PyTorch实战:实现MNIST手写数字识别
前言
PyTorch可以说是三大主流框架中最适合初学者学习的了,相较于其他主流框架,PyTorch的简单易用性使其成为初学者们的首选。这样我想要强调的一点是,框架可以类比为编程语言,仅为我们实现项目效果的工具,也就是我们造车使用的轮子,我们重点需要的是理解如何使用Torch去实现功能而不要过度在意轮子是要怎么做出来的,那样会牵扯我们太多学习时间。以后就出一系列专门细解深度学习框架的文章,但是那是较后期我们对深度学习的理论知识和实践操作都比较熟悉才好开始学习,现阶段我们最需要的是学会如何使用这些工具。
深度学习的内容不是那么好掌握的,包含大量的数学理论知识以及大量的计算公式原理需要推理。且如果不进行实际操作很难够理解我们写的代码究极在神经网络计算框架中代表什么作用。不过我会尽可能将知识简化,转换为我们比较熟悉的内容,我将尽力让大家了解并熟悉神经网络框架,保证能够理解通畅以及推演顺利的条件之下,尽量不使用过多的数学公式和专业理论知识。以一篇文章快速了解并实现该算法,以效率最高的方式熟练这些知识。
博主专注数据建模四年,参与过大大小小数十来次数学建模,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。此专栏的目的就是为了让零基础快速使用各类数学模型、机器学习和深度学习以及代码,每一篇文章都包含实战项目以及可运行代码。博主紧跟各类数模比赛,每场数模竞赛博主都会将最新的思路和代码写进此专栏以及详细思路和完全代码。希望有需求的小伙伴不要错过笔者精心打造的专栏。
一文速学-数学建模常用模型
一、数据集加载
MNIST(Modified National Institute of Standards and Technology)是一个手写数字数据集,通常用于训练各种图像处理系统。
它包含了大量的手写数字图像,这些数字从0到9。每个图像都是一个灰度图像,大小为28x28像素,表示了一个手写数字。

MNIST数据集分成两部分:训练集和测试集。训练集通常包含60,000张图像,用于训练模型。测试集包含10,000张图像,用于评估模型的性能。
MNIST数据集是一个非常受欢迎的数据集,被用于测试和验证各种机器学习和深度学习模型,特别是在图像识别任务中。大家可以直接访问官网下载或者是在程序中使用torchvision下载数据集。
官网:THE MNIST DATABASE
一共4个文件,训练集、训练集标签、测试集、测试集标签:
| 文件名称 | 大小 | 内容 |
|---|---|---|
| train-labels-idx1-ubyte.gz | 9,681 kb | 55000张训练集,5000张验证集 |
| train-labels-idx1-ubyte.gz | 29 kb | 训练集图片对应的标签 |
| t10k-images-idx3-ubyte.gz | 1,611 kb | 10000张测试集 |
| t10k-labels-idx1-ubyte.gz | 5 kb | 测试集图片对应的标签 |
程序加载MNIST数据集:
from torch.utils.data import DataLoader
import torchvision.datasets as dsetstransform = transforms.Compose([transforms.Grayscale(num_output_channels=1), # 将图像转为灰度transforms.ToTensor(), # 将图像转为张量transforms.Normalize((0.1307,), (0.3081,))
])#MNIST dataset
train_dataset = dsets.MNIST(root = '/ml/pymnist', #选择数据的根目录train = True, #选择训练集transform = transform, #不考虑使用任何数据预处理download = True #从网络上下载图片)
test_dataset = dsets.MNIST(root = '/ml/pymnist',#选择数据的根目录train = False,#选择测试集transform = transform, #不考虑使用任何数据预处理download = True #从网络上下载图片)
#加载数据
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size = batch_size,shuffle = True #将数据打乱)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size = batch_size,shuffle = True)图片展示:
import matplotlib.pyplot as plt
digit = train_dataset.train_data[0]
plt.imshow(digit,cmap=plt.cm.binary,interpolation='none')
plt.title("Labels: {}".format(train_dataset.train_labels[0]))
plt.show()
之后需要切分数据集,分为训练集和测试集,MNIST数据集已经做好了直接使用就好了:
print("train_data:",train_dataset.train_data.size())
print("train_labels:",train_dataset.train_labels.size())
print("test_data:",test_dataset.test_data.size())
print("test_labels:",test_dataset.test_labels.size())
train_data: torch.Size([60000, 28, 28]) train_labels: torch.Size([60000]) test_data: torch.Size([10000, 28, 28]) test_labels: torch.Size([10000])
还需要确定批次的尺寸,在神经网络训练中,batch_size 是指每次迭代训练时,模型同时处理的样本数量。它在训练过程中起到了几个重要作用:
- 加速训练过程:通过同时处理多个样本,利用了现代计算机的并行计算能力,可以加速训练过程,尤其在使用GPU时。
- 减少内存消耗:一次性加载整个训练集可能会占用大量内存,而将数据分批次加载可以降低内存消耗,使得在内存受限的环境中也能进行训练。
- 提高模型泛化能力:在训练过程中,模型会根据每个batch的数据调整权重,而不是依赖于整个训练集。这样可以提高模型对不同样本的泛化能力。
- 避免陷入局部极小值:随机选择的小批量样本可以帮助模型避免陷入局部极小值。
- 增加噪声鲁棒性:在每次迭代中,模型只看到了一个小样本,这可以看作一种随机噪声,有助于提高模型的鲁棒性。
- 方便在线学习:对于在线学习任务,可以动态地加载新的数据批次,而不需要重新训练整个模型。
总的来说,合理选择合适的batch_size可以使训练过程更加高效、稳定,并且能够提高模型的泛化能力。然而,过大的batch_size可能会导致内存溢出或训练速度变慢,过小的batch_size可能会导致模型收敛困难。因此,选择合适的batch_size需要在实践中进行调试和优化。
print("批次的尺寸:",train_loader.batch_size)
print("load_train_data:",train_loader.dataset.train_data.shape)
print("load_train_labels:",train_loader.dataset.train_labels.shape)
批次的尺寸: 100 load_train_data: torch.Size([60000, 28, 28]) load_train_labels: torch.Size([60000])
从输出结果中,可以看到原始数据集和数据打乱按照批次读取的数据集的总行数是一样的,实际操作中train_loader以及test_loader将作为神经网络的输入数据源。
二、定义神经网络
在前面的文章中已经带着大家搭建过好几遍神经网络了,注意初始化网络和对应的输入层,隐藏层和输出层。
import torch.nn as nn
import torchinput_size = 784 #mnist的像素为28*28
hidden_size = 500
num_classes = 10#输出为10个类别分别对应于0~9#创建神经网络模型
class Neural_net(nn.Module):
#初始化函数,接受自定义输入特征的维数,隐含层特征维数以及输出层特征维数def __init__(self,input_num,hidden_size,out_put):super(Neural_net,self).__init__()self.layer1 = nn.Linear(input_num,hidden_size) #从输入到隐藏层的线性处理self.layer2 = nn.Linear(hidden_size,out_put) #从隐藏层到输出层的线性处理def forward(self,x):x = self.layer1(x) #输入层到隐藏层的线性计算x = torch.relu(x) #隐藏层激活x = self.layer2(x) #输出层,注意,输出层直接接lossreturn xnet = Neural_net(input_size,hidden_size,num_classes)
print(net)Neural_net((layer1): Linear(in_features=784, out_features=500, bias=True)(layer2): Linear(in_features=500, out_features=10, bias=True) )
super(Neural_net, self).init() 是 Python 中用于调用父类的方法或属性的一种方式。在这里,Neural_net 是你定义的神经网络模型的类名,它继承了 nn.Module 类,而 nn.Module 是 PyTorch 中用于构建神经网络模型的基类。也就是说,你的神经网络模型会继承 nn.Module 的所有属性和方法,这样你可以在 Neural_net 类中使用 nn.Module 中定义的各种功能,比如添加神经网络层、指定损失函数等。
三、训练模型
只有要注意一下Variable,之前的文章中又提到过Variable。
Variable是PyTorch早期版本(0.4版本之前)中用于构建计算图的抽象,它包含了data、grad和grad_fn等属性,可以用于构建计算图,并在反向传播时自动计算梯度。但从PyTorch 0.4版本开始,Variable被官方废弃,而Tensor直接支持了自动求导功能,不再需要显式地创建Variable。
因此,Autograd是PyTorch实现自动求导的核心机制,而Variable是早期版本中用于构建计算图的一种抽象,现在已经被Tensor所取代。 Autograd会自动追踪Tensor上的操作,并在需要时计算梯度,从而实现反向传播。
#optimization
import numpy as np
from torchvision import transformslearning_rate = 1e-3 #学习率
num_epoches = 5
criterion =nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(),lr = learning_rate) #随机梯度下降for epoch in range(num_epoches):print('current epoch = %d' % epoch)for i ,(images,labels) in enumerate(train_loader,0):images=images.view(-1,28*28)outputs = net(images) #将数据集传入网络做前向计算labels = torch.tensor(labels, dtype=torch.long)loss = criterion(outputs, labels) #计算lossoptimizer.zero_grad() #在做反向传播之前先清楚下网络状态loss.backward() #Loss反向传播optimizer.step() #更新参数if i % 100 == 0:print('current loss = %.5f' % loss.item())print('finished training')
current epoch = 1 current loss = 0.27720 current loss = 0.23612 current loss = 0.39341 current loss = 0.24683 current loss = 0.18913 current loss = 0.31647 current loss = 0.28518 current loss = 0.18053 current loss = 0.34957 current loss = 0.31319 current epoch = 2 current loss = 0.15138 current loss = 0.30887 current loss = 0.24257 current loss = 0.46326 current loss = 0.30790 current loss = 0.17516 current loss = 0.32319 current loss = 0.32325 current loss = 0.32066 current loss = 0.24271
四、准确度测试
各层的权重通过随机梯度下降法更新Loss之后,针对测试集数字分类的准确率:
#prediction
total = 0
correct =0
acc_list_test = []
for images,labels in test_loader:images=images.view(-1,28*28)outputs = net(images) #将数据集传入网络做前向计算_,predicts = torch.max(outputs.data,1)total += labels.size(0)correct += (predicts == labels).sum()acc_list_test.append(100 * correct / total)print('Accuracy = %.2f'%(100 * correct / total))
plt.plot(acc_list_test)
plt.xlabel('Epoch')
plt.ylabel('Accuracy On TestSet')
plt.show() 
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
相关文章:
PyTorch实战:实现MNIST手写数字识别
前言 PyTorch可以说是三大主流框架中最适合初学者学习的了,相较于其他主流框架,PyTorch的简单易用性使其成为初学者们的首选。这样我想要强调的一点是,框架可以类比为编程语言,仅为我们实现项目效果的工具,也就是我们…...
【计算机网络】深入理解TCP协议二(连接管理机制、WAIT_TIME、滑动窗口、流量控制、拥塞控制)
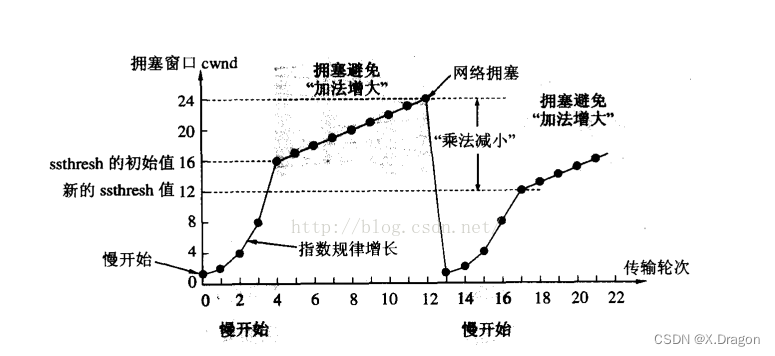
TCP协议 1.连接管理机制2.再谈WAIT_TIME状态2.1理解WAIT_TIME状态2.2解决TIME_WAIT状态引起的bind失败的方法2.3监听套接字listen第二个参数介绍 3.滑动窗口3.1介绍3.2丢包情况分析 4.流量控制5.拥塞控制5.1介绍5.2慢启动 6.捎带应答、延时应答 1.连接管理机制 正常情况下&…...
springboot整合sentinel完成限流
1、直入正题,下载sentinel的jar包 1.1 直接到Sentinel官网里的releases下即可下载最新版本,Sentinel官方下载地址,直接下载jar包即可。不过慢,可能下载不下来 1.2 可以去gitee去下载jar包 1.3 下载完成后,进行打包…...

signal(SIGPIPE, SIG_IGN)
linux查看signal常见信号。 [rootplatform:]# kill -l1) HUP2) INT3) QUIT4) ILL5) TRAP6) ABRT7) BUS8) FPE9) KILL 10) USR1 11) SEGV 12) USR2 13) PIPE 14) ALRM 15) TERM 16) STKFLT 17) CHLD 18) CONT 19) STOP 20) TSTP 21) TTIN 22) TTOU 23) URG 24) XCPU 25) XFSZ 2…...
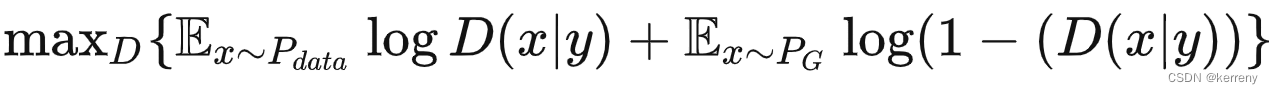
GAN学习笔记
1.原始的GAN 1.1原始的损失函数 1.1.1写法1参考1,参考2 1.1.2 写法2 where, G Generator D Discriminator Pdata(x) distribution of real data P(z) distribution of generator x sample from Pdata(x) z sample from P(z) D(x) Discriminator network G…...

layui框架学习(45: 工具集模块)
layui的工具集模块util支持固定条、倒计时等组件,同时提供辅助函数处理时间数据、字符转义、批量事件处理等操作。 util模块中的fixbar函数支持设置固定条(2.7版本的帮助文档中叫固定块),是指固定在页面一侧的工具条元素&…...
车道检测:Decoupling the Curve Modeling and Pavement Regression for Lane Detection
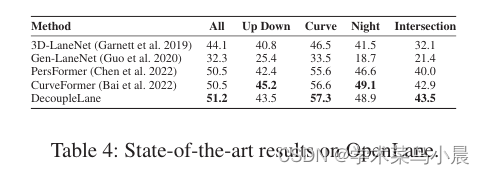
论文作者:Wencheng Han,Jianbing Shen 作者单位:University of Macau 论文链接:http://arxiv.org/abs/2309.10533v1 内容简介: 1)方向:车道检测 2)应用:车道检测 3)…...

【扩散生成模型】Diffusion Generative Models
提出扩散模型思想的论文: 《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》理解 扩散模型综述: “扩散模型”首篇综述论文分类汇总,谷歌&北大最新研究 理论推导、代码实现: What are Diffusion Models?…...

美联储加息步伐“暂停”!BTC凌晨力守27000美元!
美东时间9月20日下午,美联储宣布放缓加息步伐,将联邦基金利率目标维持在5.25%至5.50%的区间不变,保持在22年来的最高点,符合市场预期。 在最新的FOMC声明中,美联储表示最近的指标表明,经济活动一直在稳步扩…...

微信小程序与idea后端如何进行数据交互
交互使用的其实就是调用的req.get(url)方法 进行路径访问,你要先保证自己的springboot项目已经成功运行了: 如下: 如何交互的? 微信小程序:如下为index.js页面 在onLoad()事件中调用方法Project.findAllCities() 要…...

Java 学习路线分享 maven 是什么?
Maven 是一款基于 Java 平台的项目管理和整合工具,它将项目的开发和管理过程抽象成一个项目对象模型(POM)。开发人员只需要做一些简单的配置,Maven 就可以自动完成项目的编译、测试、打包、发布以及部署等工作。 Maven 是使用 Ja…...
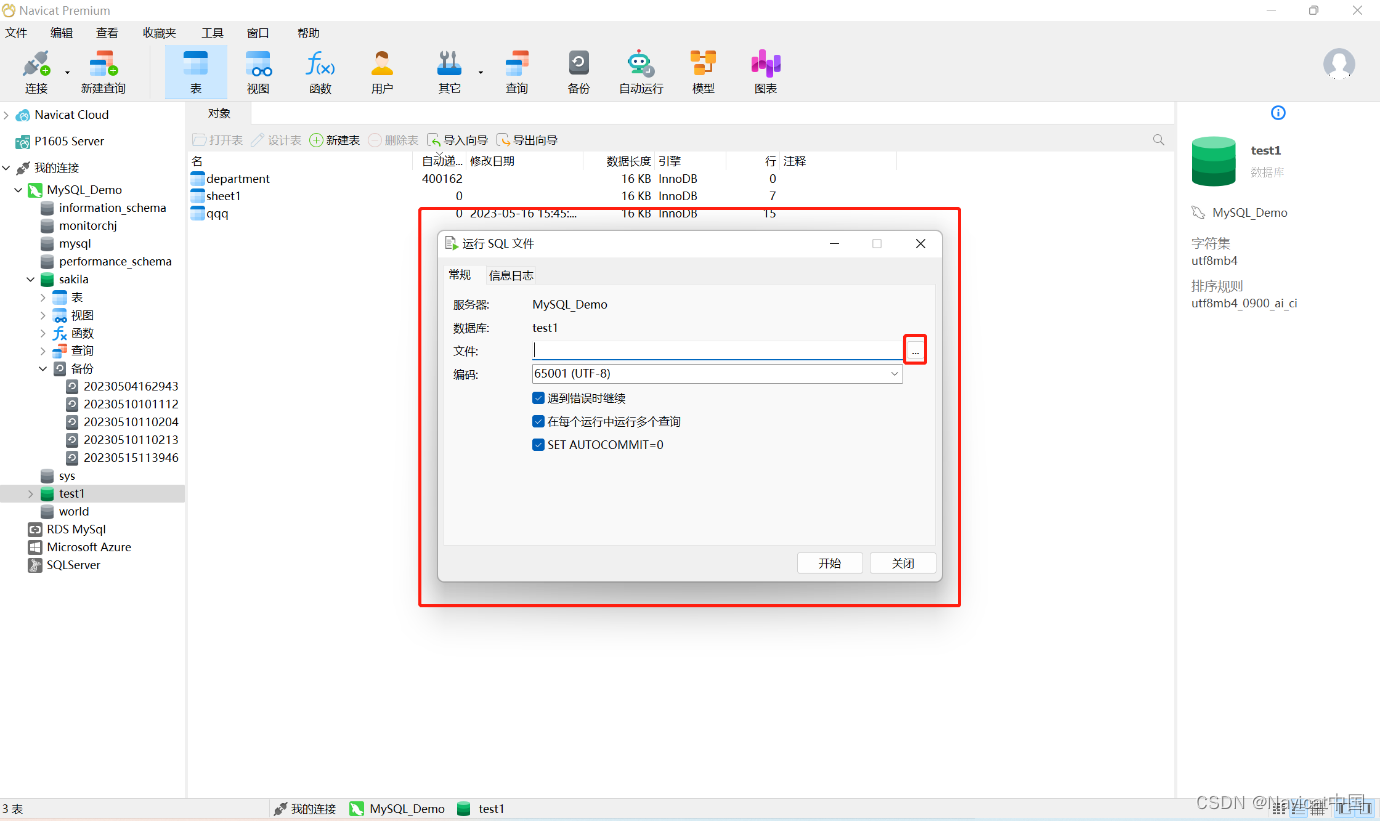
实战演练 | Navicat 常用功能之转储与运行 SQL 文件
数据库管理工作中,"转储 SQL 文件"和"运行 SQL 文件"是两个极为常见操作。一般来说,用户使用数据库管理工具或命令行工具来完成。Navicat 管理开发工具中的“转储 SQL 文件”和“运行 SQL 文件”功能具有直观易用的界面、多种文件格…...
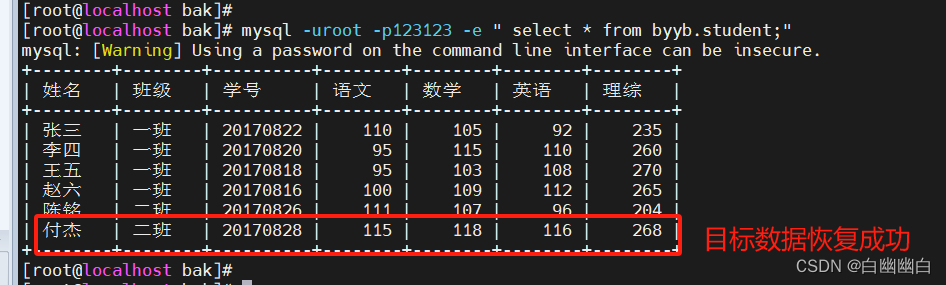
MySQL的备份与恢复
备份与恢复 一、备份1.1 数据备份的必要性1.2 数据备份分类1.2.1 物理备份1.2.2 逻辑备份 1.3 数据库备份策略1.4 常用的备份方法和工具1.5 数据库上云迁移 二、MySQL完全备份2.1 简介2.2 物理冷备份与恢复2.2.1 物理冷备份2.2.2 解压恢复 2.3 mysqldump备份与恢复1)…...

Python中的函数未定义的错误
前言: 嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 通过这个解释,我们将了解当Python程序显示类似NameError: name ‘’ is not defined的错误时,即使该函数存在于脚本中&…...

AG35学习笔记(二):安装编译SDK、CMakeLists编译app、Scons编译server
目录 一、概述二、安装SDK2.1 网盘SDK - 权限不够2.2 bj41 - 需要交叉source2.3 mullen - relocate_sdk.py路径有误 三、编译SDK3.1 /bin/sh: 1: gcc: not found3.2 curses.h: No such file or directory 四、CMakeLists - 编译app4.1 cmake - 项目构建4.2 make - 项目编译4.3 …...

多台服务器sessionId共享
目录 多台服务器sessionId共享解决方案:ASP.NET Core 参考代码(NET 7):登录处理登录(请求)过滤器过滤器使用BaseController 多台服务器sessionId共享 session id是服务器首次与浏览器创建连接时,生成的id值,存入浏览器…...
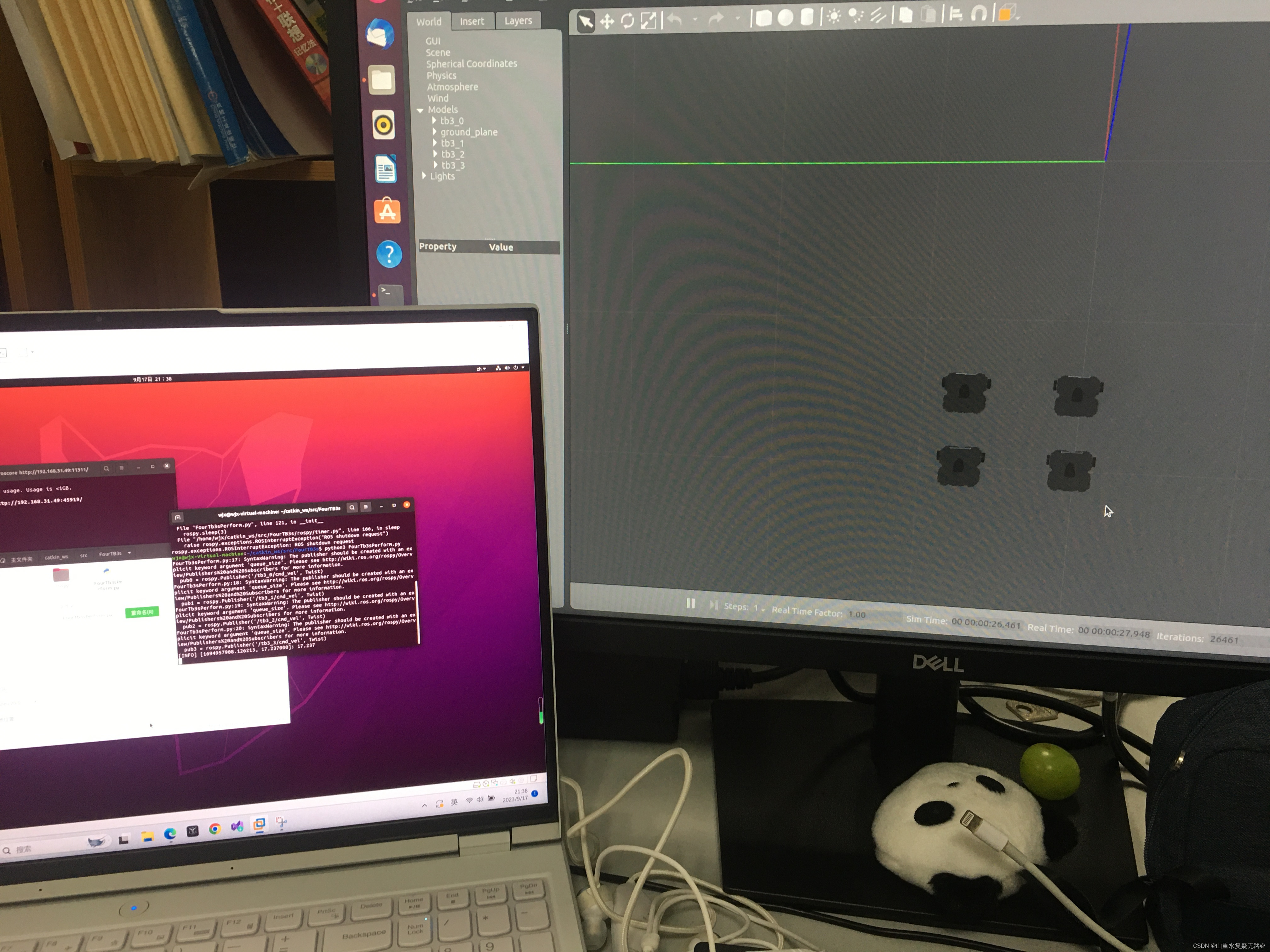
如何在Gazebo中实现多机器人编队仿真
文章目录 前言一、仿真前的配置二、实现步骤1.检查PC和台式机是否通讯成功2.编队中对单个机器人进行独立的控制3、对机器人进行编队控制 前言 实现在gazebo仿真环境中添加多个机器人后,接下来进行编队控制,对具体的实现过程进行记录。 一、仿真前的配置…...

迅为iTOP-iMX6QPLUS-Android6.0下uboot添加网卡驱动
本文档介绍在 iTOP-iMX6Q 和 iTOP-iMX6Q-PLUS 安卓 6.0 的 uboot 上添加网卡驱 动,添加完网卡驱动以后,uboot 就可以正常使用网络了。 1 具体步骤 1.1 修改 mx6sabre_common.h 文件 在 iTOP-iMX6_android6.0.1 源码目录下输入以下命令,打…...
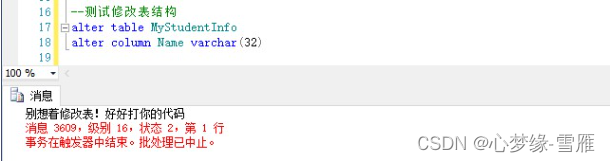
sql server 触发器的使用
看数据库下的所有触发器及状态 SELECT a.name 数据表名 , sysobjects.name AS 触发器名 , sysobjects.crdate AS 创建时间 , sysobjects.info , sysobjects.status FROM sysobjects LEFT JOIN ( SELECT * FROM sysobjects WHERE xtype U ) AS a ON sysobjects.parent_obj a.…...
使用亚马逊云服务器在 G4 实例上运行 Android 应用程序
随着 Android 应用程序和游戏变得越来越丰富,其中有些甚至比 PC 上的软件更易于使用和娱乐,因此许多人希望能够在云上运行 Android 游戏或应用程序,而在 EC2 实例上运行 Android 的解决方案可以让开发人员更轻松地测试和运行 Android 应用程序…...

D26: 向下负责——保护团队免受 AI 焦虑影响
文章目录 D26: 向下负责——保护团队免受 AI 焦虑影响 🎯 为什么这个话题重要? 现实痛点:团队 AI 焦虑的三种表现 一个真实场景 一、理解 AI 焦虑的本质 1.1 焦虑从何而来? 1.2 焦虑的恶性循环 1.3 一个心理学视角 二、建立团队心理安全网 2.1 心理安全:团队韧性的基石 2…...

软件设计师下午题训练1-3题 练习真题训练10
一、2019下1、问题1E1:帮买顾问E2:车辆交易系统E3:物流商2、问题2D1:线索表D2:订单表D3:路线表D4:合约表D5:物流商表3、问题3数据流 起点 终点物流信息 P5 …...
完全解析:从原理到代码,深入浅出)
DDR3内存训练(Training)完全解析:从原理到代码,深入浅出
DDR3内存训练(Training)完全解析:从原理到代码,深入浅出 目录 一、为什么需要内存训练? 二、DDR3训练的核心原理 三、训练流程详解:一场精密的三步仪式 四、代码实战:从初始化到训练完成...

量子纠错AI预解码器:加速表面码实时处理
1. 量子纠错与实时解码的挑战量子计算的核心难题之一是量子比特的脆弱性。与环境相互作用导致的退相干效应,使得量子信息在极短时间内就会发生不可逆的丢失。表面码(Surface Code)作为最具实用前景的量子纠错方案,通过将逻辑量子比…...

微信消息智能路由系统:3步搭建你的跨群信息高速公路
微信消息智能路由系统:3步搭建你的跨群信息高速公路 【免费下载链接】wechat-forwarding 在微信群之间转发消息 项目地址: https://gitcode.com/gh_mirrors/we/wechat-forwarding 在数字化协作时代,微信群已成为团队沟通的核心渠道。然而…...

AI专著生成神器登场!快速输出20万字专著,写作不用愁!
学术专著写作困境与AI工具的崛起 对于许多学术研究者来说,撰写学术专著时面临的最大挑战,无疑是“有限的精力”和“无穷的需求”之间的矛盾。撰写专著通常需要三到五年,甚至更长时间,而研究者还需平衡教学、科研项目和学术交流等…...

Midjourney咖啡印相落地实操:3步完成色彩校准、5种纸张适配方案与打印机ICC配置清单
更多请点击: https://intelliparadigm.com 第一章:Midjourney Coffee印相技术原理与工艺边界 Midjourney Coffee印相并非官方命名的技术标准,而是社区对一类融合生成式AI图像(如Midjourney输出)与传统咖啡渍显影工艺的…...

OpenClaw 消息路由与广播机制深度解析
OpenClaw 消息路由与广播机制深度解析 作者: Social Agent (小社) 日期: 2026-03-18 研究模块: channels/channel-routing + broadcast-groups + group-messages 一、消息路由的核心设计 1.1 确定性路由,而非 AI 决策 OpenClaw 消息路由最重要的设计决策是:路由是确定性的…...

5分钟掌握FanControl:Windows风扇控制的终极免费解决方案
5分钟掌握FanControl:Windows风扇控制的终极免费解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...

构建个人游戏串流服务器:Sunshine开源方案深度指南
构建个人游戏串流服务器:Sunshine开源方案深度指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款开源的自托管游戏串流服务端,专为Moonlig…...