5-1 Dataset和DataLoader
Pytorch通常使用Dataset和DataLoader这两个工具类来构建数据管道。
Dataset定义了数据集的内容,它相当于一个类似列表的数据结构,具有确定的长度,能够用索引获取数据集中的元素。
而DataLoader定义了按batch加载数据集的方法,它是一个实现了**iter**方法的可迭代对象,每次迭代输出一个batch的数据。
DataLoader能够控制batch的大小,batch中元素的采样方法,以及将batch结果整理成模型所需输入形式的方法(collate_fn),并且能够使用多进程读取数据。
在绝大部分情况下,用户只需实现Dataset的__len__方法和__getitem__方法,就可以轻松构建自己的数据集,并用默认数据管道进行加载。
一、深入理解Dataset和DataLoader的原理
1. 获取一个batch数据的步骤
让我们考虑一下从一个数据集中获取一个batch的数据需要哪些步骤。
(假定数据集的特征和标签分别表示为张量X和Y,数据集可以表示为(X,Y), 假定batch大小为m)
1,首先我们要确定数据集的长度n。
结果类似:n = 1000。
2,然后我们从0到n-1的范围中抽样出m个数(batch大小)。
假定m=4, 拿到的结果是一个列表,类似:indices = [1,4,8,9]
3,接着我们从数据集中去取这m个数对应下标的元素。
拿到的结果是一个元组列表,类似:samples = [(X[1],Y[1]),(X[4],Y[4]),(X[8],Y[8]),(X[9],Y[9])]
4,最后我们将结果整理成两个张量作为输出。
拿到的结果是两个张量,类似batch = (features,labels),
其中 features = torch.stack([X[1],X[4],X[8],X[9]])
labels = torch.stack([Y[1],Y[4],Y[8],Y[9]])
2.Dataset和DataLoader的功能分工
上述第1个步骤确定数据集的长度是由 Dataset的__len__ 方法实现的。
第2个步骤从0到n-1的范围中抽样出m个数的方法是由 DataLoader 的 sampler 和 batch_sampler参数指定的。
sampler参数指定单个元素抽样方法,一般无需用户设置,程序默认在DataLoader的参数shuffle=True时采用随机抽样,shuffle=False时采用顺序抽样。
batch_sampler参数将多个抽样的元素整理成一个列表,一般无需用户设置,默认方法在DataLoader的参数drop_last=True时会丢弃数据集最后一个长度不能被batch大小整除的批次,在drop_last=False时保留最后一个批次。
第3个步骤的核心逻辑根据下标取数据集中的元素 是由 Dataset的 getitem方法实现的。
第4个步骤的逻辑由DataLoader的参数collate_fn指定。一般情况下也无需用户设置。
import torch
from torch.utils.data import TensorDataset,Dataset,DataLoader
from torch.utils.data import RandomSampler,BatchSampler ds = TensorDataset(torch.randn(1000,3),torch.randint(low=0,high=2,size=(1000,)).float())
dl = DataLoader(ds,batch_size=4,drop_last = False)
features,labels = next(iter(dl))
print("features = ",features )
print("labels = ",labels )

# step1: 确定数据集长度 (Dataset的 __len__ 方法实现)
ds = TensorDataset(torch.randn(1000,3),torch.randint(low=0,high=2,size=(1000,)).float())
print("n = ", len(ds)) # len(ds)等价于 ds.__len__()# step2: 确定抽样indices (DataLoader中的 Sampler和BatchSampler实现)
sampler = RandomSampler(data_source = ds)
batch_sampler = BatchSampler(sampler = sampler, batch_size = 4, drop_last = False)
for idxs in batch_sampler:indices = idxsbreak
print("indices = ",indices)# step3: 取出一批样本batch (Dataset的 __getitem__ 方法实现)
batch = [ds[i] for i in indices] # ds[i] 等价于 ds.__getitem__(i)
print("batch = ", batch)# step4: 整理成features和labels (DataLoader 的 collate_fn 方法实现)
def collate_fn(batch):features = torch.stack([sample[0] for sample in batch]) # torch.stack是一个torch库中的函数,用于沿着指定的维度对输入的张量序列进行堆叠(即堆叠张量)labels = torch.stack([sample[1] for sample in batch])return features,labels features,labels = collate_fn(batch)
print("features = ",features)
print("labels = ",labels)
3.Dataset和DataLoader的核心源码
import torch
class Dataset(object):def __init__(self):passdef __len__(self):raise NotImplementedErrordef __getitem__(self,index):raise NotImplementedErrorclass DataLoader(object):def __init__(self,dataset, batch_size, collate_fn = None, shuffle = True, drop_last = False):self.dataset = datasetself.collate_fn = collate_fnself.sampler =torch.utils.data.RandomSampler if shuffle else \torch.utils.data.SequentialSamplerself.batch_sampler = torch.utils.data.BatchSamplerself.sample_iter = self.batch_sampler(self.sampler(self.dataset),batch_size = batch_size,drop_last = drop_last)self.collate_fn = collate_fn if collate_fn is not None else \torch.utils.data._utils.collate.default_collatedef __next__(self):indices = next(iter(self.sample_iter))batch = self.collate_fn([self.dataset[i] for i in indices])return batchdef __iter__(self):return self对源码进行测试:
class ToyDataset(Dataset):def __init__(self,X,Y):self.X = Xself.Y = Y def __len__(self):return len(self.X)def __getitem__(self,index):return self.X[index],self.Y[index]X,Y = torch.randn(1000,3),torch.randint(low=0,high=2,size=(1000,)).float()
ds = ToyDataset(X,Y)dl = DataLoader(ds,batch_size=4,drop_last = False)
features,labels = next(iter(dl))
print("features = ",features )
print("labels = ",labels )

二、使用Dataset创建数据集
Dataset创建数据集常用的方法有:
- 使用 torch.utils.data.TensorDataset 根据Tensor创建数据集(numpy的array,Pandas的DataFrame需要先转换成Tensor)。
- 使用 torchvision.datasets.ImageFolder 根据图片目录创建图片数据集。
- 继承 torch.utils.data.Dataset 创建自定义数据集。
此外,还可以通过
- torch.utils.data.random_split 将一个数据集分割成多份,常用于分割训练集,验证集和测试集。
- 调用Dataset的加法运算符(+)将多个数据集合并成一个数据集。
根据Tensor创建数据集
创建数据集:
# 根据Tensor创建数据集from sklearn import datasets
iris = datasets.load_iris()
ds_iris = TensorDataset(torch.tensor(iris.data),torch.tensor(iris.target))# 分割成训练集和预测集
n_train = int(len(ds_iris)*0.8)
n_val = len(ds_iris) - n_train
ds_train,ds_val = random_split(ds_iris,[n_train,n_val])print(type(ds_iris))
print(type(ds_train))

加载数据集:
# 使用DataLoader加载数据集
dl_train,dl_val = DataLoader(ds_train,batch_size = 8),DataLoader(ds_val,batch_size = 8)for features,labels in dl_train:print(features,labels)break

演示加法运算符(+)的合并作用:
# 演示加法运算符(`+`)的合并作用ds_data = ds_train + ds_valprint('len(ds_train) = ',len(ds_train))
print('len(ds_valid) = ',len(ds_val))
print('len(ds_train+ds_valid) = ',len(ds_data))print(type(ds_data))

根据图片目录创建图片数据集
先定义图片增强操作:
# 定义图片增强操作transform_train = transforms.Compose([transforms.RandomHorizontalFlip(), #随机水平翻转transforms.RandomVerticalFlip(), #随机垂直翻转transforms.RandomRotation(45), #随机在45度角度内旋转transforms.ToTensor() #转换成张量]
) transform_valid = transforms.Compose([transforms.ToTensor()]
)
根据图片目录创建数据集:
# 根据图片目录创建数据集def transform_label(x):return torch.tensor([x]).float()ds_train = datasets.ImageFolder("./eat_pytorch_datasets/cifar2/train/",transform = transform_train,target_transform= transform_label)
ds_val = datasets.ImageFolder("./eat_pytorch_datasets/cifar2/test/",transform = transform_valid,target_transform= transform_label)print(ds_train.class_to_idx)# 使用DataLoader加载数据集dl_train = DataLoader(ds_train,batch_size = 50,shuffle = True)
dl_val = DataLoader(ds_val,batch_size = 50,shuffle = True)for features,labels in dl_train:print(features.shape)print(labels.shape)break

创建自定义数据集
下面我们通过另外一种方式,即继承 torch.utils.data.Dataset 创建自定义数据集的方式来对 cifar2构建 数据管道。
from pathlib import Path
from PIL import Image class Cifar2Dataset(Dataset): # 继承torch.utils.data.Datasetdef __init__(self,imgs_dir, img_transform):self.files = list(Path(imgs_dir).rglob("*.jpg"))self.transform = img_transformdef __len__(self,):return len(self.files)def __getitem__(self,i):file_i = str(self.files[i])img = Image.open(file_i)tensor = self.transform(img)label = torch.tensor([1.0]) if "1_automobile" in file_i else torch.tensor([0.0])return tensor,label train_dir = "./eat_pytorch_datasets/cifar2/train/"
test_dir = "./eat_pytorch_datasets/cifar2/test/"
使用:
# 定义图片增强
transform_train = transforms.Compose([transforms.RandomHorizontalFlip(), #随机水平翻转transforms.RandomVerticalFlip(), #随机垂直翻转transforms.RandomRotation(45), #随机在45度角度内旋转transforms.ToTensor() #转换成张量]
) transform_val = transforms.Compose([transforms.ToTensor()]
)
ds_train = Cifar2Dataset(train_dir,transform_train)
ds_val = Cifar2Dataset(test_dir,transform_val)dl_train = DataLoader(ds_train,batch_size = 50,shuffle = True)
dl_val = DataLoader(ds_val,batch_size = 50,shuffle = True)for features,labels in dl_train:print(features.shape)print(labels.shape)break
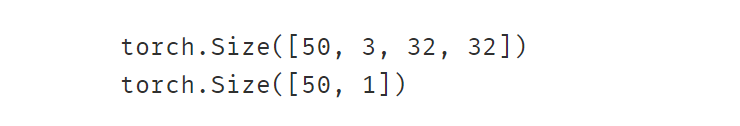
三、使用DataLoader加载数据集
DataLoader能够控制batch的大小,batch中元素的采样方法(随机否),以及将batch结果整理成模型所需输入形式的方法(collate_fn),并且能够使用多进程读取数据。
DataLoader的函数签名如下。
DataLoader(dataset,batch_size=1,shuffle=False,sampler=None,batch_sampler=None,num_workers=0,collate_fn=None,pin_memory=False,drop_last=False,timeout=0,worker_init_fn=None,multiprocessing_context=None,
)
一般情况下,我们仅仅会配置 dataset, batch_size, shuffle, num_workers, pin_memory, drop_last这六个参数,
有时候对于一些复杂结构的数据集,还需要自定义collate_fn函数,其他参数一般使用默认值即可。
DataLoader除了可以加载我们前面讲的 torch.utils.data.Dataset 外,还能够加载另外一种数据集 torch.utils.data.IterableDataset。
和Dataset数据集相当于一种列表结构不同,IterableDataset相当于一种迭代器结构。 它更加复杂,一般较少使用。
- dataset : 数据集
- batch_size: 批次大小
- shuffle: 是否乱序
- sampler: 样本采样函数,一般无需设置。
- batch_sampler: 批次采样函数,一般无需设置。
- num_workers: 使用多进程读取数据,设置的进程数。
- collate_fn: 整理一个批次数据的函数。
- pin_memory: 是否设置为锁业内存。默认为False,锁业内存不会使用虚拟内存(硬盘),从锁业内存拷贝到GPU上速度会更快。
- drop_last: 是否丢弃最后一个样本数量不足batch_size批次数据。
- timeout: 加载一个数据批次的最长等待时间,一般无需设置。
- worker_init_fn: 每个worker中dataset的初始化函数,常用于 IterableDataset。一般不使用。
#构建输入数据管道
ds = TensorDataset(torch.arange(1,50))
dl = DataLoader(ds,batch_size = 10,shuffle= True,num_workers=2,drop_last = True)
#迭代数据
for batch, in dl:print(batch)
参考:https://github.com/lyhue1991/eat_pytorch_in_20_days
相关文章:
5-1 Dataset和DataLoader
Pytorch通常使用Dataset和DataLoader这两个工具类来构建数据管道。 Dataset定义了数据集的内容,它相当于一个类似列表的数据结构,具有确定的长度,能够用索引获取数据集中的元素。 而DataLoader定义了按batch加载数据集的方法,它是…...
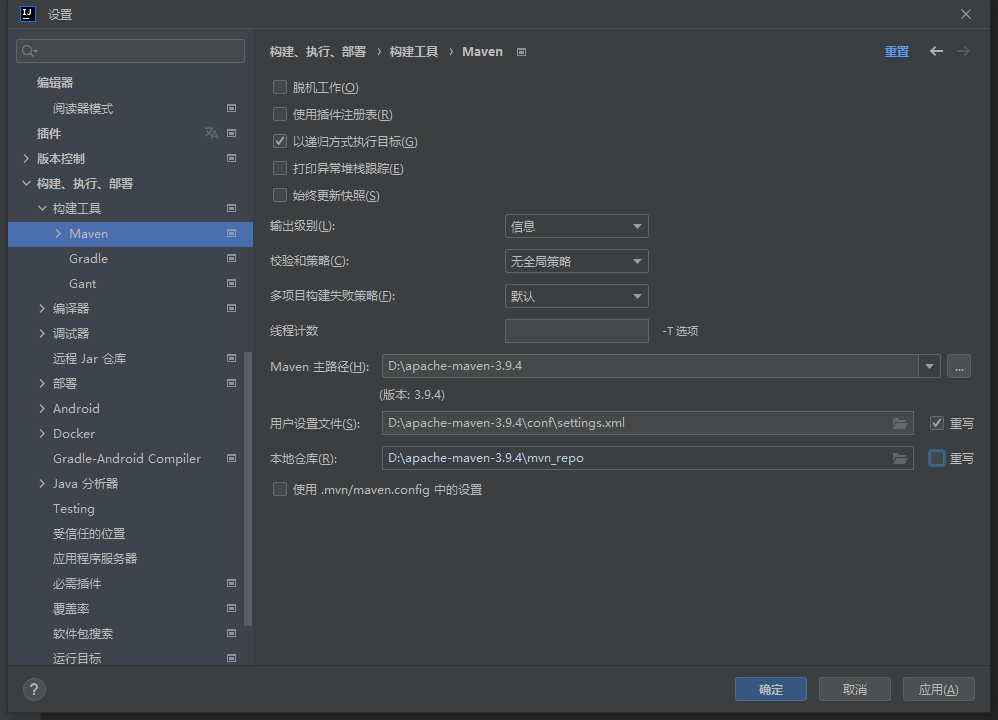
IDEA创建完Maven工程后,右下角一直显示正在下载Maven插件
原因: 这是由于新建的Maven工程,IDEA会用它内置的默认的Maven版本,使用国外的网站下载Maven所需的插件,速度很慢 。 解决方式: 每次创建 Project 后都需要设置 Maven 家目录位置(就是我们自己下载的Mav…...

最新清理删除Mac电脑内存空间方法教程
Mac电脑使用的时间越久,系统的运行就会变的越卡顿,这是Mac os会出现的正常现象,卡顿的原因主要是系统缓存文件占用了较多的磁盘空间,或者Mac的内存空间已满。如果你的Mac运行速度变慢,很有可能是因为磁盘内存被过度占用…...

【调试经验】MySQL - fatal error: mysql/mysql.h: 没有那个文件或目录
机器环境: Ubuntu 22.04.3 LTS 报错问题 在编译一个项目时出现了一段SQL报错: CGImysql/sql_connection_pool.cpp:1:10: fatal error: mysql/mysql.h: 没有那个文件或目录 1 | #include <mysql/mysql.h> | ^~~~~~~~~~~~~~~ c…...

腾讯mini项目-【指标监控服务重构】2023-08-12
今日已办 Watermill Handler 将 4 个阶段的逻辑处理定义为 Handler 测试发现,添加的 handler 会被覆盖掉,故考虑添加为 middleware 且 4 个阶段的处理逻辑针对不同 topic 是相同的。 参考https://watermill.io/docs/messages-router/实现不同topic&am…...

kubeadm部署k8sv1.24使用cri-docker做为CRI
目的 测试使用cri-docker做为containerd和docker的中间层垫片。 规划 IP系统主机名10.0.6.5ubuntu 22.04.3 jammymaster01.kktb.org10.0.6.6ubuntu 22.04.3 jammymaster02.kktb.org10.0.6.7ubuntu 22.04.3 jammymaster03.kktb.org 配置 步骤: 系统优化 禁用sw…...
在c#中使用CancellationToken取消任务
目录 🚀介绍: 🐤简单举例 🚀IsCancellationRequested 🚀ThrowIfCancellationRequested 🐤在控制器中使用 🚀通过异步方法的参数使用cancellationToken 🚀api结合ThrowIfCancel…...
【项目经验】:elementui多选表格默认选中
一.需求 在页面刚打开就默认选中指定项。 二.方法Table Methods toggleRowSelection用于多选表格,切换某一行的选中状态,如果使用了第二个参数,则是设置这一行选中与否(selected 为 true 则选中)row, selected 详细…...

外星人入侵游戏-(创新版)
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...
HTML 学习笔记(基础)
它是超文本标记语言,由一大堆约定俗成的标签组成,而其标签里一般又有一些属性值可以设置。 W3C标准:网页主要三大部分 结构:HTML表现:CSS行为:JavaScript <!DOCTYPE html> <html lang"zh-…...

最小二乘法
Least Square Method 1、相关的矩阵公式2、线性回归3、最小二乘法3.1、损失函数(Loss Function)3.2、多维空间的损失函数3.3、解析法求解3.4、梯度下降法求解 1、相关的矩阵公式 P r e c o n d i t i o n : ξ ∈ R n , A ∈ R n ∗ n i : σ A ξ σ ξ…...

使用stelnet进行安全的远程管理
1. telnet有哪些不足? 2.ssh如何保证数据传输安全? 需求:远程telnet管理设备 用户定义需要在AAA模式下: 开启远程登录的服务:定义vty接口 然后从R2登录:是可以登录的 同理R3登录: 在R1也可以查…...

python 二手车数据分析以及价格预测
二手车交易信息爬取、数据分析以及交易价格预测 引言一、数据爬取1.1 解析数据1.2 编写代码爬1.2.1 获取详细信息1.2.2 数据处理 二、数据分析2.1 统计分析2.2 可视化分析 三、价格预测3.1 价格趋势分析(特征分析)3.2 价格预测 引言 本文着眼于车辆信息,结合当下较…...
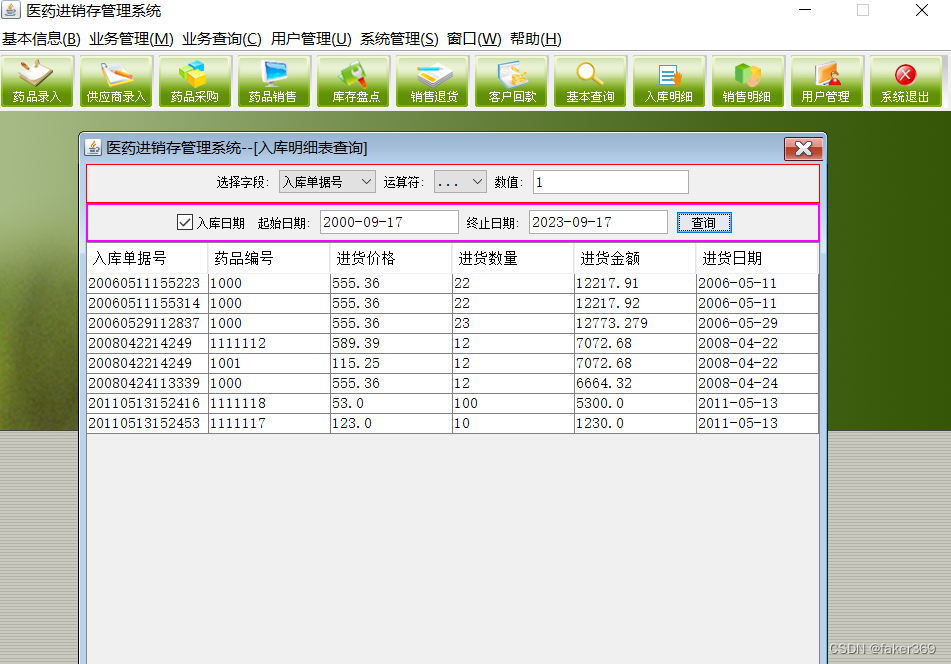
JAVA医药进销存管理系统(附源码+调试)
JAVA医药进销存管理系统 功能描述 (1)登录模块:登录信息等存储在数据库中 (2)基本信息模块:分为药品信息模块、客户情况模块、供应商情况模块; (3)业务管理模块&#x…...

H5 <blockquote> 标签
主要应用于:内容引用 标签定义及使用说明 <blockquote> 标签定义摘自另一个源的块引用。 浏览器通常会对 <blockquote> 元素进行缩进。 提示和注释 提示:如果标记是不需要段落分隔的短引用,请使用 <q>。 HTML 4.01 与 H…...
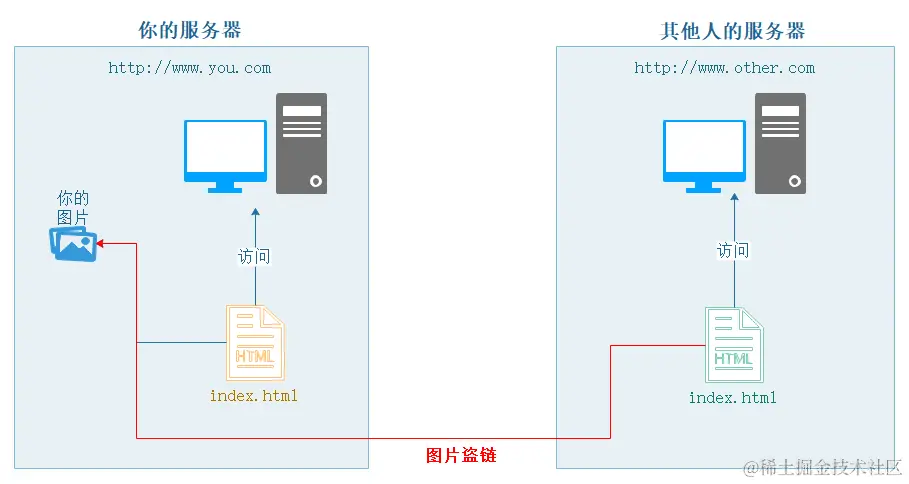
nginx配置指南
nginx.conf配置 找到Nginx的安装目录下的nginx.conf文件,该文件负责Nginx的基础功能配置。 配置文件概述 Nginx的主配置文件(conf/nginx.conf)按以下结构组织: 配置块功能描述全局块与Nginx运行相关的全局设置events块与网络连接有关的设置http块代理…...

【数据结构】优先级队列(堆)
文章目录 💐1. 优先级队列1.1 概念 💐2.堆的概念及存储方式2.1 什么是堆2.2 为什么要用完全二叉树描述堆呢?2.3 为什么说堆是在完全二叉树的基础上进行的调整?2.4 使用数组还原完全二叉树 💐3. 堆的常用操作-模拟实现3…...
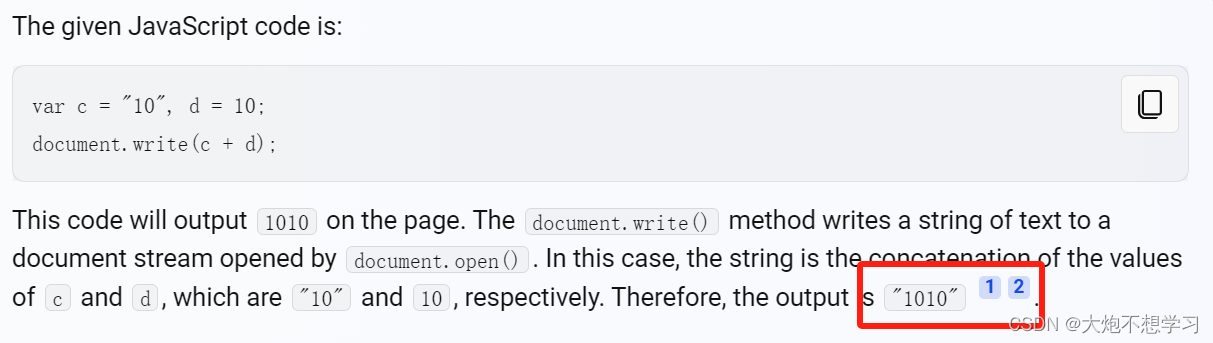
前端笔试2
1.下面哪一个是检验对象是否有一个以自身定义的属性? foo.hasOwnProperty("bar")bar in foo foo["bar"] ! undefinedfoo.bar ! null 解析: bar in foo 检查 foo 对象是否包含名为 bar 的属性,但是这个属性可以是从原型链继承来的&a…...

LeetCode:66.加一
66.加一 来源:力扣(LeetCode) 链接: https://leetcode.cn/problems/plus-one/description/ 给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。 最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。 你可以假设除了整数 0 之外,这个整数…...

Redis 常用命令
目录 全局命令 1)keys 2)exists 3) del(delete) 4)expire 5)type SET命令 GET命令 MSET 和 MGET命令 其他SET命令 计数命令 redis-cli,进入redis 最核心的命令:我们这里只是先介绍 set 和 get 最简单的操作…...

PIM-LLM:1-bit量化大语言模型的混合内存计算架构
1. 项目概述PIM-LLM是一种创新的混合内存计算架构,专门为1-bit量化的大语言模型(LLM)设计。这个架构通过结合模拟内存计算(PIM)和数字脉动阵列,实现了对低精度和高精度矩阵乘法运算的高效加速。在边缘AI加速…...

高速SOIC插座技术解析:从原理到工程实践
1. 高速SOIC插座的技术演进与核心价值在射频和高速数字电路设计中,工程师们经常面临一个经典矛盾:既要保证芯片测试的便捷性,又不能牺牲信号完整性。传统DIP插座在MHz级频率下尚能应付,但当频率攀升至GHz领域时,其机械…...

从开源模型到API服务:OpenClaw部署实战与Docker+FastAPI方案解析
1. 项目概述:从开源模型到可部署服务的跨越最近在折腾大语言模型本地部署的朋友,可能都绕不开一个名字:OpenClaw。这个由智源研究院开源的模型,以其在代码生成和数学推理上的出色表现,吸引了不少开发者和研究者的目光。…...

【仅限首批内测用户验证】:Midjourney v8“隐性美学协议”曝光——92%设计师尚未察觉的4类负向提示陷阱
更多请点击: https://intelliparadigm.com 第一章:Midjourney v8“隐性美学协议”的本质解构 Midjourney v8 并未公开发布传统意义上的“美学参数文档”,其核心创新在于将图像生成的审美判断内化为一套不可见但可触发的上下文响应机制——即…...

Newhaven 5.0英寸TFT显示屏技术解析与应用指南
1. Newhaven 5.0英寸TFT显示屏核心特性解析 1.1 3M增强膜技术解析 这款5.0英寸TFT显示屏最显著的技术亮点在于采用了3M专利的增强膜技术。在实际应用中,我发现这种增强膜通过特殊的光学结构设计,能够有效提升背光利用率。具体来说,它采用了多…...

开源实践:基于Telnyx与AI构建实时智能通信系统
1. 项目概述:当AI遇上通信,一次开源协作的深度实践最近在GitHub上看到一个挺有意思的项目,叫team-telnyx/ai。光看名字,你可能会觉得这又是一个大模型应用或者AI工具库,但点进去仔细研究,会发现它的内核远不…...

大模型低显存优化实战:量化、KV Cache与动态加载技术解析
1. 项目概述:低显存环境下的OpenClaw模型优化实战最近在GitHub上看到一个挺有意思的项目,标题是“openclaw-lowmem-optimization”。光看名字,就能猜到这大概是在做一件什么事:针对OpenClaw这个模型,进行低显存&#x…...

5个颠覆性文本处理技巧:让notepad--成为你的跨平台效率倍增器
5个颠覆性文本处理技巧:让notepad--成为你的跨平台效率倍增器 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- …...

Apple Silicon Mac原生Linux游戏体验:Asahi Linux驱动突破与实战指南
1. 项目概述:当Apple Silicon Mac遇见原生Linux游戏如果你和我一样,既是Mac用户,又对在Linux系统上折腾抱有热情,那么最近Asahi Linux项目的进展绝对会让你心跳加速。长久以来,在搭载Apple Silicon(M1、M2、…...

终极指南:PersistentWindows如何彻底解决Windows多显示器窗口管理难题
终极指南:PersistentWindows如何彻底解决Windows多显示器窗口管理难题 【免费下载链接】PersistentWindows fork of http://www.ninjacrab.com/persistent-windows/ with windows 10 update 项目地址: https://gitcode.com/gh_mirrors/pe/PersistentWindows …...