NIFI实现数据库数据增量同步
说明
nifi版本:1.23.2(docker镜像)
需求背景
将数据库中的数据同步到另一个数据库中,要求对于新增的数据和历史有修改的数据进行增量同步
模拟数据
建表语句
源数据库和目标数据库结构要保持一致,这样可以避免后面单独转换
-- 创建测试表
CREATE TABLE `sys_user` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '用户ID',`name` varchar(50) NOT NULL DEFAULT '' COMMENT '姓名',`age` int NOT NULL DEFAULT 0 COMMENT '年龄',`gender` tinyint NOT NULL COMMENT '性别,1:男,0:女',`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',`is_deleted` tinyint NOT NULL DEFAULT '0' COMMENT '是否已删除',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='用户表';测试数据
-- 模拟数据
INSERT INTO sys_user (name, age, gender) VALUES ('测试数据1', 20, 1);
INSERT INTO sys_user (name, age, gender) VALUES ('测试数据2', 21, 1);
INSERT INTO sys_user (name, age, gender) VALUES ('测试数据3', 21, 0);
INSERT INTO sys_user (name, age, gender) VALUES ('测试数据4', 18, 0);
INSERT INTO sys_user (name, age, gender) VALUES ('测试数据5', 22, 1);完整测试数据
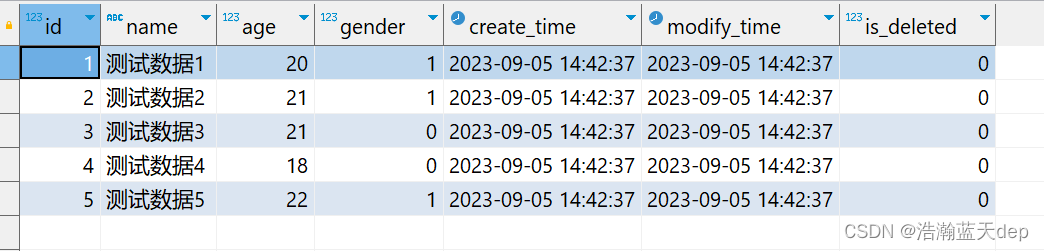
配置数据库连接池
在画布空白位置鼠标右键,选择Configure

新增配置
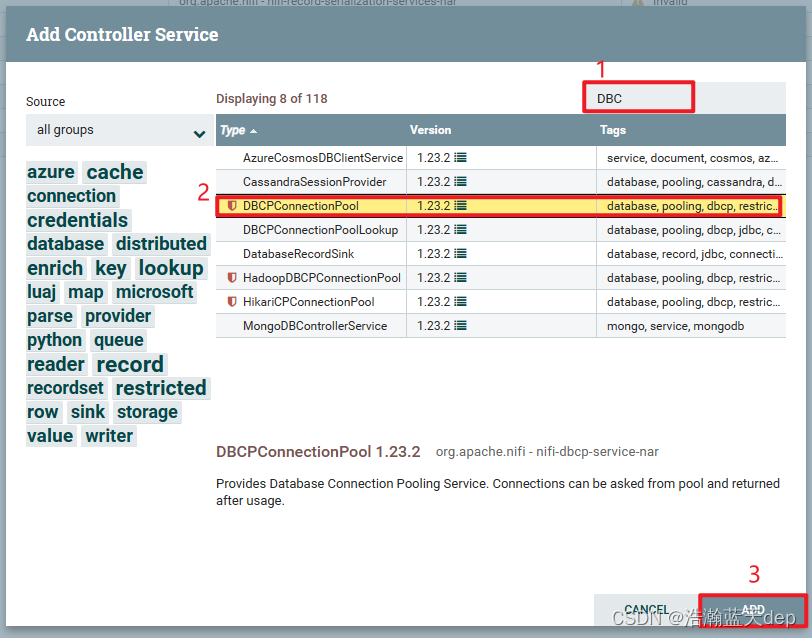
在弹出的界面点击+号,添加新的数据库连接池配置,如果已经有了配置该步骤可以跳过

在弹出的界面筛选对应类型的连接池,我这里选择DBCPConnectionPool,然后点击ADD
点击刚才新添加的那一条数据右侧的小齿轮,进行连接池相关的配置

配置连接池相关属性
主要配置以下几个内容,其他的根据情况决定是否需要修改,密码输入后是不会显示的

校验属性
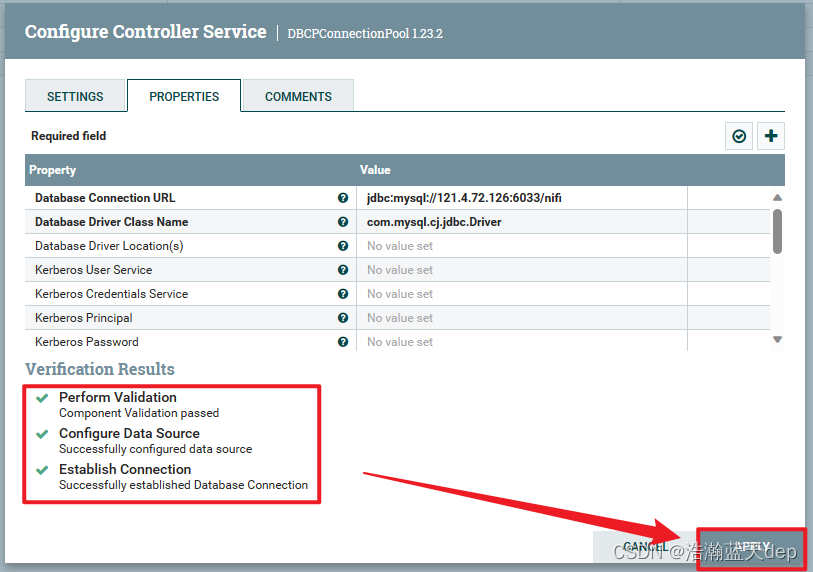
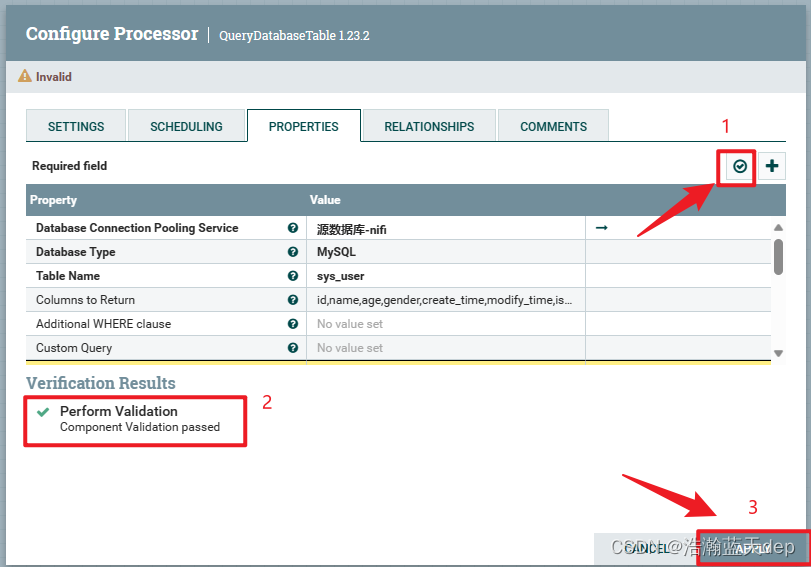
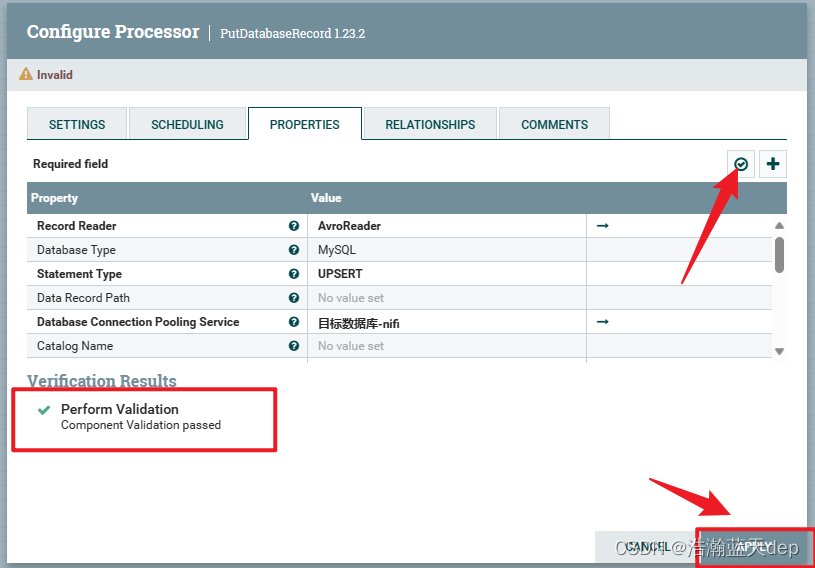
校验配置是否正确,点击右上角的对钩,然后在弹出的界面点击VERIFY进行验证
验证通过会全部显示绿色,如果某一条不通过会有提示,最后点击APPLY
(可选操作)给配置起个名字
为了方便后续使用,给连接池起个名字,要不然以后配置多了会分不清
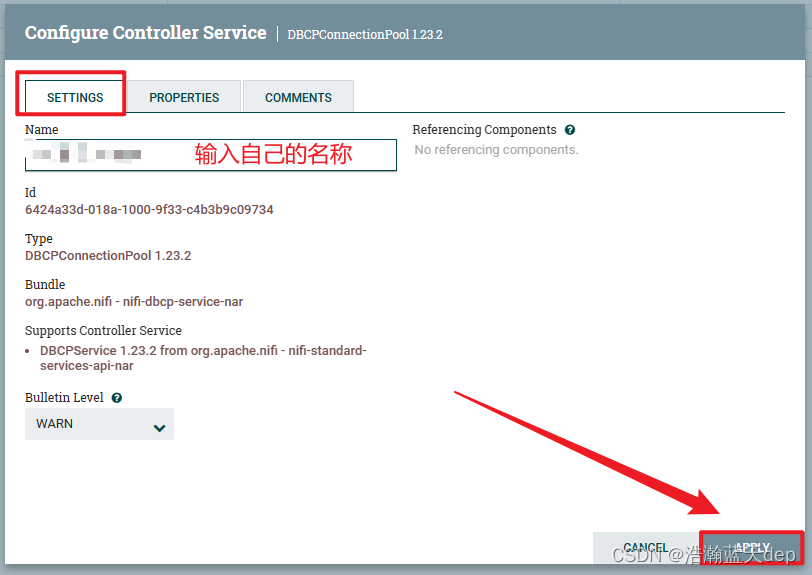
激活连接池的配置
点击右侧的闪电标志激活配置,在新的页面中点击ENABLE激活,最后点击CLOSE关闭

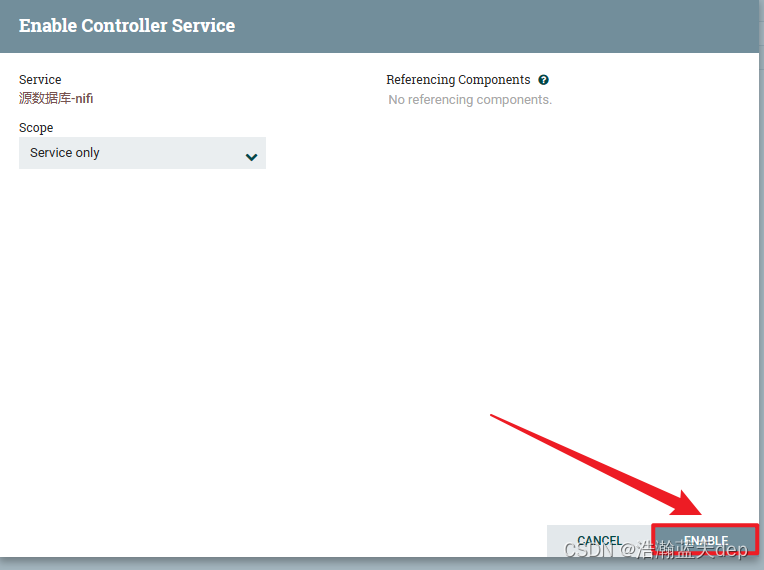
已激活的配置

同理增加目标数据库的连接池配置,步骤和上面是一样的这里不再重复了,最终配置好后会有两个连接池的配置。如下:
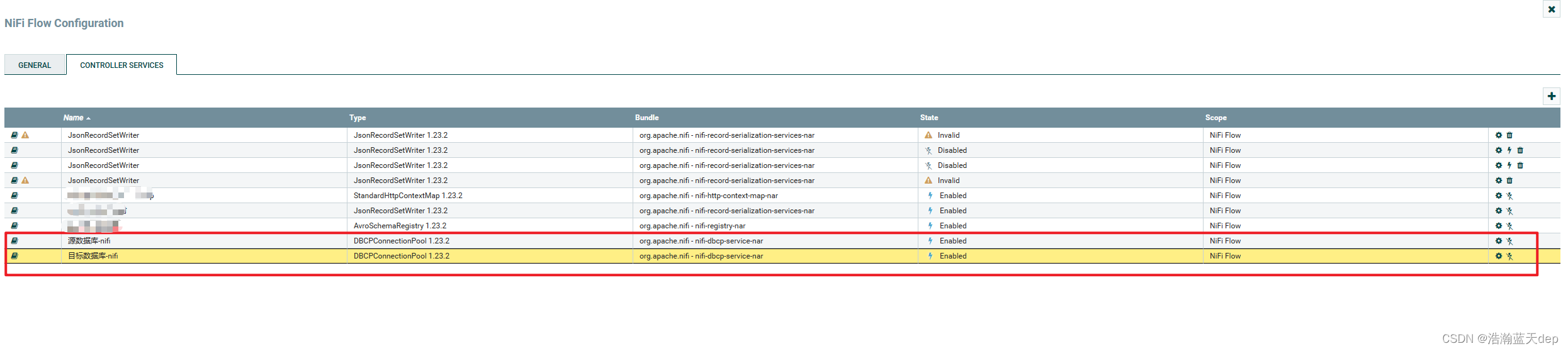
获取数据库表数据
添加处理器:QueryDatabaseTable
点击工具栏的Processor,拖拽到画布中,筛选QueryDatabaseTable处理器,然后点击ADD添加到画布中
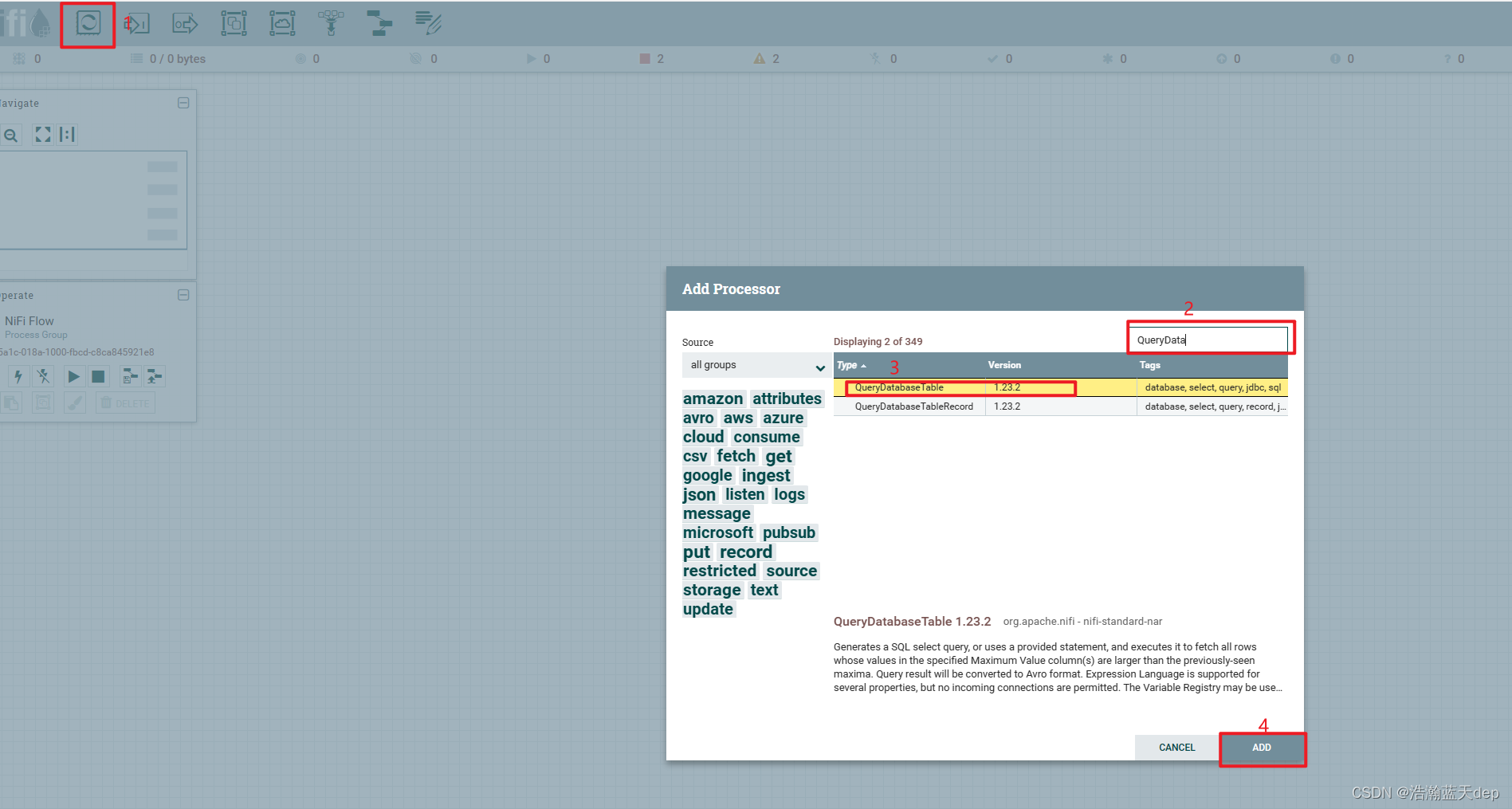
配置处理器:QueryDatabaseTable
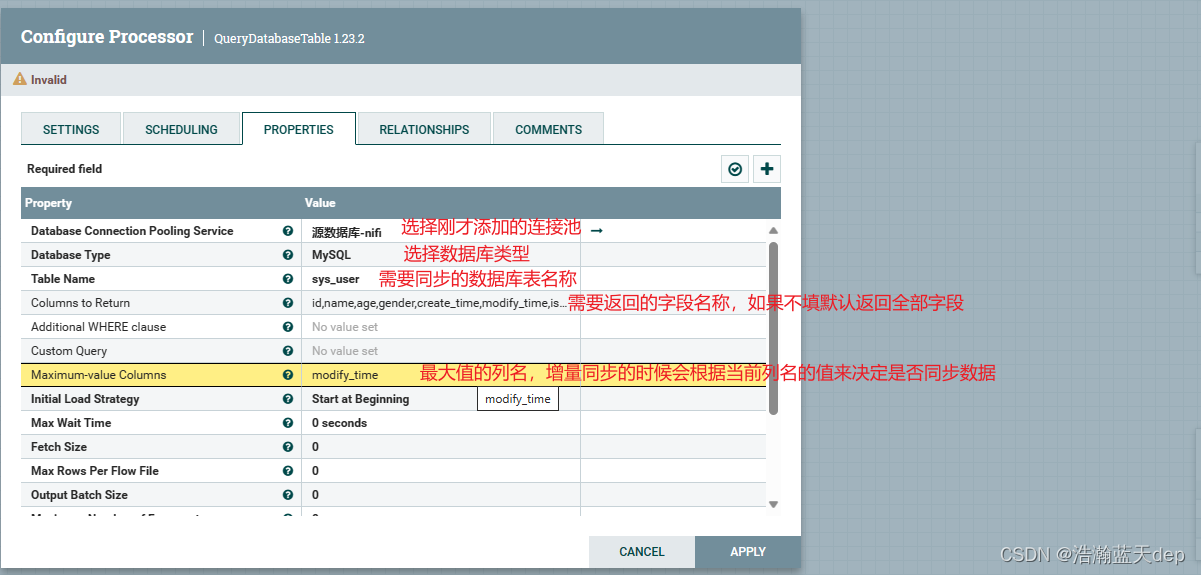
双击处理器,切换到PROPERTIES选项卡,配置以下内容
Maximum-value Columns(最大值列):官方文档是这么解释的:以逗号分隔的列名列表。处理器将跟踪自处理器开始运行以来返回的每一列的最大值。使用多个列意味着列列表的顺序,并且每列的值预计比前几列的值增加得更慢。因此,使用多个列意味着列的分层结构,通常用于对表进行分区。此处理器可用于仅检索自上次检索以来添加/更新的那些行。请注意,某些 JDBC 类型(如 bit/boolean)不利于保持最大值,因此这些类型的列不应列在此属性中,并且将导致处理过程中的错误。如果未提供列,则将考虑表中的所有行,这可能会对性能产生影响。注意:为给定表使用一致的最大值列名非常重要,这样增量提取才能正常工作。
支持表达式语言:true
校验属性
给处理器起个名字,表示当前整个工作流的作用
拆分数据
添加处理器:SplitAvro
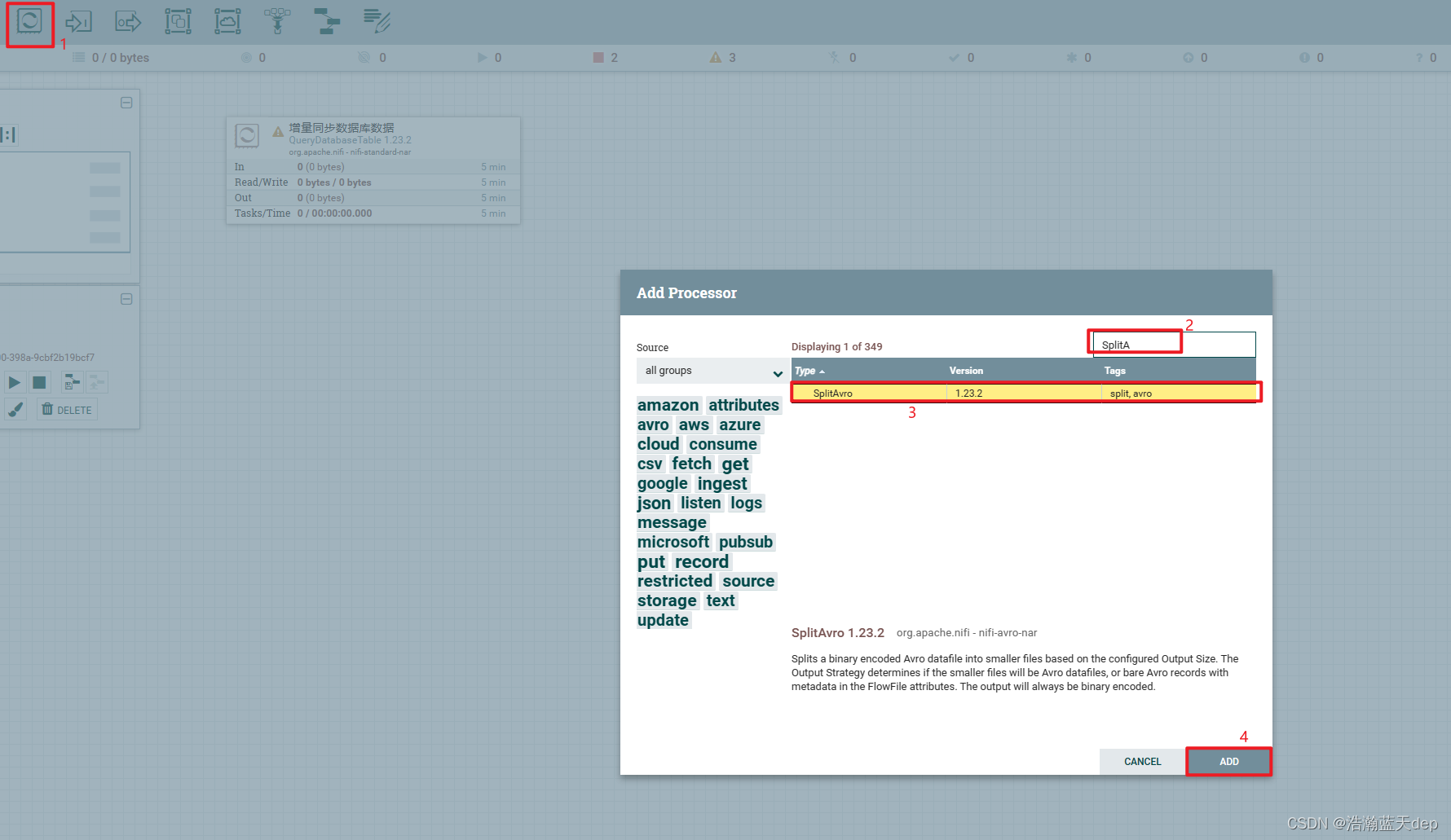
配置处理器:SplitAvro
双击处理器,切换到PROPERTIES选项卡,所有内容默认即可
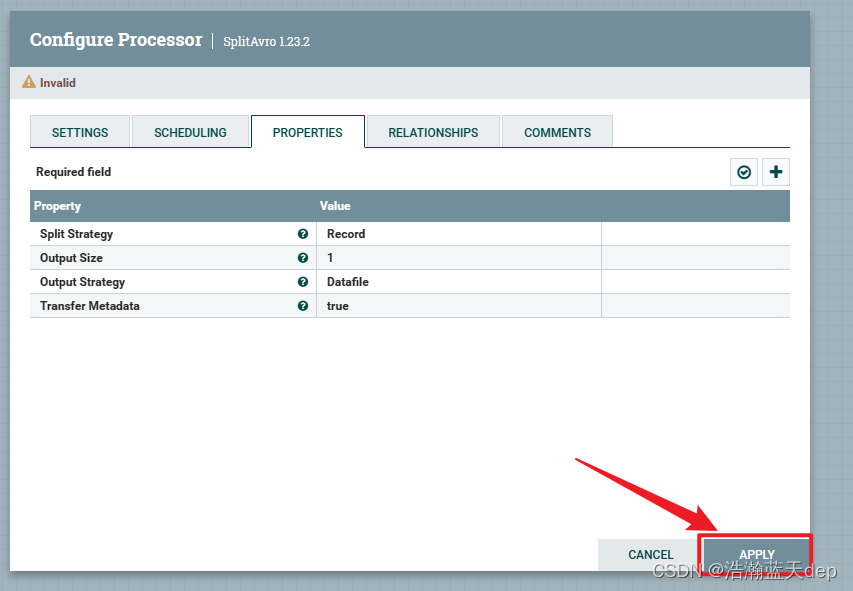
数据入库
添加处理器:PutDatabaseRecord

配置处理器:PutDatabaseRecord
双击处理器,切换到PROPERTIES选项卡
新增Record Reader

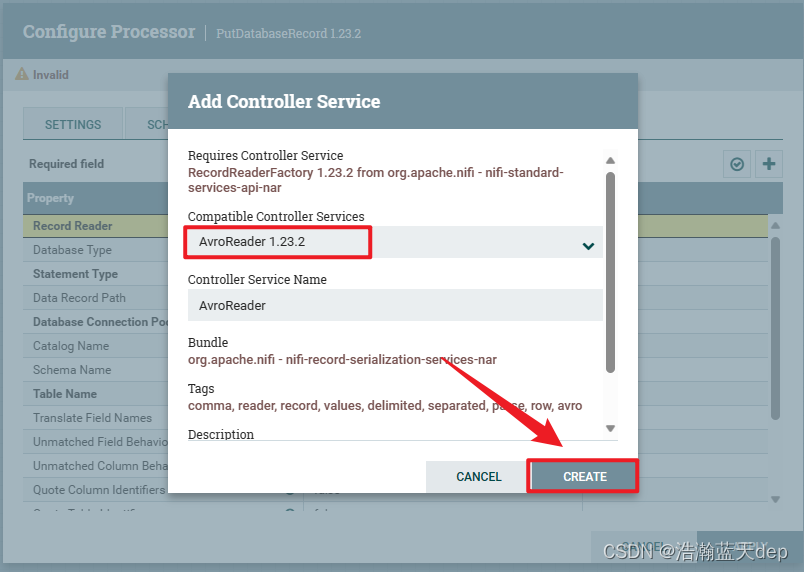
配置AvroReader
点击右侧的箭头,在弹出的界面选择刚才配置的Reader,然后点击右侧的小齿轮
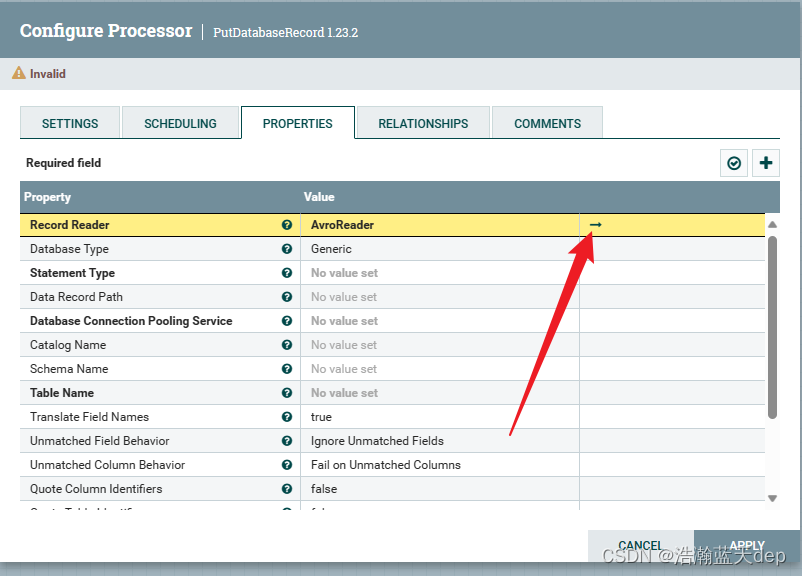
 在弹出的界面根据自己的需要自行配置,这里按照默认的配置即可
在弹出的界面根据自己的需要自行配置,这里按照默认的配置即可
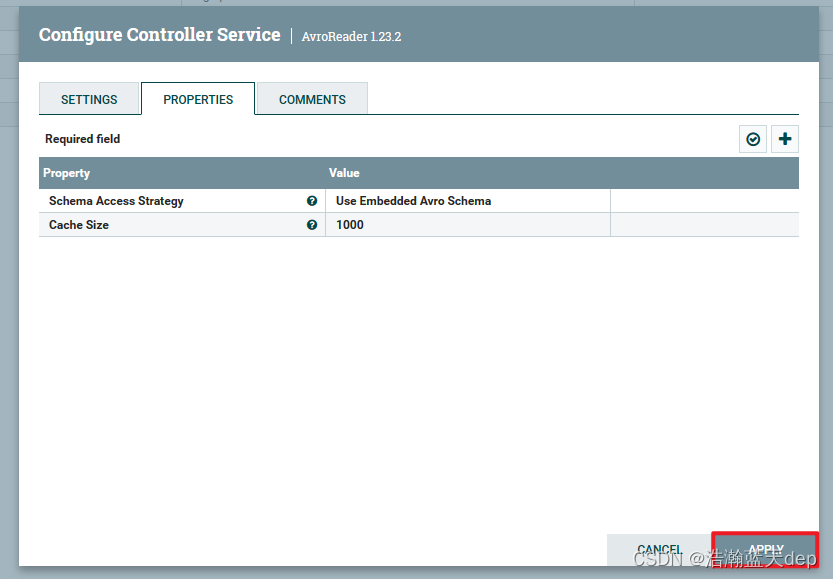
激活Reader
点击右侧的闪电标志进行激活

激活后的状态变为Enabled

其他配置
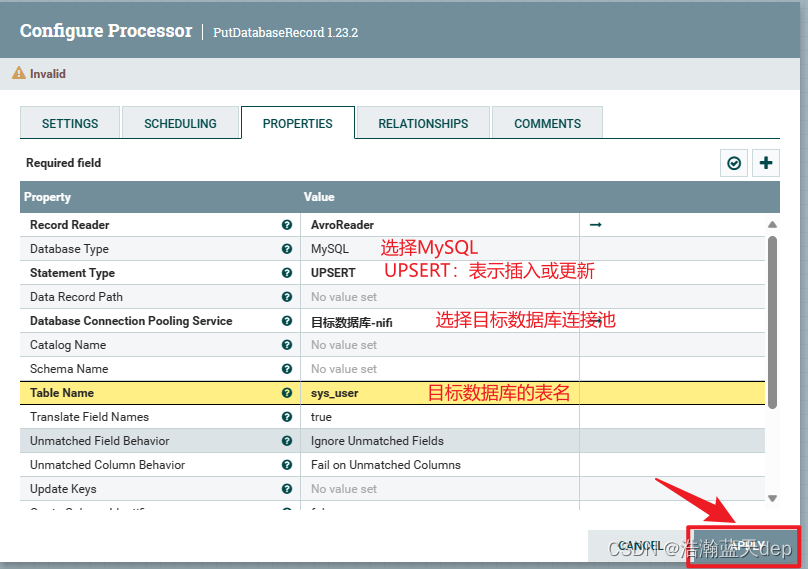
校验属性
连接所有处理器
连接处理器
连接QueryDatabaseTable和SplitAvro两个处理器,勾选For Relationships下的success

连接SplitAvro和PutDatabaseRecord两个处理器,勾选For Relationships下的split
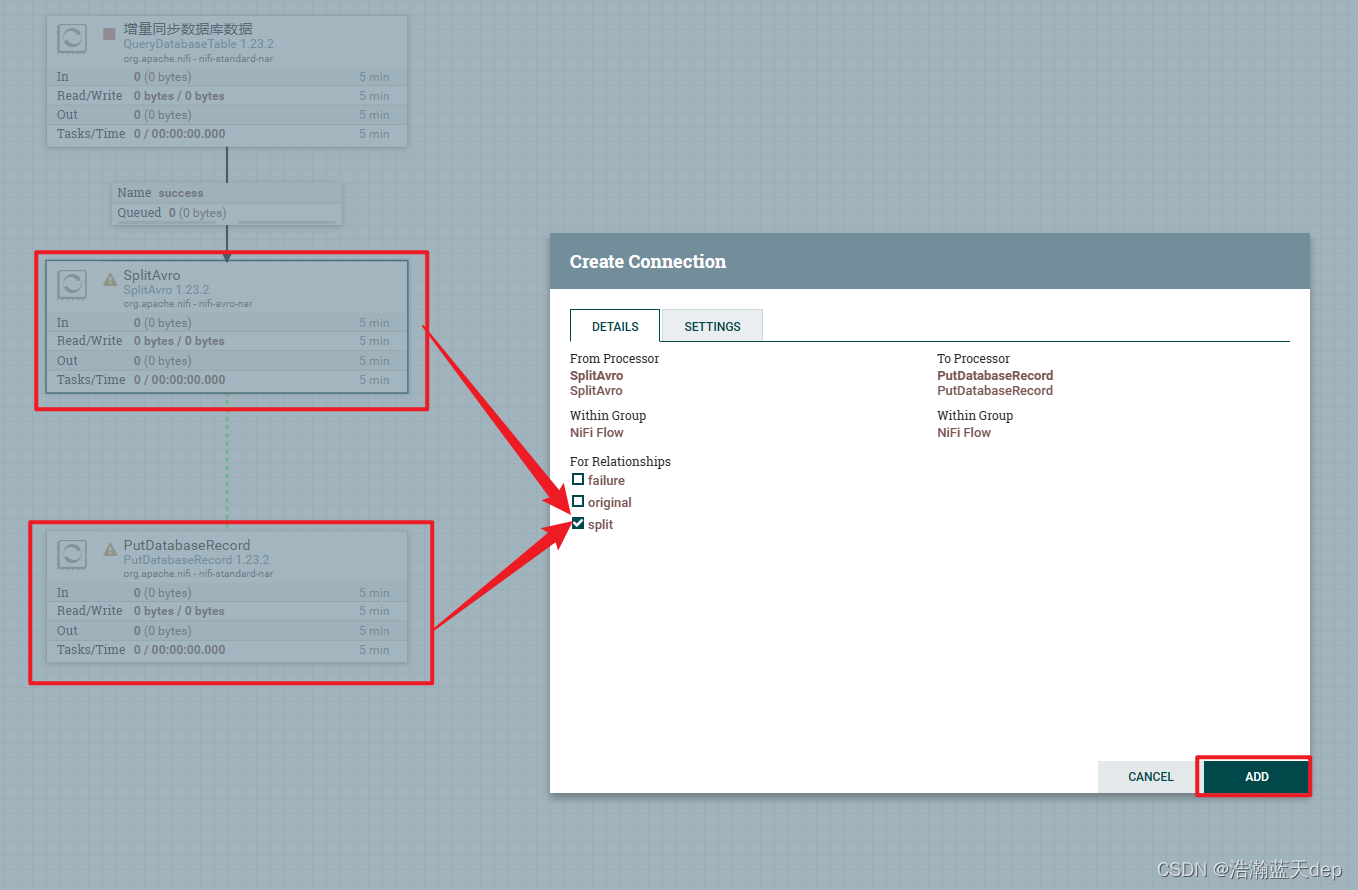
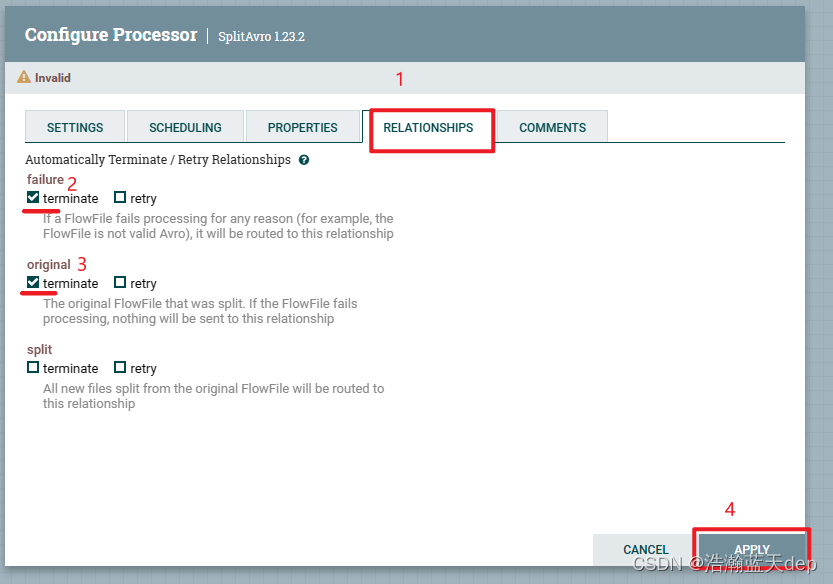
处理SplitAvro处理器的告警
双击SplitAvro处理器,切换到RELATIONSHIPS,勾选下面的两个选项,然后点击APPLY
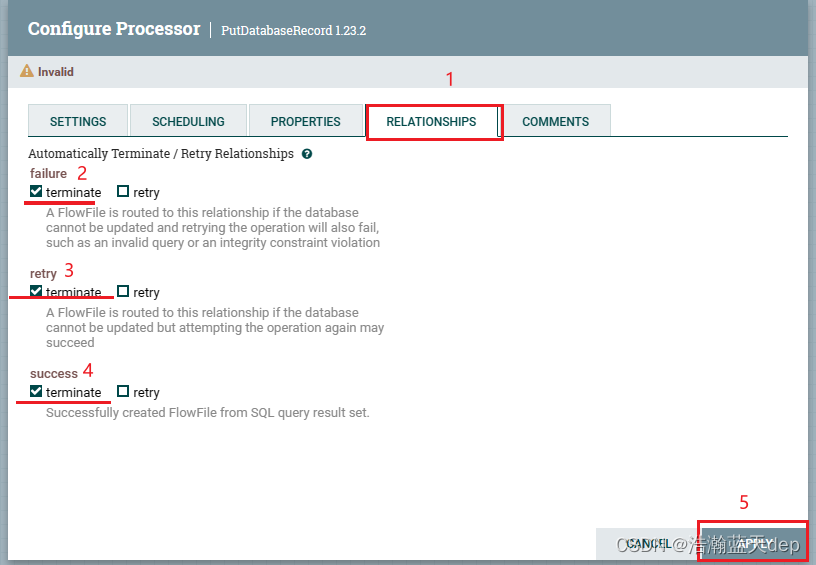
处理PutDatabaseRecord处理器的告警
双击PutDatabaseRecord处理器,切换到RELATIONSHIPS,勾选下面的选项,然后点击APPLY
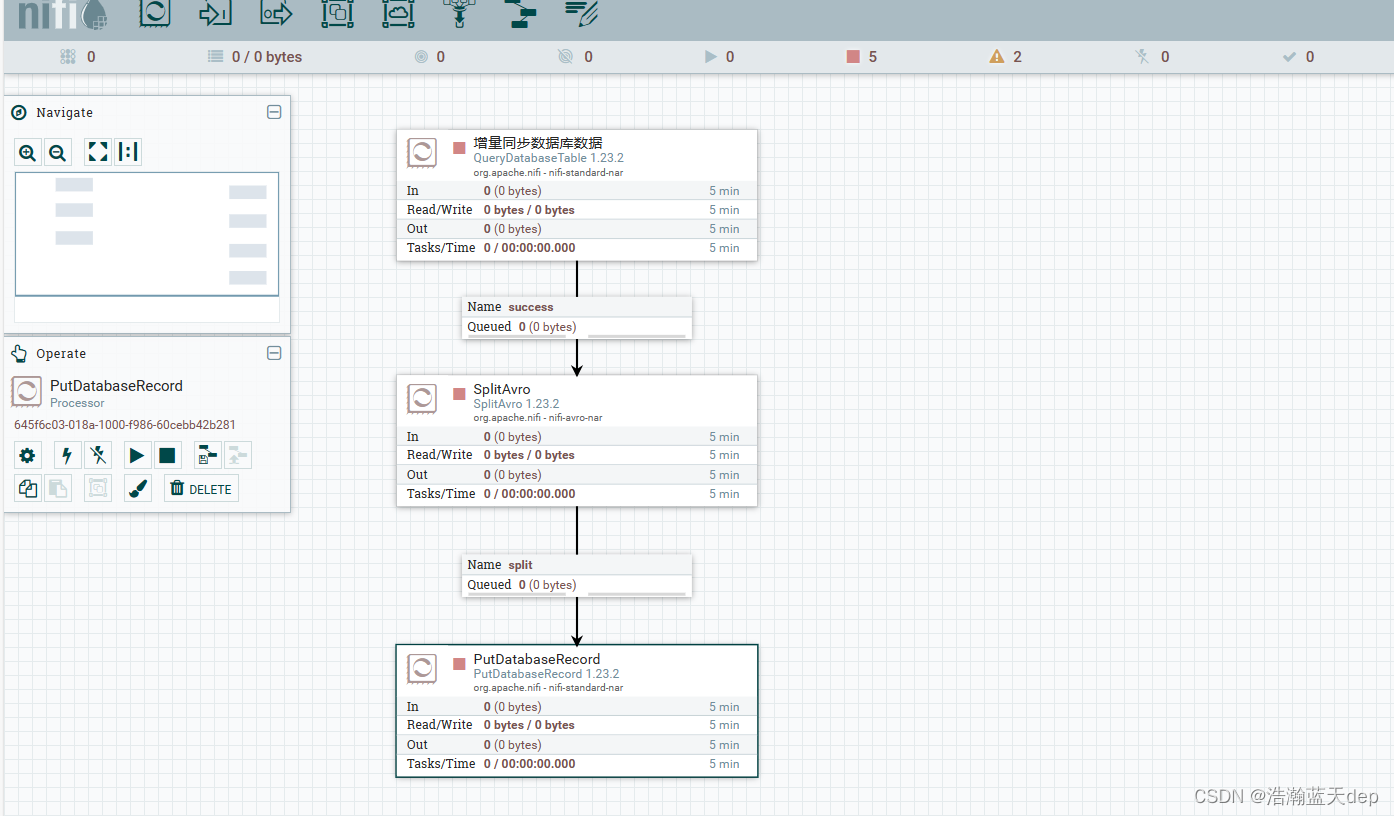
完整配置
启动所有处理器
QueryDatabaseTable处理器默认是一分钟执行一次的,可以在SCHEDULING选项卡下面进行配置,这里按照默认的时间来执行
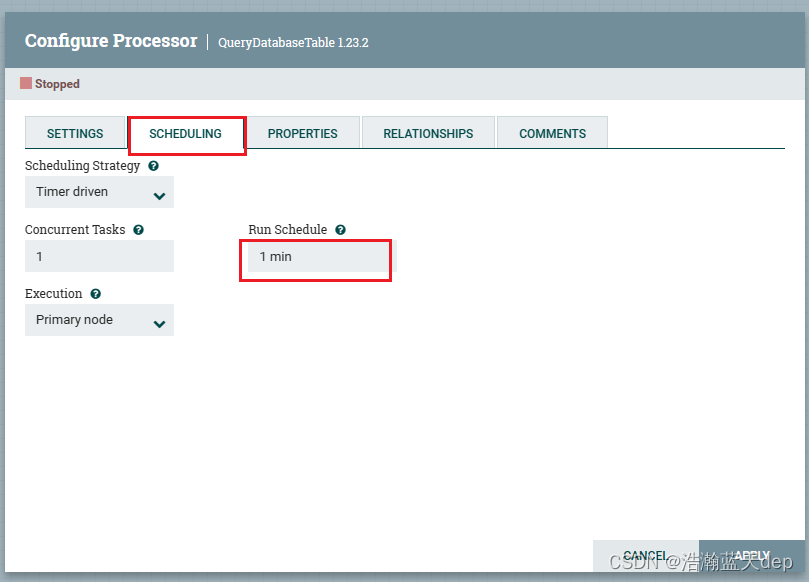
在画布空白位置鼠标右键选择Start启动所有的处理器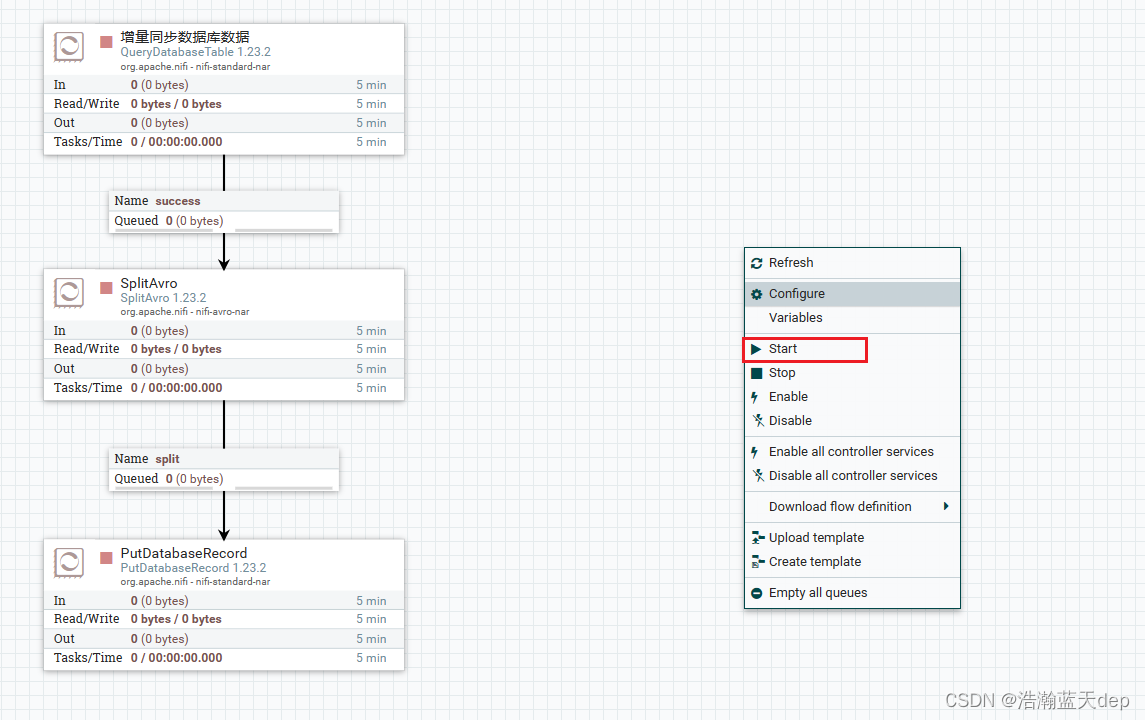
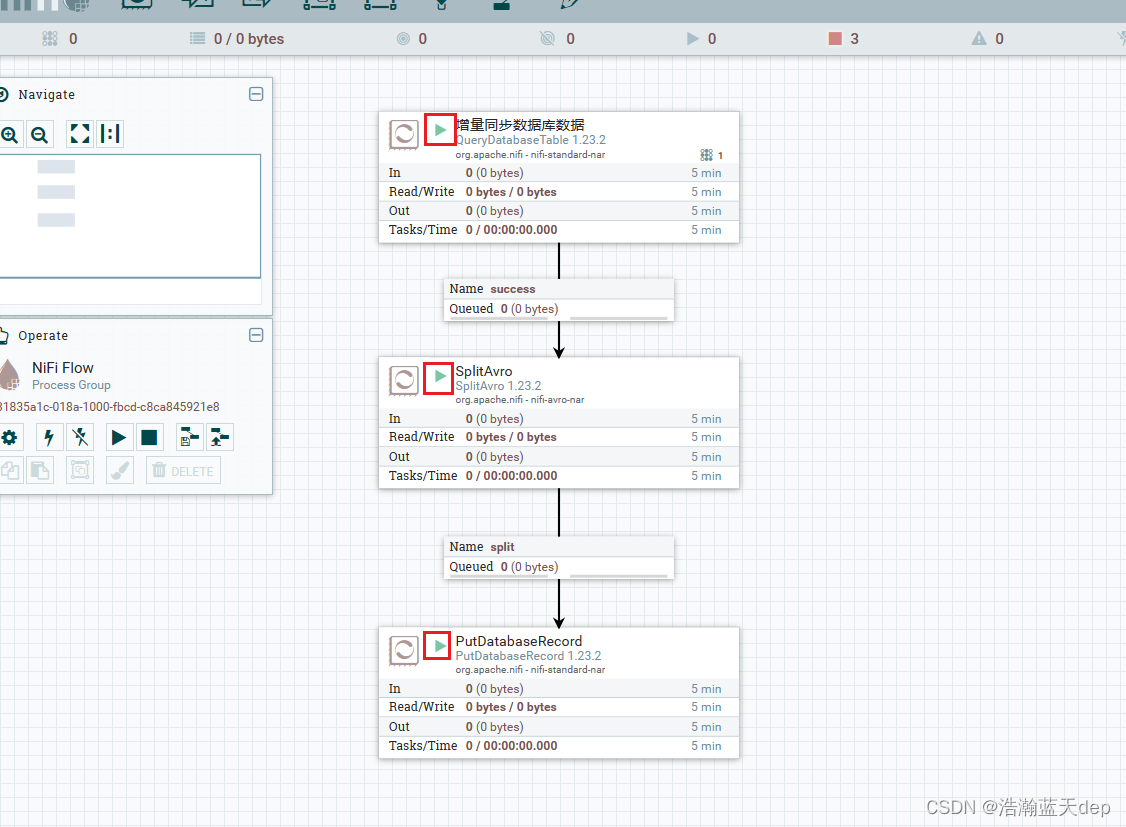
查看目标数据库数据
等待一分钟后查看目标数据库数据,发现源数据库的5条数据被同步到了目标数据库

修改源数据库的数据
UPDATE sys_user SET is_deleted = 1 WHERE id = 1;
UPDATE sys_user SET is_deleted = 1 WHERE id = 4;
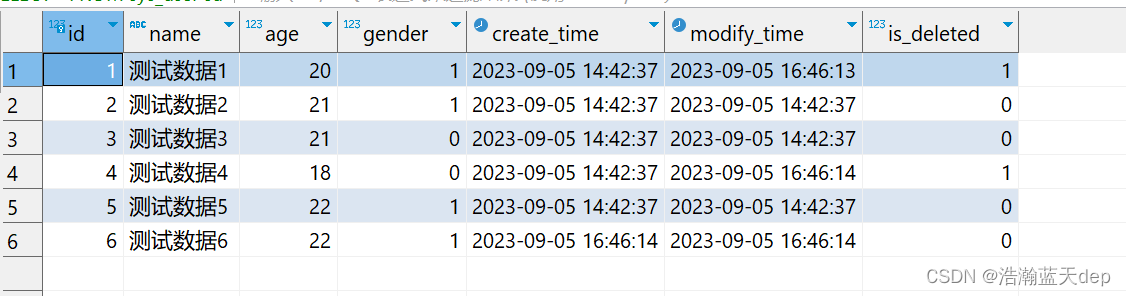
INSERT INTO sys_user (name, age, gender) VALUES ('测试数据6', 22, 1);再次查看目标数据库数据
等待处理器执行后,查看目标数据库数据发现新的数据已经被同步过去
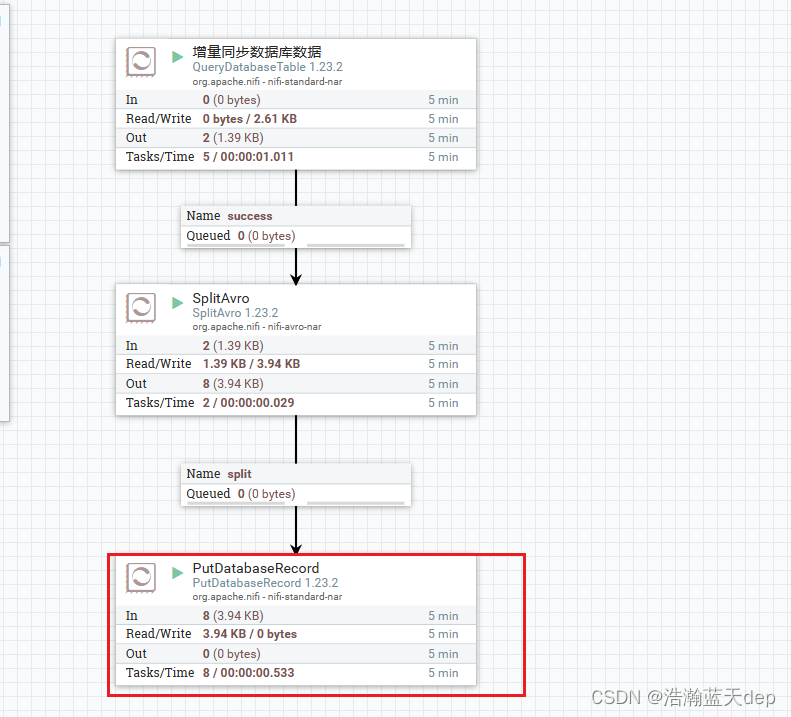
可以看到最后一个处理器最终由8条记录流入
结束语
以上便是使用NIFI增量同步数据库数据的全过程,如果有什么疑问欢迎评论区进行评论。
相关文章:
NIFI实现数据库数据增量同步
说明 nifi版本:1.23.2(docker镜像) 需求背景 将数据库中的数据同步到另一个数据库中,要求对于新增的数据和历史有修改的数据进行增量同步 模拟数据 建表语句 源数据库和目标数据库结构要保持一致,这样可以避免后…...

【C#实战】控制台游戏 勇士斗恶龙(3)——营救公主以及结束界面
君兮_的个人主页 即使走的再远,也勿忘启程时的初心 C/C 游戏开发 Hello,米娜桑们,这里是君兮_,最近开始正式的步入学习游戏开发的正轨,想要通过写博客的方式来分享自己学到的知识和经验,这就是开设本专栏的目的。希望…...
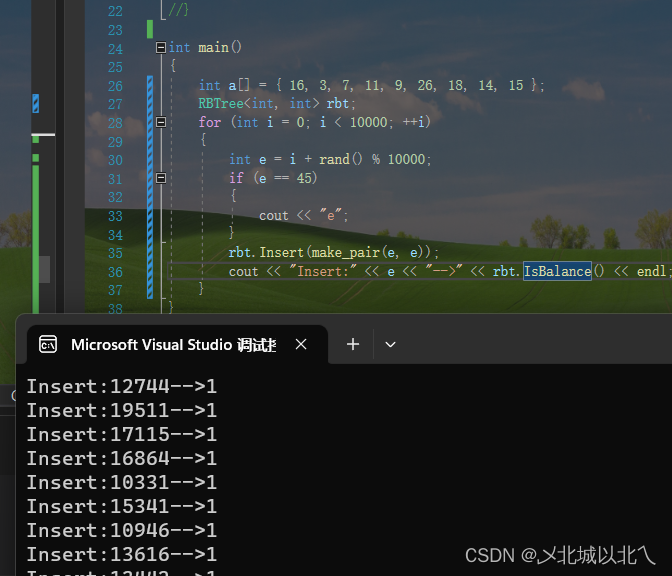
RBTree模拟实现
一、概念 概念:红黑树,是一种二叉搜索树,但在每个结点上增加一个存储位表示结点的颜色,可以是Red或 Black。 通过对任何一条从根到叶子的路径上各个结点着色方式的限制,红黑树确保没有一条路径会比其他路径长出俩倍&a…...
10.4、AP和CP)
AUTOSAR规范与ECU软件开发(实践篇)10.4、AP和CP
目录 1、AP和CP 1、AP和CP 自适应AUTOSAR平台(AP) 并不是传统经典AUTOSAR平台(CP) 的替代品, 不同的版本可同时存在于同一个车辆中, 两个ECU间可通过一些途径, 例如以太网, 将经典应用和自适应性应用进行无缝衔接。 简单而言, 两者的应用场景不太一样: 经典AUTOSAR平…...

css 命名规则
一个有规则的命名 会提高代码的可读性 一、命名规则说明: 1)、所有的命名最好都小写 2)、属性的值一定要用双引号(“”)括起来 3)、给图片加上alt标签 4)、尽量使用英文命名原则 5)、尽量不缩写࿰…...

正中优配:旅游餐饮板块走高,曲江文旅涨停,西安旅游等拉升
旅行餐饮板块7日盘中拉升走高,截至发稿,曲江文旅涨停,西安旅行涨超5%,君亭酒店、华天酒店、国旅联合、宋城演演艺等均上扬。 中国旅行研究院数据显现,今年暑期国内旅行人数达18.39亿人次,占全年国内旅行出…...

世界青岛中国海洋大学金秋悦读《乡村振兴战略下传统村落文化旅游设计》2023新学年许少辉八一新书
世界青岛中国海洋大学金秋悦读《乡村振兴战略下传统村落文化旅游设计》2023新学年许少辉八一新书...

15 | Spark SQL 的 SQL API 操作
SQL API:Spark SQL 允许使用标准 SQL 语句来查询和分析数据。用户可以通过 SparkSession 执行 SQL 查询,并将结果返回为 DataFrame。这使得熟悉 SQL 的用户能够方便地使用 Spark SQL 进行数据处理。 示例 1: 基本查询 执行基本的 SQL 查询,选择数据中的特定列并过滤数据。…...

为什么工作流中围绕XML做EDI报文数据解析/生成?
经常有客户问起,为什么在处理EDI文件时不一次到位,而需要使用多个端口来分次进行处理呢,是不是想要多占用几个端口好多卖钱呀? 实际上,在一开始的知行EDI产品中,功能还没有这么完善,当时只支持…...

C++的运算符重载介绍
所谓重载,就是赋予新的含义。函数重载(Function Overloading)可以让一个函数名有多种功能,在不同情况下进行不同的操作。运算符重载(Operator Overloading)也是一个道理,同一个运算符可以有不同的功能。 实际上,我们已经在不知不觉中使用了运算符重载。例如,+号可以对…...
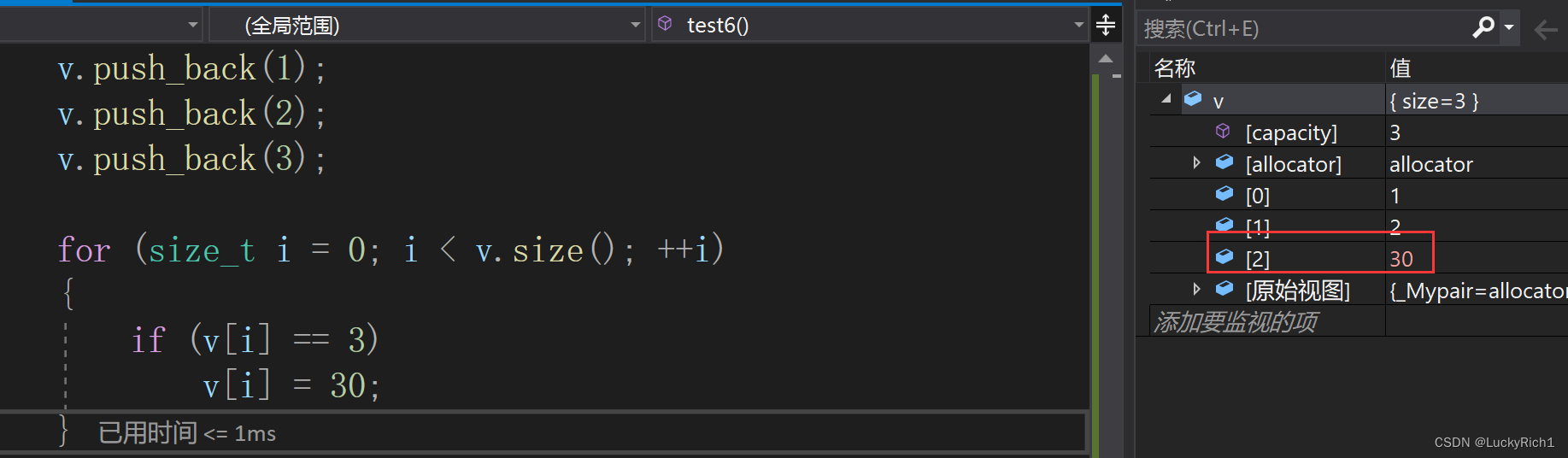
C++vector的使用
vector的使用 1.vector的介绍2.vector的使用3.Member functions3.1构造函数3.2拷贝构造3.3赋值运算符重载 4.iterator5.capacity6.Element access7.增删查改7.1增7.2删7.3查7.4改 1.vector的介绍 1.vector是表示可变大小数组的序列容器. 2.vector也采用连续空间存储元素&#x…...

angular测试API
1.resetTestEnvironment 是 Angular 测试中的一个函数,用于重置测试环境。它通常与 initTestEnvironment 和 platformBrowserDynamicTesting 一起使用,以确保在多个测试套件之间正确清理和重置 Angular 测试环境。 这是 resetTestEnvironment 函数的形式…...

mfc 浮动窗口
参考 MFC模拟360悬浮窗加速球窗口...

【C++漂流记】函数的高级应用——函数默认参数、占位参数、重载
函数的高级应用,侧重介绍函数的默认参数、函数的占位参数、函数重载定义解释及使用。 文章目录 一、函数的默认参数二、函数的占位参数三、函数重载函数重载的注意事项 一、函数的默认参数 函数默认参数是指在函数声明时为参数提供一个默认值,这样在调…...

Java——》synchronized的原理
推荐链接: 总结——》【Java】 总结——》【Mysql】 总结——》【Redis】 总结——》【Kafka】 总结——》【Spring】 总结——》【SpringBoot】 总结——》【MyBatis、MyBatis-Plus】 总结——》【Linux】 总结——》【MongoD…...

CPU主频
CPU主频,也称为时钟频率,是指中央处理单元(CPU)的工作时钟的速度,通常以赫兹(Hz)为单位表示。它表示CPU每秒钟执行的时钟周期数。CPU主频是CPU性能的一个重要指标之一,但不是唯一的性…...

PHP8中查询数组中指定元素-PHP8知识详解
php是使用最广泛的web编程语言,数组是一个数据集合,数组是一种非常常用的数据类型。在操作数组时,有时我们需要查询数组中是否有某个指定元素。在实际的程序开发中,我们用到了下列方法来查询数组中指定的元素:使用arra…...
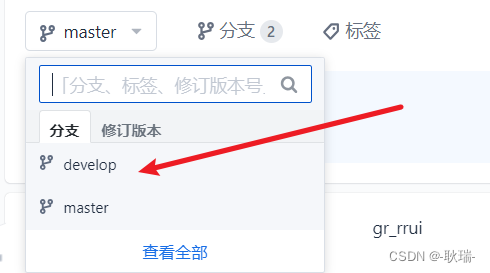
在Git中将本地分支推送到远程仓库
这里很明显 我git云端只有一个master分支 然后 我在本地创建了一个develop分支 然后 现在我想将他放在云端 首先 我们要执行 git checkout -b develop将本地切换到 develop 分支上 因为我这里已经选择的就是了 就不需要了 然后我们执行 git push origin develop这样 刷新云…...
】数据仓库需求:基本需求和数据需求)
【数据仓库基础(四)】数据仓库需求:基本需求和数据需求
文章目录 一. 基本需求1. 安全性2. 可访问性3. 自动化 三. 数据需求1. 准确性2.时效性3.历史可追溯性 从基本需求和数据需求两方面介绍对数据仓库系统的整体要求。 一. 基本需求 1. 安全性 数据仓库中含有机密和敏感的数据。为了能够使用这些数据&…...

C++类模板是一种通用的编程工具,可以创建可以适用于多种数据类型的类
C类模板是一种通用的编程工具,可以创建可以适用于多种数据类型的类。它们允许在类定义中使用参数,以便根据需要实例化具体的类。使用C类模板时,首先需要定义模板。模板定义的语法如下:cpp template <typename T> class MyCl…...
)
167.YOLOv8口罩检测常见问题避坑(loss为NaN/显存溢出/ONNX导出失败实战版)
摘要 目标检测是计算机视觉领域的核心任务之一。YOLO(You Only Look Once)系列模型凭借其端到端、单阶段、高实时性的特性,已成为工业界和学术界最广泛使用的目标检测框架。本文从零开始,系统讲解YOLOv8的核心原理,并给出从数据准备、模型训练、推理验证到ONNX部署的完整…...

ModernBERT:用现代训练技术重塑经典BERT,实现性能与效率双提升
1. 项目概述:为什么我们需要一个“现代”的BERT?如果你在过去几年里深度参与过自然语言处理(NLP)项目,那么对BERT这个名字一定不会陌生。作为Transformer架构在预训练领域的里程碑,BERT彻底改变了我们处理文…...

3PEAK思瑞浦 TP2274-TS2R TSSOP14 精密运放
特性 增益带宽积:7MHz 高斜率:20V/us 宽供电范围:3.1V至36V或2.25V至18V 低失调电压:0.5mV(最大值) 低输入偏置电流:30pA(典型值) 轨到轨输出电压范围 单位增益稳定 工作温度范围:-40C至125C...

Vivado工程实战:在ZCU102上配置MIG控制器时,SLEW属性设置成SLOW还是FAST?
Vivado工程实战:ZCU102平台MIG控制器SLEW属性深度解析 在Xilinx ZCU102开发板上进行DDR4接口设计时,MIG控制器的配置往往成为项目成败的关键。许多工程师能够顺利完成基础配置,却在面对诸如SLEW属性这类"细微"参数时陷入选择困境。…...

CSS如何实现固定页脚布局_利用calc计算高度差
最可靠的页脚固定方案是Flexbox:外层容器设min-height: 100vh和display: flex、flex-direction: column,main加flex: 1,footer保持自然高度,并重置body { margin: 0 }。页脚卡在底部但内容少时被顶上去这是 position: fixed 最常见…...

如何用CLIP-as-service实现半监督学习:有限标注数据的终极指南
如何用CLIP-as-service实现半监督学习:有限标注数据的终极指南 【免费下载链接】clip-as-service 🏄 Scalable embedding, reasoning, ranking for images and sentences with CLIP 项目地址: https://gitcode.com/gh_mirrors/cl/clip-as-service …...

从零到自动化:手把手教你用nRF Connect搭建个人BLE设备测试流水线
从零到自动化:手把手教你用nRF Connect搭建个人BLE设备测试流水线 在物联网设备开发中,蓝牙低功耗(BLE)技术的测试验证一直是让开发者头疼的环节。传统手动测试不仅效率低下,还容易因人为因素导致结果不一致。对于资源有限的硬件创业团队或个…...

https://github.com/langgenius/dify查看设置的apikey
现在我已经掌握了足够的信息,来做一个完整清晰的分析。好的,现在我来给出一个完整的分析。 Dify provider_model_credentials.encrypted_config 解密分析 整体加密架构 Dify 使用 PKCS1_OAEP 加密来保护 API key。每个用户(tenant)…...

Wwise音频文件处理终极指南:3步完成游戏音效解包与替换
Wwise音频文件处理终极指南:3步完成游戏音效解包与替换 【免费下载链接】wwiseutil Tools for unpacking and modifying Wwise SoundBank and File Package files. 项目地址: https://gitcode.com/gh_mirrors/ww/wwiseutil 还在为游戏音频文件无法编辑而烦恼…...

3个简单步骤掌握gInk:Windows上最轻量的免费屏幕画笔工具
3个简单步骤掌握gInk:Windows上最轻量的免费屏幕画笔工具 【免费下载链接】gInk An easy to use on-screen annotation software inspired by Epic Pen. 项目地址: https://gitcode.com/gh_mirrors/gi/gInk gInk屏幕画笔工具是一款专为Windows用户设计的实时…...