Java的序列化
写在前面
本文看下序列化和反序列化相关的内容。
源码 。
1:为什么,什么是序列化和反序列化
Java对象是在jvm的堆中的,而堆其实就是一块内存,如果jvm重启数据将会丢失,当我们希望jvm重启也不要丢失某些对象,或者是需要将某些对象传递到其他服务器(rpc有没有!!!)时就需要使用到序列化和反序列化,因为序列化就是将Java对象转换为文件,而反序列化就是加载文件并生成对象在堆中。
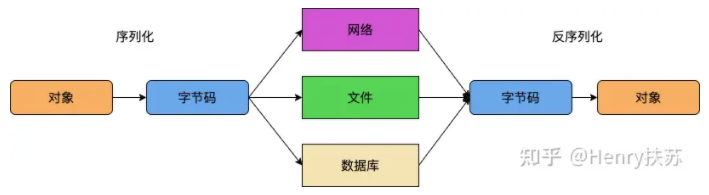
2:Java的序列化和反序列化
Java想要序列化和反序列化,必须实现java.io.Serializable接口,并给变量serialVersionUID赋值,该值用来标识Java类文件的版本。如下序列化和反序列化的例子:
@SneakyThrows
private static void javaDeserialize() {ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("d:\\test\\xxx.obj"));Student student = (Student) objectInputStream.readObject();System.out.println("java反序列化student完成");System.out.println(student);
}@SneakyThrows
private static void javaSerialize() throws IOException {Student student = new Student();student.setName("张三");student.setAge(99);ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("d:\\test\\xxx.obj"));// 如果没有实现java.io.Serializable接口将会抛出异常java.io.NotSerializableExceptionobjectOutputStream.writeObject(student);objectOutputStream.close();System.out.println("java序列化student完成");
}
java序列化的问题:
1:无法跨平台如Java对象序列化的结果反序列化为python的对象,这样就限制了其不适合某些使用场景,如rpc的场景中就无法使用这种序列化方式,因为rpc需要支持异构的系统
2:序列化的文件大这样占用磁盘大,网络传输速度慢,占用带宽,反序列化的速度也慢,这样就限制了其不适合某些使用场景,如rpc,rpc需要尽量快的序列化和反序列化速度,以提高性能
3:序列化的速度慢还是因为其序列化结果的内容多
以上的问题我们可以使用专门的序列化框架来解决,如hessian。
3:hessian的序列化和反序列化
dubbo 默认使用的是该序列化方式,将来可能会优化成性能更优的序列化方式如kryo,fst等。
hessian支持语言无关的序列化和反序列化,并且速度更快,序列化的结果更小,如下:
private void hessianSerialize() {Student stu = new Student("hessian",1);byte[] obj = serialize(stu);System.out.println("hessian serialize result length = "+obj.length);byte[] obj2 = serialize2(stu);System.out.println("hessian2 serialize result length = "+obj2.length);byte[] other = jdkSerialize(stu);System.out.println("jdk serialize result length = "+other.length);Student student = deserialize2(obj2);System.out.println("deserialize result entity is "+student);
}
具体看文章头源码。
运行结果如下:
hessian serialize result length = 65
hessian2 serialize result length = 59
jdk serialize result length = 101
deserialize result entity is Student(name=hessian, age=1)
可以看到结果的大小jdk序列化<hessian序列化<hessian2序列化,所以如果工作中有这种需求,建议使用hessian2。
4:arvo的序列化和反序列化
使用步骤如下:
1:定义.avsc描述文件
2:通过avro-tool.jar,以.avsc描述文件作为输入生成pojo
3:通过avro.jar的API进行序列化(生成.avro文件)和反序列化
首先我们需要定义IDL,命名为User.avsc:
{"namespace": "dongshi.daddy.seriablize.avro","type": "record","name": "User","fields": [{"name": "name", "type": "string"},{"name": "id", "type": "int"},{"name": "salary", "type": "int"},{"name": "age", "type": "int"},{"name": "address", "type": "string"}]
}
接着通过avro-tools.jar生成pojo,如下:
$ java -jar avro-tools-1.8.2.jar compile schema User.avsc res
Input files to compile:User.avsc
log4j:WARN No appenders could be found for logger (AvroVelocityLogChute).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
然后我们将生成的User.java文件拷贝到classpath的dongshi.daddy.seriablize.avro目录,接着就可以执行序列化和反序列化了,首先执行序列化:
@Test
public void testAvroSerialize() throws Exception {
// 声明并初始化User对象// 方式一User user1 = new User();user1.setName("wqbin");user1.setId(1);user1.setSalary(1000);user1.setAge(20);user1.setAddress("beijing");// 方式二 使用构造函数
// Alternate constructorUser user2 = new User("wang", 2, 1000, 19, "guangzhou");// 方式三,使用Build方式
// Construct via builderUser user3 = User.newBuilder().setName("bin").setId(3).setAge(21).setSalary(2000).setAddress("shenzhen").build();String userDir = System.getProperty("user.dir");System.out.println("userDir is: " + userDir);String path = userDir + "/User.avro"; // avro文件存放目录DatumWriter<User> userDatumWriter = new SpecificDatumWriter<User>(User.class);DataFileWriter<User> dataFileWriter = new DataFileWriter<User>(userDatumWriter);dataFileWriter.create(user1.getSchema(), new File(path));
// 把生成的user对象写入到avro文件dataFileWriter.append(user1);dataFileWriter.append(user2);dataFileWriter.append(user3);dataFileWriter.close();
}
生成文件如下:
接着执行反序列化:
@Test
public void testAvroDeserialize() throws Exception {DatumReader<User> reader = new SpecificDatumReader<User>(User.class);DataFileReader<User> dataFileReader = new DataFileReader<User>(new File(System.getProperty("user.dir") + "/User.avro"), reader);User user = null;while (dataFileReader.hasNext()) {user = dataFileReader.next();System.out.println(user);}
}
输出如下内容则为成功:
{"name": "wqbin", "id": 1, "salary": 1000, "age": 20, "address": "beijing"}
{"name": "wang", "id": 2, "salary": 1000, "age": 19, "address": "guangzhou"}
{"name": "bin", "id": 3, "salary": 2000, "age": 21, "address": "shenzhen"}Process finished with exit code 0
5:kryo的序列化和反序列化
kryo是底层使用了ASM字节码技术,所以其只能使用在基于JVM的语言上,如Java,scala,kotlin等,接下来看下其如何使用。
- 首先引入pom:
<dependency><groupId>com.esotericsoftware</groupId><artifactId>kryo</artifactId><version>5.2.0</version>
</dependency>
- 序列化:
@Test
public void testKrypSerialize() throws Exception {Kryo kryo = new Kryo();kryo.register(SomeClass.class);SomeClass someClass = new SomeClass();someClass.value = "dongshidaddy";Output output = new Output(new FileOutputStream(userDir + "/someCls.bin"));kryo.writeObject(output, someClass);output.close();
}
运行后:
- 反序列化
@Test
public void testKrypDeserialize() throws Exception {Kryo kryo = new Kryo();kryo.register(SomeClass.class);Input input = new Input(new FileInputStream(userDir + "/someCls.bin"));SomeClass someClassFromBin = kryo.readObject(input, SomeClass.class);System.out.println(someClassFromBin.value);
}
运行后:
dongshidaddyProcess finished with exit code 0
6:fst的序列化和反序列化
java的序列化和反序列化方式,性能优秀(jdk原生序列化速度的10倍,序列化结果体积1/3左右),如果有序列化的需求可以考虑使用。看下如何使用。
- 引入pom
<dependency><groupId>de.ruedigermoeller</groupId><artifactId>fst</artifactId><version>2.04</version>
</dependency>
- 序列化和反序列化
// fst序列化和反序列化
@Test
public void testFstSerializeAndDescrialize() {dongshi.daddy.seriablize.fst.User bean = new dongshi.daddy.seriablize.fst.User();bean.setUsername("xxxxx");bean.setPassword("123456");bean.setAge(1000000);byte[] byteBean = configuration.asByteArray(bean);System.out.println("序列化的字节大小是:" + byteBean.length);// 反序列化dongshi.daddy.seriablize.fst.User resultBean = (dongshi.daddy.seriablize.fst.User) configuration.asObject(byteBean);System.out.println("fst反序列化的结果是:" + resultBean);
}
输出如下内容则为成功:
序列化的字节大小是:68
fst反序列化的结果是:User(username=xxxxx, age=1000000, password=123456)Process finished with exit code 0
写在后面
巨人的肩膀
再来认识一下 Java 序列化 。
Hessian序列化实例 。
Avro从入门到入土 。
深入浅出序列化(2)——Kryo序列化 。
Kryo 和 FST 序列化 。
相关文章:
Java的序列化
写在前面 本文看下序列化和反序列化相关的内容。 源码 。 1:为什么,什么是序列化和反序列化 Java对象是在jvm的堆中的,而堆其实就是一块内存,如果jvm重启数据将会丢失,当我们希望jvm重启也不要丢失某些对象ÿ…...
)
计算机二级python简单应用题刷题笔记(一)
计算机二级python简单应用题刷题笔记(一) 1、词频统计:键盘输入一组我国高校所对应的学校类型,以空格分隔,共一行。2、找最大值、最小值、平均分:键盘输入小明学习的课程名称及考分等信息,信息间…...

Spring注解家族介绍: @RequestMapping
前言: 今天我们来介绍RequestMapping这个注解,这个注解的内容相对来讲比较少,篇幅会比较短。 目录 前言: RequestMapping 应用场景: 总结: RequestMapping RequestMapping 是一个用于映射 HTTP 请求…...

系统架构设计师(第二版)学习笔记----信息安全系统及信息安全技术
【原文链接】系统架构设计师(第二版)学习笔记----信息加解密技术 文章目录 一、信息安全系统的组成框架1.1 信息安全系统组成框架1.2 信息安全系统技术内容1.3 常用的基础安全设备1.4 网络安全技术内容1.5 操作系统安全内容1.6 操作系统安全机制1.7 数据…...

交换机的工作原理(含实例,华为ensp操作)
目录 1.交换机学习和转发 案例 1.设置静态地址表项 2.配置黑洞mac地址表项 1.交换机学习和转发 交换机工作在数据链路层。当交换机从某个端口收到一个帧时,它并不是向所有的接口转发此帧,而是根据此帧的目的MAC地址&a…...
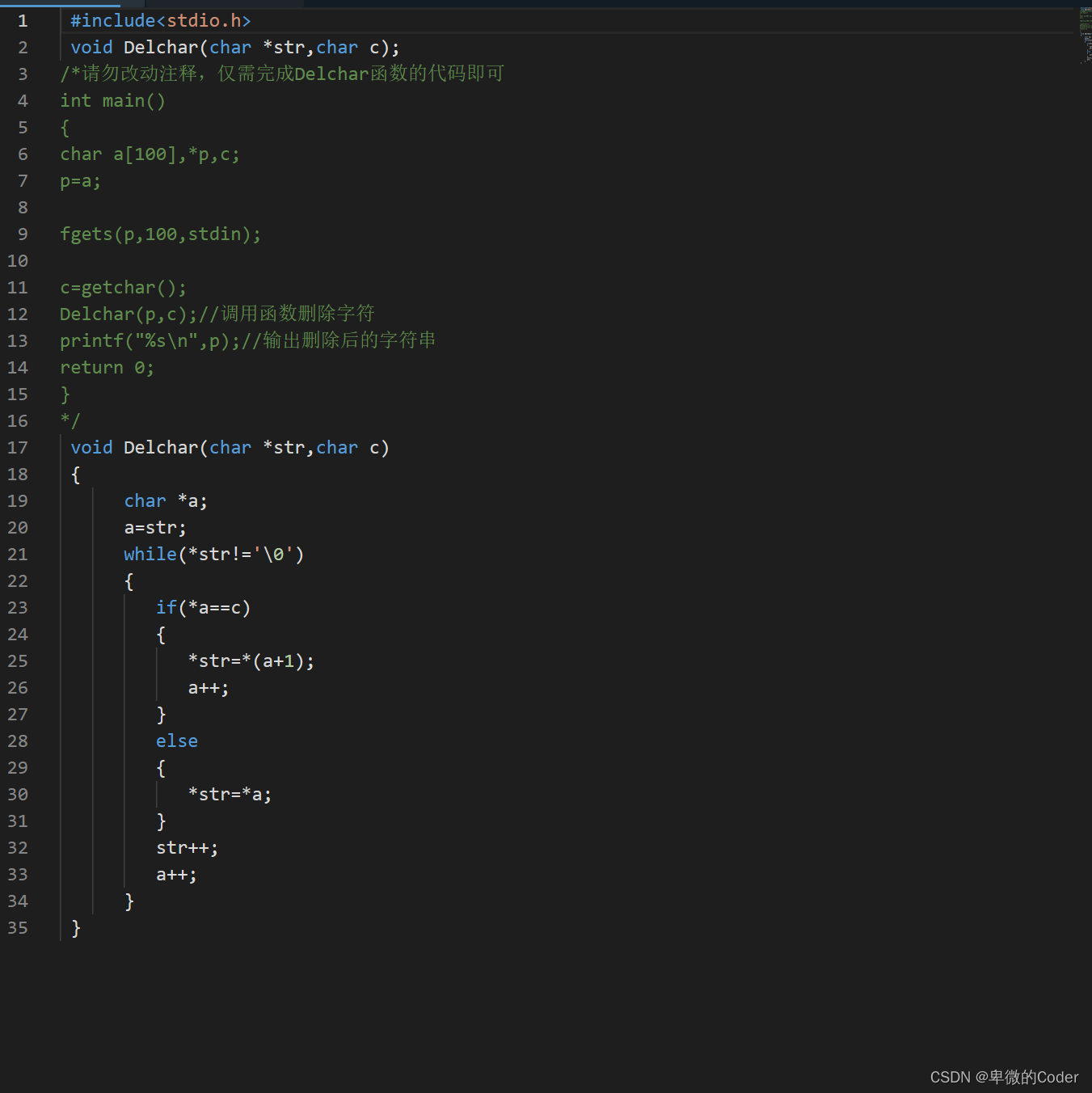
从字符串中删除指定字符
任务描述 编写一个函数实现功能:从字符串中删除指定的字符。同一字母的大、小写按不同字符处理。例如:程序执行时输入字符串:turbo c and Borland c,从键盘输入字符n,则输出后变为:turbo c ad Borlad c。如…...
)
Xcode14.3.1 真机调试iOS17的方法(无iOS17 DeviceSupport)
由于iOS17需要使用Xcode15 才能调试,而当前Xcode15都是beta,正式版还未出,那么要真机调试iOS17的方式一般有两种: 方法一: 一种是下载新的Xcode15 beta版 (但Xcode包一般比较大,好几个G&#…...

JWT基础
概念 JSON Web Token本质上就是一串字符串,一串包含了很多信息的字符串令牌拥有三个部分头部-包含加密算法和令牌类型{"alg":"算法名称","type":"JWT"}负载-包含数据和信息-七个官方默认-也可以自己定义内容{issÿ…...

关于远程工作的面试可能存在的陷阱
附上看到的完整帖子地址:面试 POPER 的后端开发工程师的离奇经历 分享一下我遇到过的,我至少面试过10个远程工作,其中有3个的面试是直接让我完成一个需求的,前两次都耐心做了,第3次看到相同要求时我都懒得回复了&…...
Qt5开发及实例V2.0-第一章Qt概述
Qt5开发及实例V2.0-第一章-Qt概述 第一章-Qt概述1.1 什么是Qt1.2 Qt 5的安装1.2.1 下载安装Qt 51.2.2 运行Qt 5 Creator1.2.3 Qt 5开发环境 1.3 Qt 5开发步骤及实例1.3.1 设计器Qt 5 Designer实现1.3.2 代码实现简单实例 L1.2 Qt 5安装:概念解析L1.3 Qt 5开发步骤及…...

matlab检索相似图像
在Matlab中检索相似图像通常需要使用图像处理和计算机视觉技术。以下是一种常见的方法,可以帮助您在Matlab中进行相似图像检索: 准备图像数据库: 首先,您需要有一个包含待检索图像的图像数据库。这些图像应该经过预处理࿰…...

ArrayBlockingQueue 带有三个参数的构造函数为何需要加锁?
哪一个构造函数 public ArrayBlockingQueue(int capacity, boolean fair,Collection<? extends E> c) {this(capacity, fair);final ReentrantLock lock = this.lock;lock.lock(); // Lock only for visibility, not mutual exclusiontry {final Object[] items = this…...

实训笔记——Spark计算框架
实训笔记——Spark计算框架 Spark计算框架一、Spark的概述二、Spark的特点三、Spark的安装部署(安装部署Spark的Cluster Manager-资源调度管理器的)3.1 本地安装--无资源管理器3.2 Spark的自带独立调度器Standalone3.2.1 主从架构的软件3.2.2 Master/wor…...
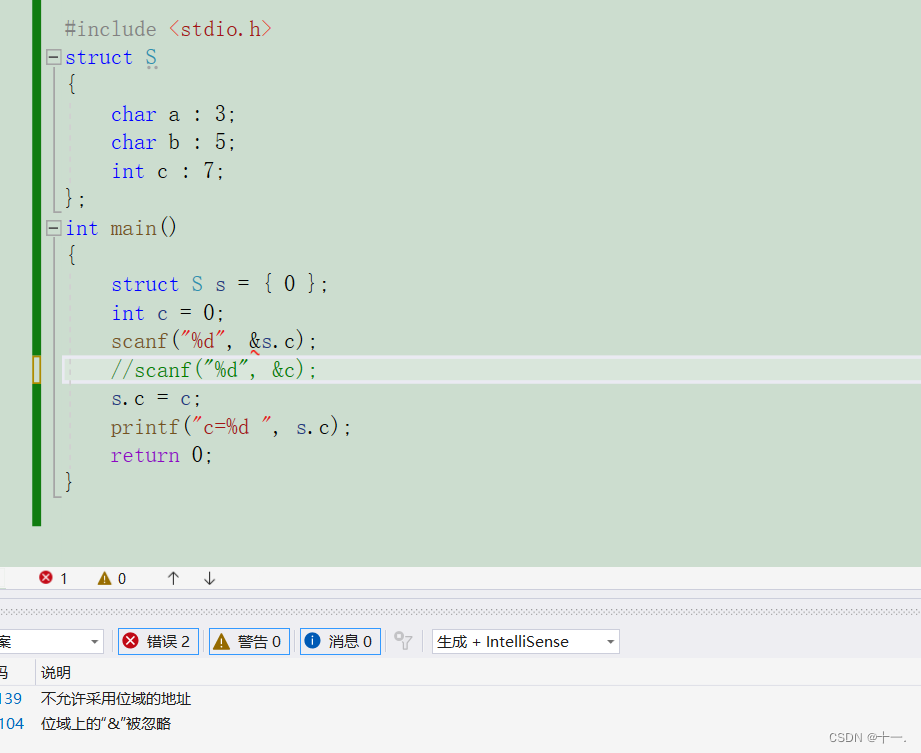
自定义类型:结构体
自定义类型:结构体 一:引入二:结构体类型的声明1:正常声明2:特殊声明 三:结构体变量的创建和初始化1:结构体变量的创建2:结构体变量的初始化 三:结构体访问操作符四:结构…...
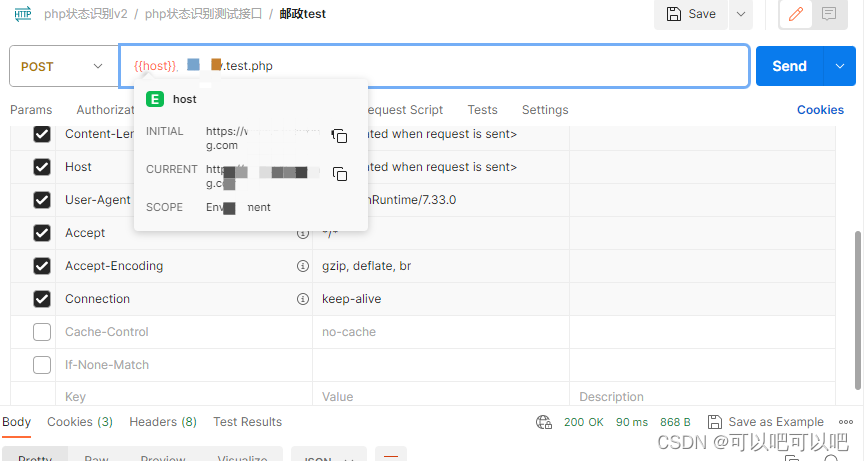
postman如何设置才能SwitchHosts切换host无缓存请求到指定ip服务
开发测试中,遇到多版本同域名的服务使用postman进行测试,一般会搭配SwitchHosts切换host类似工具进行请求,postman缓存比较重,如何做到无缓存请求呢,下面简单记录一下如何实现 首先要知道如何当前请求服务的ip是哪个 打开postman 依次点击/menu/view/show postman console 就…...

LeetCode LCR 103. 零钱兑换【完全背包,恰好装满背包的最小问题】中等
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

竞赛 基于深度学习的人脸专注度检测计算系统 - opencv python cnn
文章目录 1 前言2 相关技术2.1CNN简介2.2 人脸识别算法2.3专注检测原理2.4 OpenCV 3 功能介绍3.1人脸录入功能3.2 人脸识别3.3 人脸专注度检测3.4 识别记录 4 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于深度学习的人脸专注度…...

supervisord 进程管理器 Laravel执行队列
supervisord 进程管理器 执行队列 安装 yum install supervisor修改配置文件 /etc/supervisord.conf 最后一行 ini改为conf files=/etc/supervisor.d/*.conf vim /etc/supervisord.conf/etc/supervisord.d目录下新增配置文件 vim laravel-worker.conf 修改i 粘贴内容 退出修…...

Lnmp架构之mysql数据库实战1
1、mysql数据库编译 编译成功 2、mysql数据库初始化 配置数据目录 全局文件修改内容 生成初始化密码并进行初始化设定 3、mysql主从复制 什么是mysql的主从复制? MySQL的主从复制是一种常见的数据库复制技术,用于将一个数据库服务器(称为主…...

ChatGLM 大模型炼丹手册-理论篇
序言一)大还丹的崛起 在修真界,人们一直渴望拥有一种神奇的「万能型丹药」,可包治百病。 但遗憾的是,在很长的一段时间里,炼丹师们只能对症炼药。每一枚丹药,都是特效药,专治一种病。这样就导致,每遇到一个新的问题,都需要针对性的炼制,炼丹师们苦不堪言,修真者们吐…...

为AI编程助手设置安全规则:从原理到实践的工程指南
1. 项目概述:为你的AI编程伙伴戴上“紧箍咒”如果你和我一样,深度使用Cursor这类AI编程助手,那你一定体验过那种“冰火两重天”的感觉。一方面,它能以惊人的速度生成代码、重构函数、甚至解释复杂逻辑,极大地提升了开发…...

ClawX:OpenClaw AI智能体桌面门户,图形化编排与自动化实战
1. 项目概述:ClawX,为OpenClaw AI智能体打造的桌面门户如果你和我一样,对AI智能体(AI Agent)的潜力感到兴奋,却又对在终端里敲打复杂的命令行、配置繁琐的YAML文件感到头疼,那么ClawX的出现&…...

基于Electron构建macOS效率工具:插件化命令执行与安全实践
1. 项目概述:一个为macOS开发者量身打造的效率工具 最近在GitHub上看到一个挺有意思的项目,叫 zhaobomin/copaw-macapp 。乍一看名字, copaw 这个组合词有点意思,结合 macapp 的后缀,不难猜出这是一个专门为macO…...

Neoscroll.nvim与Telescope集成:实现搜索结果的流畅滚动
Neoscroll.nvim与Telescope集成:实现搜索结果的流畅滚动 【免费下载链接】neoscroll.nvim Smooth scrolling neovim plugin written in lua 项目地址: https://gitcode.com/gh_mirrors/ne/neoscroll.nvim Neoscroll.nvim是一款用Lua编写的Neovim平滑滚动插件…...

121.YOLOv8从零到一实战,猫犬检测全流程,代码带注释,零基础也能学会
摘要 YOLO(You Only Look Once)是当前工业界和学术界最主流的目标检测算法之一,其核心优势在于将目标检测任务转化为单次回归问题,实现端到端的实时检测。本文从零基础出发,系统讲解YOLO的核心原理、模型架构演进,并基于Ultralytics框架提供完整的可运行代码案例,涵盖数…...

基于 base-admin 人事管理系统开源项目学习与功能扩展实战笔记
最近跟着课程实战拆解了base-admin 人事管理系统开源项目,这是一款基于 SpringBoot 搭建的企业级后台管理平台,遵循 Apache 2.0 开源协议,非常适合 Java 后端和软件工程入门练手。项目整体采用经典三层架构,Controller、Service、…...

RocksDB 故障恢复与数据一致性探秘:WAL和MANIFEST文件是如何保证你的数据不丢的?
RocksDB 故障恢复与数据一致性探秘:WAL和MANIFEST文件如何守护你的数据安全 1. 数据库可靠性的基石设计 在分布式系统与存储引擎领域,数据持久性和一致性始终是核心挑战。RocksDB作为一款高性能的嵌入式键值存储引擎,其故障恢复机制的设计堪称…...

Dify-Flow:构建复杂AI工作流的流程编排引擎设计与实现
1. 项目概述:当Dify遇上Flow,一个面向开发者的AI应用编排新范式如果你最近在折腾AI应用开发,特别是想把大语言模型(LLM)的能力集成到自己的业务流程里,那你大概率听说过Dify。它作为一个开源的LLM应用开发平…...
)
告别YAML诅咒:用LLM自动生成可验证CD流水线(附奇点大会开源Schema v2.1)
更多请点击: https://intelliparadigm.com 第一章:AI原生持续交付:2026奇点智能技术大会部署流水线优化 在2026奇点智能技术大会上,AI原生持续交付(AI-Native CI/CD)成为核心实践范式——它不再将AI模型视…...

TeamHero:基于规则引擎的智能任务自动化分配系统设计与实战
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“TeamHero”,作者是sagiyaacoby。乍一看这个名字,你可能会联想到团队协作或者英雄联盟,但实际上,它是一个专注于自动化团队管理与任务分发的工具。简…...