LeNet-5
目录
一、知识点
二、代码
三、查看卷积层的feature map
1. 查看每层信息
2. show_featureMap.py
背景:LeNet-5是一个经典的CNN,由Yann LeCun在1998年提出,旨在解决手写数字识别问题。

一、知识点
1. iter()+next()
iter():返回迭代器
next():使用next()来获取下一条数据
data = [1, 2, 3]
data_iter = iter(data)
print(next(data_iter)) # 1
print(next(data_iter)) # 2
print(next(data_iter)) # 32. enumerate
enumerate(sequence,[start=0]) 函数用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
start--下标起始位置的值。
data = ['zs', 'ls', 'ww']
print(list(enumerate(data)))
# [(0, 'zs'), (1, 'ls'), (2, 'ww')]3. torch.no_grad()
在该模块下,所有计算得出的tensor的requires_grad都自动设置为False。
当requires_grad设置为False时,在反向传播时就不会自动求导了,可以节约存储空间。
4. torch.max(input,dim)
input -- tensor类型
dim=0 -- 行比较
dim=1 -- 列比较
import torchdata = torch.Tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
x = torch.max(data, dim=0)
print(x)
# values=tensor([7., 8., 9.]),
# indices=tensor([2, 2, 2])
x = torch.max(data, dim=1)
print(x)
# values=tensor([3., 6., 9.]),
# indices=tensor([2, 2, 2])
5. torch.eq:对两个张量Tensor进行逐个元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回False。
注意:item返回一个数。
import torchdata1 = torch.tensor([1, 2, 3, 4, 5])
data2 = torch.tensor([2, 3, 3, 9, 5])
x = torch.eq(data1, data2)
print(x) # tensor([False, False, True, False, True])
sum = torch.eq(data1, data2).sum()
print(sum) # tensor(2)
sum_item = torch.eq(data1, data2).sum().item()
print(sum_item) # 26. squeeze(input,dim)函数
squeeze(0):若第一维度值为1,则去除第一维度
squeeze(1):若第二维度值为2,则去除第二维度
squeeze(-1):去除最后维度值为1的维度
7. unsqueeze(input,dim)
增加大小为1的维度,即返回一个新的张量,对输入的指定位置插入维度 1且必须指明维度。
二、代码
model.py
import torch.nn as nn
import torch.nn.functional as Fclass LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.conv1 = nn.Conv2d(3, 16, 5) # output(16,28,28)self.pool1 = nn.MaxPool2d(2, 2) # output(16,14,14)self.conv2 = nn.Conv2d(16, 32, 5) # output(32,10,10)self.pool2 = nn.MaxPool2d(2, 2) # output(32,5,5)self.fc1 = nn.Linear(32 * 5 * 5, 120) # output:120self.fc2 = nn.Linear(120, 84) # output:84self.fc3 = nn.Linear(84, 10) # output:10def forward(self, x):x = F.relu(self.conv1(x))x = self.pool1(x)x = F.relu(self.conv2(x))x = self.pool2(x)x = x.view(-1, 32 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x
train.py
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transformsfrom model import LeNetdef main():# preprocess datatransform = transforms.Compose([# Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]transforms.ToTensor(),# (mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 训练集 如果数据集已经下载了,则download=Falsetrain_data = torchvision.datasets.CIFAR10('./data', train=True, transform=transform, download=False)train_loader = torch.utils.data.DataLoader(train_data, batch_size=36, shuffle=True, num_workers=0)# 验证集val_data = torchvision.datasets.CIFAR10('./data', train=False, download=False, transform=transform)val_loader = torch.utils.data.DataLoader(val_data, batch_size=10000, shuffle=False, num_workers=0)# 返回迭代器val_data_iter = iter(val_loader)val_image, val_label = next(val_data_iter)net = LeNet()loss_function = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.001)# loop over the dataset multiple timesfor epoch in range(5):epoch_loss = 0for step, data in enumerate(train_loader, start=0):# get the inputs from train_loader;data is a list of[inputs,labels]inputs, labels = data# 在处理每一个batch时并不需要与其他batch的梯度混合起来累积计算,因此需要对每个batch调用一遍zero_grad()将参数梯度设置为0optimizer.zero_grad()# 1.forwardoutputs = net(inputs)# 2.lossloss = loss_function(outputs, labels)# 3.backpropagationloss.backward()# 4.update x by optimizeroptimizer.step()# print statistics# 使用item()取出的元素值的精度更高epoch_loss += loss.item()# print every 500 mini-batchesif step % 500 == 499:with torch.no_grad():outputs = net(val_image)predict_y = torch.max(outputs, dim=1)[1] # [0]取每行最大值,[1]取每行最大值的索引val_accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)print('[epoch:%d step:%5d] train_loss:%.3f test_accuracy:%.3f' % (epoch + 1, step + 1, epoch_loss / 500, val_accuracy))epoch_loss = 0print('Train finished!')sava_path = './model/LeNet.pth'torch.save(net.state_dict(), sava_path)if __name__ == '__main__':main()

predict.py
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNetdef main():transform = transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(), # CHW格式transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']net = LeNet()net.load_state_dict(torch.load('./model/LeNet.pth'))image = Image.open('./predict/2.png') # HWC格式image = transform(image)image = torch.unsqueeze(image, dim=0) # 在第0维加一个维度 #[N,C,H,W] N:Batch批处理大小with torch.no_grad():outputs = net(image)predict = torch.max(outputs, dim=1)[1]print(classes[predict])if __name__ == '__main__':main()
2.png


三、查看卷积层的feature map
1. 查看每层信息
for i in net.children():print(i) 2. show_featureMap.py
2. show_featureMap.py
import torch
import torch.nn as nn
from model import LeNet
import torchvision
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as pltdef main():transform = transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(), # CHW格式transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])image = Image.open('./predict/2.png') # HWC格式image = transform(image)image = torch.unsqueeze(image, dim=0) # 在第0维加一个维度 #[N,C,H,W] N:Batch批处理大小net = LeNet()net.load_state_dict(torch.load('./model/LeNet.pth'))conv_weights = [] # 模型权重conv_layers = [] # 模型卷积层counter = 0 # 模型里有多少个卷积层# 1.将卷积层以及对应权重放入列表中model_children = list(net.children())for i in range(len(model_children)):if type(model_children[i]) == nn.Conv2d:counter += 1conv_weights.append(model_children[i].weight)conv_layers.append(model_children[i])outputs = []names = []for layer in conv_layers[0:]:# 2.每个卷积层对image进行计算image = layer(image)outputs.append(image)names.append(str(layer))# 3.进行维度转换print(outputs[0].shape) # torch.Size([1, 16, 28, 28]) 1-batch 16-channel 28-H 28-Wprint(outputs[0].squeeze(0).shape) # torch.Size([16, 28, 28]) 去除第0维# 将16颜色通道的feature map加起来,变为一张28×28的feature map,sum将所有灰度图映射到一张print(torch.sum(outputs[0].squeeze(0), 0).shape) # torch.Size([28, 28])processed_data = []for feature_map in outputs:feature_map = feature_map.squeeze(0) # torch.Size([16, 28, 28])gray_scale = torch.sum(feature_map, 0) # torch.Size([28, 28])# 取所有灰度图的平均值gray_scale = gray_scale / feature_map.shape[0]processed_data.append(gray_scale.data.numpy())# 4.可视化特征图figure = plt.figure()for i in range(len(processed_data)):x = figure.add_subplot(1, 2, i + 1)x.imshow(processed_data[i])x.set_title(names[i].split('(')[0])plt.show()if __name__ == '__main__':main()
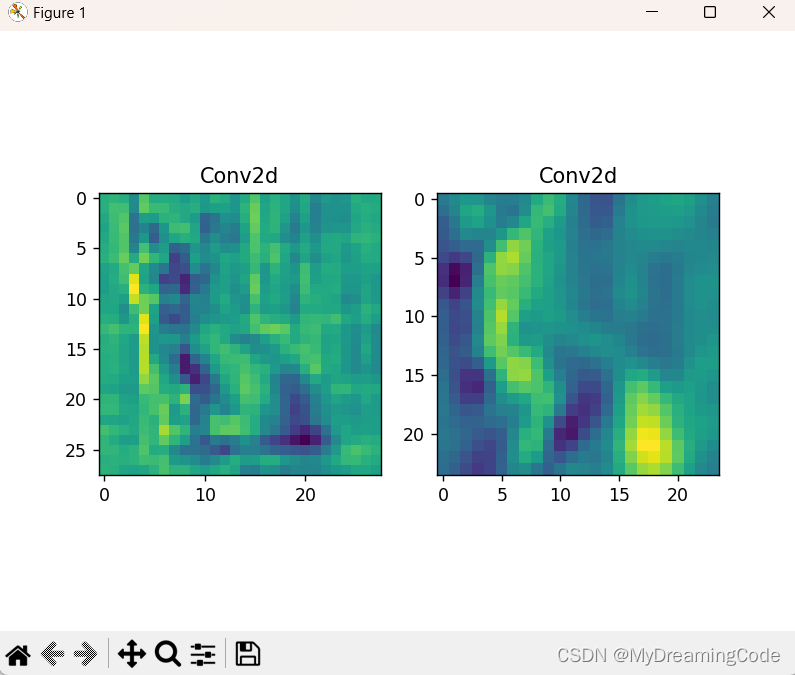
相关文章:
LeNet-5
目录 一、知识点 二、代码 三、查看卷积层的feature map 1. 查看每层信息 2. show_featureMap.py 背景:LeNet-5是一个经典的CNN,由Yann LeCun在1998年提出,旨在解决手写数字识别问题。 一、知识点 1. iter()next() iter():…...

Anaconda bug
报错如下: DEBUG:urllib3.connectionpool:Starting new HTTPS connection (1): repo.anaconda.com:443 DEBUG:urllib3.connectionpool:Starting new HTTPS connection (1): repo.anaconda.com:443 DEBUG:urllib3.connectionpool:Starting new HTTPS connection (1):…...

xen-trap
Xen-Trap xen的虚拟化实现有一个很重要的机制就是tarp,中文可以暂且叫做陷入。在ARMv8中,trap就是异常等级的一个切换。 当发生trap的时候,就会进入设定好的异常向量表中,硬件自动判断属于哪种类型的异常。 一、异常处理 ARM…...

微服务架构介绍
系统架构的演变 1、技术架构发展历史时间轴 ①单机垂直拆分:应用间进行了解耦,系统容错提高了,也解决了独立应用发布的问题,存在单机计算能力瓶颈。 ②集群化负载均衡可有效解决单机情况下并发量不足瓶颈。 ③服务改造架构 虽然系…...
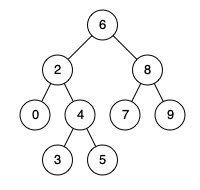
235. 二叉搜索树的最近公共祖先
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己…...
DETR:End-to-End Object Detection with Transformers
代码:https://github.com/HuKai97/detr-annotations 论文:https://arxiv.org/pdf/2005.12872.pdf 参考视频:DETR 论文精读【论文精读】_哔哩哔哩_bilibili 团队:Meta AI 摘要 DETR 做目标检测任务既不需要proposal࿰…...
如何从第一性原则的原理分解数学问题
如何从第一性原则的原理分解数学问题 摘要:牛津大学入学考试题目展示了所有优秀数学家都使用的系统的第一原则推理,而GPT4仍然在这方面有困难 作者:Keith McNulty 我们中的许多人都熟悉直角三角形的边的规则。根据毕达哥拉斯定理,…...

实现strstr函数
一个字符串有没有在另一个字符串出现过 char* my_strstr(char* arr1, char* arr2) {char* cp;char* a1;char* a2;cp arr1;while (*cp){a1 cp;a2 arr2;while (*a1 *a2){a1;a2;}if (*a2 \0){return cp;}cp;}return NULL; } int main() {char arr1[] "abbbcdefgi"…...

C语言练习题解析(2)
💓博客主页:江池俊的博客⏩收录专栏:C语言刷题专栏👉专栏推荐:✅C语言初阶之路 ✅C语言进阶之路💻代码仓库:江池俊的代码仓库🎉欢迎大家点赞👍评论📝收藏⭐ 文…...
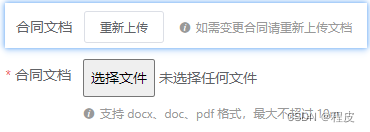
Element UI 表单验证规则动态失效问题
Element 版本:v2.15.3 问题背景 如下代码所示:有一个上传文件的 input 组件,在更新的时候,如果不上传文件表示不更新,如果要更新则点击 「重新上传」按钮将上传组件显示出来 <el-form ref"form" :mode…...
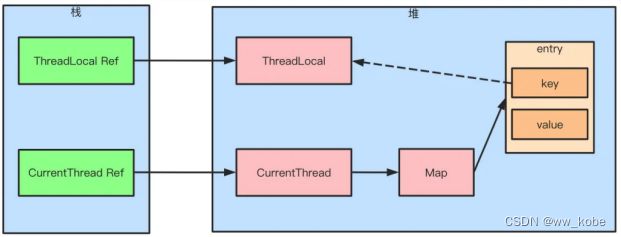
多线程并发篇
目录 1、线程生命周期 2、线程创建方式 3、Callable 与 Future 4、如何停止一个正在运行的线程 5、notify() 和 notifyAll() 的区别 6、sleep() 和 wait() 的区别 7、start() 和 run() 的区别 8、interrupted 和 isInterruptedd 的区别 9、CyclicBarrier 和 Count…...

pycharm-2023.1 closing project window stuck
pycharm-2023.1 closing project window stuck 问题描述 pycharm 切换项目/重启,一直卡在 closing project 原因分析 PyCharm 2023.1 issue - closing project window stuck (PyPIPackageUtil.lambda$parsePyPIListFromWeb) 解决方案 升级 pycharm 到 2023.3py…...

tkinter编写的打开csdn程序
目录 鬼畜tkinter简介程序代码解析现成总结鬼畜 看看你每次打开CSDN: 1.开机 2.打开浏览器 3.打开CSDN 4.等待 5.完成 我: 1.开机 2.点击%%%按钮 3.等待 4.完成 简单了不知道多少倍 上面的纯属鬼畜,下面正文!!! tkinter tkinter是一个用于创建图形用户界面(GUI)的Py…...

Vue3.2组件如何封装,以弹窗组件的封装为例
以前一直想,每次封装一个弹窗组件的时候,一直特别复杂,父传子,子传父,各种来回绕,来回修改。 一直想如何才能更加简化,但是一直没时间,今天终于抽时间出来封装了一下 本次封装简化…...
每天10个小知识点)
Vue知识系列(5)每天10个小知识点
目录 系列文章目录Vue知识系列(1)每天10个小知识点Vue知识系列(2)每天10个小知识点Vue知识系列(3)每天10个小知识点Vue知识系列(4)每天10个小知识点 知识点41.vue常用基本指令有哪些…...
)
Java基础题08——数组(查找下标所对应的值)
给定一个整数数组,输入一个值 n ,输出 n *在数组中的下标 **(*如果不存在输出 -1 ) 如:int[] arr {3, 2, 1, 4, 5}; 1 输入: 3 输出: 0 2. 输入: 6 输出: -1 int[] arr new int[]{3, 2, 1, 4,…...

LinkedList 源码分析
LinkedList 是一个基于双向链表实现的集合类。 LinkedList 插入和删除元素的时间复杂度 头部插入/删除:只需要修改头结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。尾部插入/删除:只需要修改尾结点的指针即可完成插入/删除操作…...
)
跑步锻炼(蓝桥杯)
跑步锻练 题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 小蓝每天都锻炼身体。 正常情况下,小蓝每天跑 1 千米。如果某天是周一或者月初(1 日),为了激励自己&#x…...

【SLAM】视觉SLAM简介
【SLAM】视觉SLAM简介 task04 主要了解了SLAM的主流框架,清楚VSALM中间接法与直接法的主要区别在什么地方,其各自的优势是什么,了解前端与后端的关系是什么 1.什么是SLAM 2.VSALM中间接法与直接法的主要区别在什么地方,其各自的…...
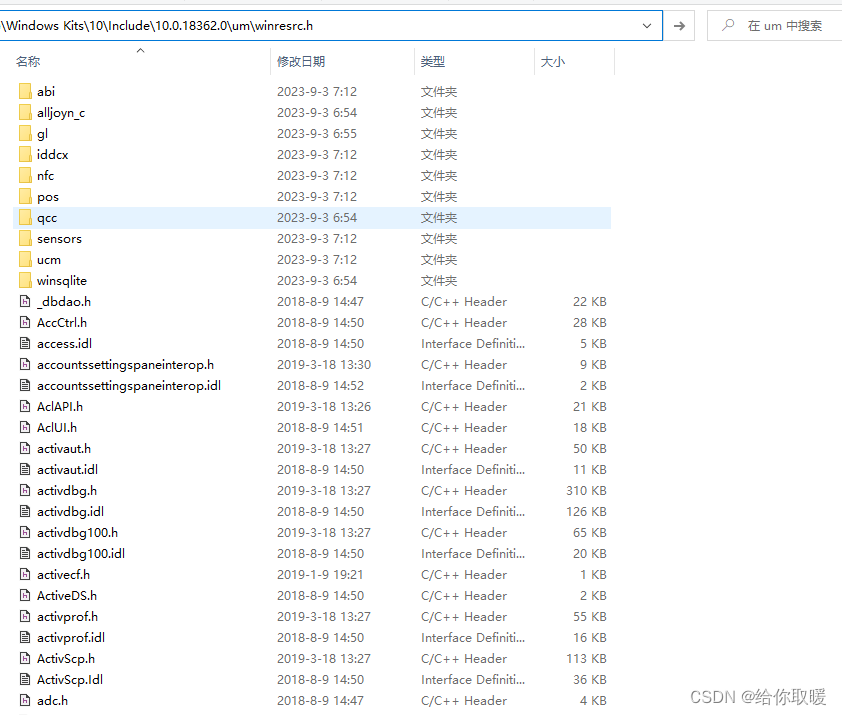
Visual Studio2019报错
1- Visual Studio2019报错 错误 MSB8036 找不到 Windows SDK 版本 10.0.19041.0的解决方法 小伙伴们在更新到Visual Studio2019后编译项目时可能遇到过这个错误:“ 错误 MSB8036 找不到 Windows SDK 版本 10.0.19041.0的解决方法”,但是我们明明安装了该…...

极域电子教室破解终极指南:5步重获电脑控制权
极域电子教室破解终极指南:5步重获电脑控制权 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在上机课时被极域电子教室的全屏广播困住,想要操作电…...

技术深度解析:5大核心要点掌握Sunshine开源游戏串流服务器实战部署
技术深度解析:5大核心要点掌握Sunshine开源游戏串流服务器实战部署 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款功能强大的自托管开源游戏串流服务器…...

ChatGPT 2026安全增强套件发布:内置FIPS 140-3认证加密引擎、GDPR实时审计追踪、AI生成内容数字水印——金融/医疗行业合规上线最后窗口期
更多请点击: https://intelliparadigm.com 第一章:ChatGPT 2026安全增强套件整体架构与合规定位 ChatGPT 2026安全增强套件(CESK-2026)是一套面向生成式AI服务的纵深防御框架,专为满足GDPR、中国《生成式人工智能服务…...

从原理到实践:详解Livox激光雷达与相机外参标定的ROS实现
1. 为什么需要激光雷达与相机标定? 在自动驾驶和机器人领域,激光雷达和相机是最常用的两种传感器。激光雷达能提供精确的三维距离信息,而相机则能捕捉丰富的纹理和颜色信息。但要让这两种传感器真正发挥11>2的效果,就必须解决…...

Axure RP中文语言包技术深度解析:从键值对到国际化架构的工程实践
Axure RP中文语言包技术深度解析:从键值对到国际化架构的工程实践 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 在…...

Cangaroo:开源CAN总线分析软件的技术架构与部署指南
Cangaroo:开源CAN总线分析软件的技术架构与部署指南 【免费下载链接】cangaroo Open source can bus analyzer software - with support for CANable / CANable2, CANFD, and other new features 项目地址: https://gitcode.com/gh_mirrors/ca/cangaroo Cang…...

构建可靠AI智能体:从提示词工程到结构化内容生成的实战指南
1. 项目概述与核心思路最近在折腾AI应用开发,特别是想搞一个能稳定输出、逻辑清晰、还能带点“人味儿”的文本生成工具。市面上现成的方案要么太“机械”,要么定制化程度不够,总感觉差点意思。后来,我在一个开发者社区里看到了一个…...

【Claude Kubernetes配置终极指南】:20年SRE亲授生产环境零失误部署的7大黄金法则
更多请点击: https://intelliparadigm.com 第一章:Claude Kubernetes配置的核心理念与演进脉络 Claude 并非原生 Kubernetes 组件,而是 Anthropic 推出的大型语言模型系列;当将其部署于 Kubernetes 集群时,“Claude K…...

不只是显示中文:用fbterm给你的CentOS终端换个‘皮肤’,提升老旧服务器运维效率
终端美学革命:用fbterm打造高效CentOS字符界面工作环境 在服务器运维的世界里,图形界面往往被视为奢侈品。当您面对一台资源受限的老旧CentOS服务器,或者需要远程管理没有X11支持的机器时,字符界面就成了唯一的选择。但单调的终端…...

从图形变换到机器学习:行列式到底在‘衡量’什么?一个直观的几何理解指南
从图形变换到机器学习:行列式到底在‘衡量’什么?一个直观的几何理解指南 想象你手中有一张弹性薄膜,拉伸、旋转或挤压它时,薄膜覆盖的面积会如何变化?这种直观的几何变换背后,隐藏着线性代数中行列式的本质…...