混合精度训练,FP16加速训练,降低内存消耗
-
计算机中的浮点数表示,按照IEEE754可以分为三种,分别是半精度浮点数、单精度浮点数和双精度浮点数。三种格式的浮点数因占用的存储位数不同,能够表示的数据精度也不同。
-

-
Signed bit用于控制浮点数的正负,0表示正数,1表示负数;
-
Exponent部分用于控制浮点数的大小,以2为底进行指数运算;
-
Significand部分用于控制浮点数的精度,存储浮点数的有效数字。
-
-
默认深度学习模型训练过程中都是使用fp32。
-
使用fp16能带来什么好处:
-
减少显存占用:现在模型越来越大,当你使用Bert这一类的预训练模型时,往往显存就被模型及模型计算占去大半,当想要使用更大的Batch Size的时候会显得捉襟见肘。由于FP16的内存占用只有FP32的一半,自然地就可以帮助训练过程节省一半的显存空间。
-
加快训练和推断的计算:与普通的空间时间Trade-off的加速方法不同,FP16除了能节约内存,还能同时节省模型的训练时间。在大部分的测试中,基于FP16的加速方法能够给模型训练带来多一倍的加速体验。
-
张量核心的普及:硬件的发展同样也推动着模型计算的加速,随着Nvidia张量核心(Tensor Core)的普及,16bit计算也一步步走向成熟,低精度计算也是未来深度学习的一个重要趋势。
-
x=FP16((−1)Signed∗2Exponent−15∗(1+SigniFicand210))x=FP16((-1)^{Signed}*2^{Exponent-15}*(1+\frac{SigniFicand}{2^{10}})) x=FP16((−1)Signed∗2Exponent−15∗(1+210SigniFicand))
-
x=FP32((−1)S∗2E−127∗1.SF)x=FP32((-1)^S*2^{E-127}*1.SF) x=FP32((−1)S∗2E−127∗1.SF)
-
x=FP64((−1)S∗2E−1023∗1.SF)x=FP64((-1)^S*2^{E-1023}*1.SF) x=FP64((−1)S∗2E−1023∗1.SF)
-
FP16最大值为
0 11110 1111111111,其计算方式为- (−1)0∗230−15∗1.1111111111=1∗215∗(1+2−1+2−2+...+2−10)=65504(-1)^0*2^{30-15}*1.1111111111\\ =1*2^{15}*(1+2^{-1}+2^{-2}+...+2^{-10})\\ =65504 (−1)0∗230−15∗1.1111111111=1∗215∗(1+2−1+2−2+...+2−10)=65504
-
如果 Exponent 位全部为0:
- 如果 Significand位 全部为0,则表示数字 0
-
如果 Exponent 位全部位1:
-
如果 fraction 位 全部为0,则表示 ±inf
-
如果 fraction 位 不为0,则表示 NAN
-
-
-
使用fp16能带来什么问题:
-
溢出错误
-
半精度浮点数有两个字节存储。由于FP16的动态范围比FP32的动态范围要狭窄很多,因此在计算过程中很容易出现上溢出(Overflow )和下溢出(Underflow)的错误,溢出之后就会出现“Nan”的问题。在深度学习中,由于激活函数的的梯度往往要比权重梯度小,更易出现下溢出的情况。
-
表示范围
-
运算结果大于最大正数时称为正上溢,小于绝对值最大负数时称为负上溢,正上溢和负上溢统称上溢。数据一旦产生上溢,计算机必须中断运算操作,进行溢出处理。
-
当运算结果在0至最小正数之间时称为正下溢,在0至绝对值最小负数之间时称为负下溢,正下溢和负下溢统称下溢。 数据下溢时,浮点数值趋于零,计算机仅将其当作机器零处理。
-

-
-
-
舍入误差
-
Rounding Error指示是当网络模型的反向梯度很小,一般FP32能够表示,但是转换到FP16会小于当前区间内的最小间隔,会导致数据溢出。如0.00006666666在FP32中能正常表示,转换到FP16后会表示成为0.000067,不满足FP16最小间隔的数会强制舍入。
-
解决方案
-
输入FP16的数据,部分运算继续使用FP16计算,得到FP16结果
-
将部分运算转成 FP32类型进行计算,得到 FP32中间结果
-
输出时将所有的FP32数据转换为FP16
-
-
-
-
混合精度训练,指代的是单精度 float和半精度 float16 混合训练。为了想让深度学习训练可以使用FP16的好处,又要避免精度溢出和舍入误差。于是可以通过FP16和FP32的混合精度训练(Mixed-Precision),混合精度训练过程中可以引入权重备份(Weight Backup)、损失放大(Loss Scaling)、精度累加(Precision Accumulated)三种相关的技术。
-
权重备份(Weight Backup)
-
权重备份主要用于解决舍入误差的问题。其主要思路是把神经网络训练过程中产生的激活activations、梯度 gradients、中间变量等数据,在训练中都利用FP16来存储,同时复制一份FP32的权重参数weights,用于训练时候的更新。
-
在计算过程中所产生的权重weights,激活activations,梯度gradients等均使用 FP16 来进行存储和计算,其中权重使用FP32额外进行备份。
-
深度模型中,lr * gradent的参数值可能会非常小,利用FP16来进行相加的话,则很可能会出现舍入误差问题,导致更新无效。因此通过将权重weights拷贝成FP32格式,并且确保整个更新过程是在 fp32 格式下进行的。即:
- weight32=weight32+lr∗graident16weight_{32}=weight_{32}+lr * graident_{16} weight32=weight32+lr∗graident16
-
权重用FP32格式备份一次,那岂不是使得内存占用反而更高了呢?是的,额外拷贝一份weight的确增加了训练时候内存的占用。 但是实际上,在训练过程中内存中分为动态内存和静态内容,其中动态内存是静态内存的3-4倍,主要是中间变量值和激活activations的值。而这里备份的权重增加的主要是静态内存。只要动态内存的值基本都是使用FP16来进行存储,则最终模型与整网使用FP32进行训练相比起来, 内存占用也基本能够减半。
-
-
损失缩放(Loss Scaling)
-
如果仅仅使用FP32训练,模型收敛得比较好,但是如果用了混合精度训练,会存在网络模型无法收敛的情况。原因是梯度的值太小,使用FP16表示会造成了数据下溢出(Underflow)的问题,导致模型不收敛。于是需要引入损失缩放(Loss Scaling)技术。
-
为了解决梯度过小数据下溢的问题,对前向计算出来的Loss值进行放大操作,也就是把FP32的参数乘以某一个因子系数后,把可能溢出的小数位数据往前移,平移到FP16能表示的数据范围内。根据链式求导法则,放大Loss后会作用在反向传播的每一层梯度,这样比在每一层梯度上进行放大更加高效。
-
-
精度累加(Precision Accumulated)
- 在混合精度的模型训练过程中,使用FP16进行矩阵乘法运算,利用FP32来进行矩阵乘法中间的累加(accumulated),然后再将FP32的值转化为FP16进行存储。简单而言,就是利用FP16进行矩阵相乘,利用FP32来进行加法计算弥补丢失的精度。这样可以有效减少计算过程中的舍入误差,尽量减缓精度损失的问题。
再将FP32的值转化为FP16进行存储**。简单而言,就是利用FP16进行矩阵相乘,利用FP32来进行加法计算弥补丢失的精度。这样可以有效减少计算过程中的舍入误差,尽量减缓精度损失的问题。
相关文章:
混合精度训练,FP16加速训练,降低内存消耗
计算机中的浮点数表示,按照IEEE754可以分为三种,分别是半精度浮点数、单精度浮点数和双精度浮点数。三种格式的浮点数因占用的存储位数不同,能够表示的数据精度也不同。 Signed bit用于控制浮点数的正负,0表示正数,1表…...

每天五分钟机器学习:新的大规模的机器学习机制——在线学习机制
本文重点 本节课程我们将学习一种新的大规模的机器学习机制--在线学习机制。在线学习机制让我们可以模型化问题。在线学习算法指的是对数据流进行学习而非离线的静态数据集的学习。许多在线网站都有持续不断的用户流,对于每一个用户,网站希望能在不将数据存储到数据库中便顺…...
计算机组成原理错题
静态RAM(SRAM)和动态RAM(DRAM)的基本电路图不同,因此可以通过观察存储器的基本电路图来判断它属于哪一类。 静态RAM的基本电路图包括一个存储单元和一个数据选择器。每个存储单元由一个触发器(flip-flop&a…...

数学基础整理
收纳一些天天忘的结论qwq 线性求逆元 invi(p−pi)invpmodiinv_i(p-\dfrac{p}{i})\times inv_{p\bmod i}invi(p−ip)invpmodi 卡特兰数 组合数公式:HnC2nn−C2nn−1H_nC_{2n}^n-C_{2n}^{n-1}HnC2nn−C2nn−1 递推式:HnHn−1(4n−2)n1H_n\d…...
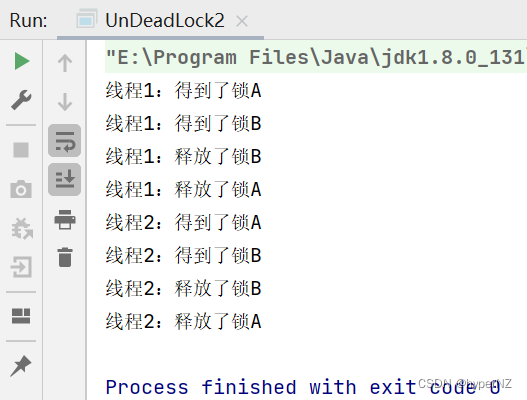
JavaWeb11-死锁
目录 1.死锁定义 1.1.代码演示 1.2.使用jconsole/jvisualvm/jmc查看死锁 ①使用jconsole:最简单。 ②使用jvisualvm:(Java虚拟机)更方便,更直观,更智能,更高级,是合适的选择。 …...
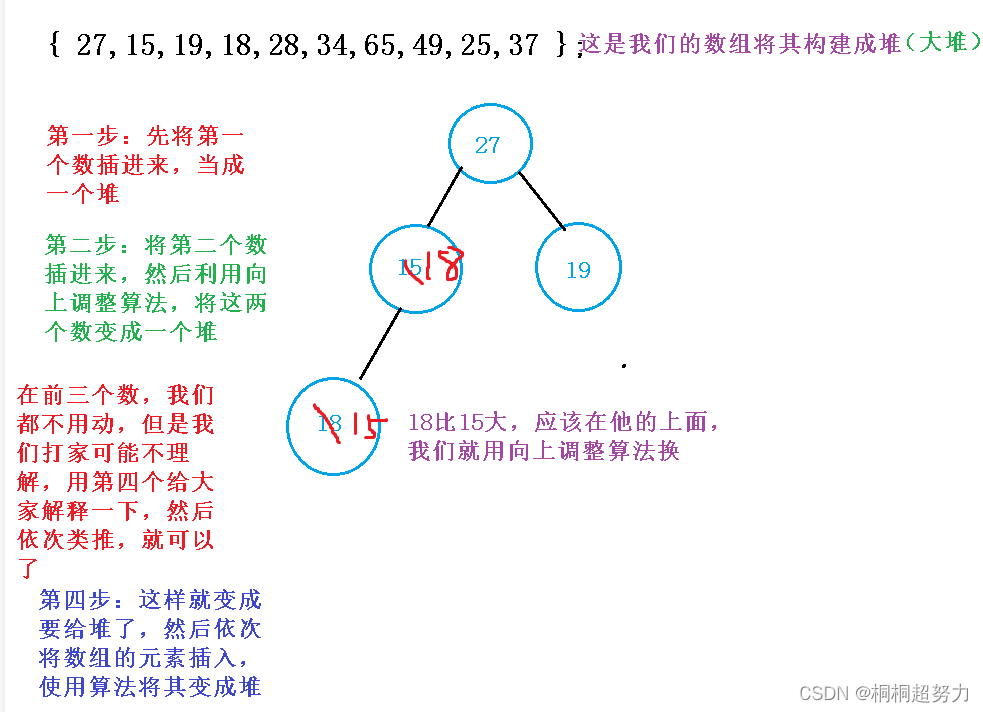
堆的概念和结构以及堆排序
前言 普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结 构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统 虚拟进程地址空间中的堆是两回事,…...
【Linux学习笔记】1.Linux 简介及安装
前言 本章介绍Linux及其安装方法。 Linux 简介 Linux 内核最初只是由芬兰人林纳斯托瓦兹(Linus Torvalds)在赫尔辛基大学上学时出于个人爱好而编写的。 Linux 是一套免费使用和自由传播的类 Unix 操作系统,是一个基于 POSIX 和 UNIX 的多…...

代码练习2~
在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。def …...

微信小程序 之 云开发
一、概念1. 传统开发模式2. 新开发模式 ( 云开发模式 )3. 传统、云开发的模式对比4. 传统、云开发的项目流程对比5. 云开发的定位1. 个人的项目或者想法,不想开发服务器,直接使用云开发2. 某些公司的小程序项目是使用云开发的,但是不多&#…...

程序员的三门课,学习成长笔记
最近是有了解到一本好书,叫做程序员的三门课在这本书的内容当中我也确实汲取到了很多前辈能够传达出来的很多关于程序员职业规划以及成长路线上的见解,令我受益匪浅,故此想要把阅读完的每一章节结合自己的工作经验做一个精细化的小结…...

[技术经理]01 程序员最优的成长之路是什么?
00前言 谈起程序员的职业规划,针对大部分的职场人士,最优的成长之路应该是走技术管理路线,而不是走技术专家路线。 01关键的一步 中国自古就有“学而优则仕”的传统,发展到今天,在我们的现代企业里面,尤…...
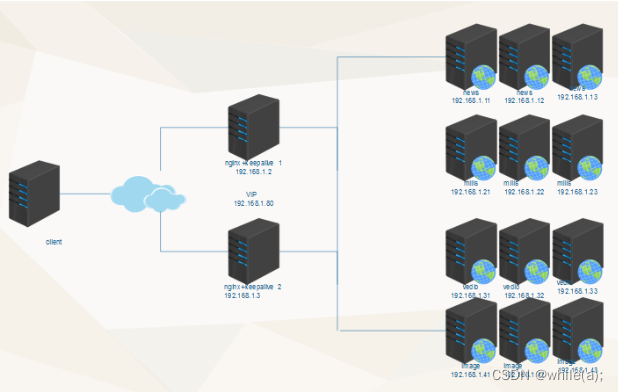
linux集群技术(三)--七层负载均衡-nginx
nginx特点nginx优势、缺点生产架构nginx 7层负载均衡语法示例nginx负载均衡算法测试案例生产案例 1.nginx特点 1. 功能强大,性能卓越,运行稳定。 2. 配置简单灵活。 3. 能够自动剔除工作不正常的后端服务器。 4. 上传文件使用异步模式。client---nginx---web1 web2 web3 lvs同…...
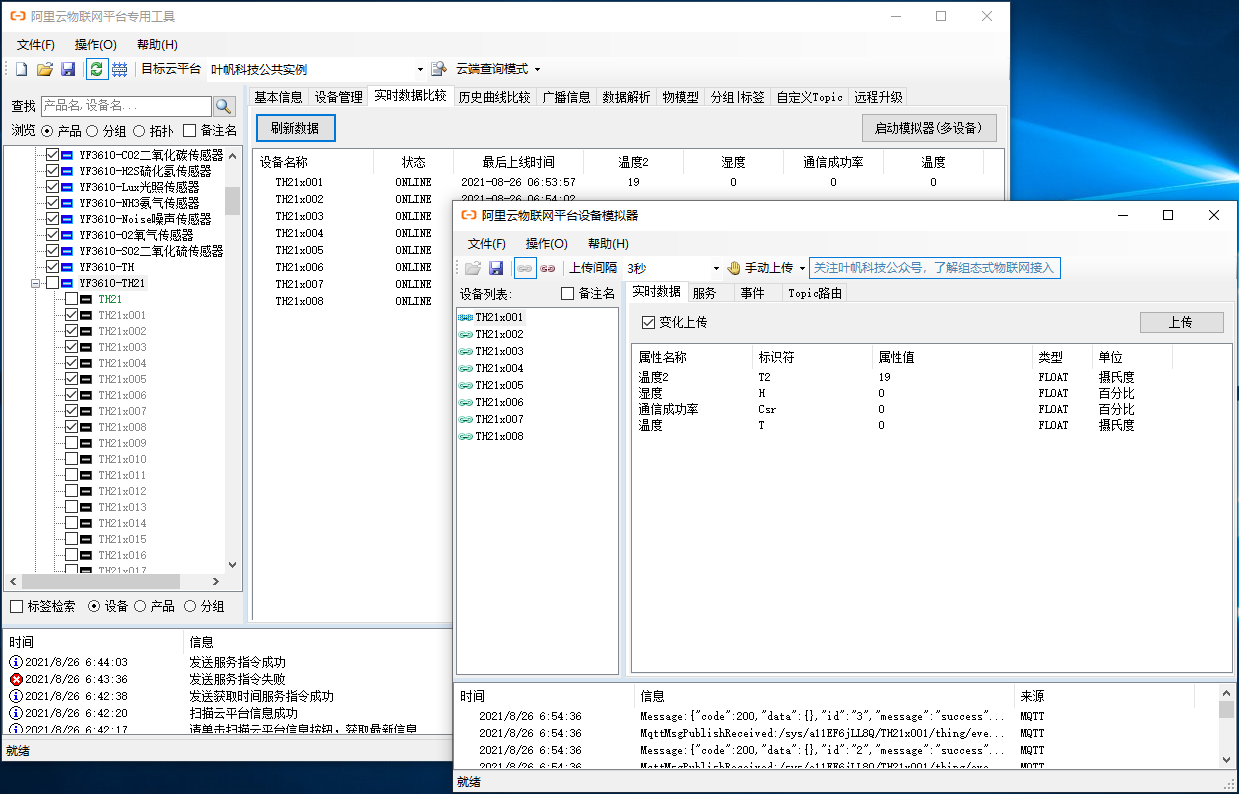
阿里云物联网平台设备模拟器
在使用阿里云物联网平台过程中,如果开始调试没有实际的物理设备,可以考虑在阿里云物联网平台使用官方自带的模拟器进行调试。不过也可以通过叶帆科技开发的阿里云物联网平台设备模拟器AliIoTSimulator进行调试,AliIoTSimulator可以独立运行&a…...
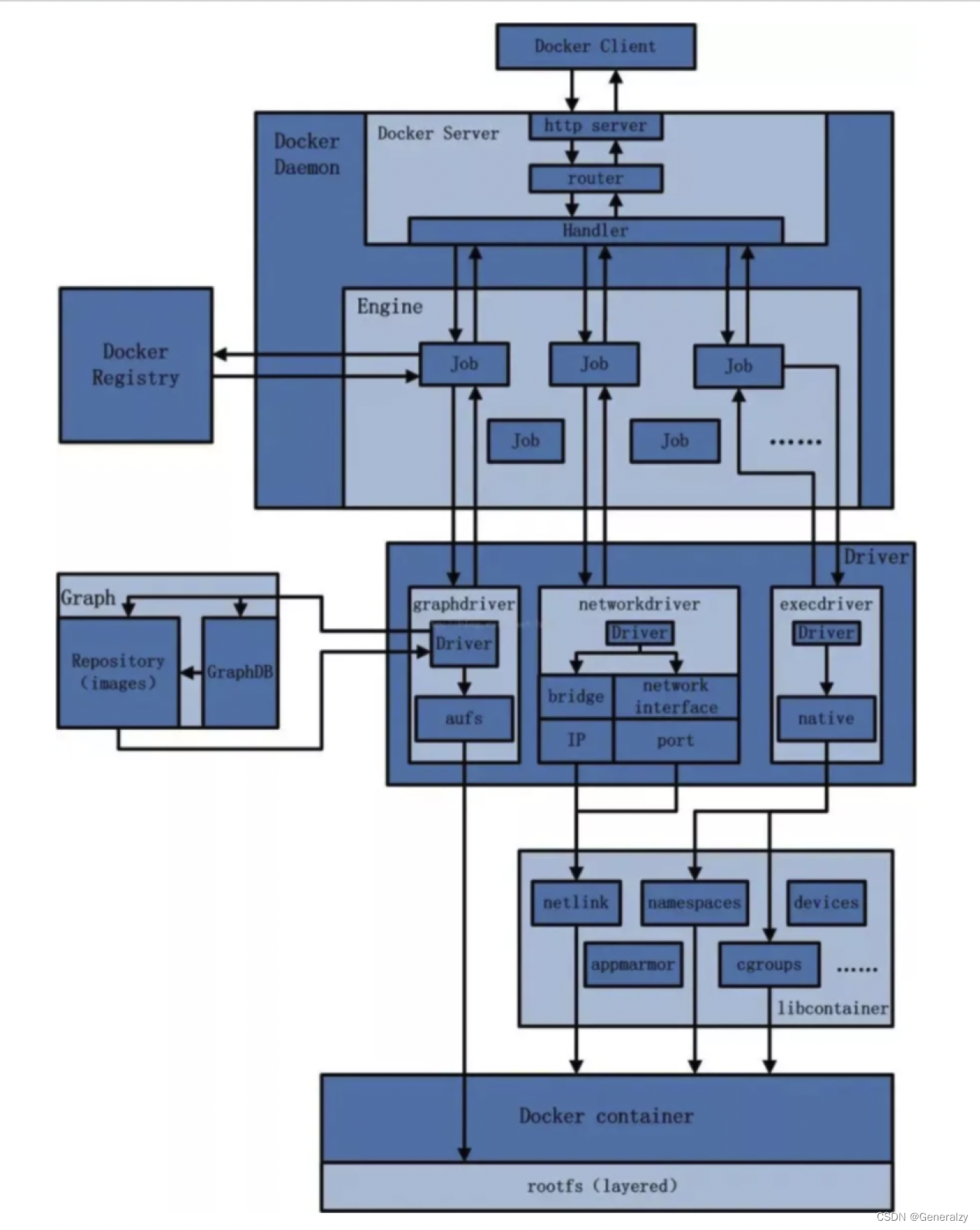
docker全解
目录说明docker简介为什么是docker容器与虚拟机比较容器发展简史传统虚拟机技术容器虚拟化技术docker能干什么带来技术职级的变化开发/运维(Devops)新一代开发工程师Docker应用场景why docker?docker的优势docker和dockerHub官网Docker安装CentOS Docker…...
Vue3 基础
Vue3 基础 概述 Vue (发音为 /vjuː/,类似 view) 是一款用于构建用户界面的 JavaScript 框架。它基于标准 HTML、CSS 和 JavaScript 构建,并提供了一套声明式的、组件化的编程模型,帮助你高效地开发用户界面。无论是简单还是复杂的界面&…...
【Linux】冯.诺依曼体系结构与操作系统
环境:centos7.6,腾讯云服务器Linux文章都放在了专栏:【Linux】欢迎支持订阅🌹冯.诺依曼体系结构什么是冯诺依曼体系结构?我们如今的计算机比如笔记本,或者是服务器,基本上都遵循冯诺依曼体系结构…...

WSO2 apim 多租户来区分api
WSO2 apim 多租户来区分api1. Tenant1.1 Add new tenant1.2 Add Role/User1.3 Published Api2. Delete Teant3. AwakeningWSO2安装使用的全过程详解: https://blog.csdn.net/weixin_43916074/article/details/127987099. Official Document: Managing Tenants. 1. Tenant 1.1 …...
)
TodoList(Vue前端经典项目)
TodoList主要是包含了CRUD功能,本地存储功能(loaclStorage)总结:全选按纽可以通过forEach循环来讲数据中的isCheck中的false删除实现就通过传递id,然后根据filter循环将符合条件的数据返回成数组,然后将返回…...

【扫盲】数字货币科普对于完全不了解啥叫比特币的小伙伴需要的聊天谈资
很多人并不清楚,我们时常听说的比特币,以太坊币,等等这些东西到底是一场骗局还是一场货币革命? 下面就围绕这数字货币的历史以及一些应用场景开始分析这个问题。 一、 开端 一切从2008年中本聪(Satoshi Nakamoto&…...

算法学习笔记:双指针
前言: 用于记录总结刷题过程中遇到的同类型问题 双指针问题及用法总结 1. 总结 双指针常用于遍历连序性对象(如数组、链表等)时,使用两个或多个指针进行单向遍历及相应的操作。避免多层循环,降低算法的时间复杂度。 …...

BiliBiliCCSubtitle终极指南:如何3秒下载B站CC字幕并转换SRT格式
BiliBiliCCSubtitle终极指南:如何3秒下载B站CC字幕并转换SRT格式 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还在为无法下载B站CC字幕而烦恼吗&am…...

Rusted PackFile Manager:免费创建全面战争模组的终极工具
Rusted PackFile Manager:免费创建全面战争模组的终极工具 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: https:/…...

四款免费抓包工具实战选型指南:HTTPS解密与跨平台调试
1. 抓包这件事,为什么90%的人从一开始就搞错了方向 “免费抓包工具有哪些?”——这是我在技术群、论坛和私信里被问得最多的问题之一。但每次看到这个问题,我都会先反问一句:“你到底想抓什么包?” 不是所有抓包场景…...

中国车牌生成器:5分钟快速创建逼真车牌图像的终极指南
中国车牌生成器:5分钟快速创建逼真车牌图像的终极指南 【免费下载链接】chinese_license_plate_generator 中国车牌生成器 项目地址: https://gitcode.com/gh_mirrors/ch/chinese_license_plate_generator 在计算机视觉和AI识别系统开发中,获取高…...

终极指南:如何用OpenCore Legacy Patcher让旧Mac焕发新生,完美运行最新macOS
终极指南:如何用OpenCore Legacy Patcher让旧Mac焕发新生,完美运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥…...

3步突破微信限制:wechat-need-web插件终极使用手册
3步突破微信限制:wechat-need-web插件终极使用手册 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 你是否经常遇到微信网页版无法正常使用…...

信用评分中的算法公平性:从理论到实践的全面解析
1. 项目概述:当信用评分遇上算法公平性在金融科技领域,信用评分模型早已不是新鲜事物。从传统的逻辑回归到如今复杂的梯度提升树和神经网络,机器学习模型凭借其强大的预测能力,已经成为银行和金融机构进行信贷决策、管理风险的核心…...

UFLUX v2.0:融合P模型与XGBoost的GPP估算混合建模框架
1. 项目概述与核心价值如果你正在从事全球变化生态学、碳循环研究或者遥感应用领域的工作,那么“如何更准确地估算陆地生态系统的总初级生产力”这个问题,大概率是你绕不开的挑战。总初级生产力,也就是我们常说的GPP,它衡量的是植…...

BetterGI原神自动化工具:5分钟轻松上手指南,彻底解放你的游戏时间!
BetterGI原神自动化工具:5分钟轻松上手指南,彻底解放你的游戏时间! 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集…...

服务器被入侵后如何应急响应:安全运维实战指南
1. 这不是演习:当告警邮件凌晨三点弹出来时,你手边该有什么 “服务器CPU持续100%、SSH登录异常增多、/tmp目录下出现陌生可执行文件”——这类告警我见过太多次。不是在靶场演练,不是在CTF赛题里,而是真实发生在某次金融客户核心A…...