NLP技术如何为搜索引擎赋能
目录
- 1. NLP关键词提取与匹配在搜索引擎中的应用
- 1. 关键词提取
- 例子
- 2. 关键词匹配
- 例子
- Python实现
- 2. NLP语义搜索在搜索引擎中的应用
- 1. 语义搜索的定义
- 例子
- 2. 语义搜索的重要性
- 例子
- Python/PyTorch实现
- 3. NLP个性化搜索建议在搜索引擎中的应用
- 1. 个性化搜索建议的定义
- 例子
- 2. 个性化搜索建议的重要性
- 例子
- Python实现
- 4. NLP多语言和方言处理在搜索引擎中的应用
- 1. 多语言处理的定义
- 例子:
- 2. 方言处理的定义
- 例子:
- 3. 多语言和方言处理的重要性
- Python/PyTorch实现
- 5. 总结
在全球化时代,搜索引擎不仅需要为用户提供准确的信息,还需理解多种语言和方言。本文详细探讨了搜索引擎如何通过NLP技术处理多语言和方言,确保为不同地区和文化的用户提供高质量的搜索结果,同时提供了基于PyTorch的实现示例,帮助您更深入地理解背后的技术细节。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

1. NLP关键词提取与匹配在搜索引擎中的应用
在自然语言处理(NLP)的领域中,搜索引擎的优化是一个长期研究的主题。其中,关键词提取与匹配是搜索引擎核心技术之一,它涉及从用户的查询中提取关键信息并与数据库中的文档进行匹配,以提供最相关的搜索结果。
1. 关键词提取
关键词提取是从文本中提取出最具代表性或重要性的词汇或短语的过程。
例子
对于文本 “苹果公司是全球领先的技术公司,专注于设计和制造消费电子产品”,可能的关键词包括 “苹果公司”、“技术” 和 “消费电子产品”。
2. 关键词匹配
关键词匹配涉及到将用户的查询中的关键词与数据库中的文档进行对比,找到最符合的匹配项。
例子
当用户在搜索引擎中输入 “苹果公司的新产品” 时,搜索引擎会提取 “苹果公司” 和 “新产品” 作为关键词,并与数据库中的文档进行匹配,以找到相关的结果。
Python实现
以下是一个简单的Python实现,展示如何使用jieba库进行中文关键词提取,以及使用基于TF-IDF的方法进行关键词匹配。
import jieba
import jieba.analyse# 关键词提取
def extract_keywords(text, topK=5):keywords = jieba.analyse.extract_tags(text, topK=topK)return keywords# 例子
text = "苹果公司是全球领先的技术公司,专注于设计和制造消费电子产品"
print(extract_keywords(text))# 关键词匹配(基于TF-IDF)
from sklearn.feature_extraction.text import TfidfVectorizer# 假设有以下文档集合
docs = ["苹果公司发布了新的iPhone","技术公司都在竞相开发新产品","消费电子产品市场日新月异"
]vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(docs)# 对用户的查询进行匹配
query = "苹果公司的新产品"
response = vectorizer.transform([query])# 计算匹配度
from sklearn.metrics.pairwise import cosine_similaritycosine_similarities = cosine_similarity(response, tfidf_matrix)
print(cosine_similarities)
这段代码首先使用jieba进行关键词提取,然后使用TF-IDF方法对用户的查询进行匹配,最后使用余弦相似度计算匹配度。
2. NLP语义搜索在搜索引擎中的应用
传统的关键词搜索主要基于文本的直接匹配,而没有考虑查询的深层含义。随着技术的发展,语义搜索已经成为现代搜索引擎的关键部分,它致力于理解用户查询的实际意图和上下文,以提供更为相关的搜索结果。
1. 语义搜索的定义
语义搜索是一种理解查询的语义或意图的搜索方法,而不仅仅是匹配关键词。它考虑了单词的同义词、近义词、上下文和其他相关性因素。
例子
用户可能搜索 “苹果” 这个词,他们可能是想要找关于“苹果公司”的信息,也可能是想了解“苹果水果”的知识。基于语义的搜索引擎可以根据上下文或用户的历史数据来判断用户的真实意图。
2. 语义搜索的重要性
随着互联网信息的爆炸性增长,用户期望搜索引擎能够理解其复杂的查询意图,并提供最相关的结果。语义搜索不仅可以提高搜索结果的准确性,还可以增强用户体验,因为它能够提供与查询更为匹配的内容。
例子
当用户查询 “如何烤一个苹果派” 时,他们期望得到的是烹饪方法或食谱,而不是关于“苹果”或“派”这两个词的定义。
Python/PyTorch实现

以下是一个基于PyTorch的简单语义搜索实现,我们将使用预训练的BERT模型来计算查询和文档之间的语义相似性。
import torch
from transformers import BertTokenizer, BertModel
from sklearn.metrics.pairwise import cosine_similarity# 加载预训练的BERT模型和分词器
model_name = "bert-base-chinese"
model = BertModel.from_pretrained(model_name)
tokenizer = BertTokenizer.from_pretrained(model_name)
model.eval()# 计算文本的BERT嵌入
def get_embedding(text):tokens = tokenizer(text, return_tensors='pt', truncation=True, padding=True, max_length=512)with torch.no_grad():outputs = model(**tokens)return outputs.last_hidden_state.mean(dim=1).squeeze().numpy()# 假设有以下文档集合
docs = ["苹果公司发布了新的iPhone","苹果是一种非常受欢迎的水果","很多人喜欢吃苹果派"
]
doc_embeddings = [get_embedding(doc) for doc in docs]# 对用户的查询进行匹配
query = "告诉我一些关于苹果的信息"
query_embedding = get_embedding(query)# 计算匹配度
cosine_similarities = cosine_similarity([query_embedding], doc_embeddings)
print(cosine_similarities)
在这段代码中,我们首先使用预训练的BERT模型来为文档和查询计算嵌入。然后,我们使用余弦相似度来比较查询和每个文档嵌入之间的相似性,从而得到最相关的文档。
3. NLP个性化搜索建议在搜索引擎中的应用
随着技术的进步和大数据的发展,搜索引擎不再满足于为所有用户提供相同的搜索建议。相反,它们开始提供个性化的搜索建议,以更好地满足每个用户的需求。
1. 个性化搜索建议的定义
个性化搜索建议是基于用户的历史行为、偏好和其他上下文信息为其提供的搜索建议,目的是为用户提供更为相关的搜索体验。
例子
如果一个用户经常搜索“篮球比赛”的相关信息,那么当他下次输入“篮”时,搜索引擎可能会推荐“篮球比赛”、“篮球队”或“篮球新闻”等相关的搜索建议。
2. 个性化搜索建议的重要性
为用户提供个性化的搜索建议可以减少他们查找信息的时间,并提供更为准确的搜索结果。此外,个性化的建议也可以提高用户对搜索引擎的满意度和忠诚度。
例子
当用户计划外出旅游并在搜索引擎中输入“旅”时,搜索引擎可能会根据该用户之前的旅游历史和偏好,推荐“海滩旅游”、“山区露营”或“城市观光”等相关建议。
Python实现
以下是一个简单的基于用户历史查询的个性化搜索建议的Python实现:
from collections import defaultdict# 假设有以下用户的搜索历史
history = {'user1': ['篮球比赛', '篮球新闻', 'NBA赛程'],'user2': ['旅游景点', '山区旅游', '海滩度假'],
}# 构建一个查询建议的库
suggestion_pool = {'篮': ['篮球比赛', '篮球新闻', '篮球鞋', '篮球队'],'旅': ['旅游景点', '山区旅游', '海滩度假', '旅游攻略'],
}def personalized_suggestions(user, query_prefix):common_suggestions = suggestion_pool.get(query_prefix, [])user_history = history.get(user, [])# 优先推荐用户的历史查询personalized = [s for s in common_suggestions if s in user_history]for s in common_suggestions:if s not in personalized:personalized.append(s)return personalized# 示例
user = 'user1'
query_prefix = '篮'
print(personalized_suggestions(user, query_prefix))
此代码首先定义了一个用户的历史查询和一个基于查询前缀的建议池。然后,当用户开始查询时,该函数将优先推荐与该用户历史查询相关的建议,然后再推荐其他普通建议。
4. NLP多语言和方言处理在搜索引擎中的应用
随着全球化的进程,搜索引擎需要处理各种语言和方言的查询。为了提供跨语言和方言的准确搜索结果,搜索引擎必须理解并适应多种语言的特点和差异。
1. 多语言处理的定义
多语言处理是指计算机程序或系统能够理解、解释和生成多种语言的能力。
例子:
当用户在英国搜索“手机”时,他们可能会使用“mobile phone”这个词;而在美国,用户可能会使用“cell phone”。
2. 方言处理的定义
方言处理是指对同一种语言中不同的方言或变种进行处理的能力。
例子:
在普通话中,“你好”是问候;而在广东话中,相同的问候是“你好吗”。
3. 多语言和方言处理的重要性
- 多样性: 世界上有数千种语言和方言,搜索引擎需要满足不同用户的需求。
- 文化差异: 语言和方言往往与文化紧密相关,正确的处理可以增强用户体验。
- 信息获取: 为了获取更广泛的信息,搜索引擎需要跨越语言和方言的障碍。
Python/PyTorch实现
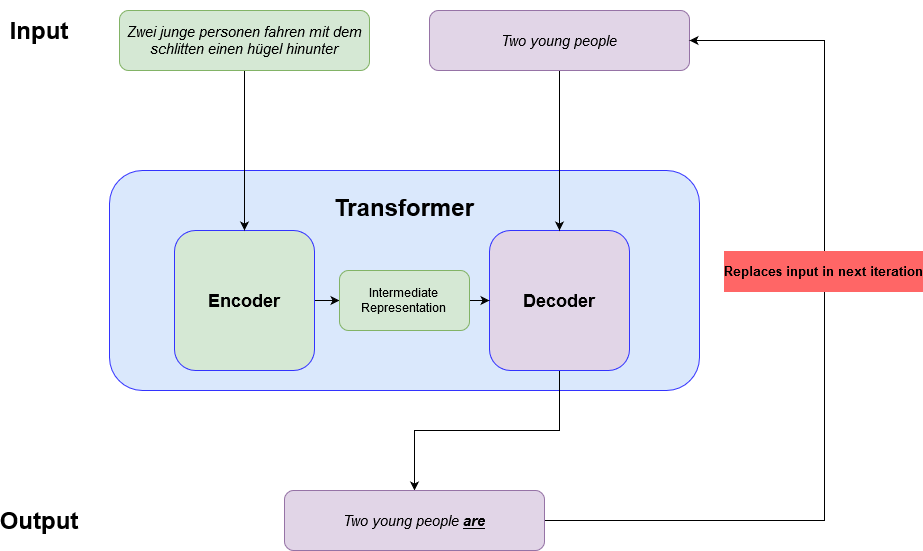
以下是一个基于PyTorch和transformers库的简单多语言翻译实现:
from transformers import MarianMTModel, MarianTokenizer# 选择一个翻译模型,这里我们选择从英语到中文的模型
model_name = 'Helsinki-NLP/opus-mt-en-zh'
model = MarianMTModel.from_pretrained(model_name)
tokenizer = MarianTokenizer.from_pretrained(model_name)def translate_text(text, target_language='zh'):"""翻译文本到目标语言"""# 对文本进行编码encoded = tokenizer.encode(text, return_tensors="pt", max_length=512)# 使用模型进行翻译translated = model.generate(encoded)# 将翻译结果转换为文本return tokenizer.decode(translated[0], skip_special_tokens=True)# 示例
english_text = "Hello, how are you?"
chinese_translation = translate_text(english_text)
print(chinese_translation)
这段代码使用了一个预训练的多语言翻译模型,可以将英文文本翻译为中文。通过使用不同的预训练模型,我们可以实现多种语言间的翻译。
5. 总结
随着信息时代的到来,搜索引擎已经成为我们日常生活中不可或缺的工具。但是,背后支持这一切的技术进步,特别是自然语言处理(NLP),往往被大多数用户所忽视。在我们深入探讨搜索引擎如何处理多语言和方言的过程中,可以看到这其中涉及的技术深度与广度。
语言,作为人类文明的基石,有着其独特的复杂性。不同的文化、历史和地理因素导致了语言和方言的多样性。因此,使得计算机理解和解释这种多样性成为了一项极具挑战性的任务。而搜索引擎正是在这样的挑战中,借助NLP技术,成功地为全球数亿用户提供了跨语言的搜索体验。
而其中最值得关注的,是这样的技术创新不仅仅满足了功能需求,更在无形中拉近了不同文化和地区之间的距离。当我们可以轻松地搜索和理解其他文化的信息时,人与人之间的理解和交流将更加流畅,这正是技术为社会带来的深远影响。
最后,我们不应该仅仅停留在技术的应用层面,更应该思考如何将这些技术与人文、社会和文化更紧密地结合起来,创造出真正有价值、有意义的解决方案。在未来的技术探索中,NLP将持续地为我们展示其无尽的可能性和魅力。

关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
相关文章:
NLP技术如何为搜索引擎赋能
目录 1. NLP关键词提取与匹配在搜索引擎中的应用1. 关键词提取例子 2. 关键词匹配例子 Python实现 2. NLP语义搜索在搜索引擎中的应用1. 语义搜索的定义例子 2. 语义搜索的重要性例子 Python/PyTorch实现 3. NLP个性化搜索建议在搜索引擎中的应用1. 个性化搜索建议的定义例子 2…...

演唱会没买到票?VR直播为你弥补遗憾
听说周杰伦开了演唱会?没买到票的人是不是有着大大的遗憾呢?很多时候大型活动、演唱会都会因为场地限制而导致很多人未能有缘得见,而且加上票价成本高,“黄牛票”事件频出,我们的钱包受不住啊!!…...

myabtis的缓存级别
文章目录 MyBatis缓存的区别是什么作用范围方面有哪些差异生命周期数据进行了存储缓存的优缺点 MyBatis缓存的区别是什么 MyBatis 提供了一级缓存和二级缓存,这两者的主要区别在于其作用范围和生命周期。 一级缓存:一级缓存是 SqlSession 级别的缓存。…...
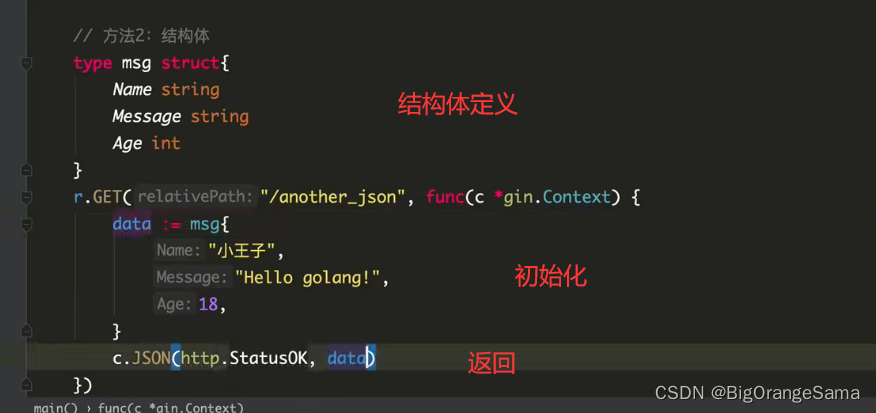
gin框架再探
Gin框架介绍及使用 | 李文周的博客 (liwenzhou.com) lesson03_gin框架初识_哔哩哔哩_bilibili 1.路由引擎 //路由引擎 rgin.Default() 2.一些http请求方法 get post put delete等等 遇到什么路径,执行什么函数 r.GET("/hello",func{做你想做的事返回…...

经典算法-----约瑟夫问题(C语言)
目录 前言 故事背景 约瑟夫问题 环形链表解决 数组解决 前言 今天我们来玩一个有意思的题目,也就是约瑟夫问题,这个问题出自于欧洲中世纪的一个故事,下面我们就去通过编程的方式来解决这个有趣的问题,一起来看看吧!…...

代码随想录 动态规划Ⅴ
494. 目标和 给你一个非负整数数组 nums 和一个整数 target 。 向数组中的每个整数前添加 或 - ,然后串联起所有整数,可以构造一个 表达式 : 例如,nums [2, 1] ,可以在 2 之前添加 ,在 1 之前添加 - …...
驱动DAY9
驱动文件 #include <linux/init.h> #include <linux/module.h> #include <linux/of.h> #include <linux/of_gpio.h> #include <linux/gpio.h> #include <linux/fs.h> #include <linux/io.h> #include <linux/device.h> #incl…...

03贪心:摆动序列
03贪心:摆动序列 376. 摆动序列 局部最优:删除单调坡度上的节点(不包括单调坡度两端的节点),那么这个坡度就可以有两个局部峰值。 整体最优:整个序列有最多的局部峰值,从而达到最长摆动序列。…...

javascript获取元素在浏览器中工作区域的左、右、上、下距离,或带滚动条的元素在页面中的大小
//获取元素在包含元素框中的大小 //第1个函数为获取元素在包含元素中左内边框的距离 function getELementLeft(element){//获取元素在包含元素左边距离var actualeftelement.offsetLeft;//获取元素的上级包含元素var currentelement.offsetParent;//循环到一直没有包含元素whil…...
VSCode 安装使用教程 环境安装配置 保姆级教程
一个好用的 IDE 不仅能提升我们的开发效率,还能让我们保持愉悦的心情,这样才是非常 Nice 的状态 ^_^ 那么,什么是 IDE 呢 ? what IDE(Integrated Development Environment,集成开发环境)是含代码…...
c盘中temp可以删除吗?appdata\local\temp可以删除吗?
http://www.win10d.com/jiaocheng/22594.html C盘AppData文件夹是一个系统文件夹,里面存储着临时文件,各种应用的自定义设置,快速启动文件等。近期有用户发现appdata\local\temp占用了大量的空间,那么该文件可以删除吗?…...

Java手写聚类算法
Java手写聚类算法 1. 算法思维导图 以下是聚类算法的实现原理的思维导图,使用Mermanid代码表示: #mermaid-svg-AK9EgYRS38PkRJI4 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-AK9EgYRS38…...
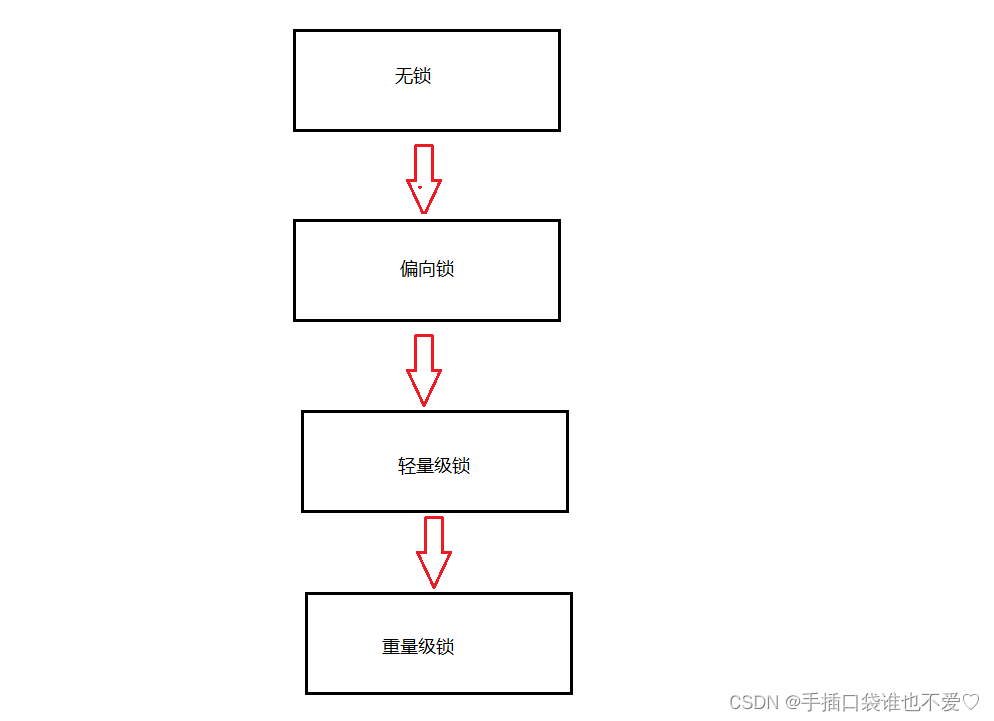
解密Java多线程中的锁机制:CAS与Synchronized的工作原理及优化策略
目录 CAS什么是CASCAS的应用ABA问题异常举例 Synchronized 原理基本特征加锁过程偏向锁轻量级锁重量级锁 其他优化操作锁消除锁粗化 CAS 什么是CAS CAS: 全称Compare and swap,字面意思:”比较并交换“,CAS涉及如下操作: 假设内存中的原数据…...

solid works草图绘制与设置零件特征的使用说明
(1)草图绘制 • 草图块 在 FeatureManager 设计树中,您可以隐藏和显示草图的单个块。您还可以查看块是欠定义 (-)、过定义 () 还是完全定义。 要隐藏和显示草图的单个块,请在 FeatureManager 设计树中右键单击草图块,…...
页面跳转后,该页面不刷新问题)
vue3使用router.push()页面跳转后,该页面不刷新问题
文章目录 原因分析最优解决 原因分析 这是一个常见问题,当使用push的时候,会向history栈添加一个新记录,这个时候,再添加一个完全相同的路由时,就不会再次刷新了 最优解决 在页面跳转时加上params参数时间 router.…...

如何理解数字工厂管理系统的本质
随着科技的飞速发展和数字化转型的推动,数字工厂管理系统逐渐成为工业4.0时代的重要工具。数字工厂系统旨在整合和优化工厂运营的各个环节,通过实时数据分析和处理,提升生产效率,降低成本,并增强企业的整体竞争力。为了…...
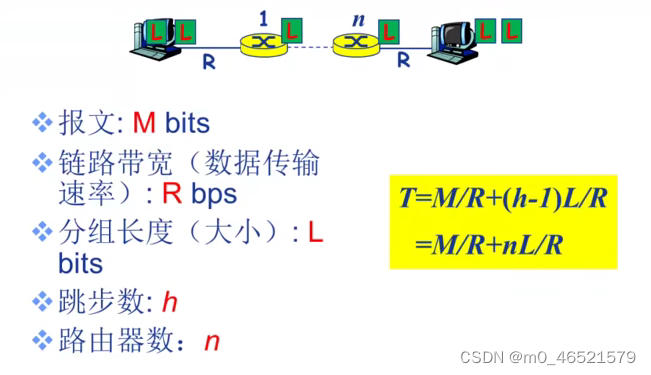
笔记1.3 数据交换
如何实现数据通过网络核心从源主机到达目的主机? 数据交换 交换网络: 动态转接动态分配传输资源 数据交换类型: (1)电路交换 (2)报文交换 (3)分组交换 电路交换的特…...
实时车辆行人多目标检测与跟踪系统(含UI界面,Python代码)
算法架构: 目标检测:yolov5 目标跟踪:OCSort其中, Yolov5 带有详细的训练步骤,可以根据训练文档,训练自己的数据集,及其方便。 另外后续 目标检测会添加 yolov7 、yolox,目标跟踪会…...

谷歌AI机器人Bard发布强大更新,支持插件功能并增强事实核查;全面整理高质量的人工智能、机器学习、大数据等技术资料
🦉 AI新闻 🚀 谷歌AI机器人Bard发布强大更新,支持插件功能并增强事实核查 摘要:谷歌的人工智能聊天机器人Bard发布了一项重大更新,增加了对谷歌应用的插件支持,包括 Gmail、Docs、Drive 等,并…...

NI SCXI-1125 数字量控制模块
NI SCXI-1125 是 NI(National Instruments)生产的数字量控制模块,通常用于工业自动化和控制系统中,以进行数字输入和输出控制。以下是该模块的一些主要产品特点: 数字量输入:SCXI-1125 模块通常具有多个数字…...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

为你的Hermes Agent自定义Provider,接入Taotoken多模型池
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent自定义Provider,接入Taotoken多模型池 在构建复杂的AI应用时,开发者常常面临一个核心挑…...

03 - 变量与数据类型
03 - 变量与数据类型 变量是编程里最基础的概念,相当于你往电脑里存东西的"容器"。这章我们把变量的命名规则、Python 的几种基本数据类型都过一遍。 变量是什么 说白了,变量就是一个有名字的盒子。你往里面放个东西,以后想用这个…...

泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅
泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you cha…...

数字合成器d-FORMANT:从模拟经典到数字复刻的工程实践
1. 项目概述:从模拟经典到数字复刻如果你对合成器稍有了解,或者对电子音乐制作背后的硬件感兴趣,那么“FORMANT”这个名字你一定不陌生。它最初是上世纪70年代由《Elektor》杂志发布的一款模拟单音合成器,以其清晰的模块化设计和出…...

OpenCore Legacy Patcher完整指南:让老旧Mac焕发新生,运行最新macOS
OpenCore Legacy Patcher完整指南:让老旧Mac焕发新生,运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台被苹…...

3分钟学会Avidemux:开源视频编辑器的完整快速入门指南
3分钟学会Avidemux:开源视频编辑器的完整快速入门指南 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你是否曾因为视频编辑软件过于复杂而放弃剪辑?或者因为专业软件价格昂…...