双视觉Transformer(Dual Vision Transformer)
摘要
已经提出了几种策略来减轻具有高分辨率输入的自注意机制的计算:比如将图像补丁上的全局自注意过程分解成区域和局部特征提取过程,每个过程都招致较小的计算复杂度。尽管效率良好,这些方法很少探索所有补丁之间的整体交互,因此难以完全捕获全局语义。
在本文中,我们提出了一种新的Transformer架构,优雅地利用全局语义的自我注意力学习,即DualVision变压器(Dual-ViT)。
新的体系结构引入了关键语义路径,可以更有效地将令牌向量压缩为全局语义,并降低了复杂度。
然后,这种压缩的全局语义在通过另一个构建的像素路径学习更精细的局部像素级细节时用作有用的先验信息。
语义路径和像素路径被集成在一起并被联合训练,通过两个路径并行传播增强的自我注意信息。
Dual-ViT从此能够利用全局语义来提高自我注意力学习,而不会影响许多计算复杂性。
1、介绍
自我注意过程形成了这种复杂性问题的主要负担,特别是对于高分辨率输入,因为每个令牌的每个表示都是通过关注所有令牌来更新的。
许多人考虑将自注意力与下采样相结合,以有效地取代所有图像块上的原始标准全局注意力。
这种方式自然地实现了区域语义信息的探索,这进一步促进了局部更精细特征的学习/提取。
例如,PVT [12]、[13]提出了线性空间减少注意力(SRA),其利用下采样操作(例如,平均池化或跨步卷积),如图所示。1(a).Twins [14](Fig.图1(B))在SRA之前添加附加的局部分组的自注意层,以经由区域内交互进一步增强表示。RegionViT [15](Fig. 1(c))通过区域和局部自我注意分解原始注意。然而,由于上述方法严重依赖于将特征图下采样到区域中,因此不可避免地忽略了描绘全局语义信息的所有补丁之间的整体交互。
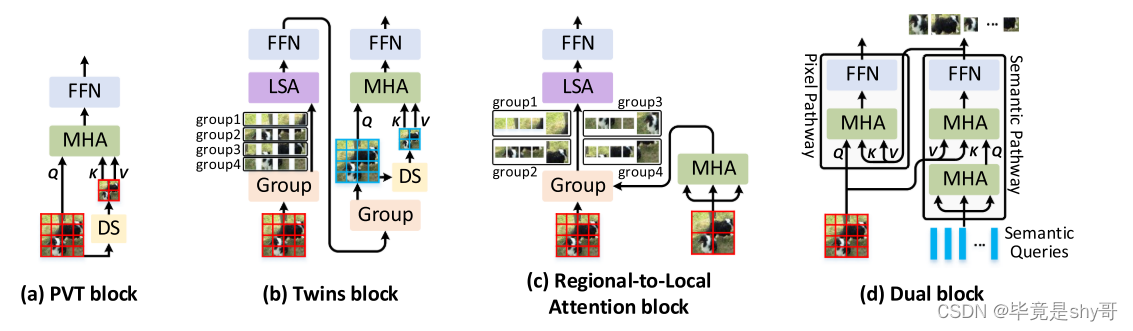
Fig. 1.(a)金字塔视觉Transformer块(PVT),(b)结合局部分组的自我注意力和空间减少注意力的双胞胎块,(c)RegionViT中的区域到局部注意力块,以及(d)我们提出的Dual-ViT中的Dual块的图示。DS:下采样操作; MSA:多头自我关注; FFN:前馈层; LSA:本地分组的自我关注。为了简单起见,省略了层归一化和残差连接。
在这些不同的组合策略中,很少有人试图研究全局语义和更精细的像素级特征之间的依赖关系,以进行自我注意力学习。
在本文中,我们考虑将训练分解为全局语义和更精细的功能注意通过建议的DualViT。动机是提取全局语义信息(即,参数语义查询),其可以用作丰富的先验信息以帮助在新的双路径设计中更精细的局部特征提取。
我们独特的分解和集成的全局语义和局部特征允许有效减少所涉及的令牌数量在多头注意,从而节省计算复杂度相比,标准的全局自注意。
特别是,如图所示。图1(d)中,Dual-ViT由两条特殊的通路组成,分别称为“语义通路”和“像素通路”。通过构造的“像素路径”的局部像素级特征提取是由“语义路径”的压缩的全局先验的强依赖性强加的。由于梯度通过语义路径和像素路径,因此Dual-ViT训练过程可以有效地补偿全局特征压缩的信息损失,同时降低更精细的局部特征提取的难度。前者和后者的程序可以在并行显着促进自我注意学习,而不会牺牲太多的计算成本,由于较小的注意力大小和两个途径之间的依赖关系。
贡献:
1)我们提出了一种新的Transformer架构称为双视觉变压器(双ViT)。顾名思义,Dual-ViT网络包括两条路径和一条像素路径,这两条路径分别用于提取输入的语义特征的全局视图,另一条像素路径则侧重于更精细的局部特征的学习。
2)Dual-ViT考虑了全局语义和两条路径沿着的局部特征之间的依赖性,目标是通过减少令牌大小和更小的关注度来简化训练。
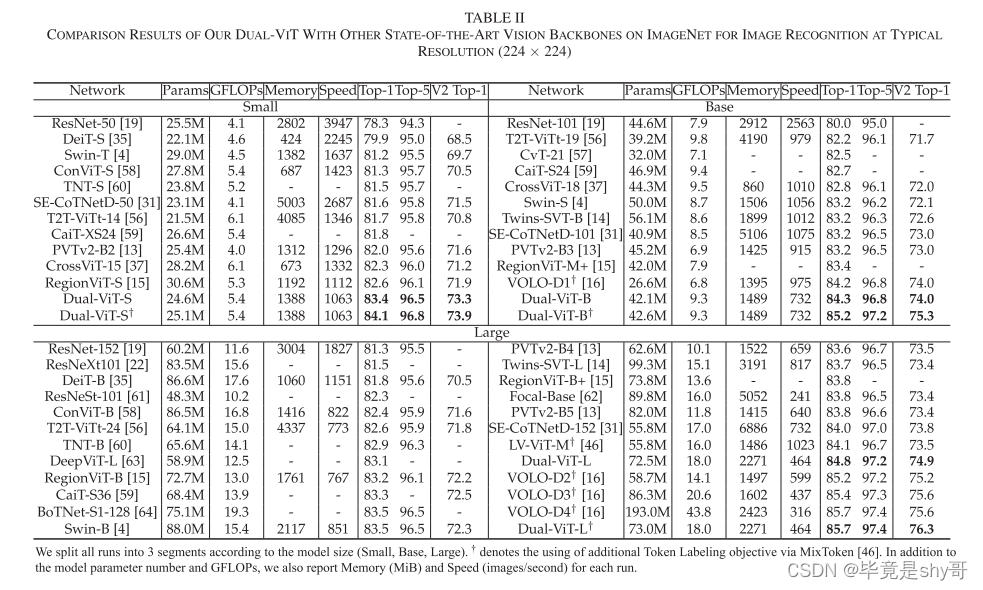
3)与VOLO-D4相比,Dual-ViT在ImageNet上实现了85.7%的top-1准确率,仅具有41.1%的FLOP和37.8%的参数[16]。在对象检测和实例分割方面,Dual-ViT还在mAP方面将PVT [13]提高了1.4%以上,在COCO上提高了0.8%,参数减少了47.3%/42.3%。
2、相关工作
我们的Dual-ViT也是一种多尺度ViT骨干网。与现有的多尺度ViT严重依赖于局部窗口内的局部自注意或下采样操作相比,Dual-ViT将自注意的建模分解为两条路径中的全局语义和更精细特征的学习。进一步将语义标记和输入特征相结合,并行传播增强的自我注意信息。这种独特的分解和集成设计不仅有效地减少了自我注意学习中的令牌数量,而且还强加了两个路径之间的交互,导致更好的准确性和延迟权衡。
3、方法
本节首先简要回顾现有ViT中采用的传统多头自注意块,并分析它们如何按比例缩小自注意计算成本。接下来,我们提出了一种新的原则性Transformer结构,即双视觉变压器(Dual-ViT)。我们的出发点是升级典型的Transformer结构与特定的双路径设计,并触发全局语义和局部特征之间的依赖性,以增强自我注意力学习。
具体地,Dual-ViT由四个阶段组成,其中每个阶段中的特征图的分辨率逐渐缩小,如[4]所示。在具有高分辨率输入的前两个阶段中,Dual-ViT采用由两条路径组成的新Dual模块:(i)通过在像素级细化输入特征来捕获细粒度信息的像素路径,以及(ii)在全局级抽象高级语义令牌的语义路径。语义路径稍微更深(具有更多操作),但包含更少的从像素抽象的语义标记,并且像素路径将这些全局语义视为在学习更精细的像素级细节之前。这样的设计方便地编码更精细的信息对整体语义的依赖性,同时在高分辨率输入上保持有利的计算成本。这两个路径的输出被合并在一起,并在最后两个阶段进一步馈送到多头自我注意。
A.传统Transformer
传统的Transformer架构(例如,[2],[35])通常依赖于多头自我注意,捕捉输入之间的长程依赖性。
将注意力范围限制在局部窗口中,因此可以仅实现相对于输入分辨率的线性计算复杂度,然而,有限的局部窗口的感受野不利地阻碍了建模的全局依赖性。
进步[13]、[33]、[36]通过使用下采样操作(例如,[13]中的平均池化或[33]、[36]中的池化内核),以降低计算成本,但是这些基于池的操作不可避免地会导致信息丢失,并且所有补丁之间的整体语义信息没有得到充分利用。
B.双重块
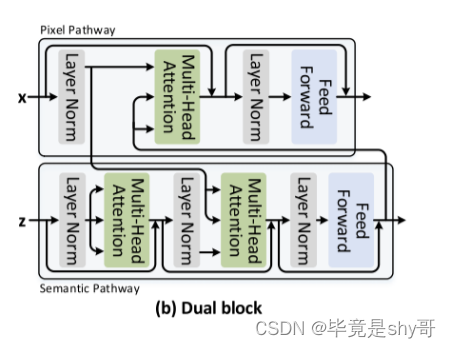
为了缓解上述问题,我们设计了针对高分辨率输入定制的原则性自注意块(即,在前两个阶段),即双块。这种新设计很好地引入了一种额外的途径,可以通过全局语义信息来促进自我注意学习。图2(B)详细描绘了双块的架构。具体而言,双块包含两个通路:像素路径和语义路径。语义路径将输入特征图总结为语义标记。之后,像素路径以键/值的形式将这些语义令牌作为丰富的先验,并执行多头注意以通过交叉注意来细化输入特征图。在复杂度方面,由于语义路径包含的令牌比像素路径中的令牌少得多,因此计算成本降低到O(nmd +m2 ~ d),其中m是语义令牌的数量。
形式上,给定第l个对偶块的输入特征xl,我们用附加的参数语义查询zl ∈ Rm×d来扩充。语义路径首先经由自注意对语义查询进行上下文编码,然后通过经由交叉注意利用精炼语义查询与输入特征xl之间的交互来提取语义令牌,随后是前馈层。此操作执行如下:
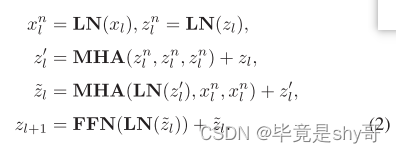
语义令牌zl+ l被馈送到像素路径中并且充当高级语义的先验信息。同时,我们将语义标记作为增强的语义查询,并将它们馈送到下一个Dual块的语义路径中。
像素路径起到与传统Transformer块类似的作用,除了它额外地采用从语义路径导出的语义标记,如之前通过交叉注意来细化输入特征。更具体地,像素路径将语义令牌zl+1视为键/值,并且如下执行交叉注意:
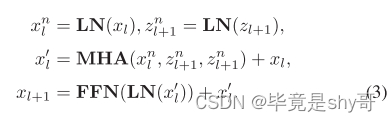
考虑到梯度通过两种路径反向传播,双块算法能够同时补偿全局特征压缩的信息损失,并通过语义-像素交互降低全局先验局部特征提取的难度。
C.合并块
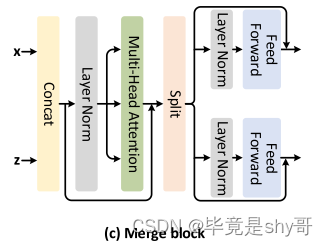
回想一下,前两个阶段中的双块利用了两个路径之间的相互作用,同时由于高分辨率输入的巨大复杂性,使得像素路径内的局部令牌之间的内部相互作用未被利用。为了缓解这个问题,我们提出了一个简单而有效的设计的自我关注块(即合并块),在最后两个阶段(低分辨率输入)的串联语义和本地令牌执行自我关注,从而使跨本地令牌的内部交互。图2(c)描绘了合并块的架构。具体来说,我们直接合并来自两个路径的输出令牌,并将它们馈送到多头自我注意层。由于来自两个路径的令牌传达不同信息的事实,在合并块中针对每个路径采用两个单独的前馈层:
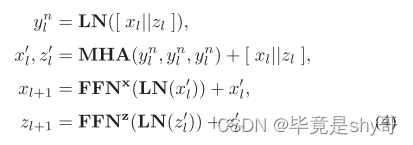
其中[||]表示张量级联,FFNx和FFNz是两个不同的前馈层。最后,我们在两个路径的输出令牌上采用全局平均池化来产生最终的分类令牌。
D.双视觉Transformer
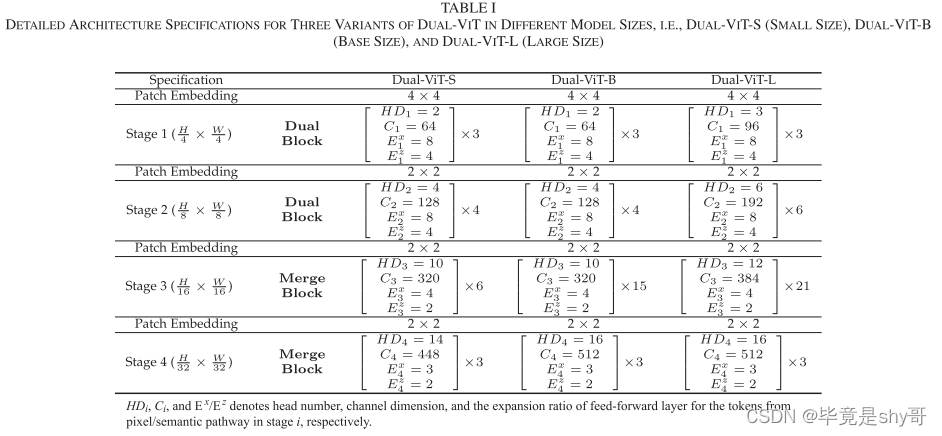
我们提出的双块和合并块本质上是统一的自我注意块。因此,通过堆叠这些块来构建多尺度ViT骨架是可行的。遵循现有多尺度ViT的基本配置[4],[12],完整的Dual-ViT包含四个阶段。前两个阶段由Dual块堆栈组成,而最后两个阶段由合并块组成。根据CNN体系结构的设计原理,在每一阶段开始采用一个补丁嵌入层来增加信道维数,同时降低空间分辨率。在这项工作中,我们提出了不同型号尺寸的Dual-ViT的三种变体,即,Dual-ViT-S(小号)、Dual-ViT-B(底座尺寸)和Dual-ViT-L(大号)。注意,Dual ViT-S/B/L与Swin-T/S/B共享相似的模型大小和计算复杂度[4]。表I详细描述了Dual-ViT的所有三个变体的架构,其中HDi、Ci和Ex/Ez是从阶段i中的像素/语义路径导出的令牌的头部数量、通道维度和前馈层的扩展比率。
E.我们的Dual-ViT和以前的Vision Transformers之间的差异
在本节中,我们将详细讨论我们的Dual-ViT与先前相关ViT主干之间的差异。
RegionViT [15]设计了区域到本地的注意力,它涉及两种令牌:具有较大补丁大小的区域令牌和具有较小补丁大小的本地令牌。RegionViT首先在所有区域令牌上执行区域自注意以学习全局信息。然后,局部自注意在局部窗口内在每个单个区域令牌及其相关联的局部令牌之间交换信息。我们的Dual-ViT在两个方面与这项工作不同:首先,Dual块中的语义标记不像RegionViT中那样被限制为大小相等的均匀块,因此在编码语义方面更灵活;其次,全局语义令牌作为整体之前,以补偿像素路径中的信息损失,而区域ViT的区域令牌仅与其相关联的本地令牌在本地窗口内交互。
Twins [14]由两种类型的注意力操作组成:局部和子采样的自我注意力。具体来说,Twins将输入令牌分成几组,并在每个局部子窗口内对每组执行局部自注意。为了实现不同子窗口之间的交互,Twins通过将特征图下采样为区域令牌来利用子采样的自注意力,区域令牌充当下采样的键和值,如[13]中所示。Dual-ViT和Twins之间的区别在于,我们的语义标记是从整个特征图中整体总结的,而Twins则从局部子窗口中独立产生每个区域标记。
CrossViT [37]包含两种具有不同补丁大小的令牌,它们被馈送到两个独立分支中的两个Transformer编码器中。最后,CrossViT将每个分支的CLS令牌与另一个分支的输出补丁令牌集成。相比之下,我们的Dual-ViT触发来自每个Dual块内的像素和语义路径的令牌之间的交互,而不是像CrossViT中那样用单独的Transformer编码器编码每个分支。此外,Dual-ViT在整个过程中在多个全局级语义令牌和更精细的像素级特征之间交换信息,而CrossViT仅与单个压缩的CLS令牌交互最终输出特征,这可能缺乏详细的语义。
非深度网络[38]和并行ViT [39]分别设计了具有多个并行分支的CNN/ViT主干。Non-deepNetworks中的每个分支都被馈送来自主要CNN分支的不同尺度的特征图。在并行ViT的每个块中,每个分支用与典型Transformer块中相同的输入触发(即,大小相等的均匀片)。相反,我们的Dual-ViT中的语义路径的输入,即,语义标记不被约束为相同大小的统一特征图/块。语义标记从整个特征图中整体地总结,从而在编码语义方面更加灵活。此外,与非深度网络和并行ViT中每个分支的独立特征编码不同,我们提出的Dual-ViT在整个架构中频繁地在像素和语义路径之间交换自我注意信息。
四、实验
我们通过多个视觉任务的各种经验证据验证了我们的Dual-ViT的优点,例如,图像识别、对象检测、实例分割和语义分割。特别是,我们首先使用最常见的图像识别基准(ImageNet [40])从头开始训练提出的Dual-ViT。接下来,预训练的Dual-ViT在COCO [41]和ADE 20 K [42]上进行微调,用于对象检测,实例分割和语义分割的下游任务,旨在评估预训练的Dual-ViT的泛化能力。
五、总结
在这项工作中,我们提出了DualVision Transformer(Dual-ViT),一个新的多尺度ViT骨干,它新颖地在两个交互路径中建模自我注意力学习:用于学习更精细像素级细节的像素路径和从输入提取整体全局语义信息的语义路径。从语义路径学习到的语义标记进一步充当高级语义先验,以便于像素路径中更精细的局部特征提取。以这种方式,增强的自我注意力信息沿着两个路径并行传播,追求更好的准确性-延迟权衡。各种视觉任务的广泛的实证结果表明,双ViT对国家的最先进的ViT的优越性。
相关文章:
双视觉Transformer(Dual Vision Transformer)
摘要 已经提出了几种策略来减轻具有高分辨率输入的自注意机制的计算:比如将图像补丁上的全局自注意过程分解成区域和局部特征提取过程,每个过程都招致较小的计算复杂度。尽管效率良好,这些方法很少探索所有补丁之间的整体交互,因…...

MES系统成为工业4.0首选,制造业真正数字化车间你看过吗?
在日益激烈的市场竞争中,MES管理系统已经成为企业提升生产效率、降低成本、提高竞争力的关键。通过MES管理系统实现数据集成和分析,能够对产品制造过程的各个环节进行可视化控制,从设计、制造、质量、物流等环节全面掌控信息,实现…...

Vuex有几种属性以及它们的意义
有五种,分别是 State、 Getter、Mutation 、Action、 Module。 一、State Vuex 使用单一状态树——是的,用一个对象就包含了全部的应用层级状态。至此它便作为一个“唯一数据源 (SSOT)”而存在。这也意味着,每个应用将仅仅包含一个 store 实…...

PRBP20P-10/250C-EB、PRDP6G-10/30-CB电液比例直动式先导减压阀放大板
PRDP6P-10/30-CB、PRDP6R-10/50-DC、PRDP6G-10/30-CC、PRDP6P-10/50-CB、PRDP6R-10/30-CC、PRDP6G-10/30-CB电液比例直动式先导减压阀 PRBP10P-10/50C-EB、PRBP20P-10/100C-EC、PRBP30P-10/150C-EB、PRBP20P-10/250C-EB、PRBP10P-10/315C-EC、PRBP30P-10/350C-EB电液比例柱塞平…...

GDB之常见缩写命令(十九)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...
)
MarkText快捷键(随时补充中)
MarkText快捷键 ctrl1:一号标题 (需要手动在【左上角】-【file】-【preferences】-【Key Bindings】-【 Transform into Heading 1】手动调整,先将【Switch tab to the 1st】占用快捷键删除才能在下面添加) ctrlg:添加…...
)
每日一题 1601最多可达成的换楼请求数目(子集模版)
题目 1601 我们有 n 栋楼,编号从 0 到 n - 1 。每栋楼有若干员工。由于现在是换楼的季节,部分员工想要换一栋楼居住。 给你一个数组 requests ,其中 requests[i] [fromi, toi] ,表示一个员工请求从编号为 fromi 的楼搬到编号为…...
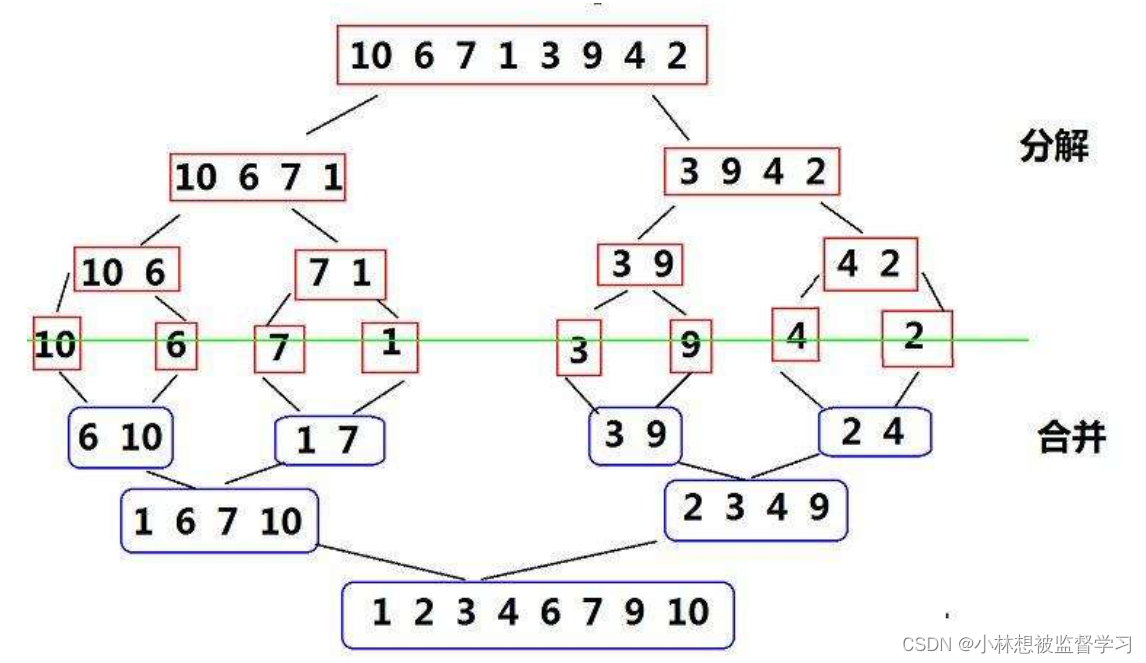
排序算法-归并排序
属性 归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序&#…...

vue3 整合 springboot 打完整jar包
前端 .env.developmen VITE_APP_BASE_URL/api.env.production VITE_APP_BASE_URL/axios 配置 axios.defaults.baseURL import.meta.env.VITE_APP_BASE_URLpackage.json "scripts": {"dev": "vite --mode development","build": &…...

依赖倒转原则是什么?
依赖倒转原则(Dependency Inversion Principle)是面向对象设计中的另一个基本原则,它是由Robert C. Martin提出的,它的中心思想是面向接口编程,该原则指出高层模块不应该依赖于低层模块,两者都应该依赖于抽…...

什么是GPT与MBR
GPT(GUID Partition Table)和MBR(Master Boot Record)是两种不同的磁盘分区表格式。 MBR是一种较早的磁盘分区表格式,它使用512字节的扇区作为存储空间。MBR分区表可以定义最多4个主分区,每个主分区都可以…...

前后端开发接口联调对接参数
前言 一个完整的互联网系统项目,需要前后端配合,进行上线,针对前端开发者,现在互联网主流的项目都是前后端分离 也就是后端负责提供数据接口,前端负责UI界面数据渲染 凡是在前台数据展示与用户交互的,都是由前端来实现的,而数据来源是由后台服务提供的 在浏览器c端能够发送后端…...

定时任务框架-xxljob
1.定时任务 spring传统的定时任务Scheduled,但是这样存在这一些问题 : 做集群任务的重复执行问题 cron表达式定义在代码之中,修改不方便 定时任务失败了,无法重试也没有统计 如果任务量过大,不能有效的分片执行 …...
idea项目配置三大步
场景: 使用 idea 打开一个新项目的时候,想让项目迅速跑起来, 其实只需要下面简单三步: 1. 首先,配maven 2. 其次,配置 jdk 这里配置 project 就行了,不用管Modules中的配置。 3. 最后&#…...

学会SpringMVC之自定义注解各种场景应用,提高开发效率及代码质量
目录 一、简介 ( 1 ) 是什么 ( 2 ) 分类 ( 3 ) 作用 二、自定义注解 ( 1 ) 如何自定义注解 ( 2 ) 场景演示 场景一(获取类与方法上的注解值) 场景二( 获取类属性上的注解属性值 ) 场景三( 获取参数修…...
步态识别常见模块解读及代码实现:基于OpenGait框架
步态识别常见模块解读及代码实现:基于OpenGait框架 最近在看步态识别相关论文,但是因为记忆力下降的原因,老是忘记一些内容。因此记录下来方便以后查阅,仅供自己学习参考,没有背景知识和论文介绍。 目录 步态识别常见…...

前端八股文之“闭包”
一、定义 一句话概括闭包:能够访问函数内部变量的函数与这个变量的组合构成了闭包结构。如下代码 function fuc1(){let num 999return function fuc2(){console.log(num)}}fuc1()(); 如代码所示,fuc2和父级变量num构成了一个闭包环境。 二、原理 子…...

数据可视化:掌握数据领域的万金油技能
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。 🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、…...
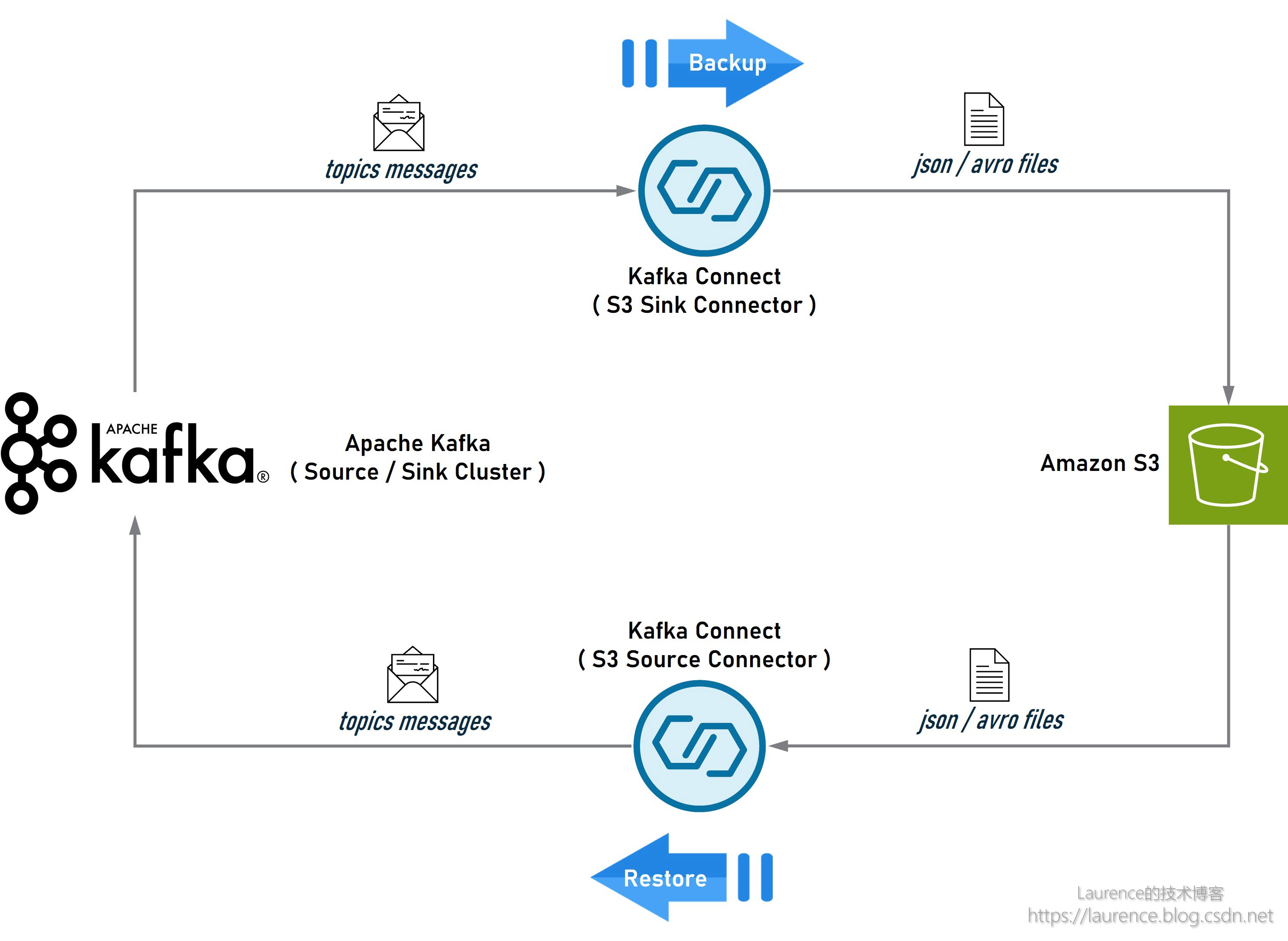
Apache Kafka 基于 S3 的数据导出、导入、备份、还原、迁移方案
在系统升级或迁移时,用户常常需要将一个 Kafka 集群中的数据导出(备份),然后在新集群或另一个集群中再将数据导入(还原)。通常,Kafka集群间的数据复制和同步多采用 Kafka MirrorMaker࿰…...

事务管理AOP
事务管理 事务回顾 概念:事务是一组操作的集合,它是一个不可分割的工作单位,这些操作要么同时成功,要么同时失败 操作: 开启事务:一组操作开始前,开启事务-start transaction/be…...

多模态大模型评测框架VLMEvalKit:从原理到实践,实现高效公平的模型评估
1. 项目概述:一个开箱即用的多模态大模型评测工具箱 如果你最近在折腾多模态大模型,不管是想复现论文里的SOTA结果,还是想给自己训的模型做个“体检”,又或者只是想快速对比一下ChatGPT-4V、Gemini Pro Vision这些闭源巨头的实力…...

AI Agent社区平台架构实战:React 19 + Cloudflare边缘计算全栈开发
1. 项目概述:一个为AI Agent时代设计的社区平台如果你最近在折腾AI Agent,或者想找一些靠谱的AI工具,那你可能已经发现了一个痛点:信息太散了。教程、工具推荐、硬件配置、社区交流,这些内容散落在各个论坛、博客和社交…...
)
拒绝纸上谈兵!深度拆解 hello-agents:从零开始构建你的第一个智能体 (AI Agent)
发布日期: 2026-02-10标签: #AIAgent #智能体 #Datawhale #大模型 #Python #人工智能入门一、 引言如果说 2024 年是大模型的元年,那么 2026 年则是 AI Agent(智能体) 的应用爆发年。单纯的对话已经无法满足需求&#…...

手机号逆向查询QQ号:3分钟快速掌握Python查询技巧
手机号逆向查询QQ号:3分钟快速掌握Python查询技巧 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 你是否曾需要快速验证手机号对应的QQ账号?手机号查QQ号工具是一个简单高效的Python开源项目,让你…...
)
简化环境配置:OpenClaw v2.7.1 部署与实操教学(新手适用)
🚀 Windows 极速部署 OpenClaw v2.7.1 教程|5 分钟搭建本地 AI 智能体 在开源 AI 智能体快速普及的当下,OpenClaw(小龙虾)凭借本地运行、零代码操控、全场景自动化能力,成为办公与技术人群的效率工具&…...

连接器选型五大雷区:从故障数据到设计落地的实战手册
许多硬件团队的失效分析报告显示,连接器引发的现场故障占比长期居高不下,且症状极其隐蔽——间歇性黑屏、信号丢包、热插拔烧毁……这些问题往往在原型测试阶段难以复现,直到批量出货后才集中爆发。本文从电源、高速信号、射频三类典型应用出…...

青龙脚本自动化:五款实用脚本助你轻松管理日常任务
青龙脚本自动化:五款实用脚本助你轻松管理日常任务 【免费下载链接】huajiScript 滑稽の青龙脚本库 项目地址: https://gitcode.com/gh_mirrors/hu/huajiScript 在当今快节奏的数字时代,自动化工具已成为提升效率的必备利器。如果你正在寻找一款能…...

GraphQL在后端开发中的应用与优势
在现代后端开发领域,GraphQL作为一种新兴的API查询语言,正迅速改变着开发者构建和交互数据的方式。与传统的RESTful API相比,GraphQL提供了一种更灵活、高效的数据获取机制,使前端能够精准地请求所需数据,避免了过度获…...

VSCode安装clang-format插件及使用
VSCode安装clang-format插件及使用1.clang-format插件安装2.安装真正的格式化工具clang-format3.生成.clang-format配置文件并修改4.修改配置文件4.1全局配置文件修改4.2工作空间配置文件修改5.格式化代码1.clang-format插件安装 插件安装方式分为直接安装和离线安装两种。 直…...

EdgeDB终极性能优化指南:5个关键磁盘IO配置大幅提升数据读写速度 [特殊字符]
EdgeDB终极性能优化指南:5个关键磁盘IO配置大幅提升数据读写速度 🚀 【免费下载链接】edgedb Gel supercharges Postgres with a modern data model, graph queries, Auth & AI solutions, and much more. 项目地址: https://gitcode.com/gh_mirro…...