阅读笔记7——Focal Loss
一、提出背景
当前一阶的物体检测算法,如SSD和YOLO等虽然实现了实时的速度,但精度始终无法与两阶的Faster RCNN相比。是什么阻碍了一阶算法的高精度呢?何凯明等人将其归咎于正、负样本的不平衡,并基于此提出了新的损失函数Focal Loss及网络结构RetinaNet,在与同期一阶网络速度相同的前提下,其检测精度比同期最优的二阶网络还要高。
为了解决一阶网络中样本的不均衡问题,何凯明等人首先改善了分类过程中的交叉熵函数,提出了可以动态调整权重的Focal Loss。
二、交叉熵损失
1. 标准交叉熵损失
标准的交叉熵函数,其形式如式(2-1)所示:
CE(p,y)={−log(p)if(y=1)−log(1−p)otherwise(2-1)CE(p,y)=\left\{\begin{matrix} -log(p) & if(y=1) & \\ -log(1-p) & otherwise & \end{matrix}\right.\tag{2-1}CE(p,y)={−log(p)−log(1−p)if(y=1)otherwise(2-1)
公式中,ppp代表样本在该类别的预测概率,yyy代表样本标签。可以看出,当标签为1时,ppp越接近1,则损失越小;标签为0时,ppp越接近0,则损失越小,符合优化的方向。
为了方便表示,按照式(2-2)将ppp标记为ptp_{t}pt:
pt={pif(y=1)1−potherwise(2-2)p_{t}=\left\{\begin{matrix} p & if(y=1) & \\ 1-p & otherwise & \end{matrix}\right.\tag{2-2}pt={p1−pif(y=1)otherwise(2-2)
则交叉熵可以表示为式(2-3)的形式:
CE(p,y)=CE(pi)=−log(pi)(2-3)CE(p,y)=CE(p_{i})=-log(p_{i})\tag{2-3}CE(p,y)=CE(pi)=−log(pi)(2-3)
标准的交叉熵中所有样本的权重都是相同的,因此如果正、负样本不均衡,大量简单的负样本会占据主导地位,少量的难样本与正样本会起不到作用,导致精度变差。
2. 平衡交叉熵损失
为了改善样本的不平衡问题,平衡交叉熵在标准的基础上增加了一个系数αt\alpha _{t}αt来平衡正、负样本的权重,αt\alpha _{t}αt由超参数α\alphaα按照式(2-4)计算得来,α\alphaα取值在[0,1]区间内。
αt={αif(y=1)1−αotherwise(2-4)\alpha _{t}=\left\{\begin{matrix} \alpha & if(y=1) & \\ 1-\alpha & otherwise & \end{matrix}\right.\tag{2-4}αt={α1−αif(y=1)otherwise(2-4)
有了αt\alpha _{t}αt,平衡交叉熵损失公式如式(2-5)所示:
CE(pt)=−αtlog(pt)(2-5)CE(p_{t})=-\alpha _{t}log(p_{t})\tag{2-5}CE(pt)=−αtlog(pt)(2-5)
尽管平衡交叉熵损失改善了正、负样本间的不平衡,但由于其缺乏对难易样本的区分,因此没有办法控制难易样本之间的不均衡。
三、Focal Loss
Focal Loss为了同时调节正、负样本与难易样本,提出了如式(3-1)所示的损失函数:
FL(pt)=−αt(1−pt)γlog(pt)(3-1)FL(p_{t})=-\alpha_{t}(1-p_{t})^{\gamma}log(p_{t})\tag{3-1}FL(pt)=−αt(1−pt)γlog(pt)(3-1)
对于该损失函数,又如下3个属性:
- 与平衡交叉熵类似,引入了αt\alpha_{t}αt权重,为了改善正负样本的不均衡,可以提升一些精度。
- (1−pt)γ(1-p_{t})^{\gamma}(1−pt)γ是为了调节难易样本的权重。当一个边框被误分类时,ptp_{t}pt较小,则(1−pt)γ(1-p_{t})^{\gamma}(1−pt)γ接近于1,其损失几乎不受影响;当ptp_{t}pt接近于1时,表明其分类预测较好,是简单样本,(1−pt)γ(1-p_{t})^{\gamma}(1−pt)γ接近于0,因此其损失被调低了。
- γ\gammaγ是一个调制因子,γ\gammaγ越大,简单样本损失的贡献度会越低,
四、RetinaNet
为了验证Focal Loss的效果,何凯明等人还提出了一个一阶物体检测结构RetinaNet,其结构如图4-1所示:
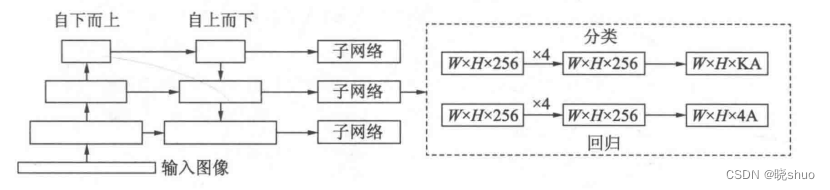
- 在Backbone部分,RetinaNet利用ResNet与FPN构建了一个多尺度特征的特征金字塔。
- RetinaNet使用了类似于Anchor的预选框,在每一个金字塔层,使用了9个大小不同的预选框。
- 分类子网络:分类子网络为每一个预选框预测其类别,因此其输出特征大小为KA×W×H,A默认为9,K代表类别数。中间使用全卷积网络与ReLU激活函数,最后利用Sigmoid函数输出预测值。
- 回归子网络:回归子网络与分类子网络平行,预测每一个预测框的偏移量,最终输出特征的大小为4A×W×W。与当前主流工作不同的是,两个子网络没有权重的共享。
相关文章:
阅读笔记7——Focal Loss
一、提出背景 当前一阶的物体检测算法,如SSD和YOLO等虽然实现了实时的速度,但精度始终无法与两阶的Faster RCNN相比。是什么阻碍了一阶算法的高精度呢?何凯明等人将其归咎于正、负样本的不平衡,并基于此提出了新的损失函数Focal L…...

ZCMU--5009: 龙虎斗
轩轩和开开正在玩一款叫《龙虎斗》的游戏,游戏的棋盘是一条线段,线段上有n个兵营(自左至右编号1~n),相邻编号的兵营之间相隔1厘米,即棋盘为长度为n-1厘米的线段。i号兵营里有ci位工兵。 下面图1为n 6的示例: 轩轩在左侧…...
创建项目(React+umi+typeScript)
项目框架搭建的方式react脚手架Ant-design官网一、安装方式npm二、安装方式yarn三、安装方式umi devreact脚手架 命令行: npx create-react-app myReactName项目目录结构: 浏览器运行,端口号3000: Ant-design官网 一、安装方…...
FISCO BCOS(二十七)———java操作WeBase
一、搭建fiscobcos环境 1.1、安装jdk1.8 https://blog.csdn.net/weixin_46457946/article/details/1232435131.2、安装mysql https://blog.csdn.net/weixin_46457946/article/details/1232447361.3、安装python https://blog.csdn.net/weixin_46457946/article/details/123…...

失眠时还在吃它?有风险,你了解过吗
失眠,是当代人的通病。所以解决失眠也成了刚需,市面上开始出现各种助眠产品。有商业机构调查发现,62%的90后消费者曾买过助眠产品,其中人气选手就是褪黑素。褪黑素本身就是人体天然存在的,与睡眠有关的物质,…...
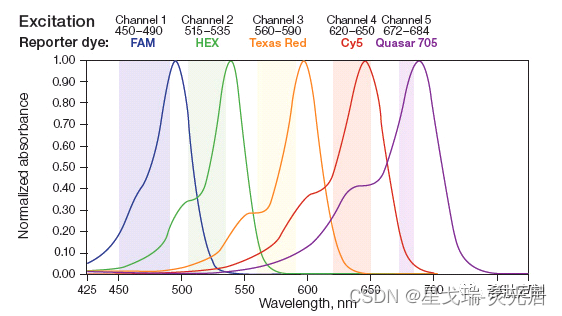
星戈瑞收藏Sulfo-CY7 amine/NHS ester/maleimide小鼠活体成像染料标记反应
关于小鼠活体成像,就一定要提到CY活性染料标记反应: 用不同的活性基团的Cyanine菁染料和相应的活性基团的生物分子或小分子药物发生反应,链接到一起。 根据需要标记的抗原、抗体、酶、多肽等分子所带的可标记基团的种类(氨基、醛…...

守护最后一道防线:Coremail邮件安全网关推出邮件召回功能
根据Coremail邮件安全大数据中心2022年Q4季报显示,2021年CAC识别钓鱼邮件1.81亿,2022年上升至2.25亿,增幅高达24.1%。 这表明2022年平均每天有61万7088封钓鱼邮件被接收及发出,企业用户面临潜在经济损失不可估量。 尤其是活跃至今…...

Python实战之小说下载神器(二)整本小说下载:看小说不用这个程序,我实在替你感到可惜*(小说爱好者必备)
前言 这次的是一个系列内容给大家讲解一下何一步一步实现一个完整的实战项目案例系列之小说下载神器(二)(GUI界面化程序) 单章小说下载保存数据——整本小说下载 你有看小说“中毒”的经历嘛?小编多多少少还是爱看小说…...
ChatGPT三个关键技术
情景学习(In-context learning) 对于一些LLM没有见过的新任务,只需要设计一些任务的语言描述,并给出几个任务实例,作为模型的输入,即可让模型从给定的情景中学习新任务并给出满意的回答结果。这种训练方式能…...
考试系统 (springboot+vue前后端分离)
系统图片 下载链接 地址: http://www.gxcode.top/code 介绍 一款多角色在线培训考试系统,系统集成了用户管理、角色管理、部门管理、题库管理、试题管理、试题导入导出、考试管理、在线考试、错题训练等功能,考试流程完善。 技术栈 Spr…...

ChatGPT告诉你:项目管理能干到60岁吗?
早上好,我是老原。这段时间最火的莫过于ChatGPT,从文章创作到论文写作,甚至编程序,简直厉害的不要不要的。本以为过几天热度就自然消退了,结果是愈演愈烈,热度未减……大家也从一开始得玩乐心态,…...

Python自动化测试框架【Allure-pytest功能特性介绍】
Python自动化测试框架【Allure-pytest功能特性介绍】 目录:导读 前言 生成报告 测试代码 目录结构 Allure特性 Environment Categories Fixtures and Finalizers allure.attach 总结 写在最后 前言 Allure框架是一个灵活的轻量级多语言测试报告工具&am…...

ToB 产品拆解—Temu 商家管理后台
Temu 是拼多多旗下的跨境电商平台,平台产品于9月1日上线,9月1日到9月15日为测试期,之后全量全品类放开售卖。短短几个月的时间,Temu 在 App Store 冲上了购物类榜首,引起了国内的广泛关注。本文将以 B 端产品经理的角度…...

Android Studio的笔记--socket通信
Android socket通信Socket协议android socket 代码清单文件开启服务服务端:TCPServerService客户端:TCPClientServicelogSocket Socket 作为一种通用的技术规范,首次是由 Berkeley 大学在 1983 为 4.2BSD Unix 提供的,后来逐渐演化…...

@Async 注解
异步执行 异步调用就是不用等待结果的返回就执行后面的逻辑;同步调用则需要等待结果再执行后面的逻辑。 通常我们使用异步操作时都会创建一个线程执行一段逻辑,然后把这个线程丢到线程池中去执行,代码如下所示。 ExecutorService executor…...

Redis:缓存穿透、缓存雪崩和缓存击穿(未完待续)
Redis的缓存穿透、缓存雪崩和缓存击穿一. 缓存穿透1.1 概念1.2 造成的问题1.3 解决方案1.4 案例:查询商铺信息(缓存穿透的实现)二. 缓存雪崩2.1 概念2.2 解决方案三. 缓存击穿(热点key)3.1 概念3.2 解决方案3.3 案例&a…...

HIVE 基础(四)
目录 分桶(Bucket) 设定属性 定义分桶 案例 建表语句 表数据 上传到数据 创建分桶语句 加载数据 分桶抽样(Sampling) 随机抽样---整行数据 随机抽样---指定列 随机抽样---百分比 随机抽样---抽取行数 Hive视图&#…...

整型在内存中的存储(详细剖析大小端)——“C”
各位CSDN的uu们你们好呀,今天小雅兰的内容是整型在内存中的存储噢,现在,就让我们进入整型在内存中的存储的世界吧 数据类型详细介绍 整型在内存中的存储:原码、反码、补码 大小端字节序介绍及判断 数据类型介绍 前面我们已经学…...
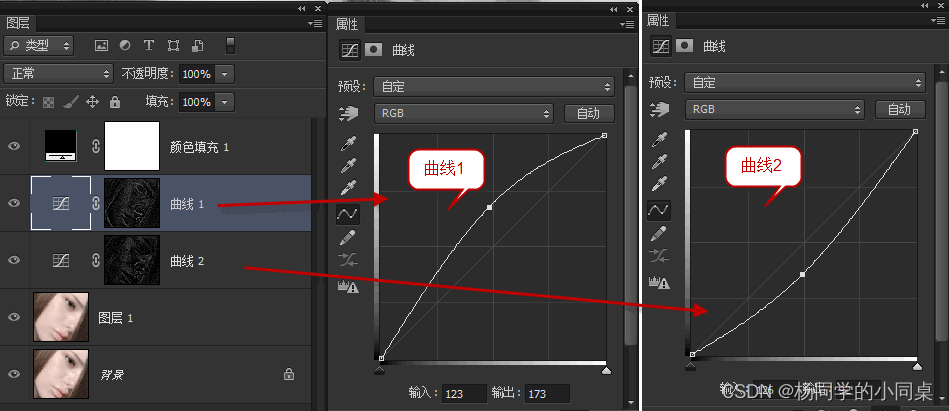
PS_高低频和中性灰——双曲线
高低频 高低频磨皮:把皮肤分成两个图层,一层是纹理层也就是皮肤的毛孔。 一层是皮肤光滑层没有皮肤细节。 高频”图层为细节层,我们用图章工具修高频 “低频”图层为颜色层,我们用混合画笔修低频 原理:修颜色亮度光影…...
Vim 命令速查表
Vim 命令速查表 简介:Vim 命令速查表,注释化 vimrc 配置文件,经典 Vim 键盘图,实用 Vim 书籍,Markdown 格式,目录化检索,系统化学习,快速熟悉使用! Vim 官网 | Vim | Vim…...

Node.js 项目如何集成 Taotoken 实现稳定的大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 项目如何集成 Taotoken 实现稳定的大模型调用 对于 Node.js 后端服务开发者而言,在项目中引入大模型能力正变得…...

如何在VSCode中快速配置专业级R语言开发环境:终极实战指南
如何在VSCode中快速配置专业级R语言开发环境:终极实战指南 【免费下载链接】vscode-R R Extension for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-R 你是否正在寻找一个现代化的R语言开发环境,能够提供智能代码补全…...

3分钟快速解锁WeMod高级功能:Wand-Enhancer完整使用指南
3分钟快速解锁WeMod高级功能:Wand-Enhancer完整使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否曾经在使用WeMod时࿰…...

观察Taotoken在多模型间自动路由与容灾切换的实际响应情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型间自动路由与容灾切换的实际响应情况 在构建依赖大模型服务的应用时,服务的连续性与稳定性是开发…...

粒子滤波算法在非线性估计中的应用【附程序】
✨ 长期致力于非线性系统、参数估计、递归贝叶斯估计、粒子滤波算法、重采样、相关系数、谐波模型研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于…...

Node.js 服务如何无缝接入 Taotoken 并管理多个模型的 API 调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 服务如何无缝接入 Taotoken 并管理多个模型的 API 调用 在构建现代 Node.js 后端服务时,集成多种大语言模型能…...

5分钟掌握暗黑破坏神2存档编辑:免费开源工具完全攻略
5分钟掌握暗黑破坏神2存档编辑:免费开源工具完全攻略 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为暗黑2刷装备而烦恼?想快速体验不同build却不想重复练级?d2s-editor这款暗黑破坏神2…...
)
ChatGPT商业计划书写作实战指南(投资人内部评分表首次公开)
更多请点击: https://codechina.net 第一章:ChatGPT商业计划书的核心价值与定位 ChatGPT商业计划书并非通用模板的简单套用,而是面向AI原生业务场景的战略性交付物,其核心价值在于将技术能力、市场需求与商业化路径进行精准对齐。…...

终极指南:如何使用d2dx开源工具让经典《暗黑破坏神2》在现代PC上完美运行
终极指南:如何使用d2dx开源工具让经典《暗黑破坏神2》在现代PC上完美运行 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d…...

小红书数据采集终极指南:5种身份伪装策略破解反爬限制
小红书数据采集终极指南:5种身份伪装策略破解反爬限制 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&…...