-第二周合集 Go-Python-Java-C-LeetCode高分解法-第三周合集 G…...
)
【前端知识】前端加密算法(base64、md5、sha1、escape/unescape、AES/DES)
前端加密算法 一、base64加解密算法 简介:Base64算法使用64个字符(A-Z、a-z、0-9、、/)来表示二进制数据的64种可能性,将每3个字节的数据编码为4个可打印字符。如果字节数不是3的倍数,将会进行填充。 优点࿱…...
leetcode 925. 长按键入
2023.9.7 我的基本思路是两数组字符逐一对比,遇到不同的字符,判断一下typed与上一字符是否相同,不相同返回false,相同则继续对比。 最后要分别判断name和typed分别先遍历完时的情况。直接看代码: class Solution { p…...

[CMake教程] 循环
目录 一、foreach()二、while()三、break() 与 continue() 作为一个编程语言,CMake也少不了循环流程控制,他提供两种循环foreach() 和 while()。 一、foreach() 基本语法: foreach(<loop_var> <items>)<commands> endfo…...

MSP 盈利、留客、提口碑,核心就盯这12个 KPI
很多 MSP(托管服务提供商)都会陷入一个误区,手里握着一堆散落在各个看板的运营数据,却始终搞不清哪些指标能真正帮自己提升服务质量、拉高利润、留住客户。忙忙碌碌做了一堆报表,最终还是凭感觉做决策,业务…...
)
2026中小企业OA软件排行榜TOP10(精简版)
2026年,中小企业数字化转型进入深水区,OA软件作为办公协同核心工具,是企业提升效率、规范流程、降本增效的关键支撑。随着SaaS模式普及、AI技术深度应用及信创政策落地,OA市场呈现“头部生态下沉、专业工具崛起、性价比为王”的格…...

MTKClient实战指南:联发科设备刷机与逆向工程全面解决方案
MTKClient实战指南:联发科设备刷机与逆向工程全面解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient是一款专为联发科芯片设备设计的开源逆向工程与刷机工具&am…...

5个维度深度解析:如何实现高性能黑苹果系统的架构设计与优化策略
5个维度深度解析:如何实现高性能黑苹果系统的架构设计与优化策略 【免费下载链接】Hackintosh 国光的黑苹果安装教程:手把手教你配置 OpenCore 项目地址: https://gitcode.com/gh_mirrors/hac/Hackintosh 在传统PC硬件与macOS系统兼容性的技术挑战…...
)
Vit工程化应用(timm 库)
pip install timm import timm import torch from PIL import Image import requests from io import BytesIO# 1. 加载模型 (ViT Base版本,16x16图块,在ImageNet-1k上预训练) # 设置 pretrainedTrue 自动下载权重 model timm.create_model(vit_base_pa…...

C++ 特殊成员函数详解:构造、析构、拷贝与移动
C 特殊成员函数详解:构造、析构、拷贝与移动 目录 概述基础成员函数 默认构造函数虚析构函数 拷贝操作 拷贝构造函数拷贝赋值运算符 移动操作(C11) 移动构造函数移动赋值运算符 常见问题解析 为什么拷贝参数是 const T&?为什…...

终极网盘直链下载助手完整指南:告别限速,快速获取八大平台真实下载地址
终极网盘直链下载助手完整指南:告别限速,快速获取八大平台真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里…...

PrismLauncher-Cracked:终极离线启动器解决方案完全指南
PrismLauncher-Cracked:终极离线启动器解决方案完全指南 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a functional Online Accou…...

外科医生AI认知变迁:从技术好奇到价值驱动的全球调查
1. 项目概述:一场关于外科医生与AI认知变迁的全球对话作为一名长期关注技术与医疗交叉领域的从业者,我始终对一个问题抱有浓厚兴趣:当一项颠覆性技术从实验室走向临床,真正使用它的医生们究竟在想什么?他们的期待、困惑…...

弯曲波触觉反馈技术:为触摸屏注入真实按键手感的工程实践
1. 项目概述:当触摸屏需要“手感”在2012年,如果你告诉一个家电设计师,未来的微波炉、冰箱或烤箱面板将是一块完全平整、没有任何物理凸起的玻璃或塑料板,他可能会皱起眉头。因为这意味着用户将失去最直接的交互反馈——那个“咔哒…...