【2023】数据挖掘课程设计:基于TF-IDF的文本分类
目录
一、课程设计题目
基于TF-IDF的文本分类
二、课程设计设置
1. 操作系统
2. IDE
3. python
4. 相关的库
三、课程设计目标
1. 掌握数据预处理的方法,对训练集数据进行预处理;
2. 掌握文本分类建模的方法,对语料库的文档进行建模;
3. 掌握分类算法的原理,基于有监督的机器学习方法,训练文本分类器。
四、课程设计内容
1. 数据采集和预处理
a. 数据采集
b. 数据清洗
c. 文本预处理:分词、去除停用词、移除低频词
2. 特征提取和文本向量模型构建
a. 词袋模型
b. TF-IDF(本次实验中选取该方法)
c. Word2Vec
3. 分类模型训练
a. 数据划分
b. 模型训练
c. 模型调参:网格搜索
d. 模型评估:计算准确率、精确率、召回率、F1值、混淆矩阵
五、实验结果分析
一、课程设计题目
基于TF-IDF的文本分类
二、课程设计设置
1. 操作系统
Windows 11 Home
2. IDE
PyCharm 2022.3.1 (Professional Edition)
3. python
3.6.0
4. 相关的库
| jieba | 0.42.1 |
| numpy | 1.13.1 |
| pandas | 0.24.0 |
| requests | 2.28.1 |
| scikit-learn | 0.19.0 |
| tqdm | 4.65.0 |
conda create -n DataMining python==3.6 pandas scikit-learn tqdm requests jieba三、课程设计目标
1. 掌握数据预处理的方法,对训练集数据进行预处理;
2. 掌握文本分类建模的方法,对语料库的文档进行建模;
3. 掌握分类算法的原理,基于有监督的机器学习方法,训练文本分类器。
四、课程设计内容
1. 数据采集和预处理
a. 数据采集
①数据来源:
GitHub - SophonPlus/ChineseNlpCorpus: 搜集、整理、发布 中文 自然语言处理 语料/数据集,与 有志之士 共同 促进 中文 自然语言处理 的 发展。搜集、整理、发布 中文 自然语言处理 语料/数据集,与 有志之士 共同 促进 中文 自然语言处理 的 发展。 - GitHub - SophonPlus/ChineseNlpCorpus: 搜集、整理、发布 中文 自然语言处理 语料/数据集,与 有志之士 共同 促进 中文 自然语言处理 的 发展。![]() https://github.com/SophonPlus/ChineseNlpCorpus
https://github.com/SophonPlus/ChineseNlpCorpus
②数据选择:
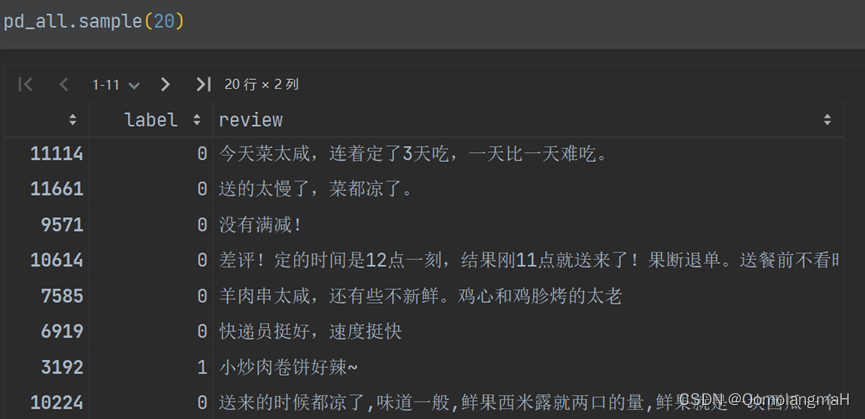
waimai_10k .csv为某外卖平台收集的用户评价,正向 4000 条,负向 约 8000 条,其中:
| 字段 | 说明 |
| label | 1 表示正向评论,0 表示负向评论 |
| review | 评论内容 |
b. 数据清洗
数据清洗是指去除数据中不需要的内容,例如空格、数字、特殊符号等。
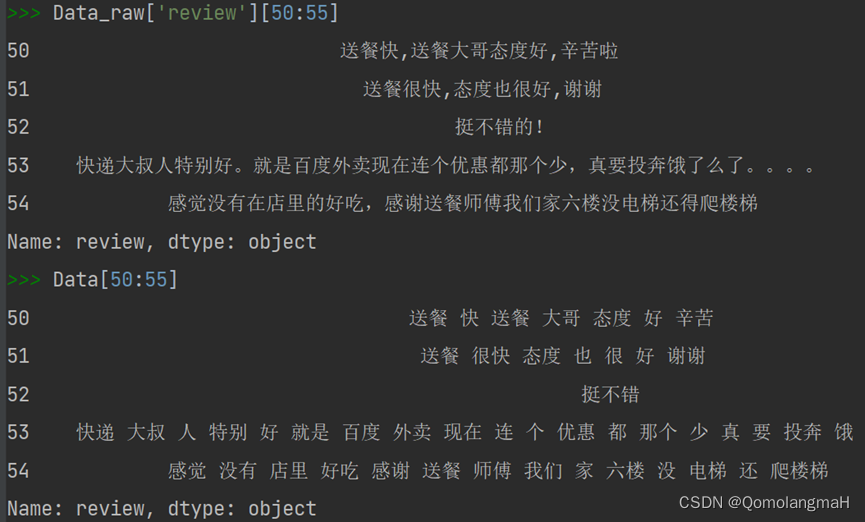
data = data.fillna('') # 用空字符串填充缺失值data = data.apply(lambda x: x.strip()) # 去除文本开头和结尾的空白字符data = data.apply(lambda x: x.replace('\n', ' ')) # 将换行符替换为空格data = data.apply(lambda x: re.sub('[0-9]', '', x)) # 去除数字data = data.apply(lambda x: re.sub("[^a-zA-Z\u4e00-\u9fff]", ' ', x)) # 去除非汉字和字母的非空白字符c. 文本预处理:分词、去除停用词、移除低频词
①文本分词
研究表明中文文本特征粒度为词粒度远远好于字粒度,目前常用的中文分词算法可分为三大类:基于词典的分词方法、基于理解的分词方法和基于统计的分词方法。
②去停用词
停用词(Stop Word)是一类 既普遍存在又不具有明显的意义的词,在中文中例如:"吧"、 "是"、 "的"、 "了"、"并且"、"因此"等。这些词的用处太普遍,去除这些词,对于文本分类来说没有什么不利影响,相反可能改善机器学习效果。
③移除低频词
低频词就是在数据中出现次数较少的词语。此类数据实际上是具有一定的信息量,但是把低频词放入模型当中运行时,它们常常保持他们的随机初始状态,给模型增加了噪声。
# 文本预处理data = data.apply(lambda x: ' '.join(jieba.cut(x))) # 使用jieba分词# 停用词列表stopwords = ["吧", "是", "的", "了", "啦", "得", "么", "在", "并且", "因此", "因为", "所以", "虽然", "但是"]data = data.apply(lambda x: ' '.join([i for i in x.split() if i not in stopwords])) # 去停用词# 移除低频词word_counts = Counter(' '.join(data).split())low_freq_words = [word for word, count in word_counts.items() if count < 3]data = data.apply(lambda x: ' '.join([word for word in x.split() if word not in low_freq_words]))④实验结果
2. 特征提取和文本向量模型构建
文本分类任务非常重要的一步就是特征提取,在文本数据集上一般含有数万甚至数十万个不同的词组,如此庞大的词组构成的向量规模惊人,计算机运算非常困难。特征提取就是要想办法选出那些最能表征文本含义的词组元素 ,不仅可以降低问题的规模,还有助于分类性能的改善。
特征选择的基本思路是根据某个 评价指标独立地对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。常用的评价有文档频率、互信息、信息增益、卡方统计量等。
a. 词袋模型
词袋模型是最原始的一类特征集,忽略掉了文本的语法和语序,用一组无序的单词序列来表达一段文字或者一个文档。就是把整个文档集的所有出现的词都丢进“袋子”里面,然后无序去重地排出来(去掉重复的)。对每一个文档,按照词语出现的次数来表示文档 。
b. TF-IDF(本次实验中选取该方法)
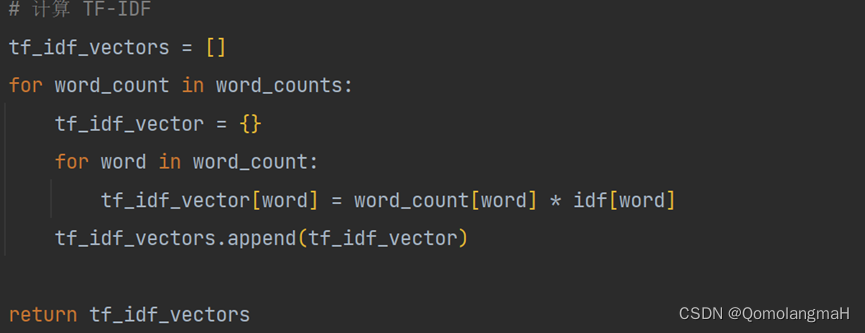
TF-IDF模型主要是用词汇的统计特征作为特征集,TF-IDF 由两部分组成:TF(Term frequency,词频),IDF(Inverse document frequency,逆文档频率)两部分组成,利用 TF 和 IDF 两个参数来表示词语在文本中的重要程度。

TF-IDF 方法的主要思路是一个词在当前类别的重要度与在当前类别内的词频成正比,与所有类别出现的次数成反比。可见 TF 和 IDF 一个关注文档内部的重要性,一个关注文档外部的重要性,最后结合两者,把 TF 和 IDF 两个值相乘就可以得到 TF-IDF 的值,即
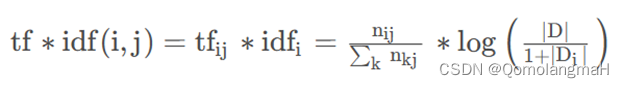
c. Word2Vec
Word2Vec是一种基于词向量的特征提取模型,该模型基于大量的文本语料库,通过类似神经网络模型训练,将每个词语映射成一个 定 维度的向量,维度在几十维到几百维之间,每个向量就代表着这个词语,词语的语义和语法相似性和通过向量之间的相似度来判断。
3. 分类模型训练
a. 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, Data_raw['label'],shuffle=True, test_size=0.3, random_state=j)b. 模型训练
model = KNeighborsClassifier()# model = svm.SVC()# model = MLPClassifier(hidden_layer_sizes=(100,), max_iter=500)# 训练模型model.fit(tfidf_train, y_train)# 测试模型y_pred = model.predict(test_selected)c. 模型调参:网格搜索
网格搜索就是先定义一个超参数的取值范围,然后对这些超参数的所有可能组合进行穷举搜索。以svm为例
def svm_grid(X_train, y_train):param_grid = [{# 'C':'kernel': ['linear', # 线性核函数'poly', # 多项式核函数'rbf', # 高斯核'sigmoid' # sigmod核函数# 'precomputed' # 核矩阵], # 核函数类型,'degree': np.arange(2, 5, 1), # int, 多项式核函数的阶数, 这个参数只对多项式核函数有用,默认为3# 'gamma': np.arange(1e-6, 1e-4, 1e-5) # float, 核函数系数,只对’rbf’ ,’poly’ ,’sigmod’有效, 默认为样本特征数的倒数,即1/n_features。# 'coef0' # float,核函数中的独立项, 只有对’poly’ 和,’sigmod’核函数有用, 是指其中的参数c。默认为0.0}]svc = svm.SVC(kernel='poly')# 网格搜索grid_search = GridSearchCV(svc,param_grid,cv=10,scoring="accuracy",return_train_score=True)grid_search.fit(X_train, y_train)# 最优模型参final_model = grid_search.best_estimator_return final_modeld. 模型评估:计算准确率、精确率、召回率、F1值、混淆矩阵
accuracy = metrics.accuracy_score(y_test, y_pred)precision = metrics.precision_score(y_test, y_pred)recall = metrics.recall_score(y_test, y_pred)f1 = metrics.f1_score(y_test, y_pred)confusion = metrics.confusion_matrix(y_test, y_pred)metric.append([accuracy, precision, recall, f1])- 多次训练求出平均值:
五、实验结果分析
请下载本实验对应的代码及实验报告资源(其中实验分析部分共2页、787字)
包括完整实验过程分析(文本预处理、建模、分类器训练、手写TF-IDF参数分析等),以及分类器性能评估等。
相关文章:
【2023】数据挖掘课程设计:基于TF-IDF的文本分类
目录 一、课程设计题目 基于TF-IDF的文本分类 二、课程设计设置 1. 操作系统 2. IDE 3. python 4. 相关的库 三、课程设计目标 1. 掌握数据预处理的方法,对训练集数据进行预处理; 2. 掌握文本分类建模的方法,对语料库的文档进行建模…...
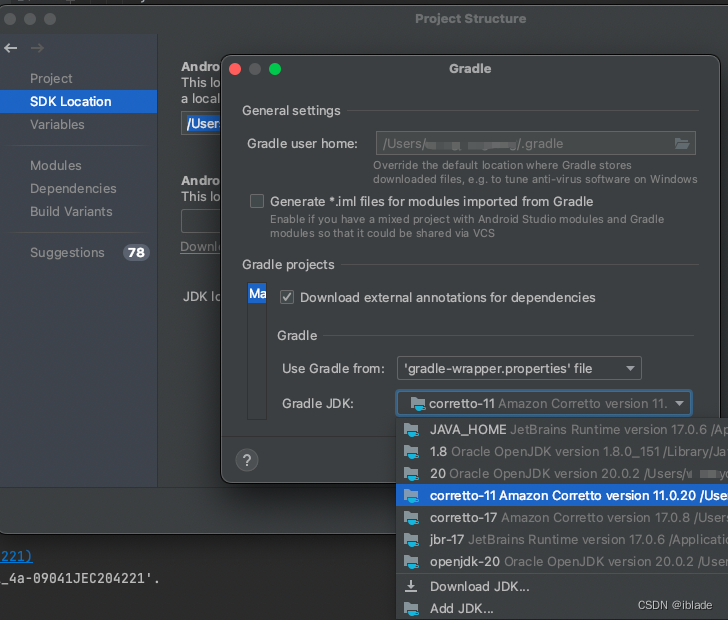
java.lang.NoSuchMethodError: java.lang.reflect.Field.trySetAccessible()Z
java.lang.NoSuchMethodError: java.lang.reflect.Field.trySetAccessible()Z 将JDK升级为11即可。 File --Project Structure – SDK Location --Gradle Setting --Gradle JDK 选择11...

如何使用SQL系列 之 如何在MySQL中使用存储过程
引言 通常,当使用关系型数据库时,你直接在应用程序代码中发出单独的结构化查询语言(SQL)查询来检索或操作数据,如SELECT、INSERT、UPDATE或DELETE。这些语句直接作用于并操作底层数据库表。如果相同的语句或一组语句中使用多个应用程序访问同…...

用 Github Codespaces 免费搭建本地开发测试环境
如何丝滑地白嫖一个本地开发环境?怎么新建一个代码空间? 1:通过Github网页新建2:通过VSCode插件新建 为代码创建相应的开发测试环境 如何丝滑地白嫖一个本地开发环境? 使用Codespaces为开发者解决这样的痛点…...
PyTorch实战-实现神经网络图像分类基础Tensor最全操作详解(一)
目录 前言 一、PyTorch数据结构-Tensor 1.什么是Tensor 2.数据Tensor使用场景 3.张量形态 标量(0D 张量) 向量(1D 张量) 矩阵(2D张量) 3D 张量与高维张量 二、Tensor的创建 1. 从列表或NumPy数组创建 2. 使用特定的初始…...
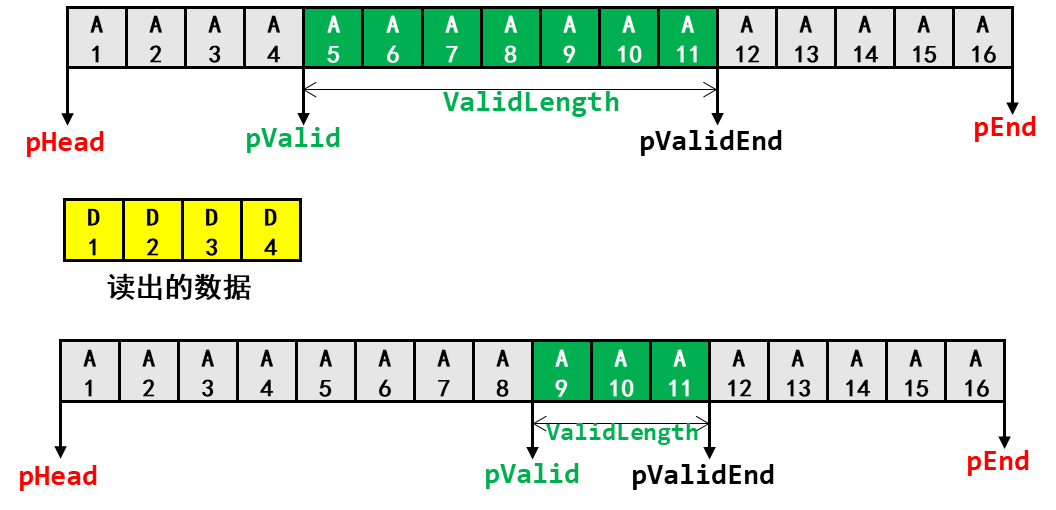
第29章_瑞萨MCU零基础入门系列教程之改进型环形缓冲区
本教程基于韦东山百问网出的 DShanMCU-RA6M5开发板 进行编写,需要的同学可以在这里获取: https://item.taobao.com/item.htm?id728461040949 配套资料获取:https://renesas-docs.100ask.net 瑞萨MCU零基础入门系列教程汇总: ht…...
)
如何搭建一个react项目(详细介绍)
要搭建一个基本的 React 项目,你需要执行以下步骤。在开始之前,请确保你已经安装了 Node.js 和 npm(Node 包管理器)。 搭建一个React项目 1,创建项目目录2,初始化项目3,安装 React 和 ReactDOM4…...

ActiveMQ用法
ActiveMQ 和 JMS的关系? ActiveMQ是流行的开源消息中间件,JMS是Java平台定义的一种消息传递的标准。ActiveMQ实现了JMS规范,因此可以使用JMS API来与ActiveMQ进行交互。 JMS定义了一种标准的API。API包括了一些接口和类,用于创建…...
TouchGFX之缓存位图
位图缓存是专用RAM缓冲区,应用可将位图保存(或缓存)在其中。 如果缓存了位图,在绘制位图时,TouchGFX将自动使用RAM缓存作为像素来源。位图缓存在许多情况下十分有用。 从RAM读取数据通常比从闪存读取要快(特…...
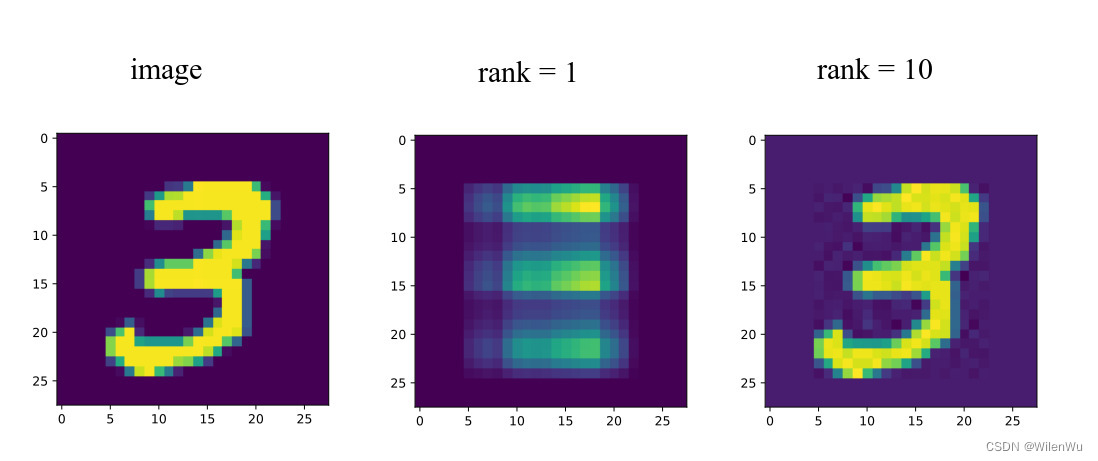
线性代数的本质(十)——矩阵分解
文章目录 矩阵分解LU分解QR分解特征值分解奇异值分解奇异值分解矩阵的基本子空间奇异值分解的性质矩阵的外积展开式 矩阵分解 矩阵的因式分解是把矩阵表示为多个矩阵的乘积,这种结构更便于理解和计算。 LU分解 设 A A A 是 m n m\times n mn 矩阵,…...

vue实现鼠标拖拽div左右移动的功能
直接代码: <template><div class"demo"><div class"third-part" id"发展历程"><div class"title">发展历程</div><div class"content" id"nav" v-if"dataList…...
基于Python和mysql开发的商城购物管理系统分为前后端(源码+数据库+程序配置说明书+程序使用说明书)
一、项目简介 本项目是一套基于Python和mysql开发的商城购物管理系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的Python学习者。 包含:项目源码、项目文档、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过…...

MySQL内外连接、索引特性
目录 内连接 外连接 索引特性 理解索引 删除索引 MySQL内外连接是一种用于联接两个或多个表的操作。内连接只返回满足连接条件的行,外连接返回满足条件和不满足条件的行。 内连接 SQL如下: SELECT ... FROM t1 INNER JOIN t2 ON 连接条件 [INNER …...

滚动条设置
不同浏览器滚动条样式及滚动定位 是否可以滚动 overflow:scroll overflow:autooverflow:scroll – 只有超出了盒子才会有滚动条 overflow:auto – 一直有滚动的盒子,只是超出了盒子才会出现滚动条滑块,可以滚动 谷歌浏览器滚动…...
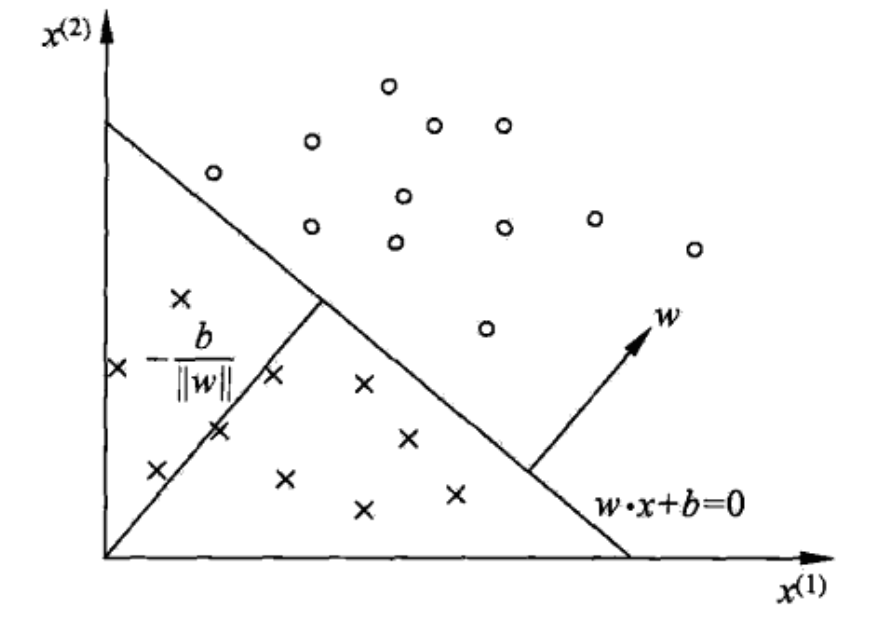
【AI】机器学习——感知机
文章目录 4.1 感知机基本概念4.2 策略4.2.1 数据集的线性可分性4.2.2 学习策略目标损失函数的构造关于距离的解释 4.3 算法4.3.1 原始形式损失函数的梯度下降法 4.3.2 PLA例题4.3.3 算法收敛性 4.4 PLA对偶形式4.4.1 原始PLA分析4.4.2 PLA对偶形式4.4.3 优点 4.1 感知机基本概念…...

蓝牙遥控器在T2-U上的应用
文章目录 简介优势使用流程示例代码遥控器命令表遥控器代码实现开启遥控器配对功能运行 简介 Tuya beacon 协议是基于 BLE 广播通信技术,完善配对解绑、组包拆包、群组管理、加密解密、安全策略,形成的一种轻量、安全的可接入涂鸦云的蓝牙协议。 蓝牙 …...
数据驱动的数字营销与消费者运营
引言:基于海洋馆文旅企业在推广宣传中,如何通过指标体系量化分析广告收益对业务带来的收益价值的思考? 第一部分:前链路引流投放的策略与实战 1.1 动态广告的实现: 偶然与必然 动态广告是一种基于实时数据和用户行为的广告形式,它…...

Qt点亮I.MX6U开发板的一个LED
本篇开始将会介绍与开发版相关的Qt项目,首先从点亮一个LED开始。I.MX6U和STM32MP157的相关信息都会用到,但是后期还是将I.MX6U的学习作为重点。当然其他开发版的开发也可以参考本博文。 文章目录 1. Qt是如何操控开发板上的一个LED2. 出厂内核设备树中注…...

网络摄像头-流媒体服务器-视频流客户端
取电脑的视频流 当涉及交通事件检测算法和摄像头视频数据处理时,涉及的代码案例可能会非常复杂,因为这涉及到多个组件和技术。以下是一个简单的Python代码示例,演示如何使用OpenCV库捕获摄像头视频流并进行实时车辆检测,这是一个…...
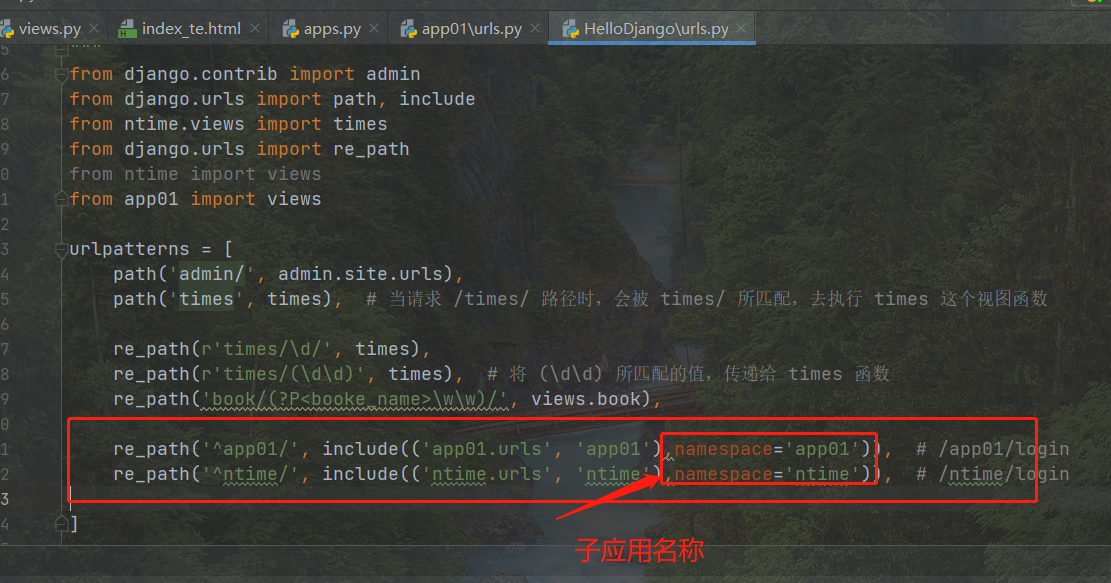
Django05_反向解析
Django05_反向解析 5.1 反向解析概述 随着功能的不断扩展,路由层的 url 发生变化,就需要去更改对应的视图层和模板层的 url,非常麻烦,不便维护。这个时候我们可以通过反向解析,将 url解析成对应的 试图函数 通过 path…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...

从入门到实践:EEG公开数据集分类与应用场景全解析
1. EEG公开数据集入门指南刚接触脑电信号分析的研究者,常常会被一个问题困扰:"我应该从哪里获取可靠的EEG数据?"作为一个在这个领域摸爬滚打多年的研究者,我完全理解这种困惑。记得我第一次接触EEG研究时,光…...

WPF虚拟桌宠组件:可嵌入、高性能、工程化UI生命体
1. 这不是“桌面宠物”,而是一个可嵌入的WPF UI组件化生命体你可能在Windows XP时代见过那只晃着尾巴、偶尔打哈欠的3D小猫,也可能在Win10系统托盘里点开过一个会眨眼的像素狐狸——但那些是独立进程、是系统级小工具、是“看一眼就关掉”的轻量娱乐。而…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...

机器学习与深度学习在社交媒体心理健康检测中的权衡与选择
1. 项目概述:当AI遇见心灵,社交媒体心理健康检测的技术十字路口在社交媒体成为我们数字生活延伸的今天,海量的文本数据无意中记录着用户的情感波动与心理状态。作为一名长期混迹于数据科学和自然语言处理(NLP)一线的从…...

3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南
3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南 【免费下载链接】Whisper-WebUI A Web UI for easy subtitle using whisper model. 项目地址: https://gitcode.com/gh_mirrors/wh/Whisper-WebUI 还在为视频制作繁琐的字幕而烦恼吗?Whis…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

Unity项目实战:用TriLib插件动态加载FBX模型,5分钟搞定外部资源读取
Unity项目实战:用TriLib插件高效加载外部FBX模型的完整指南在VR展示、产品配置器等需要动态加载用户上传模型的场景中,如何快速实现外部FBX文件的读取是许多Unity开发者面临的挑战。传统的手动导入方式不仅效率低下,更无法满足运行时动态加载…...