干货 | 中小企业选型 Elasticsearch 避坑指南
1、线上常见问题
在我线下对接企业或线上交流的时候,经常会遇到各种业务场景不同的问题。
比如,常见问题归类如下:
常见问题1:ES 适合场景及架构选型问题。
公司的核心业务是做企业员工健康管理,数据来自电子化后的员工体检报告以及各种健康数据采集设备,均存储在关系型数据库中。
先计划搞健康大数据分析,比如某企业内按部门,年龄段等对现有数据对比分析等。请问ES适合这个场景使用吗?如果适合,大致的架构是怎样的?
常见问题2:节点偶然下线问题。
运输数据场景,批量写入导致 ES 宕机,集群偶然下线后导致无法上线,怎么解决?
常见问题3:数据不一致问题。
在原有的集群规模的数据非常大的基础上,要删除接近2/3的数据。这时候,两个集群出现了数据不一致的情况,如何排查?
常见问题4:集群重启时间超过20小时以上。
超过8小时的时候,没有引起重视,后面起不起来了,才发现是大问题。
实地环境排查及大量沟通发现,这些后期出现的问题或者“坑”,前期规避的话,成本会更低。
2、发现的潜在的“坑”
如下的坑,都是中小型企业现场环境排查、腾讯会议交流等发现的。
提前声明:对于一些大型企业、大厂不见得适用,毕竟场景不同,得具体问题具体分析。
(1)没有选择相对新的8.X版本,而是选择了 6.X版本。
原因:对接 API 方便。
(2)一台高配物理机(如:256GB内存,64核CPU)部署一个节点,资源利用率非常低。
(3)不熟悉 Linux,集群部署依然基于 Windows 服务器。
(4)数据同步工具自己开发“另起炉灶”,关键功能和性能尚不如 Logstash等成熟工具。
(5)主分片设定未考虑集群未来的可横向扩展性。
(6)批量写入不考虑集群性能上限,直至节点宕机脱离集群。
(7)不借助可视化工具:Kibana monitoring 监控集群,甚至 head 插件也没有用起来,出现问题不知道如何排查。
(8)命令行 DSL 仍然借助 Postman 等工具实现。
(9)Wildcard 模糊匹配召回结果符合预期,就大量不计后果的使用。
(10)查询细节参数不了解,能用起来就不关心其他。
3、Elasticsearch 常见认知“误区”
认知误区1:Elasticsearch 是关系型数据库。
实际上,Elasticsearch是非关系型数据库,不支持严格的关系数据模型,而是采用文档型存储。
探究 | Elasticsearch 与传统数据库界限
认知误区2:Elasticsearch 只适用于搜索。
Elasticsearch不仅适用于搜索,还支持聚合、分析等功能。
认知误区3:Elasticsearch 无需预处理数据。
Elasticsearch需要预处理数据,并对数据结构有严格的要求,否则可能导致检索效果不佳。
认知误区4:Elasticsearch 可以无限扩展。
(1)纵向扩展得看机器是否支持动态扩内存、CPU等资源,取决于硬件。
(2)横向扩展得看多节点集群规模能否适配性能指标,不见得是机器越多越好。
认知误区5:Elasticsearch 安全性很高。
Elasticsearch 本身 7.1 之前不提供严格的安全性,需要通过相关的插件或配置来实现安全性。7.1(含)之后 xpack 基础功能免费,8.X 之后安全成为必选项!
认知误区6:Elasticsearch 无需维护。
不止要维护,Elasticsearch 需要定期维护,包括数据备份(借助快照和恢复功能)、性能优化、安全更新等。
4、避坑方案探讨
4.1 Elasticsearch 版本及架构选型避坑
关于版本选型,Elastic 官方工程师如是说:“我完全理解稳定性是最重要的问题。在那种情况下,我们不应该选择最新版本的 Elasticsearch。作为参考,所有当前和过去的版本都可以在此页面上找到......作为一种模式,我建议比最新版本早发布 4 到 6 个月的版本”。——来自阮一鸣老师和ES官方的讨论帖。
关于版本选型,张超老师说“对稳定性要求比较高的生产,不要用最新的版本,谁不也知道有没有严重 bug,往前推一些,看看社区反馈没有大问题的版本,修正版本号用最高的”。
如下几点要谨慎考虑:
考虑功能要求:选择支持我们需要的功能的版本,比如:xpack 功能7.1之后才免费,ilm功能 6.7 版本才推出。
考虑兼容性:确保您选择的版本与正在使用的其他软件和工具兼容,比如:java、python客户端的选择。
考虑数据量: Elasticsearch是否能够满足数据存储和处理的要求?
考虑硬件资源:使用Elasticsearch需要充足的硬件资源,包括内存,硬盘,带宽等。
考虑集群架构:要根据业务需求选择合适的集群架构,并考虑到集群的可用性和扩展性。
历史版本下载地址:
https://www.elastic.co/cn/downloads/past-releases#ela...
Elasticsearch架构选型指南——不止是搜索引擎,还有......
干货 | Elasticsearch方案选型必须了解的10件事!
干货 | Elasticsearch Java 客户端演进历史和选型指南
https://blog.csdn.net/u013613428/article/details/103317806
4.2 Elasticsearch 常用工具避坑
“工欲善其事必先利其器”,没有工具,效率无从谈起。
推荐优先级:Kibana > Head / cerebro > Postman。
学会使用:Kibana Dev Tool,并用好 ctrl + i 快捷键。
学会使用:Kibana monitor 监控可视化工具。
更多推荐:
严选 | Elasticsearch史上最全最常用工具清单
MetricBeat + Elasticsearch + Kibana 实现监控指标可视化
4.3 Elasticsearch 集群避坑
结合集群能承载的总数据量、每日的增量,在有预留的前提下,给出集群规模的评估。避免“拍脑袋”,要理性计算给出实际参考依据。
布局好节点角色,早期版本叫节点类型。要知道节点角色更为便捷。
确定是否需要冷热集群架构,区分:热节点、温节点、冷节点。冷热集群架构是 ILM 的前提,没有它,ILM无从谈起。
更多推荐:
探究 | Elasticsearch集群规模和容量规划的底层逻辑
干货 | Elasticsearch 8.X 节点角色划分深入详解
4.4 Elasticsearch 索引避坑
确定是否需要 ILM 索引生命周期管理,而不是仅适用 rollover + 脚本自己维护方式或借助 curator 实现。用好 Kibana 可视化管理好 ILM。
考虑索引承载数据上限和大索引可能带来的风险,提前做好业务层面的布局,不同业务使用不同索引,不要混用。
能用模板 template 的就不要单独使用 index。
能支持 datastream 数据流(智能别名)就大胆使用。
模板和别名搭配、索引和别名搭配,干活不累。
定期备份集群索引数据,尤其业务索引,并准备恢复方案,以防数据丢失。
数据迁移需要认真计划,以防迁移不当可能导致数据丢失或损坏问题。
更多推荐:
Elasticsearch ILM 索引生命周期管理常见坑及避坑指南
干货 | Elasticsearch 索引生命周期管理 ILM 实战指南
Elasticsearch 7.X data stream 深入详解
Elasticsearch 快照生命周期管理 (SLM) 实战指南
干货 | Elasitcsearch7.X集群/索引备份与恢复实战
4.5 Elasticsearch 分片避坑
由于路由机制原因,不同于副本分片支持 update 动态更新,Elasticsearch 主分片数一旦设定就不能动态更新,除非 reindex。
分片设置要不仅满足当下集群的需求,也要考虑集群的未来可扩展性。
单分片大小参见官方的 30GB-50GB的优化建议(因场景而异,可能微调)。
更多推荐:
Elasticsearch究竟要设置多少分片数?
4.6 Elasticsearch 同步工具避坑
能借助 Ingest 预处理功能解决的,就不要使用 logstash。
能使用 logstash 解决基于时间递增和基于id递增同步的,就不要自己开发。
衡量好 Kafka_connector 和 logstash 的性能和适用场景。
阿里的 canal 工具在同步删除和更新操作时,要优先选择,因为 logstash 不支持同步更新和删除操作。
更多推荐:
Elasticsearch的ETL利器——Ingest节点
Elasticsearch 预处理没有奇技淫巧,请先用好这一招!
从一个线上问题看 Elasticsearch 数据清洗方式
实战 | canal 实现Mysql到Elasticsearch实时增量同步
干货 | Logstash Grok数据结构化ETL实战
4.7 Elasticsearch 检索选型避坑
如果查询语句不正确,可能导致查询性能下降,例如查询条件过于复杂、数据量过大等。
首先,建立起 ES 支持的检索类型的全局认知。
其次:
区分好:什么是召回率?什么是精准率?
区分好:什么是精准匹配,什么是全文检索?
区分好:哪些需要评分?哪些不需要评分?
区分好:什么叫 query?什么叫 filter?
最后:选型成功后,做充分的验证,再部署到线上环境。
涉及性能相关的,要做足检索并发性能测试。
PS:如果所有的已经存在的检索都无法达到业务指标,得考虑分词处下功夫,得考虑空间换时间。
推荐阅读:
Elasticsearch 8.X 如何实现更精准的检索?
实战 | Elasticsearch自定义评分的N种方法
干货 | Elasticsearch 检索类型选型指南
JMeter 如何实现 Elasticsearch 8.X 性能测试?
esrally 如何进行简单的自定义性能测试?
4.8 Elasticsearch 数据建模避坑
Elasticsearch要求数据结构符合其特定 Mapping 格式,如果数据结构不合适,可能导致数据存储不完整,后续检索可能会非常复杂。
建模问题的核心在于,前期不会发现,往往项目的中后期才会发现。但,一旦发现,返工的概率就会极大,带来了整体工期的延长和效率的降低。
所以,建议设计初期做足准备。
做什么准备呢?
(1)业务层面:不同索引可能跨索引检索,字段的一致性必要性尤为凸显。
(2)能“宽表”就不要或少用 Nested 嵌套字段、Join 多表关联数据类型。
(3)避免字段爆炸,设置 strict 最为严谨,设置dynamic:false相对谨慎,设置默认的 dynamic:true 要慎之又慎,评估好风险。
更多推荐:
干货 | Elasticsearch 数据建模指南
干货 | Elasticsearch多表关联设计指南
Elasticsearch 8.X 防止 Mapping “爆炸”的三种方案
4.9 Elasticsearch 运维避坑
不要等出了问题采取看监控,而是动态更新监控指标数据,考虑将集群各节点的健康状态,以定时任务的形式发送到邮箱等。
定期监控集群健康状态,并及时解决任何问题,以保证集群稳定运行。
用好运维监控工具。Kibana monitor、grafana 均可。
日志建议再归集到一个独立的小ES集群,通过 kibana 可视化展示,并对于 Warn 及以上级别日志及时预警。
推荐如下:
(1)使用Elasticsearch的内置监控工具:如Node Stats API和Cluster Stats API,可用于监控节点和集群的性能。
(2)使用 Kibana Monitoring:提供了全面的监控功能,包括集群监控、节点监控、索引监控等。
(3)定期评估集群健康:使用Elasticsearch的Cluster Health API评估集群的健康状况,以检测性能问题。
(4)记录并分析日志:记录并分析Elasticsearch的日志,以诊断性能问题。
(5)设置告警:设置告警,以提醒您有关性能问题的变化。建议和监控工具(如:Zabbix)结合。
更多推荐:
MetricBeat + Elasticsearch + Kibana 实现监控指标可视化
干货 | Elasticsearch Top10 监控指标
干货 | Elasticsearch 运维实战常用命令清单
干货 | Elasticsearch 集群健康值红色终极解决方案
4.10 Elasticsearch 安全避坑
安全无小事,早期版本(1.X、2.X、5.X、6.X、7.X)“luo奔”导致的安全事故依然屡见不鲜。8.X 的版本已经全线支持默认安全机制,用起来是王道。
如果非要早期版本(5.X、6.X、7.X),建议一定至少加上 xpack 安全机制,至少设置好密码。如果更早版本(1.X、2.X),建议不要开放外网权限,切记!
更多推荐:
你的Elasticsearch在裸奔吗?
重要!!Elasticsearch 安全加固指南
Elasticsearch 脚本安全使用指南
5、小结
“坑”是成长过程中的财富,提前关注“坑”能提高开发效率。
欢迎大家就使用 Elasticsearch 过程中遇到的坑留言交流。
5、参考
https://articles.zsxq.com/id_oo0h8a5b6b8a.html
https://wx.zsxq.com/dweb2/index/search/%E4%BC%81%E4%B8%9A/alltopics?groupId=225224548581
https://t.zsxq.com/0bUYswMJn
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单(2022年国庆更新版)
如何系统的学习 Elasticsearch ?
2023,做点事

更短时间更快习得更多干货!
和全球 1800+ Elastic 爱好者一起精进!

比同事抢先一步学习进阶干货!
相关文章:
干货 | 中小企业选型 Elasticsearch 避坑指南
1、线上常见问题在我线下对接企业或线上交流的时候,经常会遇到各种业务场景不同的问题。比如,常见问题归类如下:常见问题1:ES 适合场景及架构选型问题。公司的核心业务是做企业员工健康管理,数据来自电子化后的员工体检…...
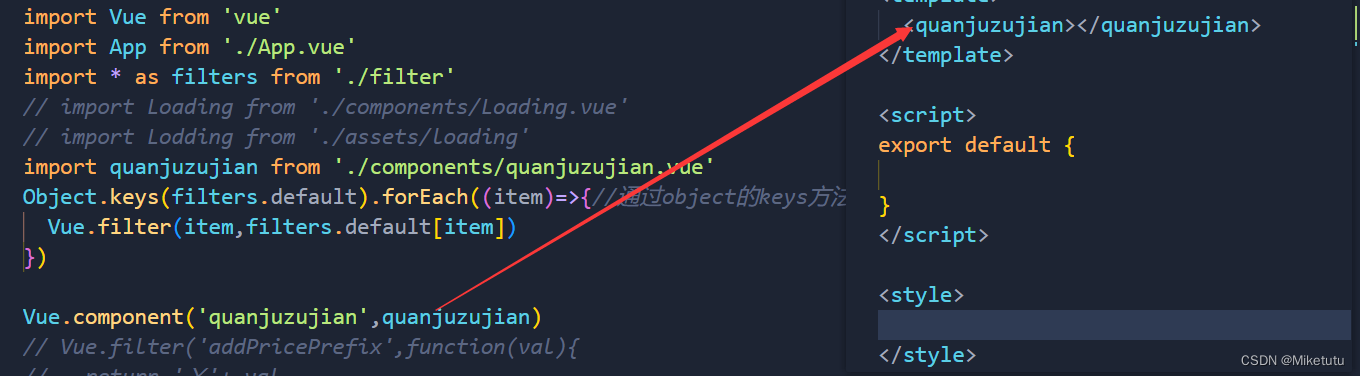
全局组件和局部组件
全局组件第一种定义方法:A、创建自己的组件:Loading.vueB、在main.js文件中引入组件并注册import Vue from vue import App from ./App.vue import * as filters from ./filterimport quanjuzujian from ./components/quanjuzujian.vueVue.component(qua…...
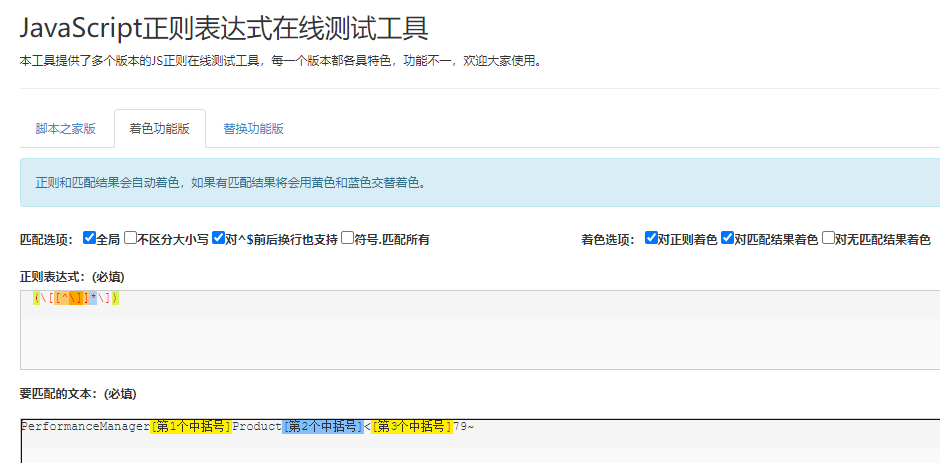
提取括号中的内容
正则能解决不嵌套的括号内容提取问题遇到一个问题,就是需要提取字符串中每一个中括号里的内容,在网上搜了一下,发现用正则表达式(\[[^\]]*\])可以提取中括号中的内容,以下面文本为匹配对象:PerformanceManager[第1个中…...

数据结构-算法的空间复杂度(1.2)
目录 1.空间复杂度 1.1 例子 1.2 空间的特殊性质 写在最后: 1.空间复杂度 空间复杂度也是一个数学表达式, 是对一个算法在运行过程中临时占用存储空间大小的量度。 他也是用大O渐进表示法。 1.1 例子 例1: 冒泡排序: v…...
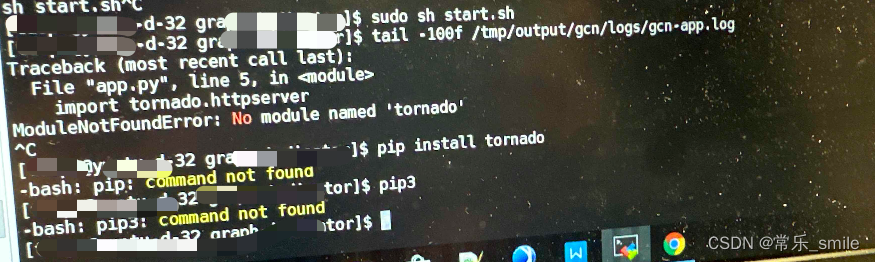
【总结】python3启动web服务引发的一系列问题
背景 在某行的实施项目,需要使用python3环境运行某些py脚本。 由于行内交付的机器已自带python3 ,没有采取自行安装python3,但是运行python脚本时报没有tornado module。 错误信息 ModuleNotFoundError:No module named ‘torn…...
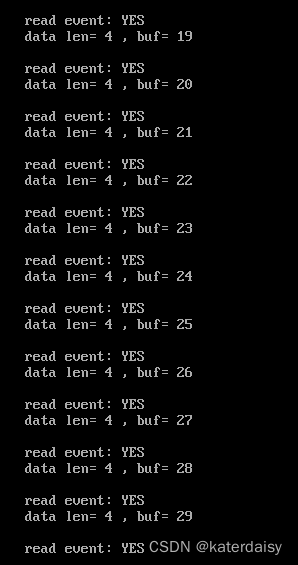
Linux:基于libevent读写管道代码,改进一下上一篇变成可以接收键盘输入
对上一篇进行改进,变成可以接收键盘输入,然后写入管道: 读端代码: #include <stdlib.h> #include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <s…...
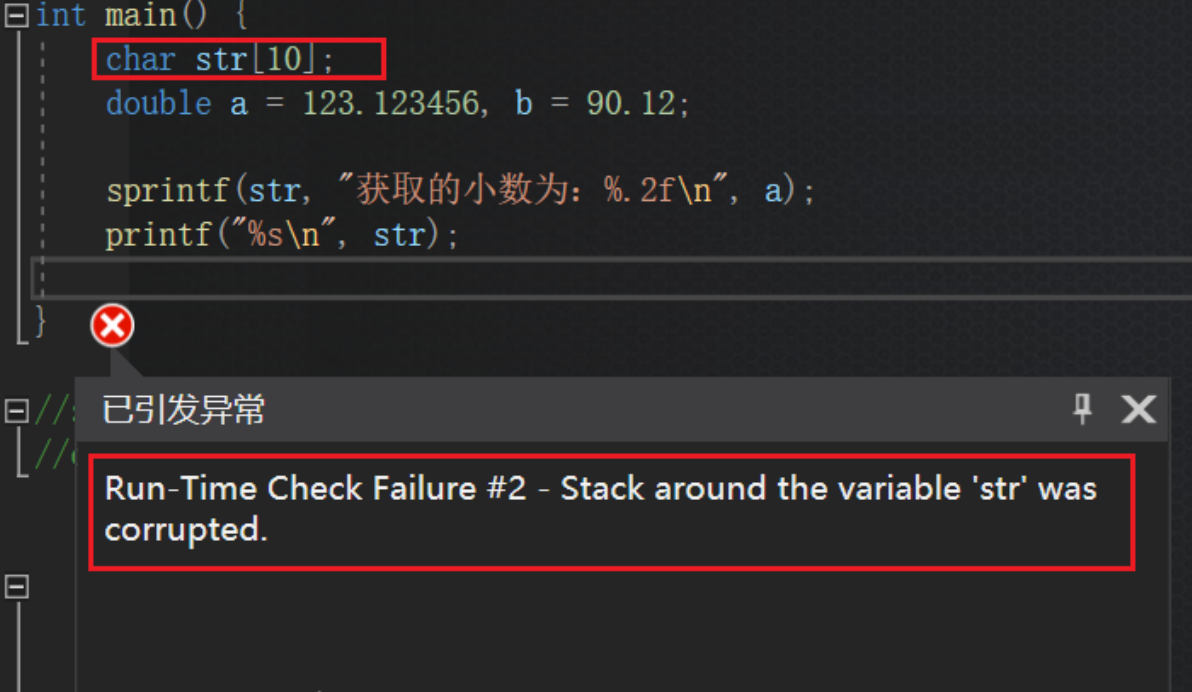
C语言格式化输出总结:%d,%c,%s,%f, %lf,%m.nd,%m.nf,%m.ns 以及sprintf函数
凡事发生必将有益于我,高手,从来都不仅仅是具备某种思维的人,而是那些具备良好学习习惯的人,成为高手,无他,手熟尔!加油在最近的学习之中,对于格式化输出这个知识点,这里…...
Nginx之反向代理、负载均衡、动静分离。
Nginx之反向代理、负载均衡、动静分离。 1、Nginx是啥? 轻量级Web服务器、反向代理服务器、电子邮件(IMAP/POP3)代理服务器 在 BSD-like 协议下发行、占内存少、并发高(同时处理请求能力)。 2、安装 官网…...
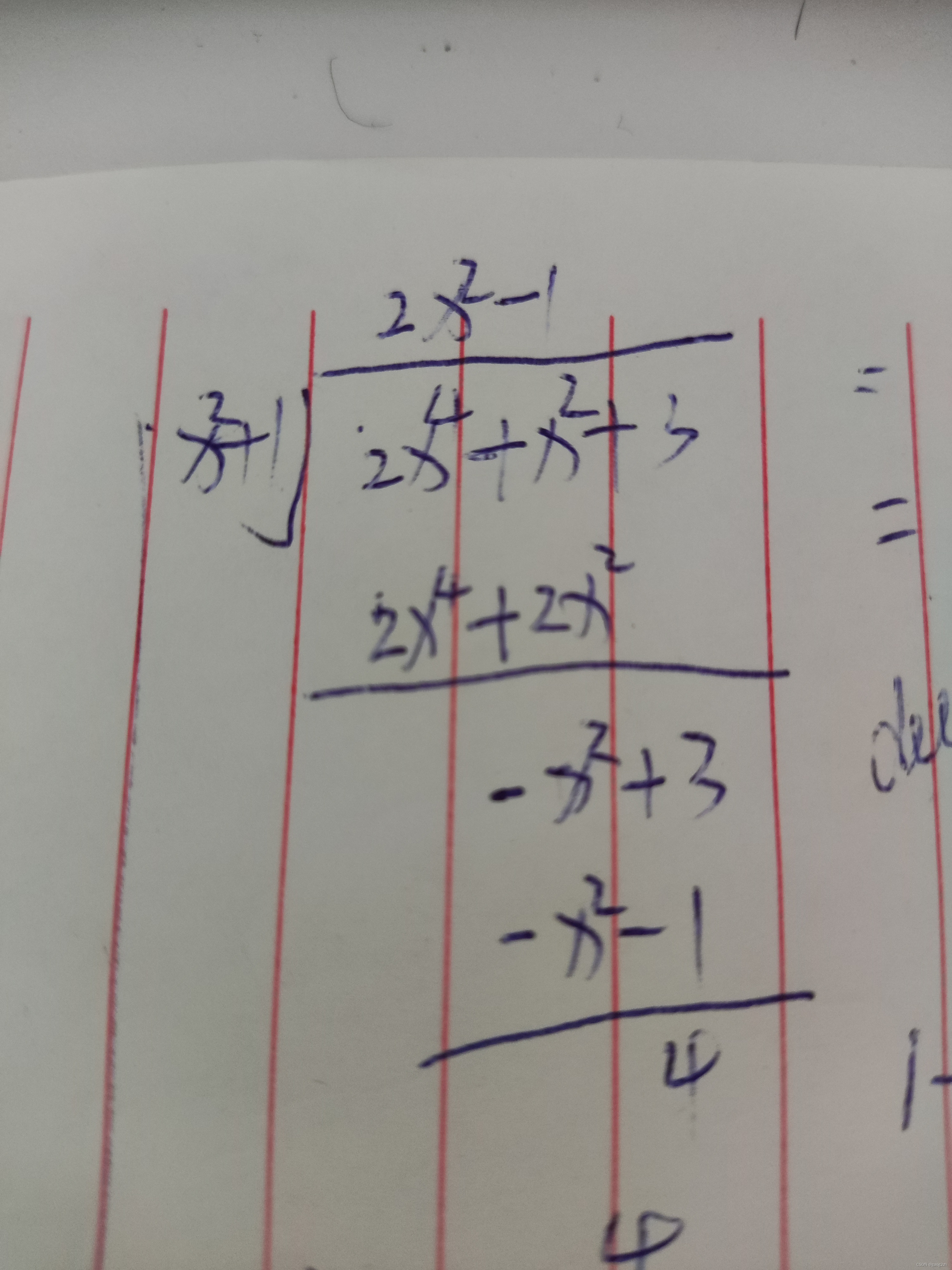
0401不定积分的概念和性质-不定积分
文章目录1 原函数与不定积分的概念1.1 原函数1.2 原函数存在定理1.3 不定积分2 不定积分的性质3 基本积分表4 例题后记1 原函数与不定积分的概念 1.1 原函数 定义1 如果在区间I上,可导函数F(x)的导航为f(x),即对任一x∈Ix\in Ix∈I,都有 F′…...

数组中的各种迭代API方法手写
js的数组上有很多实用的方法,不论是在遍历数组上,还是在操作数组内元素上,它有许多不同的遍历数组的方法,同时它还有着可以直接操作数组中间元素的方法。 接下来,我来带大家手写数组里的 遍历方法 。 Array.forEach(…...
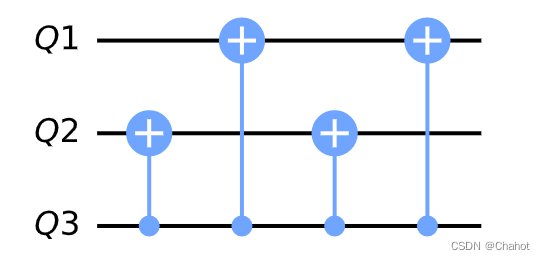
详解量子计算:相位反冲与相位反转
前言 本文需要对量子计算有一定的了解。需要的请翻阅我的量子专栏,这里不再涉及基础知识的科普。 量子相位反冲是什么? 相位反转(phase kickback)是量子计算中的一种现象,通常在量子算法中使用,例如量子…...
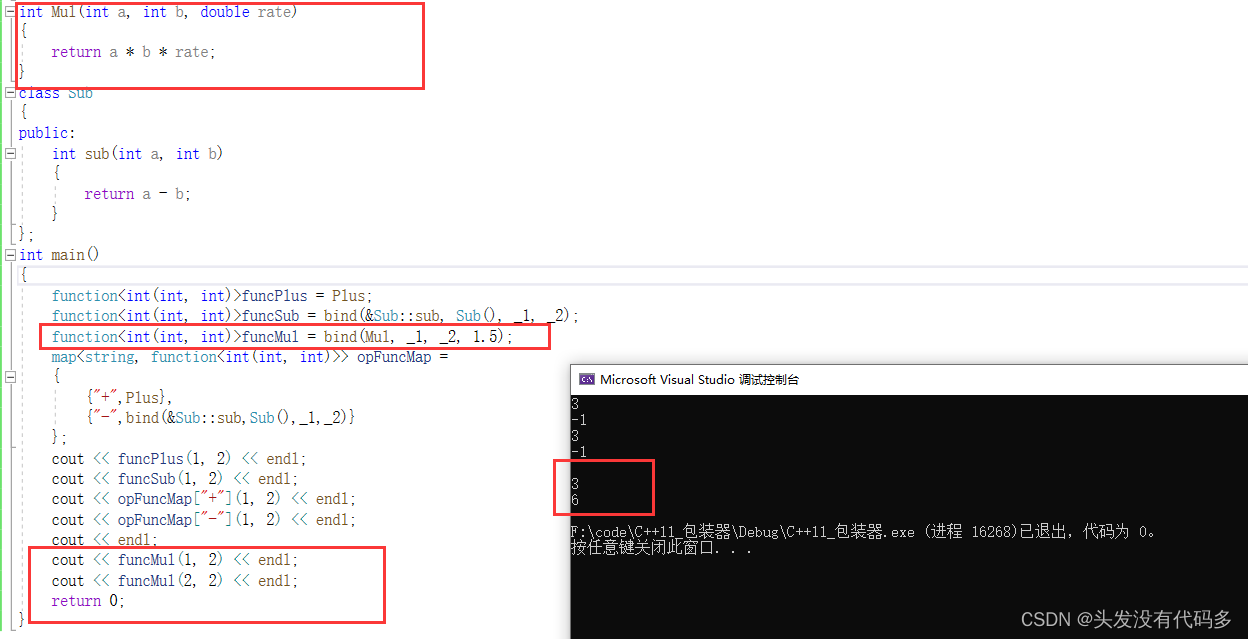
C++——C++11第三篇
目录 包装器 function包装器 bind 包装器 function包装器 function包装器 也叫作适配器。C中的function本质是一个类模板,也是一个包装器。 上面的程序验证,我们会发现useF函数模板实例化了三份。 包装器可以很好的解决上面的问题 ,让它只实…...

180 2 22222
选择题(共180题,合计180.0分) 1. 在项目开工会议期间,项目发起人告诉产品负责人和团队项目章程即将完成。然而,由于存在在紧迫的期限内满足政府监管要求的压力,发起人希望立即开始工作。产品负责人下一步应该做什么? A 告诉发起人…...

成人高考初中毕业能报名吗 需要什么条件
初中学历的人员不能直接报名成人高考,考生需要有普通高中,职业高中,中专毕业证等高中同等学力就可以进行报名,在报名期间登陆所在省的教育考试院的成人高考报名入口进行报考。成人高考报名条件是什么1、遵守宪法和法律。2、国家承…...

ChatGPT初体验
ChatGPT初体验 前言 嘿嘿,最近啊AI ChatGPT刷新各大网站,对于我们国人而将很不友好,真的太不友好了。我呢在去年open AI发布的时候就有所关注,那个时候还没有像现在这样火热。谁知道短短几个月便传遍大街小巷。 一、什么是chatG…...

ChatGPT概念狂飙!究竟魅力何在?
原文:http://www.btcwbo.com/6988.html 近期,ChatGPT引领的人工智能概念在资本市场一路狂飙,AIGC题材持续发酵。截至2月7日,Wind ChatGPT指数今年以来累计上涨超50%,汉王科技、海天瑞声、云从科技等概念股股价已经翻倍…...
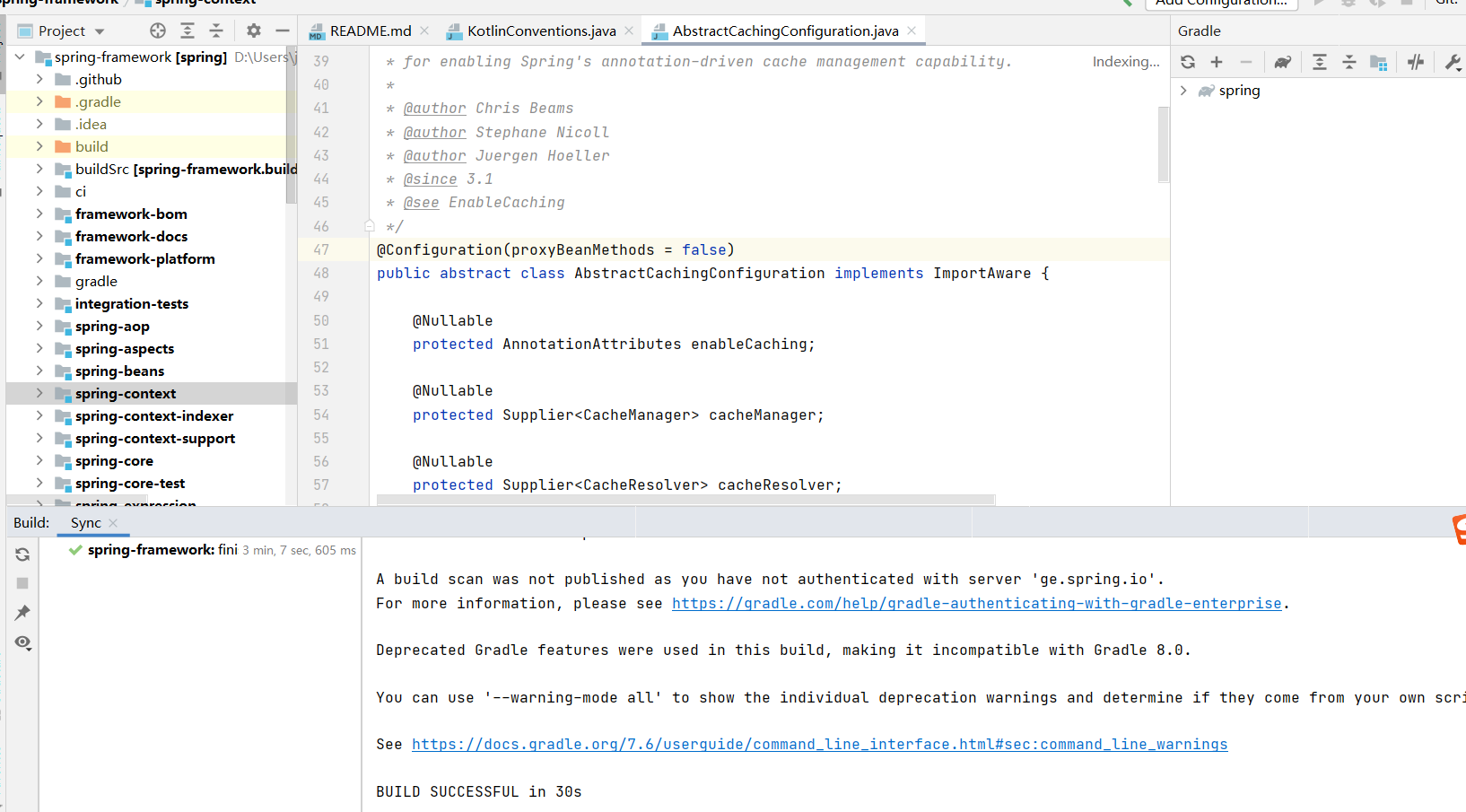
如何下载阅读Spring源码-全过程详解
这篇文章记录了下载spring源码和在IDEA中打开运行的全过程,并且记录了过程中遇到的问题和解决方案,适合需要学习spring源码的同学阅读。 1.spring源码下载地址 通过Git下载spring-framework项目源码: git clone https://github.com/spring…...
学了两个月的Java,最后自己什么也不会,该怎么办?
学着学着你会发现每天的知识都在更新,也都在遗忘,可能就放弃了。但是只要自己肯练,肯敲代码,学过的知识是很容易就被捡起来的。等你学透了用不了一年也可以学好 Java的运行原理:Java是一门编译解释型语言,…...
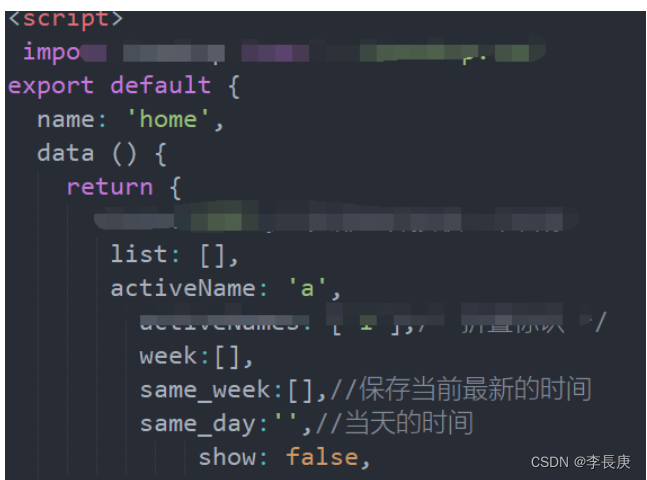
前端vue实现获取七天时间和星期几功能
前端vue实现获取七天时间和星期几功能 功能展示代码 <div v-for"(item,index) in same_week" :class"[same_dayitem.date? activ :,dis]" click"select(item)" :keyindex><span>{{item.name}}</span><span>{{item.…...

zookeeper单机部署
一.下载zookeeper压缩包 二.上传解压安装包到/data/zookeeper目录,并解压 tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz 三.修改配置文件 cd apache-zookeeper-3.5.10-bin/conf mv zoo_sample.cfg zoo.cfg vi zoo.cfg 修改为如下: dataDir/data/zooke…...

3分钟快速上手:bilibili-parse视频解析API终极指南
3分钟快速上手:bilibili-parse视频解析API终极指南 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse bilibili-parse是一款高效专业的B站视频解析工具,为开发者和内容创作者提供…...

MT-R1-Zero:基于强化学习的机器翻译范式革新与实战指南
1. 项目概述:当强化学习遇上机器翻译 在机器翻译这个老牌的自然语言处理任务里,我们似乎已经习惯了“数据驱动”的剧本:收集海量的双语平行句对,用它们来监督训练模型,让模型学会从源语言到目标语言的映射。这套方法&a…...

如何5分钟搭建暗黑破坏神2存档编辑器:终极可视化解决方案指南
如何5分钟搭建暗黑破坏神2存档编辑器:终极可视化解决方案指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为暗黑破坏神2复杂的存档编辑而烦恼吗?想要自由调整角色属性却无从下手?d2s-…...

HoRain云--Ollama 安装
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...
)
不止是移动:用UE5.1蓝图优化你的MetaHuman性能(头发渲染、LOD设置避坑指南)
不止是移动:用UE5.1蓝图优化你的MetaHuman性能(头发渲染、LOD设置避坑指南)在虚幻引擎5.1中,MetaHuman已经成为了数字人创作的重要工具。然而,许多开发者在实现了基础移动控制后,往往会忽视对MetaHuman资产…...

Beyond Compare 5密钥生成技术深度解密:从RSA加密到完整激活解决方案
Beyond Compare 5密钥生成技术深度解密:从RSA加密到完整激活解决方案 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 在软件开发与系统维护领域,Beyond Compare 5作为文件…...

Qt/C++源码/监控GB28181组件/实时视频/云台控制/预置位/录像回放和下载/事件订阅/语音对讲/推流分发
一、功能特点 支持设备注册、注销、心跳、校时、注册认证、注销认证等。设备上线后可以手动获取设备状态、设备信息、配置信息、预置位信息等。设备上线后自动获取设备通道信息,包括中文通道名称。识别到通道上线离线变化,会重新获取该设备的所有通道信…...
)
Unity打包Linux服务器应用踩坑记:从发布到后台稳定运行(含Systemd服务配置)
Unity服务器应用Linux部署实战:从Systemd配置到稳定运维引言:当Unity遇见Linux服务器三年前接手第一个Unity服务器项目时,我完全没料到会在部署环节连踩72小时坑。那个本该简单的部署过程,最终演变成与Linux权限、内存泄漏和日志管…...

华硕笔记本终极优化指南:如何用G-Helper轻量级工具全面提升使用体验
华硕笔记本终极优化指南:如何用G-Helper轻量级工具全面提升使用体验 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook…...

AArch64虚拟内存系统架构与页表转换机制详解
1. AArch64虚拟内存系统架构概述在AArch64架构中,虚拟内存系统是处理器核心功能之一,它通过多级页表机制实现虚拟地址到物理地址的转换。这套系统不仅支持常规的内存管理需求,还针对虚拟化、安全隔离等场景提供了丰富的硬件支持特性。虚拟内存…...