6.1 使用scikit-learn构建模型
6.1 使用scikit-learn构建模型
- 6.1.1 使用sklearn转换器处理数据
- 6.1.2 将数据集划分为训练集和测试集
- 6.1.3 使用sklearn转换器进行数据预处理与降维
- 1、数据预处理
- 2、PCA降维算法
- 代码
scikit-learn(简称sklearn)库整合了多种机器学习算法,可以帮助使用者在数据分析过程中快速建立模型,且模型接口统一,使用起来非常方便。同时,sklearn拥有优秀的官方文档,知识点详尽,内容丰富,是入门学习sklearn的最佳内容。
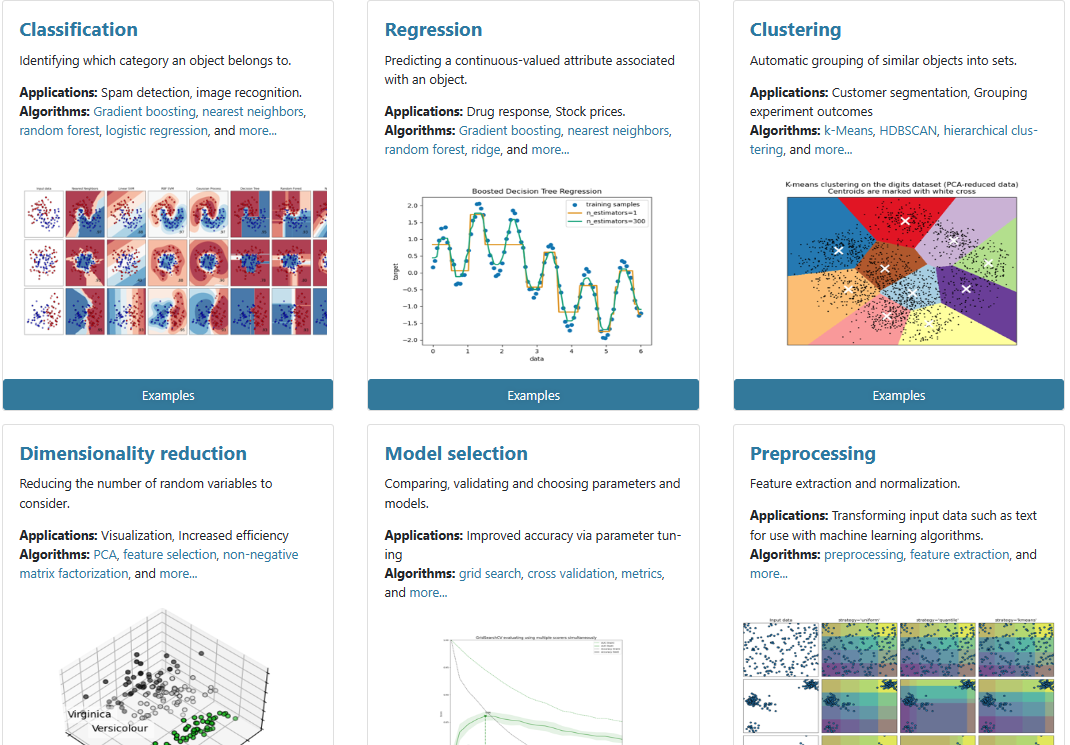
开源机器学习库:https://scikit-learn.org/stable/index.html 开源机器学习库

涵盖分类、回归、聚类、降维、模型选择、数据预处理六大模块
6.1.1 使用sklearn转换器处理数据
sklearn提供了model_selection模型选择模块、preprocessing数据预处理模块与decomoisition特征分解模块。通过这三个模块能够实现数据的预处理与模型构建前的数据标准化、二值化、数据集的分割、交叉验证和PCA降维等工作。
datasets模块常用数据集的加载函数与解释如下表所示:
波士顿房价、鸢尾花、红酒数据集

使用sklearn进行数据预处理会用到sklearn提供的统一接口——转换器(Transformer)。
加载后的数据集可以视为一个字典,几乎所有的sklearn数据集均可以使用data,target,feature_names,DESCR分别获取数据集的数据,标签,特征名称和描述信息。
from sklearn.datasets import load_boston # 波士顿房价数据集
from sklearn.datasets import load_breast_cancer # 癌症数据集
# cancer = load_breast_cancer() # 读取数据集
# print("长度: ", len(cancer))
# print("类型: ", type(cancer))
boston = load_boston() # 读取数据集
print("长度: ", len(boston))
# print(boston)
print('data:\n', boston['data']) # 数据
print('target:\n', boston['target']) # 标签
print('feature_names:\n', boston['feature_names']) # 特征名称
print('DESCR:\n', boston['DESCR']) # 描述信息
6.1.2 将数据集划分为训练集和测试集
在数据分析过程中,为了保证模型在实际系统中能够起到预期作用,一般需要将样本分成独立的三部分:
- 训练集(train set):用于训练模型。
- 验证集(validation set):用于训练过程中对模型性能评估。
- 测试集(test set):用于检验最终的模型的性能。
典型的划分方式是训练集占总样本的50%,而验证集和测试集各占25%。
K折交叉验证法
当数据总量较少的时候,使用上面的方法将数据划分为三部分就不合适了。
常用的方法是留少部分做测试集,然后对其余N个样本采用K折交叉验证法,基本步骤如下:
- 将样本打乱,均匀分成K份。
- 轮流选择其中K-1份做训练,剩余的一份做验证。
- 计算预测误差平方和,把K次的预测误差平方和的均值作为选择最优模型结构的依据。
sklearn的model_selection模块提供了train_test_split函数,能够对数据集进行拆分,其使用格式如下。
sklearn.model_selection.train_test_split(*arrays, **options)

将数据集划分为训练集和测试集
- train_test_split函数根据传入的数据,分别将传入的数据划分为训练集和测试集。
- 如果传入的是1组数据,那么生成的就是这一组数据随机划分后训练集和测试集,总共2组。
- 如果传入的是2组数据,则生成的训练集和测试集分别2组,总共4组。
- train_test_split是最常用的数据划分方法,在model_selection模块中还提供了其他数据集划分的函数,如PredefinedSplit,ShuffleSplit等。
from sklearn.datasets import load_boston # 波士顿房价数据集
boston = load_boston() # 读取数据集
# 划分数据集
from sklearn.model_selection import train_test_split
X, y = boston.data, boston.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
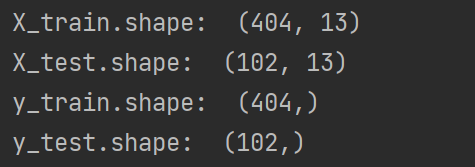
print("X_train.shape: ", X_train.shape)
print("X_test.shape: ", X_test.shape)
print("y_train.shape: ", y_train.shape)
print("y_test.shape: ", y_test.shape)
6.1.3 使用sklearn转换器进行数据预处理与降维
在数据分析过程中,各类特征处理相关的操作都需要对训练集和测试集分开操作,需要将训练集的操作规则,权重系数等应用到测试集中。如果使用pandas,则应用至测试集的过程相对烦琐,使用sklearn转换器可以解决这一困扰。
sklearn把相关的功能封装为转换器(transformer)。使用sklearn转换器能够实现对传入的NumPy数组进行标准化处理,归一化处理,二值化处理,PCA降维等操作。转换器主要包括三个方法:fit、transform 和 fit-transform。

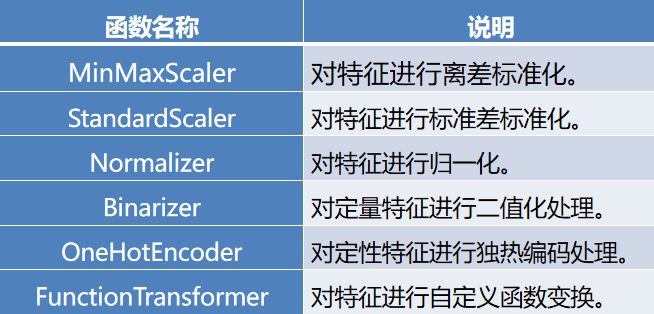
1、数据预处理
sklearn部分预处理函数与其作用
2、PCA降维算法
sklearn还提供了降维算法,特征选择算法,这些算法的使用也是通过转换器的方式。

代码
from sklearn.datasets import load_boston # 波士顿房价数据集
boston = load_boston() # 读取数据集
# print("长度: ", len(boston))
# # print(boston)
# print('data:\n', boston['data']) # 数据
# print('target:\n', boston['target']) # 标签
# print('feature_names:\n', boston['feature_names']) # 特征名称
# print('DESCR:\n', boston['DESCR']) # 描述信息# 划分数据集
from sklearn.model_selection import train_test_split
X, y = boston.data, boston.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# print("X_train.shape: ", X_train.shape)
# print("X_test.shape: ", X_test.shape)
# print("y_train.shape: ", y_train.shape)
# print("y_test.shape: ", y_test.shape)
# 离差标准化
import numpy as np
from sklearn.preprocessing import MinMaxScaler
Scaler = MinMaxScaler().fit(X_train) # 生成规则
# 将规则用于训练集
data_train = Scaler.transform(X_train)
# 将规则用于训练集
data_test = Scaler.transform(X_test)
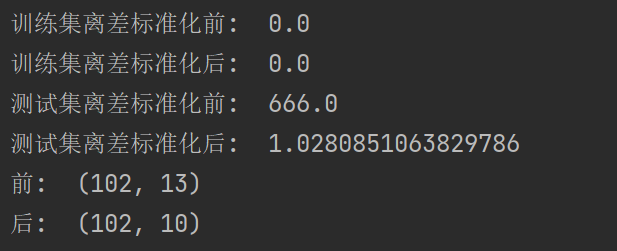
print("训练集离差标准化前: ", np.min(X_train))
print("训练集离差标准化后: ", np.min(data_train))
print("测试集离差标准化前: ", np.max(X_test))
print("测试集离差标准化后: ", np.max(data_test))# PCA降维
from sklearn.decomposition import PCA
pca = PCA(n_components=10).fit(data_train) # 生成规则
# 将规则用于训练集
pca_test = pca.transform(data_test)
print("前: ", data_test.shape)
print("后: ", pca_test.shape)
相关文章:
6.1 使用scikit-learn构建模型
6.1 使用scikit-learn构建模型 6.1.1 使用sklearn转换器处理数据6.1.2 将数据集划分为训练集和测试集6.1.3 使用sklearn转换器进行数据预处理与降维1、数据预处理2、PCA降维算法 代码 scikit-learn(简称sklearn)库整合了多种机器学习算法,可以…...
React 全栈体系(十一)
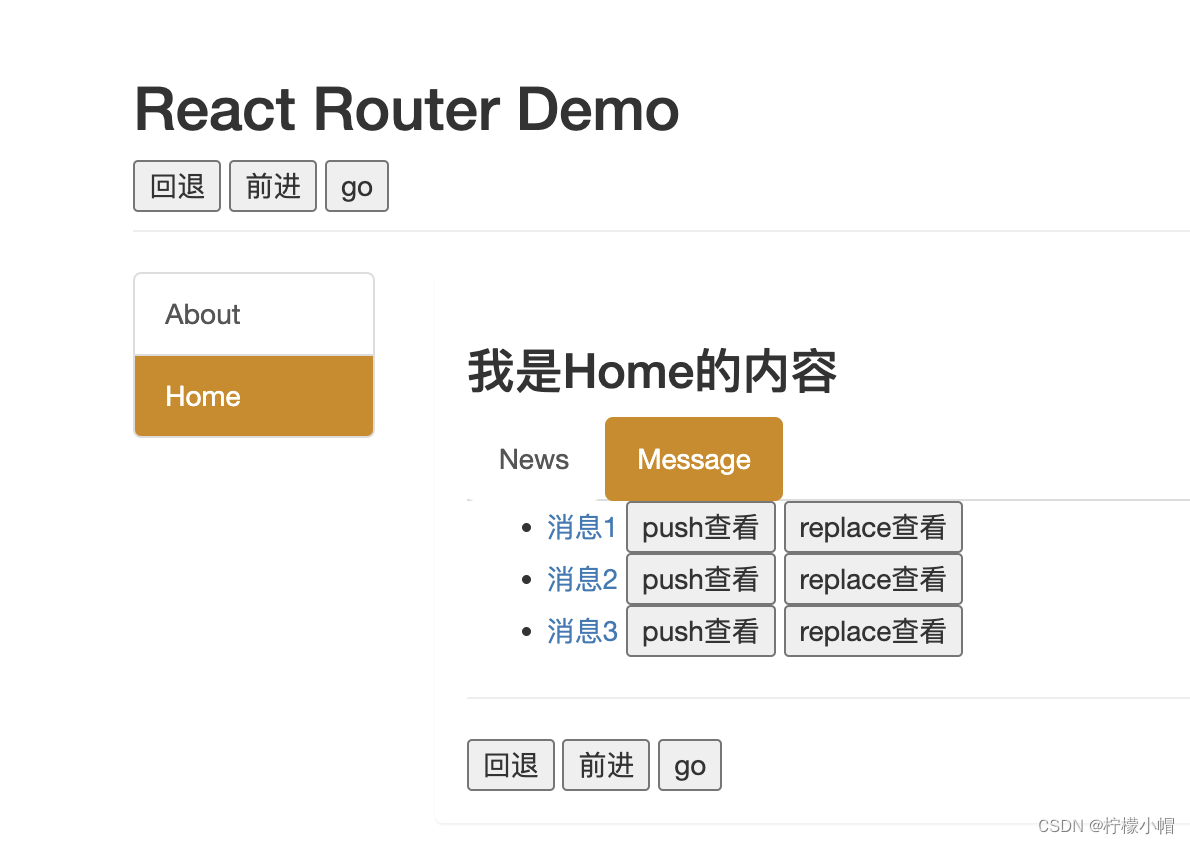
第五章 React 路由 五、向路由组件传递参数数据 1. 效果 2. 代码 - 传递 params 参数 2.1 Message /* src/pages/Home/Message/index.jsx */ import React, { Component } from "react"; import {Link, Route} from react-router-dom import Detail from ./Detai…...
AI 时代的向量数据库、关系型数据库与 Serverless 技术丨TiDB Hackathon 2023 随想
TiDB Hackathon 2023 刚刚结束,我仔细地审阅了所有的项目。 在并未强调项目必须使用人工智能(AI)相关技术的情况下,引人注目的项目几乎一致地都使用了 AI 来构建自己的应用。 大规模语言模型(LLM)的问世使得…...

Vue的路由使用,Node.js下载安装及环境配置教程 (超级详细)
前言: 今天我们来讲解关于Vue的路由使用,Node.js下载安装及环境配置教程 一,Vue的路由使用 首先我们Vue的路由使用,必须要导入官方的依赖的。 BootCDN - Bootstrap 中文网开源项目免费 CDN 加速服务https://www.bootcdn.cn/ <…...

vue修改node_modules打补丁步骤和注意事项
当我们使用 npm 上的第三方依赖包,如果发现 bug 时,怎么办呢? 想想我们在使用第三方依赖包时如果遇到了bug,通常解决的方式都是绕过这个问题,使用其他方式解决,较为麻烦。或者给作者提个issue,然…...

CSS 响应式设计:媒体查询
文章目录 媒体查询添加断点为移动端优先设计其他断点方向:横屏/竖屏 媒体查询 CSS中的媒体查询是一种用于根据不同设备的屏幕尺寸和分辨率来定义样式表的方法。在CSS中,我们可以使用媒体查询来根据不同的设备类型和屏幕尺寸来应用不同的样式,…...
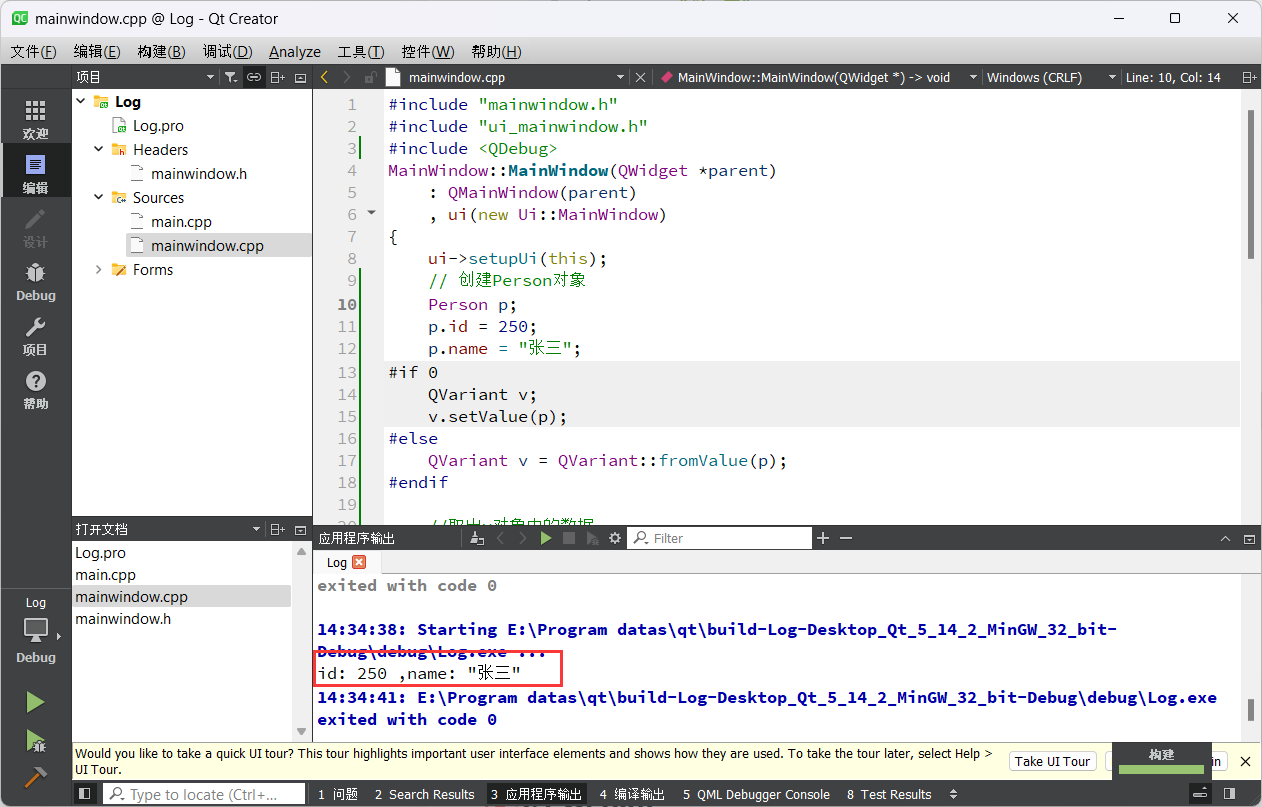
Qt开发 - Qt基础类型
1.基础类型 因为Qt是一个C 框架, 因此C中所有的语法和数据类型在Qt中都是被支持的, 但是Qt中也定义了一些属于自己的数据类型, 下边给大家介绍一下这些基础的数类型。 QT基本数据类型定义在#include <QtGlobal> 中,QT基本数据类型有: 虽然在Qt中…...
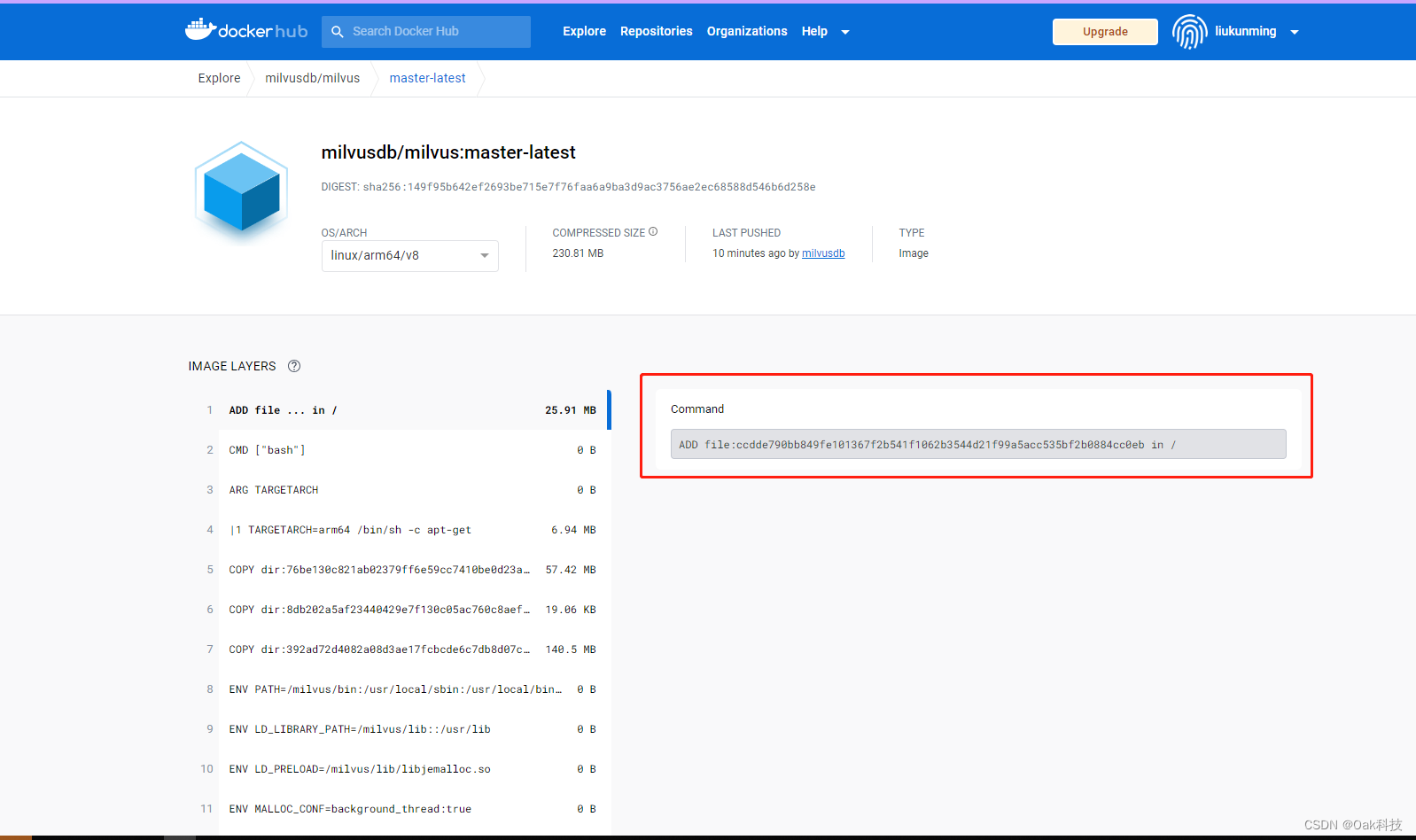
Docker-如何获取docker官网x86、ARM、AMD等不同架构下的镜像资源
文章目录 一、概要二、资源准备三、环境准备1、环境安装2、服务器设置代理3、注册docker账号4、配置docker源 四、查找资源1、服务器设置代理2、配置拉取账号3、查找对应的镜像4、查找不同版本镜像拉取 小结 一、概要 开发过程中经常会使用到一些开源的资源,比如经…...

Vuex状态管理最佳实践
文章目录 单一状态树使用模块使用常量定义Mutation类型使用Actions处理异步操作使用Getters计算属性严格模式分模块管理Getter、Mutation和Action:注释和文档:Vue Devtools ✍创作者:全栈弄潮儿 🏡 个人主页: 全栈弄潮…...

platform和led中断项目
设备树根节点下添加 myledIrqPlatform{compatible"hqyj,myledIrqPlatform";reg<0x22334455 59>;interrupt-parent<&gpiof>;interrupts<9 0>;led1-gpio<&gpioe 10 0>;//10表示使用的gpioe第几个管脚 0,表示gpio默认属性…...
R语言-关于颜色
目录 颜色 示例 R 颜色板 参考: 颜色 什么场景会用到颜色?比如在绘图过程中,为了让图更好看,有的时候,需要选择使用不同的颜色进行绘制或者填充。本文提供了R颜色的相关参数。 在R中,可以通过颜色下标…...

抖音seo优化排名源码搭建
抖音seo优化排名技术开发源码搭建: 思路:看上去比较简单,貌似使用 get、set 这两个 trap 就可以,但实际上并不是。实际上还需要实现 has, ownKeys , getOwnPropertyDescriptor 这些 trap,这样就能最大限度的限制私有属…...
pytorch的卷积层池化层和非线性变化 和机器学习线性回归
卷积层: 两个输出的情况 就会有两个通道 可以改变通道数的 最简单的神经网络结构: nn.Mudule就是继承父类 super执行的是 先执行父类函数里面的 forward执行的就是前向网络,就是往前推进的,当然也有反向转播,那就是…...

Java手写快速选择算法应用拓展案例
Java手写快速选择算法应用拓展案例 1. 引言 快速选择算法是一种高效的选择算法,可以用于在数组中找到第K小/大的元素。除了基本的应用场景外,快速选择算法还可以应用于其他问题,如查找中位数、查找最大/最小值等。本文将介绍两个拓展应用案…...

js制作柱状图的x轴时间, 分别展示 月/周/日 的数据
背景 有个需求是要做一个柱状图, x 轴是时间, y 轴是数量. 其中 x 轴的时间有三种查看方式: 月份/周/日, 也就是分别查看从当前日期开始倒推的最近每月/每周/每日的数量. 本篇文章主要是用来制作三种不同的 x 轴 从当前月开始倒推月份 注意 getMonth() 函数可以获取当前月份…...

安防监控/视频汇聚/云存储/AI智能视频分析平台EasyCVR下级海康设备无法级联是什么原因?
安防视频监控平台/视频集中存储/云存储/磁盘阵列EasyCVR可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。 有用户反馈&…...

HttpUtils带连接池
准备祖传了,有问题欢迎大家指正。 HttpUtil import com.txlc.cloud.commons.exception.ServiceException; import com.txlc.dwh.common.constants.MyErrorCode; import org.ssssssss.script.annotation.Comment;import java.io.UnsupportedEncodingException; impo…...
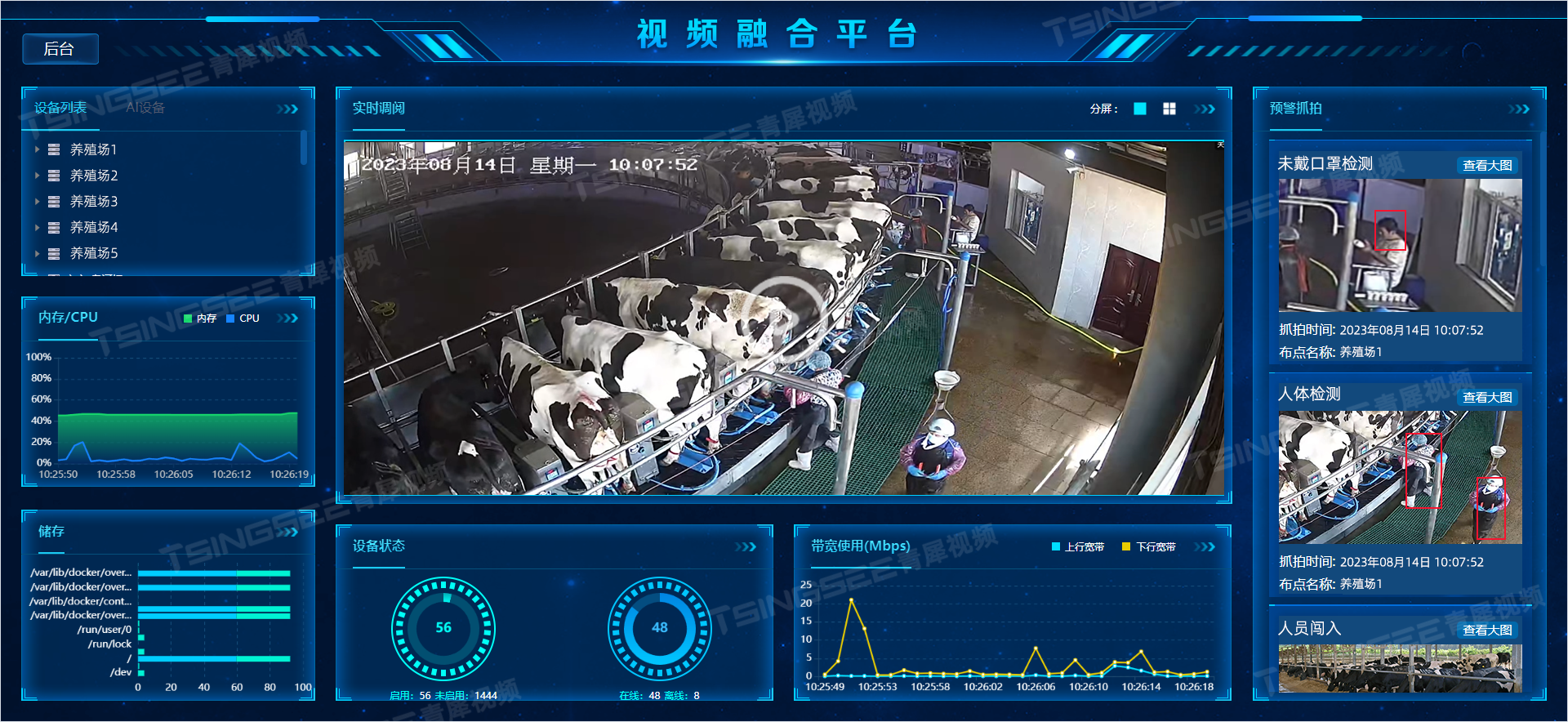
智慧养殖:浅谈视频监控与AI智能识别技术助力奶牛高效、智慧养殖
一、方案背景 随着科技的飞速发展,智能化养殖逐渐成为现代畜牧业的发展趋势。人工智能技术、物联网、视频技术、云计算、大数据等新兴技术,正在为奶牛养殖业带来全新的变革。越来越多的牧场、养殖场开始运用新技术来进行智能监管、提高生产效率、降低生…...

一文总结提示工程框架,除了CoT还有ToT、GoT、AoT、SoT、PoT
夕小瑶科技说 原创 编译 | 谢年年 大语言模型LLM被视为一个巨大的知识库,它可以根据你提出问题或陈述的方式来提供答案。就像人类可能会根据问题的不同提供不同的答案一样,LLM也可以根据输入的不同给出不同的答案。因此,你的问题或陈述方式就…...

Java面试笔试acm版输入
首先区分scanner.nextInt()//输入一个整数,只能读取一个数,空格就停止。 scanner.next()//输入字符串,只能读取一个字符串,空格就停止,但是逗号不停止。 scanner.nextLine() 读取一行,换行停止,…...

Agent设计模式全景图——从ReAct到Multi-Agent的完整知识体系
Agent概念在2023年就已出现,2024年是框架快速迭代的一年。到了2026年,Agent设计模式逐渐成熟,成为工程实践的关键。 GitHub上关于Agent的开源项目突破10万个,LangChain、LangGraph、AutoGen、CrewAI……框架层出不穷。但翻遍这些文…...

别再只用fitInView了!Qt QGraphicsView自适应显示避坑指南与高级技巧
别再只用fitInView了!Qt QGraphicsView自适应显示避坑指南与高级技巧 在Qt图形界面开发中,QGraphicsView作为展示复杂图形的核心组件,其自适应显示功能经常让开发者又爱又恨。许多开发者第一次遇到需要自适应显示的场景时,都会欣喜…...

别再只调参了!搞懂MaxPool2D的padding=‘same‘和‘valid‘,让你的CNN模型效果立竿见影
别再只调参了!搞懂MaxPool2D的paddingsame和valid,让你的CNN模型效果立竿见影 在构建卷积神经网络(CNN)时,许多开发者习惯性地将注意力集中在卷积核大小、激活函数选择等显性参数上,却常常忽略池化层中padd…...
)
QCustomPlot之颜色图实战:从静态数据到动态刷新的可视化(十四)
1. 认识QCPColorMap:从静态热力图开始 第一次接触QCustomPlot的颜色图功能时,我正需要可视化一组服务器CPU温度分布数据。当时尝试了多种图表类型,最终发现QCPColorMap简直是二维矩阵数据可视化的"神器"。这个类专门用于绘制热力图…...

智能水表、血糖仪、工业HMI:STM32L152ZET6的超低功耗MCU应用版图
STM32L152ZET6:带LCD驱动的超低功耗Cortex-M3旗舰MCU 在电池供电的工业仪表、医疗设备和消费电子产品中,微控制器的功耗与集成度往往是决定产品可行性的关键因素。STM32L152ZET6是意法半导体STM32 L1系列中的高端型号,采用2020mm的LQFP-144封…...

3分钟掌握B站缓存转换:开源m4s-converter工具全攻略
3分钟掌握B站缓存转换:开源m4s-converter工具全攻略 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 还在为B站下架视频而烦恼吗&…...

Intel RealSense D435i 标定实战:从工具安装到VINS配置全流程解析
1. 准备工作:认识D435i与标定原理 第一次拿到Intel RealSense D435i时,我盯着这个火柴盒大小的设备看了半天——它凭什么能实现三维感知?拆开包装后发现,这玩意儿居然集成了双目红外相机、RGB彩色相机和IMU惯性测量单元。但问题来…...

英雄联盟Akari助手:5大核心功能解决游戏中的常见痛点
英雄联盟Akari助手:5大核心功能解决游戏中的常见痛点 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟游戏中的繁琐操…...

Unlock Music:打破音乐平台格式壁垒的终极浏览器解密工具
Unlock Music:打破音乐平台格式壁垒的终极浏览器解密工具 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: ht…...

AI原生Next.js启动器:集成Claude与Cursor的现代前端开发模板
1. 项目概述:一个为AI时代开发者量身定制的Next.js启动器如果你和我一样,每天都在和Next.js、TypeScript、Tailwind CSS打交道,同时又在频繁地与Claude、Cursor、Copilot这些AI编程助手“对话”,那你肯定也遇到过类似的烦恼&#…...