JS操作数组方法学习系列(1)
目录
- 数组添加元素 (push)
- 数组移除末尾元素 (pop)
- 数组添加元素到开头 (unshift)
- 数组移除开头元素 (shift)
- 数组查找元素索引 (indexOf)
- 数组反向查找元素索引 (lastIndexOf)
- 数组切割 (slice)
- 数组连接 (concat)
- 数组元素查找 (find 和 findIndex)
- 数组元素过滤 (filter)
- 数组元素映射 (map)
- 数组元素归并 (reduce)
- 数组元素迭代 (forEach)
- 数组元素去重 (filter 和 Set)
- 数组元素排序和去重 (sort 和 Set)
- 数组元素计数 (reduce 和 Object)
- 数组元素计数 (reduce 和 Map)
👍 点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富!
数组添加元素 (push)
作用: 向数组末尾添加一个或多个元素,并返回新数组的长度。
示例:
const fruits = ['apple', 'banana'];
const newLength = fruits.push('cherry');
// newLength: 3, fruits: ['apple', 'banana', 'cherry']
常见场景: 在数组中动态添加新数据。
数组移除末尾元素 (pop)
作用: 移除并返回数组的最后一个元素。
示例:
const fruits = ['apple', 'banana', 'cherry'];
const removedFruit = fruits.pop();
// removedFruit: 'cherry', fruits: ['apple', 'banana']
常见场景: 移除最后一个元素,如栈操作。
数组添加元素到开头 (unshift)
作用: 向数组开头添加一个或多个元素,并返回新数组的长度。
示例:
const fruits = ['banana', 'cherry'];
const newLength = fruits.unshift('apple');
// newLength: 3, fruits: ['apple', 'banana', 'cherry']
常见场景: 在数组开头插入新数据。
数组移除开头元素 (shift)
作用: 移除并返回数组的第一个元素。
示例:
const fruits = ['apple', 'banana', 'cherry'];
const removedFruit = fruits.shift();
// removedFruit: 'apple', fruits: ['banana', 'cherry']
常见场景: 移除第一个元素,如队列操作。
数组查找元素索引 (indexOf)
作用: 返回数组中第一个匹配元素的索引,如果未找到则返回-1。
示例:
const numbers = [1, 2, 3, 4, 5];
const index = numbers.indexOf(3);
// index: 2
常见场景: 查找元素在数组中的位置。
数组反向查找元素索引 (lastIndexOf)
作用: 返回数组中最后一个匹配元素的索引,如果未找到则返回-1。
示例:
const numbers = [1, 2, 3, 4, 3, 5];
const lastIndex = numbers.lastIndexOf(3);
// lastIndex: 4
常见场景: 反向查找元素在数组中的位置。
数组切割 (slice)
作用: 从数组中提取一个子数组,不会修改原数组。
示例:
const fruits = ['apple', 'banana', 'cherry', 'date'];
const slicedFruits = fruits.slice(1, 3);
// slicedFruits: ['banana', 'cherry']
常见场景: 提取部分数组,而不影响原始数据。
数组连接 (concat)
作用: 连接两个或多个数组,并返回一个新数组。
示例:
const fruits1 = ['apple', 'banana'];
const fruits2 = ['cherry', 'date'];
const combinedFruits = fruits1.concat(fruits2);
// combinedFruits: ['apple', 'banana', 'cherry', 'date']
常见场景: 将多个数组合并成一个。
数组元素查找 (find 和 findIndex)
作用: find返回数组中满足条件的第一个元素,findIndex返回数组中满足条件的第一个元素的索引。
示例:
const numbers = [1, 2, 3, 4, 5];
const evenNumber = numbers.find(num => num % 2 === 0);
const evenIndex = numbers.findIndex(num => num % 2 === 0);
// evenNumber: 2, evenIndex: 1
常见场景: 查找满足特定条件的元素或索引。
数组元素过滤 (filter)
作用: 创建一个新数组,其中包含满足条件的所有元素。
示例:
const numbers = [1, 2, 3, 4, 5];
const evenNumbers = numbers.filter(num => num % 2 === 0);
// evenNumbers: [2, 4]
常见场景: 从数组中过滤出满足条件的元素。
数组元素映射 (map)
作用: 创建一个新数组,其中包含对原数组中的每个元素应用函数后的结果。
示例:
const numbers = [1, 2, 3, 4, 5];
const squaredNumbers = numbers.map(num => num * num);
// squaredNumbers: [1, 4, 9, 16, 25]
常见场景: 对数组中的每个元素进行转换或映射。
数组元素归并 (reduce)
作用: 将数组中的元素累积为一个值,通过指定的函数。
示例:
const numbers = [1, 2, 3, 4, 5];
const sum = numbers.reduce((acc, num) => acc + num, 0);
// sum: 15
常见场景: 对数组中的元素执行归纳操作,如计算总和或找到最大值。
数组元素迭代 (forEach)
作用: 遍历数组中的每个元素,对每个元素执行提供的函数。
示例:
const fruits = ['apple', 'banana', 'cherry'];
fruits.forEach(fruit => console.log(fruit));
// 输出: 'apple', 'banana', 'cherry'
常见场景: 执行对每个元素的操作,例如打印或发送请求。
数组元素去重 (filter 和 Set)
作用: 使用filter和Set对象来去重数组中的元素。
示例:
const numbers = [1, 2, 2, 3, 4, 4, 5];
const uniqueNumbers = numbers.filter((value, index, self) => self.indexOf(value) === index);
// 或者
const uniqueNumbers2 = [...new Set(numbers)];
// uniqueNumbers: [1, 2, 3, 4, 5]
常见场景: 去除数组中的重复元素。
数组元素排序和去重 (sort 和 Set)
作用: 使用sort方法进行排序,然后使用Set对象去重。
示例:
const numbers = [5, 2, 9, 2, 1, 5];
const sortedUniqueNumbers = [...new Set(numbers.sort((a, b) => a - b))];
// sortedUniqueNumbers: [1, 2, 5, 9]
常见场景: 对数组元素进行排序并去重。
数组元素计数 (reduce 和 Object)
作用: 使用reduce和对象来计算数组中每个元素的出现次数。
示例:
const fruits = ['apple', 'banana', 'cherry', 'apple', 'banana'];
const fruitCount = fruits.reduce((acc, fruit) => {acc[fruit] = (acc[fruit] || 0) + 1;return acc;
}, {});
常见场景: 计算数组中元素的出现频率。
数组元素计数 (reduce 和 Map)
作用: 使用reduce和Map对象来计算数组中每个元素的出现次数。
示例:
const fruits = ['apple', 'banana', 'cherry', 'apple', 'banana'];
const fruitCount = fruits.reduce((acc, fruit) => {acc.set(fruit, (acc.get(fruit) || 0) + 1);return acc;
}, new Map());
常见场景: 计算数组中元素的出现频率,同时保留键值对。
相关文章:
)
JS操作数组方法学习系列(1)
目录 数组添加元素 (push)数组移除末尾元素 (pop)数组添加元素到开头 (unshift)数组移除开头元素 (shift)数组查找元素索引 (indexOf)数组反向查找元素索引 (lastIndexOf)数组切割 (slice)数组连接 (concat)数组元素查找 (find 和 findIndex)数组元素过滤 (filter)数组元素映射…...

翻牌闯关游戏
翻牌闯关游戏 3关:关卡由少至多12格、20格、30格图案:12个玩法:点击两张卡牌,图案一到即可消除掉 记忆时长(毫秒):memoryDurationTime:5000 可配置:默认5000 提示游戏玩法:showTipsFlag:1 可…...

CilckHouse创建表
一、引擎 一开始没注意有引擎选择,要用什么引擎去官方文档看看自己建的表适合什么引擎,大部分用MergeTree 二、用sql语句生成表 1、MergeTree引擎 原文地址:https://blog.csdn.net/qq_21383435/article/details/122812921?ops_request_misc%…...
Ceph 概述与部署)
高级运维学习(八)Ceph 概述与部署
ceph概述 ceph可以实现的存储方式: 块存储:提供像普通硬盘一样的存储,为使用者提供“硬盘”文件系统存储:类似于NFS的共享方式,为使用者提供共享文件夹对象存储:像百度云盘一样,需要使用单独的客…...
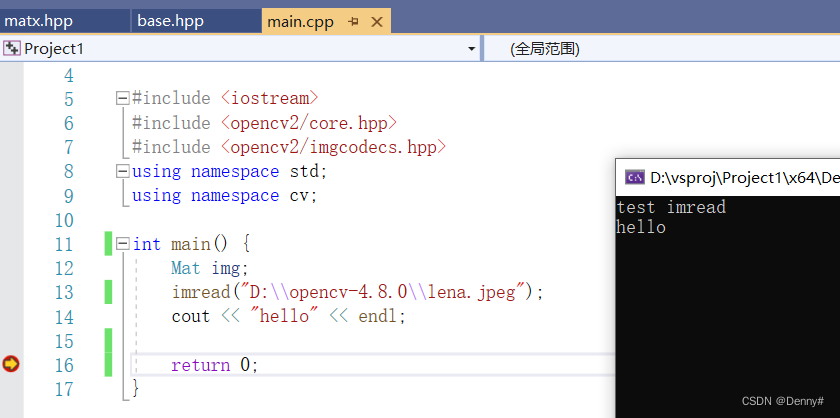
【图像处理】VS编译opencv源码,并调用编译生成的库
背景 有些时候我们需要修改opencv相关源码, 这里介绍怎么编译修改并调用修改后的库文件。 步骤 1、下载相关源码工具: 下载opencv4.8源码并解压 https://down.chinaz.com/soft/40730.htm 下载VS2019,社区版免费 https://visualstudio.micro…...
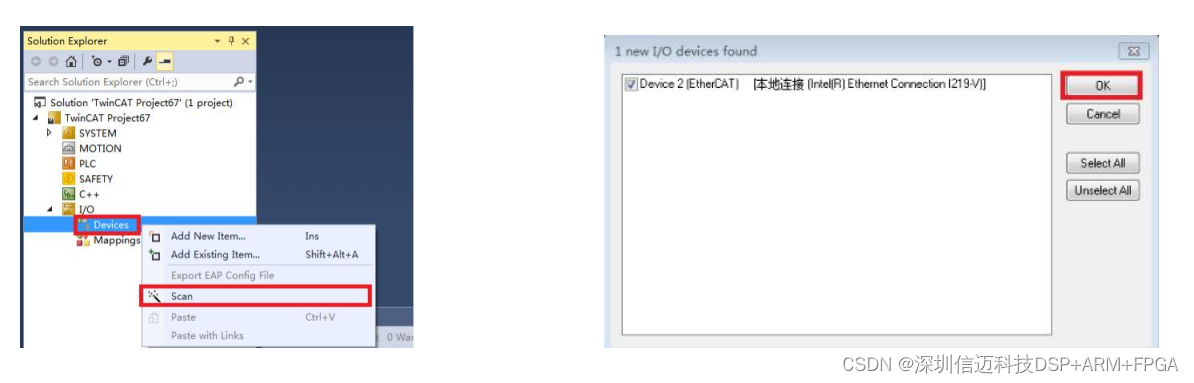
STM32 EtherCAT 总线型(1 拖 4)步进电机解决方案
第 1 章 概述 技术特点 支持标准 100M/s 带宽全双工 EtherCAT 总线网络接口及 CoE 通信协议一 进一出(RJ45 接口),支持多组动态 PDO 分组和对象字典的自动映射,支持站 号 ID 的自动设置与保存,支持 SDO 的…...
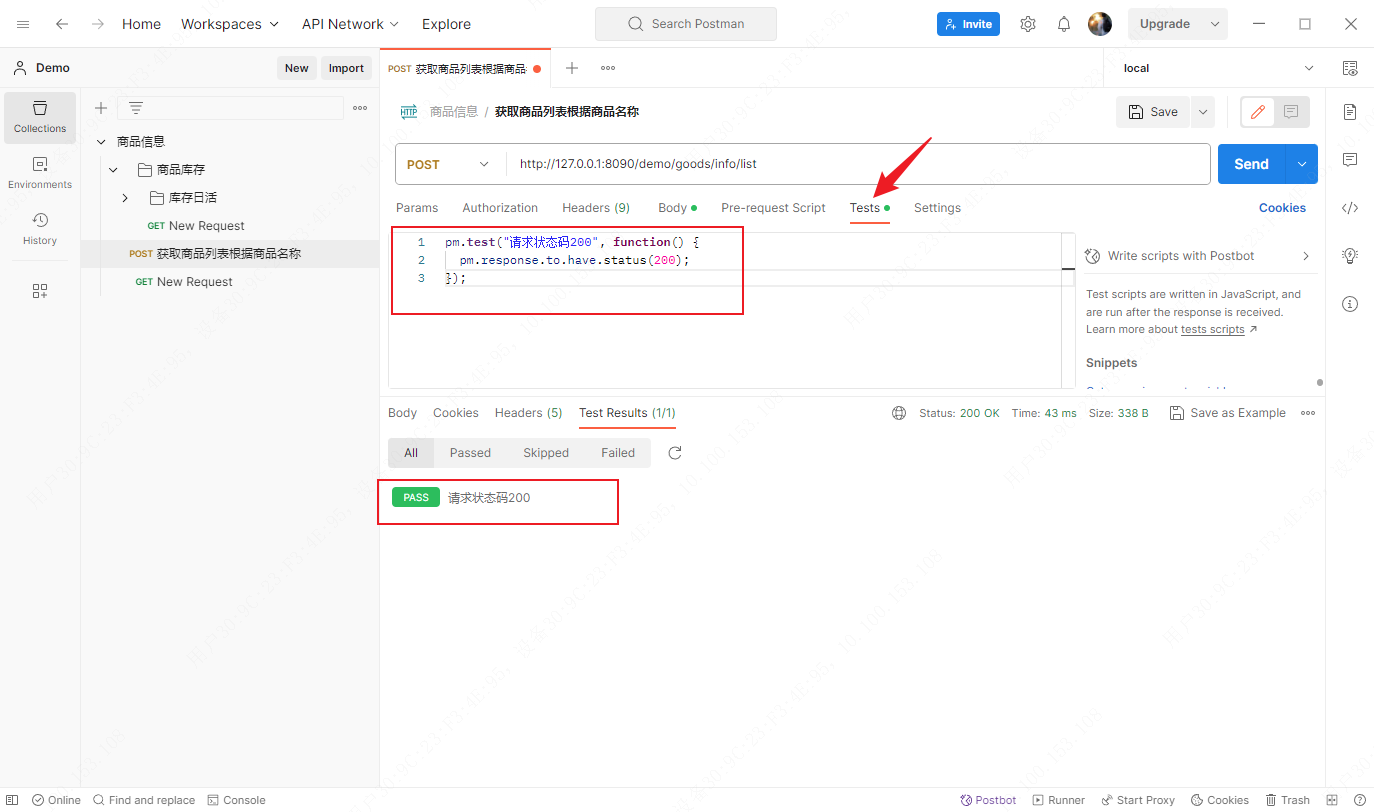
Postman应用——测试脚本Test Script
文章目录 Test Script脚本CollectionFolderRequest 解析响应体断言测试 测试脚本可以在Collection、Folder和Request的Pre-request script 和 Test script中编写,测试脚本可以检测请求响应的各个方面,包括正文、状态代码、头、cookie、响应时间等&#x…...

JS的网络状态以及强网弱网详解
文章目录 1. online 和 offline 事件2. navigator.onLine2.1 什么是 navigator.connection?2.2 如何使用 navigator.connection?2.3 总结 1. online 和 offline 事件 online 和 offline 事件是浏览器自带的两个事件,可以通过添加事件监听器来…...
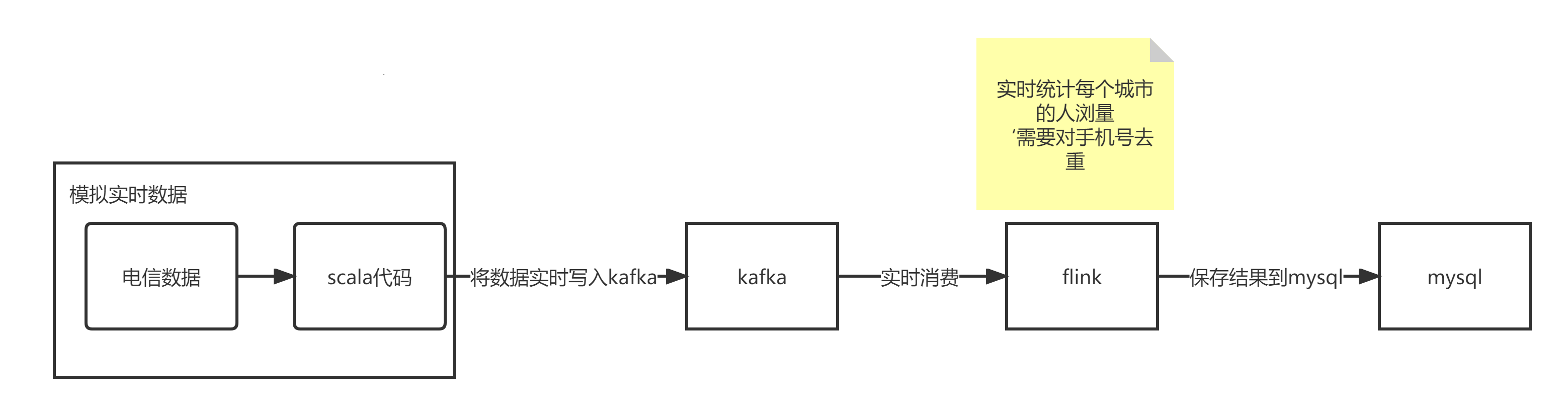
大数据-kafka学习笔记
Kafka Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。 Kafka可以用作Flink应用程序的数据源。Flink可以轻松地从一个或多个Kafka主题中消费数据流。这意味着您可以使用Kafka来捕获和传输…...

详述RPA项目管理流程,RPA项目管理流程是什么?
RPA(Robotic Process Automation,机器人流程自动化)是一种通过软件机器人模拟人类在计算机上执行重复性任务的技术。RPA可以帮助企业提高工作效率、降低成本、减少错误并提高客户满意度。然而,为了确保RPA项目的成功实施ÿ…...

爬虫 — Js 逆向
目录 一、概念1、爬虫2、反爬虫3、加密解密4、加密5、步骤 二、常用加密方式1、加密方式2、常见加密算法3、JS 中常见的算法4、MD5 算法4.1、MD5 加密网站4.2、特点 5、DES/AES 算法6、RSA 算法7、base64 算法 三、环境配置1、node.js 环境配置2、PyCharm 环境配置 一、概念 1…...
Python 网络爬取的时候使用那种框架
尽管现代的网站多采取前后端分离的方式进行开发了,但是对直接 API 的调用我们通常会有 token 的限制和可以调用频率的限制。 因此,在一些特定的网站上,我们可能还是需要使用网络爬虫的方式获得已经返回的 JSON 数据结构,甚至是处理…...
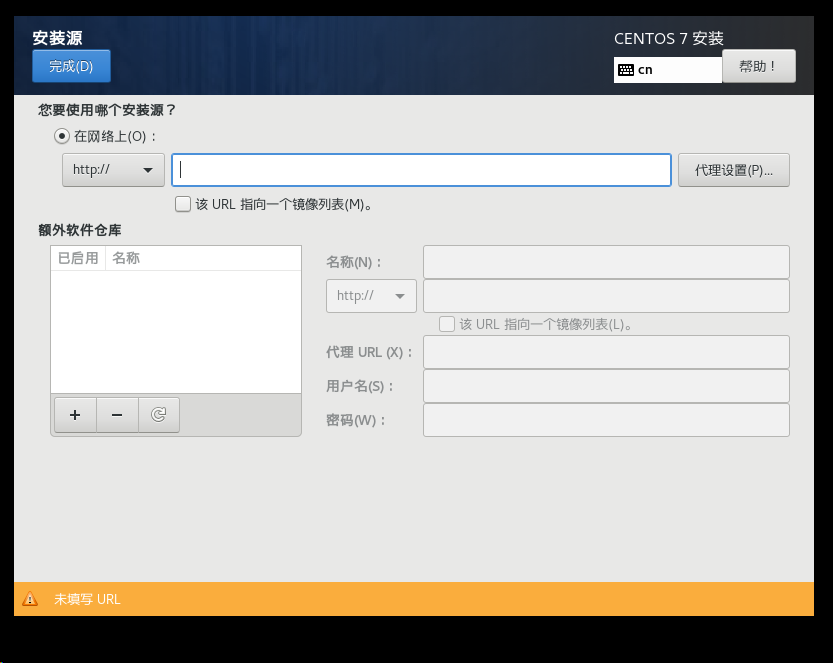
CentOS7安装源设置
此处的安装源地址需要填写:(适用于centos7) http://mirrors.aliyun.com/centos/7/os/x86_64/...
报错:module object has no attribute Pool)
pool = multiprocessing.Pool()报错:module object has no attribute Pool
pool multiprocessing.Pool()报错:module object has no attribute Pool,为什么? 我很抱歉,前面提供的回答是错误的。在Python的multiprocessing模块中,确实有一个名为Pool的类。如果你在使用multiprocessing.Pool()…...

Linux Shell 实现一键部署podman
podman 介绍 使用 Podman 管理容器、Pod 和映像。从本地环境中无缝使用容器和 Kubernetes,Podman 提供与 Docker 非常相似的功能,它不需要在你的系统上运行任何守护进程,并且它也可以在没有 root 权限的情况下运行。 Podman 可以管理和运行…...

Biome-BGC生态系统模型与Python融合技术
Biome-BGC是利用站点描述数据、气象数据和植被生理生态参数,模拟日尺度碳、水和氮通量的有效模型,其研究的空间尺度可以从点尺度扩展到陆地生态系统。 在Biome-BGC模型中,对于碳的生物量积累,采用光合酶促反应机理模型计算出每天…...
Matlab图像处理-区域描述
一旦一幅图像的目标区域被确定,我们往往用一套描述子来表示其特性。选择区域描述子的动机不单纯为了减少在区域中原始数据的数量,而且也应有利于区别带有不同特性的区域。因此,当目标区域有大小、旋转、平移等方面的变化时,针对这…...

openGauss学习笔记-69 openGauss 数据库管理-创建和管理普通表-更新表中数据
文章目录 openGauss学习笔记-69 openGauss 数据库管理-创建和管理普通表-更新表中数据 openGauss学习笔记-69 openGauss 数据库管理-创建和管理普通表-更新表中数据 修改已经存储在数据库中数据的行为叫做更新。用户可以更新单独一行、所有行或者指定的部分行。还可以独立更新…...

Flink RowData 与 Row 相互转化工具类
RowData与Row区别 (0)都代表了一条记录。都可以设置RowKind,和列数量Aritry。 (1)RowData 属于Table API,而Row属于Stream API (2)RowData 属于Table内部接口,对用户不友…...
企业架构LNMP学习笔记48
数据结构类型操作: 数据结构:存储数据的方式 数据类型 算法:取数据的方式,代码就把数据进行组合,计算、存储、取出。 排序算法:冒泡排序、堆排序 二分。 key: key的命名规则不同于一般语言…...

2026发文避坑指南:告别大众型AI,用对垂直编辑器让过审更轻松
在2026年的学术大环境下,核心期刊的收录门槛持续走高,许多科研工作者正面临着一种隐性焦虑:明明实验数据扎实、研究背景深厚,投递出去的稿件却屡屡被退。其实,很多时候被拒的根本原因并非学术价值不足,而是…...

抖音批量下载终极指南:3步实现无水印高清视频免费下载
抖音批量下载终极指南:3步实现无水印高清视频免费下载 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppo…...

怎样高效管理微信社交网络:5个微信工具箱实用技巧完整指南
怎样高效管理微信社交网络:5个微信工具箱实用技巧完整指南 【免费下载链接】wechat-toolbox WeChat toolbox(微信工具箱) 项目地址: https://gitcode.com/gh_mirrors/we/wechat-toolbox 微信工具箱(wechat-toolbox…...

短视频矩阵系统技术选型:从自研到 SaaS 的成本与收益分析
前言在短视频运营规模化的今天,几乎所有有一定规模的团队都面临着一个关键的技术决策:是自研矩阵管理系统,还是选择成熟的 SaaS 解决方案。很多团队在初期都会选择自研,认为这样可以更好地满足个性化需求,但最终往往陷…...

别再手动下载了!用Chocolatey在Windows上一键安装Zookeeper 3.8.0
告别繁琐配置:用Chocolatey在Windows上极速部署Zookeeper 每次在Windows环境下部署Zookeeper,你是否还在重复下载压缩包、配置环境变量、修改配置文件的传统流程?对于追求效率的开发者而言,这种手动操作不仅耗时耗力,还…...

ARM GICv5 ITS_CR1寄存器配置与中断优化实践
1. ARM GICv5 ITS架构概述中断控制器是现代计算机系统中的关键组件,负责管理和分发硬件中断请求。ARM GICv5架构中的Interrupt Translation Service (ITS)模块通过创新的设备ID和事件ID映射机制,实现了灵活高效的中断路由方案。ITS作为GICv5的可选扩展组…...

spawnfile:轻量级进程编排工具,提升本地开发与测试效率
1. 项目概述:一个被低估的进程管理利器如果你在Linux或macOS环境下做过开发,尤其是需要频繁启动、停止、监控一堆后台服务(比如微服务架构下的多个组件),那你一定对进程管理工具不陌生。从最基础的nohup加&&#x…...

别再让代码异味溜走:手把手教你用SonarQube为团队搭建代码质量守护神
别再让代码异味溜走:手把手教你用SonarQube为团队搭建代码质量守护神 当项目规模从几千行扩展到几十万行代码时,技术债务就像房间里的大象——人人都知道存在,却少有人主动清理。去年我们团队在重构一个核心模块时,发现其中隐藏的…...

ARM Firmware Suite与Integrator开发板嵌入式开发指南
1. ARM Firmware Suite与Integrator开发板概述ARM Firmware Suite(AFS)是ARM架构下专为嵌入式系统开发设计的固件套件,在Integrator系列开发板上发挥着核心作用。这套工具链最初由ARM Limited在1999-2002年间开发,至今仍在许多传统…...

深度解析:HS2-HF Patch如何通过模块化架构彻底重塑游戏体验
深度解析:HS2-HF Patch如何通过模块化架构彻底重塑游戏体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF Patch作为《Honey Select 2》最全…...