大数据技术准备
Hbase:HBase 底层原理详解(深度好文,建议收藏) - 腾讯云开发者社区-腾讯云
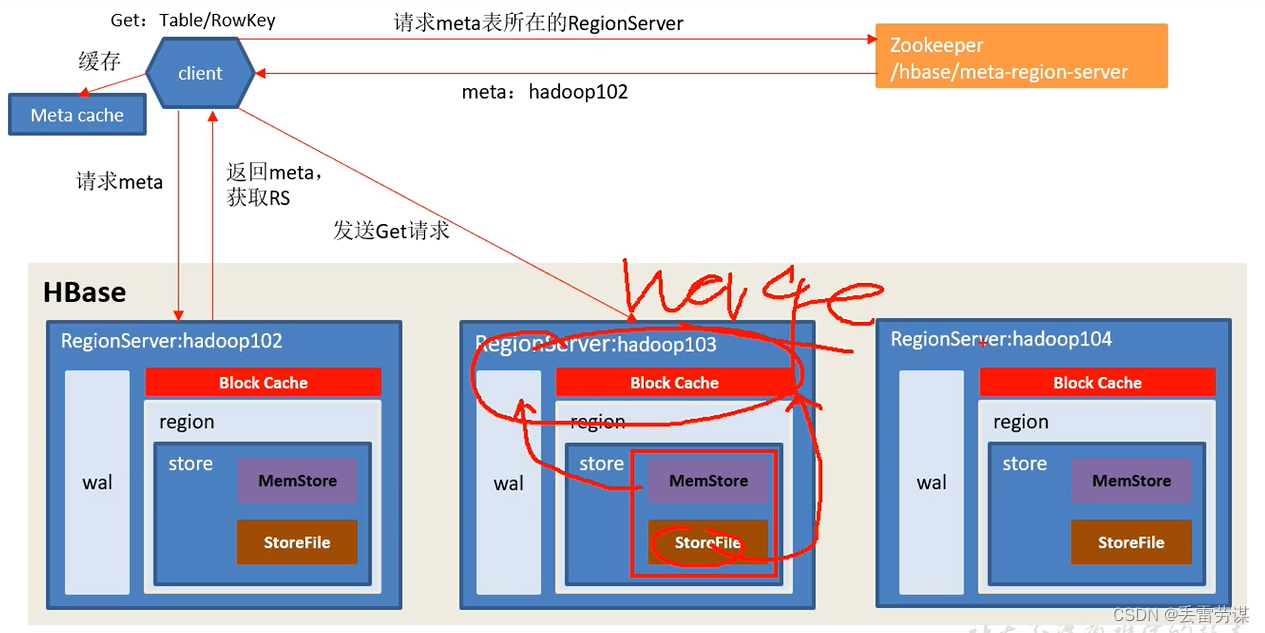
Hbase架构图

同一个列族如果有多个store,那么这些store在不同的region
Hbase写流程(读比写慢)

MemStore Flush

Hbase读流程:
先读block Cache,若命中了结果,则不读磁盘;若没有命中结果,那么同时读MemStore(内存)和StoreFile(磁盘),将从磁盘读取的结果放到内存(Block Cache)中,然后和从MemStore读取结果进行merge(比较时间戳返回最新数据)
Compact操作:
该操作非常消耗资源,一般关闭该操作的自动执行。有需要的话,手动执行。
数据真正的删除时机:
Flush时会删数据,合并文件时会删除数据。
HBase 不直接操作文件,而是通过 HDFS(Hadoop Distributed File System)进行数据存储。因此,HBase 中的数据删除并不涉及直接删除底层文件。相反,HBase 通过维护一系列称为“HFile”的底层数据文件来管理数据。
当执行删除操作时,HBase 实际上是将删除标记(Tombstone)写入相应的 HFile 中。这个删除标记会告诉 HBase 在查询时跳过这些被标记为删除的数据。随着时间的推移,HBase 会定期进行合并(compaction)操作,将多个 HFile 合并为更大的文件,并在此过程中清理掉已经被标记为删除的数据块。
由于合并操作是由 HBase 自动触发和处理的,因此具体删除标记从被写入到实际清理的时间会有一定的延迟。这个延迟取决于多个因素,包括表的负载、合并策略以及系统配置等。
总之,HBase 中删除数据的时间可以说是异步的,并且受到 HBase 的自动合并和清理机制的影响。根据具体的情况,可以通过调整 HBase 的合并策略和配置参数来控制删除操作对存储空间的影响和清理速度。
Split操作:
split时机:
HBase 的拆分(split)是根据一定的策略和条件自动触发和执行的。以下是一些常见的 HBase 拆分时机:
-
Region 大小超过设定的阈值:HBase 监测每个 Region 的大小,并在某个 Region 的大小超过预设的阈值(称为 split size)时触发拆分。这个阈值可以通过配置参数进行设置,通常以字节数或行数来表示。
-
基于 Region 数量的拆分:当集群中的 Region 数量达到了预设的最大 Region 数量时,HBase 可能会触发拆分操作。这是一种基于负载均衡的策略,确保数据在不同的 RegionServer 上更加均匀地分布。
-
定期拆分:HBase 还可以按照一定的时间间隔或频率定期执行拆分操作。这样可以避免 Region 过大导致查询性能下降,同时也有助于数据的均衡分布。
-
手动触发拆分:除了自动触发,HBase 还支持手动触发拆分操作。管理员可以通过 HBase Shell 或 API 来手动指定需要拆分的 Region,以满足特定的需求。
需要注意的是,拆分操作是一个比较昂贵的操作,可能会对系统产生一些开销。因此,拆分的时机需要谨慎选择,避免过于频繁或不必要的拆分操作。可以通过定期监测和调整配置参数来优化拆分策略,以适应具体的业务需求和系统负载情况。
Split流程:
在 HBase 中,split(拆分)是指将一个大的 Region 拆分成多个较小的子 Region 的过程。这个过程是自动进行的,由 HBase 系统根据一定的策略和条件触发和执行的。
下面是 HBase 的拆分流程概述:
-
监测 Region 大小:HBase 运行时会监测每个 Region 的大小。当一个 Region 的大小超过了预设的阈值(称为 split size),就会被标记为需要拆分。
-
触发拆分:一旦有一个或多个需要拆分的 Region 被标记,HMaster(HBase 的主节点)会收到这些拆分请求,并决定如何进行拆分操作。
-
拆分策略:HBase 提供了两种拆分策略:按行键范围拆分和按 Region 数量拆分。
-
按行键范围拆分:HBase 将会根据 Region 当前的行键范围,计算出新的行键范围并生成新的子 Region。
-
按 Region 数量拆分:HBase 将会根据当前 Region 的数量和预设的最大 Region 数量,将一个大的 Region 均匀地拆分成多个子 Region。
-
-
创建新的子 Region:根据选定的拆分策略,HBase 会创建新的子 Region,并将其分配给适当的 RegionServer 进行处理。
-
数据拷贝:新的子 Region 在创建后会开始从父 Region 拷贝数据。这个过程可能需要一些时间,具体取决于数据量和系统的负载情况。
-
更新元数据:拆分完成后,HBase 会更新相应的元数据(例如 .META. 表)以反映新的子 Region 的信息和位置。
整个拆分流程是自动进行的,并且由 HBase 系统根据配置和内部算法来管理和执行。拆分操作可以使数据在集群中更均衡地分布,提高系统的性能和可扩展性。
相关文章:
大数据技术准备
Hbase:HBase 底层原理详解(深度好文,建议收藏) - 腾讯云开发者社区-腾讯云 Hbase架构图 同一个列族如果有多个store,那么这些store在不同的region Hbase写流程(读比写慢) MemStore Flush Hbas…...

【力扣周赛】第 362 场周赛(⭐差分匹配状态压缩DP矩阵快速幂优化DPKMP)
文章目录 竞赛链接Q1:2848. 与车相交的点解法1——排序后枚举解法2——差分数组⭐差分数组相关题目列表📕1094. 拼车1109. 航班预订统计2381. 字母移位 II2406. 将区间分为最少组数解法1——排序贪心优先队列解法2——差分数组 2772. 使数组中的所有元素…...
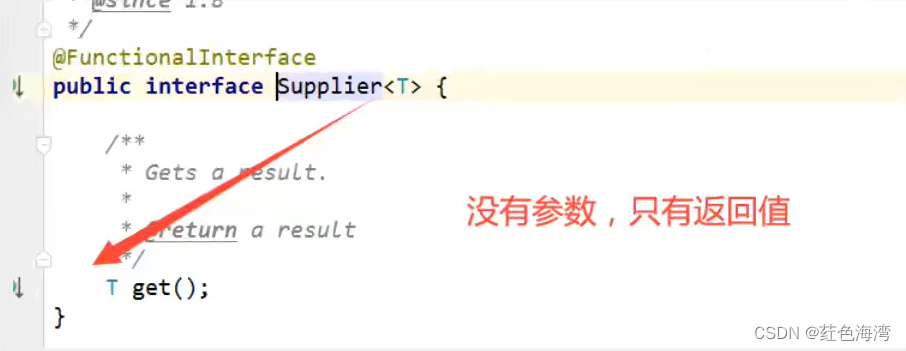
四大函数式接口(重点,必须掌握)
新时代程序员必须要会的 :lambda表达式、链式编程、函数式接口、Stream流式计算 什么是函数式接口 1.函数型接口 package com.kuang.function;import java.util.function.Function;/*** Function函数型接口 有一个输入参数,有一个输出* 只要是函数式接口…...
2023Web前端逻辑面试题
1、现有9个小球,已知其中一个球比其它的重,如何只用天平称2次就找出该球? ①把9个球分成三份,三个一份; ②拿出其中两份进行称量;会分为两种情况 若拿出的两份小球称量结果,重量相等;…...

uniapp中git忽略node_modules,unpackage文件
首先在当前项目的命令行新建.gitignore文件: touch .gitignore再在编辑器中打开该文件,并在该文件中加入需要忽略的文件名: node_modules/ .project unpackage/ .DS_Store 提示:如果以前提交过unpackage文件的话,需…...

Json-Jackson和FastJson
狂神: 测试Jackson 纯Java解决日期格式化 设置ObjectMapper FastJson: 知乎:Jackson使用指南 1、常见配置 方式一:yml配置 spring.jackson.date-format指定日期格式,比如yyyy-MM-dd HH:mm:ss,或者具体的…...

RK3588 点亮imx586摄像头
一.硬件原理图 mipi摄像头硬件确认点: 1.供电:5V,2.8V,1.2V,1.8V,reset脚(硬拉3.3,上电的时候从低到高),pwron脚外接 3.3V。 2,时钟:MCLKOUT是2…...
C++---继承
继承 前言继承的概念及定义继承的概念继承定义继承关系和访问限定符 基类和派生类对象赋值转换继承中的作用域派生类的默认成员函数继承与友元继承与静态成员**多重继承**多继承下的类作用域菱形继承虚继承使用虚基类 支持向基类的常规类型转换 前言 在需要写Father类和Mother…...

使用新版Maven-mvnd快速构建项目
目前我们项目的构建方式多数是 maven、gradle,但是 maven 相对 gradle 来说,构建速度较慢,特别是模块相对较多的时候,构建速度更加明显。但是我们将项目由 maven 替换为 gradle 相对来说会比较麻烦,成本较高。于是我们…...
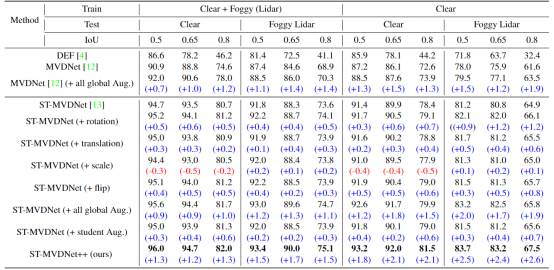
【ICASSP 2023】ST-MVDNET++论文阅读分析与总结
主要是数据增强的提点方式。并不能带来idea启发,但对模型性能有帮助 Challenge: 少有作品应用一些全局数据增强,利用ST-MVDNet自训练的师生框架,集成了更常见的数据增强,如全局旋转、平移、缩放和翻转。 Contributi…...
MySQL 面试题——MySQL 基础
目录 1.什么是 MySQL?有什么优点?2.MySQL 中的 DDL 与 DML 是分别指什么?3.✨数据类型 varchar 与 char 有什么区别?4.数据类型 BLOB 与 TEXT 有什么区别?5.DATETIME 和 TIMESTAMP 的异同?6.✨MySQL 中 IN …...
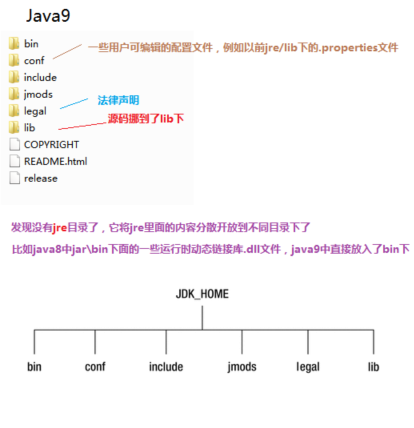
JDK9特性——概述
文章目录 引言JDK9特性概述JDK9的改变JDK和JRE目录变化总结 引言 JAVA8 及之前,版本都是特性驱动的版本更新,有重大的特性产生,然后进行更新。 JAVA9开始,JDK开始以时间为驱动进行更新,以半年为周期,到时…...

征战开发板从无到有(三)
接上一篇,翘首已盼的PCB板子做好了,管脚约束信息都在PCB板上体现出来了,很满意,会不会成为爆款呢,嘿嘿,来,先看看PCB裸板美图 由于征战开发板电路功能兼容小梅哥ACX720,大家可以直…...
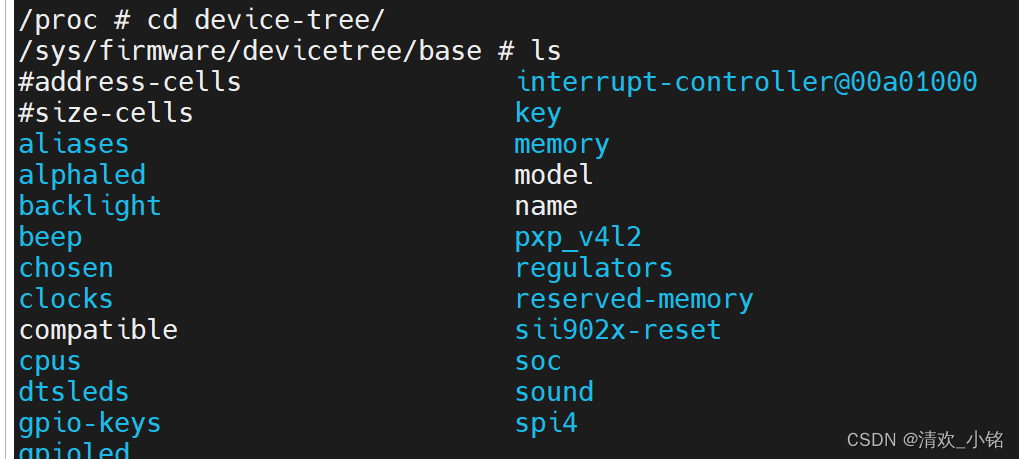
Linux设备树详细学习笔记
参考文献 参考视频 开发板及程序 原子mini 设备树官方文档 设备树的基本概念 DT:Device Tree //设备树 FDT: Flattened Device Tree //开放设备树,起源于OpenFirmware (所以后续会见到很多OF开头函数) dts: device tree source的缩写 //设备树源码 dtsi: device …...
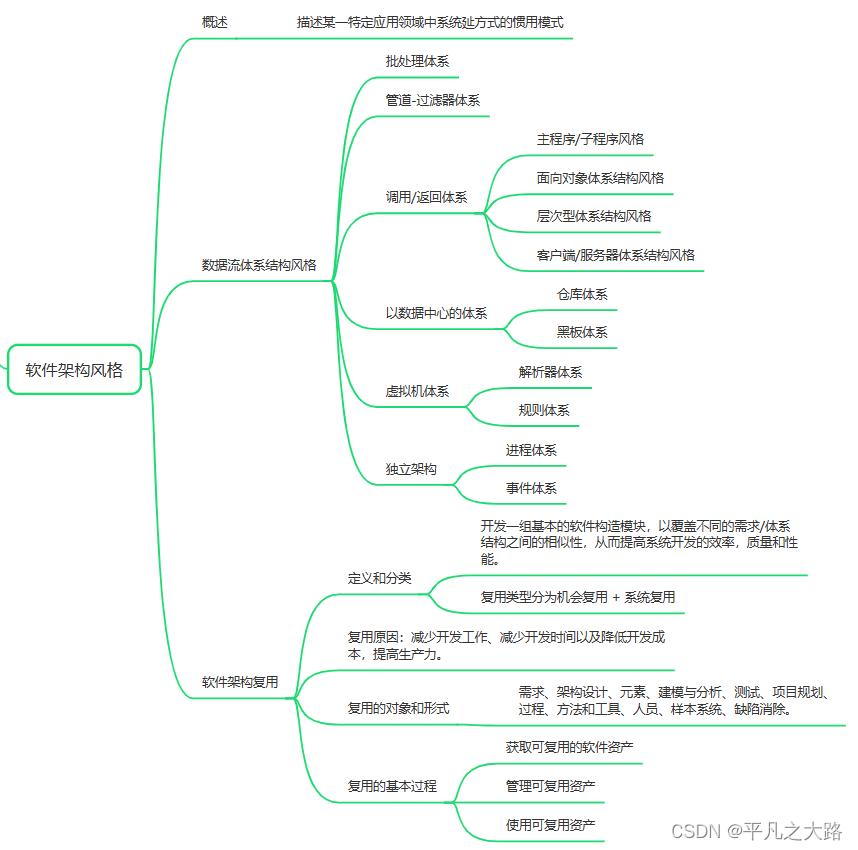
【系统架构】系统架构设计基础知识
导读:本文整理关于系统架构设计基础知识来构建系统架构知识体系。完整和扎实的系统架构知识体系是作为架构设计的理论支撑,基于大量项目实践经验基础上,不断加深理论体系的理解,从而能够创造新解决系统相关问题。 目录 1、软件架…...
快递、外卖、网购自动定位及模糊检索收/发件地址功能实现
概述 目前快递、外卖、团购、网购等行业 :为了简化用户在收发件地址填写时的体验感,使用辅助定位及模糊地址检索来丰富用户的体验 本次demo分享给大家;让大家理解辅助定位及模糊地址检索的功能实现过程,以及开发出自己理想的作品…...

Springboot后端导入导出excel表
一、依赖添加 操作手册:Hutool — 🍬A set of tools that keep Java sweet. <!--hutool工具包--><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.20</versio…...
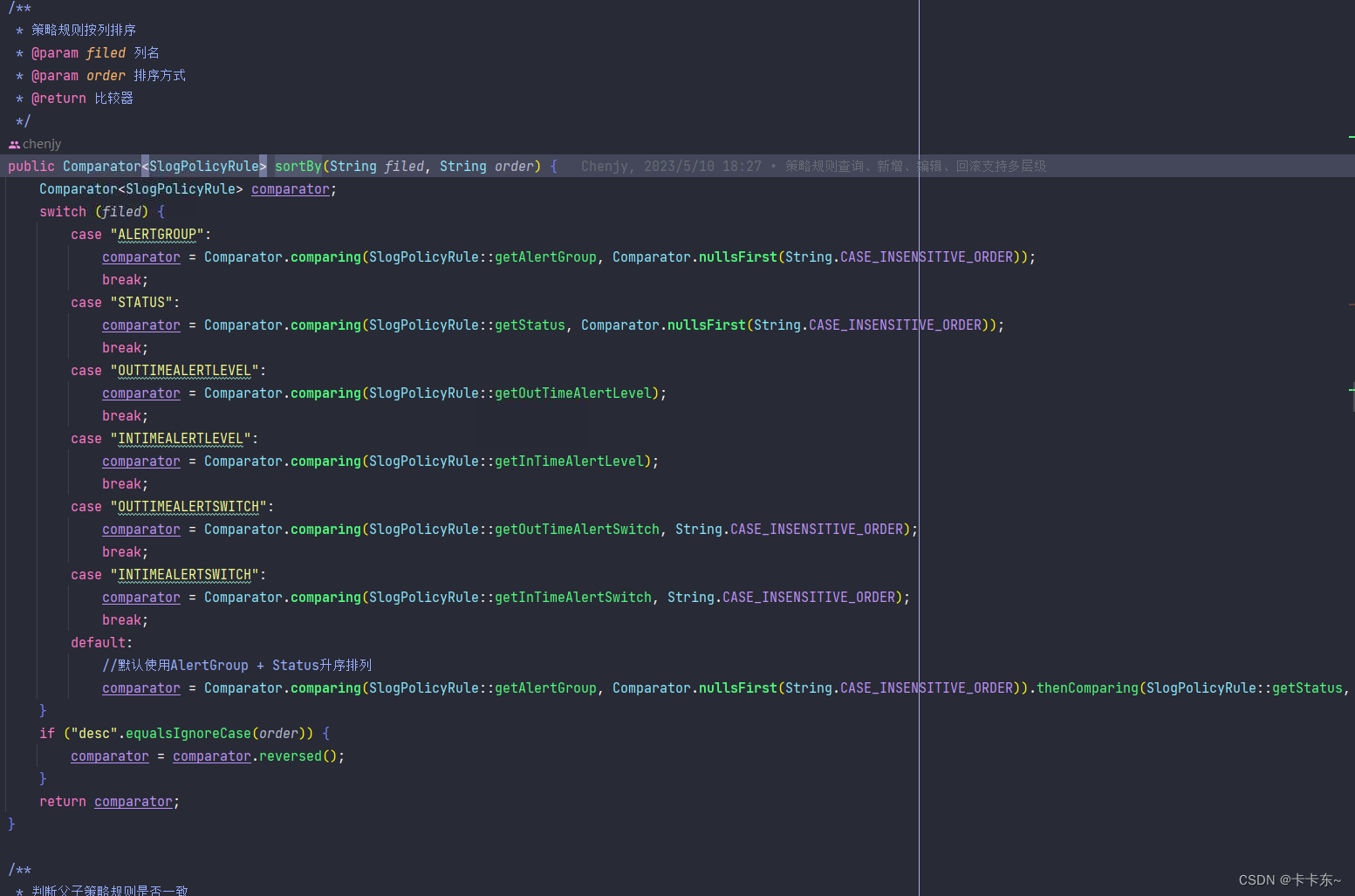
通过stream流实现分页、模糊搜索、按列过滤功能
通过stream实现分页、模糊搜索、按列过滤功能 背景逻辑展示示例代码 背景 在有一些数据通过数据库查询出来后,需要经过一定的逻辑处理才进行前端展示,这时候需要在程序中进行相应的分页、模糊搜索、按列过滤了。这些功能通过普通的逻辑处理可能较为繁琐…...

webpack:系统的了解webpack一些核心概念
文章目录 webpack 如何处理应用程序?何为webpack模块chunk?入口(entry)输出(output)loader开发loader 插件(plugin)简介流程插件开发:Tapable类监听(watching)compiler 钩子compilation 钩子compiler和compilation创建自定义 插件 loader和pl…...

Unreal Engine Loop 流程
引擎LOOP 虚幻引擎的启动是怎么一个过程。 之前在分析热更新和加载流程过程中,做了一个图。记录一下!! 
Pearcleaner技术深度解析:macOS应用清理的架构设计与实现原理
Pearcleaner技术深度解析:macOS应用清理的架构设计与实现原理 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner Pearcleaner是一款面向技术开发者和…...

LeetCode 118. 杨辉三角
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。在「杨辉三角」中,每个数是它左上方和右上方的数的和。示例 1:输入: numRows 5 输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]示例 2:输入: numRows 1 输出: [[1]]提示:1 < numRows…...

建筑消防防火分区专用钢质卷帘门
在现代建筑消防设计体系中,防火分区的科学划分与有效分隔,是控制火灾蔓延、减少人员伤亡与财产损失的核心环节。建筑消防防火分区专用钢质卷帘门,作为固定式防火分隔的重要配套设施,凭借稳定的耐火性能、可靠的启闭功能与强适配性…...

ESP32开发踩坑记:从HID库缺失到PlatformIO环境搭建的全流程复盘
ESP32开发踩坑记:从HID库缺失到PlatformIO环境搭建的全流程复盘 那天深夜,我盯着屏幕上"hid.h: No such file or directory"的报错信息,意识到自己掉进了嵌入式开发的第一个坑。原本想用Arduino做个体感鼠标来提升游戏体验…...

ROS2机械臂实战:ros2_control、moveit2与move_group核心问题排查与解决
1. ROS2机械臂开发中的常见问题与调试思路 最近在做一个ROS2机械臂项目,用到了ros2_control、moveit2和move_group这几个核心组件。说实话,从零开始搭建这套系统踩了不少坑,特别是硬件接口初始化、控制器配置这些环节。今天就把我遇到的一些典…...

Keil 5 Debug隐藏技巧:手把手教你配置软件仿真,避开‘no read permission’等常见报错
Keil 5 Debug高阶实战:从软件仿真配置到逻辑分析仪深度应用 在嵌入式开发领域,Keil MDK作为ARM架构的主流开发环境,其Debug功能尤其是软件仿真模块往往被开发者低估。许多工程师仅停留在基础调试层面,对逻辑分析仪等高级功能要么望…...
)
别再乱点鼠标了!用netsh advfirewall命令搞定Windows防火墙,效率翻倍(附常用场景命令清单)
Windows防火墙命令行实战:netsh advfirewall高阶应用指南 每次看到同事在图形界面里一层层点击"控制面板→系统和安全→Windows Defender防火墙→高级设置"时,我都忍不住想递给他一个命令行窗口。作为IT运维老手,我早已习惯用netsh…...

实战复盘:我是如何通过一个SSRF漏洞,利用Gopher协议拿下内网Redis的
从SSRF到内网Redis入侵:一次真实渗透测试的深度剖析 那天下午,我正在对某企业Web应用进行常规安全评估。一个看似普通的文件下载接口引起了我的注意——它接受URL参数并返回对应资源内容。直觉告诉我,这里可能存在SSRF漏洞。接下来的72小时&a…...

3分钟搞定!VideoDownloadHelper视频下载插件终极安装使用指南
3分钟搞定!VideoDownloadHelper视频下载插件终极安装使用指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网页…...

照片元数据管理终极指南:3步告别繁琐手动操作
照片元数据管理终极指南:3步告别繁琐手动操作 【免费下载链接】ExifToolGui A GUI for ExifTool 项目地址: https://gitcode.com/gh_mirrors/ex/ExifToolGui 你是否曾因数百张照片的拍摄时间错误而头痛不已?是否在为大量图片添加版权信息时感到力…...