深度学习相关VO梳理
相关论文
基于学习的VO 相关:
DeepVO Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks(ICRA,2017)
TartanVO: A Generalizable Learning-based VO(CoRL2021)
SimVODIS: Simultaneous Visual Odometry ,Object Detection, and Instance Segmentation(PAMI,2022)
基于学习的SLAM:
DROID-SLAM: Deep Visual SLAM for Monocular,Stereo, and RGB-D Cameras
NICE-SLAM: Neural Implicit Scalable Encoding for SLAM(CVPR,2022)
NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields(arXiv,2022)
对Dynamic的处理:
DytanVO:Joint Refinement of Visual Odometry and Motion Segmentation in Dynamic Environments(ICRA2023)
SimVODIS++: Neural Semantic Visual Odometry in Dynamic Environments(RAL,2022)
MaskVO: Self-Supervised Visual Odometry with a Learnable Dynamic Mask(SII,2022)
GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose(CVPR,2018)
Competitive Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation(CVPR,2019)
背景
传统方法
基于几何的VO方法在实际中不够鲁棒
传统SLAM方法容易特征缺失、优化算法发散、误差累计
基于学习的方法
基于学习的方法的VO在并没有表现出强大的性能,当前表现甚至不如几何的方法:
a.现有的VO模型训练多样性不足
b.大多数基于学习的VO模型没有关注到问题的一些基本性质
动态环境
基于学习的视觉里程计在动态、人口稠密的环境中容易失败
基于无监督和自监督方式的VO泛化性不行
基于语义方式的问题:1.漏报 2.无法区分实际运动和静态但能运动
Tartanvo
提出了第一个基于学习的视觉里程计(VO)模型,该模型可以推广到多个数据集和现实场景:
- 我们通过比较不同数量的训练数据的性能来证明数据多样性对 VO 模型泛化能力的关键影响。
- 我们设计了一个尺度损失函数(up-to-scale loss function)来处理单目 VO 的尺度模糊性。
- 我们在 VO 模型中创建一个本征层 (IL,instrinsics layer),以实现跨不同相机的泛化。
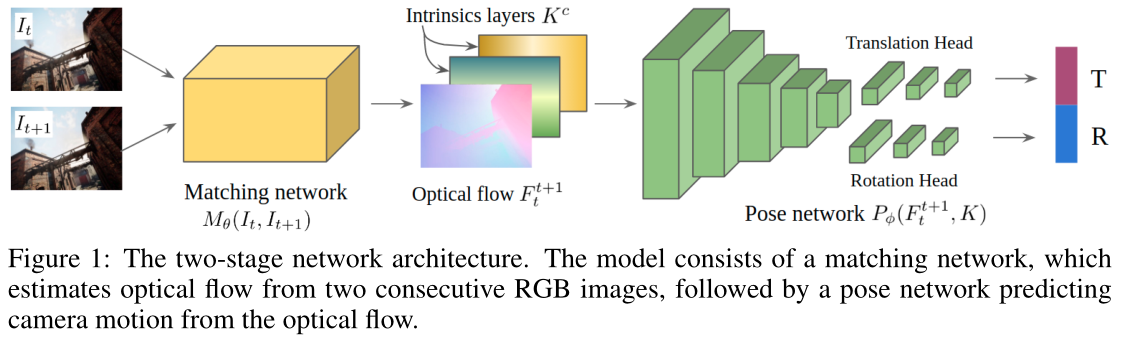
整体结构
匹配模块+位姿模块
input:相邻帧图像
output:相对相机运动(T|R)
多样化训练
利用异常丰富的大规模数据集TartanAir
我们在任务中利用单目图像序列 { I t } \{I_t\} {It}、光流标签 { F t t + 1 } \{F ^{t+1}_t \} {Ftt+1} 和地面实况相机运动 { δ t t + 1 } \{δ^{t+1}_t\} {δtt+1}。我们的目标是共同最小化光流损耗 L f L_f Lf 和相机运动损耗 L p L_p Lp。端到端损耗定义为:
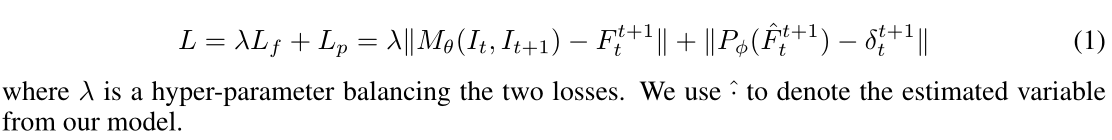
尺度损失函数
尺度模糊度只影响平移 T T T ,我们为 T T T 设计了一个新的损失函数,并保持旋转 R R R 的损失不变。我们为 L P L_P LP 提出了两个大规模损失函数:余弦相似度损失 L p c o s L^{cos}_p Lpcos 和归一化距离损失 L p n o r m L^{norm}_p Lpnorm 。 L p c o s L^{cos}_p Lpcos 由估计的 T ^ \hat{T} T^ 和标签 T T T 之间的余弦角定义:

相机差异的统一
1. 使用instrinsics layer
我们设计了一个新的姿态网络 P ϕ ( F t t + 1 , K ) P_\phi(F^{t+1}_t , K) Pϕ(Ftt+1,K),而不是仅从特征匹配 F t t + 1 F^{t+1}_t Ftt+1 中恢复相机运动 T t t + 1 T^{t+1}_t Ttt+1 ,该网络也取决于相机内在参数 K = { f x , f y , o x , o y } K = \{f_x ,f_y,o_x,o_y\} K={fx,fy,ox,oy},其中 f x f_x fx和 f y f_y fy是焦距, o x o_x ox和 o y o_y oy表示主点的位置。

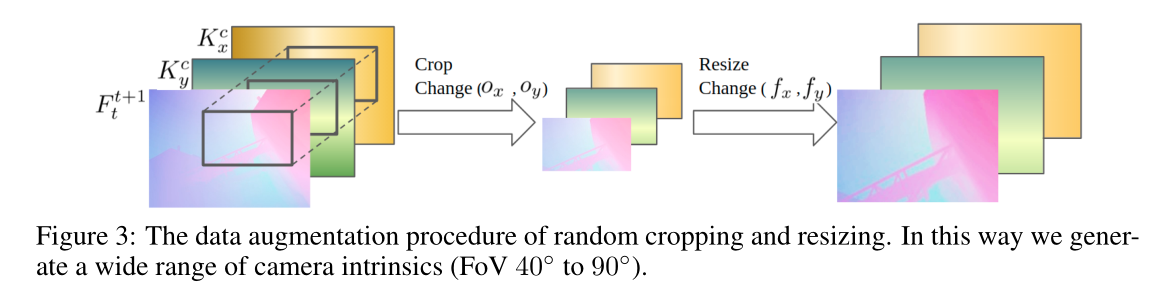
2. 将数据裁剪为不同内参的数据
TartanAir 只有一组相机内在函数,其中 f x = f y = 320 、 o x = 320 f_x = f_y = 320、o_x = 320 fx=fy=320、ox=320 和 o y = 240 o_y = 240 oy=240。我们通过随机裁剪和调整 (RCR,Randomly cropping and resizing) 输入图像大小来模拟各种内在函数。
如图3所示,我们首先在随机位置以随机大小裁剪图像。接下来,我们将裁剪后的图像调整为原始大小。
DytanVO
• 引入了一种新颖的基于学习的VO,以利用相机自我运动、光流和运动分割之间的相互依赖性。
• 我们引入了一个迭代框架,其中自我运动估计和运动分割可以在实时应用的时间限制内快速收敛。
• 在基于学习的 VO 解决方案中,我们的方法无需微调即可在现实动态场景中实现最先进的性能。此外,我们的方法的性能甚至可以与优化后端轨迹的视觉 SLAM 解决方案相媲美。
Architecture
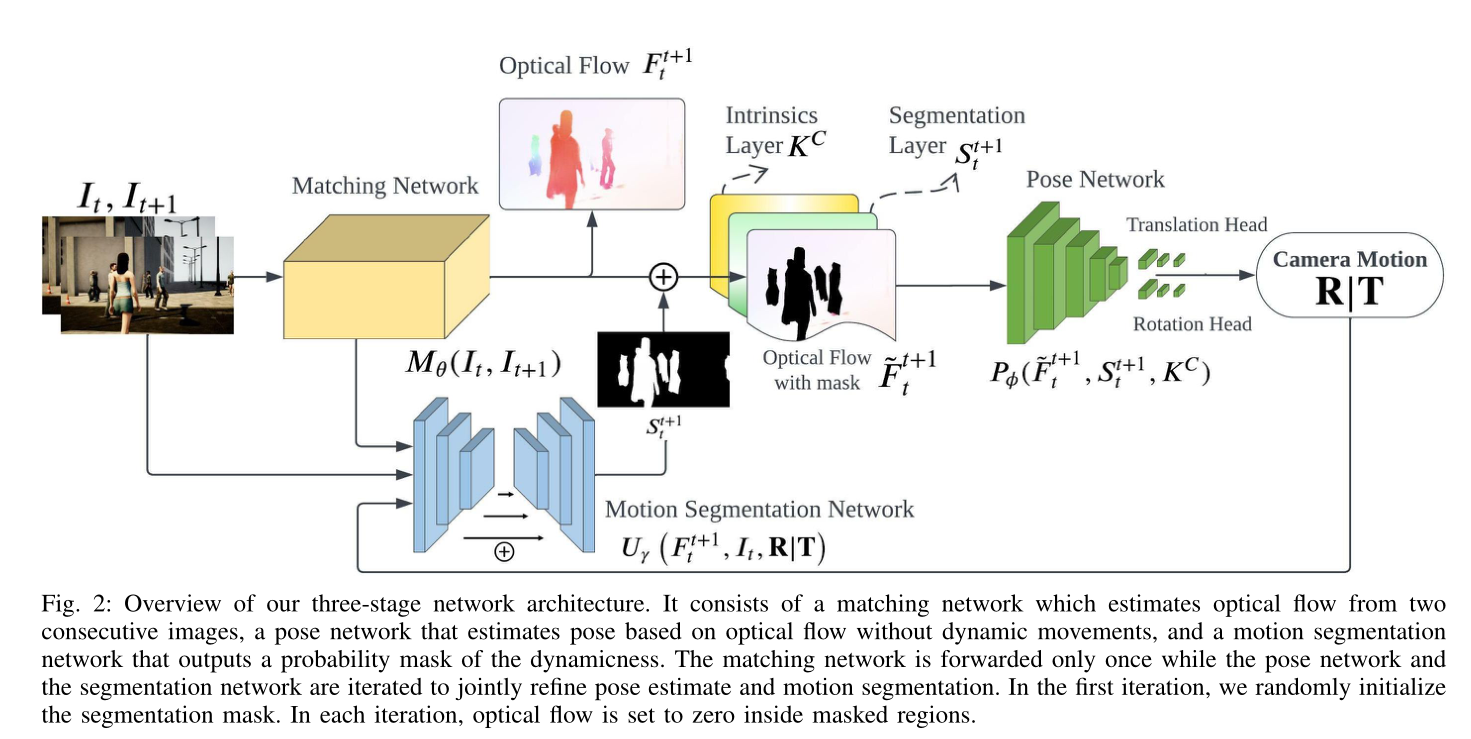
我们的框架由三个子模块组成:匹配网络、运动分割网络和姿态估计网络。
Interactive refine camera motion

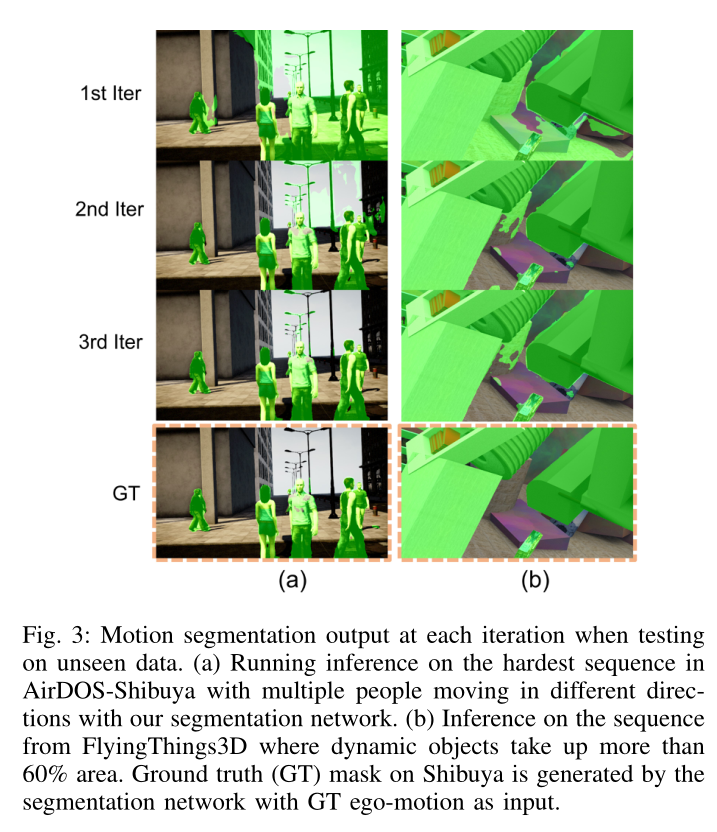
在实践中,我们发现 3 次迭代足以细化相机运动和分割。为了消除任何歧义,1 次迭代过程由一次 M θ M_θ Mθ 前向过程和一次具有随机掩码的 P ϕ P_{\phi} Pϕ 前向过程组成,而 3 次迭代过程由一次 Mθ 前向过程、两次 U γ U_γ Uγ 前向过程和 3 个 P ϕ P_{\phi} Pϕ 前向过程组成。
Supervision
我们在相机运动损失 LP 上监督我们的网络。
在单目设置下,我们只能恢复最大尺度的相机运动。我们按照[5],在计算到地面实况的距离之前对平移向量进行归一化。给定地面真实运动 R ∣ T R|T R∣T:

我们的框架也可以以端到端的方式进行训练,在这种情况下,目标变成光流损失 L M L_M LM 、相机运动损失 L P L_P LP 和运动分割损失 L U L_U LU 的聚合损失,其中 L M L_M LM 是之间的 L1 范数预测流和地面真实流,而 L U L_U LU 是预测概率和分割标签之间的二元交叉熵损失。
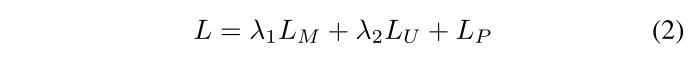
SimVODIS
Architeture
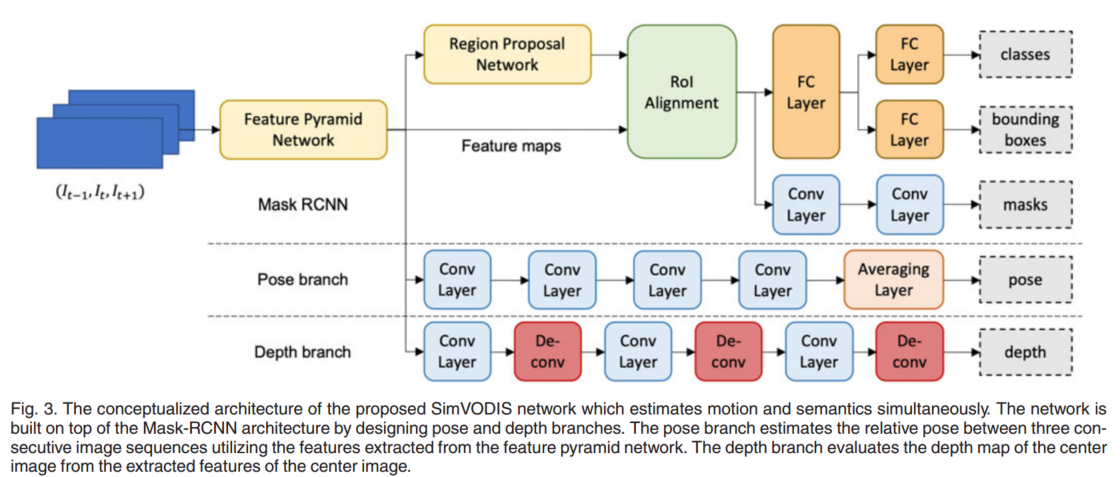
图3描述了所提出的SimVODIS网络的概念化架构。我们基于以下思想设计了SimVODIS网络:
1)Mask RCNN为语义和几何任务提取通用特征,如区域建议、类标记、边界框回归和掩码提取;
2)我们可以使用这些丰富的特征来估计相对姿态和预测深度图,因为提取的特征对语义和几何工作都有用。
对于SimVODIS,我们设计了两个网络分支:姿态分支和深度分支。姿态分支使用来自特征金字塔网络(FPN)的丰富特征来估计三个连续图像序列之间的相对姿态。
Loss
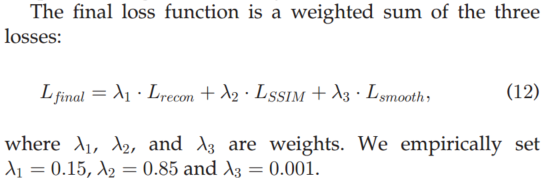
SimVODIS++
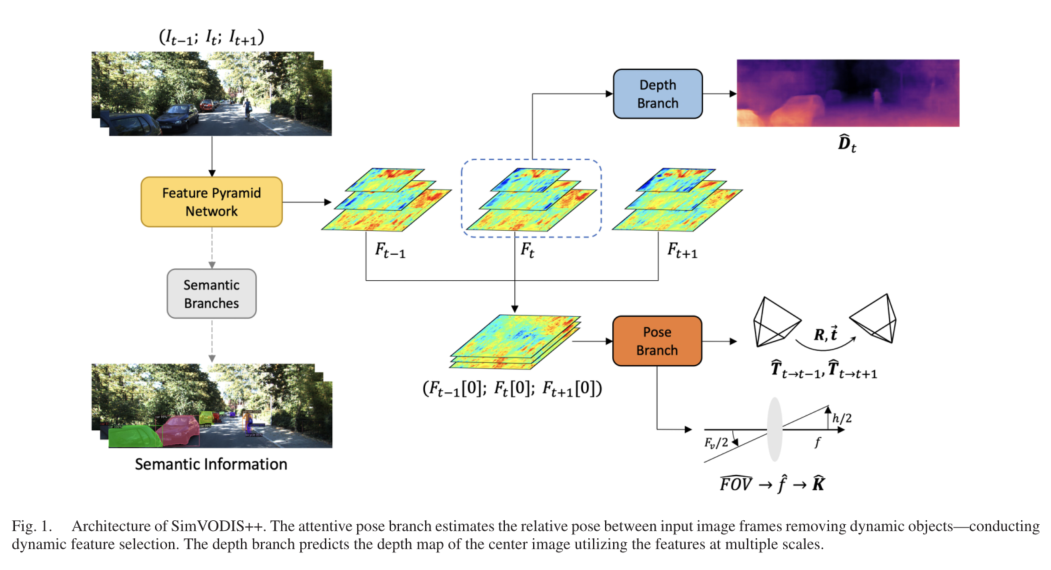
我们基于以下推理设计了SimVODIS++网络:
(1)用于语义分支(对象检测和实例分割)的特征金字塔网络(FPN)提取能够执行语义和几何任务的一般特征;
(2)我们可以利用这些丰富的特征来执行位姿估计和深度图预测。对于SimVODIS++,与SimVODIS[10]相比,我们设计了两个新功能:姿态估计和相机校准。我们进行专注的姿态估计以去除动态对象,并进行相机校准以提高VO性能。由于所提出的姿态估计和相机校准导致的参数总量的增加是最小的。
Attention Pose Estimation(比较质疑)
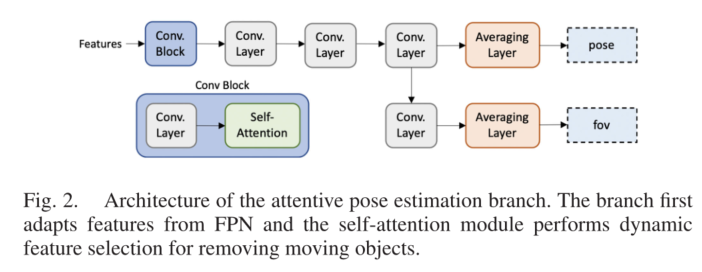
图2描述了在动态环境中用于鲁棒性能的所提出的注意姿态估计的架构。
Conv. Block 从FPN接收特征,调整输入特征以进行自注意,并通过自注意进行动态特征选择。对于自我注意,我们使用CBAM模块[37]。在训练过程中,CBAM模块让姿势分支学会专注于具有相关特征的区域,并尽量减少对动态对象的关注。

MaskVO
这项工作的目的是提出一种自监督学习系统,从未标记的图像序列中重建尺度一致的自我运动。
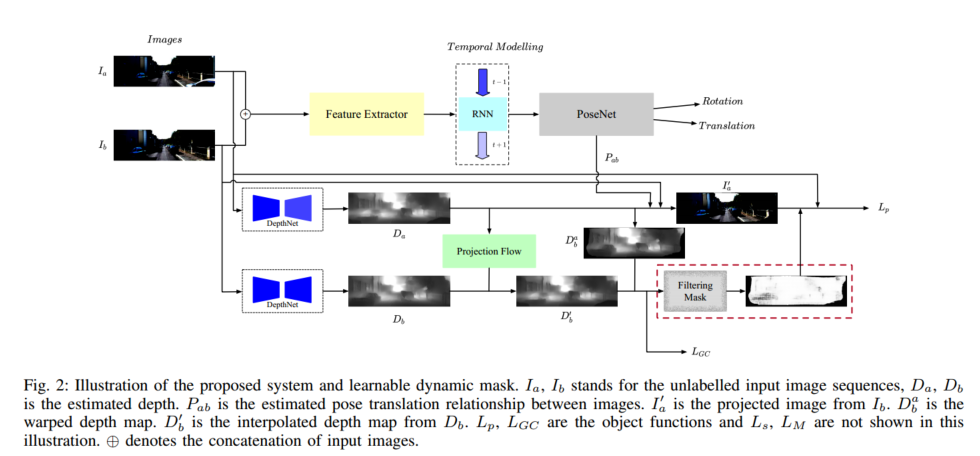
如图 2 所示,两个未标记的 RGB 图像 I a I_a Ia 和 I b I_b Ib 堆叠在一起并输入到特征提取器中。
I a I_a Ia 和 I b I_b Ib 是源图像和目标图像。与[6]、[12]不同,我们使用图像序列来利用视觉运动的时间依赖性。
特征时间建模模块提取图像序列的时间信息,由循环神经网络组成。
然后,6-DoF 位姿 P a b P_{ab} Pab 由位姿网络生成。同时,输入图像的深度图由深度网络生成。
投影图像 I a ′ I_{a}^{\prime} Ia′ 使用 D a 、 I b D_a、I_b Da、Ib和6-DoF位姿 P a b P_{ab} Pab通过等式5生成。
引入掩模网络将学习到的空间信息合并到框架中,减少场景动态的影响。真实图像 I a I_{a} Ia和合成 I a ′ I_{a}^{\prime} Ia′ 之间的差异可以用作自监督信号来构造光度损失。它可以约束并强制系统根据不同的输入图像序列估计姿态和深度。
GeoNet
GeoNet,这是一种联合无监督学习框架,用于视频中的单目深度、光流和自我运动估计。
这三个组件通过 3D 场景几何的性质耦合在一起,由我们的框架以端到端的方式共同学习。具体来说,根据各个模块的预测提取几何关系,然后将其组合为图像重建损失,分别对静态和动态场景部分进行推理。
此外,我们提出了一种自适应几何一致性损失,以提高对异常值和非朗伯区域的鲁棒性,从而有效地解决遮挡和纹理模糊问题。
我们的 GeoNet 的概述如图 2 所示。
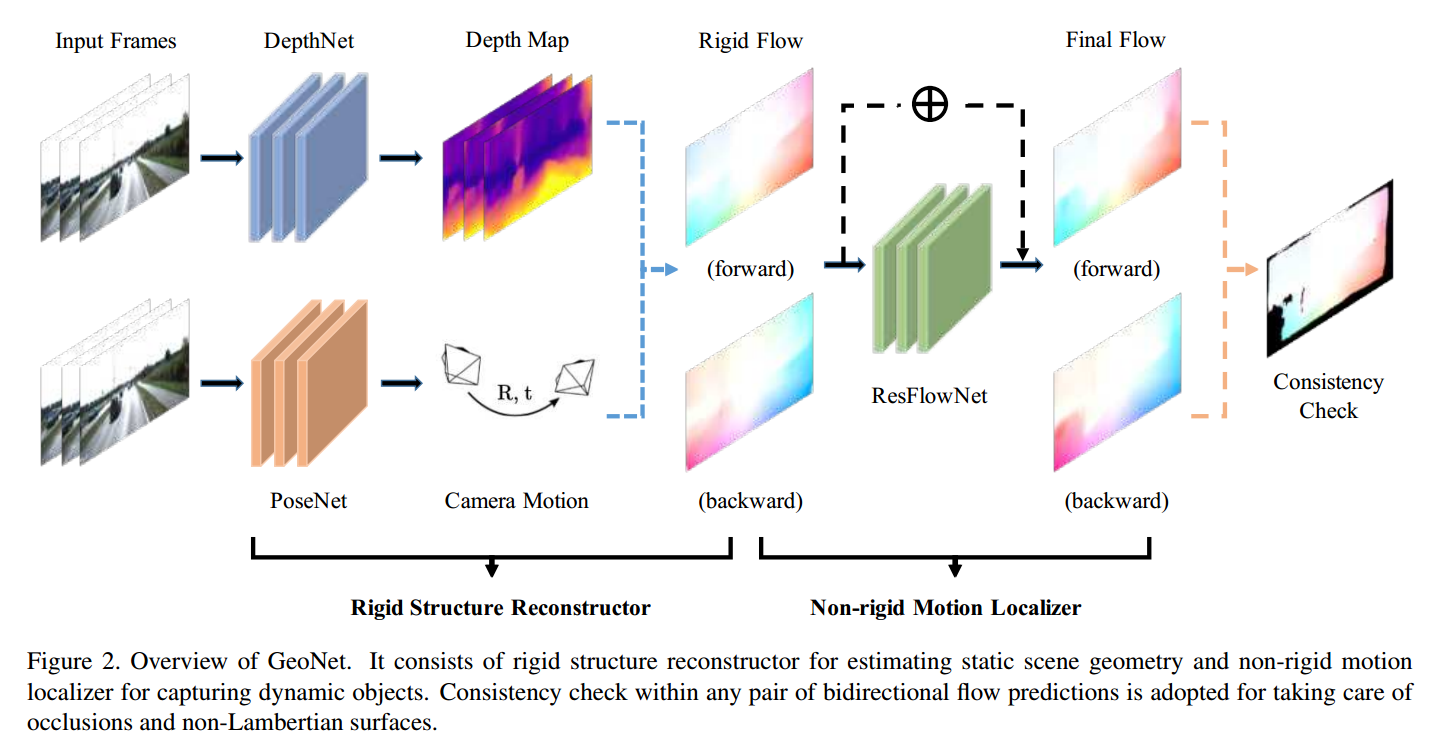
它包含两个阶段,刚性结构推理阶段和非刚性运动细化阶段。
推断场景布局的第一阶段由两个子网络组成,即 DepthNet 和 PoseNet。深度图和相机位姿分别回归并融合以产生刚性流。
第二阶段由 ResFlowNet 完成以处理动态对象。 ResFlowNet 学习到的残余非刚性流与刚性流相结合,得出我们最终的流预测。由于我们的每个子网络都针对特定的子任务,因此复杂的场景几何理解目标被分解为一些更简单的目标。不同阶段的视图合成是我们无监督学习范式的基本监督。
最后但并非最不重要的一点是,我们在训练期间进行几何一致性检查,这显着增强了我们预测的一致性并取得了令人印象深刻的性能
Competitive Collaboration
我们在本文中考虑了四个这样的问题:单视图深度预测、相机运动估计、光流和运动分割。之前的工作已经使用真实数据[5]和合成数据[4]通过监督来解决这些问题。然而,合成数据与真实数据之间始终存在现实差距,并且真实数据有限或不准确。
如图 2 所示,我们在框架中引入了两个参与者,即静态场景重建器 R = ( D , C ) R = (D, C) R=(D,C),它使用深度 D 和相机运动 C 来推理静态场景像素;以及运动区域重建器 F,其推理独立运动区域中的像素。这两个玩家通过推理图像序列中的静态场景和移动区域像素来竞争训练数据。比赛由运动分割网络 M 主持,该网络分割静态场景和运动区域,并将训练数据分发给选手。不过,主持人也需要培训,以保证公平竞争。因此,玩家 R 和 F 合作训练主持人 M,使其在训练周期的交替阶段正确分类静态和移动区域。这个通用框架在本质上与期望最大化 (EM) 类似,但专为神经网络训练而制定。
相关文章:
深度学习相关VO梳理
相关论文 基于学习的VO 相关: DeepVO Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks(ICRA,2017) TartanVO: A Generalizable Learning-based VO(CoRL2021) SimVODIS: Simultaneous Vis…...

SpringMVC---CRUD实现
思路分析 搭建环境逆向生层对应的类(model、mapper.xml、mapper.java)编写业务逻辑层编写web层(控制器)前端页面 一、环境搭建 1.1、导入项目所需依赖(pom.xml) <project xmlns"http://maven.apache.org/POM/4.0.0"…...
vue+elementUI el-select 自定义搜索逻辑(filter-method)
下拉列表的默认搜索是搜索label显示label,我司要求输入id显示label名称 <el-form-item label"部门:"><el-select v-model"form.region1" placeholder"请选择部门" filterable clearable:filter-method"dataFilter&qu…...

数据库——事务
事务是指作为一个整体被执行的一系列操作。在数据库管理系统中,事务是指一组数据库操作(如插入、更新、删除等)的逻辑单元,也就是说事务的本质是把多个操作打包成一个操作,并且它要么完全执行,要么完全不执…...
echarts折线图每段显示不同的颜色
效果图 配置项: zqChartFour: {title: {text: "一天用电量分布",subtext: "纯属虚构",},tooltip: {trigger: "axis",axisPointer: {type: "cross",},},toolbox: {show: true,feature: {saveAsImage: {},},},xAxis: {type:…...
)
设计模式-单例模式(Singleton)
文章目录 前言一、单例模式的概念二、单例模式的实现三、单例模式的应用场景四、单例模式优缺点优点:缺点:总结 前言 单例模式(Singleton Pattern)是一种创建型设计模式,它确保一个类只有一个实例,并提供一…...

优漫动游 常见的AI视频生成网站的官方网站:
1、Lumen5 Lumen5是一款在线视频制作工具,利用人工智能技术能够迅速将文本、和音乐转换为视频。它可以帮助你把博客文章、社交媒体内容等转化为吸引人的视频,从而提高你的品牌曝光率和社交媒体的参与度。 2.Animoto Animoto是一个视频制作平台&…...

Vue中数据可视化关系图展示与关系图分析
Vue中数据可视化关系图展示与关系图分析 数据可视化是现代Web应用程序的重要组成部分之一,它可以帮助我们以图形的方式呈现和分析复杂的数据关系。Vue.js是一个流行的JavaScript框架,它提供了强大的工具来构建数据可视化应用。本文将介绍如何使用Vue.js…...
【启扬方案】基于启扬安卓屏一体机的医疗手推车解决方案
医疗手推车作为医院基础设施的一部分,被广泛应用于医院内部,包括急诊室、手术室、病房和其他临床部门。伴随着互联网技术的发展和行业的渗透,智慧医疗受到越来越多的青睐,这也使得很多医疗设施得到了改进,医疗手推车也…...

JavaScript实现MD5加密的6种方式
关于MD5: MD5.js是通过前台js加密的方式对用户信息,密码等私密信息进行加密处理的工具,也可称为插件。 在本案例中 可以看到MD5共有6种加密方法: 1, hex_md5(value) 2, b64_md5(value) 3, …...
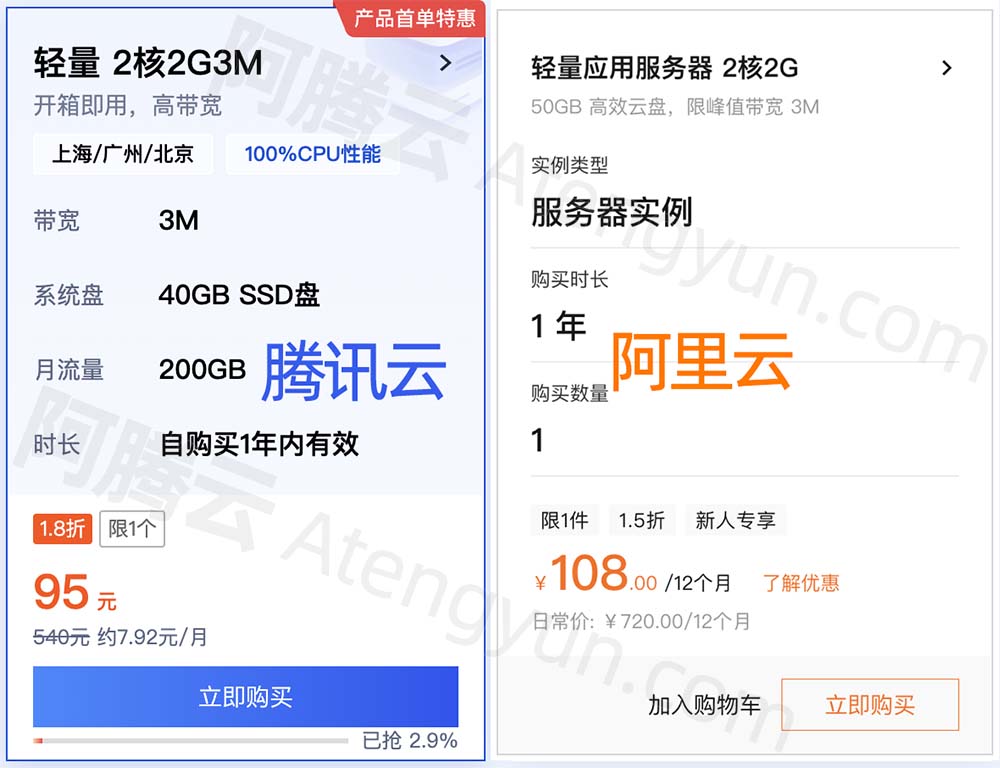
腾讯云和阿里云2核2G服务器租用价格表对比
2核2G云服务器可以选择阿里云服务器或腾讯云服务器,腾讯云轻量2核2G3M带宽服务器95元一年,阿里云轻量2核2G3M带宽优惠价108元一年,不只是轻量应用服务器,阿里云还可以选择ECS云服务器u1,腾讯云也可以选择CVM标准型S5云…...

抖音无需API开发连接Stable Diffusion,实现自动根据评论区的指令生成图像并返回
抖音用户使用场景: 随着AI绘图的热度不断升高,许多抖音达人通过录制视频介绍不同的AI工具,包括产品背景、使用方法以及价格等,以吸引更多的用户。其中,Stable Diffusion这款产品受到了许多博主达人的青睐。在介绍这款产…...
)
MySQL(三)
DDL(数据定义语言) 库 /* 创建数据库testone */ create database testone; /* 查询数据库testone */ show databases; /* 选择数据库testone */ use testone; /* 删除数据库testone */ drop database testone; 表 创建表 create table table_name (…...
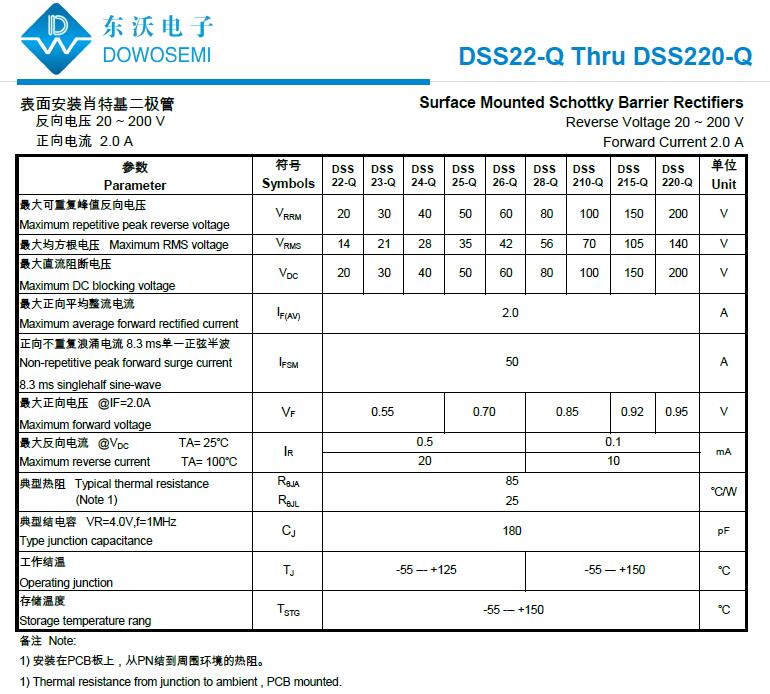
汽车级肖特基二极管DSS220-Q 200V 2A
DSS220-Q是什么二极管?贵司有生产吗? 肖特基二极管DSS220-Q符合汽车级AEC Q101标准吗? DSS220-Q贴片肖特基二极管参数是什么封装?正向电流和反向电压是多大? DSS220-Q肖特基二极管需要100KK,有现货吗&#…...

maven jetty post 上传长度设置
maven jetty post 上传长度设置 <plugin><groupId>org.eclipse.jetty</groupId><artifactId>jetty-maven-plugin</artifactId><version>9.4.8.v20171121</version><configuration><scanIntervalSeconds>1</scanInter…...

LeetCode 面试题 03.03. 堆盘子
文章目录 一、题目二、C# 题解 一、题目 堆盘子。设想有一堆盘子,堆太高可能会倒下来。因此,在现实生活中,盘子堆到一定高度时,我们就会另外堆一堆盘子。请实现数据结构 SetOfStacks,模拟这种行为。SetOfStacks 应该由…...

Python-函数进阶
函数的多返回值 按照返回值的顺序, 写对应顺序的多个变量接受即可, 变量之间用逗号隔开,支持不同类型的数据return def test_return():return 1, 2, 3x, y, z test_return()print(x) print(y) print(z)函数参数种类 使用方式上的不同&am…...
)
实操Hadoop大数据高可用集群搭建(hadoop3.1.3+zookeeper3.5.7+hbase3.1.3+kafka2.12)
前言 纯实操,无理论,本文是给公司搭建测试环境时记录的,已经按照这一套搭了四五遍大数据集群了,目前使用还未发现问题。 有问题麻烦指出,万分感谢! PS:Centos7.9、Rocky9.1可用 集群配置 iph…...
如何在 Ubuntu 上安装和使用 Nginx?
ginx(发音为“engine-x”)是一种流行的 Web 服务器软件,以其高性能和可靠性而闻名。它是许多流行网站使用的开源软件,包括 Netflix、GitHub 和 WordPress。Nginx 可以用作 Web 服务器、负载均衡器、反向代理和 HTTP 缓存等。 它以…...
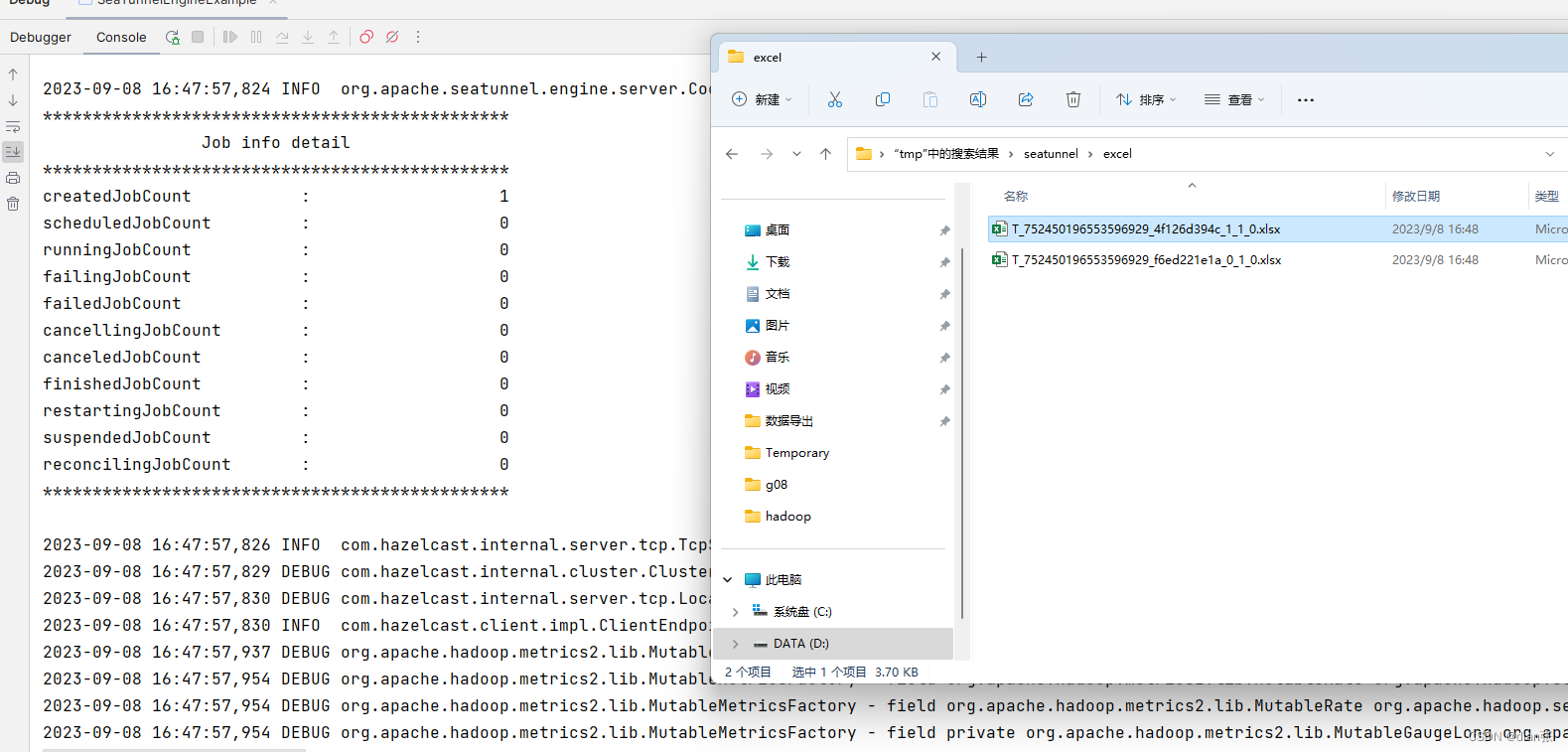
seatunnel win idea 本地调试
调试FakeSource,LocalFile # Set the basic configuration of the task to be performed env {execution.parallelism 1job.mode "BATCH" }# Create a source to connect to Mongodb source {# This is a example source plugin **only for test and d…...

突破传统命令行限制:PortProxyGUI如何重塑Windows网络配置体验
突破传统命令行限制:PortProxyGUI如何重塑Windows网络配置体验 【免费下载链接】PortProxyGUI A manager of netsh interface portproxy which is to evaluate TCP/IP port redirect on windows. 项目地址: https://gitcode.com/gh_mirrors/po/PortProxyGUI …...

Eclipse构建后处理:从ELF到HEX的自动化转换实践
1. 为什么需要从ELF转换到HEX? 在嵌入式开发领域,特别是汽车电子控制器(ECU)开发中,我们经常会遇到两种关键的可执行文件格式:ELF和HEX。ELF(Executable and Linkable Format)是编译…...

C#怎么使用LINQ OrderBy排序 C#如何用LINQ对集合按多个字段进行升序降序排列【语法】
OrderBy必须唯一且首置,后续字段用ThenBy/ThenByDescending链式调用;null默认排最前(升序)或最后(降序);延迟执行,避免重复ToList。OrderBy 和 ThenBy 怎么连用才对多个字段排序不能…...

Redux Thunk终极兼容性测试指南:多版本支持全解析
Redux Thunk终极兼容性测试指南:多版本支持全解析 【免费下载链接】redux-thunk Thunk middleware for Redux 项目地址: https://gitcode.com/gh_mirrors/re/redux-thunk Redux Thunk作为Redux生态中最流行的中间件之一,为开发者提供了处理异步逻…...

如何使用Android Sunflower构建可预测UI:掌握单向数据流的终极指南
如何使用Android Sunflower构建可预测UI:掌握单向数据流的终极指南 【免费下载链接】sunflower A gardening app illustrating Android development best practices with migrating a View-based app to Jetpack Compose. 项目地址: https://gitcode.com/gh_mirro…...

使用Nodejs和Taotoken构建一个多轮对话代理服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js和Taotoken构建一个多轮对话代理服务 为全栈或后端开发者设计一个场景,利用Node.js环境下的openai包&#…...

独立开发者如何通过taotoken以更低成本实验多种大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何通过Taotoken以更低成本实验多种大模型能力 对于独立开发者或小型工作室而言,在项目原型阶段验证不同大…...

在Serv00共享主机上部署SOCKS5代理:原理、部署与优化指南
1. 项目概述与核心价值最近在折腾一些需要稳定网络连接的自托管服务时,遇到了一个经典难题:如何在资源受限的共享主机环境里,搭建一个轻量、稳定且可控的网络代理通道。这让我想起了之前在社区里看到的一个项目——cmliu/socks5-for-serv00。…...
)
面试题:文本表示方法详解——One-hot、Word2Vec、上下文表示、BERT词向量全解析(NLP基础高频考点)
1. 为什么面试官总爱问“文本表示方法”?1.1 这个问题的本质是什么任何 NLP 系统,不管是情感分析、文本分类、搜索推荐、智能客服,还是今天的大模型应用,本质上都绕不开一个前提:机器并不真正认识“文字”,…...
函数绘制三维曲面图)
用surf( )函数绘制三维曲面图
在“用plot3( )函数绘制三维曲线图”中,实现了三维曲线的绘制,得到了一个类似面包圈形状的旋转曲面,很喜欢这个造型,就想到是不是可以直接绘制出曲面,而不只是用曲线方式绘制出看起来像曲面的图形。一看参考书…...