【数据库】redis数据持久化
目录
数据持久化
一, RDB
1, 什么是RDB
2,持久化流程
3, 相关配置
案例演示:
4, 备份和恢复
1、备份
2、恢复
3,优势
4, 劣势
二,AOF
1,什么是AOF
2, 持久化流程
3, 使用AOF
1、开启AOF
2、使用演示
3、备份
4、恢复
5、异常恢复
4, Rewrite压缩
1,Rewrite是什么
2、重写原理与流程
3, 优势
4, 劣势
5,选择AOF还是RDB
数据持久化
Redis提供了主要提供了 2 种不同形式的持久化方式:
- RDB(Redis数据库):RDB 持久性以指定的时间间隔执行数据集的时间点快照。
- AOF(Append Only File):AOF 持久化记录服务器接收到的每个写操作,在服务器启动时再次播放,重建原始数据集。 命令使用与 Redis 协议本身相同的以仅追加的格式记录。 当日志变得太大时,Redis 能够在后台重写日志。
一, RDB
1, 什么是RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘, 也就是Snapshot快照,它恢复时是将快照文件直接读到内存里。正是这种特性,让我们可以随时来进行备份,因为快照文件总是完整可用的。RDB是redis默认的持久化策略。
2,持久化流程
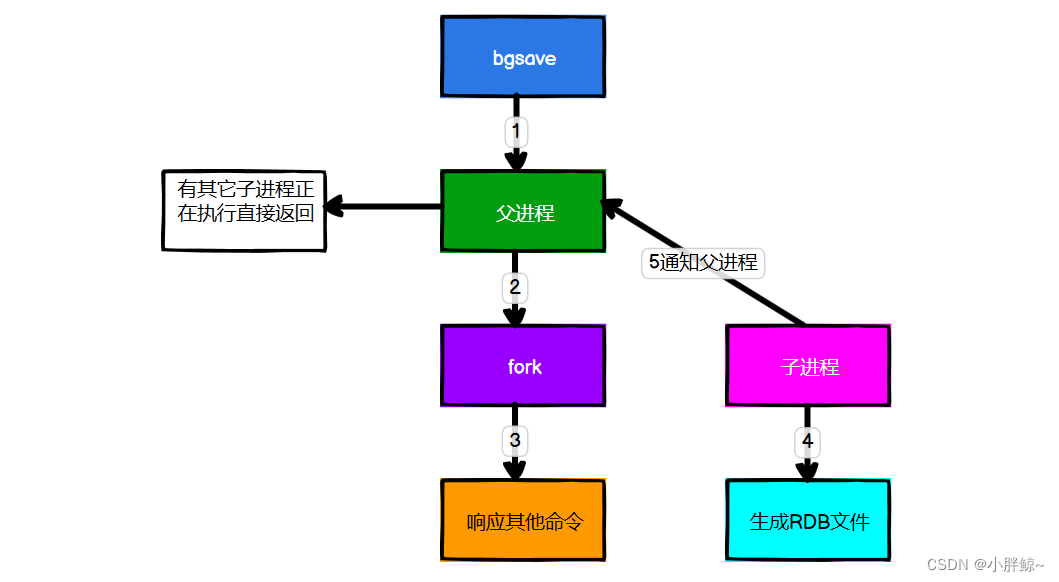
启动持久化后:
(1)检查是否存在子进程正在执行 AOF 或者 RDB 的持久化任务。如果有则返回 false。
(2)调用 Redis 源码中的 rdbSaveBackground 方法,方法中执行 fork() 产生子进程执行 RDB 操作。也就是说Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束后,再用这个临时文件替换上次持久化好的文件。 整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
Fork 的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等) 数值都和原进程一致,但它是一个全新的进程,并作为原进程的子进程。
在 Linux 程序中,fork() 会产生一个和父进程完全相同的子进程,但子进程在此后可能会执行 exec 系统调用,出于效率考虑,Linux 中引入了“写时复制技术”。一般情况下父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
虽然RDB有不少优点,但它的缺点也是不容忽视的。如果你对数据的完整性非常敏感,那么RDB方式就不太适合你,因为即使你每5分钟都持久化一次,当redis故障时,仍然会有近5分钟的数据丢失。所以,redis还提供了另一种持久化方式,那就是AOF。
3, 相关配置
redis创建RDB文件的方式:
- 手动执行SAVE
- 优点:节约系统资源。
- 缺点:直接调用rdbSave ,阻塞Redis主进程,直到保存完成为止。在主进程阻塞期间,服务器不能处理客户端的任何请求。
- 手动执行BGSAVE
- 优点:fork 出一个子进程,子进程负责调用 rdbSave ,并在保存完成之后向主进程发送信号,通知保存已完成。 Redis 服务器在BGSAVE 执行期间仍然可以继续处理客户端的请求。
- 缺点:由于会fork一个进程,因此更消耗内存。
- 满足配置条件进行rdb持久化。
快照持久化是Redis中默认开启的持久化方案,根据redis.conf中的配置设置一些默认参数。
读取redis的配置文件redis.conf。
1、快照将被写入dbfilename指定的文件中(默认是dump.rdb文件)。
dbfilename dump.rdb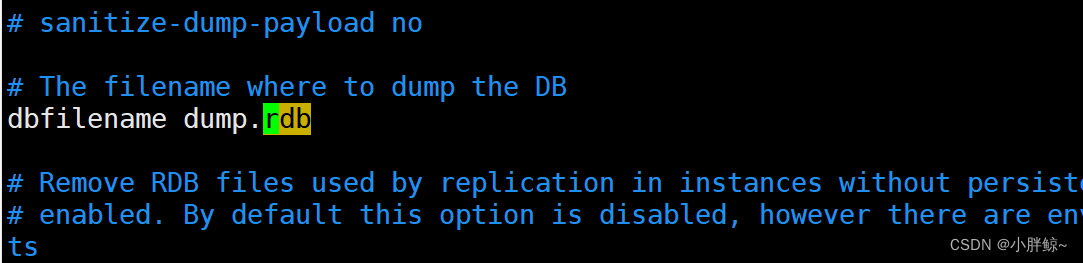
2、快照将保存在dir选项指定的路径上,我们可以修改为指定目录,建议使用绝对路径,如果使用相对路径,则会根据执行命令所在目录来生成dump.rdb文件。
dir /var/lib/redis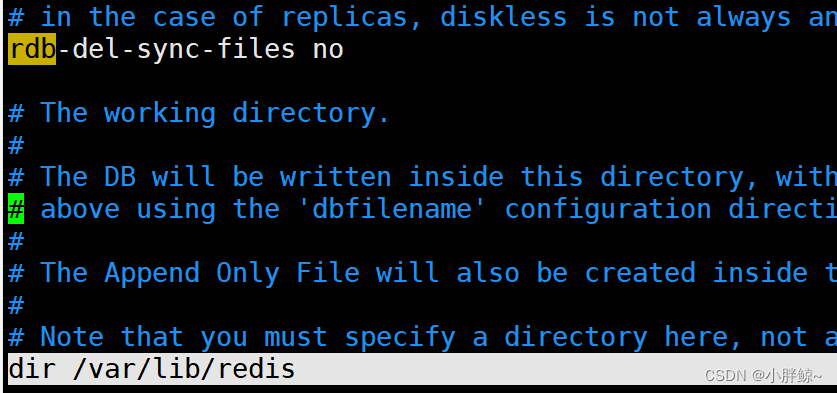
3、可以使用单个空字符串参数完全禁用快照。
save ""
![]()
4、在3600s内如果有1条数据被写入,则执行bgsave选项,产生一次快照
save 3600 1![]()
在300s内如果有100条数据被写入,则执行bgsave选项,产生一次快照
save 300 100![]()
在60s内如果有10000条数据被写入,则执行bgsave选项,产生一次快照
save 60 10000![]()
5、该指令用于指定是否开启当做快照时发生错误停止服务器写入数据;默认是yes,表示开启当做快照时发生错误而停止redis服务器的写入;
stop-writes-on-bgsave-error yes![]()
6、对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,Redis 会采用 LZF 算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能。推荐配置为 yes。
rdbcompression yes![]()
7、在存储快照后,还可以让 Redis 使用 CRC64 算法来进行数据校验,检查数据完整性。但是这样做会增加大约 10% 的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。推荐配置为 yes。
rdbchecksum yes![]()
案例演示:
1,在配置文件中设置30秒内写入5条数据就产生一次快照,也就是生成 rdb 文件
Save 30 5
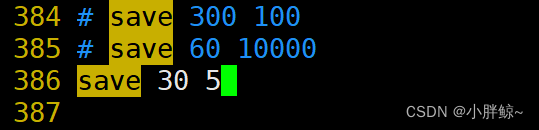
修改完配置文件需要重启服务
systemctl restart redis
2,在/var/lib/redis目录下面查看文件dump.rdb,此时文件大小为854
cd /var/lib/redisll
3,输入5条记录
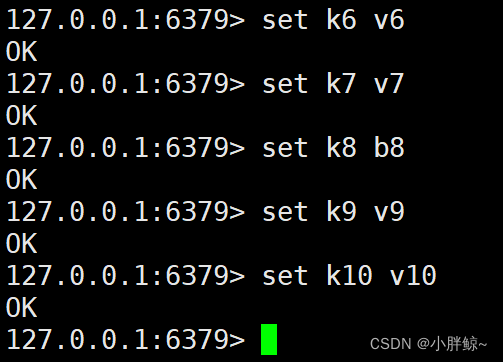
(1)执行前四条指令,文件大小并没有改变

(2)执行5条指令,发现文件大小变大了,

4,也可以通过查看日志的方法
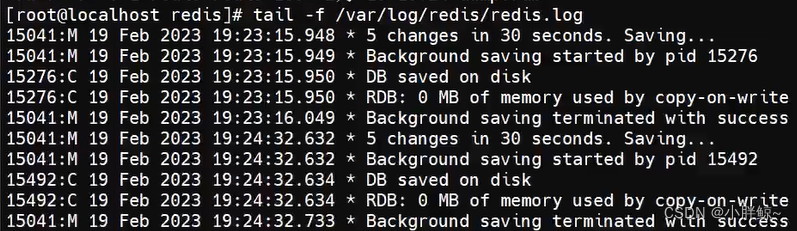
(1)输入5次
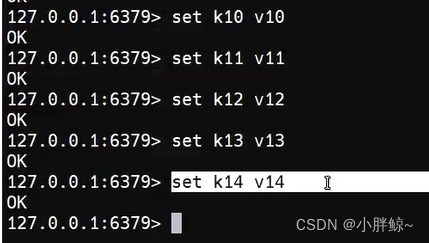
(2)日志文件更新

可以通过查看 dump.rdb 文件的大小,就可以发现文件快照已经产生了。
如果输入6 条数据,是否都持久化了?
只持久化了前 5 条数据,最后 1 条数据没有持久化。
4, 备份和恢复
1、备份
(1)首先执行如下命令来清空数据:
flushdb
ll
(2)然后再重新添加如下数据:
set k1 v1set k2 v2set k3 v3set k4 v4set k5 v5set k6 v6

(3)备份 dump.rdb,备份文件名为dump.rdb.back
cp dump.rdb dump.rdb.back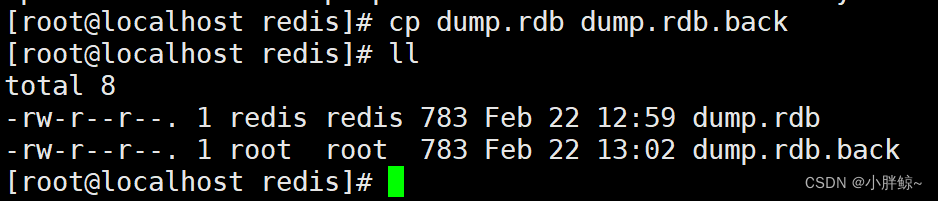
(4)最后把 Redis 服务关闭
systemctl stop redis
(5)然后把 dump.rdb 文件删除
rm -f dump.rdb
2、恢复
(1)首先执行如下命令来把 dump.rdb.back 文件修改为 dump.rdb。
mv dump.rdb.back dump.rdb
(2)恢复后所属者与所属组为root,若继续持续化,强制转化为redis
备份和还原时可以使用-a选项来保留所有属性

(3)然后重启 Redis 服务
systemctl restart redis
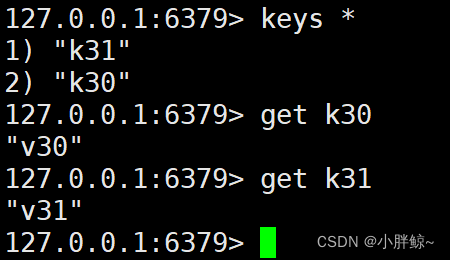
(4)然后连接客户端后再执行如下命令来查看:
keys *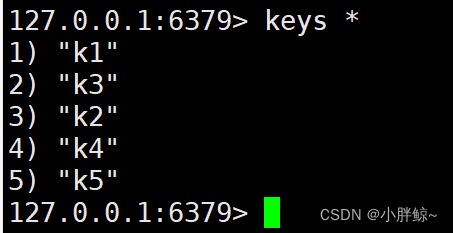
3,优势
RDB 方式适合大规模的数据恢复,并且对数据完整性和一致性要求不高更适合使用。它有以下几种优势:
- 节省磁盘空间
- 恢复速度快

4, 劣势
- Fork的时候,内存中的数据被克隆了一份,导致2倍的膨胀性需要考虑
- 虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
- 备份周期是在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
二,AOF
1,什么是AOF
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来(读操作不记录), 只追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据。简单说,Redis 重启时会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
在Redis的默认配置中AOF(Append Only File)持久化机制是没有开启的,要想使用AOF持久化需要先开启此功能。AOF持久化会将被执行的写命令写到AOF文件末尾,以此来记录数据发生的变化,因此只要Redis从头到尾执行一次AOF文件所包含的所有写命令,就可以恢复AOF文件记录的数据集。
2, 持久化流程

1)客户端的请求写命令会被 append 追加到 AOF 缓冲区内。
2)AOF 缓冲区根据 AOF 持久化策略 [always,everysec,no] 将操作sync同步到磁盘的 AOF 文件中。
3)AOF 文件大小超过重写策略或手动重写时,会对 AOF 文件 rewrite 重写,压缩 AOF 文件容量。
4)Redis 服务重启时,会重新 load 加载 AOF 文件中的写操作达到数据恢复的目的。
3, 使用AOF
1、开启AOF
#修改 redis.conf 配置文件
(1)AOF持久化是否开启
appendonly no

(2)指定日志文件名
appendfilename "appendonly.aof"

(3)通过appendfsync指定日志记录频率
# appendfsync always
appendfsync everysec
# appendfsync no

- always选项,每个redis写命令都会被写入AOF文件中,并完成磁盘同步,好处是当发生系统崩溃时数据丢失减至最少,缺点是这种策略会产生大量的I/O操作,会严重降低服务器的性能。
- everysec选项,以每秒一次的频率对AOF文件进行同步,并完成磁盘同步,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器几乎没有任何影响。
- no选项,写入aof文件,不等待磁盘同步。完全由操作系统决定什么时候同步AOF日志文件,这个选项不能给服务器性能带来多大的提升,反而会增加系统崩溃时数据丢失的数量。
2、使用演示
(1)修改redis.conf文件,开启AOF持久化
vim /etc/redis/redis.conf
appendonly yes

(2)重启服务
systemctl restart redis
(3)查找文件 appendonly.aof的路径
find / -name appendonly.aof
(4)appendonly.aof文件在/var/lib/redis,此时大小为0个字节
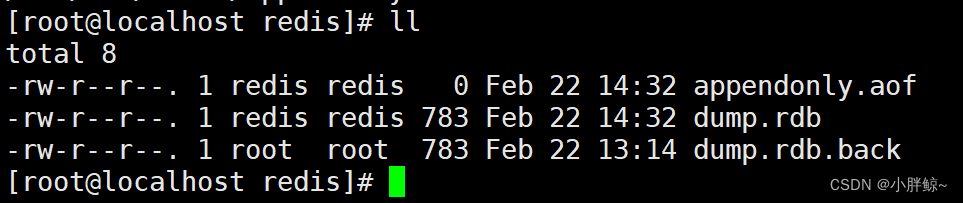
(5)默认读取AOF文件,AOF文件不存在才读取RDB文件

说明:发现没有任何数据。这说明:如果 RDB 和 AOF 文件同时存在,Redis 默认使用的是 AOF 文件。
3、备份
AOF的备份机制和性能虽然和RDB不同,但是备份和恢复的操作同RDB一样:都是拷贝备份文件,需要恢复时再拷贝到Redis工作目录下,启动系统即加载。
此时,appendonly.aof文件中有下面两个数据
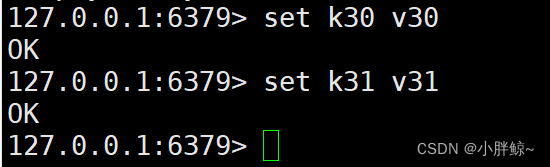
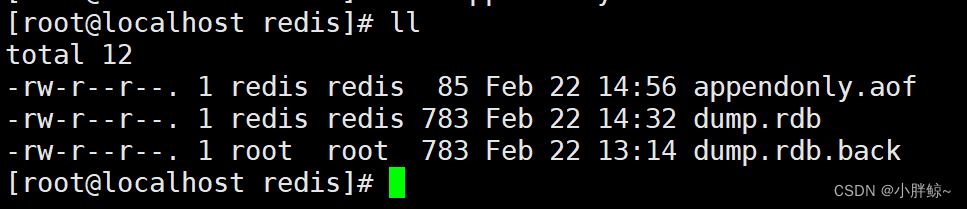
(1)备份appendonly.aof文件
cp -a appendonly.aof appendonly.aof.back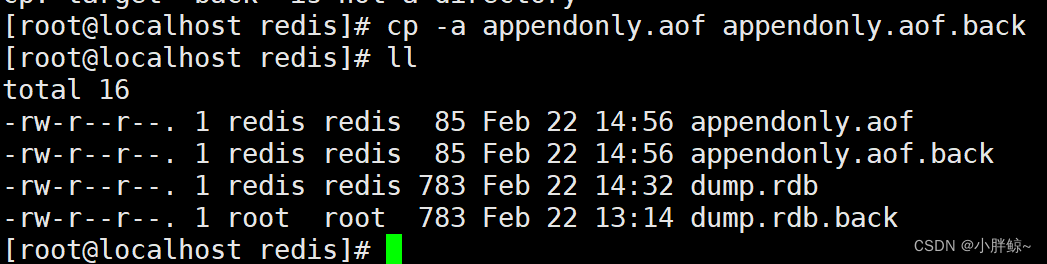
(2)关闭redis服务
systemctl stop redis
(3)删除appendonly.aof文件
rm -f appendonly.aof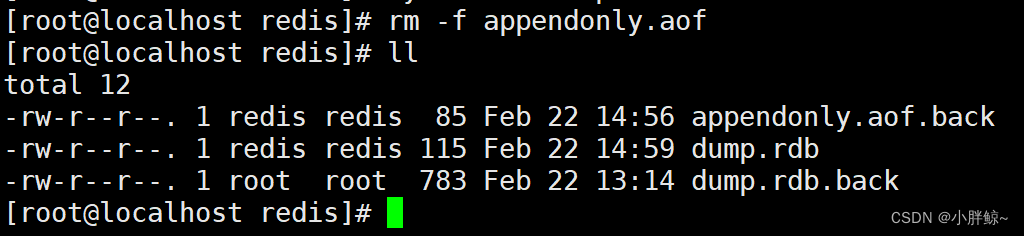
4、恢复
(1)恢复appendonly.aof文件
cp -a appendonly.aof.back appendonly.aof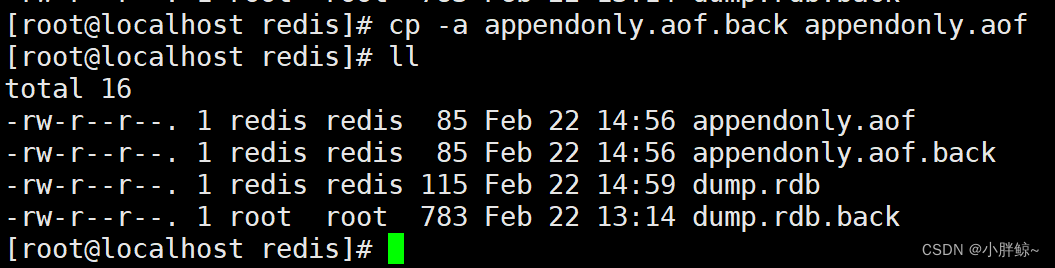
(2)重启reids服务
systemctl restart redis
(3)重新连接服务,并查询所有数据
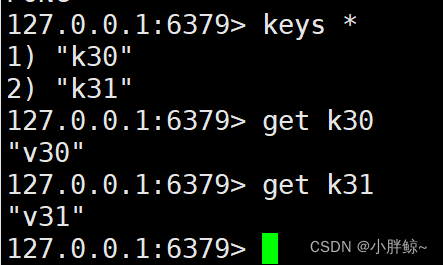
5、异常恢复
如遇到 AOF 文件被损坏,可以通过 /usr/local/bin/redis-check-aof --fix appendonly.aof 进行恢复。
(1)我们人为的在 appendonly.aof 中添加一点内容,假设文件损坏
在文件最后添加
vim appendonly.aof
redis-aof

(2)重启服务,重启失败
systemctl restart redis
(3)访问redis服务也失败
redis-cli
(4)对appendonly.aof文件进行修复
redis-check-aof --fix appendonly.aof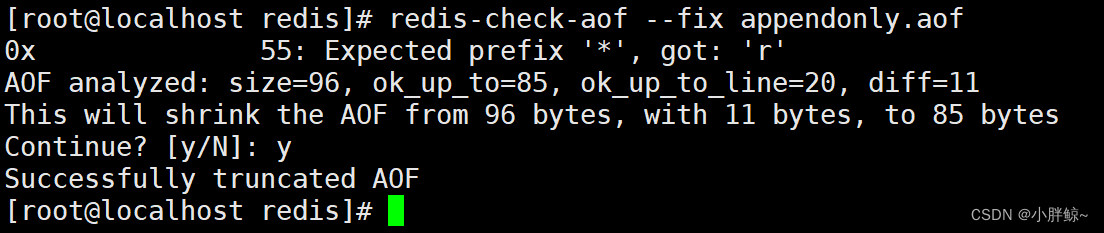
查看修复后的文件
cat appendonly.aof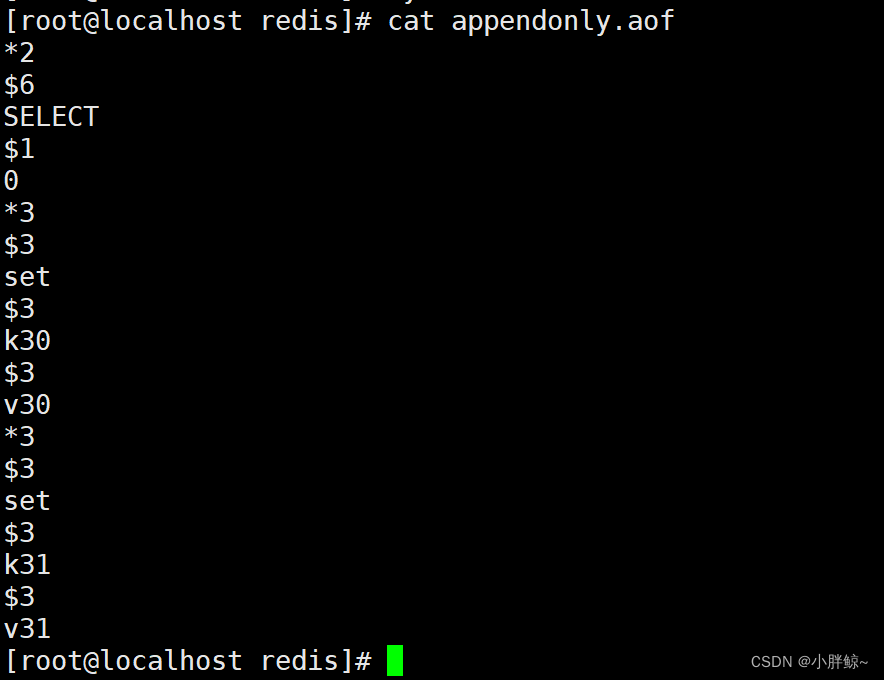
(5)重启服务
systemctl restart redis
(6)重新连接服务
redis-cli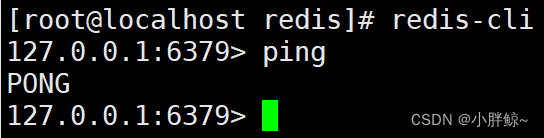
查看数据
4, Rewrite压缩
1,Rewrite是什么
AOF采用文件追加方式,文件会越来越大,为避免出现此种情况,新增了重写机制, 当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩, 只保留可以恢复数据的最小指令集。可以使用命令bgrewriteaof。
2、重写原理与流程
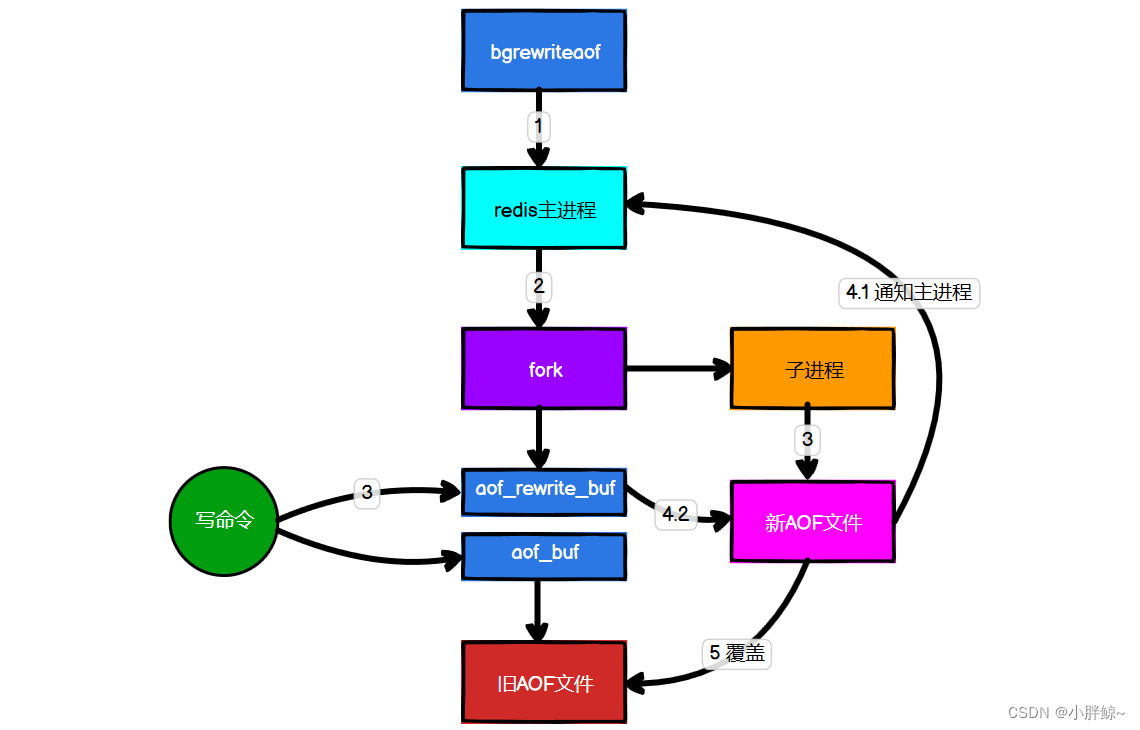
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再 rename),redis 4.0 版本后的重写,就是把rdb 的快照,以二进制的形式附在新的aof头部作为已有的历史数据,替换掉原来的流水账操作。
重写AOF文件具体流程:
1)手动执行bgrewriteaof命令或者自动触发重写,判断当前是否有bgsave或bgrewriteaof在运行,如果有,则等待该命令结束后再继续执行。
2)主进程fork出子进程执行重写操作,保证主进程不会阻塞。
3)子进程遍历redis内存中数据到临时文件,客户端的写请求同时写入aof_buf缓冲区和aof_rewrite_buf重写缓冲区保证原AOF文件完整以及新AOF文件生成期间的新的数据修改动作不会丢失。
4)子进程写完新的AOF文件后,向主进程发信号,父进程更新统计信息。主进程把aof_rewrite_buf中的数据写入到新的AOF文件。
5)使用新的AOF文件覆盖旧的AOF文件,完成AOF重写。
现在问题出现了,同时在执行bgrewriteaof操作和主进程写aof文件的操作,两者都会操作磁盘,而bgrewriteaof往往会涉及大量磁盘操作,这样就会造成主进程在写aof文件的时候出现阻塞的情形。
通过设置配置文件中参数no-appendfsync-on-rewrite=yes,表示不写入aof文件只写入缓存,并没有执行磁盘操作,只是写入了缓冲区,因此这样用户请求不会阻塞(因为没有竞争磁盘),但是在这段时间如果宕机会丢失这段时间的缓存数据。这样做可以提高性能,降低了数据安全性。

如果 no-appendfsync-on-rewrite=no,还是会把数据往磁盘里刷,但是遇到重写操作,可能会发生阻塞。这样做可以数据安全,但是性能降低。
因此,如果应用系统无法忍受延迟,而可以容忍少量的数据丢失,则设置为yes。如果应用系统无法忍受数据丢失,则设置为no。
重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定Redis要满足一定条件才会进行重写。

auto-aof-rewrite-percentage 100:设置重写的基准值,表示当前aof文件增长占用空间和上一次重写后aof文件空间的比值。
auto-aof-rewrite-min-size 64mb:设置重写的基准值,最小文件64MB。达到这个值开始重写。
因为假设本身aof文件就很小的话,如果增长达到相应比值就要重写的话,重写会很频繁,所以redis重写条件为:系统载入时或者上次重写完毕时,Redis会记录此时AOF大小,设为base_size,如果Redis的AOF当前大小>= base_size +base_size*100% (默认)且当前大小>=64mb(默认)的情况下,Redis会对AOF进行重写。
例如:文件达到70MB开始重写,降到50MB,下次什么时候开始重写?
答:100MB
[root@mysql8-0-30 redis]# redis-cli
127.0.0.1:6379> info persistence
aof_current_size:118
aof_base_size:118
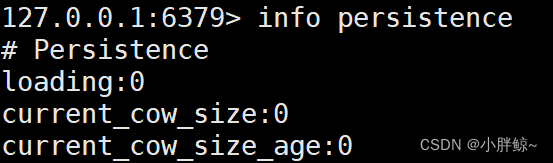

也可以手动重写
3, 优势
- 备份机制更稳健,丢失数据概率更低,就算发生故障停机,也最多只会丢失一秒钟的数据。
- 可读的日志文本,即使日志因为某些原因而包含了未写入完整的命令,redis-check-aof工具也可以轻易地修复这种问题。
4, 劣势
- 比起RDB占用更多的磁盘空间。
- 恢复备份速度要慢。
- 存在个别Bug,因为个别命令的原因,导致AOF文件在重新载入时,无法将数据集恢复成保存时的原样。
5,选择AOF还是RDB
那么,在开发中是选择 RDB 还是选择 AOF 来持久化呢?
官网建议如下:
Ok, so what should I use?
The general indication you should use both persistence methods is if you want a degree of data safety comparable to what PostgreSQL can provide you.
If you care a lot about your data, but still can live with a few minutes of data loss in case of disasters, you can simply use RDB alone.
There are many users using AOF alone, but we discourage it since to have an RDB snapshot from time to time is a great idea for doing database backups, for faster restarts, and in the event of bugs in the AOF engine.
The following sections will illustrate a few more details about the two persistence models.
- RDB持久化方式能够在指定的时间间隔对你的数据进行快照存储。
- AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF持久化方式追加保存每次写的操作到文件末尾。
- Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
- 只做缓存:如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式。
- 同时开启两种持久化方式:在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
- RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只使用AOF呢? 建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),而且不会有AOF可能潜在的bug,并且数据恢复更快,留着作为一个万一的手段。
相关文章:
【数据库】redis数据持久化
目录 数据持久化 一, RDB 1, 什么是RDB 2,持久化流程 3, 相关配置 案例演示: 4, 备份和恢复 1、备份 2、恢复 3,优势 4, 劣势 二,AOF 1,什么是A…...
前端编译、JIT编译、AOT编译
一、前端编译:java设计之初就是强调跨平台,通过javac将源文件编译成于平台无关的class文件, 它定义了执行 Java 程序所需的所有信息(许多Java"语法糖",是在这个阶段完成的,不依赖虚拟机ÿ…...

父子组件中,子组件调用父组件的方法
父子组件中,子组件调用父组件的方法 方法一:直接在子组件中通过this.$parent.event来调用父组件的方法 父组件 <template><p><child>父组件</child></p> </template> <script>import child from ~/compone…...
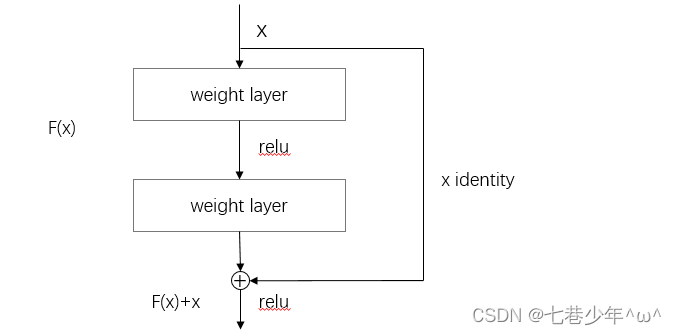
第七章.深度学习
第七章.深度学习 7.1 深度学习 深度学习是加深了层的深度神经网络。 1.加深层的好处 1).可以减少网络的参数数量 5*5的卷积运算示例: 重复两次3*3的卷积层示例: 图像说明: ①.一次5 * 5的卷积运算的区域可以由两次3 * 3的卷积运算抵消&a…...
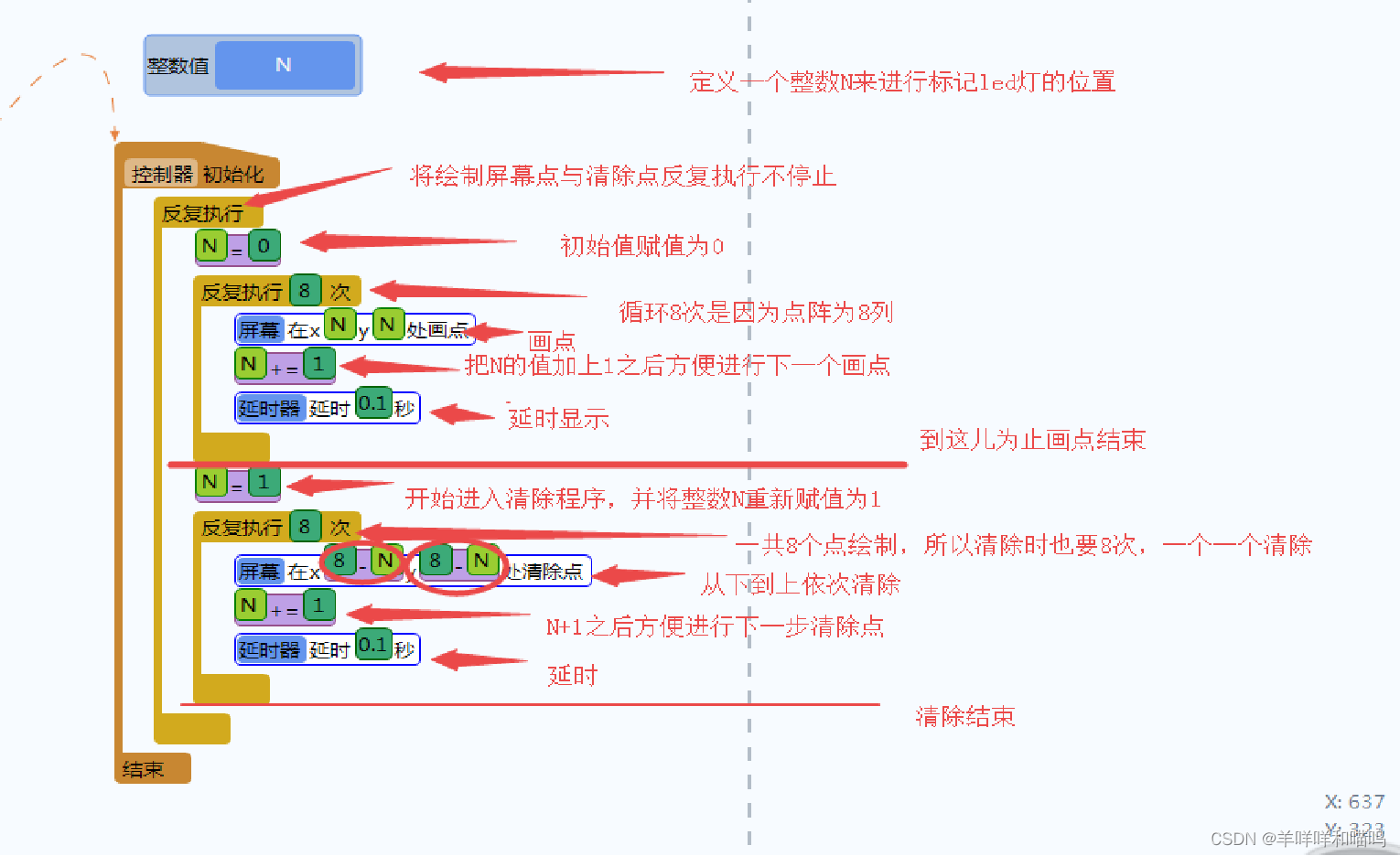
小学生学Arduino---------点阵(三)动态的显示与清除
学习目标: 1、理解“整数值”的概念与使用 2、理解“N1”指令的意义 3、掌握“反复执行多次”指令的使用 4、掌握屏幕模块的清除功能指令 5、理解“反复执行”指令与“反复执行多次”指令的嵌套使用 6、搭建电路图 7、编写程序 效果: 整数包括…...

opencv图片处理
目录1 图片处理1.1 显示图片1.2 旋转图片1.3 合并图片1.4、Mat类1.4.1、像素的储存结构1.4.2、访问像素数据1.6、rgb转灰度图1.7、二值化1.8、对比度和亮度1.9、图片缩放1.9.1、resize临近点算法双线性内插值1.9.2、金字塔缩放1.10、图片叠加1 图片处理 1.1 显示图片 #includ…...
—— 复合类型)
C++ Primer Plus 学习笔记(二)—— 复合类型
数组 当我们只是定义了数组,而没有对数组进行初始化时,那数组的值将是未定义的。 在对数组进行初始化时,如果只对数组的一部分进行初始化,编译器会将把其他元素自动设置为0。 #include <iostream>using namespace std;in…...
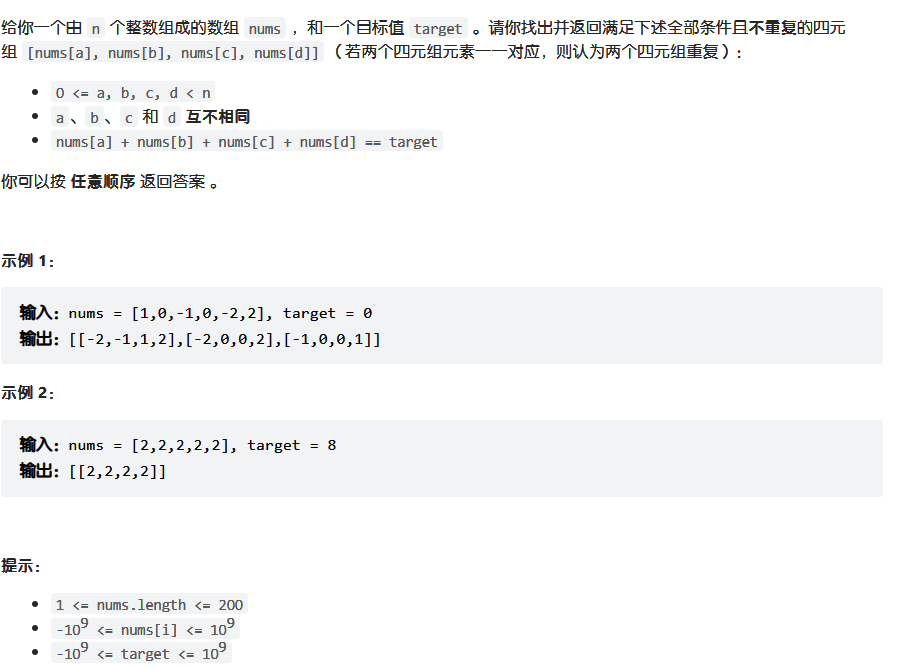
代码随想录算法训练营第七天 | 454.四数相加II 、 383. 赎金信、15. 三数之和、18. 四数之和 、总结
打卡第七天,还是哈希表。 今日任务 454.四数相加II383.赎金信15.三数之和18.四数之和总结 454.四数相加II 代码随想录 class Solution { public:int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, ve…...

apply函数族
apply函数族 apply函数族是R语言中帮助用户实现高效的向量化运算的一系列函数,包括apply,lapply,sapply,vapply等。 apply() apply函数以列或行为单位进行循环操作,可以处理matrix、array数据,返回一个向量或matrix。 apply(data,1/2,fuc…...

读书笔记可读性素材
《深入理解Java虚拟机》 《深入理解Java虚拟机》 《深入理解Java虚拟机》 本地方法栈(Native Method Stacks) 本地方法栈(Native Method Stacks) 本地方法栈(Native Method Stacks) -----------------…...
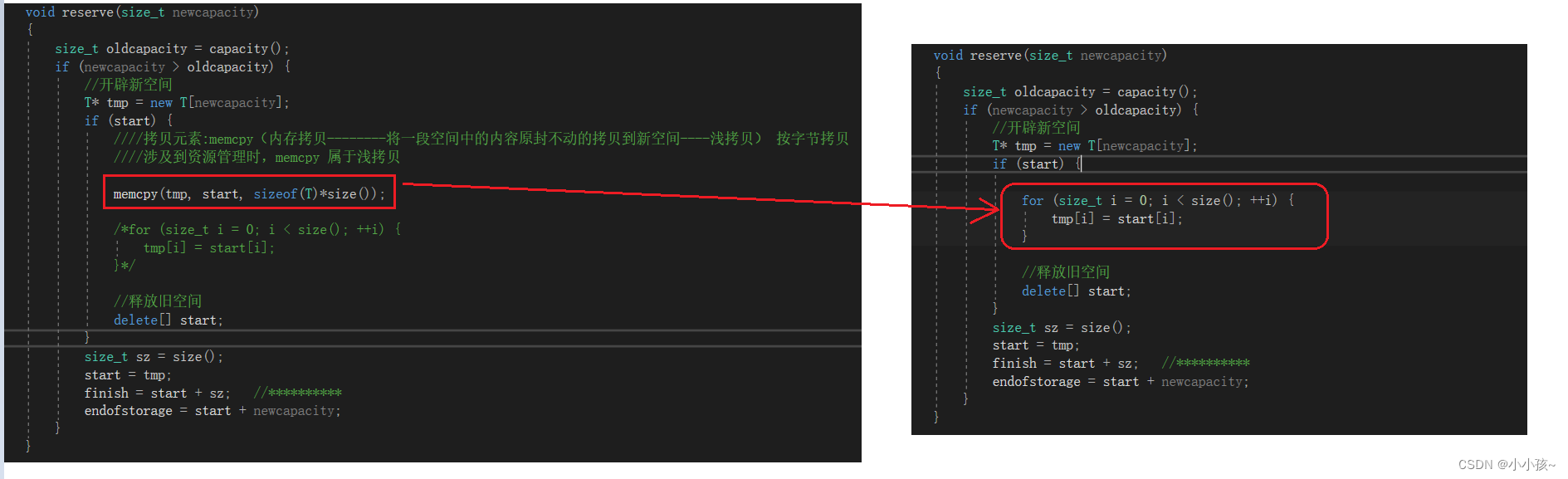
【C++】vector 模拟实现
vectorvector 容器vector 基本使用vector 定义库中各类接口的使用迭代器容量相关接口元素访问相关接口元素修改相关接口模拟实现 vector前期准备构造与析构赋值运算符重载迭代器相关容量相关元素访问相关元素的修改相关二维数组的创建对于自定义类型数据的测试vector 容器 C S…...

canvas初体验
canvas介绍 Canvas 最初由Apple于2004 年引入,用于Mac OS X WebKit组件,为仪表板小部件和Safari浏览器等应用程序提供支持。后来,它被Gecko内核的浏览器(尤其是Mozilla Firefox),Opera和Chrome实现&#x…...

JavaWeb12-线程通讯(线程等待和唤醒)
目录 1.方法介绍 1.1.wait()/wait(long timeout):让当前线程进入等待状态。 1.1.1.wait执行流程 1.1.2.wait结束等待的条件 1.1.3.wait() VS wait(long timeout) 1.1.4.为什么wait要放在Object中? --->PS:wait(0) 和 sleep(0) 的区…...

江苏专转本如何事半功倍的备考
专转本如何事半功倍的备考 一个人学习成绩的优劣取决于他的学习能力,学习能力包括三个要素:规范的学习行为;良好的学习习惯;有效的学习方法。有了规范的学习行为才能培养出良好的学习习惯,形成了良好的学习习惯就会形成…...
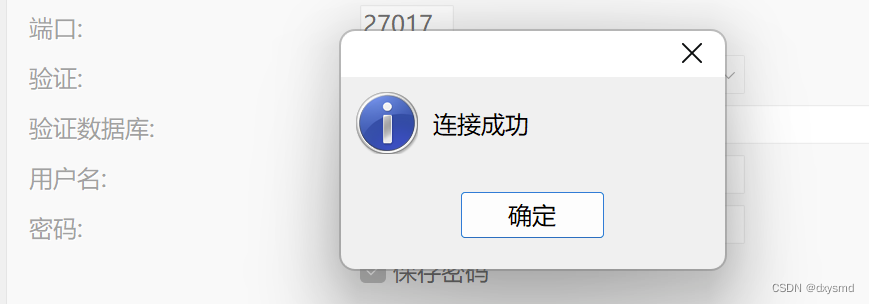
linux下安装mongoDB
一、下载mongoDB包 下载地址: https://www.mongodb.com/try/download/community 个人建议:如果是学习阶段,使用5以下版本更好些。 二、安装及配置 1、安装 # 1、解压 $ tar -zxvf mongodb-linux-x86_64-rhel70-4.4.19-rc1.tgz# 2、迁移目…...
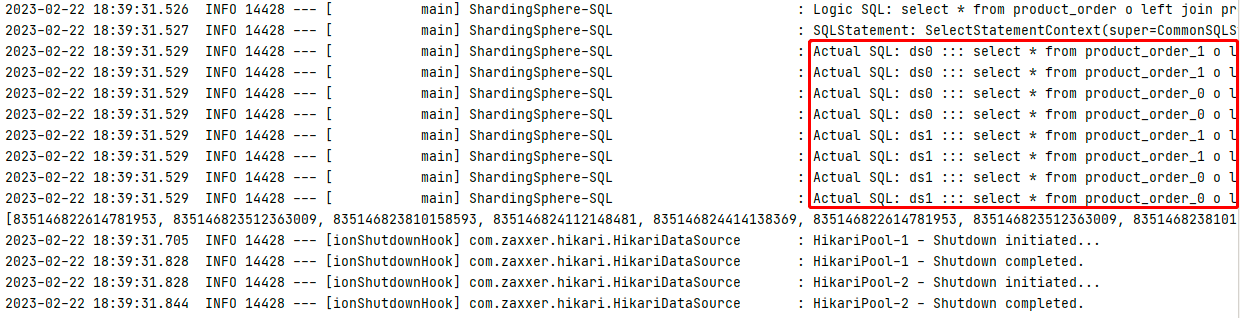
掌握MySQL分库分表(七)广播表、绑定表实战,水平分库+分表实现及之后的查询和删除操作
文章目录什么是广播表广播表实战数据库配置表Java配置实体类配置文件测试广播表水平分库分表配置文件运行测试什么是绑定表?绑定表实战配置数据库配置Java实体类配置文件运行测试水平分库分表后的查询和删除操作查询操作什么是广播表 指所有的分片数据源中都存在的…...
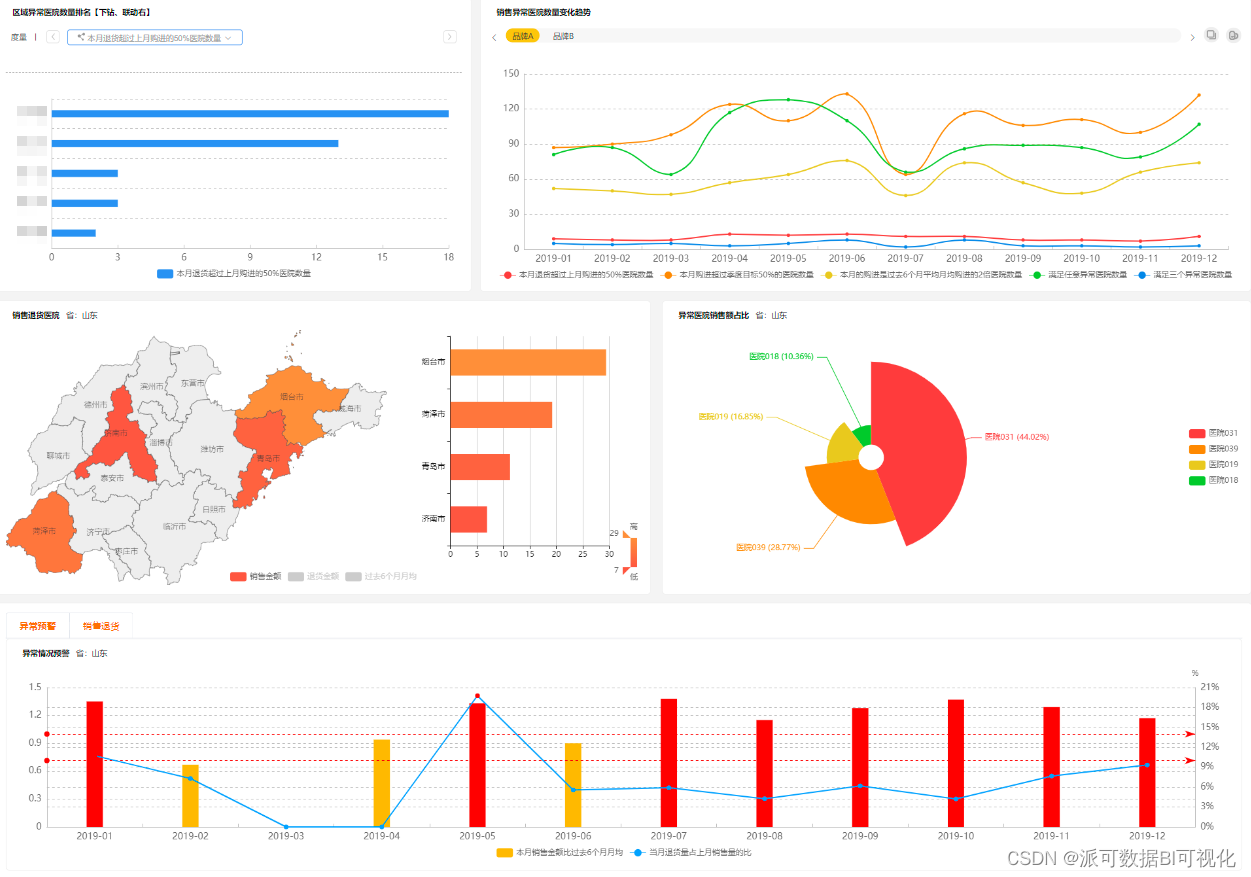
企业为什么需要数据可视化报表
数据可视化报表是在商业环境、市场环境已经改变之后,发展出来为当前企业提供替代解决办法的重要方案。而且信息化、数字化时代,很多企业已经进行了初步的信息化建设,沉淀了大量业务数据,这些数据作为企业的资产,是需要…...
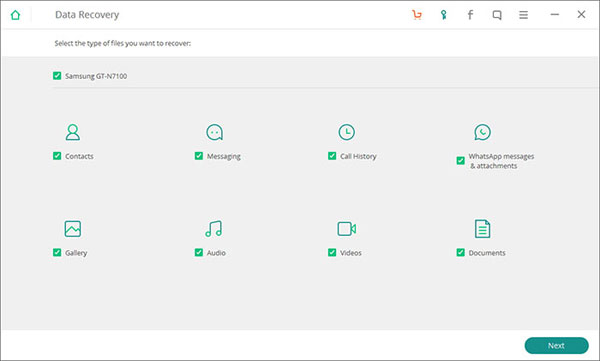
5个有效的华为(HUAWEI)手机数据恢复方法
5个有效的手机数据恢复方法 华为智能手机中的数据丢失比许多人认为的更为普遍。发生这种类型的丢失有多种不同的原因,因此数据恢复软件的重要性。您永远不知道您的智能手机何时会在这方面垮台;因此,预防总比哀叹好,这就是为什么众…...
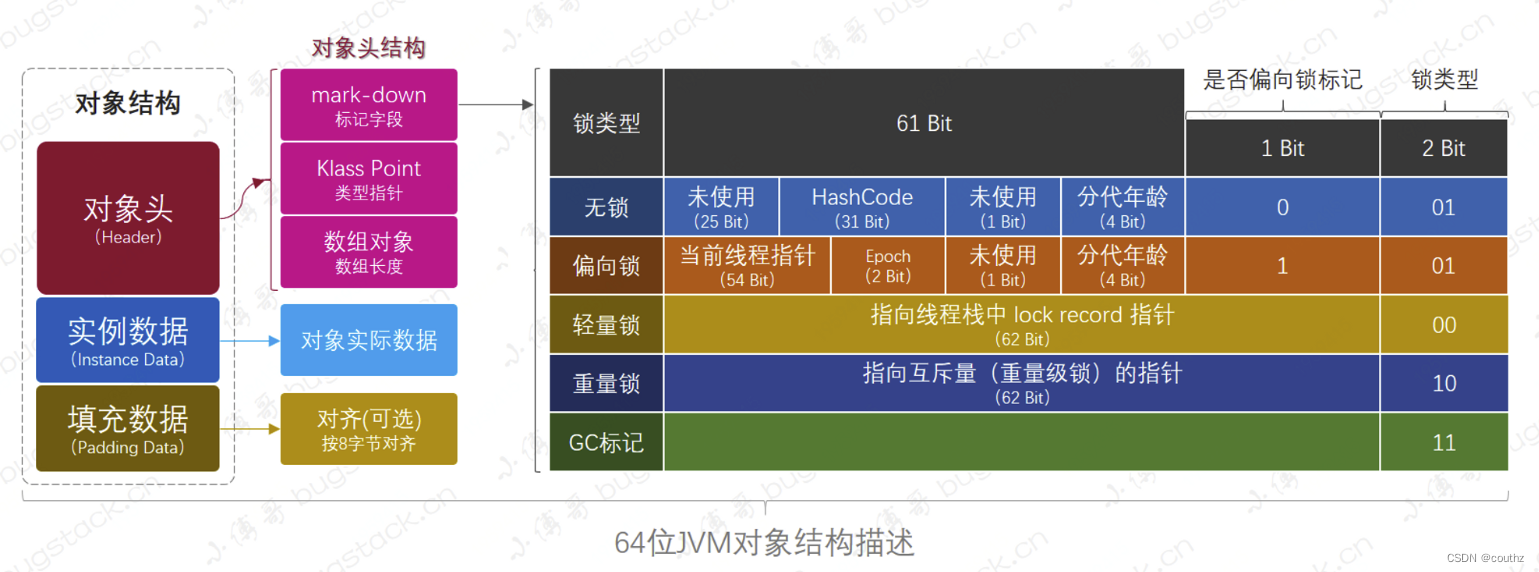
【Java并发编程】线程安全(一)Synchronized原理
Synchronized底层实现 简单来说,Synchronized关键字的执行主体是线程对象,加锁是通过一个锁对象来完成的是,而锁对象底层关联了一个c源码的monitor的对象,monitor对象底层又对应了操作系统级别的互斥锁,同一时刻只有一…...

[apollo]vue3.x中apollo的使用
[apollo]vue3.x中apollo的使用通过客户端获取Apollo配置环境工具的安装获取Apollo配置相关代码错误提示Uncaught (in promise) Error: Apollo client with id default not found. Use provideApolloClient() if you are outside of a component setup通过开放接口获取Apollo配置…...

重新定义Android设备管理:告别命令行,拥抱可视化操作新时代
重新定义Android设备管理:告别命令行,拥抱可视化操作新时代 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance 你是否曾经面对…...

奇异线性系统与矩阵方程数值解法【附仿真】
✨ 长期致力于奇异线性方程组、鞍点问题、块二乘二线性方程组、矩阵方程、偏微分方程、最小范数最小二乘解、迭代方法、预处理、Schwarz-Christoffel映射、Sherman-Morrison-Woodbury公式研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕…...

零起点Python机器学习快速入门【1.0】
第 1 章 从阿尔法狗开始说起1.1 阿尔法狗的前世今生百度百科的“阿尔法狗”词条是:阿尔法狗( AlphaGo)是一款围棋人工智能程序,由谷歌( Google)旗下 DeepMind 公司的戴密斯哈萨比斯、大卫席尔瓦、黄士杰与他…...

独立开发者如何利用Taotoken的Token Plan套餐有效控制月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的Token Plan套餐有效控制月度预算 作为一名独立开发者,项目预算通常有限,而AI…...

OpenWebUI 到底解决了什么,没解决什么?
先说结论OpenWebUI 把多模型切换、对话管理、参数调整从命令行搬到了浏览器,交互体验接近 ChatGPT,但部署本身有硬性前提。免费内网穿透方案有 24 小时域名更换限制,固定域名需付费,远程访问稳定性取决于网络环境。对于只跑单个模…...

基于SpringBoot的校园心理健康匿名互助社区毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的校园心理健康匿名互助社区系统以解决当前高校心理健康服务中存在的信息传播效率低下、公众参与度不足以及资源利用…...
)
DeepSeek负载均衡方案竟被90%团队忽略的3个致命盲区:长连接保活、gRPC流式重试、Token级会话粘滞(附Checklist)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek负载均衡方案的演进与核心挑战 DeepSeek作为高性能开源大语言模型推理框架,其负载均衡方案经历了从静态路由到动态感知、从单层代理到多级协同的持续演进。早期版本依赖Nginx反向代…...
:如何用3步完成eIDAS 2.0兼容性认证与审计留痕闭环)
Gemini KYC合规沙盒实战(仅限首批200家持牌机构开放):如何用3步完成eIDAS 2.0兼容性认证与审计留痕闭环
更多请点击: https://intelliparadigm.com 第一章:Gemini KYC流程优化 Gemini 交易所的 KYC(Know Your Customer)流程长期以来以严谨著称,但用户反馈表明,传统表单提交人工审核模式存在平均 3.2 天的等待延…...

【DeepSeek R1-VL流式优化白皮书】:基于127个真实生产案例的RTT压缩公式与chunk_size黄金阈值表
更多请点击: https://intelliparadigm.com 第一章:DeepSeek R1-VL流式响应优化的工程意义与挑战全景 DeepSeek R1-VL作为多模态大模型,其视觉-语言联合推理能力依赖于高吞吐、低延迟的流式响应机制。在实时图文理解、交互式AI助手、边缘端多…...

粒子滤波算法在非线性估计中的应用【附程序】
✨ 长期致力于非线性系统、参数估计、递归贝叶斯估计、粒子滤波算法、重采样、相关系数、谐波模型研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于…...