[pai-diffusion]pai的easynlp的clip模型训练
EasyNLP带你玩转CLIP图文检索 - 知乎作者:熊兮、章捷、岑鸣、临在导读随着自媒体的不断发展,多种模态数据例如图像、文本、语音、视频等不断增长,创造了互联网上丰富多彩的世界。为了准确建模用户的多模态内容,跨模态检索是跨模态理解的重要任务,…![]() https://zhuanlan.zhihu.com/p/528476134
https://zhuanlan.zhihu.com/p/528476134
initialize_easynlp()->train_dataset = CLIPDataset(pretrained_model_name_or_path=get_pretrain_model_path("alibaba-pai/clip_chinese_roberta_base_vit_base"),data_file="MUGE_MR_train_base64_part.tsv",max_seq_length=32,input_schema="text:str:1,image:str:1",first_sequence="text",second_sequence="image",is_training=True)
valid_dataset = CLIPDataset()model = get_application_model(app_name='clip',...)
- easynlp.appzoo.api.ModelMapping->CLIPApp
- easynlp.appzoo.clip.model.py->CLIPApp
- CHINESE_CLIP->
- self.visual = VisualTransformer()
- self.bert = BertModel()trainer = Trainer(model,train_dataset,user_defined_parameters, evaluator=get_application_evaluator(app_name="clip",valid_dataset=valid_dataset,user_defined_parameters=user_defined_parameters,eval_batch_size=32))trainer.train()
- for _epoch in range(self._first_epoch,int(args.epoch_num)):for _step,batch in enumerate(self._train_loader): label_ids = batch.pop()forward_outputs = self._model(batch)loss_dict = self.model_module.compute_loss(forward_outputs,label_ids)_loss = loss_dict('loss')_loss.backward()model = get_application_model_evaluation()
evaluator = get_application_evaluator()
evaluator.evaluate(model)数据处理:
import os
import base64
import multiprocessing
from tqdm import tqdmdef process_image(image_path):# 从图片路径中提取中文描述image_name = os.path.basename(image_path)description = os.path.splitext(image_name)[0]# 将图片转换为 Base64 编码with open(image_path, 'rb') as f:image_data = f.read()base64_data = base64.b64encode(image_data).decode('utf-8')return description, base64_datadef generate_tsv(directory):image_paths = [os.path.join(directory, filename) for filename in os.listdir(directory) iffilename.endswith(('.jpg', '.png'))]with multiprocessing.Pool() as pool, tqdm(total=len(image_paths), desc='Processing Images') as pbar:results = []for result in pool.imap_unordered(process_image, image_paths):results.append(result)pbar.update(1)with open('/home/image_team/image_team_docker_home/lgd/e_commerce_sd/data/vcg_furnitures_text_image/vcg_furnitures_train.tsv','w', encoding='utf-8') as f:for description, base64_data in results:line = f"{description}\t{base64_data}\n"f.write(line)if __name__ == '__main__':target_directory = "/home/image_team/image_team_docker_home/lgd/e_commerce_sd/data/vcg_furnitures_text_image/vcg_furnitures_train/img_download/"# import pdb;pdb.set_trace()generate_tsv(target_directory)
训练代码:
import torch.cuda
from easynlp.appzoo import CLIPDataset
from easynlp.appzoo import get_application_predictor, get_application_model, get_application_evaluator, \get_application_model_for_evaluation
from easynlp.core import Trainer, PredictorManager
from easynlp.utils import initialize_easynlp, get_args, get_pretrain_model_path
from easynlp.utils.global_vars import parse_user_defined_parametersdef main():# /root/.easynlp/modelzoo中train_dataset = CLIPDataset(pretrained_model_name_or_path=get_pretrain_model_path(args.pretrained_model_name_or_path),data_file=args.tables.split(",")[0],max_seq_length=args.sequence_length,input_schema=args.input_schema,first_sequence=args.first_sequence,second_sequence=args.second_sequence,is_training=True)valid_dataset = CLIPDataset(# 预训练模型名称路径,这里我们使用封装好的get_pretrain_model_path函数,来处理模型名称"alibaba-pai/clip_chinese_roberta_base_vit_base"以得到其路径,并自动下载模型pretrained_model_name_or_path=get_pretrain_model_path(args.pretrained_model_name_or_path),data_file=args.tables.split(",")[-1],# "data/pai/MUGE_MR_valid_base64_part.tsv"max_seq_length=args.sequence_length, # 文本最大长度,超过将截断,不足将paddinginput_schema=args.input_schema, # 输入tsv数据的格式,逗号分隔的每一项对应数据文件中每行以\t分隔的一项,每项开头为其字段标识,如label、sent1等first_sequence=args.first_sequence, # 用于说明input_schema中哪些字段作为第一/第二列输入数据second_sequence=args.second_sequence,is_training=False) # 是否为训练过程,train_dataset为True,valid_dataset为Falsemodel = get_application_model(app_name=args.app_name, # 任务名称,这里选择文本分类"clip"pretrained_model_name_or_path=get_pretrain_model_path(args.pretrained_model_name_or_path),user_defined_parameters=user_defined_parameters# user_defined_parameters:用户自定义参数,直接填入刚刚处理好的自定义参数user_defined_parameters)trainer = Trainer(model=model,train_dataset=train_dataset,user_defined_parameters=user_defined_parameters,evaluator=get_application_evaluator(app_name=args.app_name,valid_dataset=valid_dataset,user_defined_parameters=user_defined_parameters,eval_batch_size=32))trainer.train()# 模型评估model = get_application_model_for_evaluation(app_name=args.app_name,pretrained_model_name_or_path=args.checkpoint_dir,user_defined_parameters=user_defined_parameters)evaluator = get_application_evaluator(app_name=args.app_name,valid_dataset=valid_dataset,user_defined_parameters=user_defined_parameters,eval_batch_size=32)model.to(torch.cuda.current_device())evaluator.evaluate(model=model)# 模型预测if test:predictor = get_application_predictor(app_name="clip",model_dir="./outputs/clip_model/",first_sequence="text",second_sequence="image",sequence_length=32,user_defined_parameters=user_defined_parameters)predictor_manager = PredictorManager(predictor=predictor,input_file="data/vcg_furnitures_text_image/vcg_furnitures_test.tsv",input_schema="text:str:1",output_file="text_feat.tsv",output_schema="text_feat",append_cols="text",batch_size=2)predictor_manager.run()if __name__ == "__main__":initialize_easynlp()args = get_args()user_defined_parameters = parse_user_defined_parameters('pretrain_model_name_or_path=alibaba-pai/clip_chinese_roberta_base_vit_base')args.checkpoint_dir = "./outputs/clip_model/"args.pretrained_model_name_or_path = "alibaba-pai/clip_chinese_roberta_base_vit_base"# args.n_gpu = 3# args.worker_gpu = "1,2,3"args.app_name = "clip"args.tables = "data/pai/MUGE_MR_train_base64_part.tsv,data/pai/MUGE_MR_valid_base64_part.tsv"# "data/vcg_furnitures_text_image/vcg_furnitures_train.tsv," \# "data/vcg_furnitures_text_image/vcg_furnitures_test.tsv"# "data/pai/MUGE_MR_train_base64_part.tsv,data/pai/MUGE_MR_valid_base64_part.tsv"args.input_schema = "text:str:1,image:str:1"args.first_sequence = "text"args.second_sequence = "image"args.learning_rate = 1e-4args.epoch_num = 1000args.random_seed = 42args.save_checkpoint_steps = 200args.sequence_length = 32# args.train_batch_size = 2args.micro_batch_size = 32test = Falsemain()# python -m torch.distributed.launch --nproc_per_node 4 tools/train_pai_chinese_clip.py说一点自己的想法,在我自己工作之初,我很喜欢去拆解一些框架,例如openmm系列,但其实大部分在训练过程上都是相似的,大可不必,在改动上,也没有必要对其进行流程上的大改动,兼具百家之长,了解整体pipeline,更加专注在pipeline实现和效果导向型的结果提交更加有效。
相关文章:
[pai-diffusion]pai的easynlp的clip模型训练
EasyNLP带你玩转CLIP图文检索 - 知乎作者:熊兮、章捷、岑鸣、临在导读随着自媒体的不断发展,多种模态数据例如图像、文本、语音、视频等不断增长,创造了互联网上丰富多彩的世界。为了准确建模用户的多模态内容,跨模态检索是跨模态…...
期权如何交易?期权如何做模拟交易?
买卖期权的第一步就是要有期权账户,国内的期权品种有商品期权和ETF期权以及股指期权,每种的开户方式和要求都不同,下文为大家介绍期权如何交易?期权如何做模拟交易? 一、期权交易需要开立一个期权账户,可以…...

【新书推荐】大模型赛道如何实现华丽的弯道超车 —— 《分布式统一大数据虚拟文件系统 Alluxio原理、技术与实践》
文章目录 大模型赛道如何实现华丽的弯道超车 —— AI/ML训练赋能解决方案01 具备对海量小文件的频繁数据访问的 I/O 效率02 提高 GPU 利用率,降低成本并提高投资回报率03 支持各种存储系统的原生接口04 支持单云、混合云和多云部署01 通过数据抽象化统一数据孤岛02 …...

Calendar对象获取当前周的bug
项目场景: 双周项目管理,需要获取当前周为一年之中的第几周,原先的代码是用Calendar对象,先用setTime()把当前时间传入,再用get(3)获取一年中的第几周 问题描述 实际发…...

嵌入式环境buildroot的espeak配置与编译
1、在buildroot目录下输入make menuconfig 2、选择Target packages 3、选择Audio and video applications 4、选择espeak、选择alsa via portaudio (新版嵌入式linux一般都是用alsa音频驱动) 5、配置portaudio 选择Library 6、选择Audio/Sound 7、选择…...

物理机环境搭建-linux部署nginx
1、安装nginx部署所需依赖 yum install -y gcc-c pcre pcre-devel zlib zlib-devel openssl openssl-devel2、安装nginx包 wget http://nginx.org/download/nginx-1.8.0.tar.gz 如果没有wget可以安装一下 yum install -y wget下载完成后可以在/usr/local/下放置tar包…...
删除安装Google Chrome浏览器时捆绑安装的Google 文档、表格、幻灯片、Gmail、Google 云端硬盘、YouTube网址链接(Mac)
删除安装Google Chrome浏览器时捆绑安装的Google 文档、表格、幻灯片、Gmail、Google 云端硬盘、YouTube网址链接(Mac) Mac mini操作系统,安装完 Google Chrome 浏览器以后,单击 启动台 桌面左下角的“显示应用程序”,我们发现捆绑安装了 Goo…...

硬件故障诊断:快速定位问题
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

IP代理与加速器:理解它们的区别与共同点
在网络使用过程中,我们经常会遇到需要提高访问速度或保护隐私的需求。IP代理和加速器都是常见的应对方案,但它们在工作原理和应用场景上存在一些区别。本文将为您深入探讨IP代理和加速器的异同,帮助您更好地理解它们的作用和适用情况…...

Java中List转字符串的方法
一、使用String.join方法 在Java 8之后,String类增加了一个静态方法join(),可以方便地将列表中的元素连接成字符串。 // 创建List List<String> list Arrays.asList("Google", "Baidu", "Taobao"); // 以逗号分隔…...

PyTorch实战:实现MNIST手写数字识别
前言 PyTorch可以说是三大主流框架中最适合初学者学习的了,相较于其他主流框架,PyTorch的简单易用性使其成为初学者们的首选。这样我想要强调的一点是,框架可以类比为编程语言,仅为我们实现项目效果的工具,也就是我们…...
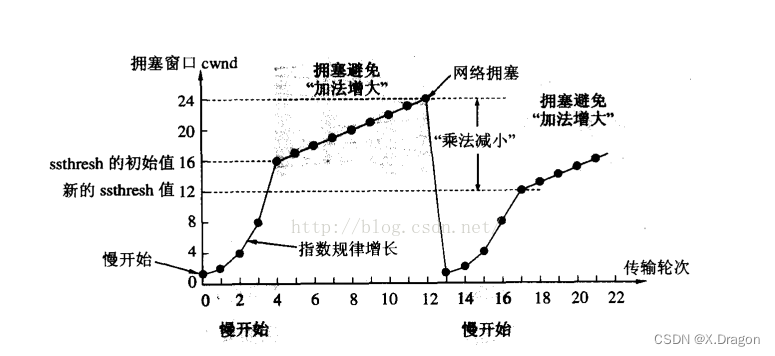
【计算机网络】深入理解TCP协议二(连接管理机制、WAIT_TIME、滑动窗口、流量控制、拥塞控制)
TCP协议 1.连接管理机制2.再谈WAIT_TIME状态2.1理解WAIT_TIME状态2.2解决TIME_WAIT状态引起的bind失败的方法2.3监听套接字listen第二个参数介绍 3.滑动窗口3.1介绍3.2丢包情况分析 4.流量控制5.拥塞控制5.1介绍5.2慢启动 6.捎带应答、延时应答 1.连接管理机制 正常情况下&…...
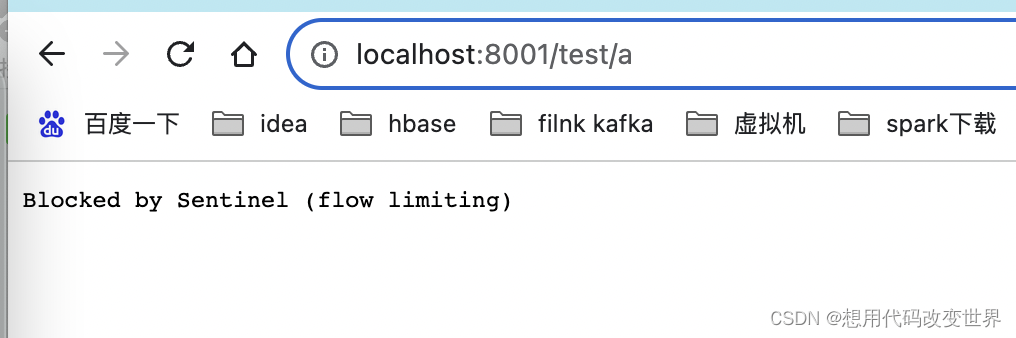
springboot整合sentinel完成限流
1、直入正题,下载sentinel的jar包 1.1 直接到Sentinel官网里的releases下即可下载最新版本,Sentinel官方下载地址,直接下载jar包即可。不过慢,可能下载不下来 1.2 可以去gitee去下载jar包 1.3 下载完成后,进行打包…...

signal(SIGPIPE, SIG_IGN)
linux查看signal常见信号。 [rootplatform:]# kill -l1) HUP2) INT3) QUIT4) ILL5) TRAP6) ABRT7) BUS8) FPE9) KILL 10) USR1 11) SEGV 12) USR2 13) PIPE 14) ALRM 15) TERM 16) STKFLT 17) CHLD 18) CONT 19) STOP 20) TSTP 21) TTIN 22) TTOU 23) URG 24) XCPU 25) XFSZ 2…...
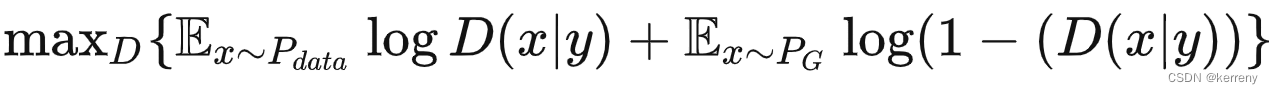
GAN学习笔记
1.原始的GAN 1.1原始的损失函数 1.1.1写法1参考1,参考2 1.1.2 写法2 where, G Generator D Discriminator Pdata(x) distribution of real data P(z) distribution of generator x sample from Pdata(x) z sample from P(z) D(x) Discriminator network G…...

layui框架学习(45: 工具集模块)
layui的工具集模块util支持固定条、倒计时等组件,同时提供辅助函数处理时间数据、字符转义、批量事件处理等操作。 util模块中的fixbar函数支持设置固定条(2.7版本的帮助文档中叫固定块),是指固定在页面一侧的工具条元素&…...
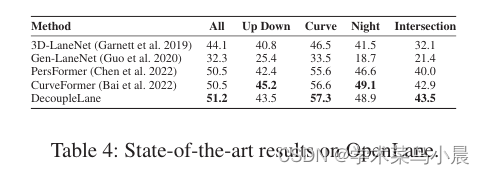
车道检测:Decoupling the Curve Modeling and Pavement Regression for Lane Detection
论文作者:Wencheng Han,Jianbing Shen 作者单位:University of Macau 论文链接:http://arxiv.org/abs/2309.10533v1 内容简介: 1)方向:车道检测 2)应用:车道检测 3)…...

【扩散生成模型】Diffusion Generative Models
提出扩散模型思想的论文: 《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》理解 扩散模型综述: “扩散模型”首篇综述论文分类汇总,谷歌&北大最新研究 理论推导、代码实现: What are Diffusion Models?…...

美联储加息步伐“暂停”!BTC凌晨力守27000美元!
美东时间9月20日下午,美联储宣布放缓加息步伐,将联邦基金利率目标维持在5.25%至5.50%的区间不变,保持在22年来的最高点,符合市场预期。 在最新的FOMC声明中,美联储表示最近的指标表明,经济活动一直在稳步扩…...

微信小程序与idea后端如何进行数据交互
交互使用的其实就是调用的req.get(url)方法 进行路径访问,你要先保证自己的springboot项目已经成功运行了: 如下: 如何交互的? 微信小程序:如下为index.js页面 在onLoad()事件中调用方法Project.findAllCities() 要…...

麒麟系统上跑32位老程序,别再折腾了!用这个离线打包法,5分钟搞定依赖
麒麟系统32位程序兼容方案:离线依赖打包全流程指南 在国产化操作系统迁移浪潮中,许多企业面临一个共同难题——那些关键业务依赖的32位遗留程序如何在仅支持64位的新系统上运行?本文将以麒麟系统为例,详解一套经过实战检验的离线依…...

CANN Ascend C矩阵乘法特殊配置
GetSpecialMDLConfig 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gi…...

3个关键决策:为什么顶级技术团队选择Arco Design Pro构建企业级应用
3个关键决策:为什么顶级技术团队选择Arco Design Pro构建企业级应用 【免费下载链接】arco-design-pro An out-of-the-box solution to quickly build enterprise-level applications based on Arco Design. 项目地址: https://gitcode.com/gh_mirrors/ar/arco-de…...

我把Cursor和Copilot都扔了:实测Token从120万砍到4万
Claude Code称霸后,我把Cursor和Copilot都扔了:实测Token从120万砍到4万上周,Graphon AI 低调完成 830 万美元融资,推出 “pre-model intelligence layer” 来解决企业多模态数据关联难题;几乎同一时间,Ant…...

如何掌握Il2CppDumper:Unity逆向工程实战指南与深度解析
如何掌握Il2CppDumper:Unity逆向工程实战指南与深度解析 【免费下载链接】Il2CppDumper Unity il2cpp reverse engineer 项目地址: https://gitcode.com/gh_mirrors/il/Il2CppDumper 你是否曾面对Unity游戏的il2cpp二进制文件感到无从下手?是否在…...
)
基于 SOFAJRaft + Spring Boot 构建高可用 KV 存储集群(完整源码)
基于 SOFAJRaft + Spring Boot 构建高可用 KV 存储集群(完整源码) 引言 在分布式系统中,一致性 是核心难题。Raft 是比 Paxos 更易于理解的共识算法,而 SOFAJRaft 是蚂蚁集团开源的 Java 高性能 Raft 实现。 本文带你从零构建一个 3 节点高可用 KV 存储集群,包含完整源码、…...

手把手改造libmad:将一次性加载改为流式解码,拯救你的内存不足嵌入式系统
嵌入式音频革命:libmad流式解码改造实战指南 在资源受限的嵌入式环境中处理MP3音频,就像试图用吸管喝光整个游泳池的水——传统的一次性加载方式会让你的系统瞬间窒息。当树莓派Pico这类微控制器只有264KB的RAM时,一个5MB的MP3文件就能让内存…...

3个架构策略:构建企业级前端应用的完整解决方案
3个架构策略:构建企业级前端应用的完整解决方案 【免费下载链接】arco-design-pro An out-of-the-box solution to quickly build enterprise-level applications based on Arco Design. 项目地址: https://gitcode.com/gh_mirrors/ar/arco-design-pro 在快速…...

OpCore Simplify:告别繁琐配置,轻松构建黑苹果OpenCore EFI的智能工具
OpCore Simplify:告别繁琐配置,轻松构建黑苹果OpenCore EFI的智能工具 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑…...

一键永久保存:B站缓存视频转换终极方案,让珍贵内容不再消失
一键永久保存:B站缓存视频转换终极方案,让珍贵内容不再消失 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾有过…...