【数据结构与算法】十大经典排序算法
文章目录
- 前言
- 一、常见十大排序算法总结
- 1、名词解释
- 2、时间复杂度
- 二、排序算法与C语言实现
- 1、冒泡排序
- 2、选择排序
- 3、插入排序
- 4、希尔排序
- 5、归并排序
- 6、快速排序
- 7、堆排序
- 8、计数排序
- 9、桶排序
- 10、基数排序
- 总结
前言
排序算法是《数据结构与算法》中最基本的算法之一。
排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。常见的排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、技术排序等。
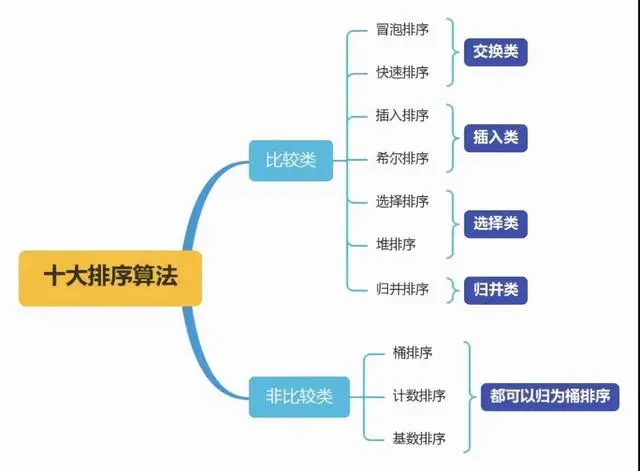
一、常见十大排序算法总结
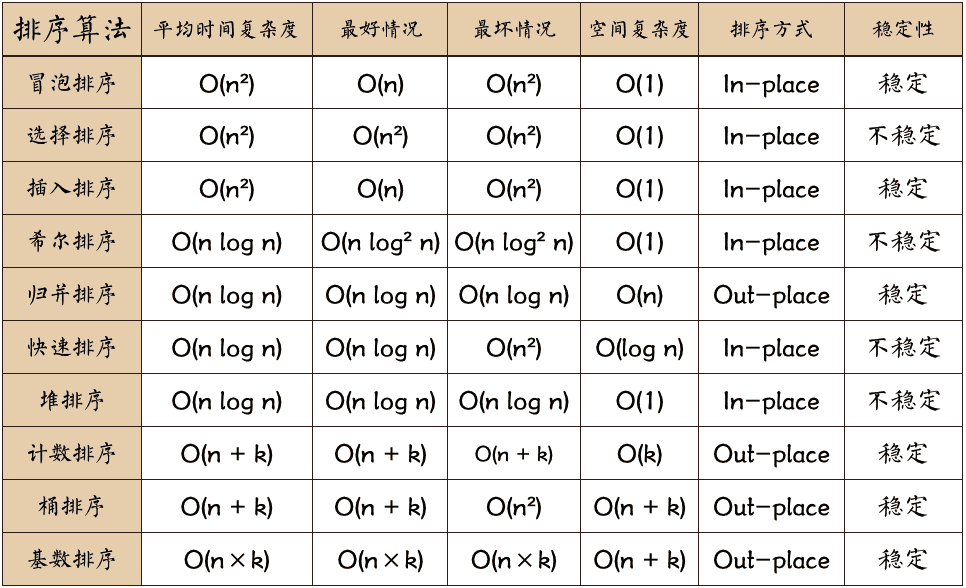
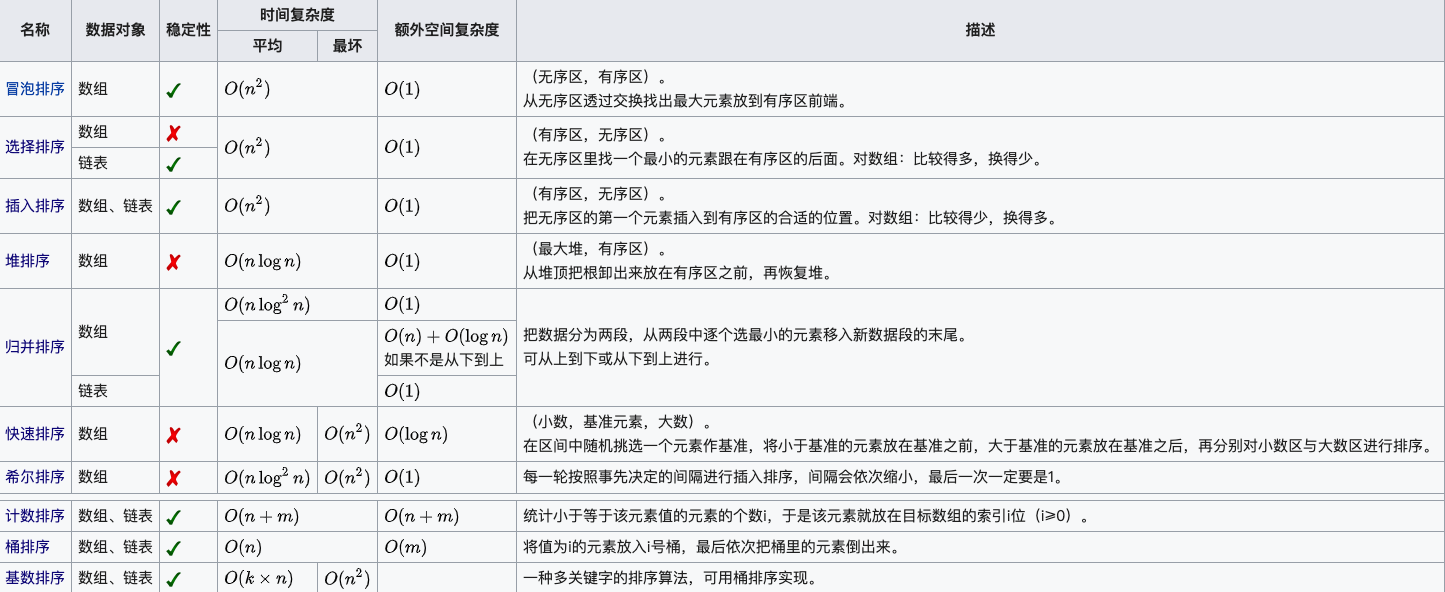
以下为常见的排序算法冒泡排序、选择排序、插入排序、希尔排序、归并排序、快速排序、堆排序、计数排序、桶排序、基数排序的平均时间复杂度、最好情况下的时间复杂度、最坏情况下的时间复杂度、空间复杂度、排序方式、稳定性的汇总。
1、名词解释
- n:数据规模
- k:“桶”的个数
- In-Place:占用常数内存,不占用额外内存
- Out-Place:占用额外内存
- 稳定性:排序后2个相等键值的顺序和排序之前他们的顺序相同
稳定的排序算法有:冒泡排序、插入排序、归并排序和基数排序。
不稳定的排序算法有:选择排序、快速排序、希尔排序、堆排序。
点击以下图片查看大图:
2、时间复杂度
-平方阶O(n2):各类简单排序,直接插入、直接选择、冒泡排序;
- 线性对数阶O(nlog2n):快速排序、归并排序、堆排序;
- O(n1+ζ):ζ是介于0和1之间的常数,希尔排序;
- 线性阶O(n):基数排序、桶排序、箱排序;
二、排序算法与C语言实现
1、冒泡排序
冒泡排序(Bubble Sort)是一种简单直观的排序算法。两两对比,大的总是排在后,然后继续与后面的数对比,直到最大的数排在最后,然后再最后排好的数之前的数列中继续重复该过程,直到所有的数都排好。
-
算法步骤
比较相邻的元素,如果第一个比第二个大,就交换将大的排在后面。
对每对相邻元素进行同样的比较,最后的元素会是最大的数。
针对所有元素进行相同处理,直到第一个数是最小的数。 -
动图演示

-
什么时候最快
当输入的数据已经有序时。 -
什么时候最慢
当输入的数据是反序时,需要移动交换所有步骤。 -
C语言实现冒泡排序
#include <stdio.h>
void bubble_sort(int arr[], int len) {int i, j, temp;for (i = 0; i < len - 1; i++)for (j = 0; j < len - 1 - i; j++)if (arr[j] > arr[j + 1]) {temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}
}
int main() {int arr[] = { 22, 34, 3, 32, 82, 55, 89, 50, 37, 5, 64, 35, 9, 70 };int len = sizeof(arr) / sizeof(arr[0]);bubble_sort(arr, len);int i;for (i = 0; i < len; i++)printf("%d ", arr[i]);return 0;
}
2、选择排序
选择排序是一种简单直观的排序算法,无论什么数据进去都是O(n2)的时间复杂度。所以用到它的时候,数据规模越小越好。
- 算法步骤
首先选择在未排序的序列中找到最小(大)元素,存放到排列序列的起始位置。
再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
重复第二步,直到所有元素均排序完毕。
-
动图演示

-
C语言实现选择排序
void swap(int *a,int *b) //交換兩個變數
{int temp = *a;*a = *b;*b = temp;
}
void selection_sort(int arr[], int len)
{int i,j;for (i = 0 ; i < len - 1 ; i++) {int min = i;for (j = i + 1; j < len; j++) //走訪未排序的元素if (arr[j] < arr[min]) //找到目前最小值min = j; //紀錄最小值swap(&arr[min], &arr[i]); //做交換}
}
3、插入排序
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了,因为只要打过扑克牌的人都应该能够秒懂。插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,相对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
- 算法步骤
将待排序序列的第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
从头到尾扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面)
- 动图演示

- C语言实现
void insertion_sort(int arr[], int len){int i,j,key;for (i=1;i<len;i++){key = arr[i];j=i-1;while((j>=0) && (arr[j]>key)) {arr[j+1] = arr[j];j--;}arr[j+1] = key;}
}
4、希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出的改进方法:
- 插入排序在对几乎已经排好的数据操作时,效率高,即可以达到线性排序的效率;
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干个序列分别进行直接插入排序(根据步长交换),待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
- 算法步骤
以序列: {8, 9, 1, 7, 2, 3, 5, 6, 4, 0} 为例!
1.初始步长gap = length/2 = 5,意味着将整个数组分为了5组,即[8,3],[9,5],[1,6],[7,4],[2,0],对每组进行插入排序,得到序列:{3,5,1,4,0,8,9,6,7,2},可以看到:3,5,4,0这些小元素都被提到前面了。
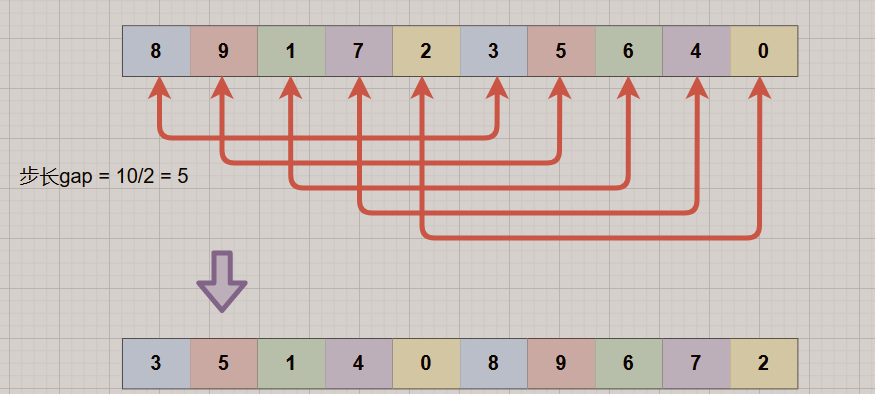
2.缩小增量gap = 5/2 = 2,数组被分为两组,即[3,1,0,9,7],[5,4,8,6,2],对这两组分别进行直接插入排序,可以看到,整个数组的有序程度更进一步了。
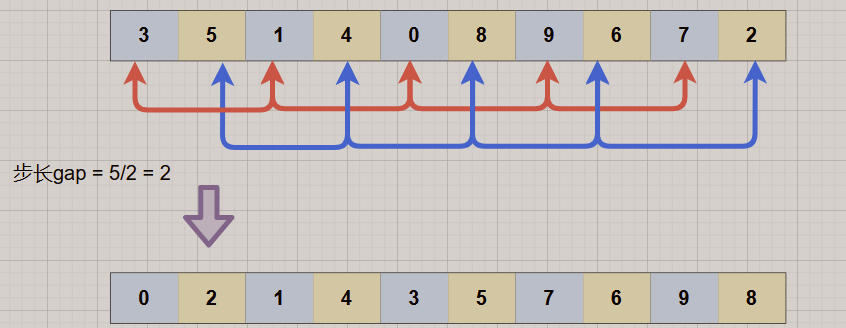
3.再次缩小增量,gap = 2/2 = 1,此时整个数组为[0,2,1,4,3,5,7,6,9,8],进行一次插入排序,即可实现数组的有序化(仅需要简单微调,而无需大量移动操作)。

- java语言实现
import java.util.Arrays;/*** @author 兴趣使然黄小黄* @version 1.0* 希尔排序*/
public class ShellSort {public static void main(String[] args) {int[] arr = {8, 9, 1, 7, 2, 3, 5, 6, 4, 0};System.out.println("排序前: " + Arrays.toString(arr));shellSort(arr);System.out.println("排序后: " + Arrays.toString(arr));}//希尔排序public static void shellSort(int[] arr){//设定步长for (int gap = arr.length / 2; gap > 0; gap /= 2){//将数据分为arr.length/gap组,逐个对其所在的组进行插入排序for (int i = gap; i < arr.length; i++) {//遍历各组中的所有元素,步长为gapint j = i;int temp = arr[j]; //记录待插入的值while (j - gap >= 0 && temp < arr[j-gap]){//移动arr[j] = arr[j-gap];j -= gap;}//找到位置,进行插入arr[j] = temp;}System.out.println(Arrays.toString(arr));}}
}5、归并排序
归并排序(Merge Sort)是建立在归并操作上的一种有效,稳定的排序算法,该算法是采用 分治法(Divide and Conquer) 的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
-
算法步骤
Step1——确定分界点mid(三种常用的方法):q[l]、q[(l+r)/2]、q[r],或者随机确定;
Step2——将待排序列调整成 left 和 right 两个子序列,递归排序 left 和 right ;
Step3——归并(合二为一),Finish! -
演示
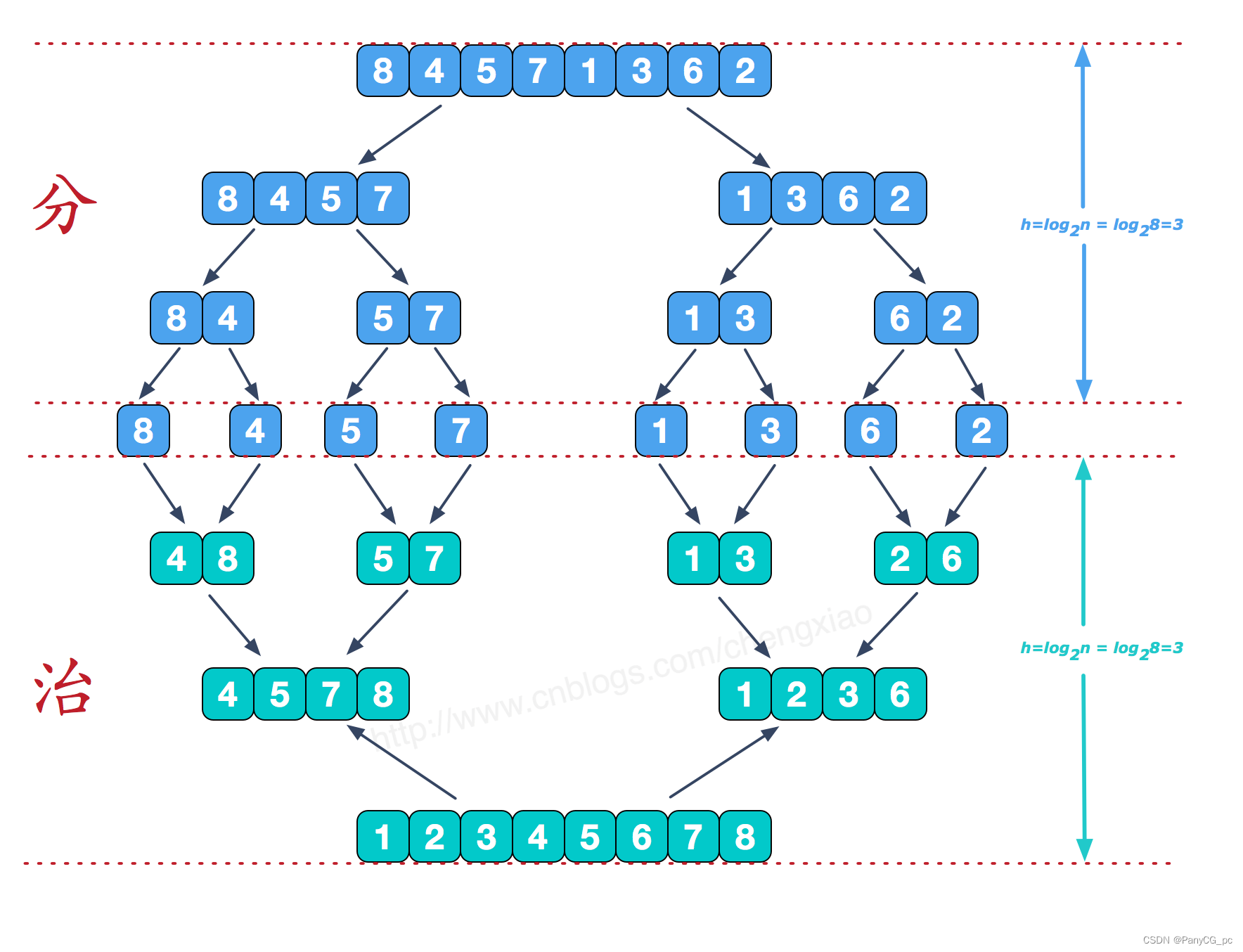

-
C实现
int min(int x, int y) {return x < y ? x : y;
}
void merge_sort(int arr[], int len) {int *a = arr;int *b = (int *) malloc(len * sizeof(int));int seg, start;for (seg = 1; seg < len; seg += seg) {for (start = 0; start < len; start += seg * 2) {int low = start, mid = min(start + seg, len), high = min(start + seg * 2, len);int k = low;int start1 = low, end1 = mid;int start2 = mid, end2 = high;while (start1 < end1 && start2 < end2)b[k++] = a[start1] < a[start2] ? a[start1++] : a[start2++];while (start1 < end1)b[k++] = a[start1++];while (start2 < end2)b[k++] = a[start2++];}int *temp = a;a = b;b = temp;}if (a != arr) {int i;for (i = 0; i < len; i++)b[i] = a[i];b = a;}free(b);
}
6、快速排序
快速排序(Quick Sort)是对冒泡排序的一种改进。由C. A. R. Hoare在1962年提出,其基本思想是选取一个记录作为枢轴,经过一趟排序,将整段序列分为两个部分,其中一部分的值都小于枢轴,另一部分都大于枢轴。然后继续对这两部分继续进行排序,从而使整个序列达到有序。
- 算法步骤
- 1.基本思想:
例如对于一个待排序的源数组arr = { 4,1,3,2,7,6,8}。

我们可以随便选一个元素,假如我们选数组的第一个元素吧,我们把这个元素称之为“主元”吧。
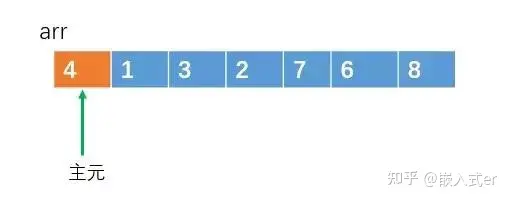
然后将大于或等于主元的元素放在右边,把小于或等于主元的元素放在左边。
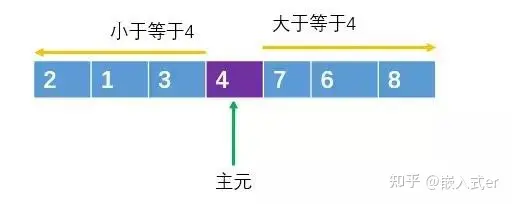
通过这种规则的调整之后,左边的元素都小于或等于主元,右边的元素都大于或等于主元,很显然,此时主元所处的位置,是一个有序的位置,即主元已经处于排好序的位置了。
主元把数组分成了两半部分。把一个大的数组通过主元分割成两小部分的这个操作,我们也称之为分割操作(partition)。
接下来,我们通过递归的方式,对左右两部分采取同样的方式,每次选取一个主元元素,使他处于有序的位置。当然是递归到子数组只有一个元素或者0个元素了,递归结束。

代码:quick_sort 是快速排序的算法,partion函数是对于数组的分割操作,分割操作有很多种方法。
快速排序分割操作有多种方法,这里列举的最基本的一种。
-
动图演示

-
C语言实现选择排序
void QuickSort(int array[], int low, int high) {int i = low; int j = high;if(i >= j) {return;}int temp = array[low];while(i != j) {while(array[j] >= temp && i < j) {j--;}while(array[i] <= temp && i < j) {i++;}if(i < j) {swap(array[i], array[j]);}}//将基准temp放于自己的位置,(第i个位置)swap(array[low], array[i]);QuickSort(array, low, i - 1);QuickSort(array, i + 1, high);
}
7、堆排序
堆排序(Heapsort)是指利用堆这种数据结构设计的一种排序算法,堆积一个近似完全二叉树的结构,并同时满足堆积的性质:子节点的键值或索引总是小于(或者大于)它的父节点。
分为两种方法:
大顶堆:父节点大于等于子节点,属于升序算法;
小顶堆:父节点小于等于子节点,属于降序算法;
堆排序平均时间复杂度为O(nlogn)
堆一般用来在大量数据中找到前N大或者前N小的数据。
大顶堆:从大到小为降序(Desc)12…
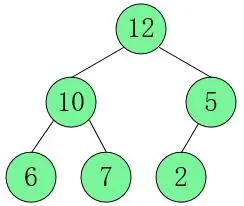
小顶堆:从小到大为升序(Asc)2…
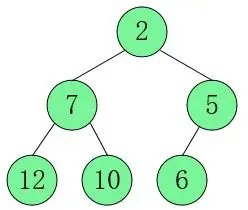
- 算法步骤
构建大顶堆:
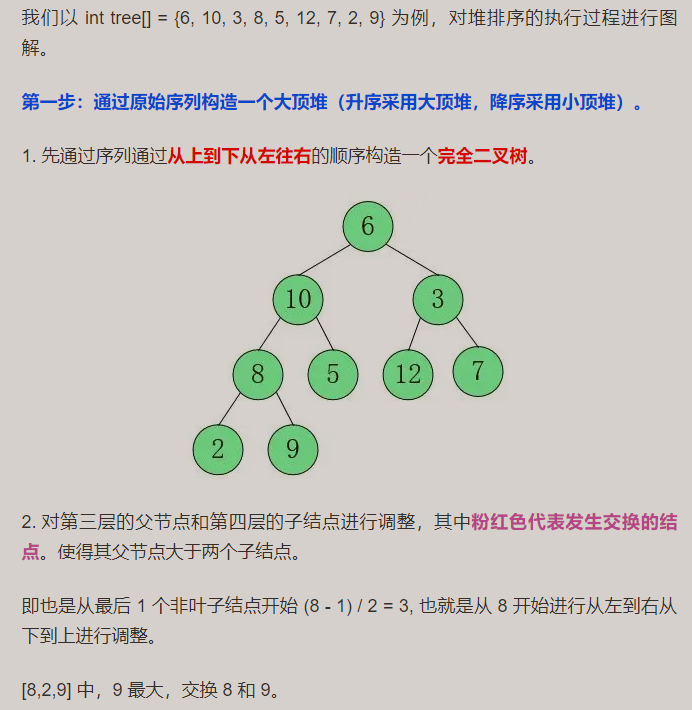
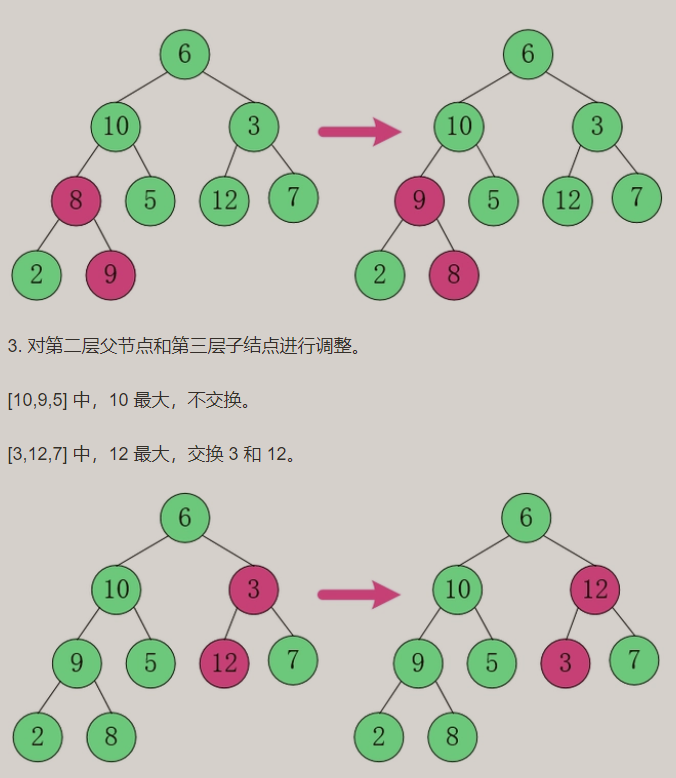
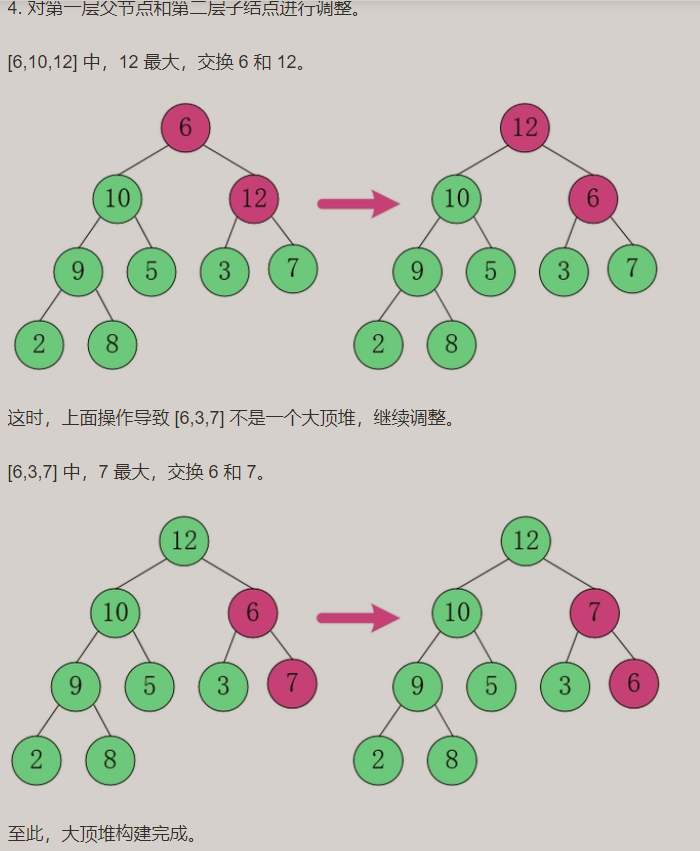
构建小顶堆:
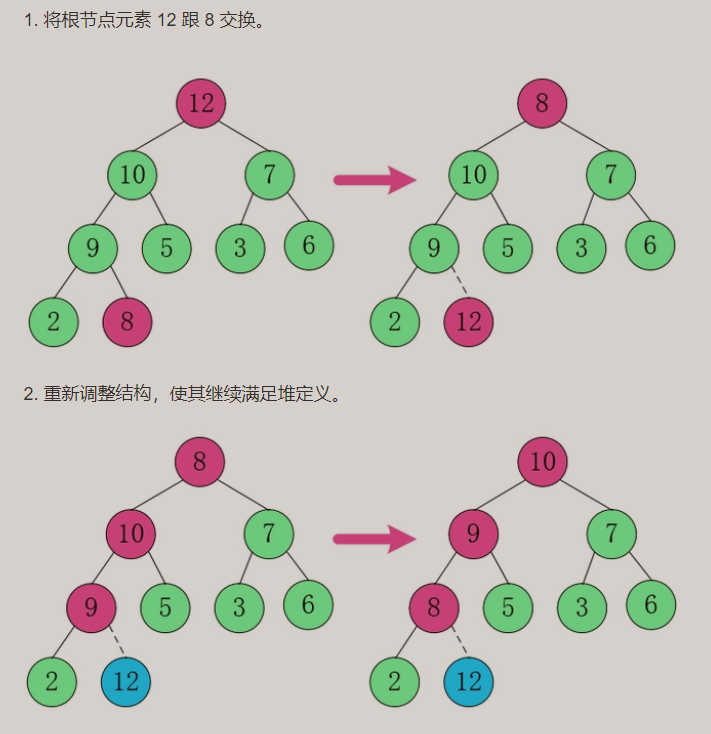
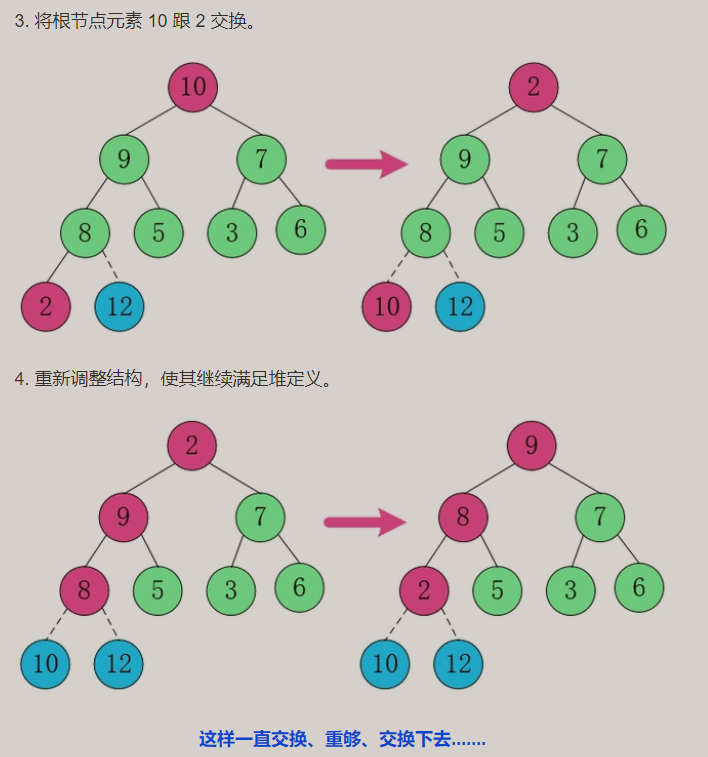
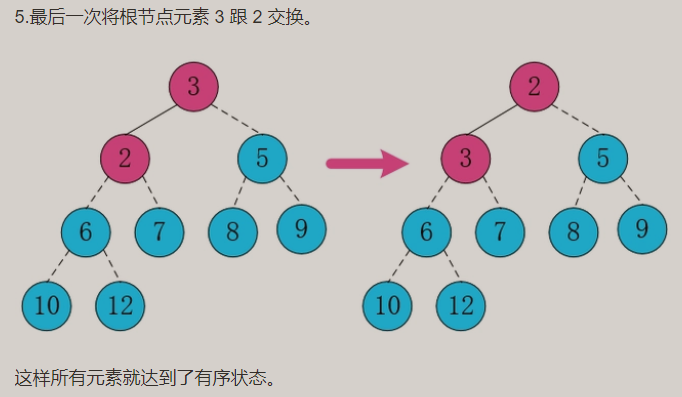
- 动图演示


- C语言实现选择排序
大顶堆代码:
#include <stdio.h>void swap(int arr[], int i, int j){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}void heapify(int tree[], int n, int i){
if (i >= n){
return;
}int c1 = 2 * i + 1;
int c2 = 2 * i + 2;
int max = i;
if (c1 < n && tree[c1] > tree[max]){
max = c1;
}
if (c2 < n && tree[c2] > tree[max]){
max = c2;
}
if (max != i){
swap(tree, max ,i);
heapify(tree, n, max);
}
}void build_heap(int tree[], int n){
int last_node = n - 1;
int parent = (last_node - 1) / 2;
for (int i = parent; i >= 0; i--){
heapify(tree, n, i);
}
}void heap_sort(int tree[], int n){
build_heap(tree, n);
for (int i = n - 1; i >= 0; i--){
swap(tree, i, 0);
heapify(tree, i, 0);
}
}int main(){
int tree[] = {6, 10, 3, 9, 5, 12, 7, 2, 8};
int n = 9;build_heap(tree, 9);
// heap_sort(tree, 9);for(int i = 0; i < n; i++){
printf("%d\n",tree[i]);
}
return 0;
}
大顶堆结果:从大到小结果为降序(Desc)
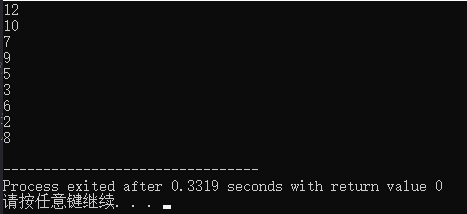
小顶堆代码:
#include <stdio.h>void swap(int arr[], int i, int j){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}void heapify(int tree[], int n, int i){
if (i >= n){
return;
}int c1 = 2 * i + 1;
int c2 = 2 * i + 2;
int max = i;
if (c1 < n && tree[c1] > tree[max]){
max = c1;
}
if (c2 < n && tree[c2] > tree[max]){
max = c2;
}
if (max != i){
swap(tree, max ,i);
heapify(tree, n, max);
}
}void build_heap(int tree[], int n){
int last_node = n - 1;
int parent = (last_node - 1) / 2;
for (int i = parent; i >= 0; i--){
heapify(tree, n, i);
}
}void heap_sort(int tree[], int n){
build_heap(tree, n);
for (int i = n - 1; i >= 0; i--){
swap(tree, i, 0);
heapify(tree, i, 0);
}
}int main(){
int tree[] = {6, 10, 3, 9, 5, 12, 7, 2, 8};
int n = 9;// build_heap(tree, 9);
heap_sort(tree, 9);for(int i = 0; i < n; i++){
printf("%d\n",tree[i]);
}
return 0;
}
小顶堆结果:从小到大为升序(Asc)
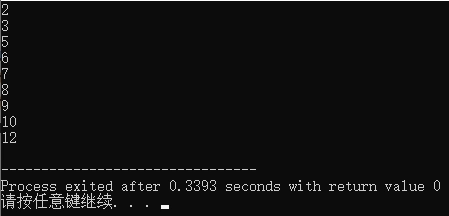
8、计数排序
计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
- 计数排序的特征
当输入的元素是 n 个 0 到 k 之间的整数时,它的运行时间是 Θ(n + k)。计数排序不是比较排序,排序的速度快于任何比较排序算法。
由于用来计数的数组C的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上1),这使得计数排序对于数据范围很大的数组,需要大量时间和内存。例如:计数排序是用来排序0到100之间的数字的最好的算法,但是它不适合按字母顺序排序人名。但是,计数排序可以用在基数排序中的算法来排序数据范围很大的数组。
通俗地理解,例如有 10 个年龄不同的人,统计出有 8 个人的年龄比 A 小,那 A 的年龄就排在第 9 位,用这个方法可以得到其他每个人的位置,也就排好了序。当然,年龄有重复时需要特殊处理(保证稳定性),这就是为什么最后要反向填充目标数组,以及将每个数字的统计减去 1 的原因。
-
算法步骤
(1)找出待排序的数组中最大和最小的元素
(2)统计数组中每个值为i的元素出现的次数,存入数组C的第i项
(3)对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
(4)反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1 -
动图演示

-
C语言实现选择排序
#include <stdio.h>
#include <stdlib.h>
#include <time.h>void print_arr(int *arr, int n) {int i;printf("%d", arr[0]);for (i = 1; i < n; i++)printf(" %d", arr[i]);printf("\n");
}void counting_sort(int *ini_arr, int *sorted_arr, int n) {int *count_arr = (int *) malloc(sizeof(int) * 100);int i, j, k;for (k = 0; k < 100; k++)count_arr[k] = 0;for (i = 0; i < n; i++)count_arr[ini_arr[i]]++;for (k = 1; k < 100; k++)count_arr[k] += count_arr[k - 1];for (j = n; j > 0; j--)sorted_arr[--count_arr[ini_arr[j - 1]]] = ini_arr[j - 1];free(count_arr);
}int main(int argc, char **argv) {int n = 10;int i;int *arr = (int *) malloc(sizeof(int) * n);int *sorted_arr = (int *) malloc(sizeof(int) * n);srand(time(0));for (i = 0; i < n; i++)arr[i] = rand() % 100;printf("ini_array: ");print_arr(arr, n);counting_sort(arr, sorted_arr, n);printf("sorted_array: ");print_arr(sorted_arr, n);free(arr);free(sorted_arr);return 0;
}
9、桶排序

- C++语言实现选择排序
#include<iterator>
#include<iostream>
#include<vector>
using namespace std;
const int BUCKET_NUM = 10;struct ListNode{explicit ListNode(int i=0):mData(i),mNext(NULL){}ListNode* mNext;int mData;
};ListNode* insert(ListNode* head,int val){ListNode dummyNode;ListNode *newNode = new ListNode(val);ListNode *pre,*curr;dummyNode.mNext = head;pre = &dummyNode;curr = head;while(NULL!=curr && curr->mData<=val){pre = curr;curr = curr->mNext;}newNode->mNext = curr;pre->mNext = newNode;return dummyNode.mNext;
}ListNode* Merge(ListNode *head1,ListNode *head2){ListNode dummyNode;ListNode *dummy = &dummyNode;while(NULL!=head1 && NULL!=head2){if(head1->mData <= head2->mData){dummy->mNext = head1;head1 = head1->mNext;}else{dummy->mNext = head2;head2 = head2->mNext;}dummy = dummy->mNext;}if(NULL!=head1) dummy->mNext = head1;if(NULL!=head2) dummy->mNext = head2;return dummyNode.mNext;
}void BucketSort(int n,int arr[]){vector<ListNode*> buckets(BUCKET_NUM,(ListNode*)(0));for(int i=0;i<n;++i){int index = arr[i]/BUCKET_NUM;ListNode *head = buckets.at(index);buckets.at(index) = insert(head,arr[i]);}ListNode *head = buckets.at(0);for(int i=1;i<BUCKET_NUM;++i){head = Merge(head,buckets.at(i));}for(int i=0;i<n;++i){arr[i] = head->mData;head = head->mNext;}
}
10、基数排序

- LSD 基数排序动图演示

- C语言实现选择排序
#include<stdio.h>
#define MAX 20
//#define SHOWPASS
#define BASE 10void print(int *a, int n) {int i;for (i = 0; i < n; i++) {printf("%d\t", a[i]);}
}void radixsort(int *a, int n) {int i, b[MAX], m = a[0], exp = 1;for (i = 1; i < n; i++) {if (a[i] > m) {m = a[i];}}while (m / exp > 0) {int bucket[BASE] = { 0 };for (i = 0; i < n; i++) {bucket[(a[i] / exp) % BASE]++;}for (i = 1; i < BASE; i++) {bucket[i] += bucket[i - 1];}for (i = n - 1; i >= 0; i--) {b[--bucket[(a[i] / exp) % BASE]] = a[i];}for (i = 0; i < n; i++) {a[i] = b[i];}exp *= BASE;#ifdef SHOWPASSprintf("\nPASS : ");print(a, n);
#endif}
}int main() {int arr[MAX];int i, n;printf("Enter total elements (n <= %d) : ", MAX);scanf("%d", &n);n = n < MAX ? n : MAX;printf("Enter %d Elements : ", n);for (i = 0; i < n; i++) {scanf("%d", &arr[i]);}printf("\nARRAY : ");print(&arr[0], n);radixsort(&arr[0], n);printf("\nSORTED : ");print(&arr[0], n);printf("\n");return 0;
}
总结
相关文章:
【数据结构与算法】十大经典排序算法
文章目录 前言一、常见十大排序算法总结1、名词解释2、时间复杂度 二、排序算法与C语言实现1、冒泡排序2、选择排序3、插入排序4、希尔排序5、归并排序6、快速排序7、堆排序8、计数排序9、桶排序10、基数排序 总结 前言 排序算法是《数据结构与算法》中最基本的算法之一。 排序…...
Android 12.0 SystemUI下拉状态栏定制化之隐藏下拉通知栏布局功能实现(一)
1.前言 在12.0的系统定制化开发中,由于从12.0开始SystemUI下拉状态栏和11.0的变化比较大,所以可以说需要从新分析相关的SystemUI的 布局,然后做分析来实现不同的功能,今天就开始实现关于隐藏SystemUI下拉状态栏中的通知栏布局系列一 如图: 2.SystemUI下拉状态栏定制化之…...

665. 非递减数列-先改后验法
665. 非递减数列 给你一个长度为 n 的整数数组 nums ,请你判断在 最多 改变 1 个元素的情况下,该数组能否变成一个非递减数列。 我们是这样定义一个非递减数列的: 对于数组中任意的 i (0 < i < n-2),总满足 nums[i] < …...
调教 文心一言 生成 AI绘画 提示词(Midjourney)
文章目录 第一步第二步第三步第四步第五步第六步第七步第八步 文心一言支持连续对话 我瞎玩的非专业哈哈 第一步 你好,今天我们要用扩散模型创建图像。我会给你提供一些信息。行吗? 第二步 这是Midjourney的工作原理:Midjourney是另一个基于ai的工具,能…...
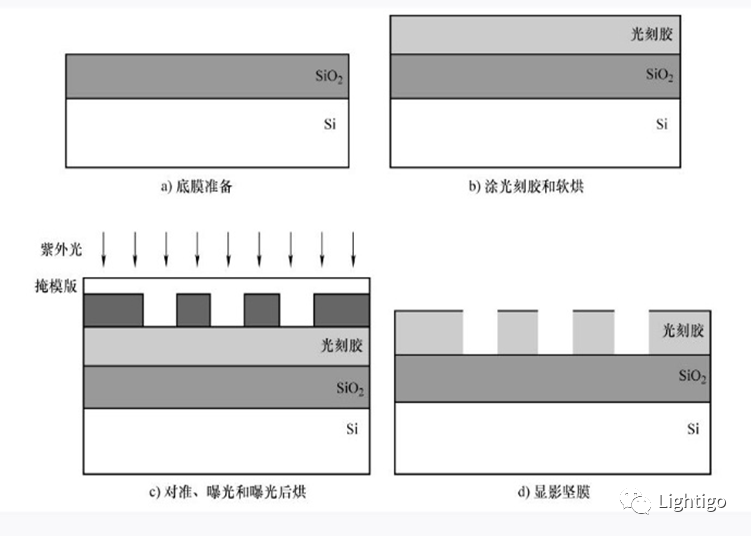
半导体制造工艺(一)光刻
在这里开个新专题,主要详细描述半导体制造整个流程中所用到的设备工艺步骤。 在集成电路制造工艺中,光刻是决定集成器件集成度的核心工序,该工序的作用是将图形信息从掩模版(也称掩膜版)上保真传输、转印到半导体材料衬…...

【海思SS626 | 开发环境】VMware17安装Ubuntu 18.04.6
目录 一、下载 Ubuntu 18.04.6 LTS二、VMware17创建虚拟机三、安装Ubuntu18.04LTS四、安装其他软件五、总结 一、下载 Ubuntu 18.04.6 LTS 问题:为什么要下载 Ubuntu18.04.6 LTS 而不是使用最新的,或者其他Linux发行版? 答:在ss6…...
每天10个小知识点)
Vue知识系列(3)每天10个小知识点
目录 系列文章目录Vue知识系列(1)每天10个小知识点Vue知识系列(2)每天10个小知识点 知识点**21. Vue不同生命周期**的概念、作用、原理、特性、优点、缺点、区别、使用场景**22. Vue 子组件和父组件执行顺序****23. created 和 mo…...

Java基础入门·多线程·线程池ThreadPool篇
前言 特点分析 线程池ThreadPool 销毁线程池 Executor类 Callable接口 线程池使用 …...

Trinitycore学习之在vscode查看远端服务器上源码配置
1:安装vscode,去官网下载,这里下载windows版本安装包 .zip https://code.visualstudio.com/Download 2:安装后,安装扩展chinese,使用中文设置,需要重启vscode。 3:安装ssh相关插件…...

583. 两个字符串的删除操作 -- 动规
583. 两个字符串的删除操作 class MinDistance:"""583. 两个字符串的删除操作https://leetcode.cn/problems/delete-operation-for-two-strings/description/"""def solution(self, text1: str, text2: str) -> int:"""这道题…...
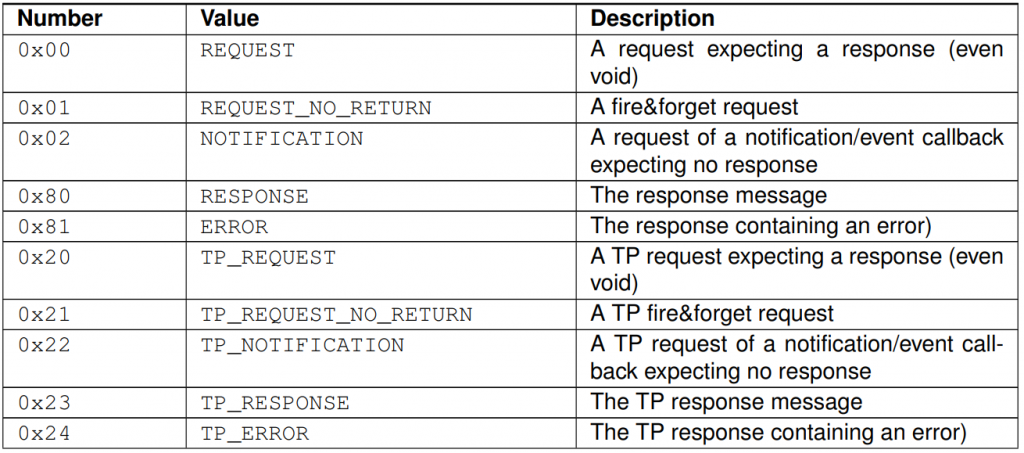
SOME/IP
介绍 SOME/IP是一种汽车中间件解决方案,可用于控制消息。它从一开始就被设计为完美地适应不同尺寸和不同操作系统的设备。这包括小型设备,如相机、AUTOSAR 设备,以及头戴设备或远程通信设备。它还确保SOME/IP支持信息娱乐域以及车辆中其他域…...

[2023.09.12]: Yew应用开发的第一个hook--use_state
Yew的SSR模式推荐使用function_component组件,并且在function_component中使用hooks。其中,我使用到的第一个hook是use_state。use_state的设计意图与React中的useState非常相似,都是为了保存并修改当前的状态。然而,由于Yew是用R…...

使用Langchain+GPT+向量数据库chromadb 来创建文档对话机器人
使用LangchainGPT向量数据库chromadb 来创建文档对话机器人 一.效果图如下: 二.安装包 pip install langchainpip install chromadbpip install unstructuredpip install jieba三.代码如下 #!/usr/bin/python # -*- coding: UTF-8 -*-import os # 导入os模块&…...
系列教程(一) 服务注册与发现(eureka))
Spring Cloud(Finchley版本)系列教程(一) 服务注册与发现(eureka)
Spring Cloud(Finchley版本)系列教程(一) 服务注册与发现(eureka) 为了更好的浏览体验,欢迎光顾勤奋的凯尔森同学个人博客http://www.huerpu.cc:7000 如有错误恳请大家批评指正,与大家共同学习、一起成长,万分感谢。 一、构建环境 Spring Cloud的构建工具可以使用Maven或Gr…...

【大数据】美团 DB 数据同步到数据仓库的架构与实践
美团 DB 数据同步到数据仓库的架构与实践 1.背景2.整体架构3.Binlog 实时采集4.离线还原 MySQL 数据5.Kafka2Hive6.对 Camus 的二次开发7.Checkdone 的检测逻辑8.Merge9.Merge 流程举例10.实践一:分库分表的支持11.实践二:删除事件的支持12.总结与展望 1…...
分类预测 | MATLAB实现WOA-CNN-BiGRU鲸鱼算法优化卷积双向门控循环单元数据分类预测
分类预测 | MATLAB实现WOA-CNN-BiGRU鲸鱼算法优化卷积双向门控循环单元数据分类预测 目录 分类预测 | MATLAB实现WOA-CNN-BiGRU鲸鱼算法优化卷积双向门控循环单元数据分类预测分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.Matlab实现WOA-CNN-BiGRU多特征分类…...
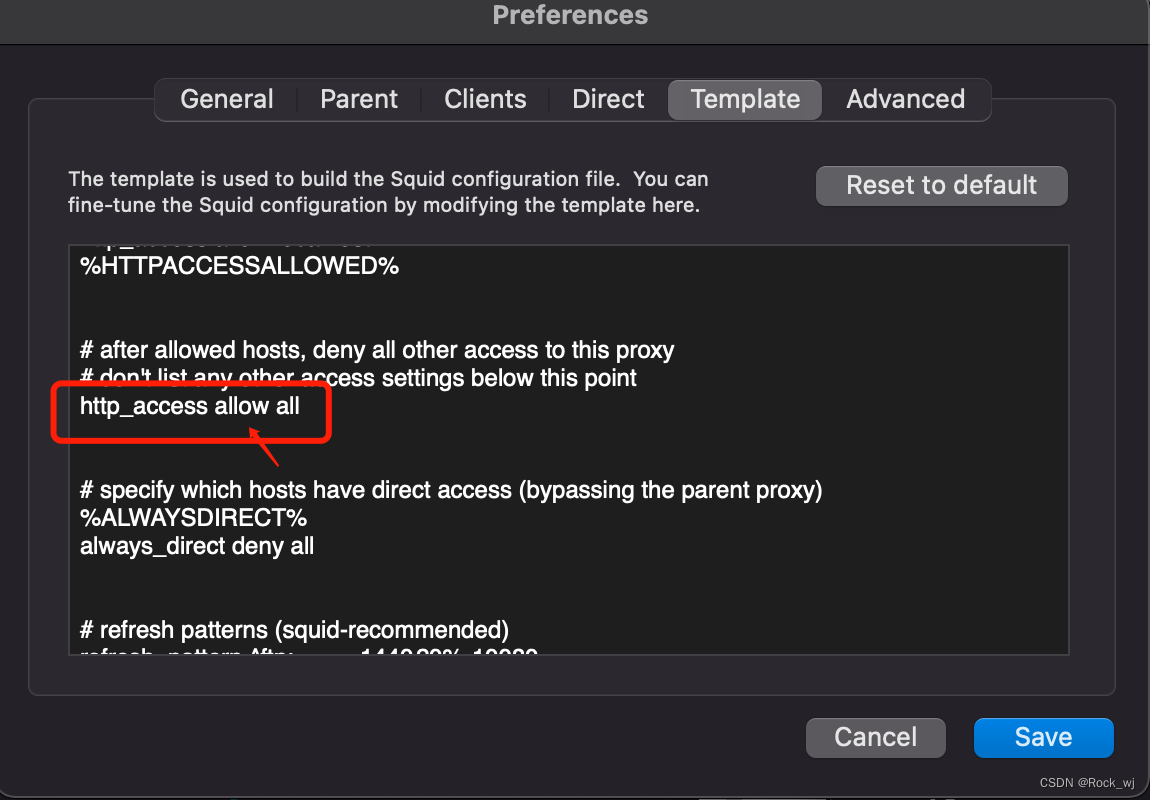
mac使用squidMan设置代理服务器
1,下载squidMan http://squidman.net/squidman/ 2, 配置SquidMan->Preference 3, mac命令窗口配置 export http_proxy export https_porxy 4,客户端配置(centos虚拟机) export http_proxyhttp://服务器ip:8080 export https…...

大数据Flink(七十八):SQL 的水印操作(Watermark)
文章目录 SQL 的水印操作(Watermark) 一、为什么要有 WaterMark...
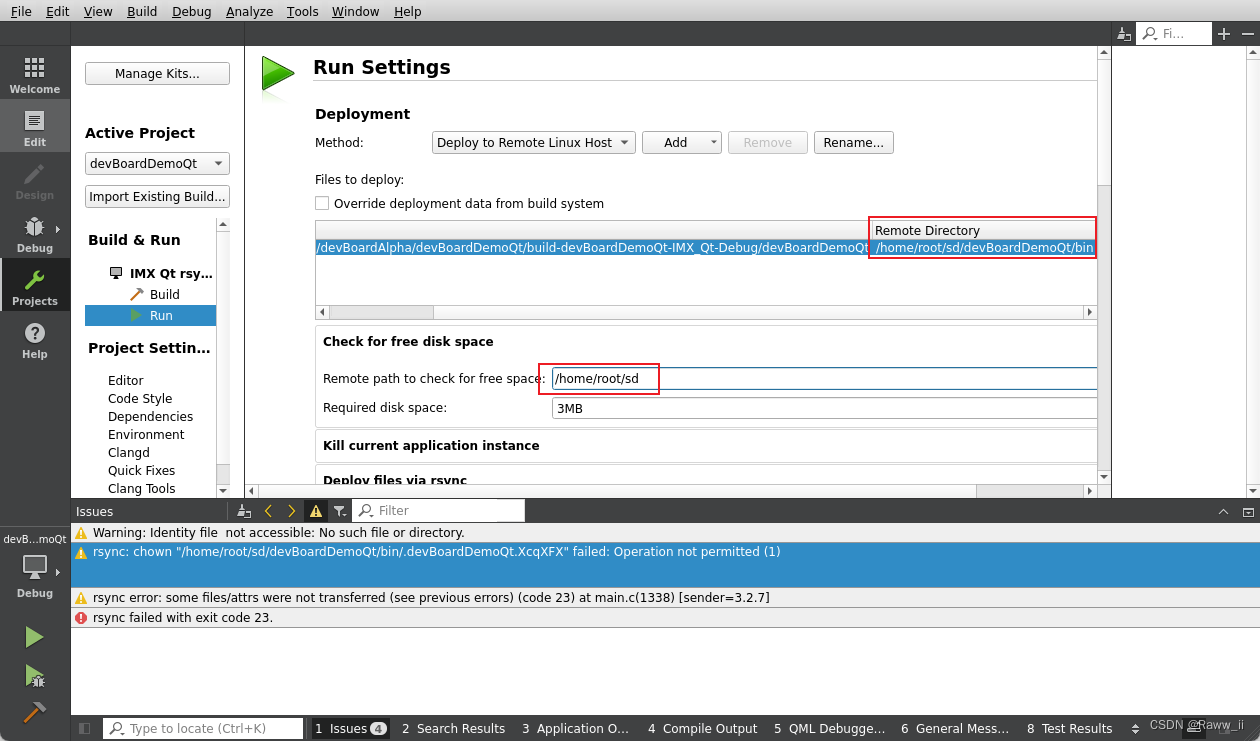
【Linux】Qt Remote之Remote开发环境搭建填坑小记
总体思路 基于WSL2(Ubuntu 22.04 LTS)原子Alpha开发板进行Qt开发实验,基于Win11通过vscode remote到WSL2,再基于WSL2通过Qt 交叉编译,并通过sshrsync远程到开发板,构建起开发工具链。 Step1 基于Win11通过…...

ATFX汇市:离岸人民币大幅升值,昨日盘中跌破7.3关口
ATFX汇市:美国CPI数据即将公布之际,周一美元指数大跌,带动离岸人民币升值0.85%,实现3月14日以来的最大单日升值幅度,当日汇率(USDCNH)最低触及7.292,突破7.3000关口。消息面上&#…...

Enzyme协议:DeFi资产管理智能合约架构与实战指南
1. 项目概述:当智能合约遇上资产管理如果你在区块链领域,特别是DeFi(去中心化金融)生态里待过一段时间,大概率听说过“Enzyme”这个名字。它不是一个新概念,但绝对是DeFi乐高积木中一块承重墙级别的组件。简…...
换个角度思考【牛客tracker 每日一题】
换个角度思考 时间限制:1秒 空间限制:256M 知识点:线段树 网页链接 牛客tracker 牛客tracker & 每日一题,完成每日打卡,即可获得牛币。获得相应数量的牛币,能在【牛币兑换中心】,换取相…...

算法将驱动一切:边缘AI智能体如何重塑智能系统
仓库装卸区的安全摄像头每天采集86400秒的视频数据。长途卡车上的车队远程信息记录仪在两次加油之间积累了数GB的行车影像。外科手术机器人的立体摄像头以每秒60帧的速度生成密集点云。所有这些数据都产生于数字世界与现实世界的交界处,但几乎没有任何一条被用于智能…...

libhv实战:300行构建C++异步RPC框架,集成Protobuf与evpp
1. 为什么需要C异步RPC框架 在微服务架构盛行的今天,服务间的通信效率直接决定了系统整体性能。传统同步RPC调用就像打电话,必须等对方接听才能开始对话,而异步RPC更像是发微信,发完消息就可以去做其他事情,等对方回复…...

Docker 的了解和使用
1. 虚拟化全虚拟化:虚拟机的操作系统可以和宿主机的操作系统完全不同。os层虚拟化:操作内核相同,软件虚拟化。2. docker安装 Docker容器本质上是Linux容器,它需要Linux内核环境才能运行。在Windows上直接运行Docker,需…...

Windows系统级课堂管理软件反控制技术实现:JiYuTrainer内核驱动与API拦截架构解析
Windows系统级课堂管理软件反控制技术实现:JiYuTrainer内核驱动与API拦截架构解析 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 在现代化教育信息化环境中ÿ…...

ASML如何用“先买单后上菜”模式改写半导体设备研发规则
1. 从“被放鸽子”到“先买单后上菜”:ASML的450毫米晶圆博弈论在半导体这个以“摩尔定律”为信仰的行业里,每一次技术节点的跃进都伴随着天文数字的投入和巨大的商业风险。对于设备商而言,最怕的不是技术难题,而是倾尽所有研发出…...

高海拔环境下的硬件设计挑战与GPS定位故障分析
1. 从数据记录到真实体验:高海拔环境下的技术挑战作为一名电子工程师,我习惯了在实验室里与精密的仪器和数据打交道,一切都在可控范围内。但当你带着自己设计的设备,踏上非洲之巅乞力马扎罗的征途时,现实会给你上一堂生…...
)
植物大战僵尸杂交版下载2026最新版更新v3.16及版本介绍分享(附下载链接)
作为一名长期沉迷植物大战僵尸改版的玩家,我近期完整体验了杂交版全新V3.16版本,从植物、关卡到平台适配,逐一实测验证。整体而言,这是一次诚意满满的更新,既有新鲜玩法的创新,又兼顾了不同玩家的需求&…...

ncmdumpGUI终极使用教程:轻松解密网易云音乐NCM文件
ncmdumpGUI终极使用教程:轻松解密网易云音乐NCM文件 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐下载的NCM格式文件无法在普通…...