轻松搭建本地知识库的ChatGLM2-6B
近期发现了一个项目,它的前身是ChatGLM,在我之前的博客中有关于ChatGLM的部署过程,本项目在前者基础上进行了优化,可以基于当前主流的LLM模型和庞大的知识库,实现本地部署自己的ChatGPT,并可结合自己的知识对模型进行微调,让问答中包含自己上传的知识。依托于本项目支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。下面具体讲解如何来实现本地部署,过程十分简单,使用起来十分方便。
目录
一、代码下载
二、 模型支持
2.1 LLM 模型支持
2.2 Embedding 模型支持
三、开发部署
3.1 软件需求
3.2 开发环境准备
3.3 下载模型至本地
3.4 设置配置项
3.5 知识库初始化与迁移
3.6 一键启动API 服务或 Web UI
四、添加个人知识库
4.1 本地添加知识库
4.2 通过web页面添加知识库
4.3 重新微调模型
一、代码下载
项目链接 GitHub - chatchat-space/Langchain-Chatchat
将该代码下载到本地。
二、 模型支持
本项目中默认使用的 LLM 模型为 THUDM/chatglm2-6b,默认使用的 Embedding 模型为 moka-ai/m3e-base 为例。
2.1 LLM 模型支持
本项目最新版本中基于 FastChat 进行本地 LLM 模型接入,支持模型如下:
- meta-llama/Llama-2-7b-chat-hf
- Vicuna, Alpaca, LLaMA, Koala
- BlinkDL/RWKV-4-Raven
- camel-ai/CAMEL-13B-Combined-Data
- databricks/dolly-v2-12b
- FreedomIntelligence/phoenix-inst-chat-7b
- h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b
- lcw99/polyglot-ko-12.8b-chang-instruct-chat
- lmsys/fastchat-t5-3b-v1.0
- mosaicml/mpt-7b-chat
- Neutralzz/BiLLa-7B-SFT
- nomic-ai/gpt4all-13b-snoozy
- NousResearch/Nous-Hermes-13b
- openaccess-ai-collective/manticore-13b-chat-pyg
- OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5
- project-baize/baize-v2-7b
- Salesforce/codet5p-6b
- StabilityAI/stablelm-tuned-alpha-7b
- THUDM/chatglm-6b
- THUDM/chatglm2-6b
- tiiuae/falcon-40b
- timdettmers/guanaco-33b-merged
- togethercomputer/RedPajama-INCITE-7B-Chat
- WizardLM/WizardLM-13B-V1.0
- WizardLM/WizardCoder-15B-V1.0
- baichuan-inc/baichuan-7B
- internlm/internlm-chat-7b
- Qwen/Qwen-7B-Chat
- HuggingFaceH4/starchat-beta
- 任何 EleutherAI 的 pythia 模型,如 pythia-6.9b
- 在以上模型基础上训练的任何 Peft 适配器。为了激活,模型路径中必须有
peft。注意:如果加载多个peft模型,你可以通过在任何模型工作器中设置环境变量PEFT_SHARE_BASE_WEIGHTS=true来使它们共享基础模型的权重。
以上模型支持列表可能随 FastChat 更新而持续更新,可参考 FastChat 已支持模型列表。
除本地模型外,本项目也支持直接接入 OpenAI API,具体设置可参考 configs/model_configs.py.example 中的 llm_model_dict 的 openai-chatgpt-3.5 配置信息。
2.2 Embedding 模型支持
本项目支持调用 HuggingFace 中的 Embedding 模型,已支持的 Embedding 模型如下:
- moka-ai/m3e-small
- moka-ai/m3e-base
- moka-ai/m3e-large
- BAAI/bge-small-zh
- BAAI/bge-base-zh
- BAAI/bge-large-zh
- BAAI/bge-large-zh-noinstruct
- sensenova/piccolo-base-zh
- sensenova/piccolo-large-zh
- shibing624/text2vec-base-chinese-sentence
- shibing624/text2vec-base-chinese-paraphrase
- shibing624/text2vec-base-multilingual
- shibing624/text2vec-base-chinese
- shibing624/text2vec-bge-large-chinese
- GanymedeNil/text2vec-large-chinese
- nghuyong/ernie-3.0-nano-zh
- nghuyong/ernie-3.0-base-zh
- OpenAI/text-embedding-ada-002
三、开发部署
3.1 软件需求
本项目已在 Python 3.8.1 - 3.10,CUDA 11.7 环境下完成测试。已在 Windows、ARM 架构的 macOS、Linux 系统中完成测试。
3.2 开发环境准备
参见 开发环境准备。
请注意: 0.2.3 及更新版本的依赖包与 0.1.x 版本依赖包可能发生冲突,强烈建议新建环境后重新安装依赖包。
首先要创建虚拟环境,然后在虚拟环境中切换到代码文件目录:
cd /d E:\Demo\Langchain-Chatchat-master # 切换到代码所在位置创建虚拟环境:
conda create -n Chat_GLM python=3.9 # 虚拟环境名称为ChatGLM启用虚拟环境:
conda activate ChatGLM安装环境依赖:
pip install requirements.txt安装zh_core_web_sm语言包:
spacy/zh_core_web_sm at main (huggingface.co)
只需下载下方图片目录中的whl文件,然后切换到zh_core_web_sm-any-none-any.whl目录,采用pip 安装
pip install zh_core_web_sm-any-none-any.whl
3.3 下载模型至本地
如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
以本项目中默认使用的 LLM 模型 THUDM/chatglm2-6b 与 Embedding 模型 moka-ai/m3e-base 为例。直接点击下载。
网盘下载:
链接:https://pan.baidu.com/s/14vm-yc8EDQ3DqrRAliFWXw?pwd=eaxq
提取码:eaxq链接:https://pan.baidu.com/s/1OAqm5sQOUHYyg-YzZu7eCw?pwd=0arh
提取码:0arh
3.4 设置配置项
复制模型相关参数配置模板文件 configs/model_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 model_config.py。
复制服务相关参数配置模板文件 configs/server_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 server_config.py。
在开始执行 Web UI 或命令行交互前,请先检查 configs/model_config.py 和 configs/server_config.py 中的各项模型参数设计是否符合需求:
- 请确认已下载至本地的 LLM 模型本地存储路径写在
llm_model_dict对应模型的local_model_path属性中,如:
llm_model_dict={"chatglm2-6b": {"local_model_path": "E:\Demo\chatglm2-6b", # 只需该这里"api_base_url": "http://localhost:8888/v1", # "name"修改为 FastChat 服务中的"api_base_url""api_key": "EMPTY"},}- 请确认已下载至本地的 Embedding 模型本地存储路径写在
embedding_model_dict对应模型位置,如:
embedding_model_dict = {"m3e-base": "E:\Demo\m3e-base", # 只需改这里}如果你选择使用OpenAI的Embedding模型,请将模型的 key写入 embedding_model_dict中。使用该模型,你需要能够访问OpenAI官的API,或设置代理。
3.5 知识库初始化与迁移
当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库(我们强烈建议您在执行操作前备份您的知识文件)。
-
如果您是从
0.1.x版本升级过来的用户,针对已建立的知识库,请确认知识库的向量库类型、Embedding 模型与configs/model_config.py中默认设置一致,如无变化只需以下命令将现有知识库信息添加到数据库即可: -
python init_database.py -
如果您是第一次运行本项目,知识库尚未建立,或者配置文件中的知识库类型、嵌入模型发生变化,或者之前的向量库没有开启
normalize_L2,需要以下命令初始化或重建知识库: -
python init_database.py --recreate-vs
3.6 一键启动API 服务或 Web UI
1. 一键启用默认模型
一键启动脚本 startup.py,一键启动所有 Fastchat 服务、API 服务、WebUI 服务,示例代码:
python startup.py -a自动跳转到web页面,若不能跳转记得在代码末尾按一下Enter键,即可一键启动web页面。

并可使用 Ctrl + C 直接关闭所有运行服务。如果一次结束不了,可以多按几次。
可选参数包括 -a (或--all-webui), --all-api, --llm-api, -c (或--controller), --openai-api, -m (或--model-worker), --api, --webui,其中:
--all-webui 为一键启动 WebUI 所有依赖服务;
--all-api 为一键启动 API 所有依赖服务;
--llm-api 为一键启动 Fastchat 所有依赖的 LLM 服务;
--openai-api 为仅启动 FastChat 的 controller 和 openai-api-server 服务;
其他为单独服务启动选项。2. 启用非默认模型
若想指定非默认模型,需要用 --model-name 选项,示例:
python startup.py --all-webui --model-name Qwen-7B-Chat更多信息可通过 python startup.py -h查看。
四、添加个人知识库
如果当前回答结果并不理想,如下图所示,可添加知识库,对知识进行优化

4.1 本地添加知识库
将文档添加到knowledge_base——samples——content目录下:
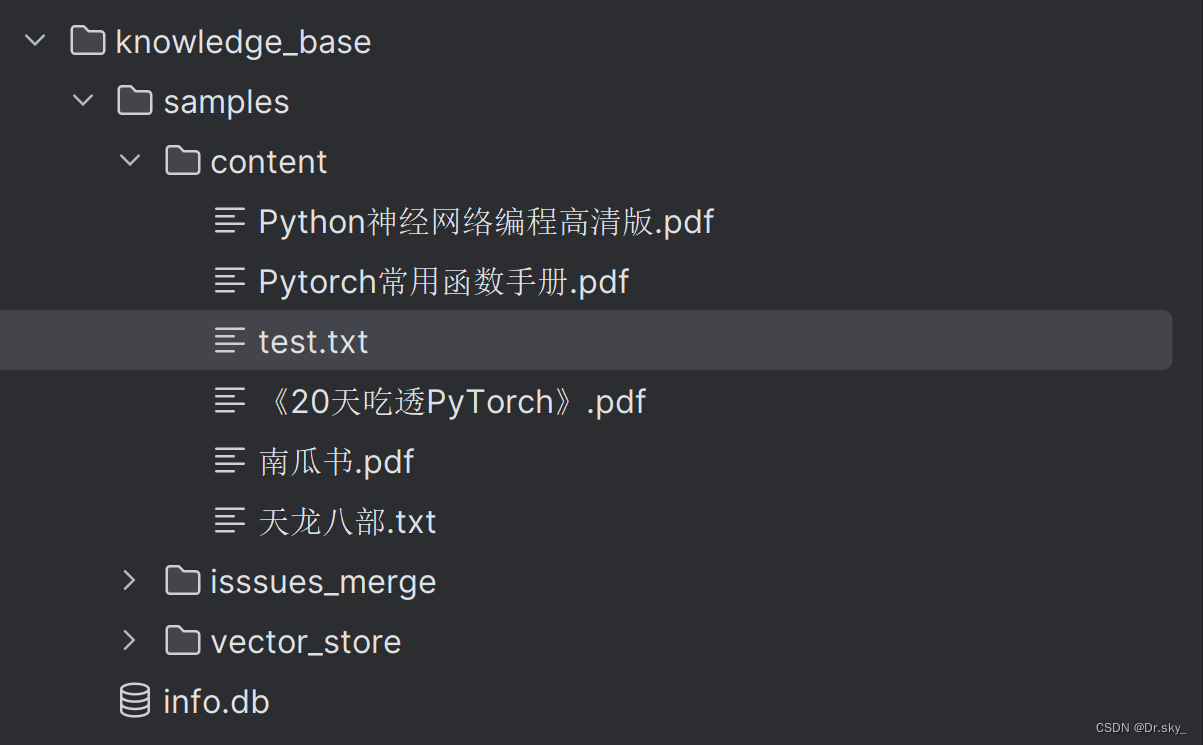
4.2 通过web页面添加知识库
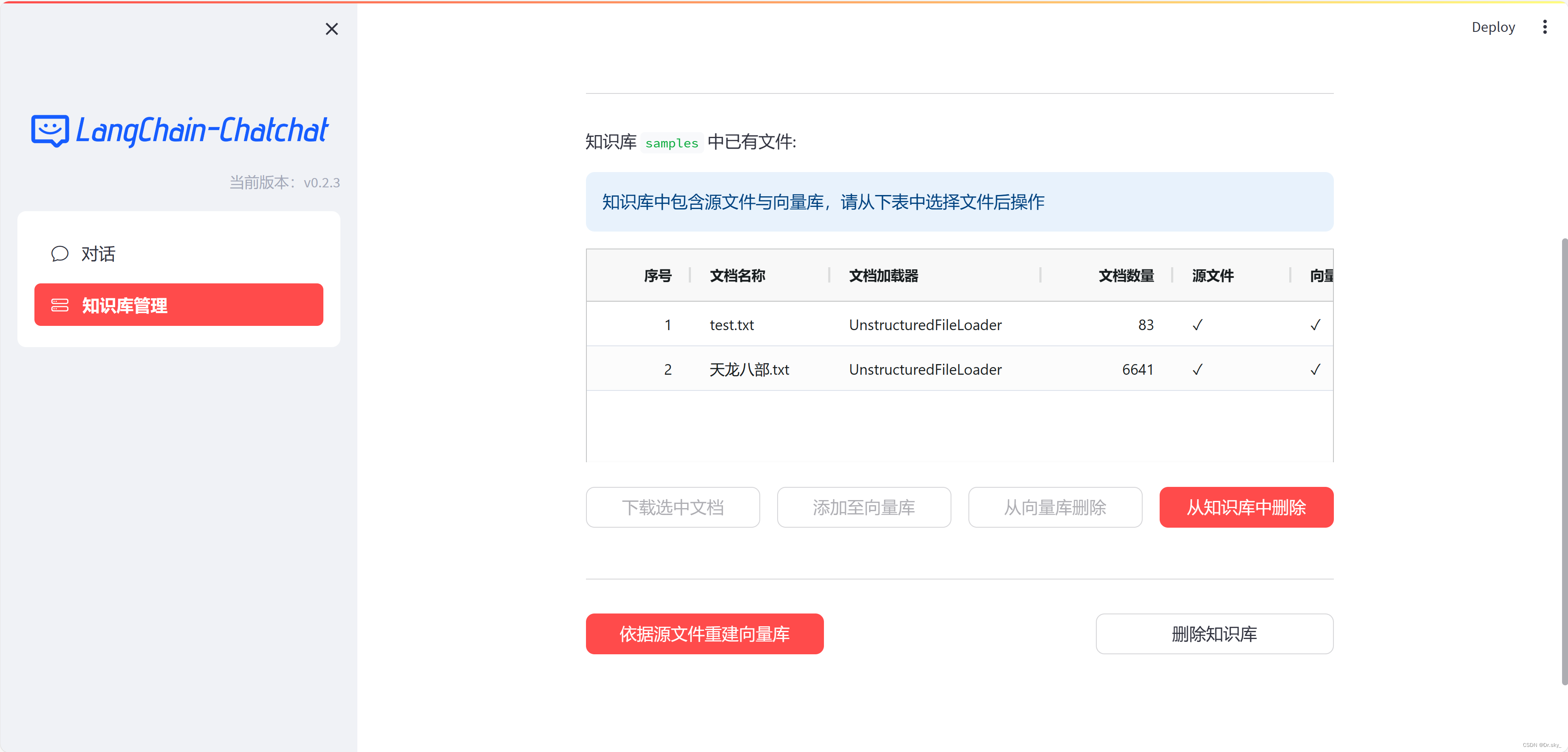
4.3 重新微调模型
知识库添加完成之后,按照3.5-3.6重新运行程序,即可实现本地知识库更新。如下图所示,添加完《天龙八部》电子书之后,回答结果变得精准。

提升回答速度,把CPU改为GPU:
model_config.py文件中,修改
# Embedding 模型运行设备。设为"auto"会自动检测,也可手动设定为"cuda","mps","cpu"其中之一。
EMBEDDING_DEVICE = "auto"为:
# Embedding 模型运行设备。设为"auto"会自动检测,也可手动设定为"cuda","mps","cpu"其中之一。
EMBEDDING_DEVICE = "cuda"修改
# LLM 运行设备。设为"auto"会自动检测,也可手动设定为"cuda","mps","cpu"其中之一。
LLM_DEVICE = "auto"为:
# LLM 运行设备。设为"auto"会自动检测,也可手动设定为"cuda","mps","cpu"其中之一。
LLM_DEVICE = "cuda"提示:
若上述部署中遇到问题,可关注我dy:dyga9uraeovh
相关文章:
轻松搭建本地知识库的ChatGLM2-6B
近期发现了一个项目,它的前身是ChatGLM,在我之前的博客中有关于ChatGLM的部署过程,本项目在前者基础上进行了优化,可以基于当前主流的LLM模型和庞大的知识库,实现本地部署自己的ChatGPT,并可结合自己的知识…...

flink的物理DataFlow图及Slot处理槽任务分配
背景 在flink中,有几个比较重要的概念,逻辑DataFlow图,物理DataFlow图以及处理槽执行任务,本文就来讲解下这几个概念 概念详解 假设有以下代码:数据源和统计单词算子的并行度是2,数据汇算子的并行度是1&…...

与面试相关的redis
这里写自定义目录标题 📝 redis的知识点数据结构及其特性,用途和操作方法持久化高可用分布式锁发布订阅性能优化安全性数据分片缓存策略键过期删除策略内存淘汰策略 🤗 总结归纳📎 参考文章 😀 这里写文章的前言&#…...

MapStruct从0到0.5
MapStruct从0到0.5 开发的过程,经常会用到实体类属性映射,同时为了方便,开发者也很少自己写专门的属性赋值工具类。索性会直接使用Sprrng提供的BeanUtils工具类,然后在性能上和字段属性赋值上的问题,一直是为开发者所…...
STM32H750 HAL CUBEMX 时钟失败及死机无法下载问题解决
芯片采样电压设置,否则 无法运行 解决死机问题 设置swd 模式 短接 boot0 —vcc 3.3v即可正常下载...

paddlespeech on centos7
概述 paddlespeech是百度飞桨平台的开源工具包,主要用于语音和音频的分析处理,其中包含多个可选模型,提供语音识别、语音合成、说话人验证、关键词识别、音频分类和语音翻译等功能。 paddlespeech整体是比较简单易用的,但是安装…...

ROM是什么? 刷ROM是什么意思?
文章目录 ROM是什么?刷ROM是什么意思 ROM是什么? ROM是只读内存(Read-Only Memory)的简称,是一种只能读出事先所存数据的固态半导体存储器。其特性是一旦储存资料就无法再将之改变或删除。通常用在不需经常变更资料的…...
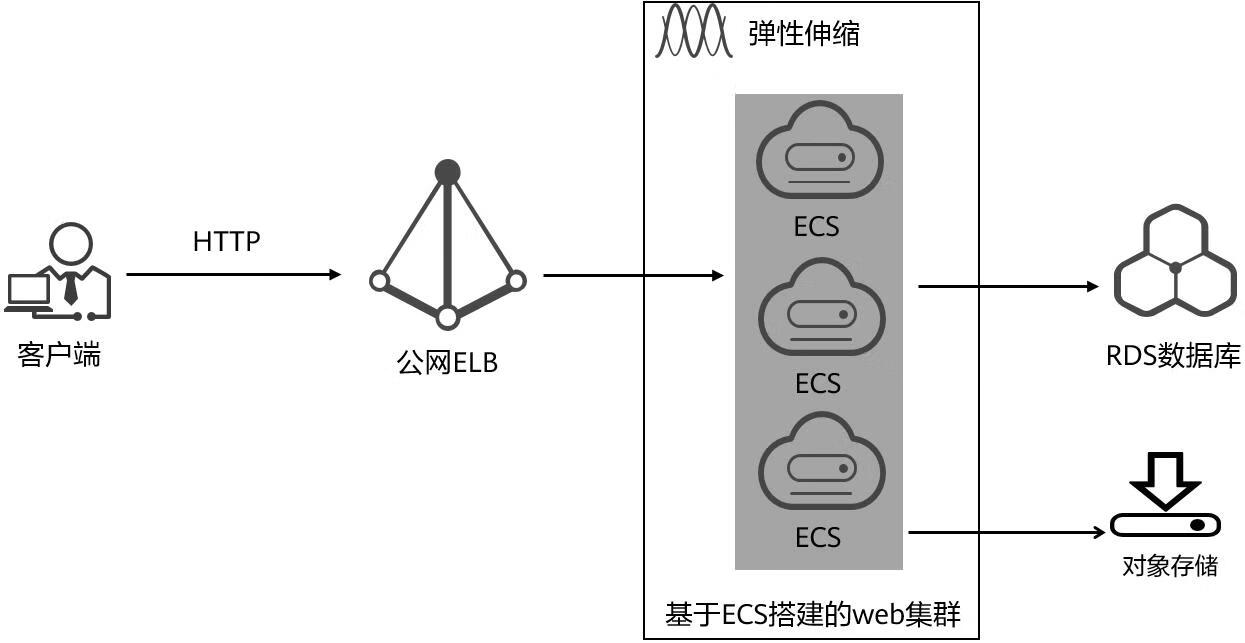
华为云Stack的学习(五)
六、华为云stack服务简介 1.云服务在华为云Stack中的位置 云服务对接多个数据中心资源池层提供的资源,并向各种行业应用提供载体。 2.华为云Stack通用服务 2.1 云计算的服务模式 2.2 计算相关的云服务 2.3 存储相关的云服务 2.4 网络相关的云服务 3.云化案例 **…...

【LeetCode-中等题】904. 水果成篮
文章目录 题目方法一:滑动窗口方法二: 题目 题目的意思就是:找至多包含两种元素的最长子串,返回其长度 方法一:滑动窗口 class Solution { // 滑动窗口 找至多包含两种元素的最长子串,返回其长度public …...
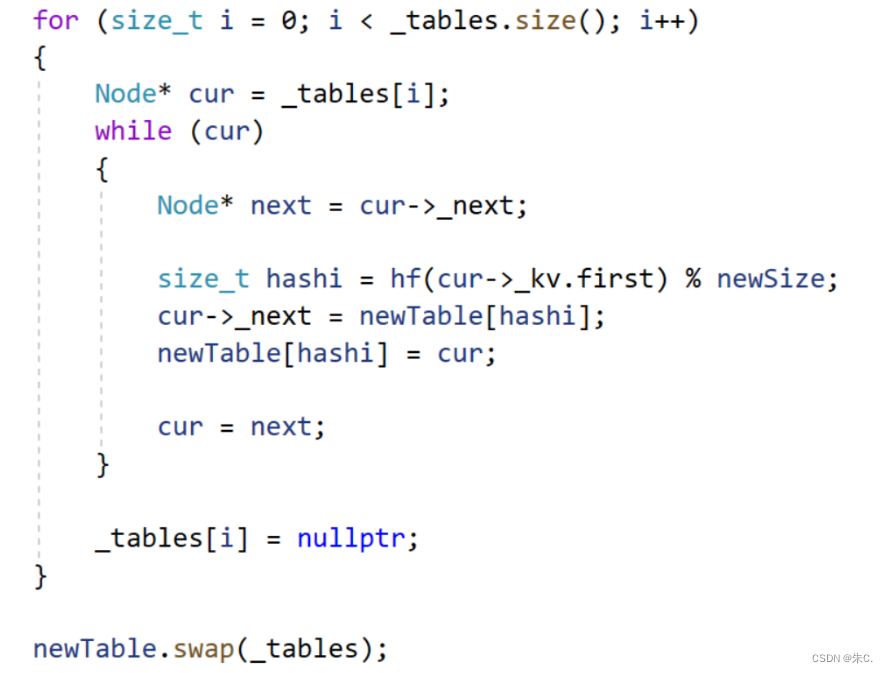
【C++】哈希——哈希的概念,应用以及闭散列和哈希桶的模拟实现
前言: 前面我们一同学习了二叉搜索树,以及特殊版本的平衡二叉搜索树,这些容器让我们查找数据的效率提高到了O(log^2 N)。虽然效率提高了很多,但是有没有一种理想的方法使得我们能提高到O(1)呢?其实在C语言数据结构中&a…...

Kubernetes (K8s) 解读:微服务与容器编排的未来
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🐅🐾猫头虎建议程序员必备技术栈一览表📖: 🛠️ 全栈技术 Full Stack: 📚…...
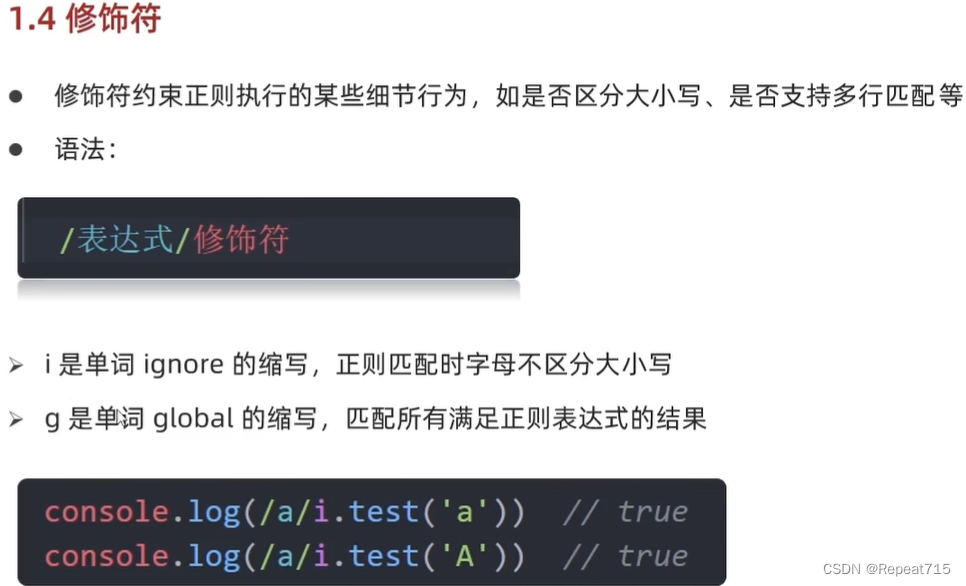
JavaScript学习--Day04
元字符 边界符: /^/:以什么开头 /$/:以什么结尾 量词: 预定义类:...
)
HCS 基本概念(三)
一、定义 HCS采用FusionSphere OpenStack作为云平台,对各个物理数据中心资源做整合,采用ManageOne作为数据中心管理软件对多个数据中心提供统一管理,通过云平台和数据中心管理软件协同运作,达到多数据中心融合、提升企业整体IT效率…...
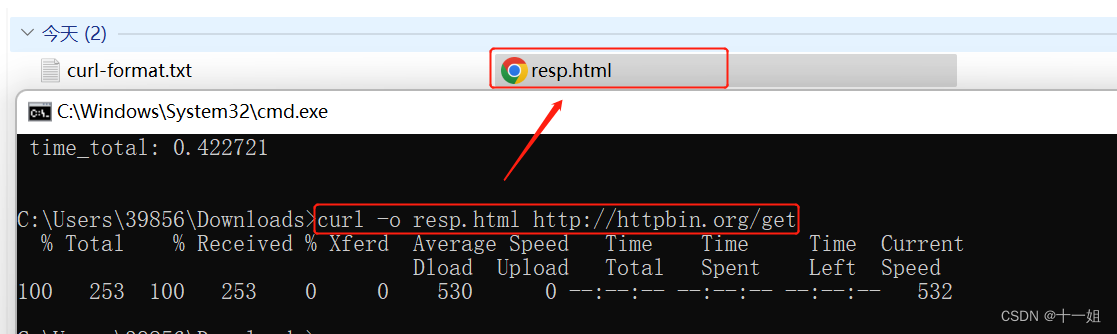
通过curl命令分析http接口请求各阶段的耗时等
目录 一、介绍二、功能1、-v 输出请求 响应头状态码 响应文本等信息2、-x 测试代理ip是否能在该网站使用3、-w 额外输出查看接口请求响应的消耗时间4、-o 将响应结果存储到文件里面5、-X post请求测试 (没测成功用的不多) 一、介绍 Curl是一个用于发送和接收请求的命令行工具和…...

Linux工具——gcc
目录 一,gcc简介 二,C语言源文件的编译过程 1.预处理 2.编译 3.汇编 4.链接 5.动静态库 一,gcc简介 相信有不少的小白和我一样在学习Linux之前只听说过visual studio。其实这个gcc这个编译器实现的功能便是和visual studio一样的功能&…...

uni-app 使用uCharts-进行图表展示(折线图带单位)
前言 在uni-app经常是需要进行数据展示,针对这个情况也是有人开发好了第三方包,来兼容不同平台展示 uCharts和pc端的Echarts使用差不多,甚至会感觉在uni-app使用uCharts更轻便,更舒服 但是这个第三方包有优点就会有缺点…...
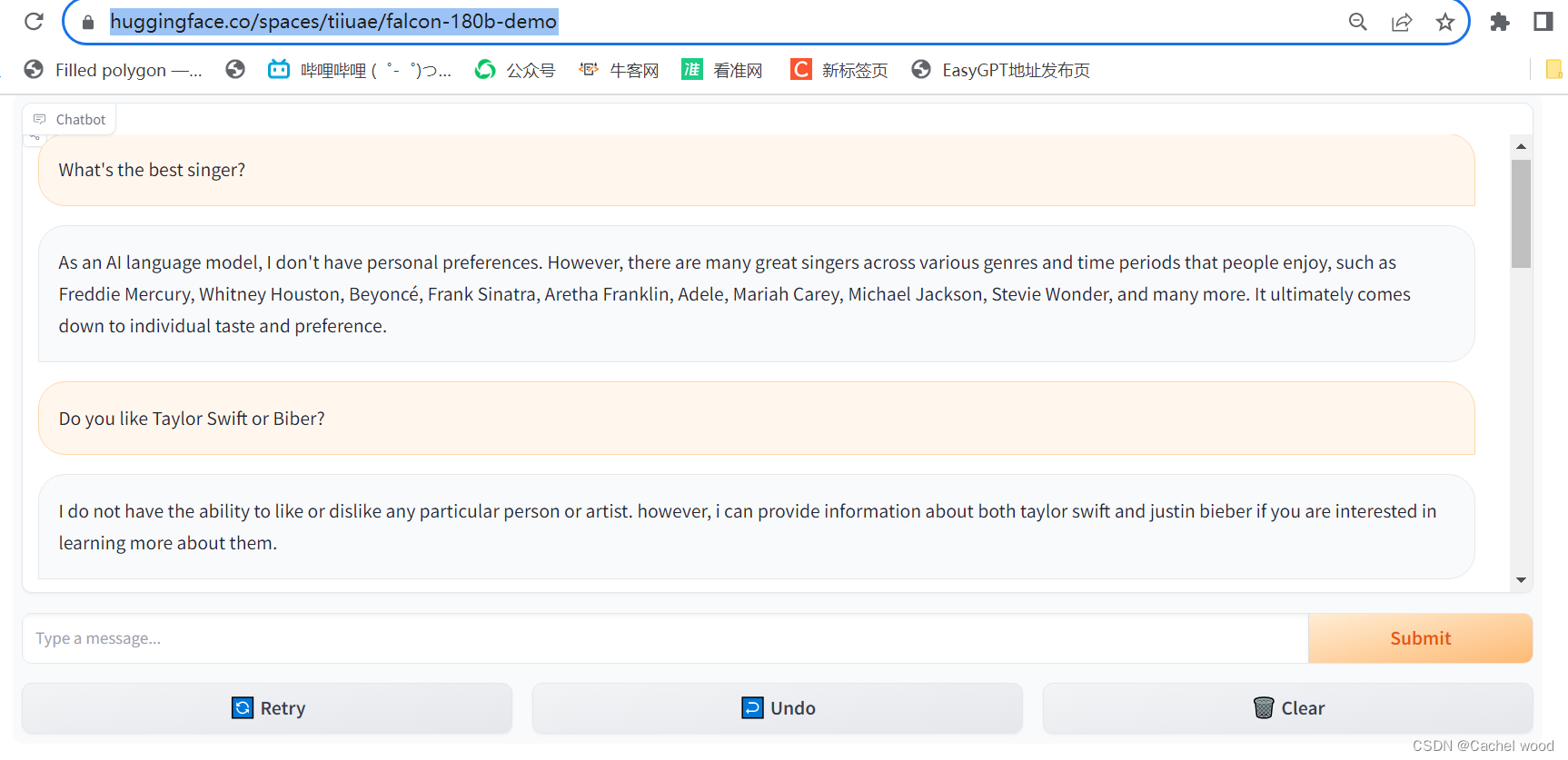
180B参数的Falcon登顶Hugging Face,vs chatGPT 最好开源大模型使用体验
文章目录 使用地址使用体验test1:简单喜好类问题test2:知识性问题test3:开放性问题test4:中文支持test5:问题时效性test6:学术问题使用地址 https://huggingface.co/spaces/tiiuae/falcon-180b-demo 使用体验 相比Falcon-7b,Falcon-180b拥有1800亿的参数量...
服务器数据恢复-EMC存储磁盘损坏的RAID5数据恢复案例
服务器数据恢复环境: 北京某单位有一台EMC某型号存储,有一组由10块STAT硬盘组建的RAID5阵列,另外2块磁盘作为热备盘使用。RAID5阵列上层只划分了一个LUN,分配给SUN小机使用,上层文件系统为ZFS。 服务器故障࿱…...

Nginx优化文件上传大小限制
Nginx默认配置 Nginx 默认情况下,上传文件的大小为1M,超过1M就会返回413错误。只用对Nginx进行简单配置即可解决问题。 优化Nginx文件上传大小限制 可以在Nginx配置文件中配置 client_max_body_size 配置项。 设置客户端请求正文允许的最大大小。如果…...
navicat SSH连接数据库报错: Putty key format too new
问题 下载 Putty 0.79 生成了密钥,但是在navicat 15 使用SSH通道连接数据库报错: Putty key format too new 错误原因和处理 原来是因为生成的私钥格式是 V3 , navicat 15 只能识别 V2 所以,在 PuTTYgen Load 私钥,重新保存为 …...

如何快速上手MuseTalk:从零开始的实时高质量唇语同步完整指南
如何快速上手MuseTalk:从零开始的实时高质量唇语同步完整指南 【免费下载链接】MuseTalk MuseTalk: Real-Time High Quality Lip Synchorization with Latent Space Inpainting 项目地址: https://gitcode.com/gh_mirrors/mu/MuseTalk 想要为静态人物图像添加…...

科技晚报|2026年5月15日:AI 代理开始补协作、编排和护栏
科技晚报|2026年5月15日:AI 代理开始补协作、编排和护栏 一句话导读:今晚更值得看的,不是哪家模型榜单又变了,而是几家平台同时在补 AI 代理真正进生产前最缺的三块能力:跨 IDE 共享状态、团队级可观测&…...

MoneyPrinterTurbo终极指南:5步实现AI短视频自动化创作
MoneyPrinterTurbo终极指南:5步实现AI短视频自动化创作 【免费下载链接】MoneyPrinterTurbo 利用AI大模型,一键生成高清短视频 Generate short videos with one click using AI LLM. 项目地址: https://gitcode.com/GitHub_Trending/mo/MoneyPrinterTu…...

第11章:C++ PGO与LTO优化
第11章:C++ PGO与LTO优化 本章定位:第四卷《实战卷》第三篇"性能优化"第 11 章。 在第 10 章"找热点"和第 11 章"改代码"之后,本章讨论"什么也不改、只调编译选项"能再榨出 5%-30% 的性能:LTO 让编译器看到全程序,PGO 让它看到运…...

nRF52840开发板移植CircuitPython实战:从编译到蓝牙应用
1. 项目概述与核心价值 如果你手头有一块基于 Nordic nRF52840 芯片的开发板,比如官方的 nRF52840-DK 或者 Particle 的 Argon/Xenon,并且厌倦了在 C 语言和复杂的 SDK 中挣扎,想用 Python 的简洁语法快速实现一个蓝牙传感器节点或者物联网设…...

Nooploop TOFSense激光测距模块:从快速上手指南到多平台实战应用
1. Nooploop TOFSense激光测距模块初体验 第一次拿到TOFSense激光测距模块时,我完全被它的小巧体积震惊了。这个比火柴盒大不了多少的装置,居然能实现0.1-12米的精确测距,精度高达1cm!作为一名经常在无人机项目中折腾的嵌入式工程…...

AI IDE CLI:为AI编程助手打造的轻量级本地开发环境
1. 项目概述:一个为AI时代量身定制的本地开发环境CLI工具如果你是一名开发者,最近肯定没少和各类AI编程助手打交道。无论是GitHub Copilot、Cursor,还是各种本地部署的大模型,它们正在深刻地改变我们写代码的方式。但随之而来的一…...

小微团队如何利用 Taotoken 统一管理多个 AI 模型密钥与用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 小微团队如何利用 Taotoken 统一管理多个 AI 模型密钥与用量 对于小型开发或产品团队而言,在项目开发中集成多个大语言…...

终极指南:如何用DroidCam OBS插件将手机变成专业直播摄像头
终极指南:如何用DroidCam OBS插件将手机变成专业直播摄像头 【免费下载链接】droidcam-obs-plugin DroidCam OBS Source 项目地址: https://gitcode.com/gh_mirrors/dr/droidcam-obs-plugin 想要将手机摄像头变成OBS直播的高清视频源吗?DroidCam …...

别再死记硬背了!Vivado伪双口RAM的wea、ena信号到底怎么用?一个实例讲透
Vivado伪双口RAM控制信号实战指南:从原理到避坑 第一次接触Vivado的伪双口RAM时,那些密密麻麻的控制信号确实让人头疼。尤其是wea和ena这两个看似简单却暗藏玄机的信号,稍不注意就会导致数据读取异常或者意外覆盖。记得去年我在一个图像处理项…...