java进阶Map 集合
通过之前的学习我们知道Map是一个双列集合,就是以键值对的形式进行数据存储 java进阶—集合
Map 下面有 三个子接口,HashMap , HashTable 以及 TreeMap
提醒一点:Map不是Collection下的集合,Collection是单列集合(List,Set)
Map 的存储方式跟 list ,set 是不一样的,先来看看他的基本结构长什么样
Map<String,String> resultMap = new HashMap<>(3);
泛型里面,贴的标签是 键值对的类型 ,<键,值> ,括号里面的3 是设置这个Map 容器的大小 ,开发中一定要设置map的初始化大小,具体多少按需求而定
接下来我们一个一个来看
HashMap
可以说HashMap在开发中最常用,代码中随处可见,创建也很简单,new 一个 ,一样的集合创造出来了,不用就浪费了
- 添加(put)
Map<String,String> resultMap = new HashMap<>(3);resultMap.put("1号","去玩");resultMap.put("2号","去吃");resultMap.put("3号","睡觉");
- 移除(remove)
remove 是根据key 移除 value
Map<String, String> resultMap = new HashMap<>(3);resultMap.put("1号", "去玩");resultMap.put("2号", "去吃");resultMap.put("3号", "睡觉");resultMap.remove("1号");
- 是否存在这个Key(containsKey)
Map<String, String> resultMap = new HashMap<>(3);resultMap.put("1号", "去玩");resultMap.put("2号", "去吃");resultMap.put("3号", "睡觉");boolean flag = resultMap.containsKey("3号");System.out.println(flag);

- 是否存在这个Value(containsValue)
Map<String, String> resultMap = new HashMap<>(3);resultMap.put("1号", "去玩");resultMap.put("2号", "去吃");resultMap.put("3号", "睡觉");boolean flag = resultMap.containsValue("上班");System.out.println(flag);

4. 判断集合是否为空(isEmpty)
Map<String, String> resultMap = new HashMap<>(3);resultMap.put("1号", "去玩");resultMap.put("2号", "去吃");resultMap.put("3号", "睡觉");boolean flag = resultMap.isEmpty();System.out.println(flag);

5. 获取集合大小(size)
Map<String, String> resultMap = new HashMap<>(3);resultMap.put("1号", "去玩");resultMap.put("2号", "去吃");resultMap.put("3号", "睡觉");int size = resultMap.size();System.out.println(size);

6. 遍历
map集合遍历这边介绍三种方式
entrySet (推荐使用)
for (Map.Entry<String, String> entry : resultMap.entrySet()) {System.out.println(entry.getKey()+entry.getValue());}

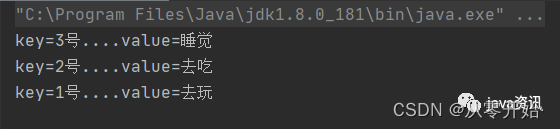
keySet (不要使用,效率很低)
Map<String, String> resultMap = new HashMap<>(3);resultMap.put("1号", "去玩");resultMap.put("2号", "去吃");resultMap.put("3号", "睡觉");for (String s : resultMap.keySet()) {System.out.println("key="+s+"...."+"value="+resultMap.get(s));}
jdk1.8 forEach
Map<String, String> resultMap = new HashMap<>(3);resultMap.put("1号", "去玩");resultMap.put("2号", "去吃");resultMap.put("3号", "睡觉");resultMap.forEach((k, v) -> {System.out.println(k+"..."+v);});
我们来做个实验,看看哪种遍历效率更高
我们先造100W的数据
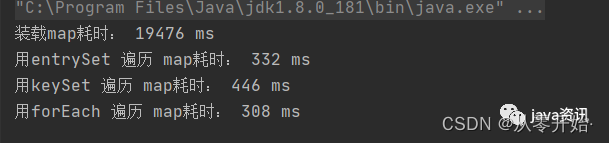
int count = 1000000;long start = System.currentTimeMillis();Map<String, String> resultMap = new HashMap<>(count);for (int i = 1; i <= count; i++) {resultMap.put(i + "", i + " ---> map");}//效率对比,装载Map耗时System.out.println("装载map耗时: "+(System.currentTimeMillis()-start)+ " ms");//用entrySetstart = System.currentTimeMillis();for (Map.Entry<String, String> entry : resultMap.entrySet()) {String key = entry.getKey();String value = entry.getValue();}System.out.println("用entrySet 遍历 map耗时: "+(System.currentTimeMillis()-start)+ " ms");//用keySetstart = System.currentTimeMillis();for (String s : resultMap.keySet()) {String key = s;String value = resultMap.get(s);}System.out.println("用keySet 遍历 map耗时: "+(System.currentTimeMillis()-start)+ " ms");//用forEachstart = System.currentTimeMillis();resultMap.forEach((k, v) -> {String key = k;String value = v;});System.out.println("用forEach 遍历 map耗时: "+(System.currentTimeMillis()-start)+ " ms");
输出
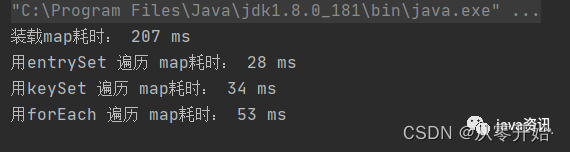
可以看到,entrySet效率是最高的 forEach 效率是最低的
当我们把数据调整到1000W时
int count = 10000000;long start = System.currentTimeMillis();Map<String, String> resultMap = new HashMap<>(count);for (int i = 1; i <= count; i++) {resultMap.put(i + "", i + " ---> map");}//效率对比,装载Map耗时System.out.println("装载map耗时:"+(System.currentTimeMillis()-start)+ " ms");//用entrySetstart = System.currentTimeMillis();for (Map.Entry<String, String> entry : resultMap.entrySet()) {String key = entry.getKey();String value = entry.getValue();}System.out.println("用entrySet 遍历 map耗时:"+(System.currentTimeMillis()-start)+ " ms");//用keySetstart = System.currentTimeMillis();for (String s : resultMap.keySet()) {String key = s;String value = resultMap.get(s);}System.out.println("用keySet 遍历 map耗时:"+(System.currentTimeMillis()-start)+ " ms");//用forEachstart = System.currentTimeMillis();resultMap.forEach((k, v) -> {String key = k;String value = v;});System.out.println("用forEach 遍历 map耗时:"+(System.currentTimeMillis()-start)+ " ms");
输出结果:
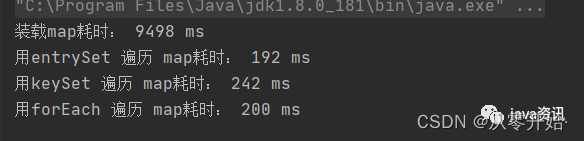
entrySet 的效率依然是最高的,foreach这边效率跟entry差不多了
将数据 换成1500W
int count = 15000000;long start = System.currentTimeMillis();Map<String, String> resultMap = new HashMap<>(count);for (int i = 1; i <= count; i++) {resultMap.put(i + "", i + " ---> map");}//效率对比,装载Map耗时System.out.println("装载map耗时:"+(System.currentTimeMillis()-start)+ " ms");//用entrySetstart = System.currentTimeMillis();for (Map.Entry<String, String> entry : resultMap.entrySet()) {String key = entry.getKey();String value = entry.getValue();}System.out.println("用entrySet 遍历 map耗时:"+(System.currentTimeMillis()-start)+ " ms");//用keySetstart = System.currentTimeMillis();for (String s : resultMap.keySet()) {String key = s;String value = resultMap.get(s);}System.out.println("用keySet 遍历 map耗时:"+(System.currentTimeMillis()-start)+ " ms");//用forEachstart = System.currentTimeMillis();resultMap.forEach((k, v) -> {String key = k;String value = v;});System.out.println("用forEach 遍历 map耗时:"+(System.currentTimeMillis()-start)+ " ms");
可以看到forEach的效率是最高的,keySet 效率一直很低
总结: 对map进行遍历,建议使用 entrySet,数据量很庞大,千万级别,建议用forEach ,keySet不要用
HashTable
HashTable 不建议使用,就跟vector 跟arrayList 一样 ,其主要一个原因就是线程安全(这是个优点),但是它效率低
TreeMap
treeMap中的元素默认是按照key来进行自然排序的
对Integer来说,其自然排序就是数字的升序
对String来说,其自然排序就是按照字母表排序
主要体现在他的构造
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, Serializable
来看代码:
TreeMap<Integer, String> treeMap = new TreeMap<>();treeMap.put(1,"1号");treeMap.put(7,"7号");treeMap.put(6,"6号");treeMap.put(3,"3号");for (Map.Entry<Integer, String> entry : treeMap.entrySet()) {System.out.println(entry.getKey()+"...."+entry.getValue());}
打印结果:

【最后来一个例子,加深对map集合的使用】
创建三个学生,有属性(姓名,年龄),给每个学生定义上整形编号, 保存在map中,并且遍历输出学生编号,姓名,年龄
public class Person {private String name;private Integer age;public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}
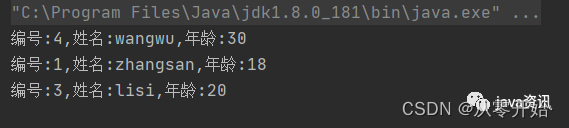
}public static void main(String[] args) {Map<Integer, Person> treeMap = new HashMap<>(3);treeMap.put(1,new Person("zhangsan",18));treeMap.put(3,new Person("lisi",20));treeMap.put(4,new Person("wangwu",30));for (Map.Entry<Integer, Person> entry : treeMap.entrySet()) {System.out.println("编号:"+entry.getKey()+",姓名:"+entry.getValue().getName()+",年龄:"+entry.getValue().getAge());}}
执行结果:
相关文章:
java进阶Map 集合
通过之前的学习我们知道Map是一个双列集合,就是以键值对的形式进行数据存储 java进阶—集合 Map 下面有 三个子接口,HashMap , HashTable 以及 TreeMap 提醒一点:Map不是Collection下的集合,Collection是单列集合&am…...

Java 方法超详细整理,适合新手入门
目录 一、什么是方法呢? 二、方法的优点 三、带返回值方法定义 语法: 示例: 四、带返回值方法调用 语法: 示例: 五、结果示例 一、什么是方法呢? Java方法是语句的集合,它们在一起执行…...

软考学习笔记(题目知识记录)
答案为 概要设计阶段 本题涉及软件工程的概念 软件工程的任务是基于需求分析的结果建立各种设计模型,给出问题的解决方案 软件设计可以分为两个阶段: 概要设计阶段和详细设计阶段 结构化设计方法中,概要设计阶段进行软件体系结构的设计&…...
2021.3.3idea创建Maven项目
首先new - project - 找到Maven 然后按下图操作:先勾选使用骨架,再找到Maven-archetype-webapp,选中,然后next填写自己想要创建的项目名,然后选择自己的工作空间①、选择自己下载的Maven插件②、选择选择Maven里的sett…...
ASP.NET MVC | 创建应用程序
目录 首先 NO.1 No.2 App_Data 文件夹 Content 文件夹 Controllers 文件夹 Models 文件夹 Views 文件夹 Scripts 文件夹 最后 首先 一步一步的来,电脑上需要安装vs2019软件,版本高低无所谓,就是功能多少而已。 长这样的࿰…...
)
思科设备命令讲解(超基础)
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...
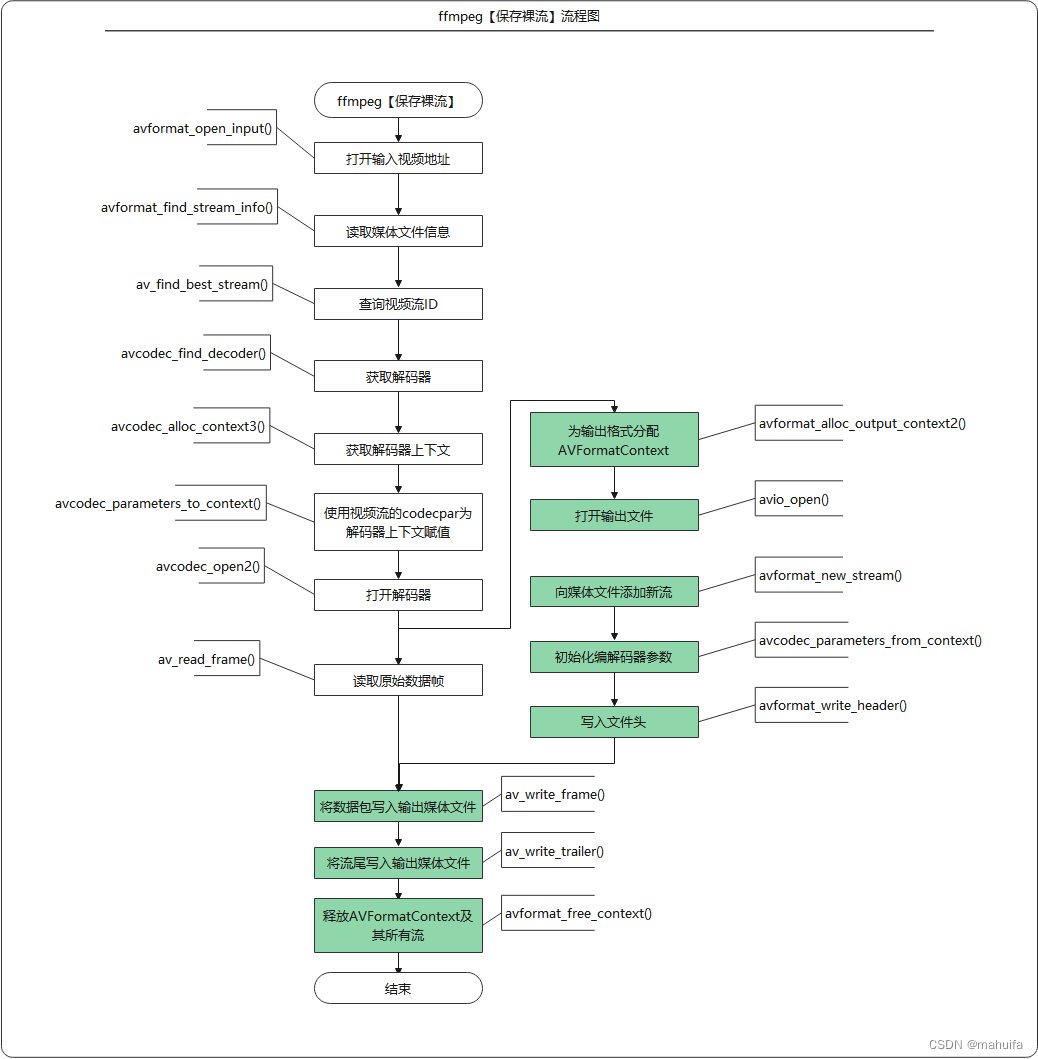
Qt-FFmpeg开发-保存视频流裸流(11)
Qt-FFmpeg开发-保存视频流裸流📀 文章目录Qt-FFmpeg开发-保存视频流裸流📀1、概述📸2、实现效果💽3、FFmpeg保存裸流代码流程💡4、主要代码🔍5、完整源代码📑更多精彩内容👉个人内容…...

Zebec官方辟谣“我们与Protradex没有任何关系”
近日,流支付协议Zebec Protocol在其官方推特上,发表了一个辟谣澄清声明。该条推特推文表示,“Zebec 与 Protradex 没有任何关系或产生关联。他们( Protradex )声称Zebec 生态正在支持他们,但这是错误的。随…...

BMS电池管理系统中的各种算法介绍
BMS电池管理系统 是一种用于电池组中的单个电池管理的系统,以确保其安全性、寿命和性能。BMS系统通过采集电池信息并对其进行分析,以确保电池组的正常运行。在BMS电池管理系统中,涉及到了许多算法,包括最大功率点追踪算法、SOC计算…...

stack Overflow 的使用
文章目录优雅的搜索1.1要在特定标签内搜索1.2搜索特定的短语1.3 限定检索位置1.4选择性屏蔽优雅的筛选搜索结果1. 返回的搜索筛选2. 特定时间段的帖子3. 精准的BOOL判断4. 其他的例子优雅的搜索 其实,在Stack OverFlow上的搜索方式,与国内的百度没什么大…...

Vue 在for循环中动态添加类名及style样式集合
介绍 在vue的 for 循环中,经常会使用到动态添加类名或者样式的情况,实现给当前的选中的 div 添加不同的样式。 动态添加类名 提示: 所有动态添加的类名,放在表达式里都需要添加引号,进行包裹。 通过 对象 的形式&a…...

Maven的优势
作用一:个人理解maven主要是用来解决导入java类依赖的jar,编译java项目主要问题。(最早手动导入jar,使用Ant之类的编译java项目)以pom.xml文件中dependency属性管理依赖的jar包,而jar包包含class文件和一些必要的资源文件。当然它可以构建项目…...

uboot,内核,根文件系统的作用
复习了下uboot,内核,根文件系统,简单概括下三者的主要内容。 1 uboot uboot的目的:启动内核。 uboot的功能可以分为两个阶段任务。 1.2.1 uboot第一阶段 uboot第一阶段主要负责硬件相关的初始化,主要在cpu/arm920…...

Vue3通透教程【四】Vue3组合API初体验
文章目录🌟 写在前面🌟 组合式 API 是什么?🌟 直观组合式API🌟 写在最后🌟 写在前面 专栏介绍: 凉哥作为 Vue 的忠实 粉丝输出过大量的 Vue 文章,应粉丝要求开始更新 Vue3 的相关技…...

coco数据集训练nanodet详细流程
github地址 首先要配置环境 conda create -n nanodet python3.8 -y conda activate nanodet确认一下cuda版本 nvcc -V确认是11.3之后,要安装11.3对应的pytorch版本。 本机装pytorch1.12.1后面运行的时候会报错(torch没有经过cuda编译)&…...
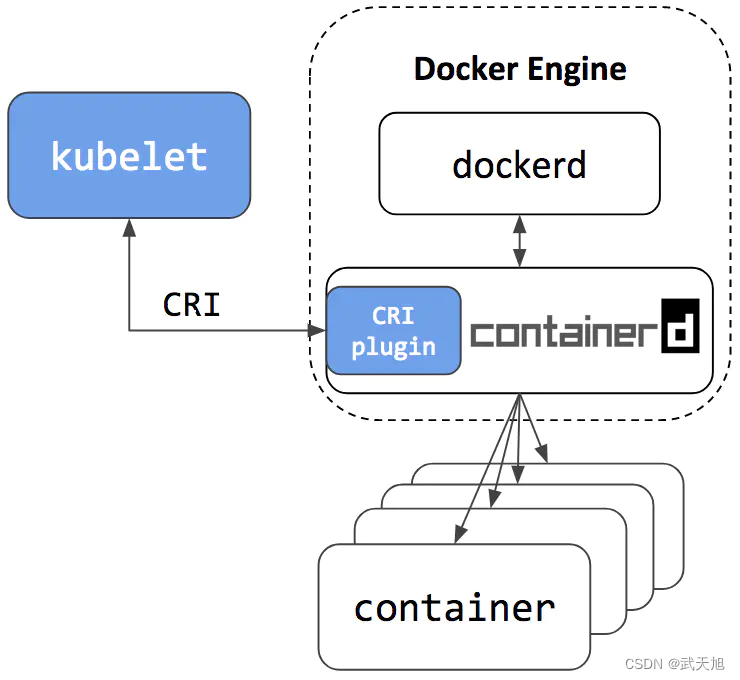
关于Kubernetes不兼容Docker
本博客地址:https://security.blog.csdn.net/article/details/129153459 参考文献:https://www.cnblogs.com/1234roro/p/16892031.html 一、总结 总结起来就是一句话: k8s只是弃用了dockershim,并不是弃用了整个Docker…...
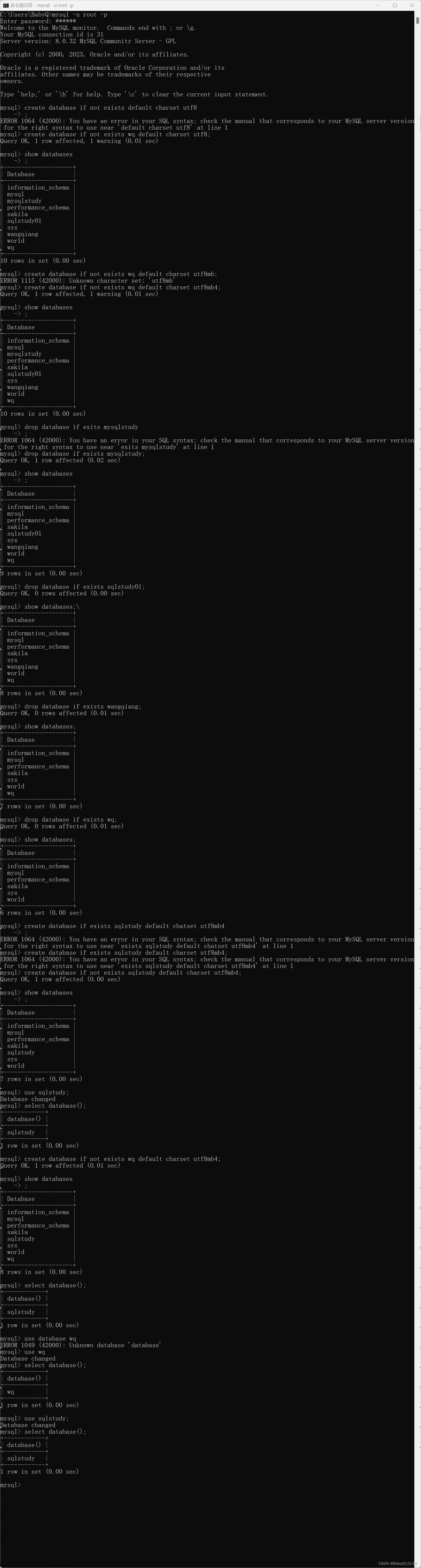
MySql_基础篇_从下载mysq到数据库操作
本笔记基于b站up主黑马程序员的视频整理 用于记录与回顾 数据库相关概念 数据库 DS 存储数据的仓库 数据库管理系统 DSMS 操纵和管理数据库的大型软件 sql 操作关系型数据库的编程语言是一套标准 mysql 默认端口号是3306 下载数据库 社区版下载 https://dev.mysql.com/…...

当我尝试问了chatGPT几个问题之后,我感到了危机......
问题1 : vue3 框架的bug有哪些? 组件内部的状态更新不及时:由于Vue3使用Proxy来实现响应式,在某些情况下,组件内部的状态更新不及时,导致组件的渲染出现问题。 组件内部的数据更新不及时:由于V…...

如何生成全局唯一ID
1.数据库自增ID 2.UUID 3.Redis生成ID 4.zookeeper生成ID 5.雪花算法...
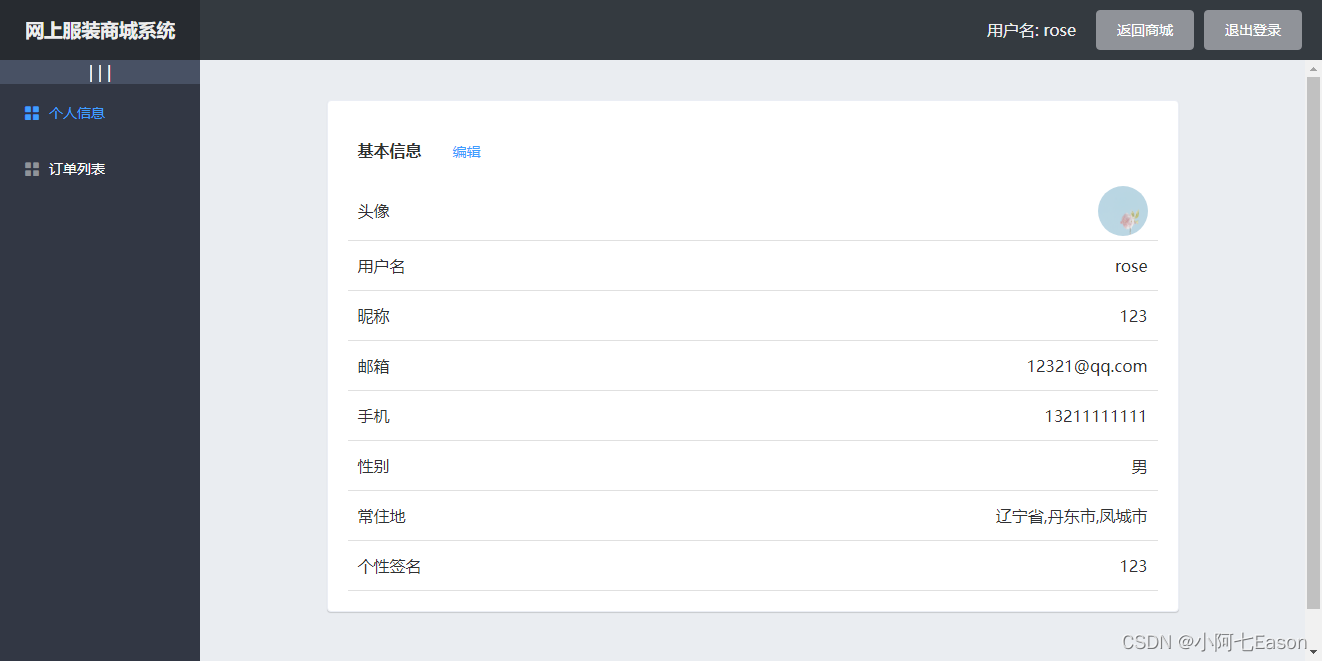
基于node vue的电商系统 mongodb express框架
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 基于node vue的电商系统 mongodb express框架前言技术栈基本功能普通用户管理员一、运行截图?二、使用步骤1.前端main.js2.后端admin路由前言 技术栈 本项目采用…...

ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程
ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程 【免费下载链接】ZjDroid Android app dynamic reverse tool based on Xposed framework. 项目地址: https://gitcode.com/gh_mirrors/zj/ZjDroid ZjDroid是一款基于Xposed框架的Android应用动态逆向分…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...
)
37家金融客户紧急启用的DeepSeek扫描辅助加固包(含未公开API调用密钥策略)
更多请点击: https://kaifayun.com 第一章:DeepSeek漏洞扫描辅助的背景与战略价值 近年来,大模型在安全领域的应用正从辅助问答向深度协同防御演进。DeepSeek系列模型凭借其开源、高推理精度及强代码理解能力,成为构建智能化漏洞…...

阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月
阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月 Jianbing Zhu 1^{1}1 1^{1}1 ECT-OS-JiuHuaShan 文明实验室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20373157 Email: ect-os-jiuhuashanzoho…...

phpMyAdmin CVE-2018-12613:从文件读取到RCE的伪协议利用链
1. 这个漏洞不是“能读文件”那么简单,而是后台权限的彻底失守phpMyAdmin 4.8.1里那个CVE-2018-12613,很多人扫到就报个“存在文件包含”,顺手贴个?targetphp://filter/convert.base64-encode/resource/etc/passwd截图完事。我去年在给一家教…...